基于改進模板匹配與深度稀疏編碼網(wǎng)絡(luò)的文檔編號自動識別
2019-03-02 02:35:28段磊劉濤李偉鵬張寧咸日常鄒國鋒
現(xiàn)代計算機 2019年2期
關(guān)鍵詞:自動識別
段磊,劉濤,李偉鵬,張寧,咸日常,鄒國鋒
(1.國網(wǎng)山東省電力公司淄博供電公司,淄博 255000;2.山東理工大學電氣與電子工程學院,淄博 255049)
0 引言
隨著信息技術(shù)和網(wǎng)絡(luò)技術(shù)的不斷發(fā)展,電力部門涉密文件檔案的信息化建設(shè)和智能化管理在檔案事業(yè)發(fā)展中扮演著越來越重要的角色[1]。因涉密文檔材料的特殊性,在一定程度上影響了其數(shù)字化的進程,例如,目前實體涉密文件收發(fā)登記方式仍然需要通過人工錄入等手段,將相關(guān)信息在數(shù)據(jù)庫中進行歸集、匯總和索引,以便于信息的檢索和查詢。顯然,現(xiàn)有的涉密文檔收發(fā)文登記方式已不能夠滿足智能化管理的需要,因此亟需通過一套先進的管理系統(tǒng)對各類收發(fā)文件進行歸類登記和匯總,在減少人員投入的同時,確保重要文件數(shù)量及傳閱路徑的全過程管控,利用信息化手段提高工作效率。
在文檔資料管理過程中,通常需要為每一份文檔分配一組唯一的文檔編號,作為該文檔的識別碼,這不僅方便于文檔的分類存放,也便于文檔查詢。因此,在實體涉密文件的收發(fā)登記時,可以通過圖像采集的方式獲取文檔編號,然后基于文檔編號自動識別技術(shù)實現(xiàn)涉密文件的自動收發(fā)登記。因此,文檔編號的自動識別成為涉密文件收發(fā)信息準確登記的關(guān)鍵影響因素。按照書寫形式不同,電力部門文檔編號分為機打編號和手寫編號兩種,且文檔編號通常由省份簡稱、英文字母、數(shù)字、連接線混合編寫組成。正是由于文檔編號書寫形式不同和復雜的組編方式,導致文檔編號識別的準確度與實際需求產(chǎn)生較大差距。
秦守鵬[2]采用工業(yè)相機采集軌道噴繪區(qū)域圖像,經(jīng)過圖像預處理后獲取圖像目標區(qū)域,然后采用Tesseract-OCR技術(shù)實現(xiàn)軌道板編號識別。趙麗科等[3]提出基于BP神經(jīng)網(wǎng)絡(luò)實現(xiàn)田徑運動員號碼牌圖像的號碼識別。該算法采用可形變部件模型進行人體檢測,并基于先驗知識實現(xiàn)運動員號碼牌定位,然后通過字符分割和BP網(wǎng)絡(luò)識別了號碼牌識別。陳哲[4]通過閾值分割獲取印章編號區(qū)域,并進一步基于卷積神經(jīng)網(wǎng)絡(luò)的實現(xiàn)了印章編號識別。顯然,目前已有編號自動識別算法主要針對純數(shù)字序號或機打印書體編號,編號模式比較簡單,數(shù)據(jù)量較小。李少輝[5]采用改進的BP網(wǎng)路實現(xiàn)了低質(zhì)量文本識別,在含有噪聲和缺陷的低質(zhì)量文本圖片中保持了較高的識別準確率。陳英[6]等人采用了自適應(yīng)閾值分割和模板匹配算法實現(xiàn)了水表字符的識別。這些編號自動識別算法無法直接應(yīng)用于文檔編號的自動識別中,但為文檔編號的自動識別提供了可借鑒的思路。
鑒于山東省電力部門涉密文檔信息化建設(shè)的迫切需求,及其當前文檔編號自動識別技術(shù)的不足,本文提出融合特征匹配和稀疏編碼器的文檔編號自動識別方法。首先,通過圖像采集裝置掃描文檔編號,然后對文檔編號圖像進行預處理,主要實現(xiàn)圖像灰度化、二值化和字符分割。對于機打編號,本文提出結(jié)合歐拉數(shù)粗分類與特征匹配再識別的字符識別方法,在一定程度上克服了相似字符之間的干擾。對于手寫編號,本文提出一種自適應(yīng)稀疏編碼網(wǎng)絡(luò)進行編號識別,能夠有效地控制網(wǎng)絡(luò)規(guī)模,達到了較高的手寫編號識別精度。
1 文檔編號的預處理
圖像采集裝置捕獲的圖像為彩色圖像,需要經(jīng)過灰度化、二值化處理,并采用相應(yīng)的字符分割和歸一化算法獲得標準字符圖像。
1.1 字符圖像的灰度化與二值化
彩色圖像信息量豐富,但參與識別運算,計算量較大,而對于文檔編號的識別無需過多的顏色信息參與運算。因此為了減少運算量,采用加權(quán)平均法需將彩色圖像轉(zhuǎn)換為灰度圖像:
灰度化處理后,本文采用了基于閾值的二值化方法:

其中,閾值T的選取采用了基于OTSU的方法。經(jīng)過圖像分割后的結(jié)果如圖1。

圖1 二值化后的文檔編號
1.2 字符的分割
字符分割是文檔編號識別的重要環(huán)節(jié)。本文采用了投影法實現(xiàn)字符的分割,由于文檔編號通常只有一行,所以只采用垂直方向的投影即可實現(xiàn)字符之間的分割。垂直投影公式:
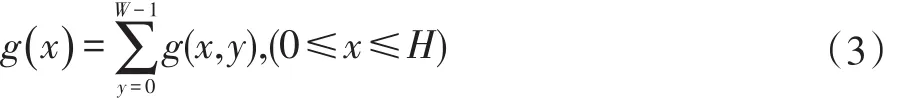
其中,W為圖像寬度,H為圖像高度。字符分割的部分結(jié)果如圖2所示。

圖2 文檔編號字符分割的部分結(jié)果
2 基于特征匹配的機打編號識別
由于機打編號字體格式統(tǒng)一,共包含1個“魯”字、26個大寫英文字母、26個小寫英文字母、10個數(shù)字和連接線“—”,即64種模式。模式簡單,數(shù)據(jù)量較少,適合采用特征匹配方式實現(xiàn)快速識別。
模板匹配[7]是經(jīng)典的圖像識別方法之一,其基本原理是從待識別圖像或圖像區(qū)域中提取若干特征量與已有模板相應(yīng)的特征量逐個進行比較,計算它們之間規(guī)格化的相關(guān)量,其中相關(guān)量最大的一個就表示其間相似程度最高,可將圖像歸于該類。模板匹配需要事先構(gòu)建樣本標準模板庫,標準樣本是經(jīng)過二值化處理的數(shù)字模板,且模板大小相同。而待識別字符匹配識別前,通常也需要標準化為模板樣本的大小。本文構(gòu)建的機打文檔編號模板庫如圖3所示。

圖3 部分機打文檔編號模板
目前,機打文檔編號字符匹配通常采用簡單模板匹配法。簡單模板匹配是將標準化后的待識別字符圖像與字符模板逐個匹配,求出其相似度。本文采用的模板匹配相似度計算公式如下:

其中,f表示二值模板圖像,g表示待識別的二值圖像,兩幅圖像的大小一致,均為M×N,Tf和Tg分別表示對應(yīng)于二值圖像中值為1的像素個數(shù),∧表示與運算。
簡單模板匹配能夠?qū)崿F(xiàn)基本的文檔編號識別功能,但是對于相似性較強的字符,也容易產(chǎn)生誤識,例如字符G和Q、C和O、B和8。為了克服誤識情況的發(fā)生,提高文檔編號識別準確度,本文提出通過計算字符圖像歐拉數(shù)進行前期粗分類,然后進行模板匹配識別的思路,對于未正確識別的字符,則采用人工更正方式保證錄入文檔收發(fā)系統(tǒng)的編號正確。
歐拉數(shù)[8]定義為E,它表示一幅圖像區(qū)域中的孔數(shù)H和連接部分數(shù)C的差,即:

其中,連接部分數(shù)C是指圖像中的有多少個單獨連接的部分,而其中的每一個部分都是連接在一塊的,例如字母A,連接數(shù)C為1,孔洞數(shù)H為1,則歐拉數(shù)為0。
3 基于稀疏自動編碼網(wǎng)絡(luò)的手寫編號識別
手寫編號因不同人的書寫習慣不同,即使相同編號,不同人書寫也可能會產(chǎn)生較大差異,給準確識別帶來困難。因此,針對不同的手寫體文檔編號需要構(gòu)建規(guī)模較大的手寫字符數(shù)據(jù)集,本文采用稀疏自動編碼器網(wǎng)絡(luò)進行訓練學習,獲得豐富的手寫編號特征,構(gòu)建魯棒性更強的分類模型,能有效提升手寫編號的識別準確度。
3.1 自動編碼器
深度網(wǎng)絡(luò)[9,10]是一種具有多層結(jié)構(gòu)的神經(jīng)網(wǎng)絡(luò),通過逐層的自動學習實現(xiàn)輸入數(shù)據(jù)的深層次特征表達和分類。自動編碼器[11](AutoEncoder,AE)是一種包含輸入層、隱層和輸出層的3層神經(jīng)網(wǎng)絡(luò),其中,隱含層實現(xiàn)了對數(shù)據(jù)的特征提取,輸出層則實現(xiàn)了對特征數(shù)據(jù)的重構(gòu)。自動編碼器的訓練目標是使網(wǎng)絡(luò)輸出與輸入數(shù)據(jù)的重構(gòu)誤差最小,其結(jié)構(gòu)框圖如圖4所示。

圖4自動編碼器原理結(jié)構(gòu)框圖
編碼過程如下式:

其中,sf表示隱含層激活函數(shù),通常為sigmoid函數(shù)sf(t)=1(1+exp(-t)),Wd×n是權(quán)重矩陣,p∈Rn×1表示輸入層神經(jīng)元偏執(zhí)向量,輸入向量為x∈Rn×1,編碼輸出為h∈Rd×1,h是輸入向量x的特征表達形式。
解碼過程如下式:

其中,sg表示輸出層激活函數(shù),W′是輸出層權(quán)重矩陣,其數(shù)值與權(quán)重矩陣 Wd×n的轉(zhuǎn)置相同,q∈Rd×1是隱層神經(jīng)元偏執(zhí)項,解碼結(jié)果 x′∈Rn×1作為重構(gòu)數(shù)據(jù)輸出。
自動編碼器權(quán)重矩陣和偏置向量參數(shù)為θ={W ,W′,p,q},基于重構(gòu)誤差最小的原則,實現(xiàn)網(wǎng)絡(luò)模型的訓練學習可實現(xiàn)參數(shù)的自動調(diào)整,重構(gòu)誤差定義如下:

其中,m為訓練樣本數(shù),xi為輸入,x′i為輸出,θ為全體參數(shù)集合。
3.2 稀疏自動編碼網(wǎng)絡(luò)
一般情況下,自動編碼器中隱層神經(jīng)元數(shù)量少于輸入層神經(jīng)元數(shù)量,但如果網(wǎng)絡(luò)結(jié)構(gòu)設(shè)計時,將隱層神經(jīng)元數(shù)量設(shè)置較多,甚至超過輸入層節(jié)點數(shù)量時,自動編碼器仍然能夠?qū)崿F(xiàn)輸入樣本的特征提取,但這樣的網(wǎng)絡(luò)結(jié)構(gòu)所得特征往往存在較多的冗余信息,且增加了參數(shù)數(shù)量,訓練復雜程度顯著增加。因此,研究者提出稀疏自動編碼器(Sparse AutoEncoder,SAE),通過加入稀疏性限制對隱層進行約束,使其變得稀疏。
自動編碼器中添加的稀疏性限制使用的KL散度為:


稀疏自動編碼器的總重構(gòu)誤差如下:

其中,β是控制稀疏限制的權(quán)重因子。
本文采用的深度稀疏自動編碼器由多層稀疏自動編碼器級聯(lián)而成,如圖5所示,前一級網(wǎng)絡(luò)隱層輸出作為后一級網(wǎng)絡(luò)的輸入,并通過貪婪訓練方法逐層訓練每一級稀疏自動編碼器,最終整完成個網(wǎng)絡(luò)的訓練。

圖5 深度稀疏自動編碼器結(jié)構(gòu)圖
4 實驗與分析
為了驗證本文所提文檔編號自動識別算法的有效性,實驗采用MATLAB R2014a軟件實現(xiàn),實驗分為機打編號自動識別和手寫編號自動識別。
4.1 機打編號識別實驗
本文實驗中采用了50組機打檔案編號作為測試樣本,檔案編號長度不少于6個字符。機打字符模板構(gòu)建已在第2節(jié)中介紹,本文構(gòu)建的標準模板樣本共63個模式,分別為26個大寫英文字母、26個小寫英文字母、10個數(shù)字、1個連接線字符。由于機打編號格式較為規(guī)范,所以前期的圖像預處理工作較少,字符分割過程中,本文利用圖像灰度值垂直投影形成的空白間隙將單個字符分割出來,然后將分割得到的字符進行標準化處理,進一步用于計算歐拉數(shù)和模板匹配。
為了說明本文所采用的基于歐拉數(shù)的前期粗分類和模板匹配相結(jié)合的識別方法的有效性,實驗中與經(jīng)典的模板匹配方法進行了實驗對比,實驗結(jié)果如表1所示。

表1 機打編號自動識別實驗數(shù)據(jù)
實驗數(shù)據(jù)表明了本文所提方法的有效性,經(jīng)過基于歐拉數(shù)的前期粗分類,不僅有效避免了不同字符之間的干擾作用,提升了識別準確率,而且縮小了模板匹配過程中的搜索范圍,有效縮短了模板匹配時間,平均識別時間得到大幅降低。
4.2 手寫編號識別實驗
手寫編號識別實驗中采用了50組隨機手寫的檔案編號作為測試樣本,檔案編號長度不少于6個字符。稀疏自動編碼器訓練過程中,采用了3900幅大寫手寫英文字母圖像、3900幅小寫英文字母圖像、5000幅手寫數(shù)字和連接線圖像用于網(wǎng)絡(luò)訓練,由于“魯”字字符的唯一性,所以無需參與網(wǎng)路訓練。另外,由于手寫編號差異較大,容易存在多種干擾因素,例如墨跡污染、字體傾斜等。因此,在使用測試樣本進行識別前,需要對測試樣本圖像進行必要的圖像去噪增強預處理,并對傾斜角度較大的字體進行校正,經(jīng)過字符分割后將所有手寫字符大小歸一化為20×25像素,用做網(wǎng)絡(luò)輸入。網(wǎng)絡(luò)初始參數(shù)如表2所示。

表2 聚合網(wǎng)絡(luò)初始參數(shù)設(shè)置
在初始網(wǎng)絡(luò)參數(shù)設(shè)置下,手寫檔案編號的識別準確度僅能達到28%,誤差巨大,因此需對網(wǎng)絡(luò)參數(shù)進行調(diào)試。本文實驗中分別對表2中的參數(shù)進行了優(yōu)化和調(diào)整,確定的網(wǎng)絡(luò)最優(yōu)參數(shù)如表3所示。

表3 最優(yōu)網(wǎng)絡(luò)參數(shù)配置
經(jīng)過網(wǎng)絡(luò)參數(shù)的逐步調(diào)整,基于稀疏自動編碼器的手寫檔案號識別性能得到大幅提升,在50組隨機手寫的測試檔案號中識別率達到98%。
5 結(jié)語
本文針對當前涉密文檔信息化建設(shè)中的文檔編號自動識別方法開展研究,通過提出融合歐拉數(shù)和模板匹配的機打編號自動識別算法,有效改善了傳統(tǒng)模板匹配算法在相似字符識別中錯誤率較高的不足,而且較大幅度的提升了自動識別的速率。另外,針對不同人手寫編號差距較大,難以采用傳統(tǒng)識別方法實現(xiàn)編號識別的困難,本文構(gòu)建了大規(guī)模數(shù)據(jù)集,訓練了深度稀疏自動編碼器網(wǎng)絡(luò)模型,實現(xiàn)了手寫編號的高準確度自動識別。本文研究的文檔編號自動識別理論,可以在多種場合的編號識別中進行應(yīng)用。如何將機打編號和手寫編號識別方法進行融合,形成統(tǒng)一的識別理論是我們未來的研究工作。
猜你喜歡
中國自動識別技術(shù)(2023年6期)2024-01-12 08:13:22
艦船科學技術(shù)(2022年22期)2022-12-13 03:39:42
艦船科學技術(shù)(2022年10期)2022-06-17 06:27:48
空間科學學報(2020年3期)2020-07-24 09:23:02
中國交通信息化(2019年7期)2019-10-08 09:04:40
水上消防(2019年3期)2019-08-20 05:46:08
西南交通大學學報(2018年6期)2018-12-18 02:23:20
特別健康(2018年3期)2018-07-04 00:40:18
發(fā)明與創(chuàng)新(2016年26期)2016-08-22 03:23:28
電測與儀表(2016年6期)2016-04-11 12:06:38
