基于軌跡的時空光譜特征語音情感識別算法①
2019-03-11 06:02:30朱藝偉宋泊東張立臣
計算機系統應用 2019年3期
朱藝偉,宋泊東,張立臣
(廣東工業大學 計算機學院,廣州 510006)
引言
在過去的十年中,情感計算的研究蓬勃發展,已經開始使機器能夠感知和具有情感表達行為[1].其技術廣泛應用于人機界面[2]和交互式機器人設計[3]領域,甚至是新興的交叉研究領域,如社會信號處理[4]和行為信號處理[5]等.作為人類交流的自然編碼信息,語音可以反映人類信息[6],例如:情感、性別、年齡及人格等等.因此,開發語音情感識別算法,仍然是一個流行的話題.
目前,國內外在情感識別建模語音聲學方面進行了大量的研究,比如:底層特征工程、機器學習算法、甚至是聯合特征標簽表示[7].這些研究大多數都依賴于提取一組常用的短時間特征(聲學低層描述符—— LLDs),例如:這些特征可以是相關的光譜特征(如MFCCs)、韻律特征(如音高語調)、語音質量(如抖動)、低能量算子等[8],然后選擇情感識別框架.例如:支持向量機[9]或深層神經網絡[10].或者利用時間序列模型將短語音低級描述符特征的時間性特征納入到表達水平的情感識別中.如隱馬爾科夫模型[11].有一些研究利用聽覺感知激發的調制光譜軌跡的時間特征[12],用于情感識別.基于上述研究成果,本文提出了一種基于軌跡的視頻描述符提取方法.該方法將音頻文件本質上視為一組光譜圖(通常是0.5-1),通過跟蹤重要節點提取一組軌跡.然后通過對軌跡的時間過程和隨時間的空間變化進行建模、計算,獲取這些描述符在事件[13]和運動識別特征[14].基于上述研究成果,本文提出了一種基于軌跡的時空譜特征語音情感識別方法.該方法的核心思想是從語音頻譜圖,獲得空間和時間上的描述符,進行分類和維度情感識別.與MFCCs和基頻等特征提取方法相比,本文提出的方法在噪聲條件下,調制光譜特更具魯棒性.在4類情緒識別實驗中獲得了可比較的非加權平均值回饋,在激活識別任務中顯著優于Conv-PS和Opem-Utt.
1 研究方法
1.1 情感語音數據庫的選擇
語音信號的特征是指它的聲學特征、語音信號的時域波形、頻譜特征以及語音信號的統計特性.語音信號首先是一個時間序列,進行語音分析時,最直觀的就是它的時域波形.通過分析語音信號的時域波形,提取情感特征,就可以判斷說話者的喜怒哀樂.
從語音信號中提取反映情感的參數較為困難,因為語音信號中包含了多種特征信息,不僅包括了說話者自身的特征信息、說話者的情感狀態信息,也包括了說話內容、詞匯和語法信息等.目前很多文獻對如何提取語音中的情感特征參數做了大量的研究.其中,基頻作為描述情感的最主要特征,很多文獻都采用基于基頻的統計特征,如峰值、均值、方差等.雖然這些特征描述了語音信號在不同情感狀態下的變化,但是沒有進一步詳細描述基頻曲線的變化趨勢.針對這種現狀,提出了一種基于軌跡的空間-時間譜特語音情感識別方法.其核心思想是從語音頻譜圖,獲得空間和時間上的描述符,進行分類和維度情感識別,來提高情感的判斷力.
本研究采用著名情感數據庫:USC IEMOCAP數據庫[15]用于算法實驗.這個數據庫由10個參與者組成,他們兩人一組,進行面對面的互動.二元互動的設計是為了從演員中引出自然的多模態情感表現.話語都有明確的情感標簽(如:憤怒、快樂、悲傷、神經等)和維度表征(如:價感、激活和支配).每句話的特征標簽至少由3個評分者標注,維度屬性至少由2個評分者標注.考慮到這個數據庫的自發性和評估者之間的協議約為0.4,這個數據庫對于算法的發展仍然是一個具有挑戰性的情緒數據庫.在這項工作中,我們在這個數據庫上進行了兩項不同的情緒識別任務:1)四類情緒識別;2)三層的情感效價維度和激活維度識別.對于分類情緒識別,分別是快樂的、悲傷的、中性的和憤怒的,可以認為樣本與“興奮”的標簽是相同的“快樂”.評價和激活的三個層次被定義為:低(0-1:67)、中(1:67-3:33)和高(3:33-5),其中每個樣本的值是基于評分者的平均值計算的.表1列出了每種類型標簽的樣本數量.

表1 情感分類標簽的樣本數量
1.2 基于軌跡的時空光譜特征提取
語音信號的振幅特征和各種情感信息也具有較強的相關性.當說話者處于生氣或者高興時,出現較大的幅值,而悲傷情感的幅度值較低,而且這些幅度差異越大,體現出情感的變化也越大.此外,語音的共振峰頻率也是表達情感的特征參數之一.當同一人發出的帶有不同情感而內容相同的語句時,其聲道會有不同的變化,而語音的共振峰頻率與聲道的形狀和大小有關,每種形狀都有一套共振峰頻率作為其特征.
因此,本研究試圖從語速、基頻(范圍、平均值、包絡等)、譜信息(共振峰位置,帶寬等)、 語音能量信息特征方面具體分析語音中的情感特征.
圖1描述了基于軌跡的時空光譜特性的音頻文件分析流程.以下是特征提取的步驟:空間時間譜特征提取:話語框架,代表了信號實現框架使用一個情感序列,形成每個MFB-系數軌跡,計算基于網格的時空特征和獲得額外導出軌跡.如假設p=(p1,p2,···,pk)是一個語音信號的基礎頻率,其中k為這個語音信號的基礎頻率幀數,那么,這個語音信號基礎頻率的最大值為:pmax=max(p1,p2,···,pk);最小值:pmin=min(p1,p2,···,pk);均值:;動態范圍為:prange=pmax-pmin;方差為:.

圖1 基于軌跡的時空光譜特征分析流程
語音信號的時空譜計算則可以表示為:Δp前端,Δp后端,Δp爭端語音信號幀.通過計算統計函數軌跡,就可獲得框架水平特性.
(1)框架的信號
將整個話語分割成幀的區域,每個幀的長度為L(L=250 ms,150 ms).幀之間有 50% 的重疊.
(2)代表段
使用26個Mel濾波器能量組(MFB)輸出的序列表示每一幀中的信號——也可以被成像為光譜圖.MFB 的窗口大小設置為 25 ms,重疊度為 50%.MFB計算的頻率上限為3000 Hz.
(3)形成基本軌跡
26個濾波器輸出的每個能量輪廓在每個幀的持續時間內形成一個基本軌跡.
(4)計算時空特征
對于每個基本軌跡,在t= 1 時,我們計算其相鄰網格的一階差分(8total:在圖1中標記為黃色);然后我們沿著時間軸移動,計算這些網格差,直到幀結束.因此,我們得到8個額外的軌跡(所謂的派生軌跡),為每幀26個濾鏡輸出(一個軌跡的真實例子見圖1),組成總共9個軌跡(1個基本軌跡+8個派生軌跡).
(5)框架水平時空描述符
我們通過應用4個統計功能,即基于幀級軌跡的時空描述符,得到最終的幀級軌跡.即:最大、最小、平均、標準偏差.26×9軌跡——每幀形成一組特性.
我們新提出的特性的基本思想本質上是跟蹤光譜能量的變化在一個長期的框架內,在頻率軸(空間)和時間軸的方向上.由于框架靈感來自于視頻描述符的提取方法,與語音生成/感知相關的物理意義雖然很難建立.但是,這個框架提供了一種簡單的方法來量化語音信號的頻譜-時間特性之間的各種相互關系,直接從時間-頻率表示,而不需要進行更高級別的處理.
2 實驗與結果分析
在本研究中,我們對前文所述的情感識別任務進行了如下兩個實驗:
(1)實驗 I:三種情緒識別實驗中我們提出的帶有Conv-PS和OpEmo-Uttfeatures的Traj-ST的比較和分析.
(2)實驗 II:在三個情感識別實驗中,Traj-ST 與Conv-PS和/ oropem-utt特征融合后的識別精度分析.其中,Conv-PS特征提取方法與Traj-ST相似,但不是計算Mel-filter輸出軌跡的時空特征,而是每10 ms計算基本頻率(f0)、強度(INT)、MFCCs、它們的delta和 delta-delta -delta -delta -delta -delta 45 個低級描述符.然后我們將 7 個統計函數 (max,min,mean,standard deviation,kurtosis,skewness,inter-quantile range)應用到這些LLD特征上,從而得到每一幀Conv-PS總共有315個特性.OpEmo-Utt是一個詳盡的語音級特性集.在許多輔助語言識別任務中都有使用.每句話包含6668個特征.所有的特征都是針對單個說話者的.所有的評價都是通過一對一的交叉驗證進行的,精度是用非加權平均的方法來衡量的.基于ANOVA測試的單變量特征選擇是針對Traj-ST和Conv-PS特性集進行的.
2.1 識別框架
在實驗 I中,對于 Traj-ST 和 Conv-PS 特征集,我們使用高斯混合模型(M=32)生成幀級每個類標簽的概率分數pi,t,然后使用以下簡單規則進行幀級識別:

在提到的類標簽中,t指的是框架指數,而N則指的是一個話語中的總幀數.對于OpEmo-Utt,由于它是一個大維度的話語級特征向量,我們在進行主成分分析(90%的方差)和線性核支持向量機多類分類器后,使用了基于GMM的方法.
在實驗 II中,Traj-ST與 Conv-PS和 OpEmo-Utt的融合方法如圖2所示.融合框架基于邏輯回歸.對于Traj-ST和Conv-PS,融合是在統計功能上進行的,即均值,標準差,最大值和最小值,應用于pi,t;對于OpEmo-Utt,融合是基于從一個Vs-all多類支持向量機輸出的決策分數進行的.

圖2 三個特征集融合方法
圖2描述了三種特征集的融合方法.基于框架的特征用GMM模型概率評分輸出的統計功能進行融合,使用SVM分類器的決策分數直接融合話語層次特征.最后采用的融合模型是logistic回歸.
2.2 實驗I:結果和討論
表2總結了Exp i的詳細結果.對于Traj-ST和Conv-PS,我們報告了使用不同幀長進行特征提取的GMM 模型的 UARsof,即 125 ms,250 ms,375 ms,完整發音長度.對于OpEmo-Utt,我們報告了使用GMM和svm模型的UARs.
結果中有幾點需要注意.在四類情緒識別任務中,Traj-ST 與 OpEmo-Utt (47.5% vs.47.7%)進行了比較,而最佳準確率為Conv-PS(48.6%).在三層價識別任務中,使用 OpEmo-Utt(47.4%)是最準確的,在這一任務中,Traj-ST 和 Conv-PS 表現不佳.最后,我們建議的Traj-ST特性集在三層激活識別任務上的性能明顯優于Conv-PS和OpEmo-Utt.它的識別率達到了61.5%,比Conv-PS提高了1.7%,比OpEmo-Utt提高了2.9%.通過三種類型的情緒識別任務的運行,似乎可以明顯地看出,每一組這些特征確實具有不同數量和不同質量的情緒內容.Opem-Uttem似乎對價性表現得最好,這可能是由于對價度的感知的復雜性.例如,需要在話語層面提取語氣特征.雖然過去已經證明,與聲音有關的特征在激活維度中往往包含更多的信息,但是我們仍然可以很肯定地看到我們提出的特征,Traj-ST,在預測激活的整體感知方面比這兩個其他特征集更有效.
識別任務:4級情緒識別,3級激活/情感效價識別.對于Traj-ST和Conv-PS,采用具有不同框架長度的GMM模型的UARs,用于特征提取.對于OpEmo-Utt,使用GMM和SVM模型的UARs.幀的持續時間也對獲得最佳的精度forTraj-ST(也適用于Conv-PS)起著重要的作用.由此可見,大約 250 ms 的持續時間是最理想的幀-持續時間.
這一結果證實了已有研究在情感識別中使用長期光譜特征的發現.此外,Traj-ST的特征選擇輸出結果表明,時空特征的前三個方向分別為{0,0}-基軌跡,{1,0}-高時空等效方向軌跡,以及{1,-1}-高時空-早時空方向軌跡.這三種特征占選擇產生的特征的50%.這些軌跡量化了光譜能量向高頻段方向的變化,具有較高的情感識別精度,在3級激活識別中也表現顯著.
2.3 實驗II:結果和討論
假設在實驗I中,每一組特征似乎都能識別不同的情緒表現.為了進一步驗證算法的可靠性,本文融合這三種不同的特征.表2列出了各種融合結果.OpEmo-Utt是指融合SVM模型輸出的決策分數.表3總結了三個不同特征集的融合結果.
需要注意 Traj-ST,Conv-PS,OpEmo-Utt為使用UAR計算所呈現的數目.
由表3可見.首先,不同特征集的融合都提高了最佳單特征集的結果數據.具體表現在,4類情感識別的最佳融合精度是通過融合所有三組特征獲得的53.5%(相對于絕對單個特征集的4.8%的絕對改進);3級情感效價的最佳融合結果是47.8% (1%絕對改進優于最佳單特征集,OpE).最后,三級激活的最佳融合結果是61.2% (相對于最佳單特征集0.9%的絕對改進,Traj-ST).由此可見,本文新提出的特征Traj-ST確實能夠在該融合框架下進一步提高分類情感識別和激活水平檢測的識別率,這意味著我們的特征的互補信息在情感方面具有較高的一致性.總之,實驗證明,以軌跡為基礎的空間時間譜特征可以結合利用兩個不同的聲學特征集,提高情感識別率.
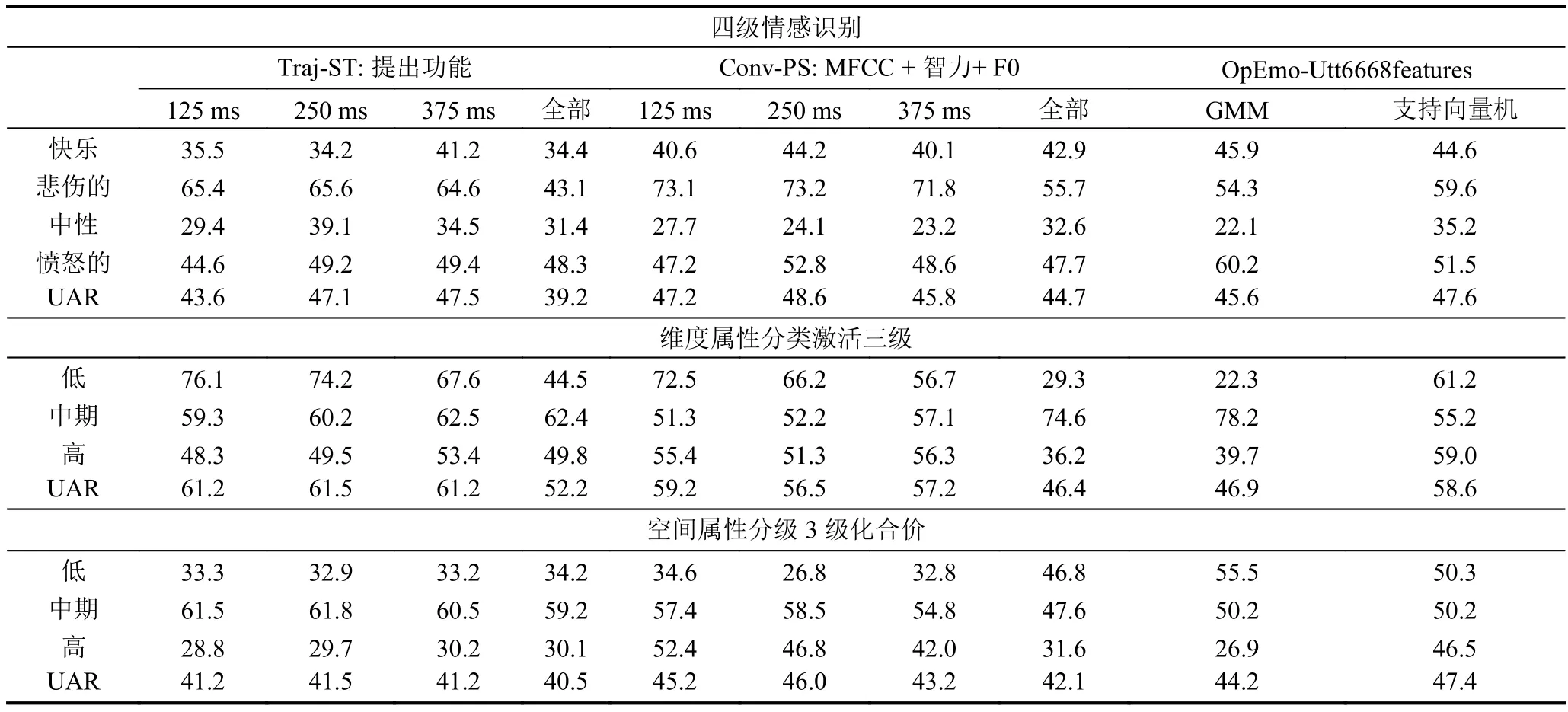
表2 實驗 I輸出了三種不同情緒的結果

表3 實驗II輸出了三個不同特征集融合的分析結果
3 結語
本文提出了一種低水平聲學特征的語音情感識別方法,以表征語音信號的長期時空信息.我們利用所提出的特征對分類情感歸因和維度表征進行情感識別實驗.實驗表明,所提出的特征集與已建立的低級聲學描述符和最先進的窮舉特征提取方法相比,在分類情感識別方面具有更優秀的性能,在激活水平識別的任務上優于現有的特征提取方法.通過融合基于軌跡的時空特征,提高了情感識別的整體精度.
猜你喜歡
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
鴨綠江(2021年35期)2021-04-19 12:24:18
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
考試與評價·高一版(2020年6期)2020-11-02 02:45:24
現代出版(2020年3期)2020-06-20 07:10:34
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
電子制作(2018年11期)2018-08-04 03:25:42
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
