深度置信網絡在齒輪故障診斷中的應用
2019-02-25 08:56:40陳保家劉浩濤陳法法肖文榮趙春華
中國機械工程 2019年2期
陳保家 劉浩濤 徐 超 陳法法 肖文榮 趙春華
1.湖北省水電機械設備設計與維護重點實驗室(三峽大學),宜昌,4430022.湖北特種設備檢驗檢測研究院宜昌分院,宜昌,443002
0 引言
作為機械傳動系統的關鍵一環,齒輪傳動系統若發生故障,極易引發整個機械系統癱瘓,從而影響正常的生產活動。作為旋轉機械中最為常用的傳動形式,齒輪傳動系統也最容易發生故障和失效。由于需要診斷的裝備量大面廣、每臺裝備測點多、數據采樣頻率高、裝備服役時間長,故海量的診斷數據被獲取,從而推動故障診斷領域進入了“大數據”時代[1]。針對故障診斷大數據多樣性、非線性、高維性的特點,利用先進的理論方法,從大數據中挖掘信息,高效、準確地識別裝備健康狀況,成為機械裝備大數據健康監測面臨的新問題。2006年,Hinton等[2]首次探討了深度學習理論,開啟了深度學習在學術界和工業界的浪潮。自2011年以來,微軟研究院先后采用深度神經網絡,將語音識別的錯誤率降低了20%~30%,成為語音識別領域十多年來的突破性進展[3]。
2014年,Google通過建立更深層的模型,將Image Net 圖像識別準確率提高到93.3%[4]。2016年,Google 宣布Google Translate新模型上線,利用循環神經網絡,將翻譯結果與人類翻譯準確率的差距縮小了55%~85%,相比谷歌已經投入生產的基于短語的系統,翻譯誤差平均降低了60%[5]。顯然,深度學習已成為大數據分析的一種重要手段,研究并利用先進的深度學習理論,從機械故障大數據中高效、準確地挖掘故障信息,已成為當下機械智能故障診斷的一種主流趨勢。雷亞國等[6]分析了機械智能故障診斷大數據的特點,從信號獲取、特征提取、故障識別與預測3個環節,綜述了機械智能故障診斷的國內外研究進展和發展動態。FENG等[7]提出了一種深度歸一化卷積神經網絡(deep normalized convolutional neural network,DNCNN)框架,克服了卷積神經網絡健康狀況分配不平衡和特征提取模糊等問題。JING等[8]針對傳統特征提取方法存在的缺陷,提出了基于卷積神經網絡的故障診斷方法,并用實驗數據驗證其具有良好的診斷效果。朱喬木等[9]將深度學習方法引入電力系統暫態穩定評估,提出了一種深度置信網絡(deep belief network,DBNs)的暫態穩定評估方法。王麗華等[10]利用堆疊降噪自編碼方法提取信號特征,結合Softmax分類器,實現了高效準確的電機故障診斷。曹玉良等[11]利用基于自動編碼器構建的深度學習模型,對離心泵的4類空化狀態成功進行了分類識別。
深度學習理論較傳統診斷方法有以下優勢:①通過組合低層特征形成更加抽象的深層特征,能從大數據中自動提取特征,減少了對專業知識和先驗知識的依賴;②模擬大腦的深層組織結構,建立深層模型,高效表征信號與健康狀況之間復雜的映射關系。本文基于深度學習理論,提出了一種基于深度置信網絡的齒輪故障診斷方法。
1 基于深度置信網絡的故障診斷原理
深度置信網絡既可以用于非監督學習,類似于一個自編碼機;也可以用于監督學習,作為分類器來使用。非監督學習目的是盡可能地保留原始特征的特點,同時降低特征的維度。監督學習的目的在于使分類錯誤率盡可能地小。不論監督學習還是非監督學習,DBNs的本質都是 Feature Learning 的過程,即如何得到更好的特征表達。
1.1 DBNs網絡結構及訓練過程
DBNs網絡由多層限制玻爾茲曼機(restricted boltzmann machine,RBM)堆疊而成,圖 1為一個由3層RBM堆疊而成的DBNs,由于網絡分類輸出層不在RBM網絡之內,故將該DBNs網絡視為4層的DBNs網絡,網絡框架可簡易表示為N-n1-n2-n3,即數據輸入層點數為N,一、二、三層隱層神經元數目分別為n1、n2、n3。
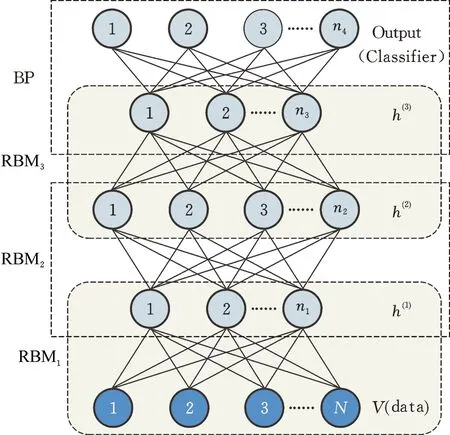
圖1 DBNs網絡結構Fig.1 DBNs network structure
在RBM中,任意兩個相連的神經元之間有一個權值w表示其連接強度,每個神經元自身有一個偏置b和c來表示其自身權重。則可用以下函數表示一個RBM的能量[12-13]:
(1)
式中,Wij為權值矩陣W的元素;n為可見層單元數;m為隱層單元數。
在RBM網絡的訓練過程中,會用到對數似然函數:
(2)
θ={W,a,b}
式中,W為權值矩陣;a為隱層偏置量;b為可見層偏量。
在RBM中,樣本真實的分布和RBM網絡表示的邊緣分布的KL距離就是兩者之間的差異性,樣本的真實分布與RBM網絡表示的邊緣分布的KL距離為
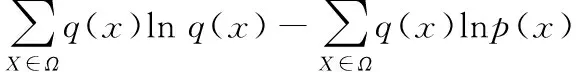
(3)
要使KL距離最小,就要求lnp(x)的值最大,即輸入樣本的最大似然估計最大:
(4)
根據計算結果,分別對w、b、c求導,有
(5)
(6)
(7)
DBNs提取故障特征的過程見圖2。
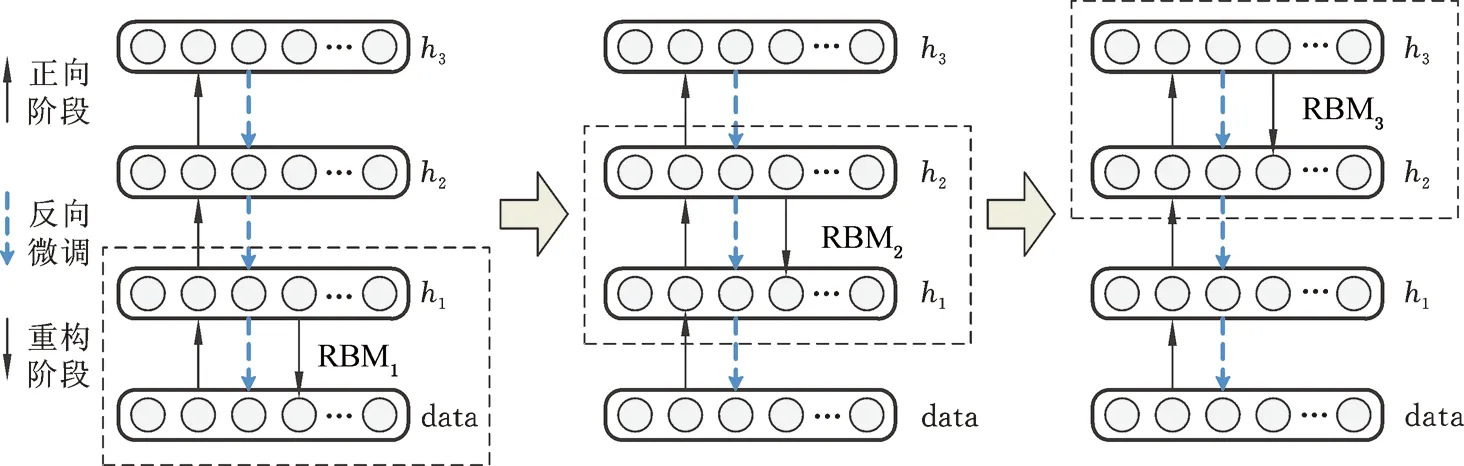
圖2 DBNs逐層特征提取過程Fig.2 DBNs layer-by-layer feature extraction process
1.2 DBNs故障診斷流程
利用DBNs對故障數據集進行特征提取的過程,實際上就是利用DBNs網絡對數據集進行無監督預訓練、得到高層特征的過程,在預訓練過程中沒有用到任何標簽信息。在多個RBM逐層訓練完成后,通過BP算法對整個網絡通過交叉熵共軛梯度下降算法進行微調,確定各層之間的權值和偏置量[14-15]。基于DBNs算法的整個故障診斷流程見圖3,其具體過程如下。
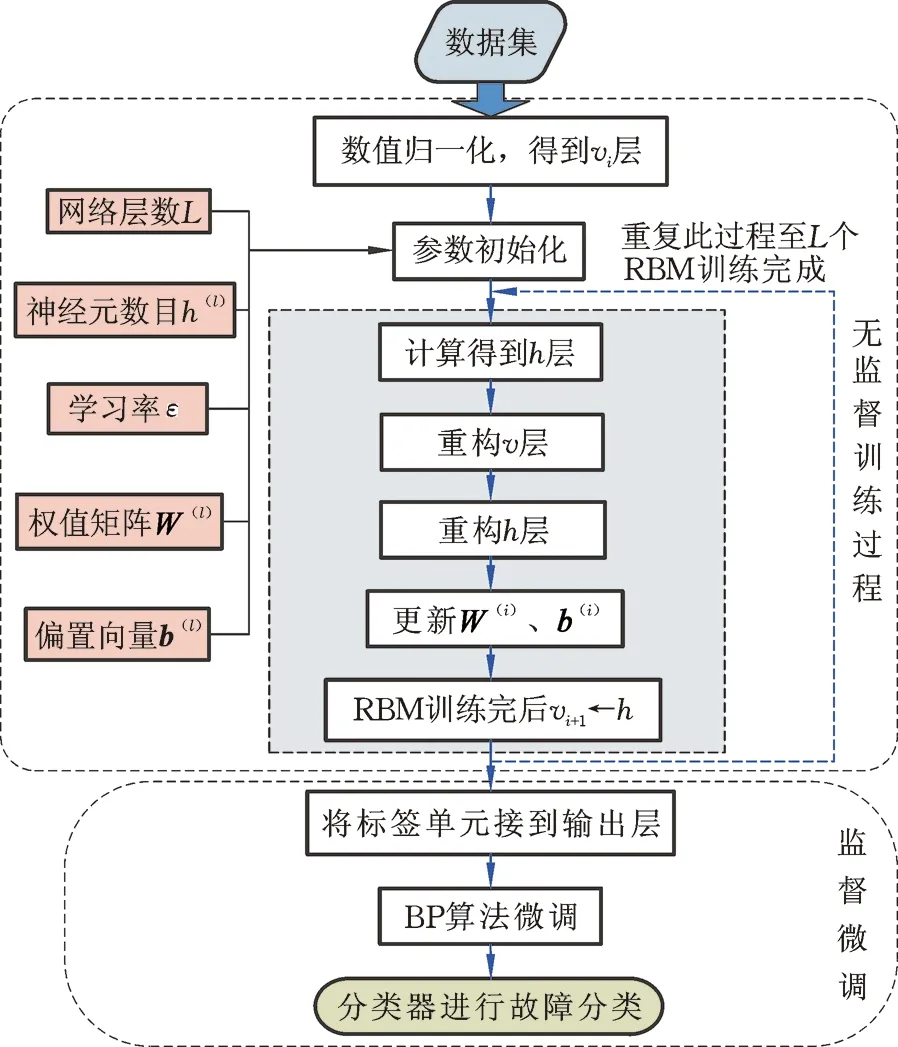
圖3 DBNs故障診斷模型Fig.3 DBNs fault diagnosis process
(1)收集故障數據,構建數據集,在DBNs預訓練之前對備用數據集進行歸一化處理,并將其賦值給DBNs網絡的v1層,即第一層顯層。
(2)初始化DBNs網絡參數,包括網絡層數L、各層網絡神經元數目h(l)、學習率ε、權值矩陣W(l)和偏置向量b(l)。
(3)利用v1層數據計算隱層中每個神經元被激活的概率,從被激活的概率分布中采用吉布斯采樣定理隨機抽取一個樣本,得到第一層RBM的隱層h1。
(4)利用h1層數據反推顯層,計算v1層中每個神經元被激活的概率,采用吉布斯采樣定理,從被激活的概率分布中隨機抽取一個樣本以重構RBM的顯層v1。
(5)利用v1層數據反推隱層,計算h1層中每個神經元被激活的概率,從被激活的概率分布中采用吉布斯采樣定理隨機抽取一個樣本以重構RBM的顯層h1。
(6)通過上述步驟,第一層RBM已經訓練完成,將第一層RBM的隱層h1作為第二層RBM的顯層v2,即v2←h1,然后重復步驟(3)~(5),直至所有RBM網絡預訓練完成。
(7)所有RBM網絡預訓練完成后,在最后一層RBM后面接入分類輸出層,然后利用BP算法進行反向微調,完成整個DBNs網絡的訓練。
(8)在整個DBNs網絡的訓練完成之后,輸入待診斷故障樣本,利用softmax分類器對輸入數據進行故障分類。
2 齒輪故障實驗及診斷實例
2.1 齒輪故障實驗過程
從基于DBNs的特征提取過程可以看出,DBNs網絡的第一層是數據層,所以構建合理的數據集對提高故障識別能力至關重要。本文中用于DBNs網絡的數據來源于實驗室齒輪模擬故障試驗臺,數據集分為訓練集和測試集。試驗平臺系統主要包括驅動電機、傳動軸、齒輪減速箱、加載系統、直流調速系統、傳感器、CA-1型電荷放大器、CDSP數據采集儀、若干信號傳輸線和用于實時監測的計算機組成,見圖4、圖5。測試信號為齒輪振動加速度信號,為有量綱數據,采樣頻率fs=10 kHz。
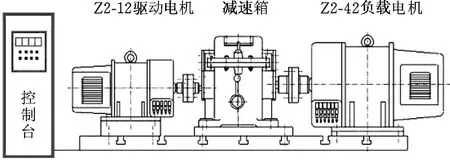
圖4 實驗系統簡易示意圖Fig.4 Simple schematic diagram of experimental system

圖5 加速度傳感器的布置Fig.5 Acceleration sensor distribution
齒輪箱是由三軸式二級變速器組成的,輸入軸與輸出軸上齒輪均為正常齒輪,中間軸上齒輪為二聯齒輪(大直齒輪,齒數為64,模數為2 mm)和三聯齒輪(小直齒輪,齒數為40,模數為2 mm),上面布置有各種齒輪故障,見圖6,故障的變換由齒輪箱前后兩個換擋手柄調節。
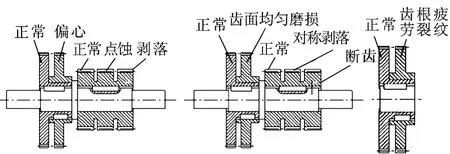
圖6 中間軸故障齒輪分布情況Fig.6 Intermediate shaft fault gear distribution
測試所得的齒輪振動信號共分為3種轉速nr(400 r/min、700 r/min、1 000 r/min)、7種狀態(剝落、點蝕、斷齒、裂紋、磨損、偏心、正常),其中,轉速為400 r/min的齒輪各狀態的時域、頻域信號見圖7。為了檢驗DBNs在不同數據條件下的診斷結果,構建后的數據集主要分為兩種,第一種為直接截取(截取點數為2048)原始時域信號構成的時域數據集;第二種則是將時域信號進行FFT變換后得到的頻譜(點數為1 024)構建而成頻譜數據集,其中,訓練集樣本數為6 000,測試集樣本數為1 000。將實驗數據集導入DBNs網絡之前,需對數據集進行整體歸一化處理。
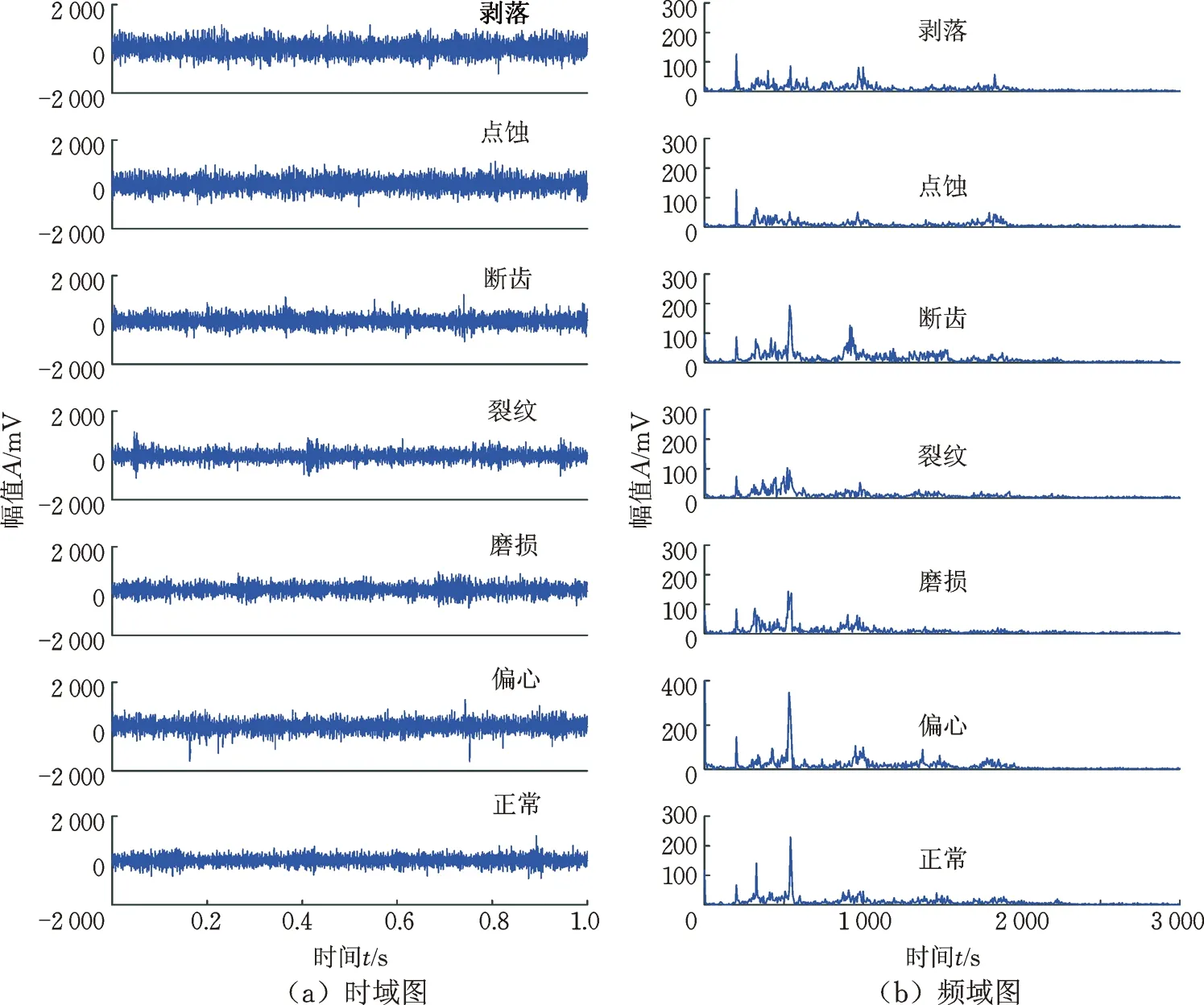
圖7 齒輪振動時域、頻域信號(nr=400 r/min)Fig.7 Gear vibration time domain signal(nr=400 r/min)
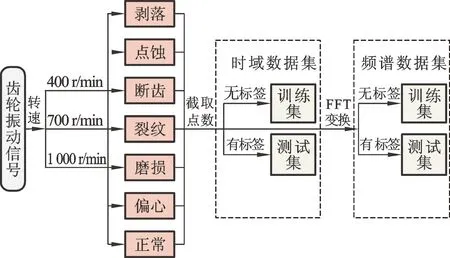
圖8 齒輪故障數據集構建過程Fig.8 Gear fault data set construction process
2.2 齒輪故障診斷實例
在構建DBNs網絡時,需要定義網絡的深度L(RBM層數),每層RBM的神經元數目n,學習率ε以及對應的權值W、b,除了權值會不斷更新外,其他參數都是固定不變的。因此,在構建DBNs網絡的過程中,需要選擇合適的網絡深度L、隱層神經元數目n和學習率ε,以盡可能提高故障識別正確率。設轉速為nr,采用單一變量法分別研究網絡框架參數L、n、ε對故障識別結果的影響(圖9~圖11),所用數據集為齒輪故障信號頻譜數據集。
從圖9中可明顯看出,當DBNs網絡層數為3(即隱層數為2)時,故障識別正確率最高,并且隨著網絡隱層數的增加,DBNs故障識別正確率整體呈下降趨勢。這是因為在理論上,只有當訓練數據集足夠大時,深度學習網絡的深度越大,故障識別的效果才會越好,而本文所用訓練數據集有限,當網絡層數為3時就完成數據的充分學習,當網絡層數繼續增加時,則會出現過擬合現象,導致故障識別正確率降低,另外,網絡的識別率不僅與網絡層數有關,而且與訓練算法、神經元個數、學習率等因素有關。為了研究隱層神經元數目對DBN故障識別正確率的影響,下文將分析當DBNs網絡層數為3時,隱層神經元數目對故障識別正確率的影響。將兩層隱層神經元數目設置成相等的數目,以便于分析。
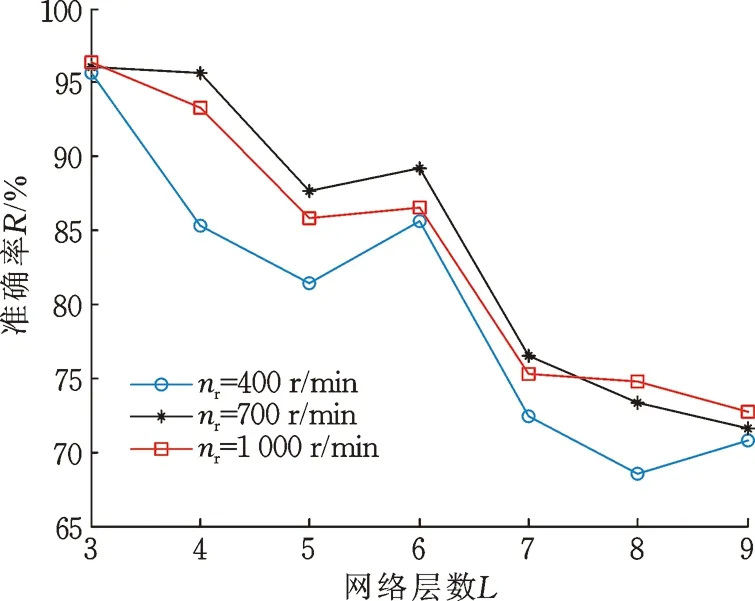
圖9 不同網絡層數對應的故障識別正確率(隱層神經元數目均為100)Fig.9 Corresponding fault identification accuracy of different network layers
從圖10中可以看出,當隱層神經元數目在50~300之間變化時,DBN故障識別正確率穩定在95%~98%之間,并且未出現明顯增大或減小的趨勢,可見隱層神經元數目對網絡故障識別正確率的影響很小。下面分析當DBN網絡層數為3、網絡框架為1024-100-100時,學習率對故障識別正確率的影響。
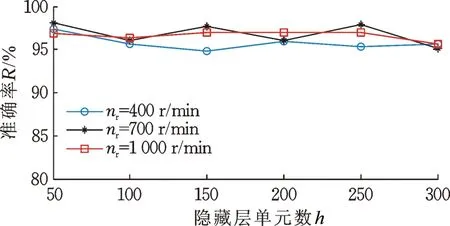
圖10 不同隱層神經元數目對應的故障識別正確率Fig.10 Corresponding fault identification accuracy of different hidden layer neurons
從圖11中可以看出,當學習率ε=0.2時,DBN網絡的故障識別正確率最高。雖然學習率在0.1~1之間變化時,DBN網絡故障識別正確率的變化很小,但隨著學習率的增加,DBN網絡故障識別正確率依然出現了緩慢下降的趨勢,由此可見,學習率的大小在一定程度上會影響DBN網絡的故障識別正確率。
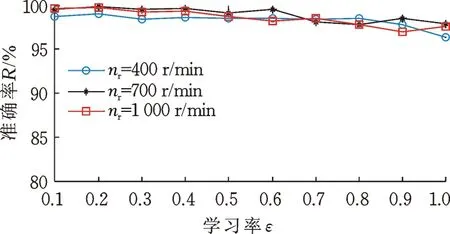
圖11 不同學習率對應的故障識別正確率Fig.11 Corresponding fault recognition accuracy rates for different learning rates
由圖9~圖11的分析結果,確定了適用于齒輪振動信號頻譜數據集的最優網絡層數為3,最優學習率ε=0.2。為了突出DBNs方法的優勢,用圖5中基于DBNs的故障診斷方法與其他模式識別方法進行對比。實驗所用數據為圖7中所創建的時域數據集和頻譜數據集,各種診斷模型對7種故障數據的判別結果見表1。
表1不同診斷模型的故障識別正確率
Tab.1Faultdiagnosisrateofdifferentdiagnosticmodels%
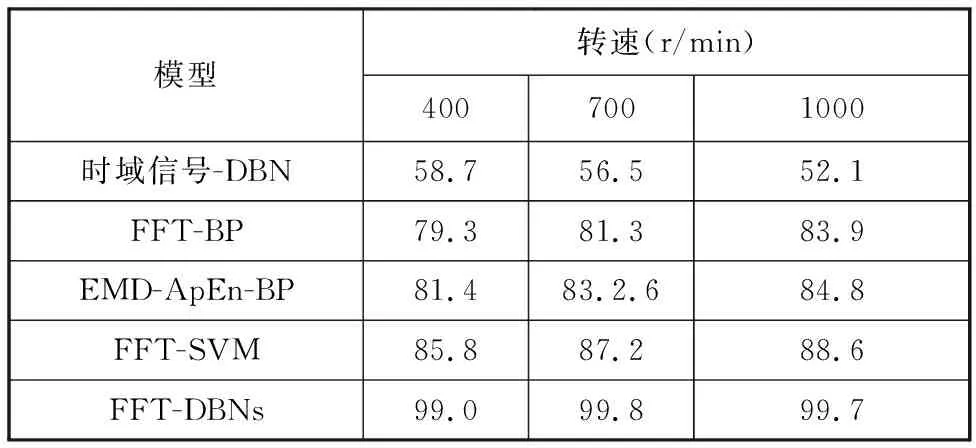
模型轉速(r/min)4007001000時域信號-DBN58.756.552.1FFT-BP79.381.383.9EMD-ApEn-BP81.483.2.684.8FFT-SVM85.887.288.6FFT-DBNs99.099.899.7
表1中的第一種方法為直接用本文所述的DBN故障診斷方法對齒輪的原始時域振動信號進行故障診斷,所用DBNs網絡框架為2048-100-100,學習率ε=0.2;第二種方法為先對振動信號進行FFT變換獲得信號頻譜,再利用BP網絡對信號頻譜進行故障分類。第三種方法為先對振動信號進行經驗模態分解(empirical mode decomposition,EMD),然后利用近似熵(approximate entropy,ApEn)求得分解分量(IMF)的熵值,最后結合BP分類器進行故障診斷。第四種方法為利用支持向量機(support vector machines,SVM)對信號頻譜進行故障識別,選用RBF核函數,交叉驗證數v=5。第五種方法為用DBN網絡對信號頻譜進行故障分類,所用DBNs網絡框架為1024-100-100,學習率ε=0.2。
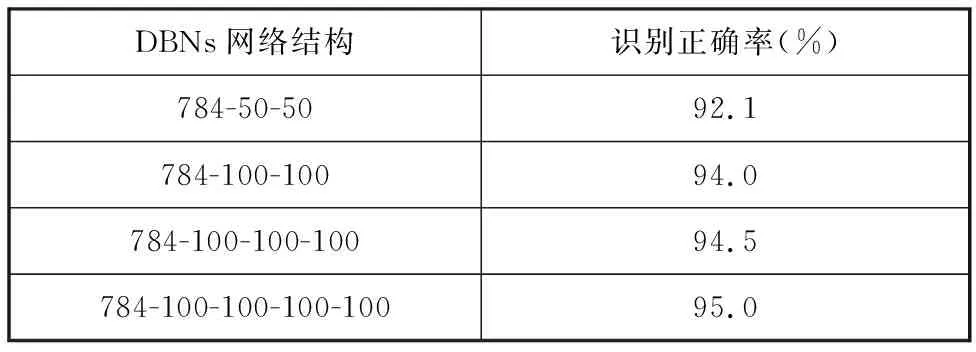
從表1中可知,當直接用DBN網絡對原始時域信號進行故障診斷時,故障識別的正確率明顯偏低,最高不超過60%,達不到故障診斷的要求;當對原始信號進行FFT變換,再進行DBN故障診斷后,故障判別效果有了質的提升,正確率最高達99.7%,并且故障識別能力明顯優于另三種機器學習方法,完全滿足齒輪故障診斷的需要。為了復現DBNs方法優異的模式識別能力,可使用通用的手寫數字標準數據集mnist_uint8進行驗證,學習率ε=0.5,迭代次數為100,結果見表2。
表2手寫數字識別結果
Tab.2Handwrittendigitrecognitionresult
DBNs網絡結構識別正確率(%)784-50-5092.1784-100-10094.0784-100-100-10094.5784-100-100-100-10095.0
3 結論
(1)網絡框架參數L、n、ε在一定程度上都會影響DBN網絡的故障識別率,其中,網絡深度L是最主要的影響因素。
(2)對齒輪原始時域故障信號進行簡單的前期處理(FFT變換)后再進行DBN故障診斷,會在很大程度上提高DBN網絡的故障識別正確率。
(3)在數據集有限的的情況下,需要選擇合適的網絡層數,否則當網絡層數超出一定值時,DBN網絡會出現過擬合現象。
(4)在相同數據集的情況下,DBN網絡的故障識別能力明顯優于BP網絡和SVM的故障識別能力。
(5)本文利用深度學習理論代替了傳統的故障診斷方法對齒輪故障進行識別,打破了傳統時、頻域特征提取的束縛,直接將原始時域振動信號或其頻譜作為DBNs網絡的顯層輸入,避免了傳統神經網絡故障診斷方法繁瑣的外部特征提取手段。由于DBNs網絡中對比散度算法的優越性,即使網絡輸入數據量過大,也不會使網絡訓練時間過長,從而大大節省了網絡運行時間。
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
汽車維修與保養(2019年7期)2020-01-06 03:30:42
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
汽車維護與修理(2016年10期)2016-07-10 08:17:41
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
汽車維修與保養(2015年6期)2015-04-17 03:31:50
汽車維護與修理(2015年2期)2015-02-28 12:15:39
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
