基于TF-IDF和改進BP神經網絡的社交平臺垃圾文本過濾①
2019-03-11 06:02:26王非凡張舒宜黃少芬許閃閃趙晨曦趙傳信
計算機系統應用 2019年3期
王 楊,王非凡,張舒宜,黃少芬,許閃閃,趙晨曦,趙傳信
(安徽師范大學 計算機與信息學院,蕪湖 241000)
1 引言
隨著互聯網的迅速發展,網絡將大千世界連接在一起,很多社交平臺應運而生并發展壯大.其為世界各地的人們提供了便利的交流方式與資源共享的平臺,從而深深地融入到了人們的學習生活和工作中.然而,社交平臺的開放性、傳播的迅速性與普遍性使得很多不法分子與廣告商散布垃圾文本,垃圾短文本是指涉及色情、暴力、廣告推銷等方面的文本消息.其擾亂了社交平臺的安寧、破壞了社交平臺的綠色環境.為響應國家號召,打造綠色社交平臺、實現垃圾文本檢測與過濾迫在眉睫.垃圾文本的檢測與過濾主要分為如下幾個步驟:(1)數據集的收集;(2)對數據集中的文本進行分詞;(3)構造文本向量;(4)對文本向量進行降維,得到特征向量,構造關鍵詞集;(5)運用關鍵詞集進行訓練,得到分類器.從而完成垃圾文本的檢測并對其進行過濾.針對這些步驟,在對已有研究成果學習、分析各自利弊的基礎上,我們提出了一種基于TF-IDF和BP神經網絡的社交平臺垃圾短文本過濾的方法.
2 相關工作
為了研究垃圾文本的接收端過濾技術,根據文本接收端過濾技術.其主要分為基于行為模式的過濾技術以及基于內容的過濾技術兩類.針對本文研究的問題,短文本的來源比較廣泛且行為模式具有很大的不確定性,從而基于行為模式的過濾技術并不適用.我們選擇運用基于內容的過濾技術對本文提出的問題進行研究.其對垃圾郵件的處理過程如圖1.根據文獻[1],基于內容的垃圾短文本過濾的主要研究難點首先是對數據集中的文本進行分詞,高效率的分詞可以為之后關鍵詞集的構建提供良好的基礎,繼而利于分類器的構建;其次是關鍵詞集的構建,如何對原始文本向量進行特征選擇,從而進行特征降維,便于之后的研究;最后是分類器的訓練,用怎樣的方法才可以得到一個高精度、高準確率的分類器.
針對難點一,目前用的比較多的是一個開源項目—“結巴分詞”[2],它將文本中漢字可能構成的一個有向無環圖,通過動態規劃的方法找到圖中最大概率路徑,基于路徑找出基于詞頻的最大切分組合.同時,由于漢語的表達習慣,在分詞中需要注意停用詞的干擾,停用詞指的是樣本集中頻繁出現且分布均勻的、攜帶的類別信息量小的詞條,如語氣助詞、介詞等.如果分詞后的文本樣本中存在大量的停用詞,會影響分類器效果,同時延長了測試集測試需要的時間,因此需要通過去停用詞提高分類效率.常用去停用詞的方法有兩種,一種為查表法,通過與現有的停用詞表進行匹配刪除文本中的停用詞;另一種為對某個特征指標設定閾值,如果某個詞條在該指標上的數值超過閾值,則該詞定義為停用詞并刪除.
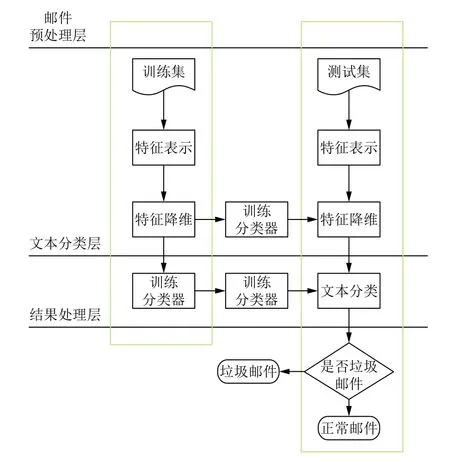
圖1 基于內容的垃圾郵件過濾流程
對于研究難點二,此前主要的特征降維的方法有信息增益[3]、互信息[4]以及期望交叉熵.由于信息增益缺乏互信息,互信息和期望交叉熵缺乏對特征詞的集中度和分散度的評估,因此我們選取了一種用于信息檢索與數據挖掘的常用加權技術 TF-IDF[5].TF-IDF 相比于如主成分分析法,層次分析法等特征提取的方法,客觀性以及真實性更強,同時它具有計算簡便、利于理解、性價比高的特點.
對于研究難點三,比較常用的分類器構建的方法有貝葉斯[6,7]、SVM[8]等,近年比較流行的是運用樸素貝葉斯[9],其算法邏輯簡單,易于實現;分類過程中時空開銷小;理論上與別的分類方法相比有較小的誤差率,但樸素貝葉斯分類有一個限制條件,就是特征屬性必須有條件獨立或基本獨立,實際上在現實應用中幾乎不可能做到完全獨立.當這個條件成立時,樸素貝葉斯分類法的準確率是最高的,但不幸的是,現實中各個特征屬性間往往并不條件獨立,而是具有較強的相關性,這樣就限制了樸素貝葉斯分類的能力.通過查閱相關資料[10-12]我們發現,與樸素貝葉斯相比,由于BP神經網絡是模擬人的認知思維推理模式,具有非線性映射能力,自學習和自適應能力,同時具有較好的泛化能力和一定的容錯能力,因此我們選取BP神經網絡構造分類器.
3 BP 神經網絡分類器
BP網絡模型處理信息的基本原理是:輸入信號Xi通過中間節點(隱層點)作用于輸出節點,經過非線形變換,產生輸出信號Yk,網絡訓練的每個樣本包括輸入向量X和期望輸出量t,網絡輸出值Y與期望輸出值t之間的偏差,通過調整輸入節點與隱層節點的聯接強度取值Wij和隱層節點與輸出節點之間的聯接強度Tjk以及閾值,使誤差沿梯度方向下降,經過反復學習訓練,確定與最小誤差相對應的網絡參數(權值和閾值),訓練即告停止.此時經過訓練的神經網絡即能對類似樣本的輸入信息,自行處理輸出誤差最小的經過非線形轉換的信息.BP網絡模型包括其輸入輸出模型、作用函數模型、誤差計算模型和自學習模型,BP神經網絡的原理圖如圖2.
(1)節點輸出模型
隱節點輸出模型:
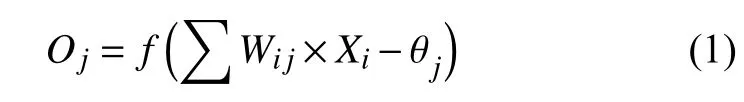
輸出節點輸出模型:
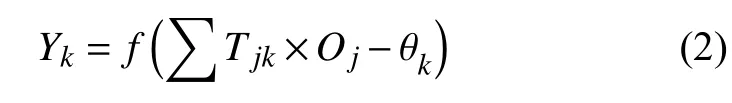
其中,f表示非線形作用函數;θ表示神經單元閾值.
(2)作用函數模型
作用函數是反映下層輸入對上層節點刺激脈沖強度的函數又稱刺激函數,一般為(0,1)內連續取值Sigmoid函數:

(3)誤差計算模型
誤差計算模型是反映神經網絡期望輸出與計算輸出之間誤差小的函數:
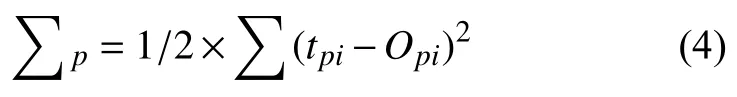
其中,tpi_i節點的期望輸出值;Opi_i節點計算輸出值.
(4)自學習模型
神經網絡的學習過程,即連接下層節點和上層節點之間的權重拒陣Wij的設定和誤差修正過程.BP網絡有師學習方式-需要設定期望值和無師學習方式-只需輸入模式之分.自學習模型為:
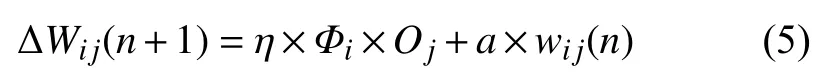
其中,η表示為學習因子;Φij表示為輸出節點i的計算誤差;Oj表示為輸出節點j的計算輸出;a表示為動量因子.
由于傳統的BP神經網絡在算法效率與收斂效果并不盡如人意,因此在原有的BP神經網絡基礎上對其進行優化改進,從而提高其效率與收斂性,使得分類效果更高.
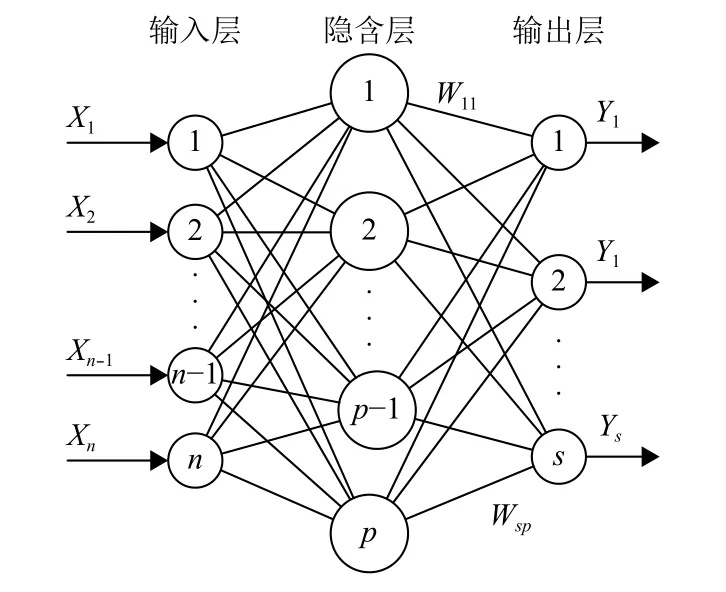
圖2 BP 神經網絡原理圖
(1)學習因子η的優化
采用變步長法根據輸出誤差大小自動調整學習因子,來減少迭代次數和加快收斂速度.
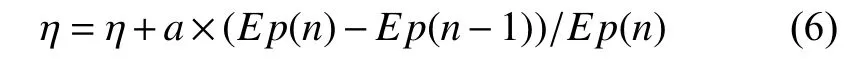
其中,a為調整步長,在 0~1 之間取值.
(2)隱層節點數的優化
隱節點數的多少對網絡性能的影響較大,當隱節點數太多時,會導致網絡學習時間過長,甚至不能收斂;而當隱節點數過小時,網絡的容錯能力差.利用逐步回歸分析法并進行參數的顯著性檢驗來動態刪除一些線形相關的隱節點,節點刪除標準:當由該節點出發指向下一層節點的所有權值和閾值均落于死區(通常取±0.1、±0.05 等區間)之中,則該節點可刪除.要確定最佳隱含層節點數應該滿足以下條件:隱含層節點數必須小于N-1(N為訓練樣本數),輸入層的節點數也必須小于N-1.最佳隱含節點數L可參考下面公式計算:
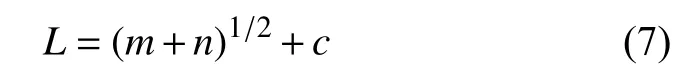
其中,m表示為輸入節點數;n表示為輸出節點數;c表示為介于1~10的常數.
(3)輸入和輸出神經元的確定輸入參數,來減少輸入節點數.
4 理論基礎
4.1 TF-IDF
TF-IDF (Term Frequency-Inverse Document Frequency)是一種用于資訊檢索與資訊探勘的常用加權技術.
在一份給定的文件里,詞頻TF指的是某一個給定的詞語在該文件中出現的次數.這個數字通常會被歸一化,以防止它偏向長的文件.對于在某一特定文件里的詞語來說,它的重要性可表示為:
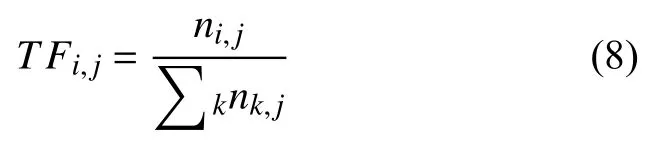
其中,ni,j是該詞ti在文件dj中出現次數,而分母則是在文件dj中所有字詞的出現次數之和.
逆向文件頻率IDF是一個詞語普遍重要性的度量.某一特定詞語的IDF,可以由總文件數目除以包含該詞語之文件的數目,再將得到的商取對數得到:
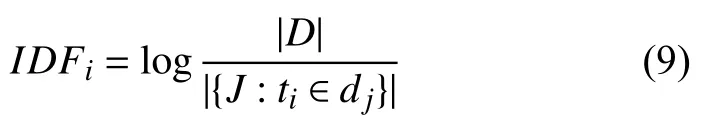
其中,|D|表示語料庫中的文件總數,{J:ti∈dj}包含詞語t的文件數目(即ni,j≠0的文件數目),如果該詞不在語料庫中,就會導致被除數為0,因此一般情況下使用1+{J:ti∈dj},TF-IDF 傾向于過濾掉常見的詞語,保留重要的詞語,從而實現特征降維.
4.2 相關算法
4.2.1 利用 TF-IDF 獲取文本分類特征向量
TF-IDF用以評估一個字詞對于一個文件集或一個語料庫中的其中一份文件的重要程度.因此算法首先應對兩類數據集Spam和Ham內的文本進行分詞處理.“結巴分詞”支持三種分詞模式:精確模式,全模式和搜索引擎模式,因精確模式試圖將句子最精確地分開,能解決歧義,適合文本分析,所以本實驗采用精確模式試圖實現文本語句的高精確度分割,以便后續工作的分析處理.另外,停用詞會對分類的準確率產生較大影響,為了提高準確率,去停用詞的步驟不必可少.兩類數據集內的文本分詞完成后,將每一類分詞結果整合為一個“分詞包”.基于兩個包含詞匯豐富的分詞包,應用TF-IDF算法計算兩類分詞包內所有詞語的TF-IDF值,選取前N個TF-IDF值較高的詞語作為文本分類特征詞.在確定文本特征詞之后,我們按照詞語在文本中是否出現將每個文本轉換為有和0組成的N維特征向量,在特征向量的基礎上進行垃圾文本檢測工作.
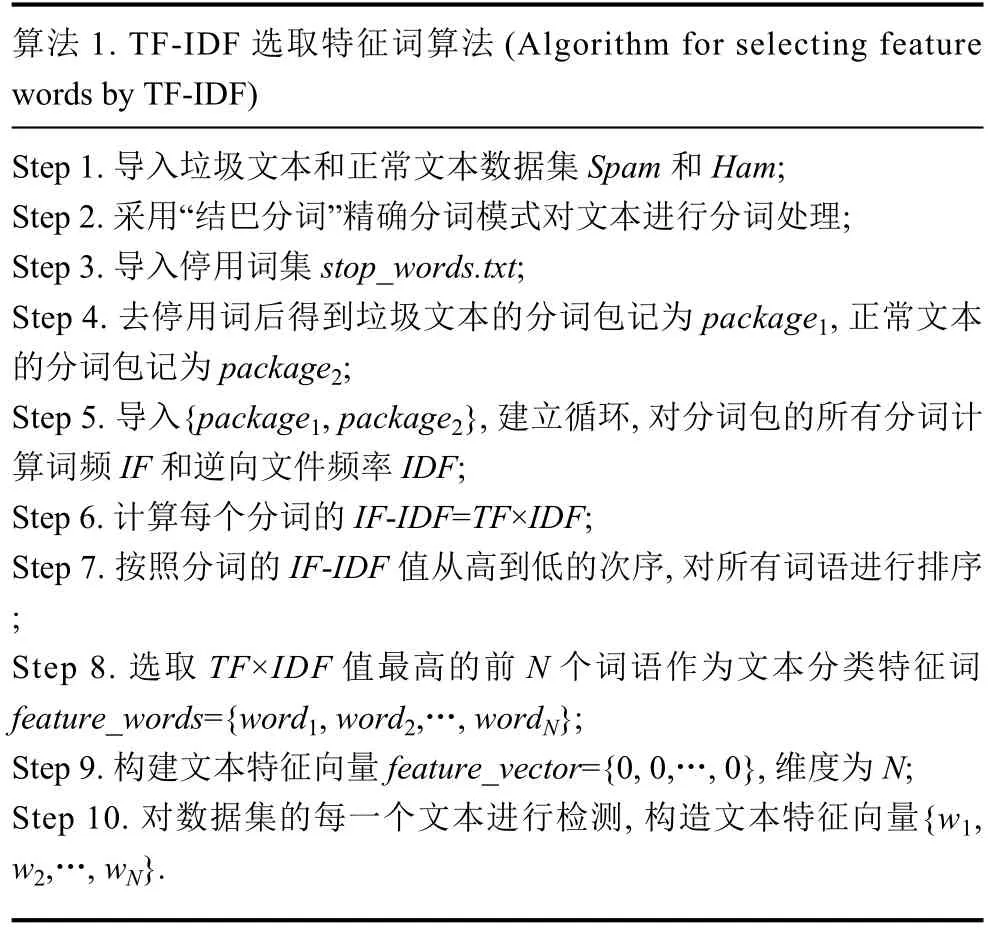
算法 1.TF-IDF 選取特征詞算法 (Algorithm for selecting feature words by TF-IDF)Step 1.導入垃圾文本和正常文本數據集Spam和Ham;Step 2.采用“結巴分詞”精確分詞模式對文本進行分詞處理;Step 3.導入停用詞集stop_words.txt;Step 4.去停用詞后得到垃圾文本的分詞包記為package1,正常文本的分詞包記為package2;Step 5.導入{package1,package2},建立循環,對分詞包的所有分詞計算詞頻IF和逆向文件頻率IDF;Step 6.計算每個分詞的IF-IDF=TF×IDF;Step 7.按照分詞的IF-IDF值從高到低的次序,對所有詞語進行排序;Step 8.選取TF×IDF值最高的前N個詞語作為文本分類特征詞feature_words={word1,word2,…,wordN};Step 9.構建文本特征向量feature_vector={0,0,…,0},維度為N;Step 10.對數據集的每一個文本進行檢測,構造文本特征向量{w1,w2,…,wN}.
4.2.2 基于特征向量的垃圾文本檢測
從TF-IDF實現思想來看,基于特征詞的特征向量能夠更好的區分文本所屬類別.目前基于特征向量的垃圾文本檢測方法主要有一般的貝葉斯網絡分類器、樸素貝葉斯、支持向量機SVM和人工神經網絡等,如何利用已有數據集進行分類器的訓練以及訓練結果的滿意程度是衡量分類模型優劣的主要標準.神經網絡算法模擬人體大腦處理問題的過程,使用最速下降法,通過反向傳播不斷調整網絡的權值和閾值,最后使全局誤差系數最小.對于文本分類問題,實驗采用兩層網絡,且第一層使用 log sig(n)=1/(1+exp(-n))線性激活函數,第二層使用purelin(n)=n對數S形轉移函數.神經網絡是一種自調整權重的學習方法,訓練過程中只需正確提供訓練集并明確輸入與輸出信號即可.

算法2.基于監督學習的神經網絡分類算法(ANN Classification algorithm based on supervised learning)Step 1.導入訓練集文本特征化后的向量,記訓練樣本數目為n;Step 2.確定訓練集的輸入為文本的特征向量,即N個輸入信號;輸出結果有兩種:1或0;Step 3.根據輸入信號,創建神經網絡net_classifier進行訓練;Step 4.給定測試數據,采用訓練完成后的網絡net_classifier對測試文本進行分類.
5 實驗設計與分析
我們選用 CDCSE (Ccert Data Sets of Chinese Emails)中的數據作為實驗數據,數據集內所有文本分為垃圾文本Spam和正常文本Ham兩類,各自數據量的大小分別為25 088和9272.首先我們通過TF-IDF算法選取特征詞算法選取1000個用于文本分類的特征詞,部分特征詞有{公司,工作,發票,水木,社區,合作,發信站,喜歡,有限公司,優惠,網上,建筑工程,介紹,獨家代理,想要,發信人,放棄,生產,主動,有時候},生成的特征詞云圖如圖3.

圖3 文本特征詞云圖
選取特征詞后,依次對兩類數據集分詞后的文本進行特征化處理,將每個由眾多分詞組成的文本量化為1000維有0和1組成的特征向量,部分量化結果如表1.
基于上述操作,我們得到了各個文本的特征向量,文本將這1000個特征屬性為分類標準,同時選取數據集的70%作為分類器訓練集,30%作為分類器測試集.實驗選用了樸素貝葉斯、貝葉斯、改進BP神經網絡的方法分別對文本進行分類,用以說明改進BP神經網絡相較于貝葉斯與樸素貝葉斯對垃圾文本過濾的優越性.首先我們利用優化的BP神經網絡構建分類器.所得分類效果如圖4所示,分類平均準確率達到了97.720%.本實驗中BP神經網絡的訓練結果目標誤差規定為0.01,從訓練效果圖來看,隨著迭代次數的遞增訓練結果的誤差在不斷降低,并在400次迭代左右趨于穩定.從網絡訓練回歸圖像來看,R達到了0.964 83,具有優良的訓練效果.我們將特征維度降為100維,重復該實驗過程,所得結果如圖5.此時平均分類準確率達到96.576%,相較于1000維特征向量,準確率變化不大,具有較強的穩定性.

表1 特征向量量化

圖4 1000維文本特征向量的BP神經網絡結果
樸素貝葉斯分類效果可由混淆矩陣度量.混淆矩陣是對有監督學習分類算法準確率進行評估的工具,通過將模型預測的數據與測試數據進行對比,使用準確率,覆蓋率和命中率等指標評價模型的分類效果.本實驗采用樸素貝葉斯對文本分類后得到的混淆矩陣如表2.
從表2中可以看出,模型正確預測正常文本的正確率SPC較高,達到了99.31%;而垃圾文本的預測準確率TPR較低,僅在0.7左右.說明樸素貝葉斯模型在預測文本所屬種類時有單向偏差,對垃圾文本的預測效果不太理想.在同樣的實驗環境下,從總體的預測結果來看,樸素貝葉斯預測準確率ACC僅達到了86.75%.同樣的,我們將特征維度降至 100 維,從總體的預測結果來看,預測準確率大幅降低,僅為77.23%.
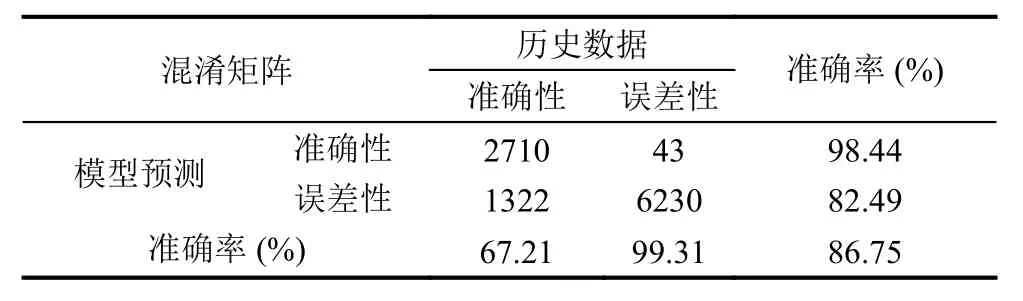
表2 1000 維樸素貝葉斯混淆矩陣
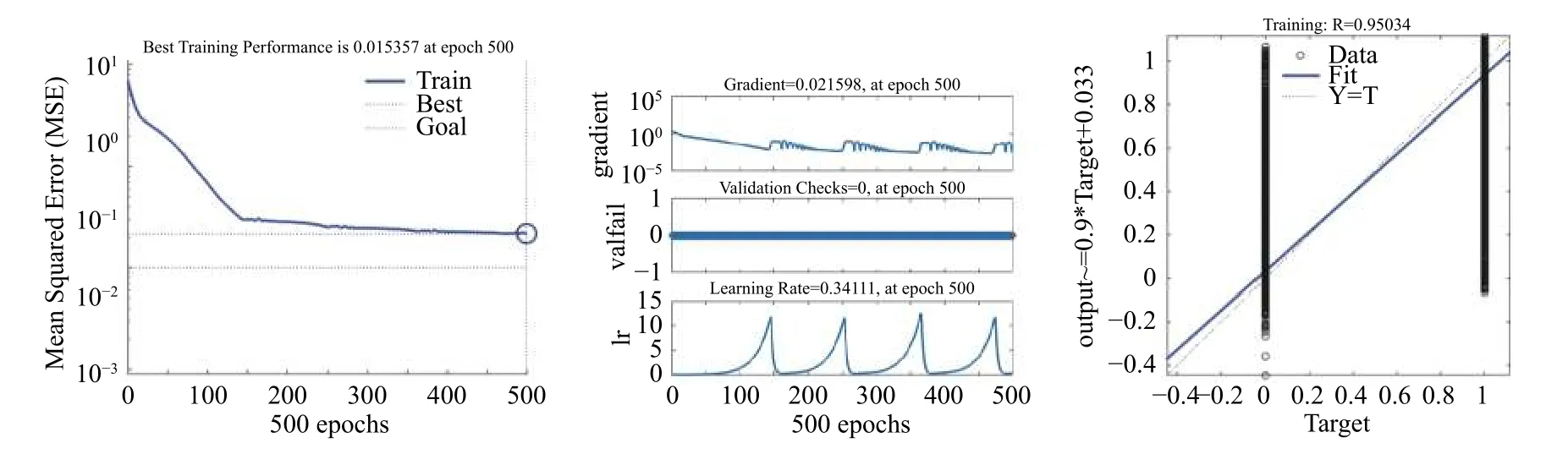
圖5 100維文本特征向量的BP神經網絡結果
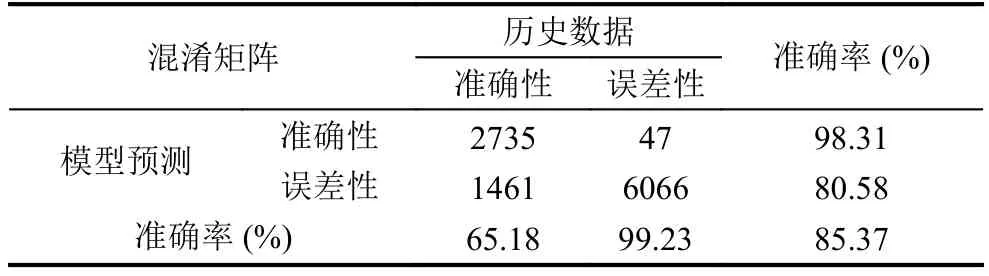
表3 100 維貝葉斯混淆矩陣
貝葉斯分類效果類似于樸素貝葉斯,可用混淆矩陣度量.貝葉斯對文本分類后得到的混淆矩陣如表3.
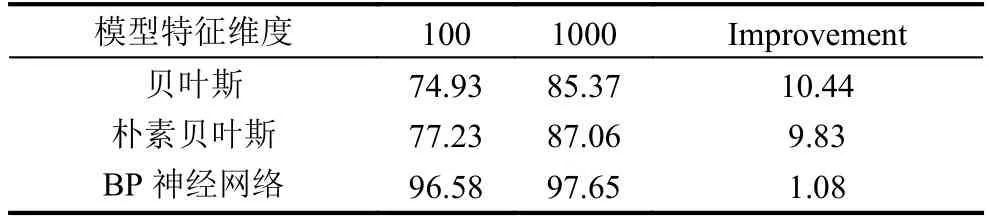
表4 準確率實驗結果對比圖(單位:%)
從表3中可以綜合看到,貝葉斯預測準確率為85.37%.將特征維度降至100維,從總體的預測結果來看,預測準確率大幅降低,僅為74.93%.對實驗所得結果進行整合,如表4.
綜上,優化的 BP 神經網絡,在同等實驗環境下,不僅僅在分類效果上有著明顯的優勢,同時在性能上也具有較強的穩定性,受特征集數目影響較小.
6 結論
社交平臺的綠色環境對建設文明中國的意義重大,因此社交平臺垃圾文本的過濾與篩選迫在眉睫.TFIDF是一種用于信息檢索與數據挖掘的常用加權技術,科學合理,使用簡單方便,適用于分詞后特征集的選擇.由于樸素貝葉斯及貝葉斯對文本的預處理要求較高,特別是樸素貝葉斯,對文本獨立性要求極高,因此我們將優化的BP神經網絡應用于文本分類器的構建,由于神經網絡是一種具有一定容錯性模仿人類思考的模型,且優化后的神經網絡的收斂性及效率有所提高,因此運用優化后的BP神經網絡所訓練的文本分類效率極好且具性能穩定,且成本有所節省,因此,基于 TF-IDF和改進BP神經網絡方法的社交平臺垃圾文本過濾不僅科學合理、結果準確、且較于其他方法具有一定的優越性及實用價值.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
甘肅教育(2020年8期)2020-06-11 06:10:02
制造技術與機床(2019年10期)2019-10-26 02:48:08
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
