基于分布式數據流的網絡處理器數據收集分類平臺
2019-02-20 02:07:48段汝林林德豐
現代電子技術 2019年4期
段汝林 林德豐
關鍵詞: 分布式數據流; 網絡處理器; 數據收集; 數據分類; 分類平臺; 特征更新
中圖分類號: TN711?34; TP274+.2 ? ? ? ? ? ? ?文獻標識碼: A ? ? ? ? ? ? ? ? ? ?文章編號: 1004?373X(2019)04?0117?04
Network processor data acquisition and classification platform
based on distributed data streams
DUAN Rulin1,2, LIN Defeng1
(1. School of Education Information Technology, South China Normal University, Guangzhou 510631, China;
2. Department of Computer Engineering, Guangdong Youth Vocational College, Guangzhou 510545, China)
Abstract: The accurate data classifier is not constructed when the adaptive distributed data stream processing and adjustment technology is used for acquisition and classification of distributed data, resulting in classification accuracy deviation. Therefore, a network processor data acquisition and classification platform based on distributed data streams is designed. The overall architecture of the designed platform includes the platform management layer, distributed data acquisition layer and distributed data classification layer. The network processor receives the distributed data streams by means of the network switch port. The transformers and PHYs are adopted to process the obtained data, and interact with the master control chip FPGA, so as to save the data and realize collection of distributed data streams. The distributed data stream classification process realized in the network processor includes the training phase and the testing phase. During the training phase, the update rules of distributed data streams are used to complete the data feature selection. During the testing phase, the classification feature update of distributed data streams is conducted, and screening of the feature data with high correlation degrees is conducted, so as to realize classification of distributed data streams. The experimental results show that the designed platform has an average classification accuracy of as high as 99.5%, a short time?consumption, and small memory usage.
Keywords: distributed data stream; network processor; data acquisition; data classification; classification platform; feature update
隨著大數據時代的到來,計算機網絡不斷更新、分布式計算機技術日新月異,使得數據流分布在不同的網絡節點上[1],因此,網絡處理器如何實現分布式數據流高效、全面、準確的收集與分類成為重點研究的問題。文獻[2]中,采用基于Web數據的自動采集與分類系統對網絡信息進行收集與分類,能夠實現集中式數據流的有效采集與分類,但面對分布式數據流的采集與分類性能較弱。文獻[3]采用自適應的分布式數據流處理調整技術對網絡處理器中的分布式數據流進行收集與分類,能夠根據具體的數據分布狀況進行數據采集,缺點是未構建精準的數據分類器,導致分類精度有所偏差。文獻[4]描述的是一種面向分布式數據流的閉頻繁模式挖掘方法,能夠有效挖掘分布式數據流的特征并實施準確分類,但在分布式數據流采集階段,僅對分布式數據庫進行一次掃描,采集到的數據不全面。針對上述問題,本文設計基于分布式數據流的網絡處理器數據收集分類平臺,實現網絡中分布式數據流高效、準確收集與分類。
1 ?網絡處理器數據收集分類平臺
1.1 ?基于分布式數據流的網絡處理器平臺總體架構
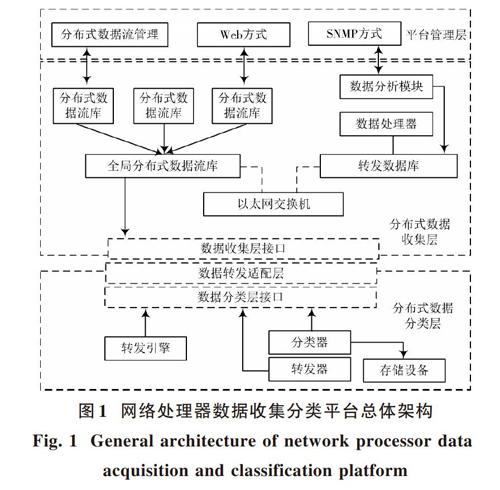
圖1為網絡處理器數據收集分類平臺的總體架構,主要包括平臺管理層、分布式數據收集層、分布式數據分類層[5]。平臺管理層主要是對分布式數據流、Web方式、SNMP方式進行管理,與分布式數據收集層連接,為分布式數據流的收集提供基礎;分布式數據分類層與分布式數據收集層可通過數據轉發適配層的接口進行連接,分布式數據收集層采集的分布式數據流信息被傳輸到分布式數據分類層,根據相關標準進行數據分類。
1.2 ?基于分布式數據流的網絡處理器數據收集
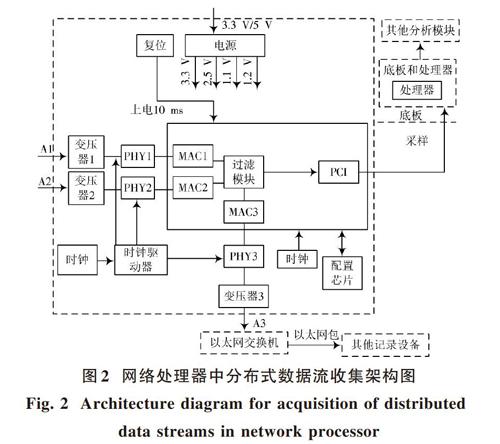
網絡處理器中分布式數據流的收集,主要采用與網絡交換機的隨機端口連接的方式收集數據信息,網絡處理器中的數據收集器對獲取的數據進行處理[6],確保收集到的數據完整保存。
網絡處理器中分布式數據流采集架構如圖2所示。圖2中,網絡處理器通過A1接口、A2接口接收網絡中分布式數據流,數據收集器的變壓器、PHY會對收集到的數據進行處理,然后與主控芯片FPGA進行交互。經過數據收集器處理后的分布式數據,從A3接口經過以太網交換機被完整地傳輸到記錄設備中,實現分布式數據流的收集。
1.3 ?基于分布式數據流的網絡處理器數據分類
網絡處理器分布式數據流分類的主要過程為訓練階段與測試階段。訓練階段主要進行分布式數據流的訓練、對其進行特征選擇[7];測試階段主要進行分布式數據流特征選擇、對關聯度較大的特征數據進行篩選,實現分布式數據流的分類。
在分布式數據流訓練階段,網絡處理器對分布式數據流進行特征選擇時,需采用分布式數據頻率調整規則更新分布式數據頻率,分布式數據流詳細更新規則為[8]:
[HDdj=cdjB]
式中:[cdj]為包含特征項[dj]的分布式數據數量;[B]為訓練集的分布式數據數量。
利用獲取的分布式數據流中特征數據的[HD]值,根據特征數據是否包含分布式數據流分類特征實施更新。設置[O1=uii=1,2,…,x]表示網絡處理器中分布式數據流的一級分類標準集合,其中,[ui]表示一級分類標準,[x]表示一級分類標準的數量。[O2=vii=1,2,…,a]表示網絡處理器中分布式數據流的二級分類標準集合。其中,[vi]表示二級分類標準,[a]表示二級分類標準的數量。經過分布式數據流特征選擇后獲取新特征集合[A=djj=1,2,…,m],拆分不符合分布式數據流特征分類標準的數據,[A1=djij=1,2,…,m;i=1,2,…,l]為[dj]拆分后的特征子集,[dj]拆分后的分布式數據用[dji]描述,[m]為特征項數量,特征子集包含[l]個分布式特征數據。
定義分布式數據流的分類閾值用[α,β]描述,詳細的數據收集分類過程為:
進行初始化,[A=?]
[Fori=1,2,…,n]
[IFHDdj<aTHENdj?A]
[IFdj∩ui∈A1THENA=dj,A,HDdj=β]
[IFdj∩vi∈A1THENA=dj,A,HDdj=β-1]
根據上述的數據收集分類過程,能夠降低數據特征的維度,獲取關聯度較大的特征數據[9],對關聯度較大的特征數據實施篩選,可獲取符合分類標準的分布式數據流分類結果,實現網絡處理器數據的有效分類[10]。
2 ?實驗分析
2.1 ?平臺性能測試
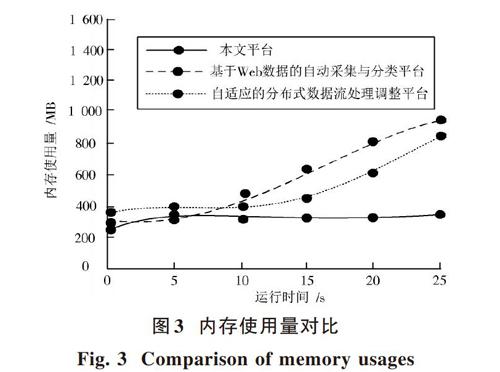
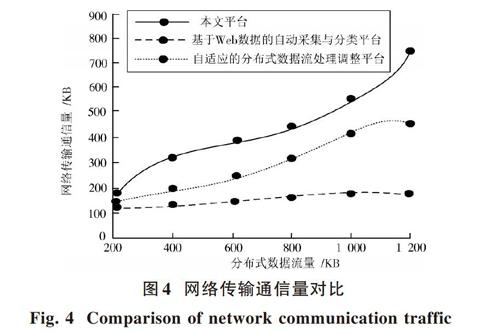
為了驗證本文設計平臺的性能,采用本文平臺、自適應的分布式數據流處理調整平臺和基于Web數據的自動采集與分類平臺構建三種仿真測試平臺。實驗從運行時間、內存使用量以及網絡通信傳輸量三方面驗證本文平臺的性能。表1為三種平臺在不同分布式數據流量下進行數據收集與分類的運行時間對比情況;圖3描述了不同平臺的內存使用量對比情況;圖4描述了不同平臺的網絡通信傳輸量對比情況。

分析表1可知,本文平臺的運行時間均值為2.98 s,隨著分布式數據流量大幅度增加,本文平臺的運行時間增長比較緩慢,運行時差較小,說明本文平臺面對大規模分布式數據流量同樣具有較高的效率;自適應的分布式數據流處理調整平臺運行時間均值為9.86 s,該平臺面對小規模的分布式數據流量,運行效率較高,但隨著分布式數據流量的增大,運行時間快速增長,直至5 000 KB時,運行時間為18.3 s,用時較長;基于Web數據的自動采集與分類平臺的運行時間均值為11.34 s,該平臺在分布式數據流量為1 000 KB與5 000 KB時運行時間分別為4.6 s,18.9 s,運行用時相對本文平臺較長,效率較低。
由圖3能夠看出,隨著運行時間的增長,本文平臺的內存使用量最少,基本穩定在300 MB左右;自適應的分布式數據流處理調整平臺所占內存隨著時間的增長呈現大幅度增長,最高達到800 MB;基于Web數據的自動采集與分類平臺的內存使用量同樣隨著時間的增長呈現較大漲幅,最大值為910 MB。
分析圖4可知,三種平臺在實驗初始階段分布式數據流量為200 KB時的網絡傳輸通信量相差較少,均在100~200 KB之間,本文平臺在之后5個分布式數據流量節點的網絡傳輸通信量增長幅度最大;自適應的分布式數據流處理調整平臺在之后5個分布式數據流量節點的網絡傳輸通信量增長幅度較小;基于Web數據的自動采集與分類平臺分布式數據流量不斷增加,該平臺傳輸通信量并沒有明顯的增長趨勢,說明該平臺的網絡傳輸能力較弱,進行分布式數據流收集的效率較低。
實驗結果表明,本文平臺能夠根據網絡處理器中分布式數據流的數量及時調整網絡傳輸通信量,數據傳輸效率較高,同時具有運行時間短、使用內存較小的優勢。
2.2 ?分布式數據流分類精確度分析
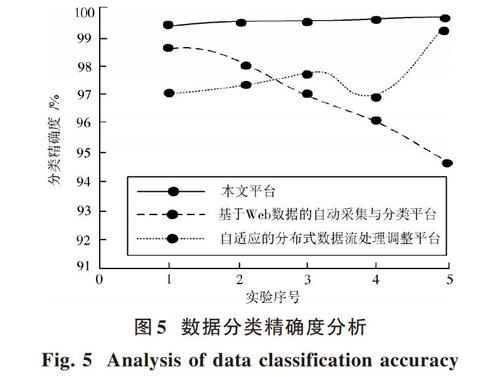
為驗證本文平臺對分布式數據流分類的高精確度優勢,利用第2.1節的實驗方法,構建3種仿真實驗平臺,人工控制網絡交換機發送分布式流量數據包,實驗分5次進行,分別記錄3種平臺的數據分類精確度如圖5所示。
由圖5得,3種平臺在實驗中呈現不同的分類狀態。本文平臺的分類精確度曲線始終位于99%~100%之間,分類精確度均值高達99.5%,無明顯波動狀態,說明本平臺不僅分類精確度高,且性能比較穩定。隨著實驗次數的增加,基于Web數據的自動采集與分類平臺的分類精確度呈大幅度下降趨勢,最低精確度僅為94.5%,該平臺不可用于網絡處理器中分布式數據流的有效分類。自適應的分布式數據流處理調整平臺分類精確度雖然總體上是上升的趨勢,但在第4次實驗時分類精確度僅為96.9%,降低了該平臺分類精確度均值。說明本文平臺能夠對分布式數據流進行準確分類。
3 ?結 ?論
本文設計基于分布式數據流的網絡處理器數據收集分類平臺,經驗證,該平臺能夠根據網絡處理器中分布式數據流的數量及時調整網絡傳輸通信量,數據傳輸效率較高;同時具有運行時間短、使用內存較小的優勢,可用于網絡處理器中分布式數據流的快速收集與分類;對于分布式數據流的分類,該平臺的分類精確度均值高達99.5%,所設計平臺為網絡中分布式數據的高效、科學處理提供參考依據。
參考文獻
[1] 段青玲,魏芳芳,張磊,等.基于Web數據的農業網絡信息自動采集與分類系統[J].農業工程學報,2016,32(12):172?178.
DUAN Qingling, WEI Fangfang, ZHANG Lei, et al. Automatic acquisition and classification system for agricultural network information based on Web data [J]. Transactions of the Chinese Society of Agricultural Engineering, 2016, 32(12): 172?178.
[2] 馬元文,王鵬,周之敏,等.一種自適應的分布式數據流處理調整技術[J].計算機工程,2015,41(12):15?20.
MA Yuanwen, WANG Peng, ZHOU Zhimin, et al. An adaptive adjustment technology of distributed data stream processing [J]. Computer engineering, 2015, 41(12): 15?20.
[3] 唐穎峰,陳世平.一種面向分布式數據流的閉頻繁模式挖掘方法[J].計算機應用研究,2015,32(12):3560?3564.
TANG Yingfeng, CHEN Shiping. Closed frequent patterns mining method over distributed data streams [J]. Application research of computers, 2015, 32(12): 3560?3564.
[4] 唐穎峰,陳世平.一種基于網格塊的分布式數據流聚類算法[J].小型微型計算機系統,2016,37(3):488?493.
TANG Yingfeng, CHEN Shiping. Distributed data stream clustering algorithm with grid blocks [J]. Journal of Chinese computer systems, 2016, 37(3): 488?493.
[5] ZHENG Z, JEONG H Y, HUANG T, et al. KDE based outlier detection on distributed data streams in multimedia network [J]. Multimedia tools & applications, 2017, 76(17): 18027?18045.
[6] PAPAPETROU O, GAROFALAKIS M, DELIGIANNAKIS A. Sketching distributed sliding?window data streams [J]. The VLDB journal, 2015, 24(3): 345?368.
[7] 田澤,索高華,張榮華,等.基于FPGA的AFDX網絡高速數據采集器設計[J].電子技術應用,2016,42(8):179?182.
TIAN Ze, SUO Gaohua, ZHANG Ronghua, et al. Design of high speed data acquisition system for AFDX network based on FPGA [J]. Application of electronic technique, 2016, 42(8): 179?182.
[8] 陳付梅,韓德志,畢坤,等.大數據環境下的分布式數據流處理關鍵技術探析[J].計算機應用,2017,37(3):620?627.
CHEN Fumei, HAN Dezhi, BI Kun, et al. Key technologies of distributed data stream processing based on big data [J]. Journal of computer applications, 2017, 37(3): 620?627.
[9] 李維聰,孫海蓉.基于LabVIEW的USB無線數據采集儀[J].計算機仿真,2015,32(2):455?458.
LI Weicong, SUN Hairong. A wireless data acquisition system based on USB and LabVIEW [J]. Computer simulation, 2015, 32(2): 455?458.
[10] RHO J, AZUMI T, OYAMA H, et al. Distributed processing for automotive data stream management system on mixed single? and multi?core processors [J]. ACM SIGBED review, 2016, 13(3): 15?22.
