常識性知識和語篇語境對代詞指認的影響*
2019-03-05 02:12:18高約飛趙思敏王穗蘋
心理學報 2019年3期
吳 巖 高約飛 趙思敏 王穗蘋
?
常識性知識和語篇語境對代詞指認的影響
吳 巖高約飛趙思敏王穗蘋
(東北師范大學心理學院, 長春 130024) (華南師范大學心理學院, 廣州 510631)
本研究圍繞中文代詞理解中, 讀者的常識性知識和語篇語境的作用以及作用時程這一問題展開。實驗1首先探討在中文閱讀理解中, 職業性別傾向這種常識性信息是否能對代詞的指認產生早期影響。存在一致和沖突(如警衛?他; 警衛?她)兩個實驗條件, 結果在凝視時間、重讀時間和總閱讀時間上都發現了職業性別傾向所引發的性別沖突效應。實驗2在實驗1基礎上增加一個代詞(如:警衛?他?他; 警衛?她?她), 考察更正后的信息, 即文本語境內容是否可以覆蓋常識的作用對代詞加工產生影響。結果發現語篇語境確實可以覆蓋常識性信息的作用, 對代詞加工產生早期影響。但是, 職業性別傾向這種常識性知識仍然在代詞加工的后期階段發揮作用。考慮到代詞所形成的語境較為含蓄, 實驗3中采用更明確的方式來界定職業名稱的性別, 例如男藝人、爸爸等, 然后再出現一個代詞, 代詞的性別始終和先前的性別描述一致, 而與職業性別傾向沖突, 這樣也存在一致和沖突兩個條件(例如:保姆?妻子?她, 警衛?妻子?她), 結果發現只有更正后的語境信息對代詞加工產生影響, 職業性別傾向不再發揮作用。說明在中文這種高語境依賴性的語言文字中, 語境可以覆蓋常識性知識對代詞加工產生早期作用。但是, 語境作用的持續性問題會受到語篇語境中性別信息明確程度的影響。
代詞; 語境; 常識性知識; 職業性別傾向
1 前言
代詞是一種具有特定功能和特殊地位的詞匯, 代詞的加工是語言理解中不可缺少的組成部分, 確定代詞的所指是保持句子乃至語篇連貫性的重要環節。所以對代詞解決過程的探討一直是心理語言學家所關心的問題(Garnham, 2001, a review)。作為一種代替人或事物的名稱, 代詞所攜帶的語義信息有限(Esaulova, Reali, & von Stockhausen, 2014)。但通常情況下, 代詞會顯示出一定的性別(中文中的“他”和“她”)和數(單復數)的區別。因此, 以往很多研究在探討代詞加工過程時, 都圍繞著代詞的性別和數量展開, 通過造就先行詞性別、性別傾向或數量與代詞的不一致性, 對代詞的加工過程以及影響因素進行研究(Canal, Garnham, & Oakhill, 2015; Duffy & Keir, 2004; Esaulova et al., 2014; Kennison & Trofe, 2003; Qiu, Chen, & Wang, 2012; Qiu, Swaab, Chen, & Wang, 2012; Xu, Jiang, & Zhou, 2013)。例如, 以往研究發現, 先行詞的數量信息、生物性別(如:爸爸?她)都可以影響到代詞的加工(Canal et al., 2015; Xu et al., 2013); 此外, 先行詞的性別刻板印象(如:警衛?她)也會影響到代詞的指認過程(Duffy & Keir, 2004; Esaulova et al., 2014; Qiu et al., 2012)。
但是, 值得注意的是, 在代詞指認過程中, 數量或生物性別違背和性別刻板印象違背并不是一回事, 前者是不可協調、不可整合的; 而后者是可以協調、可以整合的。性別刻板印象是讀者在生活中獲得的常識性知識, 并不一定是正確的。例如, 警衛雖然極有可能是男性, 但是并不必然是男性, 也有可能是女性。因此當讀者讀到“警衛匆忙地攔下正要進來的出租車, 因為她需要檢查證件”時, 雖然會產生加工困難, 但是讀者可以從代詞“她”中推測出警衛是一名女性, 從而將之前讀到的信息進行整合。
可以說, 在這里, 代詞“她”的第一次出現事實上構成了一種語境, 揭示了語言材料中其所指代人物的真正性別。那么, 在一個較長的語段里, 讀者很有可能第二次遇見代詞“她”。比如, 讀完前面一句“警衛匆忙地攔下正要進來的出租車, 因為她需要檢查證件”之后, 假設讀者又讀到以下部分“這是臺里的規定, 這也是她的工作, 所有來訪人員都必須遵守”。在這一部分里, 讀者會遇到第二個代詞“她”。此時, 將有兩種對立的因素會影響到代詞的加工, 由于代詞指代的仍是警衛, 關于警衛是男性這一性別刻板印象仍有可能使讀者對代詞的加工發生困難; 與此同時, 第一個代詞所提供的“對錯誤的職業名稱性別傾向進行更正的信息”, 又可以促進代詞的加工。那么在這兩種信息同時存在時, 讀者將會如何對代詞進行加工呢?這事實上關系到不同類型的語義知識, 如語言材料所提供的語義信息以及讀者相關的常識性知識, 如何影響到當前信息的加工這一問題。
以往研究關于更新后的信息是否可以取代讀者頭腦中固有的信息, 對當前詞匯的加工產生更快且持續的作用, 不同的理論存在著不同的觀點。來自兩階段加工模型認為, 讀者對當前代詞的加工是分兩階段完成的, 更新后的信息確實可以對當前的詞匯加工產生作用, 但是要在代詞加工的晚期階段才會發揮作用。例如, Kintsch的建構整合模型(Construction-Integration Model, 1988)認為, 對當前信息的理解加工可以分成建構和整合兩個階段。在早期建構階段, 讀者原有的一些觀念首先被激活參與到當前目標加工中, 而語篇的語境信息要到整合階段才會發揮作用。Garrod和Terras的捆綁消解模型(Bonding-Resolution Model, 2000)認為閱讀理解的早期階段是一個自動化、低水平的加工過程。在此加工階段, 通過低水平的匹配機制, 與當前信息有語義聯系的信息首先被激活; 晚期階段為高級加工過程, 在這一階段, 讀者會根據語篇的語境信息對在早期階段形成的匹配做出評價。與兩階段理論相反, 另一種觀點則認為閱讀理解中詞匯的加工是通過一個階段就可以完成的, 語境可以和常識、語義這種低水平的信息一樣, 對當前詞匯加工產生即時性影響。例如, Hess, Foss和Carroll (1995)詞匯再解釋模型(Lexical Reinterpretation Model)認為讀者會根據句子或語篇語境對詞匯的語義進行再解釋, 為了確保句子或語篇信息的連貫性, 只有解釋后的信息才會對當前的詞匯加工產生影響。
承接以上理論爭端, 已有一些研究對這一問題進行了探討(Duffy & Keir, 2004; Cook & Myers, 2004; Garrod & Terras, 2000; Nieuwland & Van Berkum, 2006b)。但是, 這方面的研究來自代詞加工的證據較少, 比較有代表性的一篇研究來自Duffy和Keir (2004)。研究者采用眼動技術, 在反身代詞的加工中探討了語境和常識的作用。眼動法可以實時監控讀者的閱讀過程, 眼動中用來測量時間的指標“注視時間”可以為不同的加工階段提供有效的證據(Rayner & Pollatsek, 1989)。例如, 首次注視時間(first fixation duration)和凝視時間(gaze duration)通常是反映詞匯早期加工的重要指標(Kliegl, Grabner, Rolfs, & Engbert, 2004), 首次注視時間指在首次通過閱讀中某一興趣區內的首個注視點的注視時間; 凝視時間又稱為第一遍閱讀時間, 指從首次注視點開始到注視點首次離開當前興趣區之間的持續時間。重讀時間(second reading time)指所有回視到當前興趣區的注視時間之和, 是反映詞匯后期加工過程的重要指標(Inhoff & Liu, 1998)。
Duffy和Keir (2004)以反映詞匯早期和晚期加工階段的眼動指標凝視時間和重讀時間為標準, 測量了常識和語境的效應。他們給被試呈現如下材料, 同時記錄被試的眼動軌跡:
The electrician taughta lot.
結果發現在單獨給被試呈現上面材料時, 沖突條件下讀者對凝視時間和重讀時間都更長。但當前面先出現“electrician is a cautious woman.”這樣的信息后, 讀者對的加工無論是在凝視時間還是在重讀時間上, 一致和沖突條件下兩者差異都不再顯著。說明語言材料所提供的信息已經完全覆蓋了常識性知識, 對代詞加工產生了即時且持續的影響, 這種結果為Hess等(1995)提出詞匯再解釋模型提供了證據。
然而, 除此之外, 目前并沒有發現其他將常識和語境結合起來, 探討兩者對代詞作用的文章。有單獨探討常識對代詞作用的文章, 如先前提及的關于先行詞性別刻板印象對代詞作用的研究(Duffy & Keir, 2004; Esaulova et al., 2014; Kennison & Trofe, 2003; Qiu et al., 2012); 也有單獨探討語境作用的文章(Chen, Cheung, Tang, & Wong, 2000; Nieuwland & Van Berkum, 2006a), 但將兩者結合起來的研究較少。可見, 關于語境和常識同時作用下, 對詞匯加工情況的探討, 來自代詞加工的研究證據非常有限。
然而我們又不能簡單地將非代詞加工和代詞加工混為一談, 這是因為代詞加工和其他詞匯, 甚至于其他類型的替代詞(如這個人)加工都存在區別(Crocker, Pickering, & Clifton, 2000; Esaulova et al., 2014)。Esaulova等(2014)認為由于代詞攜帶的語義信息有限, 所以遇到代詞, 讀者需要立即確定代詞的所指, 才能保證句子乃至篇章內容的連貫; 而其他詞匯則不同, 他們含有豐富的語義信息, 很多情況下不必要立即和前語境聯系起來, 就可以完成對當前內容的理解(Esaulova et al., 2014; p798)。這就導致先行詞乃至句子語篇語境所提供的信息在代詞和其他類型詞匯加工中所產生的作用不同。在Esaulova等研究中, 研究者發現先行詞所攜帶性別信息對代詞的影響早于對其他類型替代詞的作用。
此外, 這方面的研究尚缺乏來自中文的研究證據, 中文和英文相比, 具有很多獨特的性質。書面漢語的特點被概括為高度語境依賴性(Chen et al., 2000; Wang, Chen, Yang, & Mo, 2008), 表現為中文里單個漢字的意思比較模糊, 在很多情況下, 單字的字義必須依賴上下文才能確定。即使是意義相對較單純的代詞, 如他, 可能是單數的第三人稱, 但也可能是構成其他詞匯的一個語素, 如“其他、他鄉、排他”, 這里的他并不指具體某個對象, 也因而不需要讀者去解決他所指的對象。相比之下, 大部分西方的語言, 如英語的詞匯與詞匯之間有固定的間隔, 詞匯的意義具有相當高的透明度, 詞的意義一般不會隨著前后詞義的改變而變化。中文的這一特點將會如何影響到語境對代詞的加工呢?一種可能是, 由于上下文的信息要常常被用來確定字詞的意義, 因而語境的作用也許會更快或更強; 然而, 另一種可能性是因為漢字的字詞意義通常較為模糊, 因而更多的加工資源將被用于確定字詞的含義, 從而使語境信息的利用更為延遲。總體來說, 盡管不少研究者認為, 相比于語法結構等因素, 語義因素對成功地理解書面漢語起著相當重要的作用, 然而, 遺憾的是, 與這種重要性相比, 卻鮮有研究集中去探討不同類型的語義因素, 例如語境和常識, 分別是如何起作用的。
正是基于上述考慮, 我們采用較為敏感的眼動技術, 分三個實驗探討中文代詞加工里語境與常識性知識對代詞的作用和作用進程。實驗1首先檢驗在中文閱讀理解中, 職業性別傾向這種常識性信息是否能對代詞的指認產生早期影響。實驗1的材料中會出現一個代詞, 按照代詞的性別和職業性別傾向的關系, 形成一致和沖突兩個版本(例:警衛?他, 警衛?她)。實驗2的材料在實驗1的基礎上, 增加一個代詞, 兩個代詞總是保持一致, 同樣有一致和沖突兩個版本(例:警衛?他?他, 警衛?她?她)。對于第二個代詞來說, 第一個代詞所提供的性別, 形成了一種與常識性知識相違背的語境。因此, 可以用于考察當語境提供的信息對錯誤的常識性知識進行更正的情況下, 語境和常識性知識如何對其后的代詞加工產生影響的。由于在實驗2里, 主角的性別是通過代詞確定的, 這種性別提示相對比較含蓄。因此在實驗3里, 將進一步對主角的性別做出外顯而明確的描述, 例如男藝人、爸爸等, 然后再出現一個代詞, 代詞的性別始終和先前的性別描述一致, 這樣也存在一致和沖突兩個版本(例如:保姆?妻子?她, 警衛?妻子?她)。以進一步考察當語境所提供的性別信息清楚而明確時, 代詞加工又將如何受常識性知識與語境信息的影響。
2 實驗1:職業的性別傾向對代詞加工的影響
考察職業的性別傾向對代詞加工的影響。根據以往研究結果, 我們預期性別傾向可以影響代詞加工, 并在代詞加工的早期階段發揮作用。
2.1 研究方法
2.1.1 被試
根據參考文獻(Anderson, Kelley, & Maxwell, 2017; Taylor & Muller, 1996)設置先驗效果量值為0.8,采用軟件GPower 3.1版本(http://www.gpower.hhu.de/)計算出計劃被試量為24人。實際收集被試25名, 所有被試裸視或矯正視力正常, 母語均為漢語, 無閱讀障礙。刪除3名回答問題的正確率小于75%的被試, 有效被試22名, 男女各半。
2.1.2 實驗設計和材料
采用單因素被試內設計, 自變量為一致性, 有兩個水平, 代詞和職業名稱的性別傾向一致或沖突。首先對職業名稱的性別傾向性進行等級評價, 找出具有性別傾向性的職業名稱用于編寫實驗材料, 以確保職業名稱和代詞確實構成一致或沖突的關系。要求32名不參加正式實驗的某高校學生對80個職業名稱的性別傾向性進行評定。共有1~7評定等級, 其中一半被試的問卷里1代表極有可能是女性, 7代表極有可能是男性; 另一半被試的問卷里評價等級正好相反。數據分析時標準統一, 1代表極有可能是男性, 7代表極有可能是女性。根據平均評價等級, 選出20個具有強男性傾向的職業名稱(= 2.13;= 0.40)和20個具有強女性傾向的職業名稱(= 5.58;= 0.40)。獨立樣本t檢驗結果表明兩者差異顯著,(38) = 23.99,< 0.001。
根據篩選出來具有性別傾向的職業名稱編寫實驗材料, 每個語篇由5句話組成, 首句中出現職業名稱, 接下來是兩個過渡句, 然后是目標句, 目標句中會出現目標代詞, 最后是結語。實驗材料按照代詞的性別線索和職業名稱的性別傾向可以分為一致和沖突兩個版本, 例句如下:
一致條件:今天晚上有一個重要演出, 可是現在頭卻痛得厲害, 于是便走到后臺休息。但發現后臺一片混亂, 根本沒有休息的地方。
沖突條件:今天晚上有一個重要演出, 可是現在頭卻痛得厲害, 于是便走到后臺休息。但發現后臺一片混亂, 根本沒有休息的地方。
按照句子主題和兩種實驗條件進行拉丁方平衡, 構成兩個系列的實驗材料, 每一系列包含40個實驗材料, 每一被試只接受每個語篇的一種條件。在每一系列的實驗材料中又加入26個填充語篇, 語篇的結構和實驗材料類似。所以每一系列共包含66個語篇。
2.1.3 實驗程序
被試隨機接受兩個實驗系列中的一個, 個別施測。完成實驗大約需要40分鐘。眼動儀是SR-Research公司開發的EyeLink II, 采樣率為500次/秒, 被試眼睛注視和運動情況通過頭盔上兩個微型紅外攝像機輸入電腦, 我們只記錄被試右眼數據。顯示器屏幕與被試眼睛的距離大約是75 cm, 屏幕刷新率為150 Hz。所有材料以34號楷體呈現, 每個漢字大小為0.95 cm × 0.95 cm, 相鄰漢字之間有0.25 cm的距離, 這樣每個漢字大約形成0.73視角。
每段實驗開始前都需要進行校準以保證被試眼動軌跡記錄的精確性。每次校準都包括校對(calibration)、效度檢驗(validation)和漂移修正(drift correction)。在校對過程中, 九個校準點(白色小圓點)會依次隨機出現在屏幕中心或四周。當校準點出現時, 要求被試注視該點, 直至該點消失。校對之后是效度檢驗, 仍然出現九個校準點, 程序和校對一樣。如果效度檢驗成功, 則進行一次漂移修正, 一個校準點會隨機地出現在屏幕的中心或四周, 要求被試注視它。
校準成功后方可進入正式實驗。66個語篇分22組呈現, 每三篇為一組。具體的實驗流程圖如圖1所示, 每組語篇呈現前有提示信息“第X組”, 接下來是實驗材料, 每個語篇以多行一屏的方式呈現在電腦屏幕上, 首行空兩格, 所有材料均是黑底白字。每組后都有一個閱讀理解題, 要求被試作“是”或“否”判斷, 以鼓勵被試仔細閱讀實驗材料。被試自己控制閱讀速度, 讀完一屏后按手柄任意鍵往下翻頁。計算機在呈現提示信息、語篇或問題之前, 都會再進行一次漂移修正以保證眼動記錄的精確性。也就是屏幕左上角出現一個校準點, 只有被試的注視點和校準點重合時校準點才會消失, 下一屏內容才會呈現。實驗之前有三組練習材料, 以熟悉實驗流程。

圖1 實驗流程圖
2.2 結果與分析
由于過長或過短的注視點被認為不能反映閱讀加工(Rayner, 1998), 因而將小于60 ms或大于600 ms的注視點刪除(Angele, Slattery, Yang, Kliegl, & Rayner, 2008; Qiu et al., 2012)。中文的單數人稱代詞由一個漢字構成, 同時人稱代詞的詞頻也較高, 因此, 本實驗發現代詞的略讀概率非常高, 首次略讀概率在70%以上, 這一點與漢語以往研究(Qiu et al., 2012)以及英文單數人稱代詞的狀況非常相似(Ehrlich & Rayner, 1983)。由于數據統計是建立在有注視點的漢字上, 高略讀率引發數據的大量缺失, 從而導致結果的可靠性降低。為了獲得更多的有效數據, 研究者往往將代詞與其左右一定范圍的語言刺激合并為一個興趣區來分析(Van Gompel & Majid, 2004; Qiu et al., 2012)。分析的區域包括代詞區和代詞后區。代詞區由代詞和其前后兩字構成(其中10個左右代詞前為標點符號), 代詞后區由代詞區后三個字組成。代詞后區主要考察可能出現的延遲效應或溢出效應。
數據分析時用到的指標有首次注視時間、凝視時間、重讀時間和總閱讀時間。前三個指標前言中有介紹, 總注視時間(total fixation duration)是指落在興趣區的所有注視點時間的總和, 該指標對較慢和較長時間的認知加工過程敏感(Kliegl et al., 2004)。因此基于此四項指標的分析結果, 我們可以獲知代詞早期、晚期以及總體加工的情況。在以下處理中,t均指以被試為隨機誤差的檢驗值, 而t指以項目為隨機誤差的檢驗值, 95%CI為95%置信度下的置信區間。各興趣區內平均數和標準差見表1。

表1 代詞區和代詞后區各眼動指標的平均數和標準差 (ms)
注:括號內為標準差, 下同
對代詞區數據分析結果表明, 首次注視時間在兩條件間差異不顯著,(21) = 1.52,= 0.43,= 0.33;(39) = 1.72,= 0.093,= 0.27。但和一致條件相比, 沖突條件下的凝視時間更長,(21) = 2.25,= 0.036,= 0.50;(39) = 2.06,= 0.046,= 0.33; 95%CI = 1.4~36; 重讀時間也更長,(21) = 2.02,= 0.056,= 0.43;(39) = 1.95,= 0.058,= 0.31; 95%CI = ?0.7~48; 總閱讀時間也更長,(21) = 3.08,= 0.006,= 0.66;(39) = 2.93,= 0.006,= 0.47; 95%CI = 13~67。但這種沖突效應并沒有延續到代詞后區, 對代詞后區的分析結果表明, 無論是首次注視時間、凝視時間、重讀時間抑或是總閱讀時間, 在兩種條件下差異均不顯著(s > 0.2)。根據Cohen (1988)標準, 凝視時間和總閱讀時間的效應量都在中等偏上水平, 進一步肯定了職業的性別傾向對代詞加工的影響。
這表明, 在中文語篇閱讀理解時, 讀者可以很快地將職業名稱所攜帶的性別信息和代詞聯系起來, 因而沖突的常識信息對代詞的理解造成了阻礙。這和Duffy和Keir (2004)對英文代詞加工的研究結果一致; 和Esaulova等(2014)德語代詞加工的研究結果稍有不同, Esaulova等發現職業性別傾向在晚期加工指標如總閱讀時間上發揮作用。說明在不同語言中, 先行詞的性別傾向作用時程有所不同, 本研究結果在以往研究基礎上肯定了像中文這種高語境依賴的語言, 代詞的指認可以即時地進行。那么當文本中有信息對性別刻板印象這種常識性知識進行更正后, 更正后的信息又是如何影響代詞加工的?實驗2將探討此問題。
3 實驗2:首次出現的代詞所形成的語境對代詞加工的作用
實驗2的材料中包含兩個代詞, 兩個代詞總是保持一致, 并且和先行詞職業名稱的性別傾向形成一致和沖突兩個條件。因此, 對于第二個代詞來說, 將存在兩種信息影響其加工。首先, 由于代詞的先行詞仍然是職業名稱, 所以職業名稱的性別傾向仍會對代詞的加工產生影響; 其次, 第一個代詞所提供的性別信息也會對代詞的加工產生作用。因此, 如果文本中第一個代詞所提供的語境信息可以更新讀者頭腦中關于職業名稱所固有的性別傾向, 對代詞的加工產生作用, 那么在沖突條件下, 讀者對第二個代詞的加工將不會產生困難; 而如果即使有語境信息的提示, 職業的性別傾向仍然會對代詞加工產生影響, 那么和一致條件相比, 沖突條件下第二個代詞的閱讀時間仍會較長。
3.1 研究方法
3.1.1 被試
同上, 計劃樣本量為24人, 但是考慮到事后統計功效未達到一定標準, 實際收集被試32人, 男女各16人, 平均年齡20歲, 所有被試裸視或矯正視力正常, 母語均為漢語, 無閱讀障礙。
3.1.2 實驗設計與材料
采用單因素被試內設計, 自變量為一致性, 有兩個水平:代詞與職業名稱性別傾向一致或沖突。實驗材料與實驗1相似, 同樣包含5個分句, 與實驗1不同的是, 首句之后緊接著出現第一目標句, 該句中第一次出現與職業名稱的性別傾向一致或沖突的代詞, 接下來是過渡句, 之后是第二目標句, 該句中將第二次出現代詞, 第二個代詞與第一個代詞保持一致。最后是結語。此外, 實驗2中第二個代詞出現的位置和實驗1中代詞的位置大致相同。例句如下:
一致條件:被眼前的突發事件所驚呆了, 這是沒有想到的事情。演出就這樣被搞砸, 對真是不公平, 當初就不應該找這樣的助手。
沖突條件:被眼前的突發事件所驚呆了, 這是沒有想到的事情。演出就這樣被搞砸, 對真是不公平, 當初就不應該找這樣的助手。
按照句子主題和兩種實驗條件進行拉丁方平衡, 形成兩個系列的實驗材料, 每一系列包含40個實驗材料, 每一被試只接受每個主題材料的一種條件。在每一系列的實驗材料中又加入47句填充材料, 文本的結構和實驗材料類似。每一系列共有語篇87個, 每3個語篇為一組, 共29組。
3.1.3 實驗步驟
實驗步驟與實驗1相同。
3.2 結果與分析
被試回答問題的正確率均在81%以上, 說明被試都在認真閱讀實驗材料。同理, 刪除小于60 ms或大于600 ms的注視點。同樣, 數據分析以興趣區為單位, 包括T1區(第一個代詞和其前后兩字, 其中10個左右代詞前為逗號)、T1+1區(T1區的后三個字組成); T2區(第二個代詞和其前后兩字)和T2+1區(T2區的后三個字組成)。
實驗結果如表2所示, 當讀者第一次遇到和先行詞職業名稱相別傾向相違背的代詞時, 同樣產生了沖突效應, 表現為在T1區內沖突條件下凝視時間更長,(31) = 2.31,= 0.028,= 0.41;(39) = 2.46,= 0.018,= 0.40; 95%CI = 2.5~42; 重讀時間更長,(31) = 1.96,= 0.059,= 0.35;(39) = 1.75,= 0.089,= 0.27; 95%CI = ?1.1~53; 總閱讀時間也更長,(31) = 3.64,= 0.001,= 0.64;(39) = 2.77,= 0.009,= 0.43; 95%CI = 22~78。由Cohen (1988)關于d系數的標準可知, 凝視時間和總閱讀時間都產生了中等偏上水平的效應量, 說明兩條件差異較可靠。但是這樣沖突效應并沒有持續到T1+1區, 在T1+1區, 兩種條件在首次注視時間、凝視時間、重讀時間和總閱讀時間上差異均不顯著(s > 0.1)。此結果和實驗1結果一致, 說明職業的性別傾向對代詞的加工產生了早期且持續的影響。
但當讀者再次遇到代詞時(T2區), 沖突條件下的首次注視時間反而變小,t(31) = 2.70,= 0.007,= 0.46;t(39) = 2.82,= 0.011;= 0.47; 95%CI = 3.0~22。凝視時間在兩條件間不再存在差異。但是沖突條件下的重讀加工時間比一致條件下更長,(31) = 2.27,= 0.031,= 0.41;(39) = 1.88,= 0.068;= 0.30; 95%CI = 1.9~37。此外, 在T2+1區, 和一致條件相比, 沖突條件下的凝視時間更長,(31) = 3.22,= 0.003,= 0.75;(39) = 2.87,= 0.007;= 0.44, 95%CI = 9.1~40; 總閱讀時間也更長,(31) = 2.62,= 0.013,= 0.46;(39) = 2.74,= 0.009,= 0.43; 95%CI = 9.2~73。此結果說明第一個代詞所形成的語境信息對第二個代詞的加工產生早期影響, 導致沖突條件下第二個代詞的首次閱讀時間和凝視時間都變短, 甚至短于一致條件。但是隨著加工的進程, 在后期加工階段中, 職業性別傾向這種常識性知識仍然對代詞的加工產生了作用, 表現在T2區沖突條件下的重讀時間; T2+1區凝視時間和總閱讀時間更長。
可見, 雖然實驗2中第二個代詞與實驗1中代詞的位置基本相同, 但第一個代詞的存在造成了兩種不同的結果。實驗1中職業性別傾向對代詞加工產生了早期且持續的作用。實驗2中職業性別傾向的作用被延后, 在詞匯后期的加工階段或更漫長的認知加工過程中發揮作用。這是因為讀者注意到了第一個代詞所提供的性別信息, 對職業名稱的性別傾向進行了重新加工, 從而促進了第二個代詞的早期加工。但是, 意外的是, 反映早期加工的首次注視時間在沖突條件下反而變得更短, 我們認為此結果和讀者在閱讀過程中產生的預期有關。因為文本中前后兩個代詞始終保持一致, 那么當讀者加工第一個代詞時, 其所提供的性別信息和職業名稱的沖突性, 使讀者意識到之前關于職業名稱性別傾向的認知在當前文本中可能是不恰當的, 因而在頭腦中保持對職業性別傾向的預期。而一致條件下, 第一個代詞的非沖突性并沒有使讀者形成一定預期, 因此在遇到第二個代詞時, 反映最初加工的首次注視時間在沖突條件下反而更短。但是, 這種預期效應很快就消失了, 反映在凝視時間上兩條件間不再存在差異。
然而, 值得注意的是, 在再次或者更漫長的認知加工中, 職業性別傾向仍然可以發揮作用, 可能原因在于, 讀者通過單一的代詞并不能完全更正讀者關于先行詞的性別傾向的固有觀念, 因而在后繼的加工中, 職業名稱的性別傾向仍然在發揮作用。可見在實驗2中, 讀者對第一個代詞所提供的性別信息的加工比較曲折, 最初形成強烈的預期, 然后認可文本中提供的性別, 但在更漫長的認知加工中, 這種糾結再一次出現, 職業的性別傾向仍然在發揮作用。那么當文本中通過“男藝人、父親”等更明朗的方式揭示先行詞的性別時, 在漫長的認知加工中, 讀者是否仍然會產生糾結, 職業的性別傾向是否仍然可以影響到代詞的加工呢?這是實驗3所關心的問題。
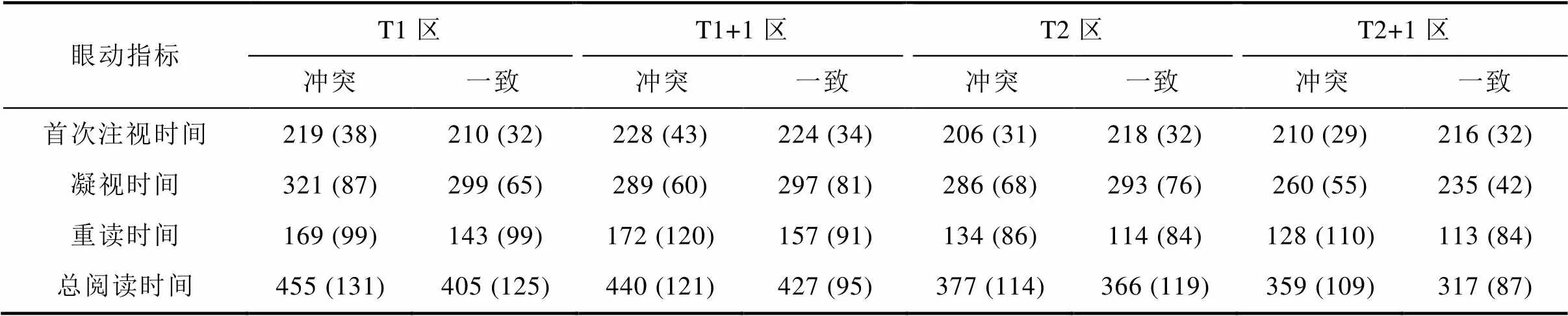
表2 T1區、T1+1區、T2區和T2+1區眼動指標的平均數和標準差(ms)
4 實驗3:性別描述所形成的語境對代詞加工的作用
在實驗3里, 將進一步對職業名稱的性別做出外顯而明確的描述, 例如男藝人、爸爸等, 然后再出現一個代詞。代詞的性別始終和先前的性別描述一致, 而與職業性別傾向沖突。如果文本中外顯的性別描述所提供的語境信息可以完全更新讀者頭腦中關于職業名稱所固有的性別傾向, 對代詞的加工產生作用, 那么在沖突條件下, 讀者對第二個代詞的加工將不會產生任何困難, 反映后期加工的重讀時間和總閱讀時間在兩條件也不會存在差異; 反之, 沖突條件下的重讀時間或總閱讀時間將會更長。
4.1 研究方法
4.1.1 被試
某高校大學生24名, 男女各半。所有被試裸視或矯正視力正常, 母語均為漢語, 無閱讀障礙。
4.1.2 實驗設計和材料
實驗設計同實驗2, 一致條件下代詞與職業名稱性別傾向一致, 與性別描述也一致; 沖突條件下代詞與職業名稱性別傾向不一致, 與性別描述一致。實驗材料同實驗2, 語料中描述性別的詞匯和職業名稱的距離, 和實驗2中第一個代詞和職業名稱的距離相似; 代詞和職業名稱的距離, 和實驗2中第二個代詞和職業名稱的距離相似。此外, 兩實驗材料總體字數基本一致, 例句如下:
一致條件:在藝術團中表現特別突出, 獲得杰出的稱號, 為此團里提出表揚, 這令整整幾天都處于興奮狀態, 逢人就提起這件事情。
沖突條件:在藝術團中表現特別突出, 獲得杰出的稱號, 為此團里提出表揚, 這令整整幾天都處于興奮狀態, 逢人就提起這件事情。
和代詞構成一致和沖突條件的兩個職業名稱在字數(3.35 vs. 3.35)、字平均筆畫數(7.97 vs. 8.24)以及詞頻(2.57 vs. 2.39)或平均字頻(5.19 vs. 5.22)上差異均不顯著(s > 0.30)。為了確定實驗2中的代詞和實驗3中的性別詞匯所提供語境明確度確實不同, 另收集28名被試, 要求其對兩實驗材料中出現的職業名稱的性別進行評價。材料樣例如下:
實驗2:魔術師被眼前的突發事件所驚呆了, 這是他/她沒有想到的事情。
實驗3:魔術師/舞蹈家在藝術團中表現特別突出, 獲得杰出男藝人的稱號。
評價材料在電腦屏幕上呈現, 要求被試確定文本中主角性別并按F (男)或J (女)鍵進行反應, 記錄被試反應時和正確率。4種條件按拉丁方平衡形成4個版本, 每個被試隨機接受其中一個版本的實驗材料。
針對項目結果, 以一致性和性別描述方式為自變量, 正確率和反應時為因變量, 分別進行兩因素重復測量方差分析。在正確率上發現性別描述方式和一致性的交互作用,(1, 39) = 4.15,= 0.04, η= 0.096, 簡單效應分析發現, 在兩種性別描述下, 一致和違背的差異均顯著(s < 0.001)。但以代詞進行性別描述時兩條件下的正確率差異(0.96 vs. 0.82)大于以性別詞進行描述時兩條件間的差異(0.95 vs. 0.86)。原因在于讀者在以性別詞匯描述職業名稱的性別時, 沖突條件下被試反應的準確率大大提升。說明性別描述確實提升了語境信息對性別界定的強度。
4.1.3 實驗步驟
與實驗1相同。
4.2 結果與分析
被試回答問題的正確率都在80%以上, 說明被試都有認真閱讀材料。分析區域包括T1區(性別描述詞)、T1+1區(性別描述詞后三字)、T2區(代詞和其前后兩字)和T2+1區(代詞區后三字)。結果分析時剔除小于60 ms或大于600 ms的注視點, 結果如表3所示。
對T1區的數據分析結果表明, 沖突條件下首次注視時間更長, 基于被試分析顯著,(23) = 2.29,= 0.023,= 0.47;(39) = 1.54,= 0.132,= 0.24, 95%CI = 1.3~25; 凝視時間更長,(23) = 2.94,= 0.007,= 0.59;(39) = 2.10,= 0.042,= 0.33, 95%CI = 9.6~55; 重讀時間更長,(23) = 3.68,= 0.001,= 0.75;(39) = 2.02,= 0.049,= 0.32, 95%CI = 17~62; 總閱讀時間也更長,(23) = 5.39,< 0.001,= 1.11;(39) = 3.45,= 0.001,= 0.55, 95%CI = 44~98。對性別描述后區進行分析, 沒有發現顯著的差異(s > 0.1)。此外, 代詞區和代詞后區的結果也不顯著(s > 0.1)。此結果說明, 當讀者遇到和職業名稱的性別傾向不一致的性別描述時, 讀者發生了加工困難。但讀者很快就接受了這種性別信息, 即時地更正了讀者頭腦中固有的關于職業的性別傾向, 因此在遇到與職業名稱性別傾向不一致的代詞時, 閱讀理解過程不再發生困難。表現在兩條件下, 代詞區和代詞后區的所有閱讀時間均無差異。此外, 對比實驗2和實驗3的結果我們發現, 語境的明確度確實影響到了語境在代詞加工中的作用, 當語境信息比較含蓄時, 語境可以產生即時但非持續的作用; 但當語境內容比較明朗時, 語境可以產生即時且持續的作用。

表3 T1區、T1+1區、T2區和T2+1區眼動指標的平均數和標準差(ms)
5 討論
本研究圍繞在中文代詞理解中, 語篇語境與常識性知識對代詞作用和作用進程展開。實驗1主要考察職業的性別傾向這種常識性知識是否可以對代詞加工產生早期影響。在此基礎上, 實驗2和實驗3分別在文本中增加一定的信息, 對職業的性別傾向進行更正, 考察更正后的信息對代詞加工的作用。
首先, 在實驗1和2中, 研究結果都肯定了職業的性別傾向對代詞加工的作用, 反映在當讀者首次遇到與先行詞職業名稱性別傾向不一致的代詞時, 代詞的凝視時間、重讀時間和總閱讀時間都更長。此外, 本研究還發現先行詞和代詞的距離不會干擾到職業性別傾向對代詞的指認過程。在實驗1和2中, 職業名稱和首次出現的代詞的距離雖然不同, 但性別傾向這種常識性知識都可以很快地被激活并參與到當前代詞的加工。這一研究結果和Qiu等(2012)的研究結果有所出入, Qiu等發現距離能夠調節先行詞的性別傾向對代詞的作用, 當先行詞和代詞距離較近時, 性別傾向對代詞加工產生即時作用; 先行詞離代詞較遠時, 性別傾向在代詞加工的晚期階段才發揮作用。兩研究結果的不同可能在于語篇中先行詞的可通達性不同。在Qiu等研究中, 先行詞是具有一定性別傾向的姓名, 而本研究中先行詞是具有性別傾向的職業名稱。以姓名作為先行詞時, 語料可以隨意編制。但是以職業名稱為先行詞, 為了保持語篇內容的自然順暢, 語篇內容基本都是圍繞各職業者所從事的行業內容展開, 正如本研究中大部分語料所示, 這就導致在先行詞職業名稱的可通達性更高。而先行詞可通達性恰恰是影響代詞能否完全被解決的關鍵因素。例如, 依據Love和McKoon (2011)的觀點, 有時代詞并不必然得到完全解決, 而是處于一種部分被解決的狀態。而代詞是否完全解決受先行詞的可通達性以及建立連貫文本表征這兩個因素的影響。依據以上觀點, 本研究中由于先行詞類型和語料特點, 先行詞通達性相對較好, 在沒有其他信息的干擾下, 代詞出現時其能夠即時激活。所以在先行詞和代詞間增加一兩句話, 不足以影響到職業性別傾向對代詞的作用。
但是, 當語境中有信息對職業名稱的性別傾向進行更正時, 性別傾向這種常識性知識對代詞加工的作用時程會發生變化, 而且這種變化和語境中性別信息的突顯程度有關。在實驗2中, 當以代詞為性別信息更正職業名稱的性別傾向時, 更正后的信息發揮早期作用, 沖突條件下的凝視時間和一致條件下的差異不再顯著, 職業性別傾向的作用被延后, 反映在沖突條件下的重讀時間和總閱讀時間仍然更長; 在實驗3中, 當采用性別描述更正職業名稱的性別傾向時, 職業性別傾向不再對代詞加工產生作用。這樣的結果很難納入現有的理論體系。例如, 根據Hess的詞匯再加工理論(Hess et al., 1995), 一旦讀者頭腦中的常識被更新后, 只有更新后的語境信息才能對代詞加工產生影響, 常識不再對代詞加工產生影響。此理論雖然可以很好地解釋實驗3的結果, 語境完全覆蓋了常識的作用, 對代詞即時且持續的作用。但卻不能解釋實驗2的結果, 語境只是部分覆蓋了常識的作用, 對代詞加工產生的即時但非持續性的作用。此外, 本研究的結果也不能用Kintsch (1998)的建構整合模型和Garrod與Terras (2000)的捆綁消解模型來解釋。依據這兩個模型, 代詞的加工要分兩個階段完成, 常識在代詞加工的早期階段發揮作用, 語境只能在代詞晚期的加工階段才能產生作用。但在實驗2和實驗3中, 我們都在反映早期加工的指標凝視時間上都發現了語境的作用。因此, 可以肯定的是, 語境可以在代詞加工的早期階段發揮作用。
可見, 在常識和語境的影響下, 代詞是分階段的還是一次完成的, 似乎和所采用語境的明確度有關。如果語境的表現方式比較含蓄, 如本研究實驗2中的代詞, 便會得出詞匯加工分為兩階段的結果; 如果采用的語境表現方式比較明確, 如本研究實驗3中的性別描述, 便得到語境較強的作用, 從而導致詞匯加工一次完成。另外, Nieuwland和Van Burkum (2006b)來自非代詞詞匯加工的證據也可以驗證語境明確度是影響語境效應的一個因素。研究者所采用的設計是營造出一種童話故事的氛圍, 從而使原來不合理的現象合理化。通過不斷地重復而形成一種語境, 使讀者認可這個童話故事。結果表明, 當讀者首次聽到和常識不相符的詞匯時, 出現了語義違背效應(N400)。當違背的詞匯第三次出現時, 違背的名詞沒有發現N400效應, 但其前面的動詞仍表現出違背效應。但當詞匯在語篇中第五次出現時, 與常識相違背的名詞和其前面的動詞已不再產生任何效應。這似乎說明, 當讀者第三次聽到與常識相違背的名詞時, 所形成的關于童話的語境還不夠明確, 不足以完全覆蓋常識對詞匯加工的作用。直到句子語境足夠明確了, 到了第五次出現才完全發揮作用。此結果表明語境明確度似乎是影響語境對詞匯作用的重要中介變量, 關于語境對詞匯作用的一些理論, 例如兩階段加工理論(Kintsch的建構整合模型和Garrod與Terras的捆綁消解模型)或一階段加工理論(Hess詞匯再解釋理論)的對立, 可能正是由于研究者所采用的語境明確度不同所導致的。
此外, 值得注意的是, 本研究兩實驗結果雖然在語境的總體作用時程上不盡相同, 但是語境均表現出了早期作用機制, 反映在實驗2中的第二個代詞區的首次注視時間在沖突條件下反而更短, 凝視時間在兩條件間差異不再顯著; 實驗3中代詞區在沖突條件下的首次注視時間和凝視時間和一致條件下差異均不顯著。這樣的結果和近年來采用眼動和腦電技術的研究結果(Cook & Myers, 2004; Duffy & Keir, 2004; Nieuwland & Van Berkum, 2006a; Hald, Steenbeek-Planting, & Hagoort, 2007)一致。表明在中文閱讀理解中, 雖然詞匯的切分困難, 容易造成詞匯理解的困難, 但正因為這種情況, 中文詞匯理解的語境依賴性更強, 所以導致語境對代詞加工的作用更快。此結果和一些對中文閱讀理解時程的研究結果一致(Wang et al., 2008), 為中文閱讀理解過程中, 語境的即時作用提供了證據支持。
最后, 值得注意的是, 本研究采用語境對常識進行更新的研究范式, 得到了語境可以對代詞加工產生即時的影響。在這樣的設計中, 語境是語料中被明確告知的正確信息, 而常識是讀者頭腦中固有的, 但被告知是錯誤的知識。相對于錯誤的常識知識, 正確的語境信息更強。因此, 較強的語境信息和錯誤的常識性知識相比, 能對代詞加工產生即時影響也是可以理解的。如果語境和常識都是錯誤的信息, 并且語境強度和常識強度相同的情況下, 語境是否仍然可以對代詞加工產生早期影響呢?這一問題值得繼續探討。
總之, 本研究結果說明在中文這種高語境依賴性的語言文字中, 語境可以覆蓋常識性知識的作用, 對代詞加工產生早期的影響, 這和以往中文加工中探討語境作用時程的研究具有一致性(Wang et al., 2008)。此外, 語境的明確度可以影響語境作用的持續性問題, 以往關于語篇中詞匯加工的兩階段理論和一階段理論的對立, 可能原因在于各研究中所采用的語境的明確度不同。
Anderson, S. F., Kelley, K., & Maxwell, S. E. (2017). Sample-size planning for more accurate statistical power: A method adjusting sample effect sizes for publication bias and uncertainty.(11), 1547? 1562.
Angele, B., Slattery, T. J., Yang, J., Kliegl, R., & Rayner, K. (2008). Parafoveal processing in reading: Manipulating n+1 and n+2 previews simultaneously.(6), 697?707.
Canal, P., Garnham, A., & Oakhill, J. (2015). Beyond gender stereotypes in language comprehension: Self sex-role descriptions affect the brain's potentials associated with agreement processing.(9), 1953.
Chen, H-C., Cheung, H., Tang, S. L., & Wong, Y. T. (2000). Effects of antecedent order and semantic context on Chinese pronoun resolution.(3), 427?438.
Cohen, J. (1988). Statistical power analysis for the behavioral sciences.(334).
Cook, A. E., & Myers, J. L. (2004). Processing discourse roles in scripted narratives: The influences of context and world knowledge.(3), 268?288.
Crocker, M. W., Pickering, M., & Clifton, C. (2000). Architectures and mechanisms for language processing.(4), 623?662.
Duffy, S. A., & Keir, J. A. (2004). Violating stereotypes: Eye movements and comprehension processes when text conflicts with world knowledge.(4), 551?559.
Ehrlich, K., & Rayner, K. (1983). Pronoun assignment and semantic integration during reading: Eye movements and immediacy of processing.(1), 75?87.
Esaulova, Y., Reali, C., & von Stockhausen, L. (2014). Influences of grammatical and stereotypical gender during reading: Eye movements in pronominal and noun phrase anaphor resolution.(7), 781?803.
Garnham, A. (Ed). (2001).. Philadelphia: Psychology Press/ Taylor & Francis.
Garrod, S., & Terras, M. (2000). The contribution of lexical and situational knowledge to resolving discourse roles: Bonding and resolution.(4), 526?544.
Hald, L. A., Steenbeek-Planting, E. G., & Hagoort, P. (2007). The interaction of discourse context and world knowledge in online sentence comprehension. Evidence from the N400., 210?218.
Hess, D. J., Foss, D. J., & Carroll, P. (1995). Effects of global and local context on lexical processing during language comprehension.(1), 62?82.
Inhoff, A. W., & Liu, W. (1998). The perceptual span and oculomotor activity during the reading of Chinese sentences.(1), 20?34.
Kennison, S. M., & Trofe, J. L. (2003). Comprehending pronouns: A role for word-specific gender stereotype information.(3), 355?378.
Kintsch, W. (1988). The role of knowledge in discourse comprehension: A construction-integration model.(2), 163?182.
Kliegl, R., Grabner, E., Rolfs, M., & Engbert, R. (2004). Length, frequency, and predictability effects of words on eye movements in reading.,(1?2), 262?284.
Love, J., & McKoon, G. (2011). Rules of engagement: Incomplete and complete pronoun resolution.(4), 874?887.
Nieuwland, M. S., & Van Berkum, J. J. A. (2006a). Individual differences and contextual bias in pronoun resolution: Evidence from ERPs.(1), 155?167.
Nieuwland, M. S., & Van Berkum, J. J. A. (2006b). When peanuts fall in love: N400 evidence for the power of discourse.(7), 1098?1111.
Qiu, L., Swaab, T. Y., Chen, H-C., & Wang, S. (2012). The role of gender information in pronoun resolution: Evidence from Chinese.(5), e36156.
Qiu, L. J., Wang, S. P., & Chen, H. C. (2012). Pronoun processing during language comprehension: The effects of distance and gender stereotype.(10), 1279?1288.
[邱麗景, 王穗蘋, 陳烜之. (2012). 閱讀理解中的代詞加工:先行詞的距離與性別刻板印象的作用.(10), 1279?1288.]
Rayner, K. (1998). Eye movements in reading and information processing: 20 years of research.(3), 372–422.
Rayner, K., & Pollatsek, A. (1989).. Englewood Cliffs, NJ: Prentice-Hall.
Taylor, D. J., & Muller, K. E. (1996). Bias in linear model power and sample size calculation due to estimating noncentrality.(7), 1595–1610.
Van Gompel, R. P. G., & Majid, A. (2004). Antecedent frequency effects during the processing of pronouns.(3), 255–264.
Wang, S., Chen, H-C., Yang, J., & Mo, L. (2008). Immediacy of integration in discourse comprehension: Evidence from Chinese readers’ eye movements.(2), 241?257.
Xu, X., Jiang, X., & Zhou, X. (2013). Processing biological gender and number information during Chinese pronoun resolution: ERP evidence for functional differentiation.(2), 223?236.
①詞頻庫來自Center for Chinese Linguistic PKU, 字頻庫來自現代漢語單字頻率列表, Modern Chinese Character Frequency List (網址為: http://lingua.mtsu.edu/chinese-computing)。詞頻和字頻均以10為底取對數。
The effects of discourse context and world knowledge on pronoun resolution
WU Yan; GAO Yuefei; ZHAO Simin; WANG Suiping
(School of Psychology, Northeast Normal University, Changchun 130024, China) (School of Psychology, South China Normal University, Guangzhou 510631, China)
Pronoun resolution can play a vital role in narrative comprehension. Understanding nature of pronoun resolution can help us to learn more about the cognitive processes underlying comprehension. Studies have shown that comprehension processes will be interrupted when a pronoun mismatches its prior context or the gender stereotype of its antecedent. This indicates that discourse context and world knowledge about gender stereotype can play an important role in pronoun resolution. Recently, researchers tried to combine these two factors together and to examine which factor is crucial to the pronoun resolution. The most controversial issue is that whether the discourse context could override the world knowledge which was told to be wrong by the passage, and exert earlier influence on the pronoun resolution. Therefore, the present study examined the effects of context and world knowledge as well as its time course on pronoun resolution with eye tracking measures.
In the Experiment 1, participants were asked to read the discourse with a personal pronoun congruent or incongruent with the gender stereotype of its antecedent, an occupation name. The results revealed that reading times (including gaze, second reading time and total reading time) increased when the gender of the pronoun mismatched with the gender stereotype of its antecedent.
In the Experiment 2, another personal pronoun indicating the gender of the antecedent would be inserted into the discourse as the prior context to update the readers’ gender stereotype of the occupation name. Therefore, readers would meet two identical personal pronouns while reading the passage. The first pronoun provided the updated gender information for the second pronoun. Again, the results of the first pronoun indicated that the gender stereotype of occupation could influence pronoun processing immediately. As for the second pronoun, the complicated results showed discourse context had an early influence on resolution of pronouns, but with the processing went on, the gender stereotype of occupation continued to influence integration. However, when the first pronoun was changed into an obvious gender description in Experiment 3, the discourse context was found not only to exert an earlier effect but the effect would be continued as the only factor to influence the pronoun resolution.
The current results clearly suggest that both gender stereotype and discourse context can affect the comprehension of Chinese pronouns. However, when the discourse context updates the gender stereotype of the antecedents, the updating information can override the world knowledge information to exert an earlier effect on pronoun resolution. But whether the effects will be continued depend on the strength of the discourse context. These findings provide evidence for the interactive model of sentence comprehension.
pronoun; discourse context; world knowledge; occupation gender stereotype
B842
10.3724/SP.J.1041.2019.00293
2018-06-22
* 國家自然科學基金項目(31500878, 31571136)、國家哲學社會科學重點研究項目(15AZD048)資助。
王穗蘋, E-mail: suiping@scnu.edu.cn
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
中學生數理化·中考版(2022年11期)2022-02-16 07:01:20
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
中華手工(2017年2期)2017-06-06 23:00:31
發明與創新(2016年38期)2016-08-22 03:02:52
太空探索(2016年5期)2016-07-12 15:17:55
中外會展(2014年4期)2014-11-27 07:46:46
實驗流體力學(2011年5期)2011-01-14 01:25:28
建筑創作(2001年3期)2001-08-22 18:48:14
祝您健康(1987年3期)1987-12-30 09:52:32
