再入飛行器自適應最優姿態控制
2019-03-14 09:48:06張振寧聶文明李惠峰
宇航學報 2019年2期
張振寧,張 冉,聶文明,李惠峰
(北京航空航天大學宇航學院,北京100191)
0 引 言
航天任務中,姿態控制器的設計是飛行器設計的關鍵環節之一,其控制性能與任務能否成功密切相關。姿態控制精度、收斂時間、控制量需求是衡量控制性能的主要因素。目前,再入飛行器的姿態控制器設計思路主要有兩種。一是線性設計方法,對飛行器原始模型在選定工作點處進行小擾動線性化,采用線性系統理論及增益整定得到全彈道控制器[1]。但再入飛行包線大,速度通常在5馬赫以上,存在極強非線性特征,因此在機動過程中采用線性控制器容易產生失穩現象。二是非線性設計方法,它一定程度上體現了模型中的非線性因素,如:反饋線性化方法[2-3]通過嚴格的狀態變化與反饋將非線性系統代數地轉化為線性系統,再應用線性系統理論設計控制器,但有相當多的系統無法進行反饋線性化;反步法[3]通過對系統進行多步遞推設計,獲得較好的全局或局部穩定性,但容易發生微分膨脹現象;滑模法[5-6]以一階鎮定問題取代原高階跟蹤問題,設計過程比較簡單且性能很好,文獻[7]還用神經網絡對估計模型、耦合等擾動進行估計,進一步改善了控制性能,但該方法容易出現控制量的顫振。
近年來,最優控制理論已成為現代控制系統設計的基礎理論之一。針對再入飛行器的姿態控制,通過最優控制理論設計控制器可以最大程度優化舵面偏轉量、姿態跟蹤精度和速度等性能。動態規劃作為一種傳統的最優控制問題求解方法,由于“維數災難”導致Hamilton-Jacobian-Bellman(HJB)方程難以直接求解。隨著計算技術的不斷進步,求解HJB方程的迭代方法得到廣泛探索。Werbos[8]首先提出了自適應動態規劃(Adaptive dynamic programming,ADP),建立執行-評價估計結構,并通過值迭代方法求解。Al-Tamimi等[9]證明了這種方法在離散系統上的收斂性。 近幾年,Xu等[10]、Lakshmikanth等[11]學者將該方法直接應用于連續系統,但對數據采樣時間的苛刻要求導致算法收斂性難以保證,且加重了計算負擔。為使連續系統的HJB方程求解更加穩定,基于策略迭代提出的積分型強化學習(Integral reinforcement learning,IRL)算法作為一種新興算法受到廣泛關注[12-13],該算法采用評價和執行兩個網絡分別估計值函數和控制策略,并同時更新直到兩個網絡均收斂到最優。Modares等[14]針對最優跟蹤問題,提出了一種非二次型的代價函數,采用IRL算法完成了跟蹤控制器的設計;Wang等[15]在Modares等[14]工作的基礎上通過修改代價函數設計了魯棒跟蹤控制器; Lee等[16]對IRL算法的收斂性進行了深入研究,并提出了四種衍生算法;Song等[17]通過將Off-Policy與IRL算法結合,大大減弱了控制器對模型的依賴性。以上研究均采用執行-評價雙網絡結構對HJB方程進行求解,但雙網絡結構的計算效率和所占用的存儲空間不能滿足目前再入飛行器姿態控制器的設計要求。
本文提出了單網絡積分型強化學習(Single-network integral reinforcement learning, SNIRL)算法,將原評價-執行結構中執行網絡的迭代過程用解析式表達,保留評價網絡的迭代對值函數進行估計,減少了近一半的計算量和存儲空間。該算法的收斂性及閉環系統的穩定性均通過李雅普諾夫穩定性理論得到了證明。
本文的結構如下:第1節構建再入飛行器的最優姿態控制問題;第2節在策略迭代框架下用評價網絡估計值函數,采用SNIRL算法求解最優控制問題,設計姿態控制器;第3節給出算法收斂性和系統穩定性證明;第4節進行縱向和橫側向姿態控制仿真。
1 問題描述
從最優控制角度出發,將再入飛行器的姿態控制問題建模為最優控制問題。
參考文獻[18],用于控制器設計的再入飛行器模型為
(1)
式中:α為攻角,β為側滑角,μ為傾側角,p為偏航角速率,q為俯仰角速率,q為滾轉角速率;g為地球引力加速度,取常值;Ix,Iy,Ixz為轉動慣量,也為常值;Z為升力,Y為橫向力,L為滾轉力矩,N為偏航力矩,M為俯仰力矩,X(·)表示X對(·)的偏導數(例如Mα表示俯仰力矩對攻角的偏導數)。
該模型是在原始模型上進行適當簡化后的仿射模型,不包含速度及位置的相關狀態,控制量顯式出現在方程中,可簡寫為
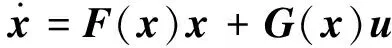
(2)
式中:x∈Rn為狀態量,u∈Rm為控制輸入;F(x)∈Rn,G(x)∈Rn×m是只與x相關的非線性函數。
最優控制策略可以通過最小化某個人為選擇的代價函數V(在ADP中也稱為值函數)得到,V的形式為
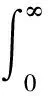
(3)
式中:
r(x,u)=Q(x)+uTRu
(4)
最優控制問題描述為:對于由方程組(2)定義的系統,尋找最優控制策略u*,最小化代價函數(3)。
容許控制[19]定義為:若F+Gu在集合Ω∈RN上連續,μ在Ω上連續且μ(0)=0,若μ在Ω上鎮定系統(2)且對?x0∈Ω,V(x0)有界,則稱μ容許控制,記作μ∈Ψ(Ω)。
對μ∈Ψ(Ω),可以將式(3)轉化為極小形式,它是一個李雅普諾夫方程
(5)
式中:Vx表示V對x的偏導。
這個無限時間最優控制問題的哈密頓方程為
(6)
根據極大值原理,最優控制μ*可通過最小化式(6)得到。實際上對形如式(2)的系統,對式(6)應用駐點條件,能得到最優控制策略與最優代價函數的關系,為
(7)
(8)
2 自適應最優姿態控制器設計
將策略迭代作為算法框架,保證迭代計算結果向最優控制律收斂;設計評價網絡,在迭代計算中估計值函數;最后提出SNIRL算法使估計值向最優值收斂,完成求解,得到自適應最優控制器。
2.1 策略迭代
策略迭代是利用強化學習求解最優控制問題的一種迭代方法。具體過程為:
(1)確定當前控制策略下的值函數
(9)
(2)求解最小化哈密頓方程的控制策略,并對當前控制策略進行更新
(10)
事實上,對系統(2),通過式(10)可以解析得到
(11)
(3)在步驟(1)和步驟(2)之間不斷迭代直至收斂。
當初始控制策略為容許控制時,該算法過程中的每次迭代都會使得控制策略向更優的方向收斂,并最終收斂到最優控制策略u*(x)以及相應的最優代價函數V*(x)。該算法的收斂性在早年文獻中已有證明[21]。
針對由式(2)~式(3)構成的最優控制問題,策略迭代過程包括依據式(5)進行策略評價(即確定值函數),以及依據式(7)進行策略更新。
2.2 評價網絡設計
從第1節的分析可以看出,控制策略對應的值函數難以求解,導致策略迭代過程的步驟1無法實現,故設計評價網絡估計值函數。
選取Φ(x)=[φ1(x),φ2(x),…,φN(x)]T保證φ1(x),φ2(x),…,φN(x)互相獨立,并對Φ(x)各元素加權達到估計值函數的目的,該估計結構被稱為評價網絡,其表達式為
V=WTΦ(x)+ε
式中:W∈RN為網絡權重,Φ(x):Rn→RN為激勵函數,ε為估計誤差。
在上述估計結構下,值函數V對狀態量x的偏導為
(12)
在計算過程中,由于W為未知量,故采用其估計量來推動迭代運行
(13)
2.3 基于單網絡積分型強化學習的控制器設計
將網絡當前輸出與期望輸出之間的差異描述為誤差函數
(14)
迭代過程中采用式(13)估計值函數后,誤差函數為
(15)
采用梯度下降法調整網絡權重最小化Δ,從而使網絡輸出向期望輸出收斂,首先定義最小方差形式代價函數
(16)
(17)
為增強梯度下降法在求解多維方程組時的性能,借鑒Levenberg-Marquardt算法在式(17)中加入歸一化處理項得到
(18)
式中:a∈R+為學習速率,
(19)

在IRL算法中,用于估計控制策略的執行網絡結構為
(20)
Vamvoudakis等[13]和Zhang等[15]提出了一種“非標準形式的更新律”來更新執行網絡。在文獻[13]中,這一更新律為
式中:aact是學習速率,為常值;ms=(T最后一項是為李雅普諾夫穩定性證明增加的量。
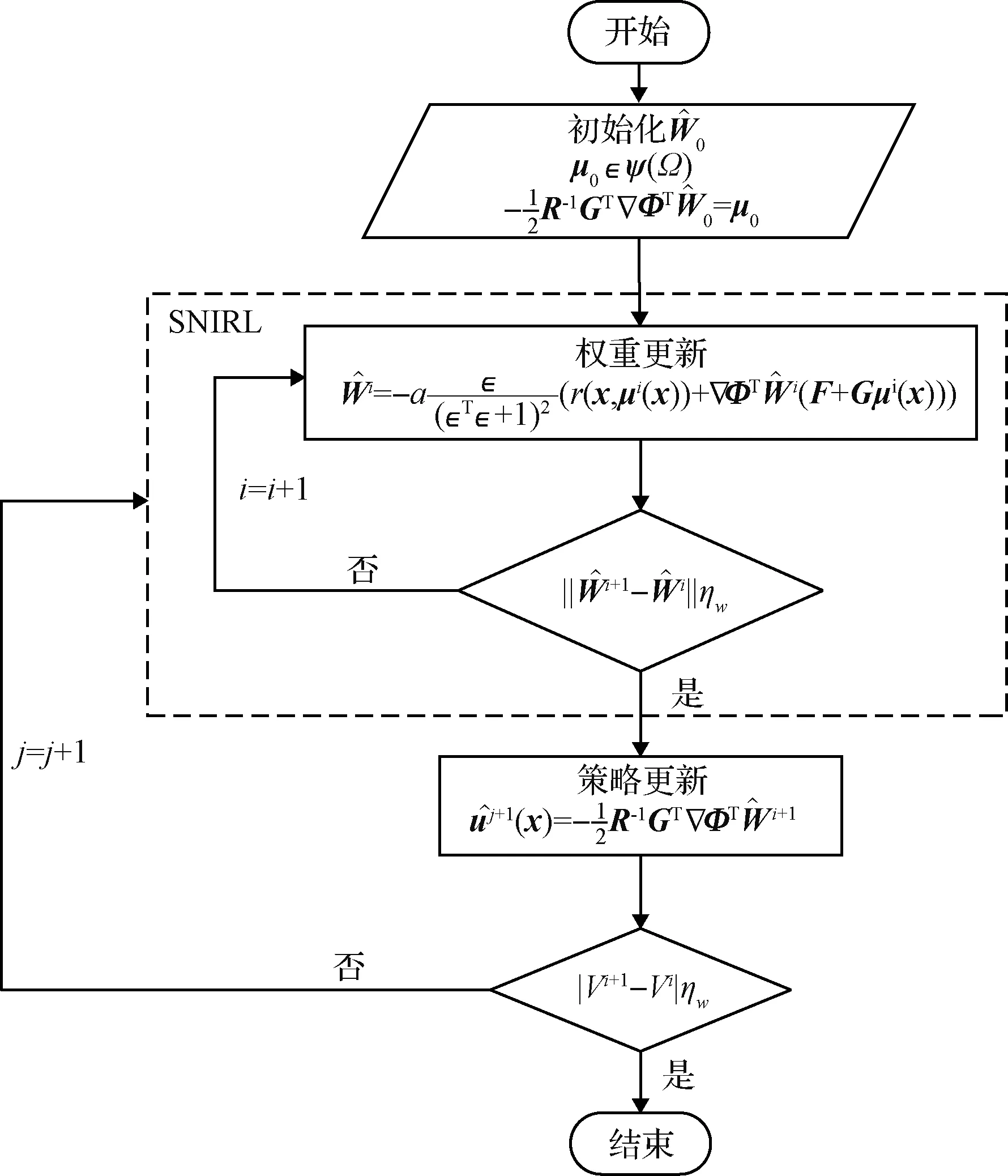
圖1 算法流程Fig.1 Algorithm progress
基于以上猜想,提出SNIRL算法,下面給出整個算法流程。
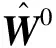
(21)
求解。

(3)相應的控制策略的計算式為
(22)
SNIRL算法將IRL算法中執行網絡的迭代過程替換為解析式(22),單網絡的設計使得算法結構更加簡潔。該算法使初始給出的容許控制在迭代過程中逐步收斂到最優控制策略。
整個控制系統的結構如圖1所示。圖中xcmd為指令信號;自適應最優控制策略記為uN,通過SNIRL求解最優控制問題獲得;前饋網絡是一個神經網絡,作用是對飛行器配平點進行擬合,給出前饋控制量uF。總控制策略為
utotal=uN+uF
(23)
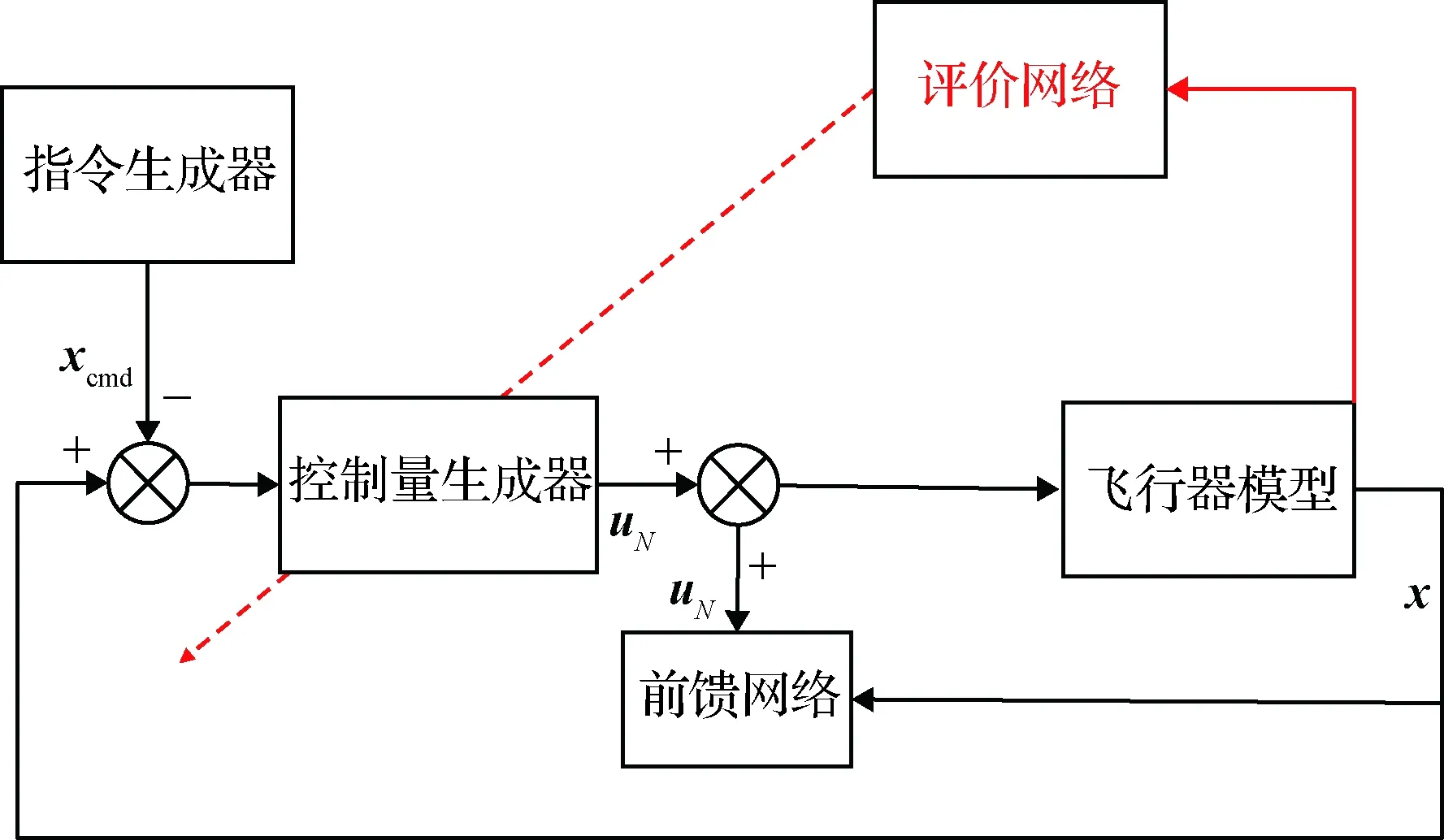
圖2 控制系統結構圖Fig.2 Control system structure
3 性能分析
下面進行算法的收斂性分析。
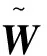

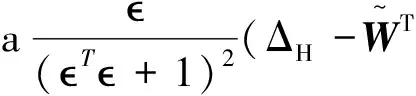
取李雅普諾夫候選函數
記ξ=(T+1)2,L的導數為
由柯西不等式:
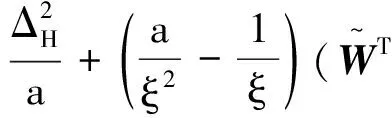
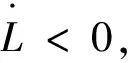
由于實數具有稠密性,?κ,使
因此只要
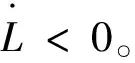
為了增強參數調節的靈活性,在實際應用時,學習速率取
a=diag(a1,a2,a3,…,aN)
(24)
式中:a1,a2,…,aN∈R+,為常值。
下面在代價函數為二次型,即C=xTQx+uTRu時,給出閉環系統穩定性分析。
定理2. 對系統(2),當網絡更新律為式(18),控制律由式(22)計算時,存在時間T,使得x(t)一致最終有界。且
式中:η>0,λmin(Q)為矩陣Q的最小特征值。
證. 考慮指令信號xcmd,記z=x-xcmd,有:
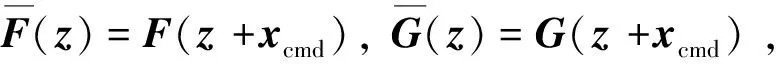
(25)
由式(8)得
(26)
對V(z)沿式(25)取時間導數,有
(27)
代入式(26),得
(28)
將式(22)代入式(28),得
考慮到R正定,有
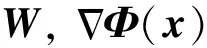
則η有界且
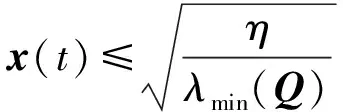
4 仿真校驗
本節以X33為對象,分縱向和橫側向對自適應最優姿態控制器進行仿真校驗。在縱向姿態仿真中與IRL算法進行對比,驗證SNIRL可以提升收斂速度和計算效率,節省存儲空間;同時在兩種仿真中均以相同的Q,R矩陣設計傳統的LQR控制器作為對比,對自適應最優控制器的有效性進行校驗。
4.1 縱向姿態控制
在高度h=45.09 km,速度v=3748 m/s,α=10°的工況下,給出機動指令αcmd=13°。
值函數由式(3)確定,式中:
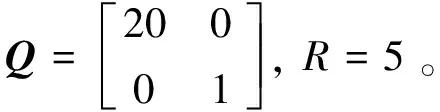
權重記為
激勵函數φ定義為
故有
初始權重為
圖2給出了SNIRL算法及雙網絡的IRL算法的權重收斂過程圖。圖中Wcritic和Wactor分別為IRL算法的評價網絡權重和執行網絡權重,W為SNIRL算法的評價網絡權重。兩種算法的權重均最終收斂到
圖3為兩種算法的權重收斂過程圖,下表為對兩種算法的計算時間、存儲占用、收斂時間的統計:

表1 SNIRL與IRL算法對比Table 1 Comparison of SNIRL and IRL

在迭代過程中,兩種算法的W1均幾乎沒有變化,這是由于W1在式(22)的計算中沒有貢獻,故算法不會對該值進行自適應學習,是合理的結果。
那么可以得到
總控制策略由式(24)計算。
控制結果在圖4中展示。LQR控制器的仿真結果也在圖中作為對比繪出。
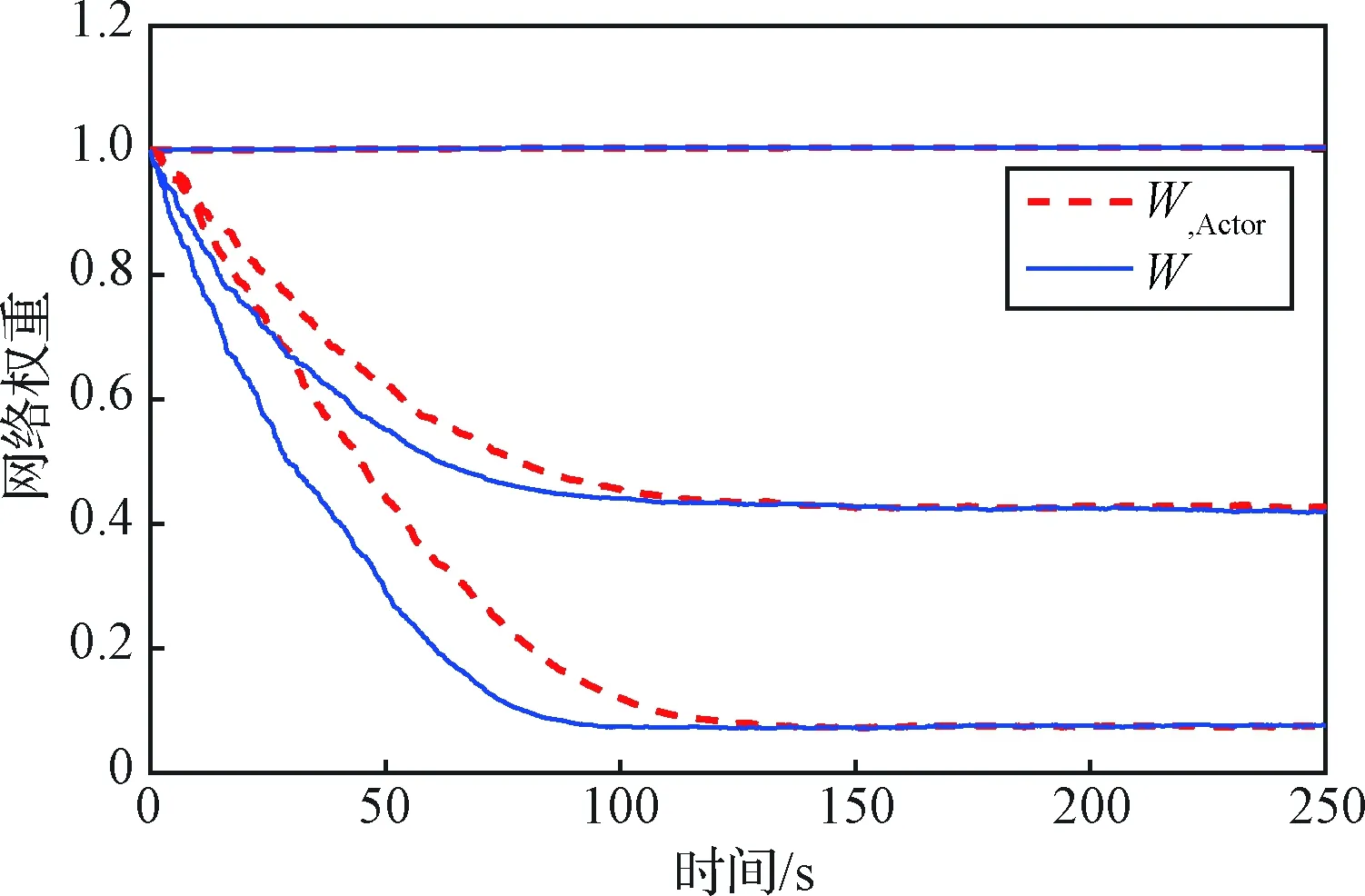
圖3 SNIRL和IRL算法的收斂過程Fig.3 Convergence of IRL and SNIRL algorithm
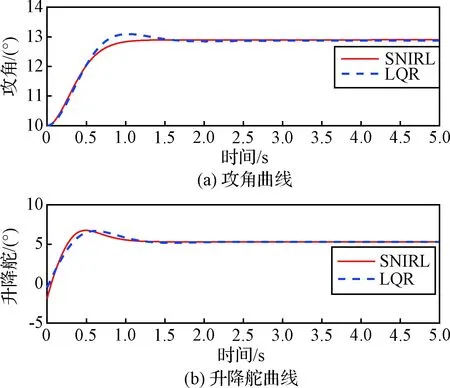
圖4 狀態量和控制量曲線Fig.4 State and control versus time
從圖3可以看出,SNIRL算法能夠收斂到最優解,且相比IRL算法,由于SNIRL算法在迭代過程中將執行網絡逐漸更新的過程代替為解析式,消除了滯后的執行網絡的收斂過程,故在每一次迭代中,權重都可以更快地收斂,因而總的收斂時間有所減少;從表1可以看出,SNIRL比IRL算法收斂更快,計算效率提高了近一倍。同時又由于SNIRL算法不需要存儲執行網絡的權重數據,故相比IRL算法可以節省近一半的存儲空間。
從圖4可以看出,自適應最優控制器完成了姿態跟蹤任務。且由于該控制器的設計是以非線性模型的最優控制理論為基礎進行的,對比LQR控制器穩態誤差更小,快速性也更好。
4.2 橫側向姿態控制
在高度h=45.09 km,速度v=3748 m/s,β=0.1293°,μ=-65.9°的工況下,給出機動指令βcmd=0°,μcmd=-68°。
值函數由式(3)確定,式中:
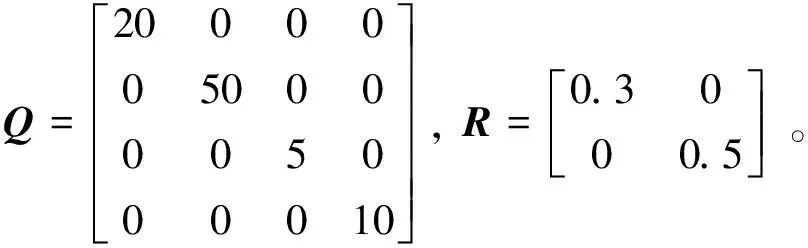
激勵函數φ定義為
φ(x)=[β2βμβpβrμ2μpμrp2prr2]T
權重記為
W=[W1W2W3W4W5W6W7W8W9W10]T
本節同樣對兩種算法進行了對比,仿真結果如圖5、圖6所示。表2進一步驗證了SNIRL算法能夠提高計算效率和節省存儲空間。
從圖5可以看出,在橫側向姿態控制中,自適應最優控制器相比LQR控制器表現出了更好的快速性和更小的穩態誤差。圖6為控制量隨時間的變化曲線,可以看到LQR控制器所給出的控制量存在震蕩,而自適應最優控制器的控制策略則更加平滑,這是自適應最優控制器更好地滿足了性能指標要求的體現。
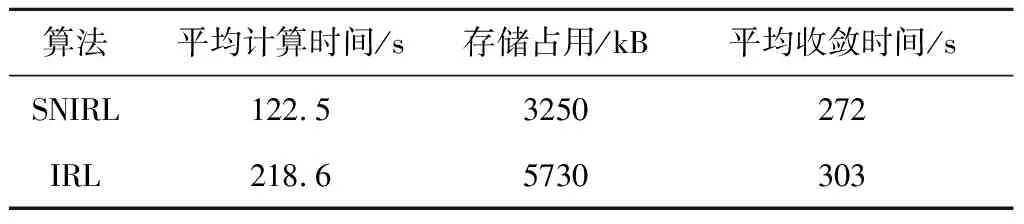
表2 SNIRL與IRL算法對比Table 2 Comparison of SNIRL and IRL
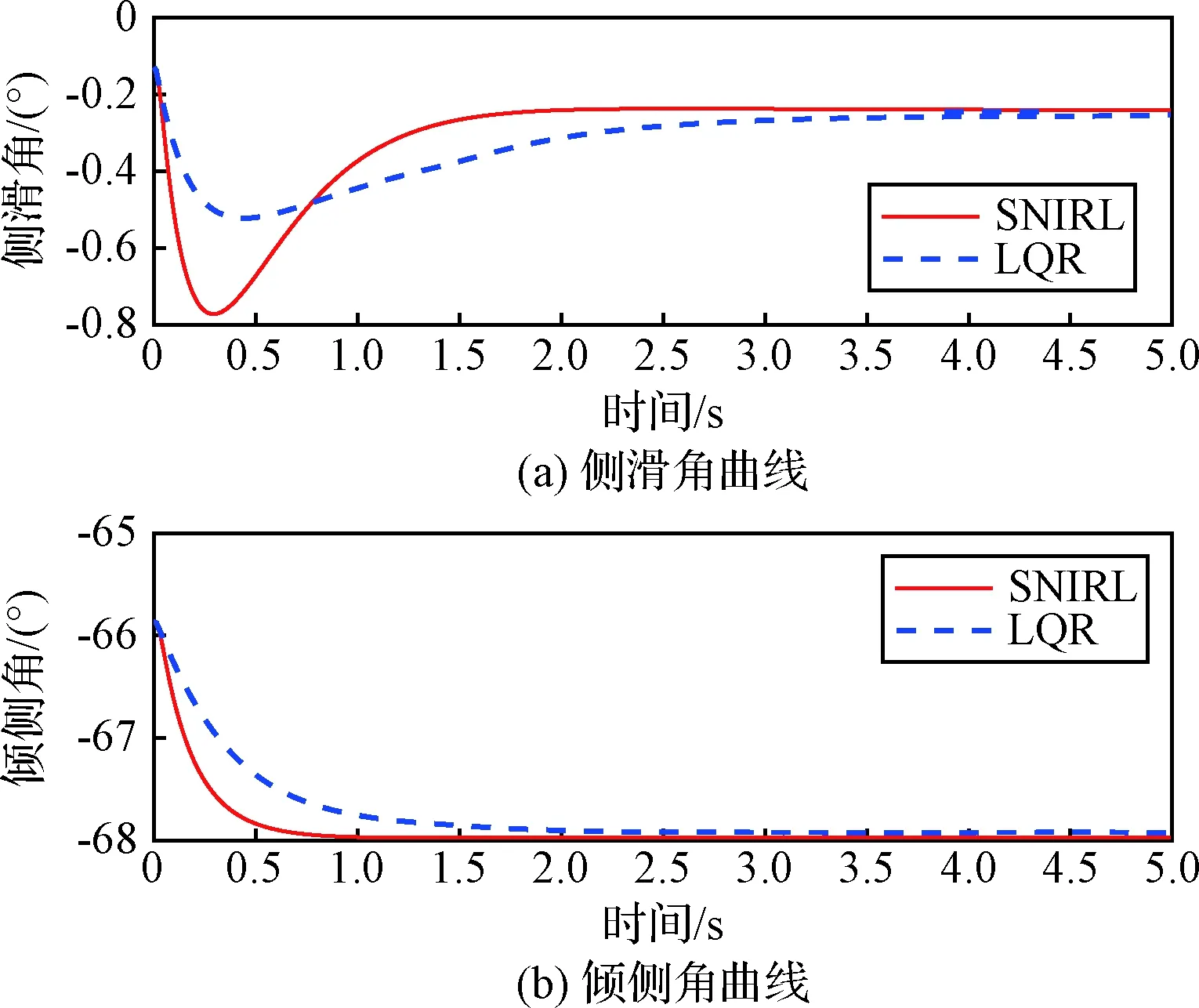
圖5 狀態量曲線Fig.5 State versus time
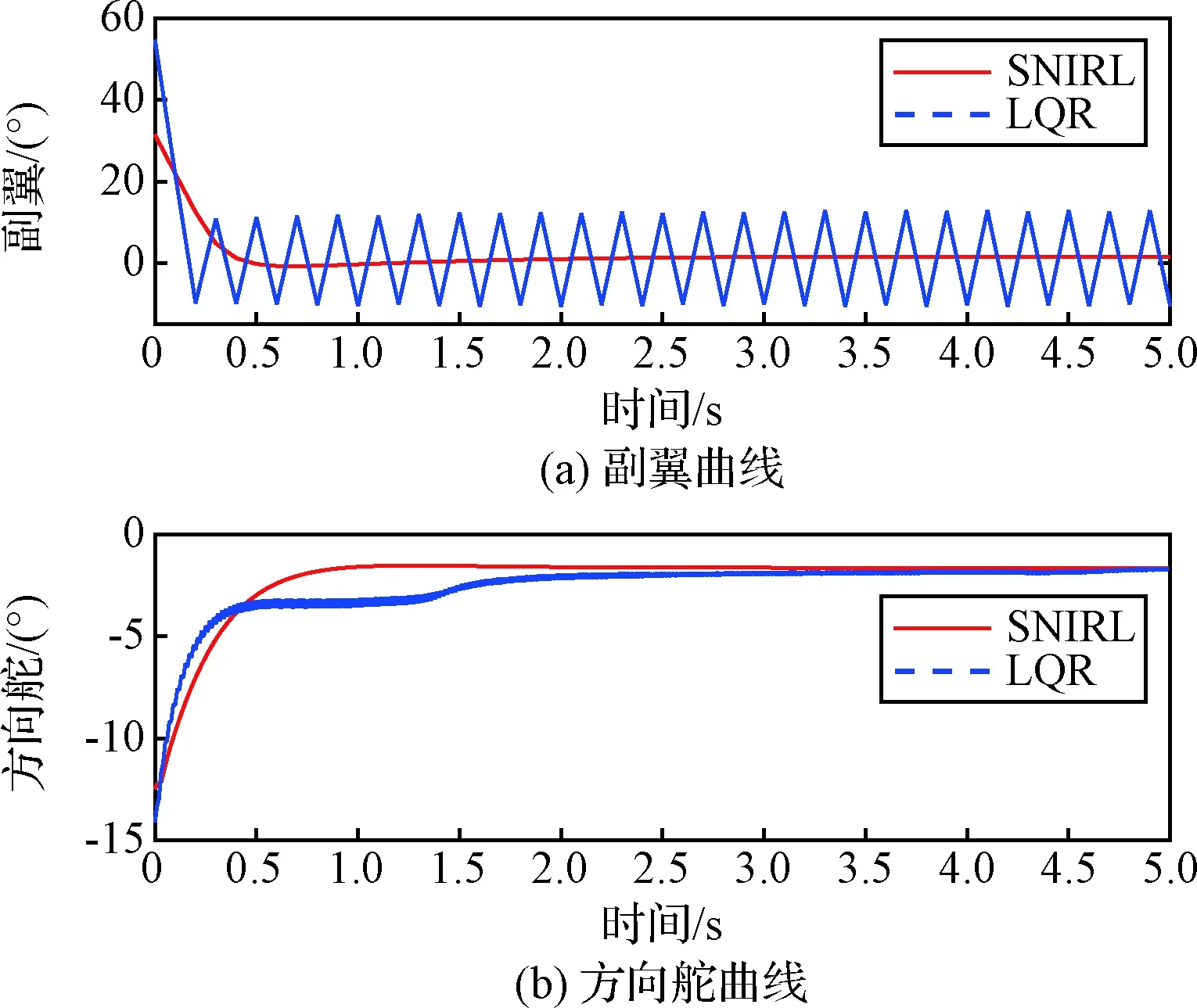
圖6 控制量曲線Fig.6 Control versus time
5 結 論
針對再入飛行器姿態控制問題,通過估計值函數,采用基于策略迭代的單網絡積分型強化學習算法,設計了自適應最優控制器。在求解最優控制問題時,改進了IRL算法,省去了執行網絡,并將其迭代計算過程用解析式代替,使算法結構更加簡潔,計算效率更高。在性能分析中通過李雅普諾夫穩定性理論證明了SNIRL算法的收斂性及閉環系統的穩定性。仿真結果表明, SNIRL算法相比IRL算法節省了近一半的計算量和存儲量,且收斂速度更快;所得到的自適應最優控制器具有良好的性能。
猜你喜歡
能源工程(2020年6期)2021-01-26 00:55:22
現代裝飾(2020年7期)2020-07-27 01:27:42
流行色(2020年1期)2020-04-28 11:16:38
山東冶金(2019年3期)2019-07-10 00:54:04
藝術啟蒙(2018年7期)2018-08-23 09:14:18
消費導刊(2018年10期)2018-08-20 02:57:02
海峽姐妹(2017年7期)2017-07-31 19:08:17
Coco薇(2017年5期)2017-06-05 08:53:16
通信電源技術(2016年1期)2016-04-16 04:57:26
電測與儀表(2016年20期)2016-04-11 11:38:24
