基于雙向LSTM的動態情感詞典構建方法研究
2019-03-13 05:14:32李永帥王黎明柴玉梅
小型微型計算機系統 2019年3期
李永帥,王黎明,柴玉梅,劉 箴
1(鄭州大學 信息工程學院,鄭州 450001) 2(寧波大學 信息科學與工程學院,浙江 寧波 315211)
1 引 言
隨著社會媒體的快速發展,互聯網正改變著人們的生活方式,據官方統計,大約新浪微博每日增加的數量是一億條,這些微博更多的是表現出某個事件或者人或者產品的情感及情感傾向性.因此利用情感分析技術幫助去分析文本的情感,這將是很重要且很實用的一個環節,可以更好的快速的整理并分析這些信息,從而獲取輿論傾向性.為了能夠更好地研究情感分析[1],構建一個高質量的情感詞典往往是占據著很重要的地位,關系著情感分類的質量好壞,一個好的全的情感詞典能夠更好的提供比較全面的情感信息,可以有效的幫助提高情感分析的質量.
在國外代表性的英文詞典有GI(General Inquirer),該詞典收錄1914個褒義詞和2293個貶義詞,并為每個詞語按照極性、強度、詞性等打上不同的標簽;還有主觀詞詞典.該詞典主觀詞語來自OpinionFinder系統,該詞典含有8211個主觀詞,并為每個詞語標注了詞性、詞性還原以及情感極性;在國內比較知名的中文情感詞典有HowNet情感詞典,包含9193個褒義詞和貶義詞;還有NTU評價詞詞典(繁體中文),該詞典由臺灣大學收錄,含有2812褒義詞與8276個貶義詞.本文把預先被標記好了其詞情感極性信息的情感詞典稱作靜態詞典.但目前的靜態情感詞典在情感分析中存在以下幾點不足:
1)一些中性詞也能表達出情感色彩.比如現實,噪音,浮云等也能表達出情感詞的效果.
2)對于本身沒有情感意義的詞匯,當加入一些肯定詞或否定詞時,會表現為具有情感意義的效果.比如:意義->有意義,問題->有問題.
3)對于動態極性詞,不同的詞組其極性是不一樣的.動態極性詞和不同的詞組搭配會出現不同的情感極性,比如,油耗高和效率高有著相反的極性.
4)沒有涵蓋流行詞匯.比如,你腦子“瓦特”了,“涼涼”等詞匯.
5)對于本來有情感意義的詞匯,有時未必表現出情感色彩.比如:好難受,其中“好”并未表現出褒義的色彩.

圖1 情感詞典構建基本思路框架圖Fig.1 Basic frame diagram of the emotion dictionary construction
以上不足都是傳統的靜態詞典無法體現的,為了解決上述問題,本文提出了動態情感詞典構建的方法,如圖1所示,主要包括三層神經網絡:1)第一層利用ECBOW模型對情感特征進行提取,該模型是基于CBOW模型基礎之上的;2)第二層在本文構建的二叉語義依存樹基礎上,利用語義依存分析模型通過雙向LSTM神經網絡[10-12]對二叉語義依存路徑特征提取;3)在第三層,利用獲取到的情感特征和二叉語義依存路徑特征加上中心詞信息和相對位置特征一起組成當前詞的特征作為另一個雙向LSTM神經網絡的輸入,并通過標簽框架標注輸出情感詞信息,最終訓練出情感詞分類器即動態情感詞典.
2 相關工作
情感詞典的構建在情感分析的過程中占據著重要的地位,目前情感詞典構建的研究主要包括基于語料庫、基于圖模型以及基于詞對齊模型的方法.宋佳穎等人[2]以PolarityRank算法為基礎,面向產品評價文本展開漢語領域動態極性詞典擴展研究.杜偉夫等人[3]提出一個可擴展的詞匯語義計算框架,把詞語語義傾向計算問題看成對其優化的問題.Duyu Tang等人[8]利用改進的Skip-Gram模型獲得情感詞向量,并借助Urban Dictionary來構建情感詞典.郗亞輝[5]基于約束的標簽傳播算法來計算情感詞的情感傾向從而構建情感詞典.趙妍妍等人[6]利用微博上的表情符獲取情感詞,然后利用點互信息計算公式計算相應情感值.Mohammad等人[7]利用每個詞和種子情感詞的點互信息來構建情感詞典.尹文科等人[9]利用Wiki百科中的鏈接結構通過有權無向圖的團滲透方法CPMw進行詞匯聚類構建出領域詞典.
以上方法構建出來的情感詞典都有引言中所述的缺點,在文本中不能很好的表現出詞匯情感信息,為了解決這些問題,本文首先獲取情感特征,Zhiyang等人[4]已經證明情感特征在雙向LSTM中可以有效的提升情感分類準確率;由于錢忠等人[14]利用句法結構路徑特征等多種信息對詞匯序列化標注任務獲得了很好的實驗效果,本文提出了二叉語義依存分析模型來獲取二叉語義依存路徑特征;然后以情感特征、二叉語義依存路徑特征、中心詞信息和相對位置特征作為輸入,以雙向LSTM神經網絡作為情感詞分類器,訓練得到動態情感詞典.
3 基于雙向LSTM的動態情感詞典的構建
本節將詳細介紹基于雙向LSTM動態情感詞典的構建方法,首先通過ECBOW神經網絡對詞向量的情感特征進行抽取,然后建立一個可以描述語義依存結構分析的二叉樹,本文規定二叉樹的根節點為整句的中心詞,通過把雙向LSTM神經網絡應用到二叉語義依存分析模型去學習二叉語義依存路徑特征;接下來依次獲取中心詞信息和相對位置特征;最后利用本文設計的標簽框架作為雙向LSTM的輸出,把情感詞特征、二叉語義依存路徑特征、中心詞信息和相對位置特征結合起來作為輸入,最后將其訓練成為一個情感詞分類器,從而達到動態情感詞典構建的目的.
3.1 詞匯的情感特征提取
Google的開源工具word2vec[15-17]中用到兩個神經網絡模型,一個是Skip-Gram神經網絡模型,另外一個是CBOW神經網絡模型.本節選取CBOW神經網絡模型作為改進目標對象并抽取詞匯的情感特征.
3.1.1 利用CBOW神經網絡模型進行詞向量學習
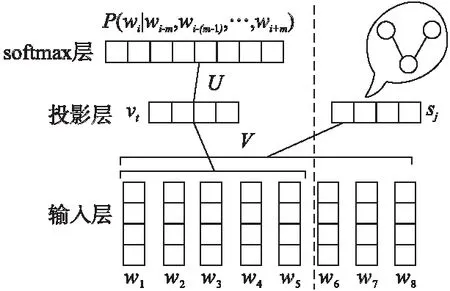
圖2 ECBOW模型圖Fig.2 ECBOW Model
CBOW神經網絡模型的工作原理是根據上下文的詞語預測當前詞語的出現概率的模型.如圖2左半部分所示,該模型分為輸入層、投影層和softmax層,語料C中每個詞匯w代表文本中的one-hot向量并作為輸入層,V代表是一個n×|V|詞向量表;在投影層經過矩陣轉換為相同的n維向量的疊加,即:
(1)
在這里設置m=2.在輸出層輸出最可能的w,也就是最大似然化函數:
(2)
3.1.2 通過ECBOW模型提取情感特征
ECBOW模型是對CBOW模型進行的改進模型,主要改進如圖2右半部分所示,在原來的CBOW模型下增添了一部分網絡結構,其目的是提取有效的情感特征.其原理為:在原來的CBOW模型做一個基本的句法結構約束,然后通過具有褒貶意義的文本,對其情感進行約束.具體過程如下描述:
在新增的網絡結構中,輸入層為褒貶意義的文本中所有詞w,投影層sj表示具有褒貶意義的文本中所有詞的one-hot向量經過詞向量表V轉化為詞向量并求和而得到的,即:
(3)
對于輸出層來說,因為只有褒貶二元分類,因此通過一個邏輯神經元來計算輸出為褒義和貶義的概率,如公式(4)所示:
(4)
其中H為向量參數,記p(sj)為文本褒貶性,如果投影層sj是由褒義文本所投影,那么p(sj)=[1,0];如果投影層sj是由褒義文本所投影,那么p(sj)=[0,1].從而最大化目標函數為:
(5)
具體的ADDEMOTION算法如算法1所示.
算法1.基于ECBOW模型情感表示(ADDEMOTION算法)
1) 語料預處理
2) 收集詞語,創建詞典
3) 初始化參數:θ:(U,V,α,η)、e、H、w、xs
4)while不收斂do
5)forsjinSdo
6)forallwt-2,wt-1,wt,wt+1,wt+2do
8)end
9)p=σ(xs·H)
10)e=e+η(hj-p)·H
11)H=H+η(hj-p)·xs
12)forw∈sjdo
13)V(w)=V(w)+(1-α)e
14)end
15)end
16)end
其中S表示訓練集的所有句子集合,θ參數包括U、V、α、η,U為圖2的左半部分投影層到softmax層向量參數;α為權重參數;η為學習速率;e為向量變化的大小;其中:
(6)
V(w)表示詞匯w的向量;
(7)
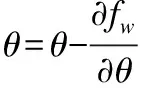
3.2 利用雙向LSTM提取二叉語義依存路徑特征
本節首先根據一個二叉樹來描述語義依存關系,并通過哈夫曼編碼記住二叉樹結構,然后通過二叉語義依存路徑信息,利用雙向LSTM神經網絡模型對每個詞的二叉語義依存路徑信息特征學習,為后面對情感詞標簽識別提供有效的特征.本文記哈夫曼語義依存結構二叉樹路徑為二叉語義依存路徑.
3.2.1 哈夫曼語義依存二叉樹
哈夫曼語義依存結構二叉樹是由詞匯節點和詞匯依存關系以及哈夫曼編碼所描述的,在講哈夫曼語義依存結構二叉樹分析之前首先解釋下該二叉樹構建方法,如圖3所示,首先按照文本序列把相鄰具有依存關系的詞節點進行合并,合并后生成的父節點為被依存的詞節點,依次類推直到把所有節點合并為一顆二叉樹.其中詞匯之間的語義依存關系以及二叉樹部分結構描述由二元組T=<“依存關系”,“哈夫曼編碼”>所描述,NULL表示依存關系為自己,哈夫曼編碼為0表示從該節點往左生成子節點,哈夫曼編碼為1表示從該節點往右生成子節點.被依存的詞匯作為生成的父節點,其左子節點到父節點如果依存關系存在,那么兩節點之間路徑被描述為<“依存關系”,0>,如果不存在,那么兩節點之間路徑被描述為
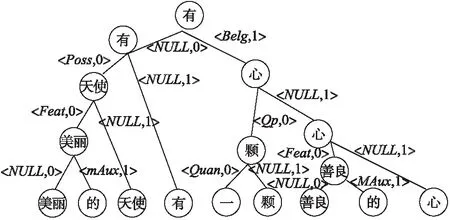
圖3 語義依存結構二叉樹圖Fig.3 Semantic dependent two forked tree structure
3.2.2 二叉語義依存路徑表示
由于中心詞通常可以代表短語主要語法、語義特征,它被認為具有較強的預測能力[18].因此選取整句話的中心詞為路徑終點即二叉樹根節點,從每句話的詞葉子節點到中心詞的路徑被稱作每個詞的二叉語義依存路徑,如“美麗”對應的路徑信息為“美麗
3.2.3 提取二叉語義依存路徑特征
LSTM是循環神經網絡[10]中的一個特殊網絡,它能夠很好的處理序列信息并從中學習有效特征[13],它把以往的神經單元用一個記憶單元(memory cell)來代替,解決了以往循環神經網絡在梯度反向傳播中遇到的爆炸和衰減問題.一個記憶單元利用了輸入門it、一個記憶細胞ct、一個忘記門ft、一個輸出門ot來控制歷史信息的儲存記憶,在每次輸入后會有一個當前狀態ht,ht計算如下:
it=σ(Wixt+Uiht-1+Vict-1+bi)
(8)
ft=1.0-it
(9)
gt=tanh(Wgxt+Ught-1+bg)
(10)
ct=ft?ct-1+it?gt
(11)
ot=σ(Woxt+Uoht-1+Voct+bo)
(12)
ht=ot?tanh(ct)
(13)
其中,xt為t時刻輸入的情感詞向量,σ為sigmoid函數,?代表向量對應元素依次相乘,其中水電費Wi,Ui,Vi,bi,Wg,Ug,bg,Wo,Uo,Vo,bo為LSTM參數.

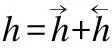
(14)
二叉語義結構模型可以定義為整句話詞節點路徑的概率的乘積:
(15)
其中,wi表示語義依存二叉樹中的葉子節點.L表示wi的路徑信息.PL(wi)表示該節點wi的路徑發生概率.利用該模型借助雙向LSTM對該二叉語義依存路徑特征提取,如圖4所示,輸入層表示每個詞的詞向量,然后經過雙向LSTM神經網路輸出并進入特征層,其向量表示為fp,它的維度大小為np,最后進入softmax層表示該詞節點二叉語義依存路徑的概率,通過最大化目標函數使該神經網絡收斂.最后得到每個詞所對應的二叉語義依存路徑特征.
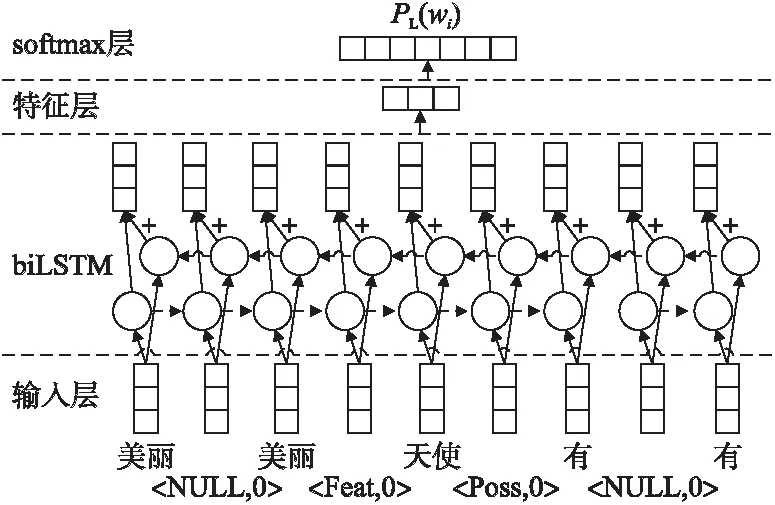
圖4 利用雙向LSTM神經網絡抽取二叉語義依存路徑特征圖Fig.4 Using bidirectional LSTM neural network to extract path characteristics of two fork semantic dependency
(16)
3.3 相對位置和句子中心詞信息
中心詞通常可以代表短語的主要語法、語義特征,它被認為具有較強的預測能力.因此決定把文本中每個詞匯到整個句子的中心詞的距離計算出來,如“美麗”到中心詞“有”的距離dm=-3.相對位置特征被映射為一個nrp維的向量frp.
中心詞信息用以表示當前詞是否為中心詞,如果當前詞為中心詞,那么該特征的取值為一個特殊的詞語“cue”;如果當前詞不為中心詞,那么該特征的取值為一另外一個特殊的詞語“not_cue”,線索詞信息被映射為一個nc維的向量fc.
3.4 情感詞典分類器構建
本文將情感詞典分類器(如圖5所示)構建問題看成是序列標注問題,對于每一個詞語,本文考慮其四個特征:情感詞特征表示fe、二叉語義依存路徑特征fp、中心詞信息fc和相對位置特征frp.因此詞語的特征f0表示為:
(17)
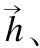
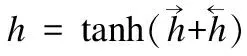
(18)
3.4.1 文本標簽框架
本文的情感詞性特征提取,采用文本標簽框架來提取,本文采用的文本標簽框架為本文定義的PNO框架,記框架標簽Ti∈{P,N,O},其中標簽集合解釋:如果在文本中一個詞表現出有褒義情感色彩的詞匯,那么這個詞被標記為P;如果在文本中一個詞表現出貶義情感色彩的詞匯,那么這個詞標記為N;如果在文本中既不表現褒義情感色彩又不表現貶義情感色彩,那么這個詞被標記為O;例句1 顯示文本中每個詞匯的標簽:
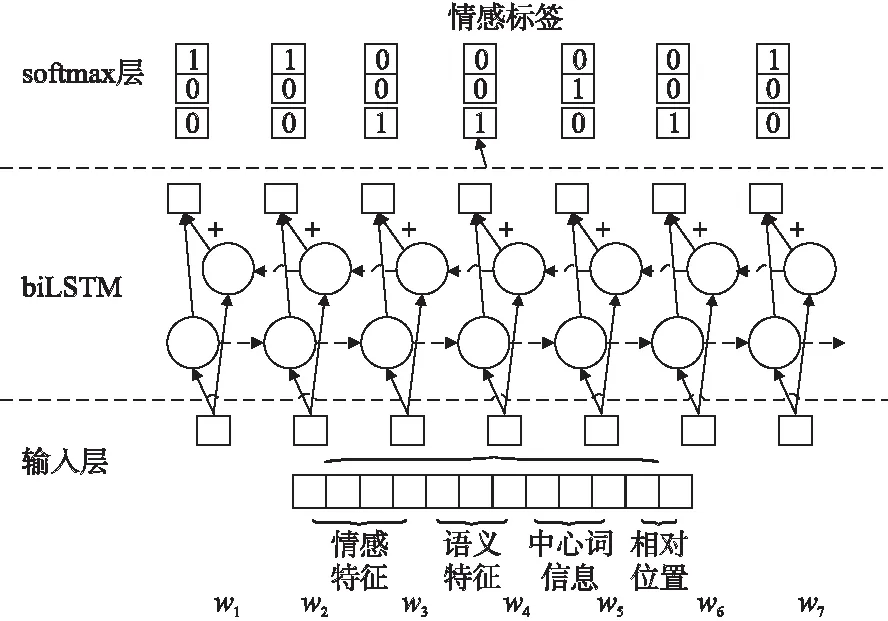
圖5 利用雙向LSTM神經網絡構建情感詞分類器圖Fig.5 Using bidirectional LSTM neural network to construct emotional word classifier
例句1 這/O 場/O 比賽/O 打的/O 真/O 委屈/N,/O 隊員/O 的/O 整個/O 狀態/O 也/O 很/O 差/N !
本文把不同的標簽映射為一個維度大小為3的詞向量的長度.
3.4.2 輸出層表示
進入輸出層,其計算公式為:
O=softmax(Wsh+bs)
(19)
在輸出層有每個輸出節點的維度大小為3,因此分別用[1,0,0]、[0,1,0]、[0,0,1]分別代表該詞匯的輸出結果為褒義(P)、貶義(N)、中性(O);在這一層的輸出做了一個softmax處理,通過這一步求取輸出屬于某一類的概率,如公式(20):
(20)
本文采用損失函數交叉熵作為目標函數,如公式(21)所示:
(21)
其中:yti指代在t時刻實際的標簽中第i個值,preti指代在t時刻預測的標簽中第i個值.
經過訓練出來的雙向LSTM神經網絡情感詞分類器即動態情感詞典,然后利用測試數據進行初級擴展得到動態情感詞典,如果該詞匯所輸出的標簽為P,那么該詞匯被判定為褒義情感詞,如果該詞匯所輸出的標簽為N,那么該詞匯被判定為貶義情感詞,如果該詞匯所輸出的標簽為O,那么該詞匯被判定為中性詞.
算法2.情感詞典初級擴展算法
輸入:詞語的特征f0、訓練文本集Stest、測試文本集Strain
輸出:輸出褒義詞典Dpos和貶義詞典Dneg
1)while不收斂do
2)forwinsj∈Straindo
3)optimizebiLSTM(e(w),Tag(w))
4)end
5)end
6)forwinsi∈Stestdo
7)pTag=biLSTM(e(w))
8)ifpTag=[1,0,0]do
9)Dpos.append(w)
10)end
11)ifpTag=[0,1,0]do
12)Dneg.append(w)
13)end
14)end
其中:e(w)∈Dp,對于上述算法首先先用本文構造的雙向LSTM模型對訓練文本集進行訓練,從而完成動態情感詞典的構建,然后對測試文本集進行預測,預測為P標簽將被判斷其為褒義情感詞,并把褒義情感詞存入褒義詞典Dpos;預測為N標簽的將被判斷其為貶義情感詞,并把貶義情感詞存入貶義詞典Dneg;預測為O標簽的將被判斷其為中性詞,最后得到初級擴展的靜態情感詞典.
4 實驗與分析
在文本只有起到情感色彩的詞匯叫做情感詞,本文規定情感詞由情感詞主體和副體組成,其副體可為空.比如在“我們的做法是很有意義的.”一句話中“有意義”表現出褒義情感色彩,其中“有”為副體,“意義”為主體,然而有的中性詞卻能表達出情感色彩,比如:當在“問題”前加上“有”的時候,卻能表現出貶義的情感色彩,因此對某些中性詞在句子中卻能表達出情感色彩時,本文規定這些詞為中性情感詞.因此規定情感詞分為褒義情感詞、貶義情感詞、中性情感詞.如圖6所示.

圖6 情感詞分類圖Fig.6 Classification of emotional words
4.1 測試數據
為了反映微博數據的真實性,隨機挑選微博語料9836條微博作為測試數據集,并將該數據集利用哈工大語言平臺中的分詞功能和語義依存分析功能將數據集進行分詞和語義依存二叉樹的構建.首先,對輸出標簽進行標注,在標注時請了五位標注者同時對這些微博數據進行人工標注.標注者根據微博文本中情感詞匯的情感傾向性將文本中具有情感的詞標注出來,若有標注不一致的情況,則使用投票的方法決定詞匯的情感傾向性.利用哈工大語言云平臺的語義依存樹功能將該數據集進行二叉樹構建,并人工核查,對語義依存關系不正確的地方進行修改,最終由五位標注者協商決定.
最后統計這9836條微博中所有標注的情感詞,這些微博數據的人工標注結果統計如表1所示.
表1 人工標注統計結果表
Table 1 Artificial selection result statistics

微博情感詞數據集標注褒義情感詞貶義情感詞中性情感詞總和10395892139819714
4.2 不同特征組合對動態情感詞典的影響
鑒于語料規模有限,本文使用十折交叉驗證的方法來進行驗證,對微博語料中情感詞進行褒義情感詞、貶義情感詞、中性情感詞和中性詞的四元情感分類,其中,中性情感詞的分類具體過程是,如果該詞匯在本句話中被確認為具有情感傾向性,而單獨拿出來的時候沒有情感傾向性,那么該詞被認為中性情感詞.
1)EWR(情感詞特征)+SR(二叉語義依存路徑特征)+TR(相對位置和中心詞信息)+TRAIN(訓練集):表示在基于ECBOW模型情感特征的基礎上,進行添加語義特征、相對位置特征和中心詞信息一起組成為該詞特征,并取出訓練集1萬句進行各種指標計算.
2)EWR+SR+TR+TEST(測試集):表示在基于情感特征的基礎上,進行添加二叉語義依存路徑特征、相對位置特征和中心詞信息一起組成為該詞特征,并用測試集進行各種指標計算.
3)WR+SR+TR+TEST:表示在基于CBOW模型下特征向量基礎上,進行添加二叉語義依存路徑特征、相對位置特征和中心詞信息一起組成為該詞特征,并用測試集進行各種指標計算.
4)EWR+SR+TEST:表示在基于情感特征的基礎上,只添加二叉語義依存路徑特征一起組成為該詞特征,并用測試集進行各種指標計算.
5)EWR+TR+TEST:表示在基于情感特征的基礎上,只添加相對位置特征和中心詞信息一起組成為該詞特征,并用測試集進行各種指標計算.
如表2所示,可知以上各種方法測試其精確率均達到97%以上,證明本文構建的動態情感詞典總體上對情感詞和中性詞識別度比較高.然而更為關心的是其識別出情感詞的精準率,從上表數據可知實驗1是基于ECBOW模型構造的情感特征的基礎,并同時添加二叉語義依存路徑特征、相對位置特征和中心詞信息,可以發現其訓練數據集的精準率略高于實驗2測試數據集的精準率,提高了1.68%,其召回率提高了2.7%;同時發現實驗3在沒有加入情感特征的組合所得的測試數據集的精準率明顯低于其加入情感特征的組合,其精準率降低了10.76%,召回率降低了9.28%,這種現象說明情感特征對判別詞匯是否存在情感傾向性所占權重比較大;實驗4在基于ECBOW模型構造的情感特征基礎上,只加入二叉語義依存路徑特征,不加入中心詞信息和相對位置特征,可以發現其精準率相對實驗2其精準率下降了1.99%,召回率下降了1.56%,由此可以發現文本中心詞可以提供具有很好的預測能力;實驗5是基于ECBOW模型構造的情感特征的基礎上,只加有相對位置和中心詞信息而沒有二叉語義依存路徑特征,發現其精準率相對實驗2其精準率下降了4.94%,召回率下降了5.18%,證明二叉語義依存路徑特征有一大部分影響到情感詞識別的能力,證明二叉語義依存路徑特征是一個很有用的信息特征.
表2 不同特征組合對比表
Table 2 Different feature combination contrast table
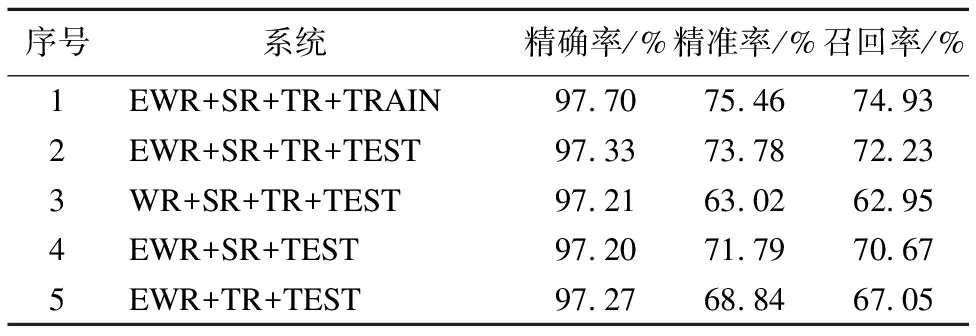
序號 系統精確率/%精準率/%召回率/%1EWR+SR+TR+TRAIN97.7075.4674.932EWR+SR+TR+TEST97.3373.7872.233WR+SR+TR+TEST97.2163.0262.954EWR+SR+TEST97.2071.7970.675EWR+TR+TEST97.2768.8467.05
4.3 驗證動態情感詞典可擴展性
本文用另外13821條測試微博數據作為測試集來進行驗證動態情感詞典擴展效果,其中EWR+SR+TR+NUM表示:在基于情感詞特征并結合二叉語義路徑特征、中心詞信息和相對位置特征的雙向LSTM模型下,對NUM條測試微博數據進行測試,從而來觀察其情感詞的擴展效果;比如,EWR+SR+TR+2000表示用了2000條微博測試數據,針對這2000條測試微博所產生出來的情感詞判斷其是否和原來標注的情感詞一樣,還是這些情感詞并不在原來標注的情感詞里面而是新增加擴展出來的情感詞.通過表1人工標注去除重復的情感詞后所得到的情感詞統計結果如表3所示.
表3 標注統計情感詞典
Table 3 Annotation of statistical affective dictionary

褒義情感詞貶義情感詞中性情感詞總和379826352646697
在進行每次依次遞增測試數據后都保留下分類出來的情感詞,在情感詞去重后進行人工挑選,不是情感詞的詞匯舍棄,然后統計出擴展出來的新的情感詞匯,每次結果統計如圖7所示,表示是通過依次增加取微博的數量的基礎上統計出來新擴展出來的情感詞的變化.
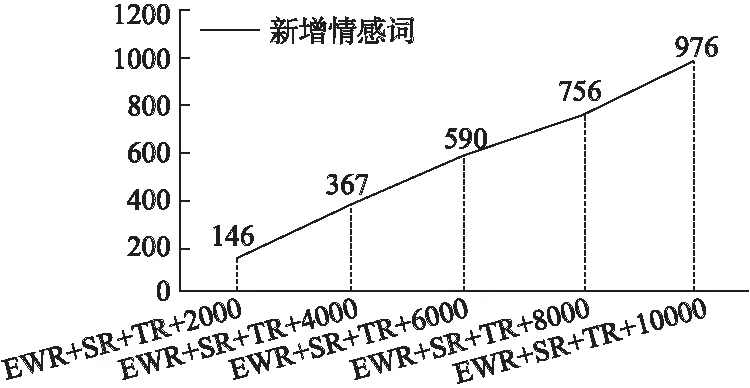
圖7 新增情感詞隨測試數據集變化Fig.7 New emotion words change with the test data set
由上圖可知,隨著測試數據集的增加新增情感詞在不斷增加,當增加測試集到1萬條微博數據時,最終統計得到的擴展出來的新詞匯數量為976個,表明動態情感詞典方法是有效的.最終得到如表4所示的較小規模情感詞典WB-Lex.
表4 較小規模靜態情感詞典WB-Lex
Table 4 Small scale static emotion dictionary WB-Lex

褒義情感詞貶義情感詞中性情感詞總和429930113657673
4.4 驗證得到的動態情感詞典有效性
在得到動態情感詞典后,為了驗證詞典質量,本文用情感分析的經典任務-情感分析,具體做法為判斷一條微博的情感傾向為褒義、貶義還是中性.本文的做法是用所構建的動態情感詞典與其他詞典進行對比,除了本文構建的動態詞典外還使用了其他四個開源的情感詞典資源,他們分別來自清華、北大、大連理工及知網,詳見表5.
表5 詞典規模統計
Table 5 Dictionary scale statistic

詞典褒義貶義總和清華(Tsinghua)5567446810035北大(Peking)95420515大連理工(DUT)110431064621689HowNet452843208848
為了對比本文構建的情感詞典與其他的情感詞典資源的性能,本文將其用于情感分類任務上,并選擇了簡單有效的基于特征分類的情感分類模型SVM.具體的,針對一條微博,提取的特征除了正規化后的情感詞向量,還加入了兩維特征分別是該微博中包含詞典中的褒義詞的個數與貶義詞個數.
1)ECBOW(情感詞特征)+ALL(all lexicon):表示在ECBOW模型下情感特征基礎上使用全部的情感詞典資源;
2)ECBOW+ALL-Our:表示在ECBOW模型下情感特征基礎上除去情感資源(動態情感詞典)的全部的情感詞典資源;
3)ECBOW+ALL-HowNet:表示在ECBOW模型下情感特征基礎上除去知網的情感資源的全部的情感詞典資源;
4)ECBOW+ALL-DUT:表示在ECBOW模型下情感特征基礎上除去大連理工的情感資源的全部的情感詞典資源;
5)ECBOW+ALL-Peking:表示在ECBOW模型下情感特征基礎上除去北京大學的情感資源的全部的情感詞典資源;
6)ECBOW+ALL-Tsinghua:表示在ECBOW模型下情感特征基礎上除去清華大學的情感資源的全部的情感詞典資源.
各詞典的性能對比詳見表6.通過分析表6可知,本文的動態構建情感詞典的性能要顯著優于其他四類情感詞典.主要原因是由于大多中性情感詞的影響.比如對于一般情感微博語句“上場 對 澳大利亞 還 貌似 不錯 來著,昨晚 看得 不是 一般 的 郁悶 啊!”各個情感詞典能判斷出“不錯”為褒義情感詞,“郁悶”為貶義情感詞,但是當面對這些語句的時候“參加 體育 運動 是 一件 有 意義 的 事情 !”,更多的情感詞典會把“意義”字識別為中性詞,從而失去了對這句話的真正理解,然而對于本文所構建的動態情感詞典來說可以把“意義”標記為褒義情感詞,從而進一步理解語句想要表達的真正意思.但是從表6也可以發現,本文的情感詞典并不能夠完全替代其他四類情感詞典.在使用了本文構建的情感詞典的基礎上再使用其他的情感詞典資源,對情感分類的性能仍能有一定的提升.
表6 各情感詞典性能對比
Table 6 Performance comparison of various affective dictionaries

系統Accuracy/% ECBOW+ALL68.71 ECBOW+ALL-Our65.73 ECBOW+ALL-HowNet67.96 ECBOW+ALL-DUT68.21 ECBOW+ALL-Peking67.99 ECBOW+ALL-Tsinghua67.86
5 結 論
為了解決現有的中文情感詞典的一些存在的問題,比如:對于一些中性詞雖然單獨使用時沒有什么情感色彩,但是放到整句話里卻能表達出情感色彩,以及當有些詞匯之前加入肯定或否定的詞時卻突顯出情感色彩,還有平常的一些極性情感詞和一些流行的網絡詞匯“給力”,本研究的情感詞典擴展方法很好的解決了這些問題,該動態情感詞典擴展方法基于雙向LSTM神經非網絡模型,不僅考慮到情感特征,還考慮了語義依存特征、中心詞信息、和相對位置特征,從而使動態標注情感詞及詞典擴展時提供了很好的幫助.實驗結果表明該方法對測試集情感詞識別的精準率達到73.78%之高,然后對另外1萬句測試微博,擴展出新情感詞匯976個,最后在文本情感分類任務也表明本文所構建的動態情感詞典可以在情感分類任務中起到重要的作用,能夠顯著的提高在情感分類任務的性能.
猜你喜歡
中華胰腺病雜志(2021年1期)2021-02-26 11:28:36
山東醫藥(2020年34期)2020-12-09 01:22:24
開放教育研究(2020年2期)2020-03-31 01:54:14
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中華胰腺病雜志(2019年4期)2019-08-29 08:52:20
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
現代語文(2016年21期)2016-05-25 13:13:44
大連民族大學學報(2015年2期)2015-02-27 08:28:11
河南科技(2014年23期)2014-02-27 14:19:15
