基于深度自編碼網絡的艦船輻射噪聲分類識別
2019-03-07 09:28:38嚴韶光康春玉夏志軍李昆鵬
艦船科學技術 2019年2期
嚴韶光,康春玉,夏志軍,李昆鵬
(1. 海軍大連艦艇學院 研究生隊,遼寧 大連 116018;2. 海軍大連艦艇學院 水武與防化系,遼寧 大連 116018)
0 引 言
水下被動目標的自動識別對于提高裝備智能化程度有著重要意義,也是國內外水聲領域的研究重點和難點。依靠艦船輻射噪聲來解決目標分類識別問題是主要途徑,近些年來陸續提出了一些新的解決方法,如提取連續譜特征,使用遺傳算法改進的神經網絡分類器完成目標分類識別[1];將免疫算法[2](Artificial immune algorithm,AIA)與支持向量機[3](Support vector machine,SVM)結合,不斷選擇適應度最高的SVM作為分類器[4];運用最小均方無失真響應(Minimu Variance Distortionless Response,MVDR)譜系數[5]作為特征參數,使用多分類支持向量機作為分類器等方法[6],但識別效果仍然有待提高。
2006 年,Hinton 提出的深度學習[7–9](Deep Learning,DL)直接掀起了人工智能又一輪研究熱潮[10],且在語音識別[11–12]、圖像識別[13–14]等模式識別領域取得了巨大的成功。但其在被動聲吶目標識別這一模式識別領域的研究尚處于起步階段。深度學習通過模擬人類大腦識別信息的過程,有意識的過濾無關信息,再從中逐層深入提取特征并據此完成分類識別。深度自編碼器[15](Stacked Autoencoders,SAE)作為深度學習中的一種無監督學習網絡,相比較線性的分類識別方法,SAE中的各層自編碼器進行編碼和解碼的訓練采用了非線性激活函數,它能夠提取更充分的特征用于分類識別。相對于淺層神經網絡而言,SAE能提取輸入數據中最具代表性的深層特征來高效地完成目標的分類識別[16]。
本文在提取艦船輻射噪聲Welch功率譜特征的基礎上,提出了基于SAE的目標分類識別方法。首先通過深度自編碼網絡獲得深層特征,然后在輸出層使用softmax函對深層特征進行分類識別。并與文獻[17]中搭建的BP神經網絡(NN)分類器進行性能對比,通過對比實驗結果證明了SAE分類器的優越性。
1 深度自編碼網絡
1.1 自編碼器
深度自編碼網絡的結構基礎是自編碼器(Autoencoder,AE)。每個AE包含輸入層、隱含層、輸出層,由輸入層向前傳播到隱含層的過程成為編碼,由隱含層向前傳播到輸出層的過程成為解碼,如圖1所示。
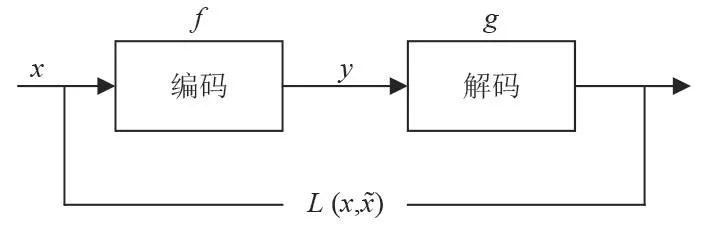
圖 1 自編碼器Fig. 1 Autoencoder
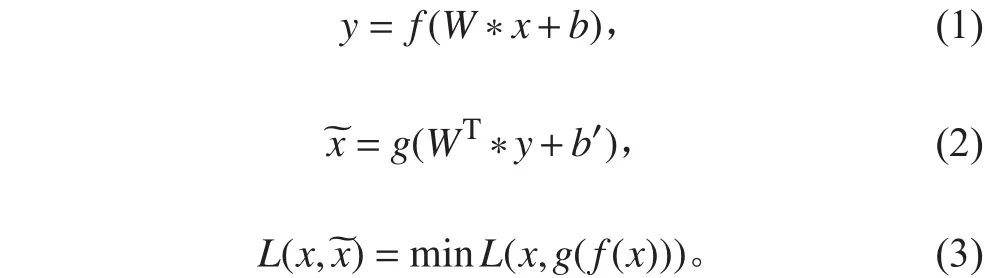
AE權重的更新可采用隨機梯度下降算法,權值更新公式如下式:
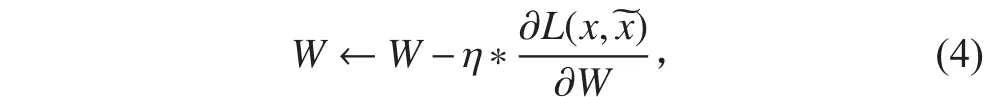
1.2 深度自編碼
為了獲取輸入的深層低維特征,基于上述AE,采用堆棧的方式來構建深度自編碼網絡[18]。首先,按照AE的訓練方式,使用輸入層訓練第1個隱含層的參數和,見圖2,訓練完成后只保留的編碼階段。
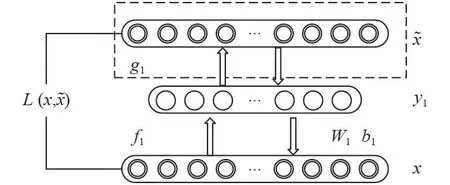
圖 2 訓練第1個隱含層Fig. 2 Training the first hidden laye
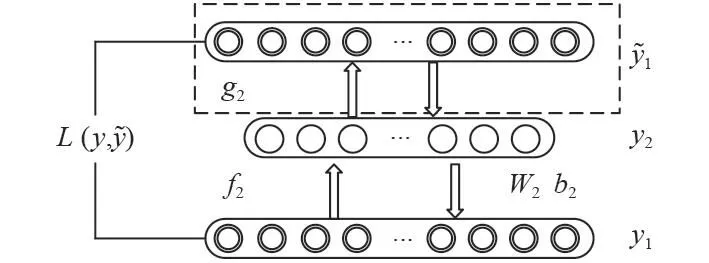
圖 3 訓練第2個隱含層Fig. 3 Training the second hidden layer
這樣每一隱含層都可以充分的包含原始信號的信息[14],通過這種“堆棧”方式完成逐層非監督預訓練就構建了深度自編碼網絡[19]。整個SAE訓練完成后,接入softmax分類器完成分類任務,如圖4所示。

圖 4 SAE結構圖Fig. 4 The System structure diagram of SAE
但由深度自編碼訓練好的權重直接堆疊構成的網絡較為粗糙,需要使用有監督的方法對權重等參數進行微調,從而加強整體層級之間連接的緊密性以及反饋調節的連續性,保證網絡處于最優狀態,所以將輸出分類結果和目標類別標記進行對比,利用反向傳播算法對全局參數進行有監督調試。對所有輸入樣本個數求平均錯誤得到損失函數,如下式:
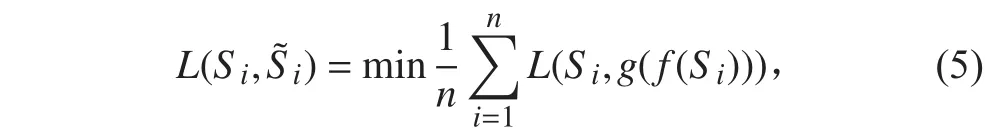
在后續分析中,損失函數選擇經典平方損失函數
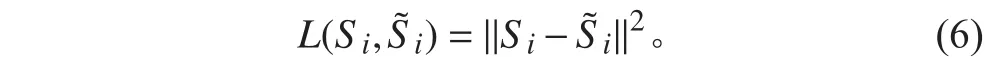
2 艦船輻射噪聲分類識別
2.1 分類識別系統框架
本文提出如圖5所示的基于SAE的艦船輻射噪聲分類識別框架。首先使用Welch功率譜估計方法對經過預處理的艦船輻射噪聲信號提取功率譜特征,然后進行歸一化得到樣本特征庫。將樣本特征庫分為訓練樣本集和測試樣本集,并對訓練樣本集進行優化處理,得到新的訓練樣本集。使用新的訓練樣本集構建和優化SAE分類器,搭建好SAE分類器后,用測試樣本對SAE分類器的效果進行檢驗。
2.2 訓練樣本集和測試樣本集
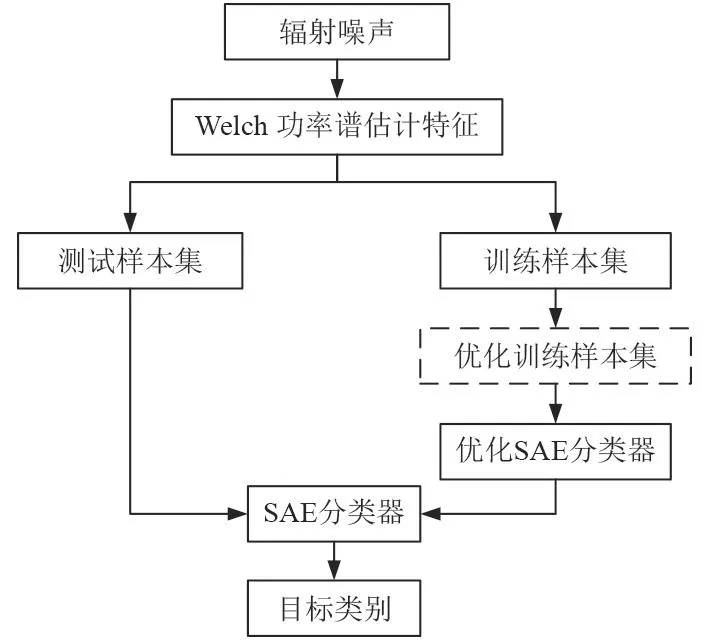
圖 5 基于SAE的艦船輻射噪聲分類識別框架Fig. 5 The classification and recognition framework of ship radiant noise based on SAE
全部輻射噪聲樣本是在不同工況和水文氣象條件下,實際錄制的3類海上目標(分別用Ⅰ,Ⅱ和Ⅲ表示)的艦船輻射噪聲。采樣頻率25 kHz,每個樣本長度為6.553 6 s。對所有的4 506個樣本集(共146艘不同工況艦船)采用文獻[20]的方法估計得到513維的Welch譜特征向量。并將整個樣本集分為訓練樣本集和測試樣本集,其中訓練樣本和測試樣本的選取方法如圖6所示,相當于每間隔65.536 s選取一個樣本進行訓練,然后取這2個訓練樣本的中間樣本作為測試樣本。由此得到訓練樣本集和測試樣本集各類樣本數量如表1所示。

圖 6 訓練樣本集和測試樣本集選取方法Fig. 6 The selection method of training sample set and test sample set
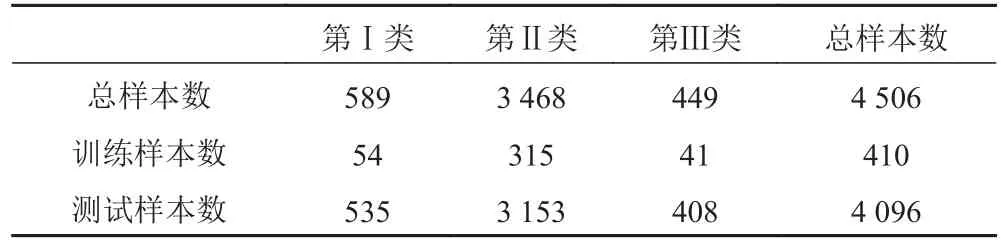
表 1 訓練樣本集和測試樣本集各類樣本數量Tab. 1 The number of different training sample sets and test sample sets
可以看出,原始訓練樣本集中各類樣本在數量上存在較大差異。其中第Ⅱ類的樣本數量最多,意味著原始訓練集中第Ⅱ類樣本不僅在數量上占有優勢性而且更具有多樣性。因此原始訓練集訓練下的SAE分類器對于第Ⅱ類樣本會得到最充分的訓練,因而在目標分類識別時會集中識別第Ⅱ類樣本[21]。針對這種情況,本文提出一種順次重復處于劣勢樣本的優化方法,即增加第Ⅰ類和第Ⅲ類樣本數量,使每類樣本數量基本處于均衡狀態。具體步驟如下:
步驟1 根據訓練樣本集中每類樣本的總數,得到訓練樣本數量最多一類的樣本個數,如式(7)所示,其中表示原始訓練樣本集中第類樣本的個數,表示訓練樣本中數量最多的一類樣本的個數,即第Ⅱ類樣本的個數。
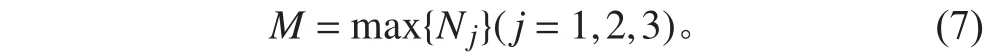
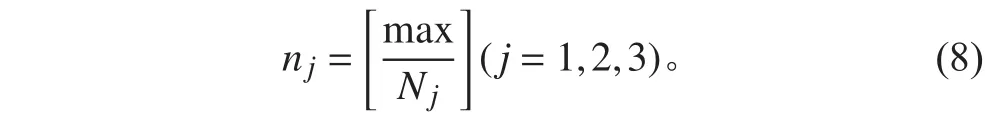
步驟3 根據步驟2獲得的重復次數對原始訓練集中各類樣本進行重復。如圖7所示,原始訓練樣本集的三類樣本和重復后獲得的新訓練樣本集中的三類樣本,分別用和表示。
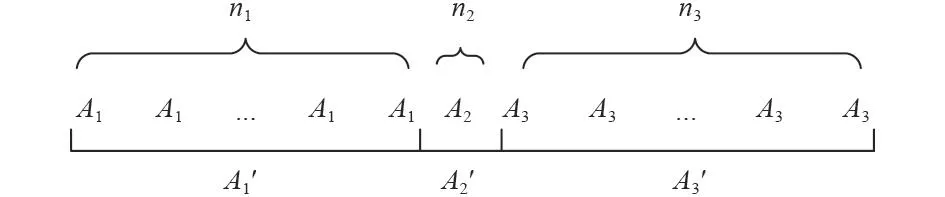
圖 7 新訓練樣本集Fig. 7 The new training sample set
通過上述步驟對訓練樣本集進行優化處理后,訓練樣本集中各類樣本數量如表2所示。
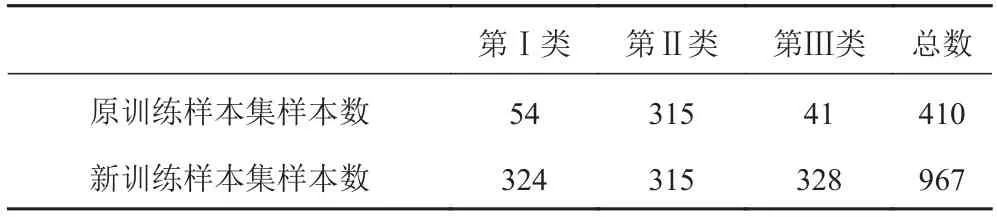
表 2 訓練樣本集中各類樣本數量Tab. 2 The number of samples in the training sample
2.3 SAE網絡結構
為了從輸入的Welch功率譜特征中獲取深層次的特征來提高SAE分類器的分類識別能力,要求自編碼網絡捕捉訓練數據中最顯著的深層特征,本文SAE分類器的各層自編碼器均采用欠完備的自編碼器,得到SAE分類器中各層節點數目之間的邏輯關系如式(9),其中表示隱含層第層的節點數目,表示輸入節點數,表示輸出節點數。
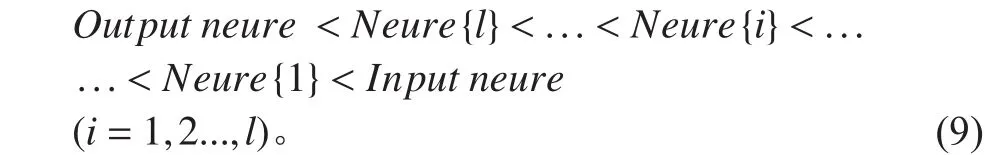
具體SAE網絡結構設置如圖8所示,以目標分類識別準確率為標準,設置恰當的網絡深度保證網絡獲取的深度特征不會因為過于抽象而無法識別,也不會因為提取的不夠深而得不到有效的深層特征。調整各層節點數,使該層節點輸出的深層特征具有維度低和有效性強的特點。
最終設置的網絡結構為4層,隱含層數為2層,具體各節點數如圖9所示。
圖 8 網絡層數和各層節點數設置Fig. 8 The number of network layer number and nodes in each layer
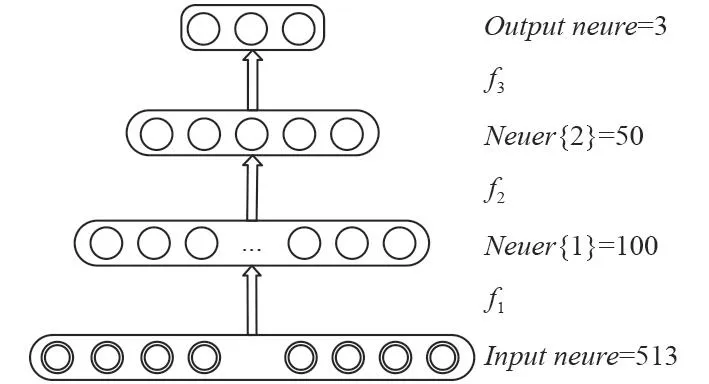
圖 9 SAE網絡結構Fig. 9 The structure diagram of SAE
2.3.1 激活函數選擇
將上述激活函數分別作為2個隱含層自編碼器的激活函數,通過對比SAE分類器的識別效果來選擇最合適的激活函數組合。
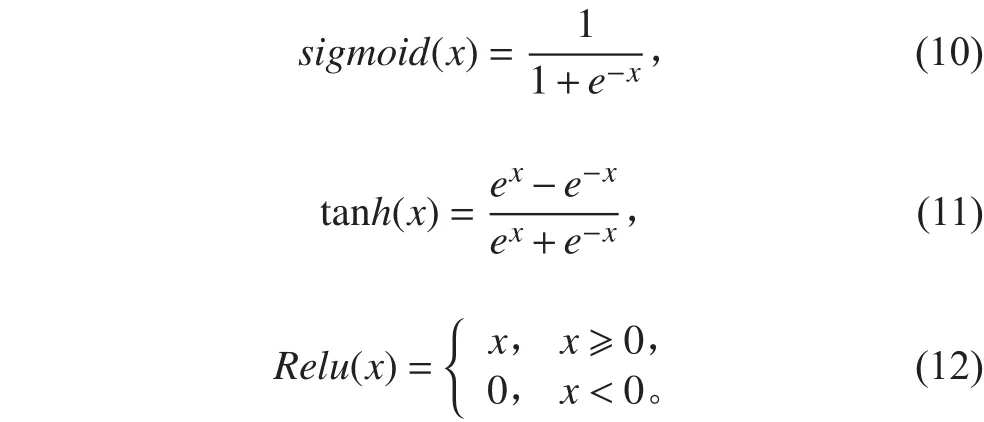
SAE分類器的識別效果如表3所示,fj為第 i層激活函數,Rj為第類目標識別精度,為總體識別精度。通過表3對比可知,當第1層和第2層激活函數均為sigmoid時,SAE分類器分類識別效果最好,故選擇sigmoid作為第1層和第2層的激活函數,選擇softmax作為輸出層的激活函數完成分類。
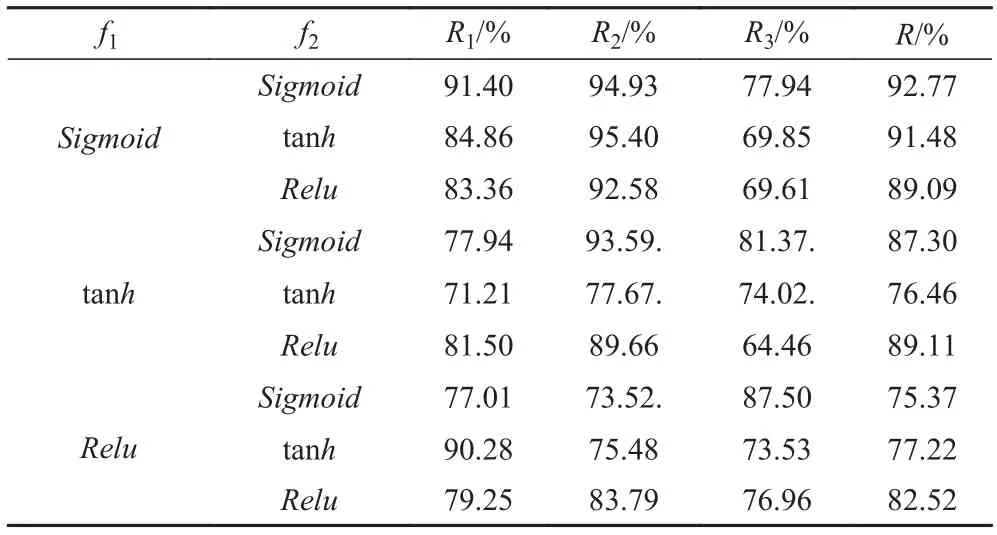
表 3 不同激活函數組合下SAE分類器的正確分類識別概率Tab. 3 Correct classification and recognition probability of SAE classifier with different activation functions
2.3.2 學習率和訓練次數的選擇
在上述SAE分類器設計的基礎上,進一步對影響網絡效率的參數——學習率和訓練次數進行選擇。因為采用隨機梯度下降算法對SAE的權重進行更新,結合權值更新式(4),可知在每次訓練中權值更新的梯度都在下降以便更有效的逼近最優值,所以SAE分類器的分類識別效果在訓練次數和學習率共同作用下才能夠達到較好效果。
學習率的經驗值區間一般為0~1,分別選擇0.1,0.5,0.9,1作為學習率代表,得到訓練次數和錯誤的下降曲線,如圖10所示。
可以看出,在采用梯度下降算法更新權重時,學習率較大則每次下降的步長越大,能夠在較少的訓練次數下快速逼近最優值,但可能存在由于步長過長使權重值在最優值點附近徘徊,無法接近最優值點;選擇的學習率過小時,雖然能夠接近最優值,但需要很多次訓練,權重逼近最優值點的速度慢,同時可能會出現過擬合的現象。因此,需要選擇恰當的學習率才能在盡可能少的訓練次數下,實現在耗時較短的前提下獲得較好的權重值。
根據上述分析,以錯誤率收斂為準則,按如圖11所示流程對SAE分類器的訓練次數和學習率進行選擇,具體步驟如下:
步驟1 將學習率經驗區間0~1劃分為10份區間間隔0.1,結合各點錯誤率曲線初步篩選區間為0.8~0.9;
步驟2 在初步篩選區間0.8~0.9基礎上,按照0.01間隔長度將0.8~0.9劃分為10份,再次結合各點錯誤率曲線進行選擇,進一步確定區間為0.88~0.89;
步驟3 在0.88~0.89區間內按照0.001間隔將0.88~0.89劃分為10份再次細化學習率,最終確定學習率為0.889,得到圖12學習率0.889時訓練次數和錯誤率下降曲線。
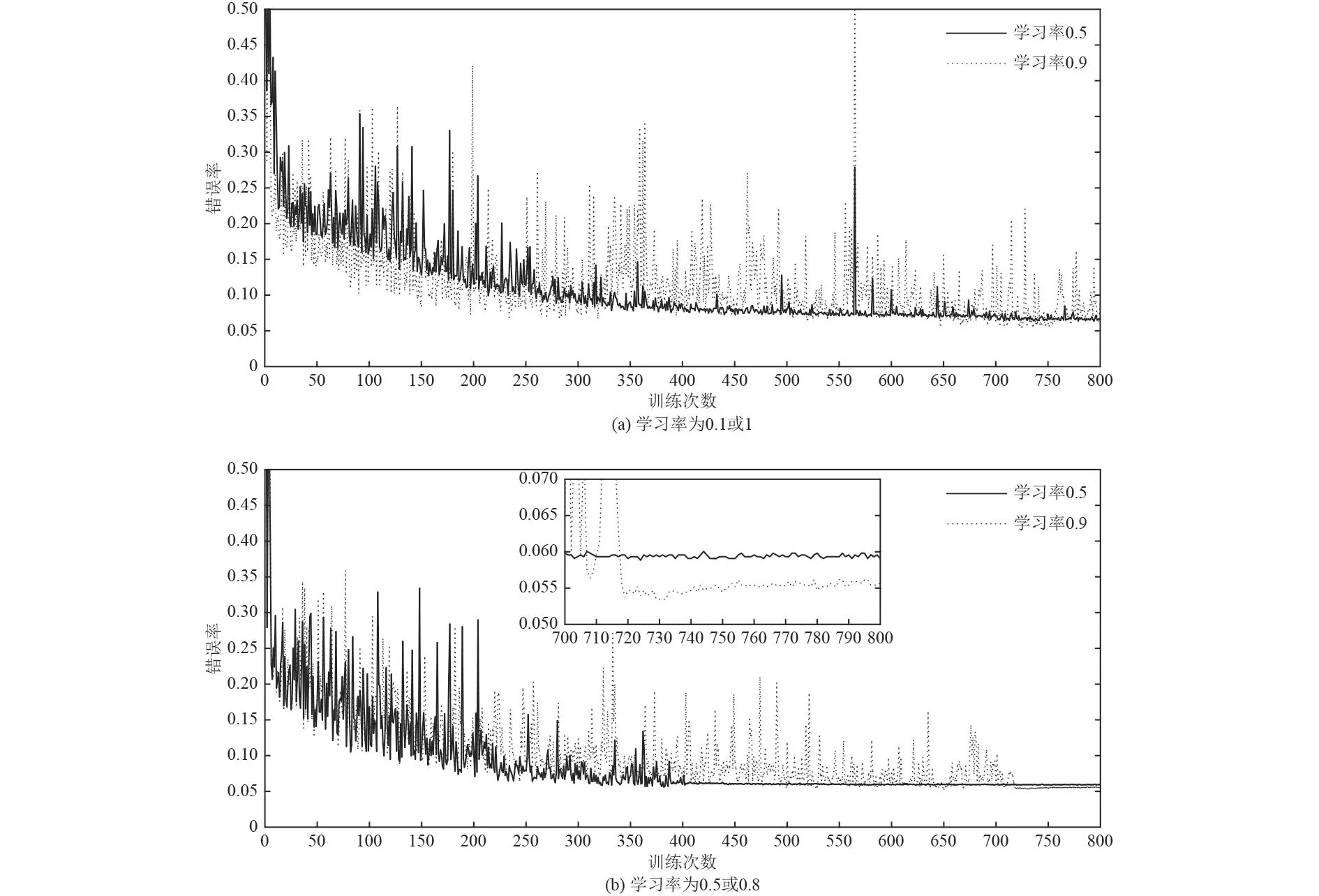
圖 10 不同學習率下訓練次數與錯誤率關系Fig. 10 The relationship between the number of training and the error rate under different learning rates
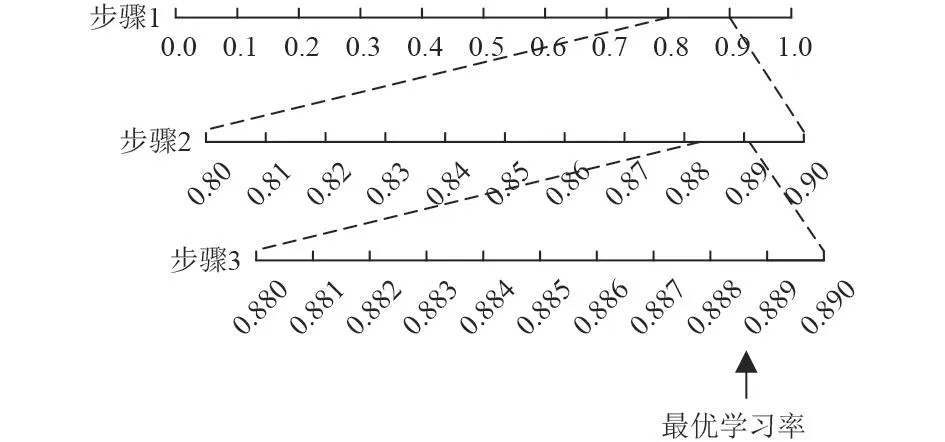
圖 11 學習率選擇流程Fig. 11 Learning rate selection process
在如圖12所示學習率為0.889的錯誤率曲線中可得訓練次數在470~480之間已經達到穩定狀態,為提高SAE分類器的實效性,在470~480之間經過對比最終選取的訓練次數為475。
3 分類識別實驗及分析
使用原始訓練樣本集分別對構建好的SAE分類器和NN分類器進行訓練,SAE和NN的參數設置訓練完成后使用測試樣本集對進行測試,得到如表4所示的正確分類識別概率。
分析可知,在三類訓練樣本數目不均勻的條件下,由于第Ⅱ類樣本數目最多,更具有多樣性,分類器對于第Ⅱ類樣本能夠提取更為豐富的特征,強化分類器對第Ⅱ類目標的分類識別能力,使分類器權值偏向第Ⅱ類目標。相比之下,第Ⅰ類和第Ⅲ類樣本樣本數目較少使得這兩類樣本的特征提取的不夠全面,導致分類器對這兩類目標的分類識別能力得不到充分訓練,識別率較低。
使用新訓練樣本集訓練再次訓練SAE分類器與NN分類器,然后使用同一測試樣本集對分類器的分類識別能力進行測試,得到表5所示2種網絡分類器的正確分類識別概率。
NN屬于淺層網絡,不具備提取數據深層特征的能力。NN分類器只能根據輸入的Welch譜特征向量進行分類識別,其分類效果受樣本數量和樣本多樣性影響。對于同一類樣本而言,數量越多、多樣性越強、識別效果就越好。對比表4和表5可以看出,新訓練樣本集增加了樣本數量,但沒有增加樣本的多樣性,因而NN分類器的分類識別能力沒有得到改善。
SAE屬于深度學習網絡模型,能夠提取深層特征,同時SAE的結構還能抑制過擬合。SAE分類器通過對Welch譜特征向量進行深層特征挖掘,找到樣本之間的本質區別,用來對目標進行高效準確地分類識別。結合表1和表4分析可以看出,原始訓練樣本集中3類目標數量差距較大、SAE分類器稀疏性強,所以在運用原始訓練集訓練SAE分類器時,提取的深層特征不全面,導致SAE分類器分類識別不準確。從表2和表5分析得到,新訓練樣本集中增加了第Ⅰ類樣本和第Ⅲ類樣本的數量,從而解決了由于這兩類樣本數量太少導致的深層特征提取不全面的問題,并且SAE分類器的稀疏度能夠有效抑制NN分類器中出現的過擬合現象。從表5可以看出,通過新訓練樣本集的訓練,SAE分類器對第Ⅰ類樣本和第Ⅲ類樣本的分類識別能力得到了明顯提升,改善了SAE分類器的整體分類識別能力。
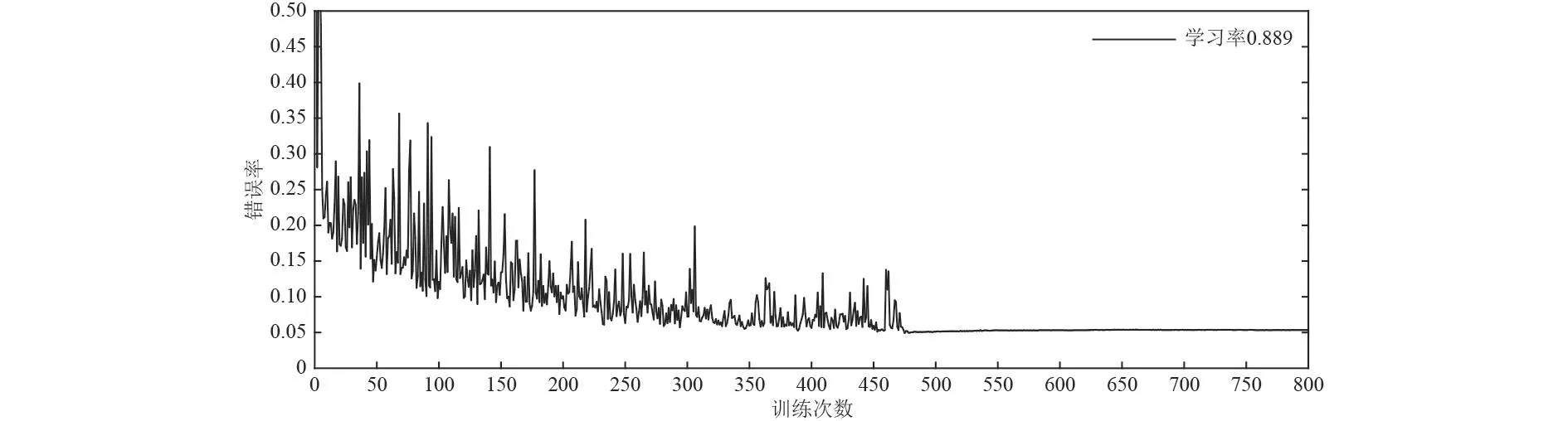
圖 12 學習率為0.889時訓練次數與錯誤率關系Fig. 12 The relationship between the number of training and the error rate when the learning rate is 0.889
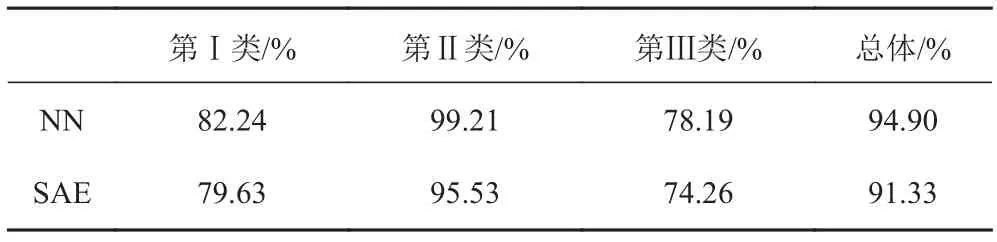
表 4 2種分類器在原始訓練樣本集訓練下的正確分類識別概率Tab. 4 The correct classification probability of two classifiers under the training of the original training sample set
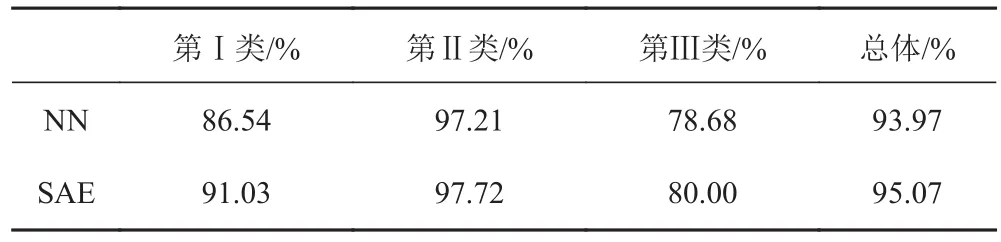
表 5 2種分類器在新訓練樣本集訓練下的正確分類識別概率Tab. 5 The correct classification probability of two classifiers under the training of new training sample set
4 結 語
深度學習多層非線性的特點,使它能夠通過簡潔的參數學習來表達復雜數據之間的關系。欠完備AE本身具有很好的特征提取能力,能夠提取樣本低維度的重要特征。AE堆疊而成的SAE發揮了這種優勢,在降低數據維度的同時能夠充分挖掘數據的深層特征,更好地完成對艦船輻射噪聲的分類識別。并且簡單的數據重復與SAE分類器自身的稀疏能力相配合,能夠在提高各類目標的分類識別率的同時防止過擬合現象的出現,SAE分類器在實際應用中與傳統淺層神經網絡相比具有很強的優越性。同時,該分類網絡也可推廣應用于艦船其他特征下的分類識別。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
