基于數據挖掘技術的應答器報文分析方法研究
2019-03-04 03:48:52楊四輩
鐵路通信信號工程技術 2019年1期
楊四輩
(北京全路通信信號研究設計院集團有限公司,北京 100070)
1 概述
我國高速鐵路列車運行控制系統多采用CTCS-2級和CTCS-3級,應答器系統在信息傳輸媒介均發揮著至關重要的作用。
在實際的使用中,往往出現因為應答器報文錯誤而導致的高鐵列車緊急制動等事故多次發生,嚴重影響列車運行效率,甚至危及旅客的生命財產安全。因此亟需對應答器報文有效性可用性等做出判斷。然而,應答器數量龐大,其所包含數據信息數量龐大、種類繁多,面對如此海量的數據,從中篩選出不一致的信息,降低數據誤差導致的不良影響,是一個急需解決的問題。
近些年來,計算機科學技術發展迅速,其處理分析數據的速度及能力高速提升,使得數據挖掘的作用得到更好發揮。
應答器報文數據信息又有復雜多樣和隱蔽性的特點,把數據挖掘技術應用于應答器報文的數據分析,必將提高工作效率和計算結果的準確度,使應答器報文分析系統具有真正的實用價值。
2 應答器報文信息的國內外研究現狀
對于應答器報文信息的研究從未中斷,主要包括:朱曉航等充分研究基于FPGA的應答器報文編碼和譯碼;邢毅等從應用層面,分析高鐵列車運行控制系統應答器報文應用原則;劉長波等人提出一種采用仿真方法對應答器報文進行動態驗證的方法:即通過使用計算機對聯鎖設備和列控中心設備進行仿真,驗證應答器報文中的相關信息是否正確,這種方法在通號實驗室普遍推廣并為理論研究提供了良好的思路。但尚未有基于數據挖掘算法對應答器報文數據信息進行系統性的結構分析和報文內容一致性驗證。
3 數據挖掘技術應用概述
數據挖掘(Data mining)是用人工智能、專家系統、統計方法和計算機數據存儲的交叉方法在大的數據集中發現規律的計算方式。
數據挖掘過程的總體目標是從一個數據集中提取信息,并將其轉換成可理解的結構,以進一步使用。而這一總體目標同對應答器報文信息的處理是一致的,所以可以使用數據挖掘技術進行應答器報文信息的處理。數據挖掘技術的算法有很多種,但是針對應答器報文信息的特點,要選擇合適算法。
基于密度的聚類算法,是為了挖掘有任意形狀特性的類別而專門設計的。此算法把一個類別看成數據集中大于某特定值的一個大區域。DBSCAN和OPTICS是兩個典型的算法。
主要的聚類算法分類如表1所示。
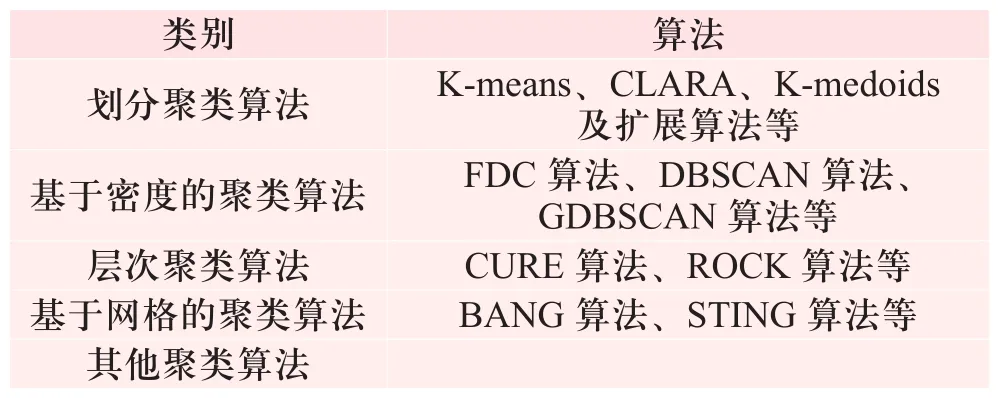
表1 常見的聚類算法Tab. 1 Common Clustering Algorithm
基于各種聚類算法的優劣,結合高速鐵路應答器報文數據的信息特征,選取K-means聚類算法,進行應答器數據挖掘技術中的數據分析算法。
4 基于K-means的應答器數據分析方法簡介
基于K-means聚類分析的應答器數據分析流程如圖1所示,主要包含以下幾個步驟。
1) 應答器原始數據的提取。
2) 應答器報文數據解析。
3) 解析后數據的分類存儲與預處理。
4) 采用K-means進行聚類分析,得到分類結果。
5) 對分類結果進行數據一致性分析,判定應答器報文數據的一致性。
5 應答器報文數據分析系統的設計及實現
5.1 應答器報文數據分析系統的功能分析
應答器報文數據主要功能需求及C/S結構的基本特征,應答器報文數據分析系統界面布局如圖2所示,包括系統工具欄區、報文數據顯示區、解析數據顯示區和日志及報警信息顯示4部分。
5.2 應答器報文數據分析系統軟件的功能實現
雖然應答器數據量大,但是其解析數據擁有結構清晰的特點,對于使用大數據分析的方法,難免大材小用,且不易于工程化的設計和實現,因此可以考慮采用小型化、輕便的數據分析工具來實現基于K-means的應答器數據分析。
應答器報文讀取功能模塊是整個應答器報文數據分析系統的基礎,其主要完成應答器報文數據的正確、高效讀取,并注入整個系統平臺,為平臺的正常正確運行提供基礎數據支撐。應答器報文讀取模塊的程序框架,如表2所示。
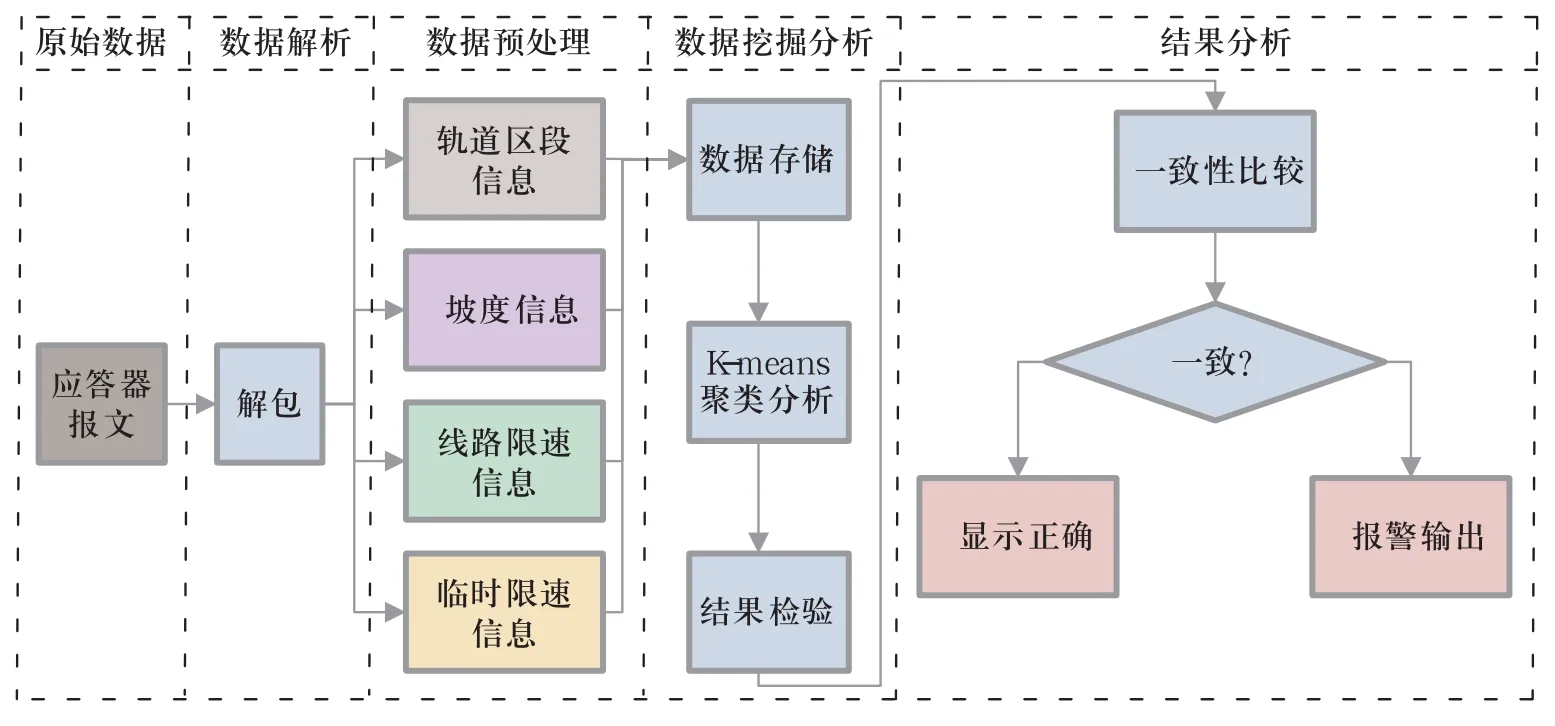
圖1 基于K-means聚類分析的應答器數據分析流程Fig.1 The Balise data analysis process based on K-means
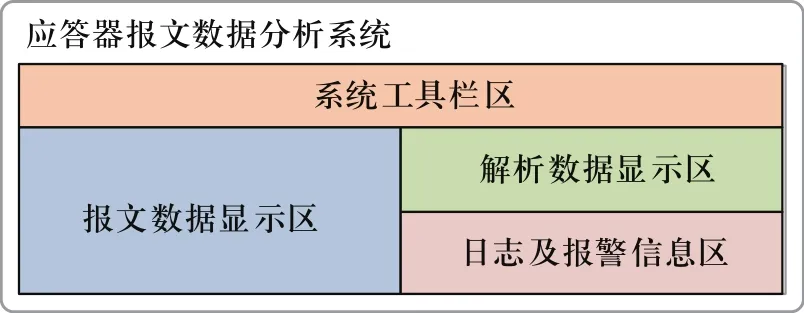
圖2 應答器報文數據分析系統界面布局Fig.2 The operation interface of balise message data analysis system

表2 應答器報文讀取模塊的程序框架Tab. 2 Program frame of the balise message reading module
應答器報文解析功能模塊是整個應答器報文數據分析系統的一個核心模塊,其主要完成應答器報文數據解碼功能,主要包含應答器原始數據進制轉換、數據位數檢查、應答器報文幀頭解析、用戶信息寶解析等功能,其程序框架,如表3所示。
5.3 數據驗證與結果分析
結合應答器報文讀取報文、報文解析、數據分析、數據顯示等主要功能需求,實現界面包含系統工具欄區、報文數據顯示區、解析數據顯示區和日志及報警信息顯示4部分,集應答器報文解析、報文組包、基于數據挖掘的應答器報文分析、分析結果顯示于一體的應答器報文分析系統,系統應答器報文解析界面如圖3所示。
應答器報文數據分析系統界面需清晰友好、操作簡單,能夠完全實現報文讀取報文、報文解析、數據分析、數據顯示等功能,在一定程度上具備系統的準確性、互操作性、依從性、安全性以及功能要求等。

表3 應答器報文解析模塊的程序框架Tab. 3 Program frame of the balise message parsing module

圖3 應答器報文數據分析系統運行界面Fig.3 The operation interface of balise message data analysis system
應答器報文數據分析系統進行應答器數據分析,相比于以往的人工數據校驗工作,效率大大提升,并且準確率也得到保障,降低了因人為疏忽導致的數據校驗誤差。
如圖4所示,通過對國內某高鐵線路的應答器信息進行數據解析、存儲,并經過基于K-means數據挖掘算法的分析得到全線的分相區信息、坡度信息、固定限速信息、應答器鏈接信息、特殊軌道區段信息、大號碼道岔信息等分類簇,并且分類簇的數據具備相同的屬性,從而為進行不同應答器描述的同一信息的一致性分析奠定數據基礎。
圖4 分相區信息聚類分析結果Fig.4 The results of clustering analysis of the phase separation zone information
經過應答器報文數據分析系統對圖4所示的全線分相區的分類匯總信息,進行數據的一致性分析,可以很直觀的得到,全線對于同一分相區的信息雖然在不同的應答器中進行描述,但是對于同一分相區信息的描述與高速鐵路應答器應用原則的要求一致,并且同一分相區的位置(反映到數據中就是公里標)一致,如圖5所示,描述分相區信息的曲線完全重合。
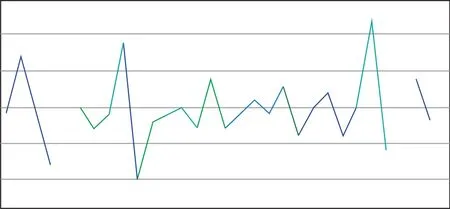
圖5 分相區信息一致性分析結果Fig.5 The results of consistency analysis of the phase separation zone information
同樣,以該高鐵線路某區間的坡度信息為例,其聚類分析后的數據分類簇如圖6所示,其中可以看到對于某段坡度信息的描述,少則在某一組應答器單獨描述,多則可以達到12個應答器組之多,可見如果對于該線路所描述的所有坡度信息進行人工的數據一致性分析,是非常龐大的工作量,需要耗費相當大的人力和物力。但是應答器報文數據分析系統實現對于數據的查看、分析和輔助完善更加便捷、高效。
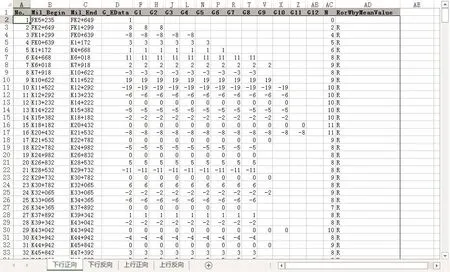
圖6 坡度信息聚類分析結果Fig.6 The results of clustering analysis of the slope information
經過本文所研發的應答器報文數據分析系統對圖6所示的全線坡度的分類匯總信息,進行數據的一致性分析可以很直觀的得到,全線對于同一坡度的描述雖然在不同的應答器中,但是對于同一坡度信息的描述有5處描述的不一致,如圖7所示。
1) 有2組應答器對于同一坡度位置的坡度信息描述不一致的4處。
2) 有3組應答器對于同一坡度位置的坡度信息描述不一致的1處。
6 總結
以地面應答器報文驗證需求為出發點,結合應答器的本身特性,對應答器應用進行分析,提出基于數據挖掘的應答器報文數據分析方法,對高速鐵路列控系統的應答器報文驗證工作有一定的參考價值和實用意義。
但也存在不足:實現算法依個人觀點總結所得,算法較簡單,究其原因,是實現思路、驗證方法過于簡單,未能使檢測結果滿足所有的現實情況所致。其次對應答器報文的驗證只局限于地面設備,未能加入車載接受信息過程對整個測試過程的影響。
7 未來工作展望
我國對于應答器系統的研制起步相對較晚,類似于應答器報文數據驗證等很多操作還需人工手動完成,時間長且工作效率低。在大量的應答器報文信息編制工作及保證應答器報文數據正確性、安全性方面仍需進一步改進。因此開發全自動化的應答器報文數據驗證工具,通過對應答器報文進行解碼譯碼驗證數據包格式正確性,并與工程數據表對應數據比對,以檢驗其內容的正確性。為后續應答器報文數據分析提供可靠真實的依據。
猜你喜歡
大眾投資指南(2021年35期)2021-02-16 01:06:26
中華手工(2017年2期)2017-06-06 23:00:31
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
中外會展(2014年4期)2014-11-27 07:46:46
河南科技(2014年23期)2014-02-27 14:18:43
電子設計工程(2014年18期)2014-02-27 12:00:13
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
