關于大數據挖掘中的數據分類算法技術的研究
2019-03-07 05:22:18王現君
電腦知識與技術 2019年35期


摘要:數據分類算法作為大數據分析與數據挖掘中的關鍵內容,面對大數據信息時代的到來,各種各樣的分類技術和算法高速發展,但在發展的過程中仍然存在部分難以有效解決的問題。該文通過對數據挖掘分類問題的分析,提出決策樹分類算法、人工神經網絡分類算法和樸素貝葉斯分類算法改進策略。
關鍵詞:大數據分析;大數據挖礦;分類算法技術
中圖分類號:TP18 文獻標識碼:A
文章編號:1009-3044(2019)35-0006-02
1 背景
若希望大數據產生實質性的價值和意義,對大數據的處理過程是極其重要的,因此大數據分析、大數據挖掘就是這些處理過程中的重要組成部門。那么大數據挖掘到底是什么?數據挖掘指的是從海量、有噪聲、不完善、模糊性較高且隨機的數據信息當中提取暗含在這些海量信息當中的,在挖掘以前人們對其具體情況完全不了解的,但是又能夠產生價值的有用信息的一種過程。在數據挖掘對象方面,需要根據數據信息的具體儲存方式,對數據庫、文本數據資源、空間數據庫等等進行一系列的挖掘工作。在數據準備方面,包括擇取數據信息,也就是在數據庫目標當中提取數據信息的最終目標數據集合;還包括數據信息的預先處理工作,也就是對數據進行二次加工,檢測數據的統一性、完整度,將這些數據信息進行降噪處理、清晰化處理,填補已經丟失的部分數據信息,將無用的、不能對需要人員產生實質性價值的信息予以刪除。
2 大數據分析與數據挖掘當中,關于數據挖掘的分類問題
大數據分析和數據挖掘技術就是從大量數據信息當中獲取可用、有效信息的一個過程,從數據當中尋找、探索、開采知識的過程。同時,數據挖掘技術是現代互聯網、計算機等信息技術高速發展下的產物,涉及信息化知識理論相對較多,包括數據庫、統計學、電子學、人工智能等多個領域,大數據分析和數據挖掘技術是一項覆蓋范圍廣闊、涉及內容煩瑣復雜、融括領域較多的學科。關于大數據分析和數據挖掘技術的工作過程,本文制定了一個可視性較強的示意圖,便于閱讀人員理解和認識,具體如圖1所示。
大數據分析與數據挖掘在主要任務方面,需要對其進行合理分類、科學預測、關聯分析、類別匯集、時間順序排列以及誤差、缺陷分析等多項工作。其中,數據的合理分類是大數據分析與數據挖掘過程中一個極為重要和關鍵的技術,始終是相關領域的討論熱點和熱門研究主題,因為差異性的分類算法將導致出現各種不同的分類器,同時分類器的優劣又會對最終分類結果的可靠性、精準性以及大數據分析與數據挖掘的效率、質量造成直接性影響,所以在我們對規模系統龐大、數據信息量較高的數據進行深度分類時,需要合理選擇分類算法,這對于相關任務的完成時至關重要的。
現階段,國內外計算機數據學領域對大數據分析與挖掘技術當中,與之關聯的分類算法研究普遍匯集于兩個方面。第一,將傳統化的分類算法以直接性的方式應用到實際案例當中,或者將傳統算法進行簡單組合再應用到實際案例當中,繼而開發出多種運用系統。第二,將傳統化的分類算法,與現代新型技術相結合,對傳統分類算法形成升級改進作用。然而,雖然以上研究均能夠對大數據分析與挖掘提供有利推動作用,但是從具體上來說,仍然缺少細節性,并不利于大數據與挖掘的進一步發展。因此,鑒于大量國內外研究對各種分類算法研究缺乏深入性和細節化的現象。本文對這些分類算法進行了系統化、深層次的對比研究分析,充分總結這些算法之間的特點、優勢和缺陷,希望能為相關領域的發展奠定夯實基礎。
3 大數據分析和數據挖掘常用分類算法對比分析
現階段,在大數據分析與數據挖掘領域主要應用的分類算法有以下三種類型。其一,是以決策樹(Decision Tree)為基礎的分類算法,例如C4、ID3等。其二,以神經網絡為基礎的分類算法,例如人工智能神經網絡(Artificial Neural Networks)等。其三,以統計學為基礎的分類算法,例如貝葉斯網絡(Bayesian net-work)、樸素貝葉斯(Naive Bayesian Model)等等。
3.1以決策樹為基礎的大數據挖掘分類算法
決策樹分類算法指的是一種基于數據集,從一系列沒有規則、沒有順序的樣本數據信息當中,推算出具體分類規則的算法,屬于歸納學習算法之一,是將組成決策方案的相關元素,以樹式圖的途徑表達出來,繼而對系統進行決策方案的選擇。決策樹分類算法可以以形象直觀的方式,彰顯出整個決策過程不同時期、關鍵點上的各種決策類問題,將這些問題以清晰的邏輯、分明的層次,直觀、形象的表示成一個樹型的模型。我們用更加貼近于真實生活的方式表現決策樹分類算法的基本工作原理:一個年輕貌美的女孩,在朋友幫忙介紹男朋友期間,其是否去和相親對象見面便是一個決策過程,這個過程我們可以用決策樹來展示,具體如圖2所示。
現階段,比較常見的決策樹算法包含種類較多,如ID3算法、C4/C5算法等等。和其他類型的分類算法進行對比,決策樹算法具有以下幾項優點:其一,決策樹分類算法便于理解和實現。對于數據挖掘技術的應用人員來講,決策樹分類算法的這種容易理解屬性,可以幫助其更加快速地將決策樹算法應用到實際分類中;其二,決策樹分類算法運行速度更快。由于決策樹分類算法工作量相對于其他分類算法更小,所以其總計算時間便會更短;其三,決策樹分類算法精準性更高。應用決策樹分類算到數據挖掘中,能夠更加快速和準確的找出分類規則,并以清晰、直觀的形象體現出重點字節。
同時,決策樹分類算法在具備多種優點的情況下,也不得避免存在一系列的缺點:第一,必須對連續性數據信息進行離散化處理,才能實現分類與學習;第二,對于已經具備時間順序的數據,需要提前進行大規模的處理加工,這是提升分類過程工作量的關鍵因素。此外,如果類別過多,將極有可能導致決策樹分類算法出現錯誤分類。
鑒于決策樹的優劣情況,國內外部分專家學者提出決策樹分類算法的改進策略。例如,將監督學習任務算法應用到決策樹分類算法之中,在決策樹形成、建設時期,該算法能夠隨著記錄的數量、屬性不斷提高,通過預排序的方式和廣度優先的方式,實現決策樹算法的有效改良。
3.2以神經網絡為基礎的數據挖掘分類算法
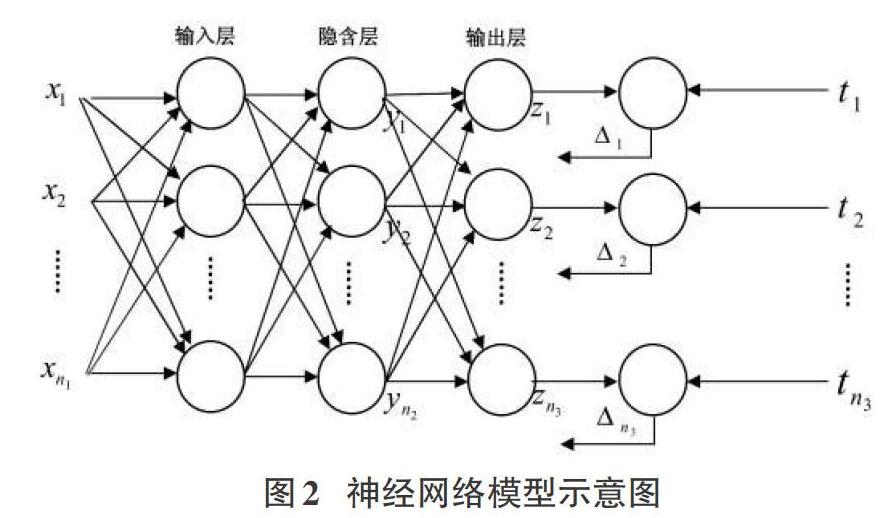
神經網絡,指的是人工神經網絡,通過對生物大腦結構、工作狀態的模擬,形成一個動態化、靈活化的信息處理模型。具體原理如下:一個神經網絡便是一個單位,該單位由多層神經元共同組成,每一個多層神經元又包含三個層次,即輸入、輸出和隱含三層。為直觀地體現出神經網絡算法的工作原理,制作神經網絡模型示意圖如圖2所示。
人工神經網絡分類算法的優勢較多,主要如下:其一,人工神經網絡分類算的精度相對較高;其二,人工神經網絡具有較強的魯棒性特點;其三,人工神經網絡分類算法具有自我學習能力和一定的記憶能力;其四,人工神經網絡分類算法能夠有效解答部分極為復雜的問題和現象,由于人工神經網絡具備非線性擬合功能,甚至在不具備條件的情況下利用變量反復實施線性組合后,再將這些線性組合轉化為非線性,所以該分類算法能夠映射出較為復雜的非線性內容。
關于人工神經網絡分類算法的缺陷,最為突出和難以解決的就是神經網絡本身的建立問題。建設一個完整、先進的神經網絡往往需要花費大量的時間,并且難度也較大。鑒于此,部分國內外專家學者提出在提取規則你對神經網絡實施剪枝的方法,對部分對分類準確程度影響非常小或者不能對分類造成影響的神經元去除,繼而簡化神經網絡的構建。
3.3以統計學為基礎的數據挖掘分類算法
以統計學為基礎的數據挖掘分類算法,其核心在于這種算法是以概率的形式展現各種數據信息的不確定性,推導、學習均是以概率學理論予以運行。樸素貝葉斯分類是現代統計學分類算法當中較為經典的,這種算法操作與原理也相對簡單易懂。
樸素貝葉斯分類算法的優點較多,主要包括:其一,樸素貝葉斯分類算法對于空間和時間的開銷相對較小,占用更少的系統資源,所以這種算法的運行速度較快。其二,樸素貝葉斯分類算法邏輯思路簡單明了,可行性和可操作性更高。其三,樸素貝葉斯分類算法分類準確的較高,且性能穩定。
在樸素貝葉斯分類算法缺點方面,這種分類算法必須立足于獨立性的假設前提,但是這一限制在現實情況下極難得到滿足,所以將導致分類的準確性大幅降低,對樸素貝葉斯分類算法的應用范圍形成嚴重制約。鑒于此,我們對樸素貝葉斯算法進行升級和更新,提出貝葉斯算法,包括貝葉斯網絡等。
4 結束語
綜上所述,對大數據分析與數據挖掘當中的分類算法進行系統化研究,得出以決策樹分類算法、人工神經網絡分類算法以及樸素貝葉斯算法的優缺點,并對這些缺點提出改進策略。雖然當前的分類算法不至于以上三種,但包括這三種算法在內的多種算法仍然處于初級發展階段,需要研究人員進一步加強相關內容的研究。
參考文獻:
[1]張樹滑.基于ID3算法的大學生成績數據挖掘與體能分析系統設計[J].現代電子技術,2019,42(5):104-106,110.
[2]陳慧萍,林莉莉,王建東,等.WEKA數據挖掘平臺及其二次開發[J].計算機工程與應用,2008(19):76-79.
[3]何清,莊福振,曾立,等.PDMiner:基于云計算的并行分布式數據挖掘工具平臺[J].中國科學:信息科學,2014,44(7):871-885.
[4]吳宏進,許家佗,張志楓,等.基于數據挖掘的圍絕經期綜合征中醫證候分類算法分析[J].中國中醫藥信息雜志,2016,23(1):39-42.
【通聯編輯:謝媛媛】
收稿日期:2019-10-19
作者簡介:王現君(1977-),男,河南魯山人,講師,碩士,研究方向為計算機應用技術,數據挖掘、人工智能、數據融合。
