基于語義信息提取的卡通非真實感渲染
2019-03-04 10:56:58張誠
現代計算機 2019年36期
關鍵詞:語義
張誠
(四川大學計算機學院,成都610065)
0 引言
和追求照片級效果的真實感渲染相比,非真實感渲染(Non-Photorealistic Rendering,NPR)為使用計算機圖形學來模擬繪畫的藝術風格的渲染算法的總稱。隨著目前電影電視以及游戲的普及帶來的需求提高,以及計算機硬件的發展,NPR 成為了一個熱門的研究對象。本文主要著眼于一種廣泛使用的所謂賽璐璐風格的卡通風格,其藝術風格可以描述為由大色塊構成的前景,層次清晰的陰影,固定的背景等。由于該風格在動畫中應用廣泛,使用CG 技術模擬賽璐璐風格的嘗試在業界已有不少嘗試。早在90 年代,就已經有小部分的動畫嘗試將部分鏡頭使用3D 渲染了,而近年甚至存在專門的從事此類工作的動畫公司。

圖1 手繪圖片與同風格的卡通渲染CG的對比
然而包括卡通渲染在內的大部分NPR 技術,其本質都是使用一套固定的算法的處理三維模型,而目標卻是對某種手繪藝術風格的模擬[1]。換句話說,作為一種3D 渲染算法其最終目標卻是消除其3D 感,此外不同藝術家的風格也有微妙的不同。為此許多情況下,在渲染算法已經確定的情況下NPR 的算法經常需要或經過參數調整才能達到希望的效果。這里存在兩個主要的不足:過于忠實于物理的光照模型導致渲染出的結果過于呆板,缺少個人風格,自由度過低;對現有二維卡通風格的基于NPR 的模擬需要基于個別案例的具體分析,為得到較為接近的效果需要多次手動重復調整-檢查的過程。
本文針對性地解決了上述問題。首先,本文提出了一套算法,通過分析現存的手繪卡通圖片樣本提取出配色,陰影風格等與其藝術風格相關的語義信息,并討論了一套緊湊而適合GPU 渲染的方式保存。其次利用提取出的語義信息,本文提出了一套改進的賽璐璐風格渲染算法,和現存算法最大相比區別在于增加了數個隨局部三維場景等改變的參數,大幅增加了可調整的參數數目,從而可以適應多樣的風格。通過自動從現存的卡通圖像中提取這些參數,不僅能減少工作量,還保證在各個視角以及不同光照下都能達到比較一致的渲染效果。
1 相關工作
圖片的語義信息理解與提取是計算機視覺(CV)的一個主要課題,且長年間都有成熟的算法。隨著近年深度學習特別是卷積神經網絡的普及與發展,各大傳統的CV 課題都迎來了新的進步。計算機視覺領域,找出圖片前景的任務被稱為saliency mapping,但對應算法大多機械地根據顏色特征進行判斷,導致對于充滿飽和顏色的卡通圖片效果不佳。2018 年,Google 開發的基于深度學習的語義分割庫DeepLab V3[2],根據其論文也可以應用于前景分割,且最近有了應用其對卡通場景進行前景分割的實例。2002 年,SF Johnston 發表了第一種實用的通過手繪線稿生成法線圖的算法:通過在線稿筆畫處設定邊界條件,Lumo 使用對畫面插值的方法實現了法線圖的生成[3]。2018 年發表的Deep-Normal 則使用大量生成的樣本訓練CNN 的方式實現了同樣的功能[4]。Anjyo K I 等人分析了不規則的高光對非真實感渲染藝術風格的影響,通過更改Blinn 公式實現了卡通風格的高光[5]。
2 語義信息提取與擬合
2.1 流程

圖2 本文的流程圖
為了實現以特定手繪卡通圖片為基準藝術風格的非真實感實時渲染的目標,整個本文大致分為兩部分:第一部分,從圖片中提取高層次的信息。本文首先通過計算機視覺和機器學習的方式獲取以下信息:前景、線稿、風格分析用的配色表、法線圖,最后由法線圖與配色信息推導出這張圖片最可信的光照方向。這些統稱為原圖片的語義信息。其中線稿圖由指定顏色通過閾值處理得到,前景提取使用了未經修改的DeepLab v3 神經網絡,法線的生成結合使用了DeepNormal 與Lumo 的方法,下文不再贅述。第二部分,說明現在常用的卡通渲染算法的不足并做修改以便表達更廣范圍的藝術風格,使用第一部分提取出的語義信息,結合源圖片的場景上下文,轉換為適合上述渲染算法使用的參數:漫反射參數與各向異性高光參數。轉換的過程中還討論了不同數據表達方式對效果的影響。
2.2 語義信息提取

圖3 輸入圖像

圖4 配色分析得到的色塊位置
前景由有限的少數幾種顏色構成是卡通風格的一個特點。然而由于掃描,圖片壓縮或后處理等因素,對同一色塊其RGB 值不一定完全一致。因此,需要一種提取出圖像中獨立色塊方法。此外,我們期望在顏色劃分的時候意識到主顏色與陰影色的關系,因為在美術上兩者被認為是表示立體關系的一對或配色,且其關系對之后的光照分析有重要作用。
將圖像轉換為HSV 表示后,我們期望擁有一類配色的像素的色相值會趨于相同。利用這個特性,我們以圖像上像素的色相值作為樣本x1, x2,…, xn使用核密度估計(Kernel Density Estimation,KDE)來尋找H 值聚集的中心,其估計函數為:
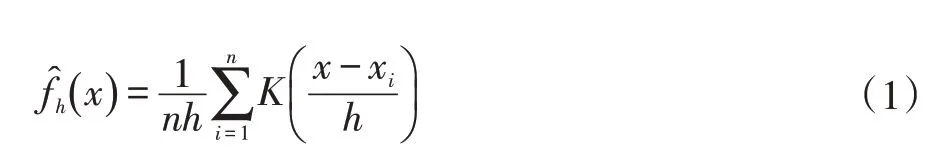
K 是任意的核函數,一般使用正態分布,h 控制核函數的寬度。但要注意色相是一個定義在圓周上的量,即最大值與最小值是連續的,因而預測時使用了定義在圓周上的von Mises 分布作為核函數進行圓周核密度估計運算。核密度估計的圓周版本有相同的表達式。von Mises 分布函數在其定義域0 到2π 中,首尾連續,且積分為1,適合此類問題的要求。直觀上可以看出對應配色的H 值位于估計函數的極大值處。在以量化誤差小于指定閾值的條件下,取盡可能少的估計函數最大的前數個H 值作為結果。
作為一個優化,觀察注意到KDE 法本質上與一個所有樣本點為中心的沖激函數之和的函數與給定核函數的卷積成正比,因而圓周上的KDE 可以看作為循環卷積,能夠等效地由兩信號的DFT(離散傅里葉變換)的乘積計算得到。在信號采樣率,即圓周0 到2π 上單位長度能表示的色相數為M 的情況下,前者的時間復雜度為O(M2),后者在對DFT 運算充分優化的情況下為O(M log M),即FFT 的時間復雜度。
每一個相似的色相同時包含了亮部與暗部,需要進行主顏色和陰影色的分離。找到一個合適的明度的閾值將對應顏色數據分為兩部分,使得兩部分的方差和最小。這也是K-means 算法的定義。最常用的隨機迭代的K-means 算法實現主要應用于高維數據,對一維數據較難收斂。對于一維的K-means 的特殊情況,有基于動態規劃的最優化算法,時間復雜度為O(N)[6]。

圖5
從左至右:記錄源圖像暗部的蒙版;記錄亮部的蒙版;生成的法線圖;猜測得到的光照。法線圖通過將三維法線向量的分量使用RGB 三個通道的強度進行存儲。
在得到圖片的主顏色與陰影色及其在圖片上的位置之后,要據此結合法線圖猜測圖片所表示場景的最合理的光照配置。我們暫時只研究受一個平行光的場景,例如典型的戶外只受太陽光的情況。設平行光方向為,圖片上x→點的法線為,光線與法線的夾角與正相關。一個合理的光照方向應盡可能直射亮表面,使得圖片的亮表面的光照夾角盡量小,而暗表面的光照夾角盡量大,即:

其中L 與D 分別表示法線圖所表示的三維場景中亮表面與暗表面的點集。為了將這個積分轉換為離散的圖像運算,需要注意到一個事實:圖像上每個像素所對應的三維場景模型的表面積與法線與視角向量夾角的余弦成反比。設是視角方向,前景有N 個像素,對于第i 個像素設L 與D 在圖像上對應位置像素下標的集合分別為L'與D',則(2)式可以離散化并求值得到:
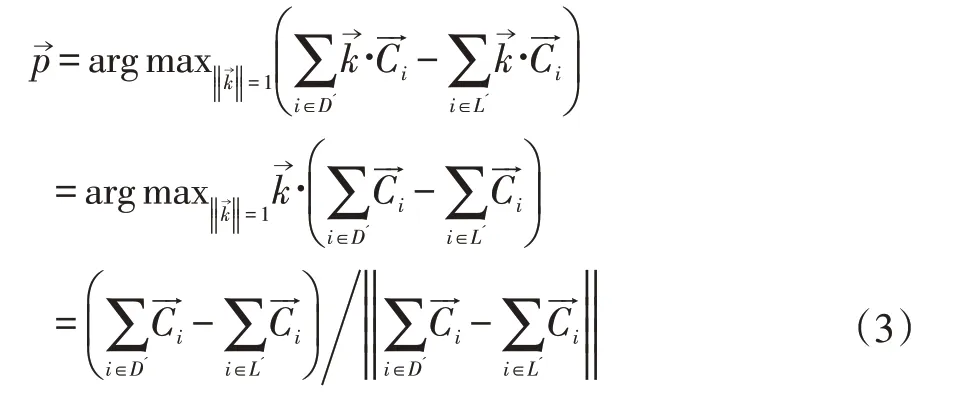
2.3 光照模型與擬合

圖6 直接采樣得到的閾值函數與濾波后結果的比較
大多數NPR 模型的光照模型都可以分為散射(Diffuse)與高光兩部分。卡通渲染的陰影基本上都是某種Lambert 光照的變體。一個常用的簡化模型就是將Lambert 二值化,根據閾值判斷表面上某點是否在陰影中,然而這種做法的結果通常比較呆板。為了減少這種現象,同時更重要地為了更精確地模擬多樣的風格,需要更精細的光照模型的建模。
我們將傳統的Lambert 模型參數化,通過一個連續函數映射到不同的Lambert 閾值并使用該函數進行三維渲染,意圖對不同的空間相對位置逐漸更改渲染方式,通過學習擬合出目標圖片最近的函數,達到風格模仿的目的。具體來說,對于場景表面任一點,我們使用切空間坐標系下光照向量L 在tangent-bitangent 平面(切平面)上的投影與切線的夾角作為自變量,Lambert二值化的閾值作為因變量。對于輸入圖像的每一個像素,其法線方向已經確定,因而可以臨時構建出一個切空間,確定該像素在上述函數中對應的自變量的位置,從而插值擬合出函數。實時渲染時通常使用一維貼圖來保存和使用這個函數。
然而這樣得到的閾值函數在實際渲染中細節處會有尖刺般的噪聲。這是因為使用一維貼圖表示函數時采樣率過高導致容納下了高頻噪聲。噪聲出現主要的原因在于當沿著法線圖陰影邊界路徑采樣時,并不能精確地采樣到并不存在的子像素的數據,而是直接讀取了距離路徑最近的像素中點的法線數據,保存下了并不該有的數據跳變。經驗表明法線圖的數據精度不足也是部分原因。
本文的解決方法為,最開始從圖片生成閾值函數時,用盡可能高的采樣率采取數據,之后使用信號處理的方法用低通濾波器去除高頻噪聲,但并不降采樣地直接寫入貼圖使用。這樣結果上解決了問題,然而使用高采樣率來保存遠小于其奈奎斯特頻率的信號是一種空間的浪費。作為改進,我們可以直接從原始函數中提取并保存諧波,對高次諧波的丟棄等效于低通濾波。渲染時實時對諧波進行加總。此方法在函數梯度大的部分可實時丟棄部分高次諧波,起到類似Mipmap的作用。
此外,出于卡通風格的要求,我們希望得到不規則形狀的高光。傳統上這個問題大多由各向異性的BRDF 進行模擬,常用Kajiya-Kay[7]與Ashikhmin[8]模型。前者的BRDF 主要由對頭發的幾何特性進行分析而得到,對任意風格的高光形狀的表達力不強,這里選用了后者。Ashikhmin BRDF 的表達式如下:

利用這個性質,由卡通圖片擬合各向異性高光渲染參數的流程如下:由圖片的高光光斑中心出發,以對應的切線或旁切線為方向找到相交的高光邊緣位置,加上由法線圖得到此處的法線,帶入Ashikhmin BRDF求解得到nu或nv。
3 結果分析

圖7
自左至右:Lambert 模型渲染結果;不使用濾波的結果;使用濾波后的結果。注意陰影邊緣的改進。
為了測試算法應用于實際卡通渲染場景的可行度,使用Unity 引擎的ShaderLab 語言實現本文的光照模型并與業界常規的UnityChanToonShader 比較,在中度復雜度的場景中實驗結果如表1。

表1
語義信息提取過程中本文改進的圓周KDE 與傳統卷積法的性能比較如表2。

表2
根據以上數據可以得出結論,與傳統方法相比,本文的解決方案從效果和速度兩個方面評價都有一定的優勢,具備了一定的可用性。
4 結語
本文通過分析現有非真實性渲染中卡通渲染算法的不足點,提出了一套全新的卡通渲染流程。通過創新的自動語義信息提取流程,在注重算法效率的前提下,實現了卡通風格的由二維到三維的風格模仿,包括一個有一定可用度的卡通渲染算法,并利用信號分析等方法對流程中的性能熱點進行了優化。實驗結果顯示,本文的解決方案在實際運行中能達到引言介紹的要求,有相當的實用性,適宜于各類實時與非實時的卡通渲染場景。
猜你喜歡
小學時代·科學小問號(2024年10期)2024-10-31 00:00:00
開放教育研究(2020年2期)2020-03-31 01:54:14
中國社會歷史評論(2016年2期)2016-06-27 07:11:52
現代語文(2016年21期)2016-05-25 13:13:44
長江學術(2016年4期)2016-03-11 15:11:31
中學語文·大語文論壇(2015年1期)2015-05-30 22:02:35
大連民族大學學報(2015年2期)2015-02-27 08:28:11
語言與翻譯(2014年2期)2014-07-12 15:49:25
語文知識(2014年2期)2014-02-28 21:59:18
當代修辭學(2011年6期)2011-01-29 02:49:50
