基于FTRL和XGBoost算法的產(chǎn)品故障預測模型①
2019-03-11 06:02:36楊正森
計算機系統(tǒng)應(yīng)用 2019年3期
楊正森
(南京財經(jīng)大學 工商管理學院,南京 210046)
1 引言
智能制造正被吹捧為下一次工業(yè)革命.利用統(tǒng)計知識結(jié)合大數(shù)據(jù)機器學習算法預測產(chǎn)品故障率,以提高生產(chǎn)力并保持競爭力,儼然成為下一步制造業(yè)企業(yè)爭相追逐的目標.針對制造業(yè)的生產(chǎn)流水線數(shù)據(jù),建立一個故障檢測模型,有利于企業(yè)及時發(fā)現(xiàn)產(chǎn)品生產(chǎn)過程中的問題并對其修正,從而實現(xiàn)更精細的智能制造過程.目前國內(nèi)外學者提出的針對大數(shù)據(jù)的預測方法主要包括神經(jīng)網(wǎng)絡(luò)預測法[1,2]、基于降維手段的傳統(tǒng)機器學習預測法[3-6].神經(jīng)網(wǎng)絡(luò)法雖然有很高的精度,但往往算法時間成本高,可解釋性不強,同時傳統(tǒng)的機器學習算法對于大規(guī)模數(shù)據(jù)集在節(jié)約內(nèi)存和時間開銷方面也往往不盡如人意.針對以上問題,學者們提出了相應(yīng)的改進方法.文獻[7]提出了一種具有動態(tài)結(jié)構(gòu)的RBF神經(jīng)網(wǎng)絡(luò),文中方法通過基于神經(jīng)元活動性和互信息來在線添加或刪除神經(jīng)網(wǎng)絡(luò)隱含層神經(jīng)元,以實現(xiàn)平衡網(wǎng)絡(luò)的復雜性和整體計算效率.文獻[8]針對工業(yè)系統(tǒng)數(shù)據(jù)的預測問題,提出了一種能夠并行的基于共享儲備池模塊化的神經(jīng)網(wǎng)絡(luò)預測模型.該方法采用K均值聚類方法將樣本數(shù)據(jù)分類并分別建模,在建模過程中提出一種改進的回聲狀態(tài)網(wǎng)絡(luò),通過對神經(jīng)網(wǎng)絡(luò)進行模塊化處理能夠?qū)栴}求解空間分層,相比單一神經(jīng)網(wǎng)絡(luò)具有更好的泛化性能.文獻[9]在對風機運行狀態(tài)數(shù)據(jù)劃分不同時間窗的基礎(chǔ)上,運用LightGBM、XGBoost、ERT模型進行嵌套融合,得到混合模型,縮小可疑故障數(shù)據(jù)的范圍,保證較為準確的情況下基本覆蓋到幾乎全部的故障數(shù)據(jù),并在再次細分的時間窗下得到更好的效果.上述改進方法存在的一個共性問題是,真實工業(yè)環(huán)境下,生產(chǎn)數(shù)據(jù)在流水線上幾乎以秒為單位不斷產(chǎn)出,因此預測模型需要不斷迭代以適應(yīng)新的生產(chǎn)狀況,上述方法雖然相比傳統(tǒng)方法在模型的計算效率和準確率有了很大提升,但在面對真實工業(yè)數(shù)據(jù)時,模型的迭代速度仍然不能滿足企業(yè)需求.針對該問題,本文提出了一種基于FTRL[10]和XGBoost[11]算法的產(chǎn)品故障預測模型,可以在保證預測準確率同時,加速模型的迭代速度,本文將其應(yīng)用于真實的制造業(yè)數(shù)據(jù),取得了令人滿意的效果.
2 數(shù)據(jù)來源與分析
2.1 數(shù)據(jù)來源
本文使用的數(shù)據(jù)來自德國的工業(yè)企業(yè)博世公司發(fā)布的一份規(guī)模龐大(14.3 GB)的匿名數(shù)據(jù)集,這份數(shù)據(jù)集由百萬條生產(chǎn)流水線記錄組成,每條記錄都測量了產(chǎn)品在生產(chǎn)流水線不同部分的相關(guān)信息,博世公司希望各界學者挑戰(zhàn)預測產(chǎn)品故障這一難題,從而使博世能夠以最低的成本為最終用戶帶來優(yōu)質(zhì)的產(chǎn)品.該數(shù)據(jù)集包含三種類型的特征:數(shù)值型特征968個,分類型特征2140個,時間序列特征1156個以及預測標簽.其中訓練數(shù)據(jù)含有1184 687個樣本(其中包括1176 868個正樣本,6879個負樣本),用于衡量模型性能的測試數(shù)據(jù)含有 1182748個樣本.針對如此龐大規(guī)模的數(shù)據(jù)集,如何才能將其有效利用并建立預測模型,確實是一個不小的挑戰(zhàn).
2.2 數(shù)據(jù)分析
數(shù)值型特征的命名方式包含了與生產(chǎn)記錄有關(guān)的工作站,生產(chǎn)線和測量值信息.例如,生產(chǎn)記錄名L3_S50_F4243的特征表示某部件的生產(chǎn)流程通過生為產(chǎn)線3,工作站50(每個工作站所屬的生產(chǎn)線唯一),并且特征值對應(yīng)的測量方式編號為4243.為了直觀了解工廠的運作方式,筆者利用數(shù)值特征,構(gòu)造了如圖1所示的工廠生產(chǎn)流水線框架圖(數(shù)字代表對應(yīng)的工作站臺),其中共含有8197條唯一的生產(chǎn)路徑.
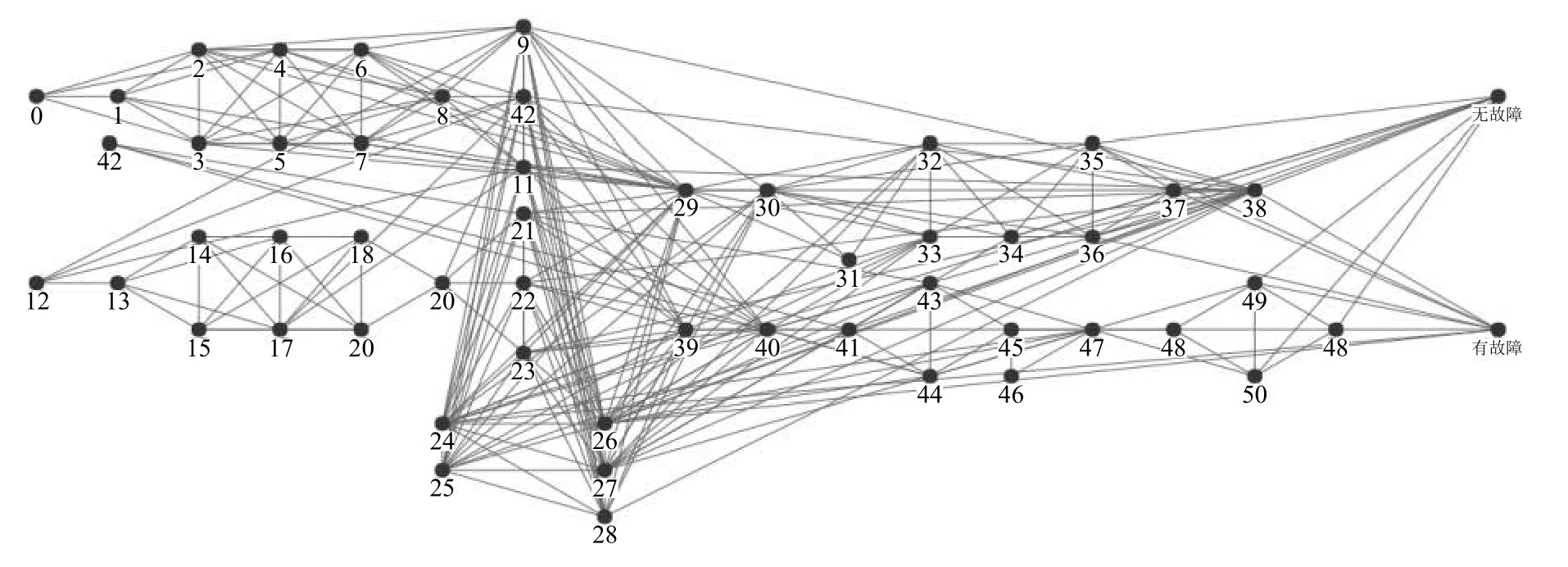
圖1 工廠生產(chǎn)流水線框架
通常來講,相似的產(chǎn)品類型在不同的生產(chǎn)線上往往具有相近的生產(chǎn)時間,為了有效區(qū)分不同類型的產(chǎn)品,本文手動構(gòu)建了一類時間差特征,來衡量產(chǎn)品在每條生產(chǎn)線上的流通時間,下文將這類特征統(tǒng)一稱作time_diff特征.
原始數(shù)據(jù)集除去空值特征后類別型特征共有1990個.針對分類型特征,一個經(jīng)典的處理方式是通過one-hot編碼.由于數(shù)據(jù)集的分類型特征本身數(shù)量就非常多,再進行one-hot編碼處理會使得特征量爆炸式增長,加上數(shù)據(jù)集的樣本量又非常大,這就使得傳統(tǒng)的機器學習算法很難再針對所有特征去擬合一個學習模型.因此下文筆者會針對該問題提出相應(yīng)的解決辦法.
時間序列特征名稱由生產(chǎn)線、站臺、日期三部分組成.例如,對于時間序列特征 L3_S50_D4242,其表明當產(chǎn)品通過生產(chǎn)線3,工作站臺50,并且數(shù)值特征(或分類特征)的測量方式id為4241時所發(fā)生的具體時間.為了弄清楚時間序列值的具體含義,筆者將時間滯后差作為x軸,對應(yīng)的自相關(guān)系數(shù)作為y軸,建立如圖2所示的關(guān)系圖.我們可以發(fā)現(xiàn)時間序列特征一個周期的區(qū)間跨度為16.75,每個周期存在7個局部峰值,據(jù)此筆者推斷一個周期為一個星期.也就是說,1周對應(yīng)的時間序列特征值為16.75,至少每六分鐘(0.01)生成一個產(chǎn)品記錄.因此原始數(shù)據(jù)集記錄了102.6周(約兩年多)的生產(chǎn)記錄.
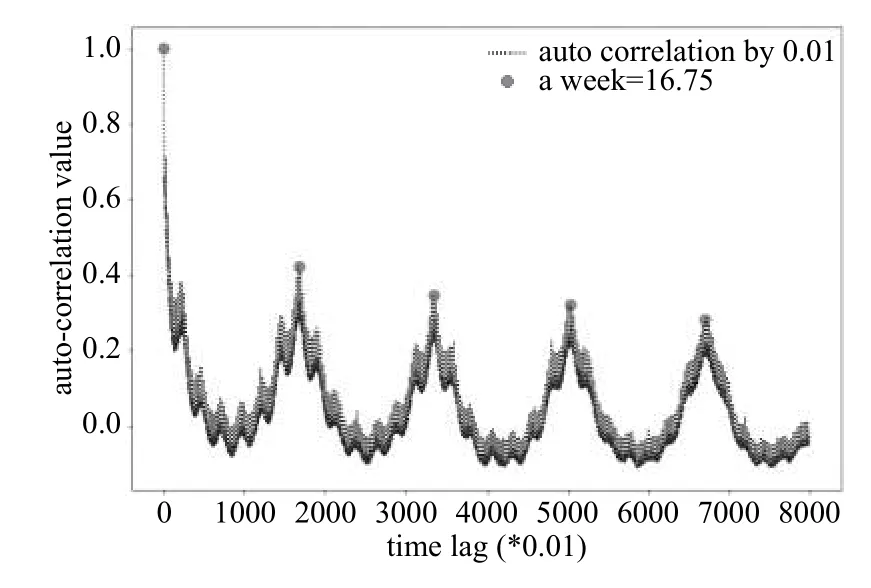
圖2 不同滯后區(qū)間下的自相關(guān)系數(shù)
2.3 解決方案思路
總結(jié)該數(shù)據(jù)集,其具有樣本量大,特征量大且類型多樣,時間跨度大,正負樣本不平衡的特點,并且數(shù)據(jù)集的樣本以流的形式不斷獲取.筆者從以下角度出發(fā),最終決定采用本文的故障預測框架:首先,由于數(shù)據(jù)樣本量和特征量都很龐大,這就要求模型的數(shù)量盡可能少而精,其次,樣本中分類特征與傳統(tǒng)工業(yè)數(shù)據(jù)相比,量級顯然多很多,為了兼顧計算效率和模型的性能,本文創(chuàng)造性將其類比為一個點擊率預估的建模問題,采取典型的FTRL點擊率預估模型來對待分類特征,最終,進一步地,本文在建模時沒有采取傳統(tǒng)的模型融合策略,而是利用FTRL模型將分類特征轉(zhuǎn)化為一列特征放進XGBoost中訓練,這么做既通過降低建模的復雜度來保證了模型的迭代速度,又間接利用了模型融合的思想,保證了模型的精確度.
3 模型理論基礎(chǔ)
3.1 FTRL (Follow the Regularized Leader)理論基礎(chǔ)
一直以來,利用在線學習 (Online learning)[12]算法優(yōu)化的廣義線性模型 (Logistic Regression,LR)被廣泛應(yīng)用于大規(guī)模機器學習問題中.在線學習算法以數(shù)據(jù)流的形式從硬盤中讀取文件,每個訓練樣本只需考慮一次,即通過在線梯度下降 (Online Gradient Descent,OGD)的方法來優(yōu)化損失函數(shù),這種方法能夠高效地訓練大數(shù)據(jù)集.OGD算法在實踐中已被證明能夠有效地解決大規(guī)模機器學習問題,其能夠在最小化所耗計算資源的同時提供不錯的預測精度.然而OGD算法對于產(chǎn)生稀疏模型并不太盡如人意.模型的稀疏化指的是實踐過程中我們希望通過減少權(quán)重向量的非零解來去除冗余變量,只保留與預測變量最相關(guān)的解釋變量.實現(xiàn)該目的往往通過向目標損失函數(shù)中加入L1范數(shù),這里L1范數(shù)是指特征權(quán)重向量中各個元素的絕對值之和,它在零處不可微,因此當最小化損失函數(shù)后得到的最優(yōu)解會使權(quán)重向量的大部分元素變?yōu)榱?剩下的較大的權(quán)重向量值對應(yīng)的特征往往是與目標向量最相關(guān)的特征.從本文的故障預測角度來看,雖然特征有近千維,但能夠持續(xù)穩(wěn)定預測故障是否發(fā)生的特征通常不過幾百維度,其他特征往往是導致當下發(fā)生故障的隨機因素,當面對未來發(fā)生的故障時不起任何預警作用,引入L1范數(shù)能夠?qū)W習地去掉這些沒有信息的特征,也就是把這些特征對應(yīng)的權(quán)重置為零.因此這種方法能夠有效降低模型復雜度,提高泛化性,同時也保留了與目標變量最相關(guān)的解釋變量.
3.2 FTRL優(yōu)化算法介紹
FTRL最初由Google的H.Brendan McMahan于2010年提出,近年來國內(nèi)外各大企業(yè)將其應(yīng)用于自身行業(yè)的相關(guān)業(yè)務(wù),都取得了很好的效果.FTRL與以往在線算法不同,其對特征權(quán)重每一維分量采取不同的更新方式,假設(shè)給定損失函數(shù)對特征權(quán)重第i維的梯度向量為wi,那么其更新公式為:
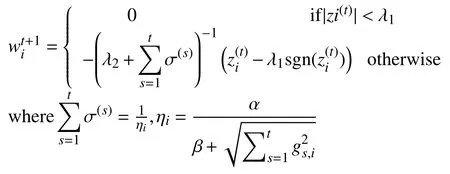
其中,σ(s)是一個和學習率(即迭代步長)i相關(guān)的參數(shù),gi為損失函數(shù)對第i維特征權(quán)重的梯度向量,α和β為超參數(shù),實驗部分會說明超參數(shù)的選擇方式.λ1>0,λ2>0分別為L1、L2正則化系數(shù).根據(jù)公式我們可以發(fā)現(xiàn),該優(yōu)化函數(shù)保證了新產(chǎn)生的權(quán)重與歷史權(quán)重不偏離太遠,同時利用L1正則進行稀疏性約束以及利用L2正則使解變得“平滑”從而來防止過擬合.FTRL對于特征權(quán)重的不同分量采取不同的更新策略,在OGD算法的基礎(chǔ)上進一步加速了算法迭代過程.實踐表明結(jié)合了FTRL的LR算法相比傳統(tǒng)的二分類算法,在模型的效率,精度,泛化性等各方面都得到了質(zhì)的提升.
由于本文采用的數(shù)據(jù)集是在制造業(yè)企業(yè)的生產(chǎn)線上以流形式不斷獲取的,而one-hot編碼后的類別特征又非常稀疏,因此對其建立FTRL-LR模型.
3.3 XGBoost算法相關(guān)理論基礎(chǔ)
XGBoost全稱為 eXtreme Gradient Boosting,是GBDT (Gradient BoostingDecision Tree)算法的一種,顧名思義,其思想主要由兩部分組成:Decison Tree[13](決策樹)算法和 Gradient Boosting[14](梯度提升)算法.
XGBoost計算效率高,泛化能力強,并且可以大大降低人工特征工程的工作量,因此將其作為最終的預測模型.XGBoost相對于 GBDT 的算法步驟,主要的改變是對損失函數(shù)生成二階泰勒展開,并在代價函數(shù)里加入了正則項,用于控制模型的復雜度.正則項里包含了樹的葉子節(jié)點個數(shù)、每個葉子節(jié)點上輸出的權(quán)重得分的平方和.從平衡偏差方差的角度來講,正則項降低了模型的方差,使學習出來的模型更加簡單和穩(wěn)健,防止過擬合,這是XGBoost優(yōu)于傳統(tǒng)GBDT的特性之一.在工程實現(xiàn)方面,XGBoost工具支持并行,其并行不是樹粒度層面上的,而是在特征粒度層面上的.眾所周知,決策樹學習最耗時的一個步驟就是根據(jù)特征的值對訓練樣本進行排序以確定最佳分割點,而XGBoost在訓練之前,預先對數(shù)據(jù)進行了排序,然后保存為block(塊)結(jié)構(gòu),后面的迭代中重復地使用這個結(jié)構(gòu),大大減小了計算量.這個block結(jié)構(gòu)也使得并行成為了可能,在進行節(jié)點的分裂時,需要計算每個特征的增益,即用貪心法枚舉所有可能的分割點,最終選增益最大的那個特征去做分裂,那么各個特征的增益計算就可以開多線程進行.XGBoost算法的主要步驟為:
(1)構(gòu)造目標損失函數(shù):
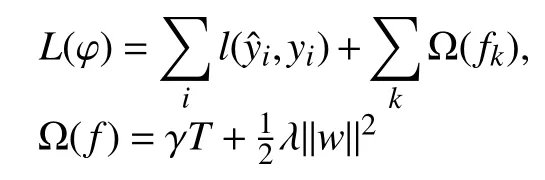
XGBoost在目標函數(shù)中加上了正則化項,基學器為CART(決策樹的一種)時,正則化項與樹的葉子節(jié)點的數(shù)量T以及葉子節(jié)點的值有關(guān).
(2)訓練目標函數(shù),將第t次的loss二次泰勒展開并掉常數(shù)項.
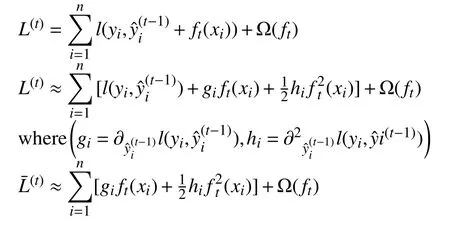
(3)求出目標函數(shù)最優(yōu)解:
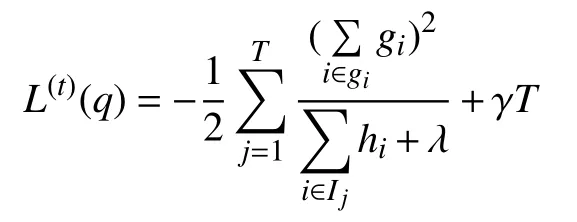
本文采用的是XGBoost的Python版本,其中重點關(guān)注的幾個超參數(shù)包括:
(1)Learning_rate:學習率.設(shè)置地相對小些可以讓模型學的更加精確.
(2)n_estimators:提升階段樹的最大迭代輪數(shù).這一參數(shù)和往往和學習率一起結(jié)合early_stopping_rouds參數(shù)使用,用來防止過擬合.
(3)early_stopping_rounds:當模型在指定驗證集上的表現(xiàn)不再提升時,停止迭代.
(4)max_depth:每顆決策樹的最大深度.這一參數(shù)限制了樹中的最多節(jié)點數(shù).值越小模型越保守.
(5)nthreads:并行訓練的最大進程數(shù).-1 代表無限制.
(6)min_child_weight:進一步分裂一個子節(jié)點的最小Hessian和.
4 實驗過程
4.1 建模框架
針對前文數(shù)據(jù)分析過程中提到的問題,為了保證模型預測性能良好的同時又兼顧模型迭代速度和節(jié)約內(nèi)存,筆者決定采用分而治之的思想,對類別特征建立利用FTRL算法優(yōu)化的Logistic Regression模型(以下簡稱 FTRL-LR),并利用 out-fold prediction (stacking 方法的本質(zhì)思想)[15]方法生成新特征.如此做的合理性有二,一是減少冗余的同時最大化分類特征信息,out-fod prediction生成的特征其實是一種滯后特征,它從分類特征中的學到最有用的信息并以單個特征儲存起來,可以去除特征中的隨機噪聲,提高了模型的魯棒性,二是間接達到模型集成的效果,如果將原始所有分類特征用XGBoost訓練,那么不僅增加了模型的復雜度,而且也沒有利用到模型集成的優(yōu)勢,也就是會忽略FTRL模型學習到的信息.
接下來將該特征和數(shù)值特征,時間序列特征以及人工特征一起建立XGBoost模型.利用XGBoost算法建立預測模型包含兩個階段.第一個階段是特征選擇階段,當XGBoost建模完成后,會返回一個特征重要性結(jié)果.XGBoost通過統(tǒng)計特征在每棵決策樹中被用來劃分數(shù)據(jù)的次數(shù),并用每次劃分所帶來的訓練損失減益來對特征劃分次數(shù)進行加權(quán)求和,最后再對所有樹求平均得到特征重要性.針對除類別特征外的所有特征(包括手工構(gòu)建的time_diff類特征)利用XGBoost進行特征選擇,選取特征重要性TOP200的特征,再和之前通過類別特征得到的一列數(shù)值特征一起作為最終XGBoost的建模特征.
對于模型的超參數(shù)選擇,本文采取貝葉斯最優(yōu)化來獲得.貝葉斯優(yōu)化用于機器學習調(diào)參由Snoek[16]提出,其主要思想是,給定優(yōu)化的目標函數(shù)(本文優(yōu)化的目標函數(shù)為訓練集三折交叉驗證的MCC得分),通過不斷地添加樣本點來更新目標函數(shù)的后驗分布(高斯過程),直到后驗分布基本貼合于真實分布.這種方法的優(yōu)勢包括由于其采用高斯過程,考慮之前的參數(shù)信息,不斷地更新先驗,這使得參迭選擇的代次數(shù)少,速度快,而且貝葉斯調(diào)參針對非凸問題依然穩(wěn)健,不容易陷入局部最優(yōu).
最終對于FTRL-RL模型,超參數(shù)設(shè)置分別為α=0.3284,β=0.6725,L1=5.698,L2=0.2587.對于預測階段的XGBoost模型超參數(shù)設(shè)置分別為learning_rate=0.05,max_depth=6,min_child_weight=1,n_estimators=1000,nthread=-1,early_stopping_rounds=50.
4.2 評價指標
MCC (Matthews Correlation Coefficient)[17]即馬修斯相關(guān)系數(shù)通常作為二分類問題的一個評價指標.二分類問題的預測結(jié)果中包含四種類型的樣本,分別是被模型分類正確的正樣本、被模型分類錯誤的正樣本、被模型分類錯誤的負樣本和被模型分類正確的負樣本,分別表示為TP、FN、FP和TN.MCC指標的計算公式為:
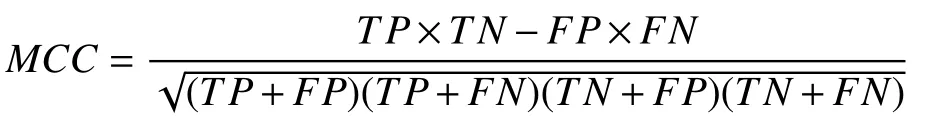
該指標綜合考慮了真陽性、真陰性和假陽性和假陰性,是一個比較均衡的指標,即使是在正負樣本量差別很大時,也能起到很好的衡量效果.由于本實驗的數(shù)據(jù)集正負樣本很不平衡,因此選用MCC作為我們的評價指標.由于最終預測模型的輸出結(jié)果為概率形式(產(chǎn)品發(fā)生故障的概率),因此為了得到最優(yōu)MCC值對應(yīng)的分類概率閾值,筆者通過計算不同閾值下訓練集的三折交叉驗證MCC得分,作出如圖3的關(guān)系曲線.我們可以發(fā)現(xiàn)最優(yōu)閾值0.2(比正常閾值選擇0.5低很多),對應(yīng)的訓練集三折交叉驗證MCC得分為0.25.
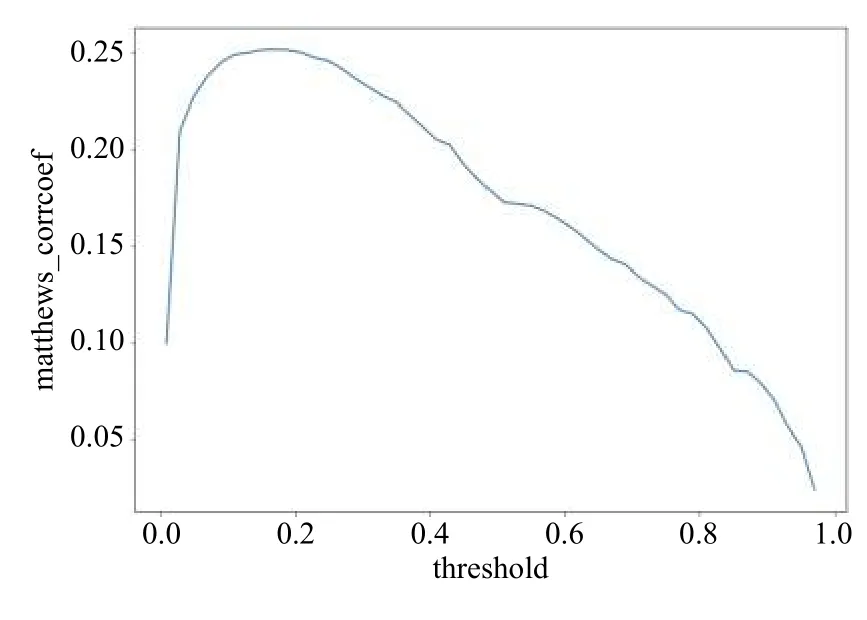
圖3 不同閾值下訓練集的三折交叉驗證MCC得分
4.3 實驗結(jié)果
本文的所有實驗(特征可視化,模型建立與衡量)都是在谷歌云實例上運行,其環(huán)境配置為Ubuntu 16.04,8 個 vCPU,52 GB 內(nèi)存,編程語言為 Python.若需實驗代碼,可向筆者索取.
表1為不同學習框架效果對比.通過對比可以發(fā)現(xiàn)FTRL和XGBoost相結(jié)合的預測框架預測效果最好.同時該預測框架也具有較好的可解釋性,最終XGBoost預測模型得出的重要特征包括生產(chǎn)線末期階段的一些特征,區(qū)分不同產(chǎn)品類型的時間差特征,由類別特征得到的數(shù)值特征.根據(jù)以上結(jié)果筆者推斷,不同的產(chǎn)品類型往往具有不同的故障發(fā)生率,一些需要更復雜的制造階段,生產(chǎn)更耗時的產(chǎn)品也通常更容易發(fā)生故障.
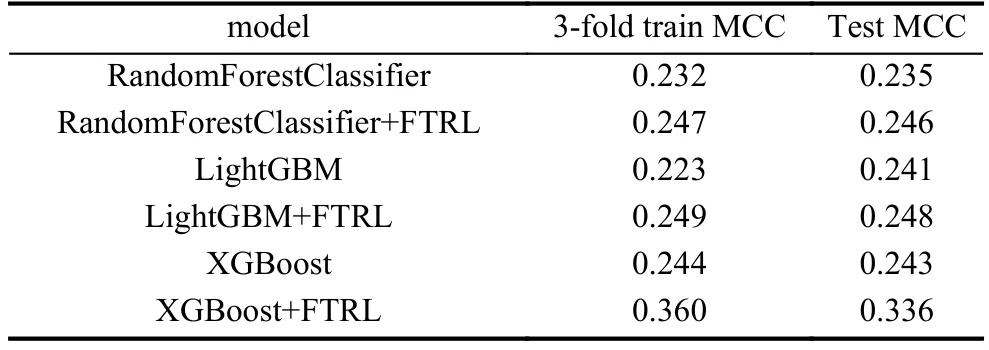
表1 不同學習框架效果對比
5 結(jié)論與展望
大數(shù)據(jù)時代,制造業(yè)已經(jīng)進入了生產(chǎn)智能化的發(fā)展階段,充分利用生產(chǎn)流水線上輸出的大數(shù)據(jù)加速這一進程變得至關(guān)重要.本文將FTRL-LR模型和XGBoost模型結(jié)合起來,充分利用各自的優(yōu)勢,建立了一個產(chǎn)品故障預測模型.實驗結(jié)果表明,此模型相比傳統(tǒng)的預測模型,具有預測精度高,泛化能力強,計算效率高,內(nèi)存耗用低,可解釋性強的優(yōu)勢.基于該模型,制造業(yè)可以提前預測產(chǎn)品生產(chǎn)過程中可能發(fā)生的故障,并對其及時進行修正.這種方法可以有效降低企業(yè)的生產(chǎn)成本和時間成本,實現(xiàn)更智能化的工廠作業(yè)流程.進一步地,由于原始數(shù)據(jù)集涉及大量不同類型的產(chǎn)品生產(chǎn),因此筆者發(fā)現(xiàn)還可以利用層次聚類的方法對不同的產(chǎn)品類型分別建模(在保障時間成本的前提下),實現(xiàn)更精細化的預測框架,所以未來本文的方法還有很大的提升空間.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數(shù)理化·七年級數(shù)學人教版(2020年10期)2020-11-26 08:24:50
數(shù)學物理學報(2020年2期)2020-06-02 11:29:24
汽車維修與保養(yǎng)(2019年7期)2020-01-06 03:30:42
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數(shù)學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
汽車維護與修理(2016年10期)2016-07-10 08:17:41
汽車維修與保養(yǎng)(2015年6期)2015-04-17 03:31:50
