基于稀疏編碼的異常檢測
2019-03-04 08:30:52袁玲
現代計算機 2019年1期
袁玲
(四川大學計算機學院,成都610065)
0 引言
近年來,隨著人口的持續增長及城市化進程的不斷加快,人群活動變得日益頻繁,在交通路口、機場、火車站、旅游景區等人群密集的公共場所發生重大異常事件的現象屢見不鮮。因此,在智能視頻監控中對大規模人群的異常檢測則顯得尤為重要。異常檢測早期研究方案集中在建立目標軌跡模型,這種方法大體思想是一個目標的軌跡如果偏離正常模型訓練出來的軌跡,則該目標被標記為異常。然而,這些基于追蹤的方法有其缺點:①對于遮擋場景下,是不穩定的;②在擁擠場景中,這些方法的計算復雜。
為了解決這些困難,有學者提出了一些基于時空低級視覺特征的方法,例如光流和梯度特征,然后使用這些特征訓練出相應的模型,在這些模型下,出現的可能性小于一定閾值的則為異常[1]。使用人群正常的視頻訓練出隱馬爾科夫模型(HMM),可以解決由于異常訓練數據的稀缺性以及難于預先定義異常事件帶來的問題。
考慮到人群本身的行為,社會力模型被Mehran 等人[2]引進,首先,該模型提出人的實際行為是受自身的期望以及周圍人的排斥力影響的理論,然后使用排斥力訓練出LDA 模型,最后,實驗證明該模型在人群異常檢測中是一個有效的運動模型。以上模型強調了時間上運動的變化,但是忽略了人群的外觀變化,因此Mahadevan 等人使用了混合動態紋理模型(MDT)[3-4]來檢測異常,該模型把異常分為時間上的異常和空間上的異常,時間上的異常被認為是出現可能性低的行為,而空間上的異常是視頻中與周圍場景相比,具有顯著性特征的行為。
最近,基于稀疏編碼的研究受到了很多關注,其中,基于稀疏編碼的異常事件檢測也取得不錯的效果。文獻[5-6]提出了動態稀疏表示的方法;Yang Cong等人[7]在此基礎上制定了基于稀疏編碼檢異常檢測的標準,該標準稱為稀疏重構代價(SRC)。但是在實際應用中,訓練樣本的有限性會導致在新場景的視頻中,異常檢測結果出現偏差,因此,在線學習和更新稀疏編碼字典的方法[8-9]被提出。盡管以上大多數基于稀疏編碼的方法在檢測效果上表現良好,但是實時性有待提高。
本文在原有稀疏編碼的思想上,提出一種新的有效的稀疏表示方法,該方法在檢測速度上,具有不錯的效率,同時檢測率也能得到保證。
1 稀疏編碼
1.1 定義
對于訓練模型,一個高維的特征顯然能更好地描述事件,但是隨著特征的維數增加,需要的訓練數據呈現指數增長,在現實生活中,收集的訓練數據是很難滿足要求的。例如,在全局的異常檢測中,要訓練出一個較好的高斯模型,但是只有400 個訓練樣本的情況下,這是比較困難的。但是稀疏表示卻適合代表具有高維特征的樣本。稀疏編碼,是通過正常樣本訓練出一個字典,該字典的線性組合可以訓練樣本。這個字典用D∈Rp×q來表示。對于一個測試樣本X,我們可以通過以下公式來表示:
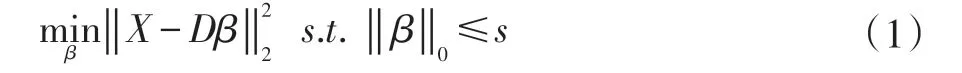
其中β∈Rp×1是稀疏系數,而是數據擬合項,‖ β‖0是稀疏重構項,而s 是(<<q)是稀疏數量控制參數。給定訓練樣本[x1,...,xn],我們可以通過公式(1)去訓練字典D。
1.2 異常檢測
使用公式(1)訓練出的字典D,引用文獻[7]中定義的稀疏重構代價來檢測異常。通常情況下,對于正常的事件應該是以很小的代價且以很少的基礎向量(字典中的列向量)構建,也就是β為0 的個數比較少,而異常事件要么不能以很小的代價構建出,要么即使能以很小的代價構建出,也需要大量的基礎向量。前人的研究驗證了這個方法可以達到較高的檢測率。
1.3 傳統稀疏編碼的效率問題
顯然,在公式(1)中的字典具有高度冗余,因此在異常檢測階段中存在效率問題,因為在這個階段中,需要在q 個基礎向量中找到不大于s 個基礎向量,而s 是遠遠小于q 的(q 足夠大是為了能夠表示更多的訓練樣本),那么這個過程是比較耗時的,因此研究怎樣減小q是很必要的,本文就是針對這個問題進行優化。
2 本文算法
針對1.3 小節提出的問題,本文提出了一種新的字典學習方法。對于字典D,我們用n 個子字典構成,其中每一個字典由一些基礎向量構成,并且使該子字典盡可能多的表示訓練樣本,在測試階段,只需要在這些子字典中找到一個合適的子字典來表示樣本。通過這樣的優化,q 的數量大大減少,而針對找到的子字典,只需要通過最小平方誤差找到合適的向量組合就能表示樣本。本文框架如圖1 所示。接下來,將詳細介紹本文的方法。
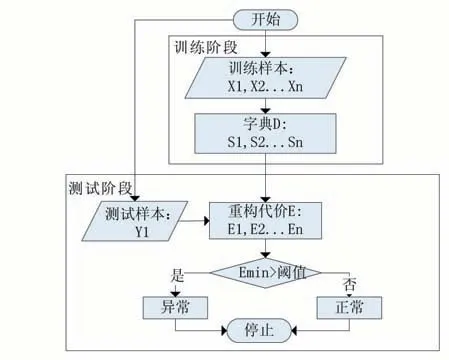
圖1 本文框架流程圖
2.1 字典的學習
對于字典的學習,我們首先得提取訓練樣本的特征數據,用以表示該樣本。本文主要提取視頻中的3D梯度特征,如文獻[10]中定義的那樣,該特征能較好地表示局部特征,因此使用該特征不但能檢測出某一幀出現異常,且能更好的定位該異常。同時,我們將每一幀視頻劃分成10×10 圖像塊,然后在時間序列上每5幀組成一個10×10×5 的立方體,每一個立方體表示一個事件。
對于每一個立方體,我們提取其3D 梯度特征,然后組成訓練樣本數據X={x1,...,xn}∈Rp×n,我們的目標是找到一個基礎字典組合S={S1,...,SK},其中每一個Si∈Rp×s。這個學習過程可以由公式(2)給出:
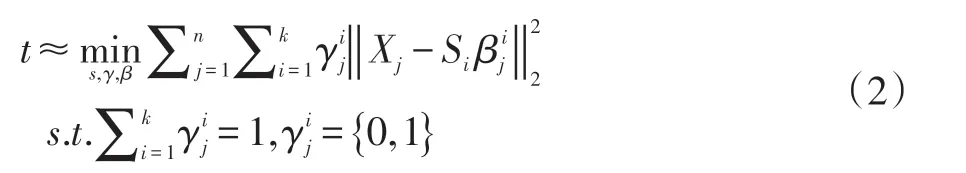
其中γ={γ1,...,γn},對于每一個γj∈K,用來指示Si集合是不是能被選擇用來表示X 的第j 個數據。而用來表明是對于子字典Si構成Xj的系數。由上面的公式可以看出,Xj至少在S 中能有一個基礎子字典能以很小的代價e 組成。很顯然,選擇合適的K 是很重要的,太小則不足夠表示所有的訓練樣本,而太大則可能導致所有樣本的重構代價幾乎趨近于0,即使是異常樣本。因此,對于K,不是固定,而是采取自適應學習的方法,也即是迭代,對于e 設置一個下限λ,當訓練樣本的所有的重構代價都達到了這個下限,此時的迭代次數K 就是最合適的。因此公式(2)可以變成為:
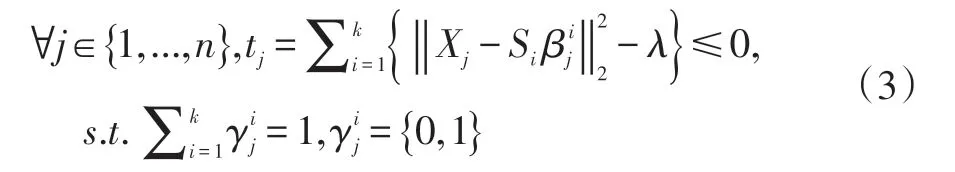
更新{Si,β,γ},對于公式(3),學習過程中要學習的參數有Si,β,γ。本文把這個學習過程分成兩步,首先保持γ不變,更新{Si,β},然后利用已經學習好的{Si,β},更新γ。
第一步,給定該γ,此時可以把公式(3)變為:
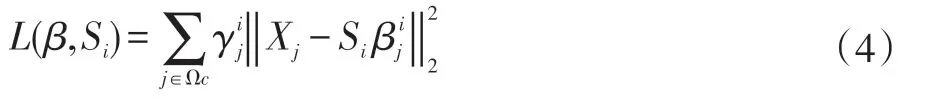
其中j∈Ωc,表示剩下的不能由S 表示的X 集合。上面這個公式可以看成求函數的最小值。對于公式(4)也將分成兩步,一是保持Si不變,其中γj不等于0,求取

更新Si,這里采用塊梯度下降方法,每一次用公式(6)更新Si,直到收斂。

更新γ,使用公式(5)、(6)得到的{Si,β},對于每一Xj,公式(3)可以轉化為公式(7):
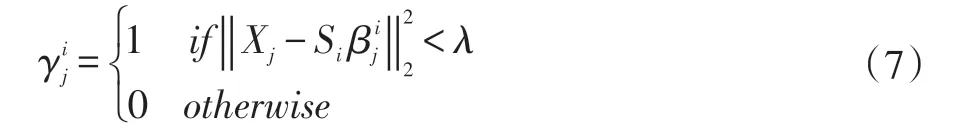
使用上文描述的字典學習過程,就可以得到一個合適的字典D,該字典能很好地描述訓練樣本,算法過程如下所示:
算法1:訓練字典
輸入:X,Xc=X
重復
重復
利用公式(5),(6)更新{Si,β}
利用(7)更新γ
直到(4)收斂
把Si加入到集合S
去除已經滿足條件(γj=0)的Xj
i=i+1;
2.2 測試
對于已經學習好的字典組合S={S1,...,SK},就可以在測試階段尋找是否存在一個Si,滿足重構代價小于閾值,可以使用(8)式得到合適的Si。

顯然這是一個二次函數,可以優化成公式(9):

然后,重構代價就可表示為:

測試算法流程如下:
算法2:測試
輸入:X,{R1,...,RK},閾值T
for j=1 →K
輸出正常
else
輸出異常
end
3 實驗
本文實驗環境為MATLAB 2015,Windows 10,在UCSD 數據集上進行實驗。對于給定的視頻將大小重新定義成為120×160,并把視頻分成10×10×5 的立方體。
3.1 UCSD數據集
USCD 數據集主要有分為兩個子集(UCSDped1,UCSDped2),每一個子集里面都有訓練數據和測試數據,而且測試數據里面含有像素級別的異常標記掩模。其中UCSDped1 訓練數據含有34 個視頻,每一個視頻有200 幀,測試數據有36 個視頻,10 個帶有異常標記的視頻,而UCSDped2 訓練數據有10 個視頻,測試數據16 個,每一個測試數據都含帶有標記的掩模,且視頻幀數為120 幀。本文把兩個子集的訓練數據都當成訓練樣本,只使用帶有人工標記異常幀的視頻進行測試。因此,本文獲得的訓練數據集(3D 梯度特征)總共有307200 個10×10×5 維的特征。
3.2 實驗結果以及分析
下圖展示了在UCSDped1 中測試數據中的第三個視頻中的第142 幀的數據。

圖2 異常行為

圖3 圖3的真實異常標記的位置

圖4 本文計算出來的異常位置
圖2 用紅色矩形框標記的為異常行為(在人行道上騎車),圖3 是人工標記的異常位置,圖4 是本文算法檢測出的異常行為位置,從圖2-圖4 可以看出,本文異常定位的結果比較準確。
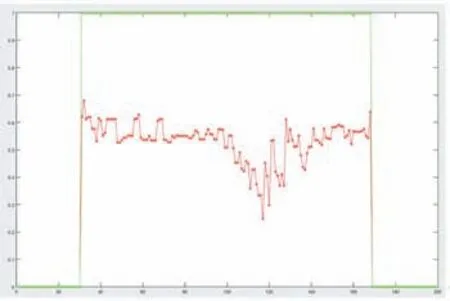
圖5
圖5 綠色代表測試數據中真實的正常和異常情況,正常為0,異常為1,紅色代表該異常的代價(對于小于一定閾值的值,本文直接計算為0)。
圖5 是圖2 所在幀的整個視頻的重構代價函數變化,橫軸表示視頻幀數,縱軸表示每一幀的重構代價,當閾值取0.25 的時候,能把含有異常行為的幀檢測出來。從圖2-圖5 可以分析出,本文算法對于異常檢測與異常定位的方法是有效的。并且經過實驗,本文異常檢測的準確率可以達到94.4%,準確率的計算是是根據本文計算出來的掩模(圖4)的面積與真實數據的掩模的面積(圖3)的比值是否大于0.4 得到的。如果比值大于0.4,則判定該幀異常定位結果正確,最后將所有測試視頻計算出來的平均值作為準確率。除此之外,本文也采取了ROC 曲線對實驗結果進行分析,同時也與其他研究中的實驗結果進行了對比。如圖6所示:
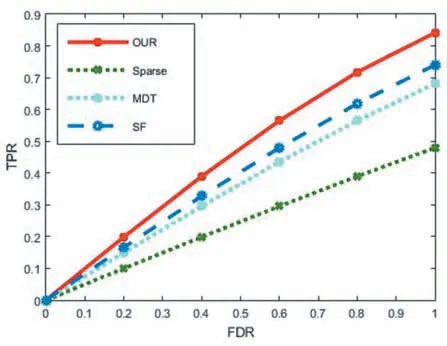
圖6 ROC曲線,橫軸為誤檢,縱軸為檢測正確
從圖6 可以看出,本文算法在被檢測為異常行為,而實際為正常行為的概率(FPR)較低的情況下,檢測率(TPR)也較高。并且也與其他算法相比,AUC(Area Under Curve)也能達到不錯的效果。最后本文在時間上也與其他算法進行了對比,本文測試階段主要有兩個過程耗時較長:一是特征提取,二是使用算法2 進行異常檢測。從表1 可以看出,本文的方法在時間上能提升不少,因此本文算法在提升時間效率方面有顯著效果。
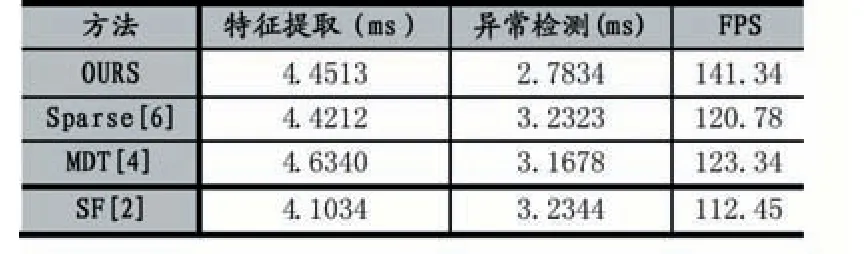
表1 幾種方法的時間比較
4 結語
本文提出了一個基于稀疏子字典組合學習的異常檢測方法,對于字典D,我們用n 個子字典構成,其中每一個字典由一些基礎向量構成,并且使該子字典能盡可能多的表示訓練樣本。最后在UCSD 數據集上對檢測結果和時間性能進行了驗證,該方法能通過減少傳統稀疏編碼的搜索維數,在不影響檢測結果的情況下,有效地提升檢測的速度,并且當使用MATLAB 在普通臺式PC 上進行計算時,本文的方法也能達到高檢測率以及高速率。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
海峽科技與產業(2016年3期)2016-05-17 04:32:12
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
