學習材料組塊方式對相似詞長時記憶的影響*
2019-03-05 02:11:48魯成柔林軍鳳梅磊磊
心理學報 2019年3期
張 蕾 魯成柔 林軍鳳 梅磊磊
?
學習材料組塊方式對相似詞長時記憶的影響
張 蕾 魯成柔 林軍鳳 梅磊磊
(華南師范大學心理應用研究中心, 心理學院, 廣東省心理健康與認知科學重點實驗室, 廣州 510631)
已有關于材料相似性影響短時記憶的研究提示, 不相似材料組塊相比于相似材料組塊可能促進記憶。為驗證該假設, 該研究采用學習?測查范式, 通過4個實驗考察了學習材料組塊方式對相似詞長時記憶的影響及機制。結果發現:1)與相似詞組塊相比, 不相似詞組塊促進了相似詞記憶; 2)不相似詞組塊的促進效應是通過增強相似詞表共同詞根的記憶而實現的; 3)不相似詞組塊的促進效應可能依賴于語音相似性。該結果說明不相似詞組塊可能是促進相似詞匯記憶的有效途徑之一。
學習?測查范式; 詞匯記憶; 組塊方式; 相似詞
1 前言
詞匯是語言的基本組成單元, 其學習的效果直接影響個體的語言習得(DeAnda, Poulin-Dubois, Zesiger, & Friend, 2016)。在現存的各種語言中, 存在大量的字形、語音和語義相似的詞匯。由于這些詞匯在學習過程中容易與其相似的詞匯混淆, 所以人們在記憶這些材料時會表現出困難(曲折, 丁玉瓏, 2010; 曲折, 劉優, 畢耀華, 2010)。因此, 如何有效學習和記憶相似詞直接關乎到個體能夠快速、高效地掌握詞匯。
已有研究發現組塊策略可以影響詞匯的學習與記憶(Gilbert, Boucher, & Jemel, 2014)。組塊策略是指在記憶過程中按照相似性或其它原則對學習材料進行組塊編碼。就學習材料的相似性而言, 組塊策略可以分為相似材料組塊和不相似材料組塊。相似材料組塊指將視覺或語音相似的材料進行組塊編碼, 而不相似材料組塊指將視覺或語音不相似的材料進行組塊編碼。與不相似材料組塊相比, 相似材料組塊中相似的學習材料相繼進行記憶編碼, 相關腦區的活動會表現出抑制效應, 即對相似材料的反應強度降低(Glezer, Jiang, & Riesenhuber, 2009; Glezer, Kim, Rule, Jiang, & Riesenhuber, 2015)。換句話說, 與不相似材料組塊相比, 學習者在相似材料組塊條件下記憶編碼相關腦區的參與強度較低, 因而可能表現出較低的記憶成績。
前人研究通過視覺相似項目和視覺不相似項目的短時記憶的對比為不相似材料組塊的優勢效應提供了間接的實驗證據。具體而言, 在短時序列記憶中, 視覺不相似材料比視覺相似材料表現出更好的記憶成績(Avons, 1999; Logie, Della Sala, Wynn, & Baddeley, 2000; Logie, Saito, Morita, Varma, & Norris, 2016; Saito, Logie, Morita, & Law, 2008; Smyth, Hay, Hitch, & Horton, 2005)。例如, Logie等人(2000)以英文單詞作為實驗材料, 要求被試完成相似項目序列和不相似項目序列交替的短時序列記憶任務。通過相似項目序列和不相似項目序列記憶成績的比較發現, 視覺不相似項目的記憶成績顯著高于視覺相似項目。類似地, Poirier (2007)以黑白線條圖為實驗材料, 要求被試完成由相似項目序列和不相似項目序列隨機組成的短時序列記憶任務, 結果發現不相似項目的記憶成績顯著好于相似項目的成績。在上述研究中, 相似項目序列的學習材料以相似材料組塊方式呈現, 即一組視覺相似的學習材料相繼呈現; 而不相似項目序列的學習材料以不相似材料組塊方式呈現, 即一組視覺不相似的學習材料相繼呈現。因此, 這些研究提示, 與相似材料組塊相比, 不相似材料組塊可能促進詞匯的記憶。盡管如此, 由于前人研究中不相似材料組塊的記憶優勢都是基于兩組不同學習材料(相似材料和不相似材料)的記憶成績對比而發現的, 所以其研究結果既可能反映了不相似材料組塊的記憶優勢, 也可能反映了兩組實驗材料的記憶難度差異。具體來說, 與視覺不相似的學習材料相比, 視覺相似的學習材料之間容易相互混淆, 因而記憶難度更大(Nairne, 1990)。為了排除實驗材料記憶難度的差異, 本研究擬使用兩組記憶難度匹配的相似詞為材料, 探討學習材料組塊方式(相似詞組塊和不相似詞組塊)對相似詞記憶的影響及作用機制。這是本研究擬解決的第一個研究問題。
在上述研究的基礎上, 研究者進一步使用因素設計對視覺相似性和語音相似性在詞匯記憶中作用進行了分離。研究者比較一致地發現語音相似性在詞匯記憶中起重要作用, 但是關于視覺相似性的作用存在爭議。一部分研究者發現, 語音相似性和視覺相似性在詞匯記憶中都會起作用(Lin, Chen, Lai, & Wu, 2015; Saito et al., 2008)。例如, Saito等人(2008)以日語單詞為實驗材料, 探討了視覺相似性和語音相似性對詞匯記憶的影響。為了操作視覺相似性和語音相似性, 研究者構建了4種詞表:視覺和語音都相似, 視覺相似而語音不相似, 視覺不相似而語音相似, 視覺和語音都不相似。結果發現, 語音不相似項目的記憶成績顯著好于語音相似項目; 視覺不相似項目的記憶成績也是顯著高于視覺相似項目。與此不同, 另一部分研究者認為語音相似性在詞匯記憶中起主要作用, 而視覺相似性的作用不明顯(李軒, 劉思耘, 2012)。具體而言, 李軒等人(2012)以漢字為實驗材料, 構建了與Saito等人的研究類似的4類詞表, 要求漢語母語者完成4類詞表的短時序列記憶任務。結果發現, 語音不相似項目記憶成績顯著好于語音相似性項目, 而視覺相似性項目與視覺不相似項目記憶成績沒有顯著差異。雖然已有研究針對語音相似性和視覺相似性在詞匯記憶中作用進行了很多探討, 但是這些研究使用的都是熟悉的文字, 因而語音相似性和視覺相似性在陌生詞匯的記憶中如何起作用尚不清楚。因此, 本研究的第二個研究目的是探究學習材料組塊方式對陌生的視覺相似詞匯記憶的影響是否依賴于語音相似性。
為了探討上述兩個研究問題, 本研究采用被試內設計和學習?測查范式, 通過4個實驗系統探討了學習材料組塊方式對相似詞長時記憶的影響及作用機制。實驗1A以英文非詞為實驗材料, 通過操縱學習階段學習材料的組塊方式(相似詞組塊和不相似詞組塊), 探究學習材料組塊方式對相似英文非詞記憶的影響。實驗1B采用與實驗1A相同的實驗方法, 但將學習和測查之間的時間間隔延長至一周, 以探究學習材料組塊方式對相似詞記憶的影響是否能長時保持。依據材料相似性影響短時記憶的研究發現(Avons, 1999; Logie et al., 2000; Logie et al., 2016; Saito et al., 2008; Smyth et al., 2005), 預期不相似詞組塊相比于相似詞組塊能夠促進相似詞的記憶。在實驗1的基礎上, 實驗2使用錯誤記憶范式, 在測查階段加入與學習材料相似的詞匯作為誘餌刺激, 進一步探討學習材料組塊方式對相似詞記憶的影響機制。模糊痕跡理論(Fuzzy Trace Theory)認為, 再認判斷主要基于兩類記憶表征:一類是在學習中對項目之間共同部分加工而形成的較籠統的記憶表征; 另一類是對各個細節特征進行加工而形成的較明確的記憶表征(Reyna & Brainerd, 1995)。依據模糊痕跡理論, 與相似詞組塊方式相比, 不相似詞組塊對相似詞記憶的促進作用既可能是因為增強了相似詞共同詞根的籠統記憶, 也可能是因為提高了單個詞匯的細節性信息的記憶。由于共同詞根的籠統記憶表征的增強會提高錯誤記憶, 而單個詞匯的細節性信息的記憶表征增強會降低錯誤記憶, 所以使用錯誤記憶范式可以有效區分上述兩種可能性(Gallo, 2010; 肖紅蕊, 黃一帆, 龔先旻, 王大華, 2015)。如果不相似詞組塊的記憶優勢是因為不相似詞組塊促進了相似詞表共同詞根的籠統記憶, 那么不相似詞組塊條件下誘餌刺激的錯誤記憶率高于相似詞組塊條件; 如果不相似詞組塊的記憶優勢是因為不相似詞組塊促進了單個詞匯獨特的細節性信息的記憶, 那么不相似詞組塊條件的錯誤記憶率更低, 或兩種條件的錯誤記憶率沒有差異。實驗3以陌生的韓字(沒有語音)作為實驗材料, 更進一步探究學習材料組塊方式對陌生相似詞記憶的影響是否依賴語音相似性。如果學習材料組塊方式效應依賴于語音相似性, 那么相似韓字的學習不會表現出不相似詞組塊的記憶優勢; 反之, 則會表現出不相似詞組塊的記憶優勢。最后, 雙加工理論(dual-process theory)認為再認記憶包含熟悉性(familiarity)和回想(recollection)兩種獨立的加工過程(Rugg & Yonelinas, 2003; Smith, Wixted, & Squire, 2011; Wixted & Mickes, 2010)。熟悉性是指對學習項目熟悉, 但無法提取細節性信息; 回想是指不僅能夠提取學習項目, 還能提取與學習項目相關聯的背景和細節。為了考察學習材料組塊方式對回想和熟悉性過程的影響, 本研究通過記憶的自信心評定嘗試分離回想和熟悉性兩種加工過程。一般認為, 與低自信記憶項目相比, 高自信記憶項目的提取包含更多回想過程(Squire, Wixted, & Clark, 2007)。因此, 如果學習材料組塊方式主要影響回想過程, 那么只有高自信記憶得分會表現出組塊方式效應; 反之,則高低自信記憶得分都會表現出組塊方式效應。
2 實驗1A:學習材料組塊方式對相似詞記憶的影響
2.1 實驗目的
通過比較相似詞組塊和不相似詞組塊條件下相似詞匯記憶效果的差異, 探究學習材料組塊方式對相似詞記憶效果的影響。
2.2 實驗方法
2.2.1 被試
招募了22名母語為漢語的大學生(男5名)為被試, 年齡19~26歲, 平均年齡21.14 ± 1.89歲, 所有被試皆為右利手, 視力或矯正視力正常, 實驗結束后, 每個被試會得到相應的報酬。被試量的確定有兩方面依據。一方面, 以往類似研究的被試量為16~24人(李軒, 劉思耘, 2012; Lin et al., 2015; Saito et al., 2008), 本實驗的被試量與這些研究相當。另一方面, 一般認為, 理想的統計檢驗力和效應量均需高于0.8 (Cohen, 1988)。使用G-power軟件(http://www.gpower.hhu.de/)計算統計檢驗力和效應量均為0.8所對應的被試量為15人。因此, 本實驗的被試量具有足夠的統計檢驗力。之后三個實驗的被試量確定依據與此相同。
2.2.2 實驗材料
實驗材料包含232個英文非詞, 所有非詞的詞長均為6。英文非詞均選自英文詞匯數據庫(http:// elexicon.wustl.edu/) (Balota et al., 2007), 英文非詞圖片材料的尺寸均為226 × 151。其中8個非詞置于學習序列的首尾, 用于排除或減弱首因和近因效應(Mei et al., 2010; 薛紅莉, 梅磊磊, 薛貴, 陳傳升, 董奇, 2017)。剩余實驗材料分為兩組, 每組112個非詞, 一組作為學習材料, 另一組用于測試階段的填充材料。學習材料分成匹配的兩組, 每組包含56個非詞, 分別用于相似詞組塊和非相似詞組塊學習。兩種學習條件的實驗材料均包含14個相似詞組, 每個詞組由4個相似的英文非詞組成。每個相似詞組中的4個非詞間至少前4個字母或后4個字母相同。兩組實驗材料中, 每個相似詞組內的4個英文非詞之間的共同字母平均數量分別為4.25個和4.26個。
為了確保兩組學習材料的同質性, 在正式實驗之前, 我們招募了9名大學生被試對兩組材料進行記憶, 發現兩組學習材料的擊中率分別為0.67和0.65。方差分析發現, 兩組材料的記憶效果沒有顯著差異(基于被試的分析:(1, 8) = 0.30,= 0.602; 基于項目的分析:(1, 110) = 0.30,= 0.585)。
2.2.3 實驗程序
實驗包含兩個階段:學習階段和再認記憶測查階段, 如圖1所示。
(1)學習階段
學習任務包含兩種學習條件:相似詞組塊條件和不相似詞組塊條件。在兩種學習條件下, 被試都需要學習56個英文非詞, 包含14組相似詞。在相似詞組塊條件下, 學習材料分成14個相似詞組, 每個相似詞組的4個相似詞連續呈現, 每個相似詞組內的4個英文非詞之間的共同字母的平均數量大于4; 而在不相似詞組塊條件下, 將由14個相似詞組組成的學習材料分成14個不相似詞組, 每個不相似詞組的4個不相似詞連續呈現, 每個不相似詞組內的4個英文非詞之間的共同字母的平均數量小于0.5個。為了平衡順序效應, 學習中相似詞組塊條件和不相似詞組塊條件以ABBA的順序交替出現。為了排除學習材料的差異, 我們對兩種學習條件的材料進行了被試間平衡。
在實驗中, 每個組塊內的4個英文非詞連續呈現, 每個英文非詞呈現3 s, 之后呈現1~3 s (平均2 s)的注視點。被試的任務是努力記住呈現的每一個英文非詞。每個組塊連續呈現兩次, 但兩次呈現時組塊內英文非詞的呈現順序不同, 同一英文非詞兩次呈現之間間隔1~5個其它英文非詞(平均3個), 兩種組塊條件的重復間隔匹配。為了排除首因和近因效應的影響, 在學習序列的首尾處各增加4個填充刺激, 這些填充刺激沒有包含在之后的再認記憶測查中。被試的任務是認真注視屏幕上的刺激, 并努力記住它。整個學習階段時長為20 min。

圖1 實驗流程示意圖:學習任務(A), 數字判斷任務(B)和再認測查任務(C)。
為了防止被試刻意回憶學習過的詞匯, 被試在學習任務結束后還需完成算式判斷任務。在該任務中, 被試需要對屏幕上呈現的數學等式進行正誤判斷, 該任務總時長為350 s。在完成算式判斷任務后, 被試被安排在一間休息室中等待再認記憶任務測查。在休息期間, 被試可以看雜志或玩手機, 但不能回憶學習材料。
(2)再認記憶測查階段
在學習階段后1小時進行再認記憶任務。再認記憶任務包含224個英文非詞, 其中112個為學習任務中的學習材料, 另外112個為被試未學習過的填充刺激。所有刺激以隨機順序依次呈現, 被試需要根據自己的記憶情況按鍵判斷屏幕上呈現的刺激是否在學習階段出現過。研究采用6點量表的反應模式, 其中6表示肯定學習過, 1表示肯定沒學習過, 2~5介于兩者之間。被試按鍵后刺激立即消失, 800 ms之后呈現下一個刺激。
2.2.4 數據分析
在數據分析中, 依據被試在再認記憶任務中的按鍵反應, 計算記憶正確率、兩種學習條件的反應時、擊中率和辨別力指數()。對學習過的詞匯進行4~6按鍵反應或未學習過的詞匯進行1~3的按鍵反應記為正確, 反之記為錯誤。辨別力指數依據公式= Z? Z進行計算。為了區分回想和熟悉性過程, 進一步計算了高自信擊中率和低自信擊中率。高自信擊中率是指對舊詞進行6的按鍵反應的項目數與舊詞數量的比值, 低自信擊中率是指對舊詞進行4~5的按鍵反應的項目數與舊詞數量的比值。采用SPSS 17.0對記憶正確率進行單樣本t檢驗, 對反應時、擊中率、辨別力指數、高自信擊中率和低自信擊中率進行配對樣本t檢驗。
2.3 實驗結果
再認記憶任務的平均正確率和標準差見表1。被試在再認記憶測查中的平均正確率為0.82。單樣本t檢驗發現, 記憶正確率顯著高于概率水平(0.50),(21) = 17.01,< 0.001,= 3.63。該結果說明被試在學習階段確實對學習材料進行了認真記憶。
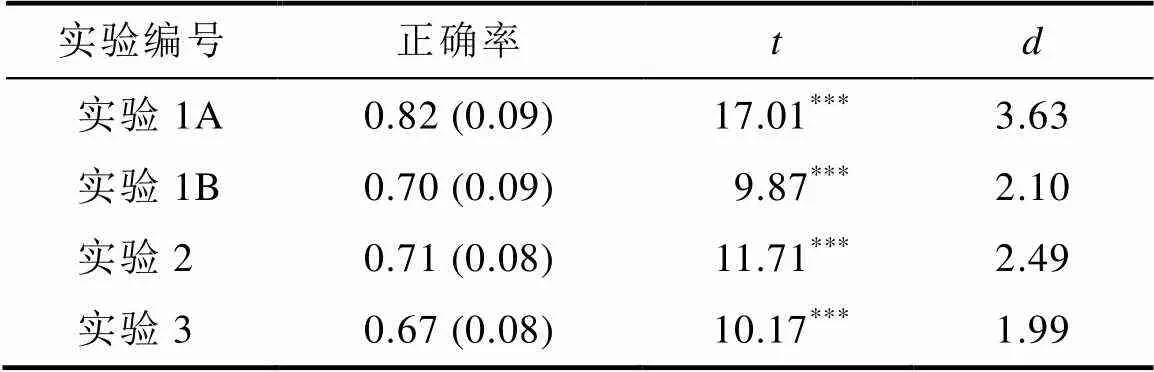
表1 再認記憶測查的平均正確率(標準差)及t檢驗結果
注:***< 0.001
兩種學習條件的擊中率和辨別力指數如圖2。相似詞組塊條件和不相似詞組塊條件的擊中率分別為0.80和0.86, 兩種學習條件的辨別力指數分別為1.96和2.28。配對樣本t檢驗發現, 相似詞組塊條件的擊中率顯著低于不相似詞組塊條件的擊中率((21) = ?3.37,= 0.003,= 0.72, 95%CI [?1.09, ?0.03]), 相似詞組塊條件的辨別力指數也顯著低于不相似詞組塊條件的辨別力指數((21) = ?3.67,= 0.001,= 0.78, 95%CI [?0.49, ?0.14])。該結果表明不相似詞組塊條件下詞匯記憶效果顯著好于相似詞組塊條件。
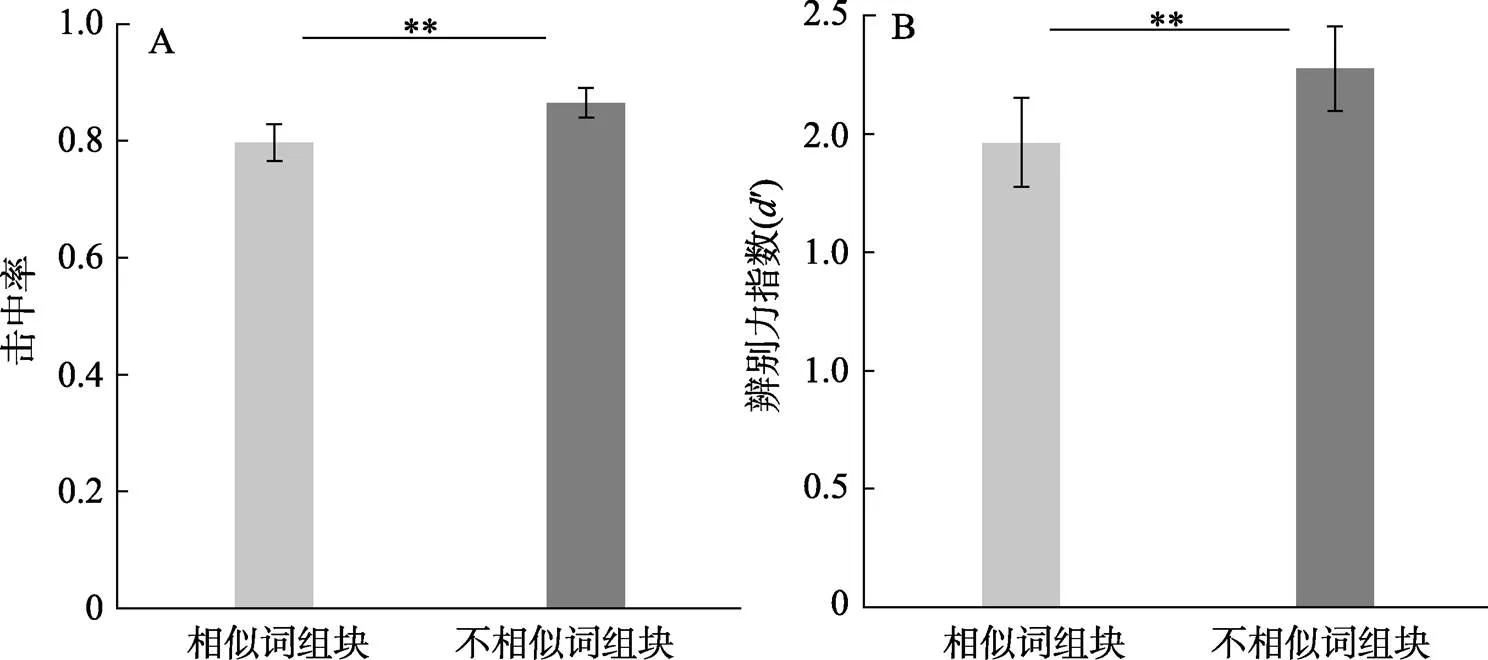
圖2 實驗1A中兩種組塊條件的擊中率(A)和辨別力指數(B)。
然后, 使用配對樣本t檢驗比較了相似詞組塊條件(2020.76 ms)和不相似詞組塊條件的反應時(1908.26 ms)發現, 兩種組塊條件的反應時沒有顯著差異,(21) = 1.55,= 0.136。該結果說明本實驗中發現的組塊方式效應沒有受到速度準確性權衡的影響(表2)。
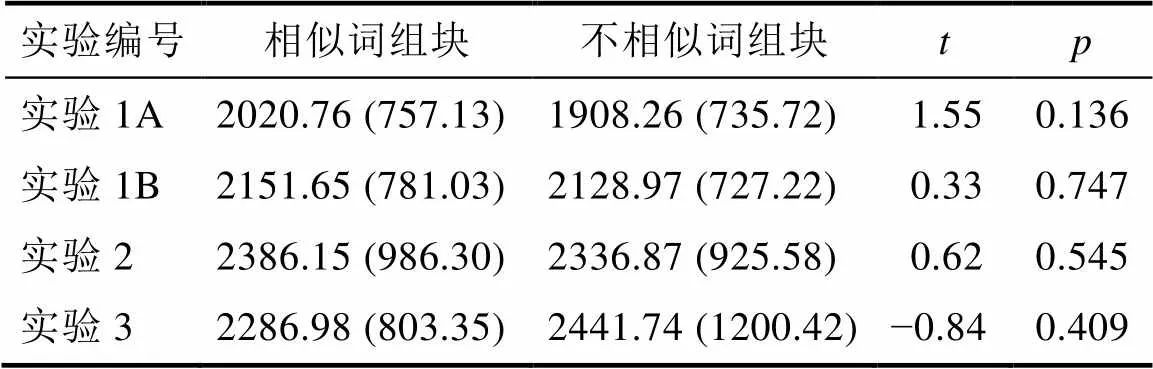
表2 再認記憶測查中兩種組塊條件的平均反應時(標準差)及t檢驗結果
最后, 為了考察學習材料組塊方式對再認記憶中熟悉性和回想過程的影響, 進一步比較了兩種組塊條件下高自信擊中率和低自信擊中率的差異(表3)。結果發現, 相似詞組塊條件的高自信擊中率顯著低于不相似詞組塊條件,(21) = ?2.66,= 0.015,= 0.57, 95%CI [?0.10, ?0.01]; 而兩種組塊條件在低自信擊中率上沒有差異,(21) = ?0.68,= 0.506。該結果說明學習材料組塊方式可能主要影響再認記憶中回想過程。
2.4 討論
實驗1A探討了學習材料的組塊方式對相似詞記憶的影響。結果發現, 無論是以擊中率還是以辨別力指數為指標, 被試在不相似詞組塊條件下的詞匯記憶效果都好于相似詞組塊條件。該結果說明, 與相似詞組塊方式相比, 不相似詞組塊方式能夠促進相似詞的記憶。
實驗1A的結果首先重復了前人研究關于不相似詞組塊的記憶優勢的發現(Avons, 1999; Saito et al., 2008)。更為重要的是, 與前人研究通過兩組不同學習材料(相似學習材料和不相似學習材料)的比較而發現的不相似詞的記憶優勢不同, 本研究發現, 當兩組學習材料同為相似詞時, 不相似詞組塊方式相比于相似詞組塊也能促進相似詞的記憶。該結果說明不相似詞組塊可能是促進相似詞匯學習和記憶的一種有效途徑。
由于實驗1A中學習與測查之間間隔一小時, 所以該實驗中發現的不相似詞組塊的記憶優勢能否長期保持還有待考證。為了探討該問題, 實驗1B將學習和測查之間的間隔延長至一周, 進而考察相似詞組塊效應的長時保持情況。
3 實驗1B:學習材料組塊方式效應的長時保持性
3.1 實驗目的
通過延長學習與記憶測查之間的時間間隔, 考察學習材料組塊方式效應的長時保持情況。

表3 再認記憶測查中兩種組塊條件的高、低自信擊中率(標準差)及t檢驗結果
3.2 實驗方法
3.2.1 被試
22名母語為漢語的大學生(男2名), 年齡18~26歲, 平均年齡20.09 ± 1.73歲, 所有被試皆為右利手, 視力或矯正視力正常, 此前未參加過實驗1A, 實驗結束后, 每個被試會得到相應的報酬。
3.2.2 實驗材料、實驗程序及數據分析
實驗1B的實驗材料、實驗流程以及數據分析均與實驗1A相同。與實驗1A唯一不同是實驗1B的學習任務與再認記憶測查任務間隔一周。
3.3 實驗結果
實驗1B中再認測查的平均正確率和標準差如表1。單樣本檢驗發現, 測查的正確率都顯著高于概率水平(0.50),(21) = 9.87,< 0.001,= 2.10。這一結果表明被試在學習階段對呈現的詞匯進行了認真記憶。
兩種學習條件的擊中率、辨別力指數、高自信擊中率和低自信擊中率如圖3和表3所示。相似詞組塊條件與不相似詞組塊條件的擊中率分別為0.68和0.73, 辨別力指數分別為1.05和1.23, 高自信擊中率分別為0.24和0.27, 低自信擊中率分別為0.44和0.45。與實驗1A類似, 使用配對樣本檢驗考察了兩種學習條件下擊中率和辨別力指數的差異。結果發現, 不相似詞組塊條件在一周之后的擊中率、辨別力指數和高自信度擊中率顯著高于相似詞組塊條件(擊中率:(21) = ?2.94,= 0.008,= 0.63, 95% CI [?0.08, ?0.01]; 辨別力指數:(21) = ?3.35,= 0.003,= 0.71, 95% CI [?0.28, ?0.07]; 高自信擊中率:(21) = ?2.31,= 0.031,= 0.50, 95% CI [?0.06, 0]), 而兩種組塊條件在低自信擊中率上沒有差異,(21) =?0.98,=0.338。并且, 相似詞組塊條件(2151.65 ms)和不相似詞組塊條件(2128.97 ms)在反應時上沒有顯著差異,(21) = 0.33,= 0.747 (表3)。該結果說明, 不相似詞組塊對相似詞記憶的促進作用可以長時間保持。
3.4 討論
實驗1B通過延長學習與再認測查之間的時間間隔(間隔一周), 考察了組塊效應的長時保持性。結果發現, 無論以擊中率還是辨別力指數為指標, 被試在不相似詞組塊條件下的記憶成績都顯著高于相似詞組塊條件。該結果說明, 不相似詞組塊方式對相似詞記憶的促進作用能夠長期保持。
該實驗的結果一方面重復了實驗1A關于不相似詞組塊方式促進相似詞記憶的實驗結果, 說明學習材料組塊方式效應是穩定存在的; 另一方面從長時記憶保持的角度拓展了實驗1A的結果, 說明不相似詞組塊的優勢能夠長時間保持。盡管如此, 不相似詞組塊方式對相似詞記憶的促進機制依然不清楚。如前所述, 與相似詞組塊相比, 不相似詞組塊對相似詞記憶的促進作用既可能通過增強單個詞匯的特異性細節信息的記憶促進了相似詞的記憶, 也可能是通過增強相似詞中共同詞根的記憶而促進了相似詞的記憶。為了區分上述兩種可能性, 實驗2將采用錯誤記憶范式, 在再認記憶測試中加入與學習材料相似的英文非詞, 對不相似詞組塊方式促進相似詞記憶的機制進行探究(Piguet, Connally, Krendl, Huot, & Corkin, 2008)。
4 實驗2:學習材料組塊方式對相似詞記憶的影響機制
4.1 實驗目的
使用錯誤記憶范式, 探討不相似詞組塊方式對相似詞記憶的促進是因為單個刺激的細節性記憶增強還是因為相似詞中共同詞根的記憶增強。
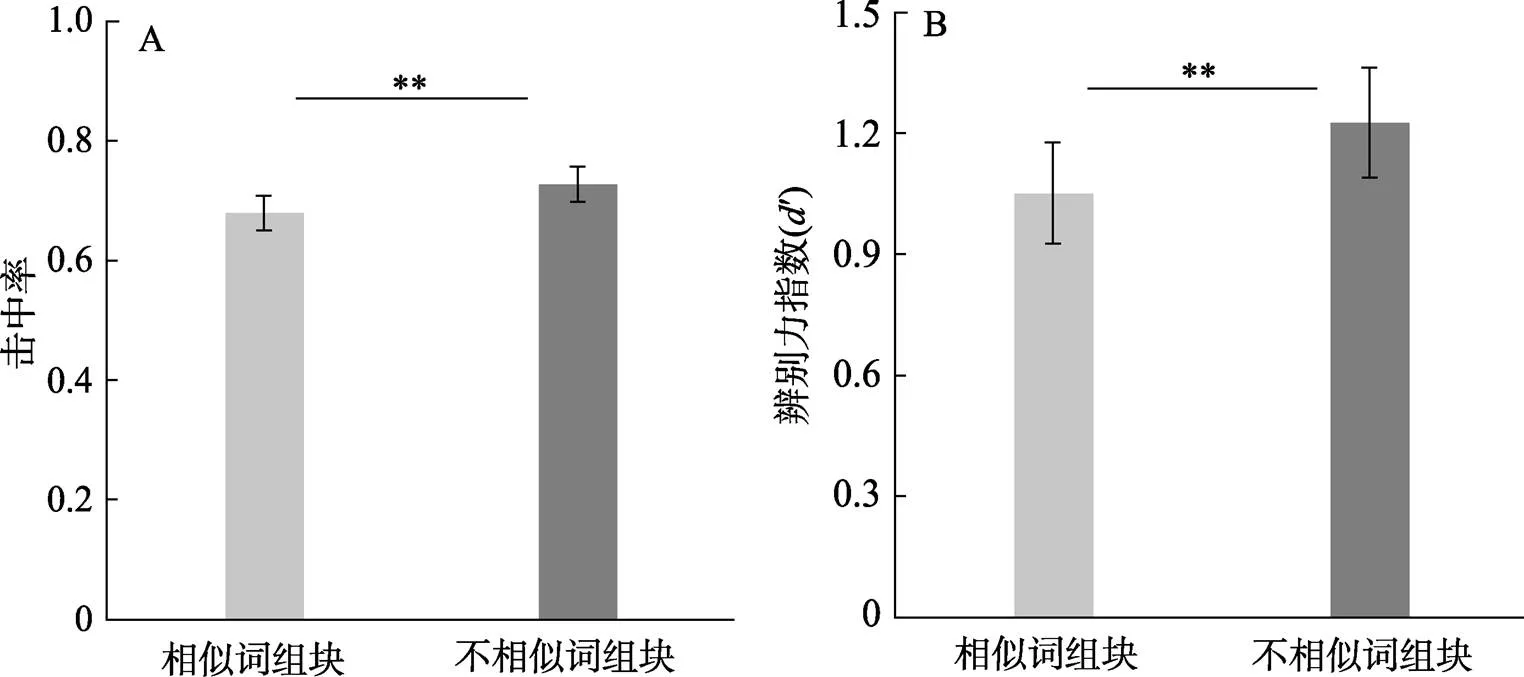
圖3 實驗1B中兩種組塊條件在學習一周后的擊中率(A)和辨別力指數(B)。
4.2 實驗方法
4.2.1 被試
22名母語為漢語的大學生(男6名), 年齡 18~22歲, 平均年齡18.96 ± 1.06歲, 被試皆為右利手, 視力或矯正視力正常, 此前均未參加過實驗1A和1B, 實驗結束后, 每個被試會得到相應的報酬。
4.2.2 實驗材料
實驗材料包含288個詞長為6的英文非詞, 其中學習材料112個, 填充刺激176個。學習材料和120個填充刺激(8個置于學習序列的首尾以排除首因和近因效應, 112個為再認記憶測試中的無關填充刺激)與實驗1A相同。另外56個填充刺激為誘餌刺激, 用于在再認記憶階段探測錯誤記憶。誘餌刺激分為28組, 每組2個刺激, 分別對應學習材料的28個相似詞組。誘餌刺激與對應學習材料相似詞組中的4個非詞共享前4個字母或后4個字母。與實驗1A相同, 學習材料分為相似詞組塊和不相似詞組塊兩種組塊方式條件, 兩種學習條件的實驗材料在被試間平衡。
4.2.3 實驗程序
(1)學習階段
同實驗1A。
(2)再認記憶測查階段
由于實驗1發現組塊方式效應是穩定存在的, 并不依賴于學習?測查間隔, 所以實驗2只設置了一種學習?測查間隔, 即完成學習任務后間隔1周進行再認記憶測查任務。選擇學習?測查間隔1周的另一個原因是實驗1中間隔1小時的再認記憶測試的成績偏高(0.82), 而間隔1周的成績適中(0.70)。在測查中, 280個英文非詞以隨機順序依次呈現, 其中包含112個學習過的英文非詞、112個無關填充刺激和56個誘餌刺激。與實驗1A相同, 被試需要在6點量表上按鍵判斷屏幕上出現的英文非詞是否在學習階段出現過, 其中6表示肯定學習過, 1表示肯定沒學習過, 2~5介于兩者之間。被試按鍵后刺激立即消失, 800 ms之后呈現下一個刺激。
4.2.4 數據分析
數據分析基本與實驗1A相同。分別計算整體記憶正確率, 兩種學習條件的反應時、擊中率、辨別力指數、高自信擊中率和低自信擊中率。記憶正確率與辨別力指數的計算不包含誘餌刺激。除此之外, 還分別計算了兩種學習條件的誘餌刺激的虛報率、區分舊詞與誘餌詞的辨別力指數和判斷標準, 用于比較兩種學習條件的錯誤記憶差異。
4.3 實驗結果
首先, 使用單樣本t檢驗對平均正確率進行分析, 發現記憶正確率顯著高于概率水平(0.50) (見表1),(21) = 11.71,< 0.001,= 2.49。該結果說明被試在學習階段對學習材料進行了認真記憶。
其次, 使用配對樣本t檢驗比較了兩種學習條件的擊中率、辨別力指數、錯誤記憶率、反應時和高、低自信擊中率。如圖4和表3所示, 相似詞組塊和不相似詞組塊條件的擊中率分別為0.64和0.71, 辨別力指數分別為1.29和1.56, 錯誤記憶率分別為0.34和0.42, 高自信擊中率分別為0.25和0.32, 低自信擊中率分別為0.39和0.39。統計檢驗發現, 不相似詞組塊條件的擊中率、辨別力指數和高自信擊中率顯著高于相似詞組塊條件(擊中率:(21) = ?3.50,= 0.002,= 0.75, 95% CI [?0.12, ?0.03]; 辨別力指數:(21) = ?3.29,= 0.003,= 0.70, 95% CI [?0.48, ?0.10]; 高自信度的擊中率:(21) = ?5.03,< 0.001,= 1.08, 95% CI [?0.10, ?0.04]), 而兩種組塊條件在低自信擊中率上沒有顯著差異,(21) =0.03,= 0.972。并且, 與相似詞組塊方式條件相比, 不相似詞組塊條件引起了更高的錯誤記憶率,(21) = ?2.38,= 0.027,= 0.51, 95% CI[?0.14, ?0.01]。在反應時上, 相似詞組塊條件(2386.15 ms)和不相似詞組塊條件(2336.87 ms)之間沒有顯著差異,(21) = 0.62,= 0.545 (表2)。該結果說明與相似詞組塊方式相比, 不相似詞組塊方式提高了相似詞的正確記憶率, 同時也提高了相似誘餌詞的錯誤記憶率。
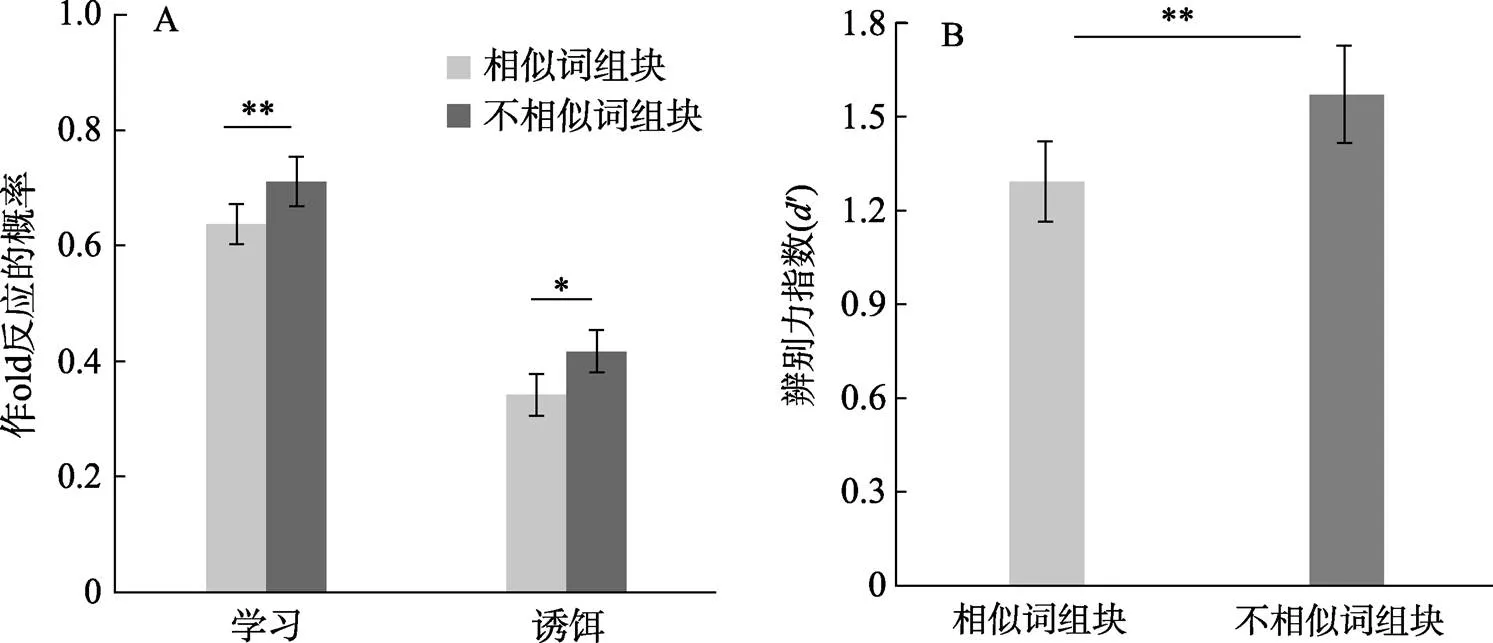
圖4 實驗2兩種學習條件的擊中率、錯誤記憶率(A)和辨別力指數(B)。
最后, 為了探討不相似詞組塊條件下誘餌詞的錯誤記憶率的上升是由于被試區分舊詞和誘餌詞的感受性降低還是由于判斷標準的降低引起的, 進一步使用配對樣本t檢驗考察了兩種學習條件下被試區分舊詞和誘餌詞的辨別力指數和判斷標準的差異。結果發現, 在辨別力指數上, 相似詞組塊和不相似詞組塊條件的辨別力指數分別為0.86和0.89, 兩者沒有差異,(21) = ?0.32,= 0.75。在判斷標準上, 相似詞組塊條件的判斷標準(= 1.36)顯著高于不相似組塊條件的判斷標準(= 0.89),(21) = 2.51,= 0.020,= 0.53, 95% CI [0.08, 0.86]。該結果說明, 不相似詞組塊條件下誘餌詞的錯誤記憶率的上升是因為被試在不相似詞組塊條件下區分舊詞和誘餌詞的判斷標準較為寬松, 更傾向于將誘餌詞判斷為舊詞。
4.4 討論
實驗2使用錯誤記憶范式(Roediger & Mcdermott, 1995; Sanchez & Naylor, 2018; Ye et al., 2016)對不相似詞組塊方式對相似詞記憶的促進機制進行了探討。結果發現, 與相似詞組塊方式相比, 被試在不相似詞組塊方式下對學習材料的擊中率和辨別力指數更高, 同時誘餌詞的錯誤記憶率也更高。該結果說明, 不相似詞組塊方式對相似詞記憶效果的提升并不是通過增強單個學習材料的特異性記憶, 而是通過增強相似詞組的共同詞根的記憶而實現的。
實驗2的結果首先重復了實驗1的結果。具體而言, 與實驗1的結果一致, 實驗2發現與相似詞組塊方式相比, 不相似詞組塊方式促進了相似詞的記憶效果, 并且這種優勢可以長期保持。更為重要的是, 實驗2通過使用錯誤記憶范式, 加入與學習材料非常相似的誘餌刺激, 對不相似詞組塊方式對相似詞記憶的促進機制進行了探究。結果發現, 相比于相似詞組塊條件, 不相似詞組塊方式同時提升了學習材料的擊中率和相似誘餌詞的錯誤記憶率, 且不相似詞組塊方式對誘餌詞的錯誤記憶率提升是由于個體區分舊詞和誘餌詞的判斷標準降低引起的, 即在不相似組塊條件下更傾向于將誘餌詞判斷為舊詞。如前言所述, 依據模糊痕跡理論(Reyna & Brainerd, 1995), 實驗2的結果直接說明不相似詞組塊方式對相似詞記憶的促進效應是通過增強相似詞組的共同詞根的籠統記憶而實現的。
值得說明的是, 實驗1和實驗2都是使用可發音的英文非詞為材料。由于本研究中所有被試均為大學生, 都接受過不少于10年的正規英語學習, 所以對于他們而言, 這些英文非詞除在視覺上相似外, 還在語音上存在很大的相似性。前人研究也發現, 視覺相似性和語音相似性都會對詞匯學習產生影響(Saito et al., 2008)。然而前人關注的都是熟悉文字的詞匯學習, 而在新的文字的詞匯學習過程中, 到底是語音相似性起作用還是視覺相似性起作用仍不清楚, 換而言之, 不相似詞組塊方式對新文字的相似詞記憶的促進作用是發生在字形層面還是語音層面尚不清楚。為了回答該問題, 實驗3以陌生韓字為材料, 進一步探討學習材料組塊方式對相似詞記憶的影響。
5 實驗3:語音相似性對學習材料組塊效應的影響
5.1 實驗目的
使用陌生韓字為實驗材料, 探討學習材料組塊方式對相似詞匯記憶的影響。
5.2 實驗方法
5.2.1 被試
26名母語為漢語的在校大學生(男8名), 年齡18~26歲, 平均年齡19.38 ± 1.76歲, 所有被試皆為右利手, 視力或矯正視力正常, 無任何韓語學習經驗, 此前均未參加過本研究的前三個實驗, 實驗結束后, 每個被試會得到相應的報酬。
5.2.2 實驗材料
相比于英文非詞, 韓字在空間頻率和結構上更加復雜, 因而記憶難度更大。為了防止產生地板效應, 實驗3選取的實驗材料數量少于前三個實驗。實驗材料包含132個3~11筆畫、3部件的韓字, 其中學習材料64個, 填充刺激68個。實驗3選取單個韓字作為詞匯記憶的材料主要基于兩方面考慮。一方面, 實驗被試的母語均為漢語, 漢語中存在很多單字詞(陳嘉映, 2007; 李敏, 2015), 因而對這些被試而言, 單個韓字也可以視作詞; 另一方面, 韓字的記憶難度較大, 使用單字能夠很大程度上降低陌生材料的記憶難度。
與實驗1A類似, 學習材料分為數量相等的兩組, 分別用于兩種組塊條件。兩組學習材料在視覺復雜性上匹配, 筆劃數分別為8.69和8.72, 部件數同為3。每組學習材料包含8個相似韓字詞組, 每個詞組由4個相似的韓字組成。每個詞組內的4個相似韓字兩兩之間共享2個部件, 且結構相同。填充刺激中4個刺激置于學習序列的首尾用于排除首因和近因效應, 另外64個作為再認記憶測查中的填充刺激。為了降低實驗材料記憶判斷的難度, 所有的填充刺激均與學習材料最多共享1個部件。
5.2.3 實驗程序
(1)學習階段
在學習階段, 被試需要學習64個韓字。與實驗1A類似, 學習任務包含兩種條件:相似詞組塊條件和不相似詞組塊條件。每種學習條件包含32個刺激, 兩種學習條件的學習材料在被試間平衡。每個刺激呈現2次, 兩次呈現之間間隔1~4個其它刺激。每個刺激呈現3 s, 刺激消失后呈現1~3 s (平均2 s)的注視點。被試的任務是認真看屏幕上出現的刺激, 并努力記住它。在學習任務完成后, 被試需要完成一個與實驗1A相同的數學等式判斷任務, 用于防止被試在學習后刻意回憶學習過的詞匯。
(2)再認記憶測查階段
如前所述, 韓字的記憶難度較大。為了防止出現地板效應, 實驗3選擇設置較短的學習?測查間隔, 即1小時。1小時的學習?測查間隔可以確保實驗3與實驗1A在學習?測查間隔上具有可比性。在再認記憶測查任務中, 128個韓字以隨機順序依次呈現, 其中64個刺激來源于學習階段, 另外64個是被試在學習階段未見過的。與前三個實驗相同, 被試需要在6點量表上按鍵判斷屏幕上出現的韓字是否在學習階段出現過。被試按鍵后刺激立即消失, 850 ms之后呈現下一個刺激。
5.2.4 數據分析
同實驗1A。
5.3 實驗結果
首先, 使用單樣本t檢驗對再認記憶測查的正確率進行分析(見表1), 發現被試的記憶正確率顯著高于概率水平(0.50),(25) = 10.17,< 0.001,= 1.99。該結果表明實驗3的被試在學習階段對學習材料進行了認真記憶, 且沒出現地板效應。
其次, 使用配對樣本t檢驗比較了兩種學習條件的擊中率、辨別力指數、反應時和高、低自信擊中率。如圖5、表2和表3所示, 相似詞組塊方式和不相似詞組塊方式的擊中率分別為0.79和0.80, 辨別力指數分別為0.70和0.76, 反應時分別為2286.98 ms和2441.74 ms, 高自信擊中率分別為0.49和0.48, 低自信擊中率分別為0.29和0.32。差異檢驗發現, 在擊中率、辨別力指數、反應時和高、低自信擊中率上, 兩種組塊條件之間均沒有顯著差異(擊中率:(25) = ?0.86,= 0.398; 辨別力指數:(25) = ?0.16,= 0.872; 反應時:(25) = ?0.84,= 0.409; 高自信擊中率:(25) = 0.24,= 0.815; 低自信擊中率:(25) = ?1.69,= 0.103)。
5.4 討論
實驗3以陌生韓字為實驗材料, 探討了學習材料組塊方式對視覺相似詞記憶的影響。結果發現, 無論是在擊中率上還是在辨別力指數上, 相似詞組塊方式與不相似詞組塊方式都沒有顯著差異。該結果說明, 不相似詞組塊不能促進只具備視覺相似性的相似詞的記憶。
本研究的前三個實驗使用英文非詞為實驗材料, 均發現了不相似詞組塊方式對相似詞記憶的促進作用。如實驗2的討論中所述, 對于中國大學生被試而言, 前三個實驗中使用的英文非詞的相似性不僅體現在視覺上, 而且還表現在語音上。為了分離視覺相似性和語音相似性的作用, 實驗3以中國被試不會發音的陌生韓字為實驗材料, 探討了學習材料組塊方式對純字形相似詞記憶的影響。結果發現, 不相似詞組塊方式不能促進只具備視覺相似性的相似詞的記憶。綜合實驗1A和實驗3的結果說明, 不相似詞組塊方式對相似詞記憶的促進作用可能依賴于學習材料的語音相似性。這一結果與前人結果一致, 即語音相似性在詞匯記憶中可能起重要作用, 語音不相似項目記憶成績好于語音相似項目(李軒, 劉思耘, 2012)。
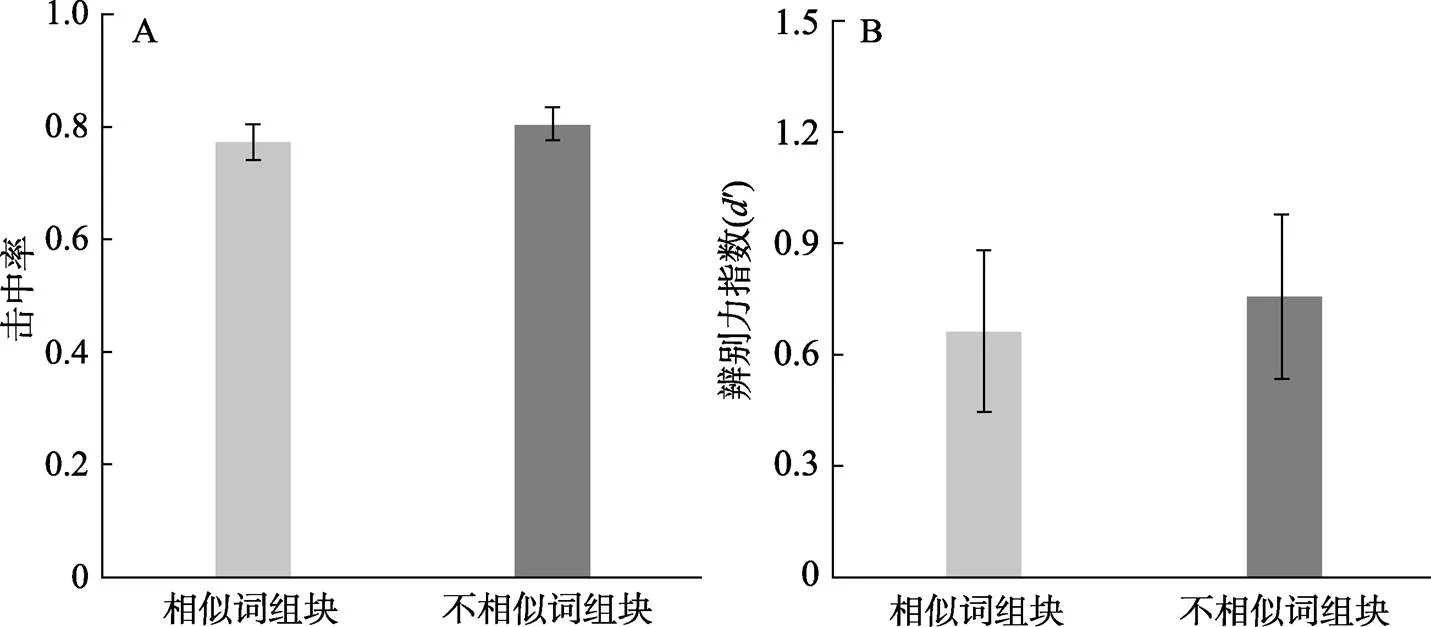
圖5 實驗3兩種學習條件的擊中率(A)和辨別力指數(B)。
6 總討論
本研究采用學習?測查范式, 探討了學習材料組塊方式對陌生相似詞長時記憶的影響。實驗1和2的結果均發現, 不相似詞組塊條件下相似詞的記憶成績優于相似詞組塊條件, 即不相似詞組塊方式能促進相似詞的長時記憶, 并且這種促進效應能夠長時保持。該結果一方面驗證了前人研究關于不相似詞的記憶優勢效應的研究發現(Avons, 1999; Saito et al., 2008)。更為重要的是, 與前人研究基于不相似材料與相似材料的對比而發現的不相似詞記憶優勢不同(Logie et al., 2000; Logie et al., 2016), 本研究發現, 當兩組學習材料同為相似詞時, 不相似詞組塊相比于相似詞組塊能促進相似詞的記憶。該結果說明學習材料的組塊方式會影響相似詞的記憶。
本研究還發現在陌生文字的相似詞的記憶中, 語音相似性表現出比字形相似性更為重要的作用。本研究以英文非詞和韓字為學習材料。對于中國大學生被試而言, 由于他們具有十多年的英文學習經驗, 所以本研究中使用的可讀的英文非詞材料在視覺和語音上都表現出相似性, 而韓字材料對于中國被試而言沒有語音, 所以只在視覺上表現出相似性。結果發現, 當學習材料在視覺和語音上都相似時(實驗1和2中可讀的英文非詞), 不相似詞組塊方式相比于相似詞組塊方式表現出記憶優勢; 而當學習材料僅在視覺上相似時(實驗3中陌生韓字), 兩種組塊方式之間沒有顯著差異。該結果說明, 不相似詞組塊對陌生相似詞長時記憶的促進作用可能需要依賴于語音相似性。與此一致, 以往關于不相似詞和相似詞短時序列記憶差異的研究也一致地發現, 語音相似性對于詞匯的短時記憶具有重要的作用(李軒, 劉思耘, 2012; Saito et al., 2008)。本研究未發現視覺相似性對相似詞記憶的作用至少存在兩方面的可能性。一方面, 視覺相似性的作用可能會受到詞匯相似性程度的調節。已有研究發現, 當詞表內詞匯之間的相似性較低時(詞表內部分詞匯相似), 語音相似性和視覺相似性在詞匯記憶中都會起作用(Lin et al., 2015; Saito et al., 2008); 而當詞匯之間的相似性較高時(詞表內所有詞匯都相似), 語音相似性對詞匯記憶起主要作用, 視覺相似性的作用不明顯(李軒, 劉思耘, 2012)。由于本研究選用的詞表內所有詞匯之間都相似, 即相似性程度較高, 所以沒有發現視覺相似性的作用。另一方面, 由于本研究中的陌生韓字材料不具有語音, 所以無法排除視覺相似性在不相似詞組塊效應中單獨起作用的可能性, 即無法排除不相似詞組塊促進視覺相似而語音不相似詞記憶的可能性。未來研究需要加入字形相似而語音不相似的陌生詞匯作為學習材料, 對上述可能性進行進一步探討。
更為重要的是, 本研究還探明了不相似詞組塊方式對相似詞記憶的促進作用的機制。本研究發現相比于相似詞組塊方式, 不相似詞組塊方式對相似詞的長時記憶具有促進作用。如前所述, 依據模糊痕跡理論(Reyna & Brainerd, 1995), 本研究發現的不相似詞組塊相對于相似詞組塊的記憶優勢既可能是因為不相似詞組塊方式增強了相似詞中共同詞根的籠統記憶, 也可能是因為不相似詞組塊方式提高了單個詞匯的細節性信息記憶。本研究的實驗2使用錯誤記憶范式對上述兩種可能性進行了區分(Roediger & Mcdermott, 1995; Ye et al., 2016)。實驗結果發現, 不相似詞組塊方式在促進相似詞記憶的同時也提高了相似誘餌刺激的錯誤記憶。該結果說明, 不相似詞組塊方式對相似詞記憶效果的提升并不是通過增強單個學習材料的細節性信息的記憶, 而是通過增強相似詞組的共同詞根的籠統記憶而實現的。與此一致, 腦成像研究發現相似陌生詞匯的連續呈現會引起腦活動的抑制效應(Glezer et al., 2009; Glezer et al., 2015)。因此, 學習者在相似詞組塊條件下記憶編碼腦區的活動強度低于不相似詞組塊條件。換句話說, 與不相似詞組塊相比, 學習者在相似詞組塊條件下會降低記憶編碼腦區在共同詞根編碼時的參與程度, 因而表現出較低的記憶成績。
此外, 本研究還嘗試分離了學習材料組塊方式對再認記憶中熟悉性和回想的影響。如前所述, 與低自信判斷的學習項目相比, 高自信判斷的學習項目在記憶提取時包含更多回想過程(Squire et al., 2007)。通過區分不同自信水平的組塊方式效應, 實驗1和實驗2一致地發現兩種組塊條件只在高自信 擊中率上表現出差異, 而在低自信擊中率上不存在差異。該結果說明, 學習材料組塊方式可能主要影響基于回想的再認記憶。盡管如此, 由于高自信判斷的學習項目的提取同時包含回想和熟悉性過程(Squire et al., 2007), 所以本研究通過高低自信記憶成績的比較無法完全排除學習材料組塊方式會影響基于熟悉性的再認記憶的可能性。因此, 該結果還需進一步使用回憶與再認記憶的比較、記住/知道范式等多種分離熟悉性和回想的實驗范式進行驗證(Smith et al., 2011; Squire et al., 2007)。
值得注意的是, 因為實驗1發現在不同學習?測查間隔條件下(1小時和1周), 材料組塊方式效應都穩定存在, 所以在實驗2和實驗3中, 只設置了一種學習?測查間隔條件。具體來說, 實驗2的學習?測查間隔為1周, 實驗3的學習?測查間隔為1小時。雖然實驗1的結果說明材料組塊方式效應不會受到學習?測查間隔的影響, 但是三個實驗在學習?測查間隔上差異仍存在影響實驗結果的可能性。未來研究需要使用完全一致的學習?測查間隔, 進一步驗證該研究的結果。
本研究關于學習材料不相似詞組塊方式促進相似詞記憶的發現對于語言學習和教學具有重要的實踐意義。詞匯學習對于個體的語言習得具有舉足輕重的作用(梅磊磊, 屈婧, 李會玲, 2017)。由于字形、語音和語義相似的詞匯之間容易相互混淆, 所以人們在學習時表現出極大困難。本研究發現, 學習材料組塊方式的改進可能是有效促進相似詞學習和記憶的有效途徑之一。具體而言, 與相似詞組塊學習相比, 不相似詞組塊學習能夠促進相似詞的記憶。因此, 為了更為高效地掌握相似詞匯, 學習者應在學習過程中更多使用不相似詞組塊學習的方式。
7 結論
本研究采用學習?測查范式, 探討了學習材料組塊方式對相似詞記憶的影響, 結果發現:1)相比于相似詞組塊方式, 不相似詞組塊方式能夠促進陌生相似詞匯的記憶, 并且這種促進效應能夠長時保持, 說明不相似詞組塊方式是促進相似詞記憶的有效途徑之一; 2)不相似詞組塊方式對陌生文字中相似詞的記憶的促進作用可能依賴于語音相似性; 3)不相似詞組塊方式的促進效應是通過增強相似詞的共同詞根的記憶而實現的。
Avons, S. E. (1999). Effects of visual similarity on serial report and item recognition.(1), 217–240.
Balota, D. A., Yap, M. J., Hutchison, K. A., Cortese, M. J., Kessler, B., Loftis, B., … Treiman, R.. (2007). The English lexicon project.(3), 445–459.
Chen, J. Y. (2007). Formulas and the definition of “word” in the Chinese language.(5), 1–7.
[陳嘉映. (2007). 約定用法和“詞”的定義.(5), 1–7.]
Cohen, J. (1988).. L. Erlbaum Associates.
DeAnda, S., Poulin-Dubois, D., Zesiger, P., & Friend, M. (2016). Lexical processing and organization in bilingual firstlanguage acquisition: Guiding future research.(6), 655–667. doi:10.1037/bul0000042
Gallo, D. A. (2010). False memories and fantastic beliefs: 15 years of the DRM illusion.(7), 833–848. doi:10.3758/MC.38.7.833
Gilbert, A. C., Boucher, V. J., & Jemel, B. (2014). Perceptual chunking and its effect on memory in speech processing: ERP and behavioral evidence., 220. doi:10.3389/fpsyg.2014.00220
Glezer, L. S., Jiang, X., & Riesenhuber, M. (2009). Evidence for highly selective neuronal tuning to whole words in the "visual word form area".(2), 199–204. doi:10. 1016/j.neuron.2009.03.017
Glezer, L. S., Kim, J., Rule, J., Jiang, X., & Riesenhuber, M. (2015). Adding words to the brain's visual dictionary: Novel word learning selectively sharpens orthographic representations in the VWFA.(12), 4965–4972. doi:10.1523/JNEUROSCI.4031-14.2015
Li, M. (2015). A new exploration on the definition of modern Chinese word.208–210.
[李敏. (2015). 關于現代漢語詞的定義新探.208–210.]
Li, X. & Liu, S. Y. (2012). The effects of phonological similarity and visual similarity in immediate serial recall of Chinese characters.(12), 1571–1582. doi:10.3724/sp.j.1041.2012.01571
[李軒, 劉思耘. (2012). 漢語短時序列回憶中的語音相似性和視覺相似性效應.(12), 1571–1582.]
Lin, Y. C., Chen, H. Y., Lai, Y. C., & Wu, D. H. (2015). Phonological similarity and orthographic similarity affect probed serial recall of Chinese characters.(3), 538–554. doi:10.3758/s13421-014-0495-x
Logie, R. H., Della Sala, S., Wynn, V., & Baddeley, A. D. (2000). Visual similarity effects in immediate verbal serial recall.(3), 626–646.
Logie, R. H., Saito, S., Morita, A., Varma, S., & Norris, D. (2016). Recalling visual serial order for verbal sequences.(4), 590–607. doi:10.3758/s13421- 015-0580-9
Mei, L., Qu, J., & Li, H. L. (2017). The cognitive neural mechanism of second language learning.(6), 63–73.
[梅磊磊, 屈婧, 李會玲. (2017). 第二語言學習的認知神經機制.(6), 63–73.]
Mei, L., Xue, G., Chen, C. S., Xue, F., Zhang, M. X., & Dong, Q. (2010). The "visual word form area" is involved in successful memory encoding of both words and faces.(1), 371–378. doi:10.1016/j.neuroimage.2010. 03.067
Nairne, J. S. (1990). A feature model of immediate memory.(3), 251–269.
Piguet, O., Connally, E., Krendl, A. C., Huot, J. R., &Corkin, S. (2008). False memory in aging: Effects of emotional valence on word recognition accuracy.(2), 307–314. doi:10.1037/0882-7974.23.2.307
Poirer, M., Saint-Aubin, J., Musselwhite, K., Mohanadas, T., & Mahammed, G. (2007). Visual similarity effects on short-term memory for order: The case of verbally labeled pictorial stimuli.(4), 711–723.
Qu, Z. & Ding, Y. L. (2010). The effect of Chinese phonological association on false memory.(2), 193–199.
[曲折, 丁玉瓏. (2010). 漢字語音關聯對錯誤記憶的影響.(2), 193–199.]
Qu, Z., Liu, Y., & Bi, Y. H. (2010). The effect of Chinese orthographic association on false memory.(2), 146–153.
[曲折, 劉優, 畢耀華. (2010). 漢字字形關聯對錯誤記憶的影響.(2), 146–153.]
Reyna, V. F. & Brainerd, C. J. (1995). Fuzzy-trace theory: An interim synthesis.(1), 1–75.
Roediger, H. L. & Mcdermott, K. B. (1995). Creating false memories: Remembering words not presented in lists.(4), 803–814.
Rugg, M. D. & Yonelinas, A. P. (2003). Human recognition memory: A cognitive neuroscience perspective.(7), 313–319. doi:10.1016/s1364- 6613(03)00131-1
Saito, S., Logie, R. H., Morita, A., & Law, A. (2008). Visual and phonological similarity effects in verbal immediate serial recall: A test with kanji materials.(1), 1–17. doi:10.1016/j.jml.2008.01.004
Sanchez, C. A. & Naylor, J. S. (2018). Disfluent presentations lead to the creation of more false memories.(1), e0191735. doi:10.1371/journal.pone.0191735
Smith, C. N., Wixted, J. T., & Squire, L. R. (2011). The hippocampus supports both recollection and familiarity when memories are strong.(44), 15693–15702. doi:10.1523/JNEUROSCI.3438-11.2011
Smyth, M. M., Hay, D. C., Hitch, G. J., & Horton, N. J. (2005). Serial position memory in the visual-spatial domain: Reconstructing sequences of unfamiliar faces.(5), 909–930.
Squire, L. R., Wixted, J. T., & Clark, R. E. (2007). Recognition memory and the medial temporal lobe: A new perspective.(11), 872–883. doi:10.1038/nrn2154
Wixted, J. T. & Mickes, L. (2010). A continuous dual-process model of remember/know judgments.(4), 1025–1054. doi:10.1037/a0020874
Xiao, H. R., Huang, Y. F., Gong, X. M., &Wang, D. H. (2015). Age alters the effects of emotional valence on false memory: Using the simplified conjoint recognition paradigm.(1), 19–28. doi: 10.3724/SP. J.1041.2015.00019
[肖紅蕊, 黃一帆, 龔先旻, 王大華. (2015). 簡化的聯合再認范式中情緒對錯誤記憶影響的年齡差異.(1), 19–28.]
Xue, H. L., Mei, L., Xue, G., Chen, C., & Dong, Q. (2017). The impact of learning method on unfamiliar visual form learning.(5), 1111–1116.
[薛紅莉, 梅磊磊, 薛貴, 陳傳升, 董奇. (2017). 學習方法對陌生語言字形學習的影響.(5), 1111–1116.]
Ye, Z. F., Zhu, B., Zhuang, L. P., Lu, Z. L, Chen, C. S., & Xue, G. (2016). Neural global pattern similarity underlies true and false memories.(25), 6792–6802. doi:10.1523/JNEUROSCI.0425-16.2016
Impacts of chunking strategy on memorising similar words
ZHANG Lei; LU Chengrou; LIN Junfeng; MEI Leilei
(Center for Studies of Psychological Application, School of Psychology, Guangdong Key Laboratory of Mental Health and Cognitive Science, South China Normal University, Guangzhou 510631, China)
The successful memorisation of similar words is critical for individuals’ vocabulary acquisition. Previous studies have found that individuals perform significantly better in an immediate serial memory test for dissimilar words than similar words. However, the memory advantage for dissimilar words in those studies was mainly based on the comparison of two sets of different learning materials (i.e., similar and dissimilar words). Therefore, whether similar words are memorised better in a similar chunking condition (similar words are successively presented) or dissimilar chunking condition (similar words are alternately presented by other dissimilar words) is unclear.
To address the above question, we performed four experiments in this study, in which within-subject design and study-test paradigm were used. Experiment 1A aims to explore the effects of chunking strategy on the memory of similar words. In this experiment, two matched sets of similar English pseudowords were used for the similar and dissimilar chunking conditions, respectively. In the similar chunking condition, similar words were successively presented, whereas in the dissimilar chunking condition, similar words were alternately presented with other dissimilar words. Participants were instructed to memorise the words during the study phase. A recognition memory test was administered one hour after the study phase. Experiment 1B aims to investigate the memory advantage of the dissimilar chunking condition for long-term retention. Experimental materials and tasks were the same with those of Experiment 1A, but the interval between study and test was prolonged to one week. Experiment 2 used Deese-Roediger-McDermott (DRM) paradigm to examine whether the dissimilar chunking strategy facilitated the memory of similar words by improving the memory of individual words or enhancing the memory of shared parts across similar words. Experiment 3 included unfamiliar Korean characters as materials to further disentangle the contributions of visual and phonological similarities on the memory of similar words.
Results show that: 1) Compared with the similar chunking strategy, the dissimilar chunking strategy show better memory performance on similar words, which can be maintained for at least one week. 2) The dissimilar chunking strategy improves the memory of similar words and results in a high false memory for similar lures. 3) The memory advantage for dissimilar chunking strategy is evident for phonologically similar words (i.e., English pseudowords) but not for visually similar words (i.e., Korean characters).
The results suggest that the dissimilar chunking strategy improves the memorisation of phonologically similar words by enhancing the memory of common parts across similar words. In other words, the dissimilar chunking strategy may be an effective way to improve the memorisation of similar words. These findings have important implications for language learning and education.
study-test paradigm; word memory; chunking strategy; similar words
10.3724/SP.J.1041.2019.00280
2018-05-07
* 國家自然科學基金項目(31771199), 廣東省普通高校創新團隊項目(人文社科) (2017WCXTD002)和廣東省普通高校哲學社會科學重點實驗室項目(2015WSYS009)資助。
梅磊磊, E-mail: mll830925@126.com
B842
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫藥(2020年34期)2020-12-09 01:22:24
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
作文周刊·小學一年級版(2016年27期)2017-06-03 23:21:17
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
新湘評論·下半月(2016年4期)2016-05-05 22:12:41
新湘評論·下半月(2016年4期)2016-05-05 22:12:41
