基于區間的時間序列分類算法的研究
2019-03-18 16:37:35李建平王興偉馬連博黃敏
網絡空間安全 2019年8期
李建平 王興偉 馬連博 黃敏
摘? ?要:時間序列分類是時間序列數據挖掘的一個分支,針對傳統時間序列分類模型存在的失真的問題,文章提出了基于區間權值的集成算法EAIW(Ensemble Algorithm of Interval Weights)。首先利用區間權值計算方法,為時間序列的不同區間賦予不同的權值,對計算做了并行化處理,以解決子序列特征不明顯的問題。進而確定集成分類器的基分類器,以保證集成分類器的性能。然后,在訓練集上訓練集成分類器,并行化改進集成分類器訓練、分類較為耗時的部分。文章將提出的算法在時間序列分類數據庫上進行了實驗,結果表明提出的算法比基準算法最優正確率數目高25%,并且算法在并行化之后具備可伸縮性。
關鍵詞:時間序列;分類;數據挖掘;CUDA
1 引言
時間序列是以均勻時間間隔連續測量的多個實值數的序列,一般被認為是一個整體,而不是單獨的數值字段[1,2]。時間序列可以反映事物的變化與發展,其廣泛存在于各行各業,如生物信息學、金融學、工程學。時間序列數據挖掘可以分為分類、聚類、檢索、預測、頻繁模式發現[3]。本文主要研究時間序列分類。
傳統的時間序列分析模型的建立依賴于嚴密的數學理論與假設,僅在假設合理時傳統方法才有效,否則所建立的模型將面臨嚴重失真的問題。與傳統的時間序列分析不同的是,時間序列數據挖掘不需要具備嚴格的數學理論以及平穩、線性且符合正態分布等假設,它可以根據經驗,發現數據中存在的新的有價值的模式、信息等。
本文主要工作是,為時間序列區間賦予權值,采用集成分類的算法,通過權值對時間序列進行分類。此外,針對分類器訓練、預測運行時間較長的問題,基于CUDA[4],對本文的分類器中較為耗時的部分進行了并行化改進。
2 相關工作
近年來,提出了許多不同的時間序列分類算法。Kate[3]通過計算測試集中時間序列與訓練集中所有時間序列的DTW(Dynamic Time Warping)距離,并將其作為該時間序列的特征,再將該特征輸入至分類器中,以達到對時間序列分類的目的。Ye等人[5]提出了基于時間序列shapelets構建決策樹的分類算法。Fang Z等人[6]對Ye等人的算法進行了改進。首先從分段聚合近似(Piecewise Aggregate Approximation,PAA)詞空間中發現shapelet候選詞,然后引入覆蓋度的概念來度量候選對象的質量,并設計了一種計算shapelet的最佳數量的方法解釋分類決策。Fulcher等人[7]通過從時間序列分析文獻中的上千種特征中選擇最具判別性的特征集,來解決時間序列分類問題。Hatami等人[8]使用遞歸圖(recurrence plot)把序列轉化為紋理圖像,再基于特征袋(Bag of Features,BoF)方法對它們進行分類。Ergezer H等人[9]提出了一種利用特征協方差矩陣進行時間序列分類的新方法。Silva等人[10]指出DTW距離計算中存在的問題,為解決該問題,忽略DTW距離計算中首尾的一小部分,通過引入一個參數來描述忽略部分的多少,解決該問題。
基于集成學習的分類算法,Sch?fer[11]提出了BOSS(Bag-of-SFA-Symbols)算法,通過對時間序列的子序列應用SFA[12],其可以獲得一種對噪聲與冗余數據容忍度較高的時間序列模型,并基于該模型構建多個分類器對時間序列進行分類。
本文主要貢獻:(1)引入時間序列區間權值,使子序列更有區分度;(2) 使用GPU,對區間權值計算過程與集成分類器訓練過程做出并行化改進。對時間序列進行分類時,目前許多研究只采用單一分類器,效率低下。另一些研究雖然采用集成分類器,但時間序列的特征選擇不佳,導致算法正確率低下。因此,選用時間序列區間權值作為分類特征,采用集成算法,對時間序列分類,提高了分類正確率。
3 區間權值計算
3.1 最近鄰算法
在時間序列研究中,常用的基準算法就是最近鄰算法(1 Nearest Neighbor,1NN),下面對其進行簡要介紹。
給定訓練集,其中包含條時間序列,分別屬于個類別,定義待分類時間序列到訓練集中時間序列的距離為:。若滿足公式(1),則最鄰近分類器認為待分類時間序列的類別為。
(1)最近鄰算法常用的距離度量有兩種,分別為歐幾里得距離(Euclidean Distance,ED)與DTW距離。在本文中使用歐幾里得距離進行區間權值計算,使用DTW距離算法作為基分類器的算法。
3.2 權值的計算
在一些數據集中,當時間索引處于某些區間內時,數據集中各個類別的時間序列的子序列不具有能夠顯著區分類別的特征。比如在一些區間內,數據受到了較多的噪聲的干擾。而在另一些區間內,可能會存在能夠較好地區分不同類別的特征。面臨這樣的數據集時,該分類器的分類準確率會下降。
為了解決上述問題,本文為時間序列的不同區間賦予不同的權值,該權值代表了其區分數據集中不同類別時間序列的能力。權值越大,表示該區間區分類別的能力越強,反之則越小。并將時間序列區間的權值作為相應的基分類器的權值。
若某一區間內存在較多能夠區分不同類別的特征,則分類器在該區間上的分類準確率必然較高,反之分類準確率會較低。因此,使用分類準確率作為區間的權值是合理的。1NN-ED分類器與本文基分類器所采用的1NN-DTW分類器較為接近,因此使用其計算區間的權值,能夠近似地反映該區間作為1NN-DTW的訓練集使用時的分類能力。此外,歐幾里得距離與DTW距離相比,計算時的時間復雜度較低,對于需要計算訓練集中全部區間的權值的EAIW算法而言,能夠減少訓練時間。
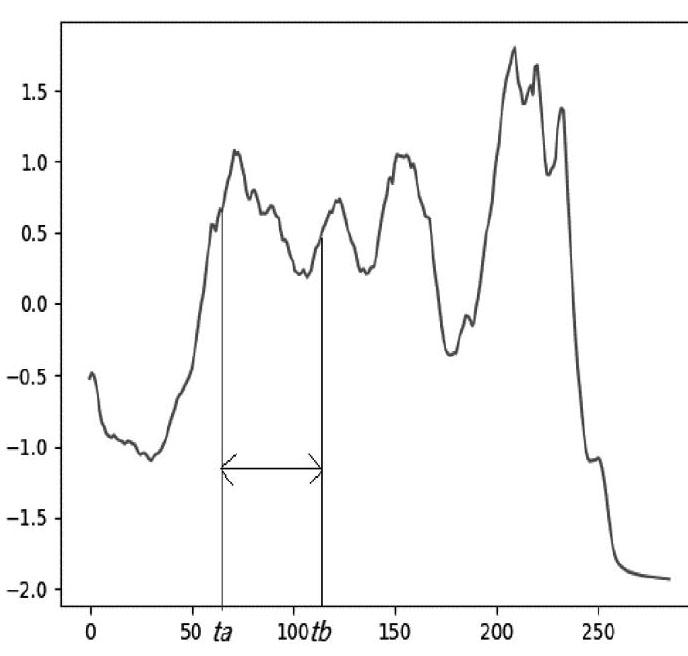
時間序列區間的示意圖如圖1所示,[ta,tb]為一個區間,對應了圖中時間序列的一條子序列。
在給出計算時間序列區間的權值的算法之前,首先給出時間序列區間的定義。
定義1 時間序列區間:給定時間序列,其中時間索引,將[ta,tb]稱為時間序列區間,其中,且a < b。
本文中的時間序列區間的權值是指時間序列數據集的訓練集的子集的權值,該子集由訓練集中處于該區間內的所有時間序列的子序列所構成,且該子集被用做基分類器的訓練集。本文所采用的時間序列數據集中的所有時間序列的長度均相等,因此某一條時間序列的區間也可以對應其他時間序列相同位置的區間,從而構成訓練集在該區間上的子集。該權值在分類器訓練時得出,用于后續的預測類標號的過程中。下面給出時間序列區間的權值的形式化定義。
定義2 時間序列區間的權值:給定時間序列數據集的訓練集,其在區間[ta,tb]上的子集為,,該子集所對應的權值為,將該權值稱為時間序列區間的權值。
為了能夠反映某一區間區分不同類別的時間序列的能力大小,同時充分利用訓練集,本文采用了留一交叉驗證(leave-one-out cross validation)的思想,來計算區間的權值。留一交叉驗證的示意圖如圖2所示。對于區間[ta,tb],計算其權值如公式(4)所示:
3.3 計算并行化
本文引入權值矩陣W來記錄每個GPU線程的計算結果,線程的計算結果記錄在W的元素中。同時該矩陣也能夠為GPU線程指示其需要計算的區間。每個GPU線程僅計算一個區間的權值。區間與W的行號、列號的對應關系如公式(5)、公式(6)所示:
4.1 基于區間的基分類器
本文提出的EAIW算法是一種集成算法,對于時間序列長度為m的數據集,則集成分類器由m-1個構造相似的基分類器所構成。由于時間序列長度m可能很大,造成基分類器數量較多,因此在選擇基分類器時要遵循三個基本要求。
(1)簡單有效。由于集成分類器中可能存在較多基分類器,因而要求基分類器結構要簡單,以免造成分類算法運行時間過長的問題。簡單的同時,還要保證算法的有效性,基分類器的分類準確率也要高。
(2)非參數。在時間序列分類的相關文獻中,常用于確定分類器參數的方法為交叉驗證,此方法十分耗費時間。對于每個存在參數的基分類器,都需要使用交叉驗證來確定其參數,這對于內部存在較多基分類器的集成分類器而言,是不可取的。
(3)基于實例。基于實例的分類器無需經過訓練就可以直接對時間序列進行分類,能有效地提高集成分類器的效率。
根據上述三點要求,因此選擇1NN分類器作為基分類器。在1NN分類器的距離度量方面,選擇DTW作為其距離度量。與歐幾里得距離相比,DTW距離能夠更加有效地應對時間序列中特征的形變,從而提高分類準確率。
4.2 訓練集成分類器
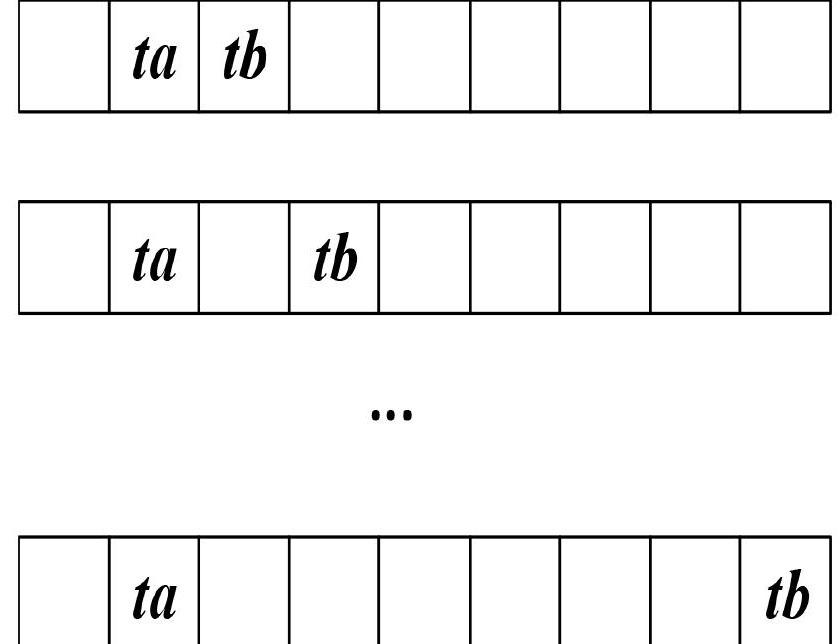
本文提出的EAIW算法在對測試集進行分類之前,需要在訓練集上進行訓練。在訓練過程開始之前,首先對訓練集中的時間序列進行z-score標準化。z-score標準化是時間序列分類文獻中常用的數據預處理方法,該方法將一條時間序列中的數據點的均值化為0,標準差化為1。將序列標準化,以便使時間序列之間的距離能夠反映它們之間的相似程度。接下來EAIW算法需要計算訓練集上所有區間的權值,其遍歷所有區間的方式為,對于任一時間索引 ,將其作為區間的左端點,從最小的區間長度2開始,每次為區間長度增加1,直至區間的右端點等于時間序列的長度m,計算區間的權值weight。這一過程的示意圖如圖3 所示。
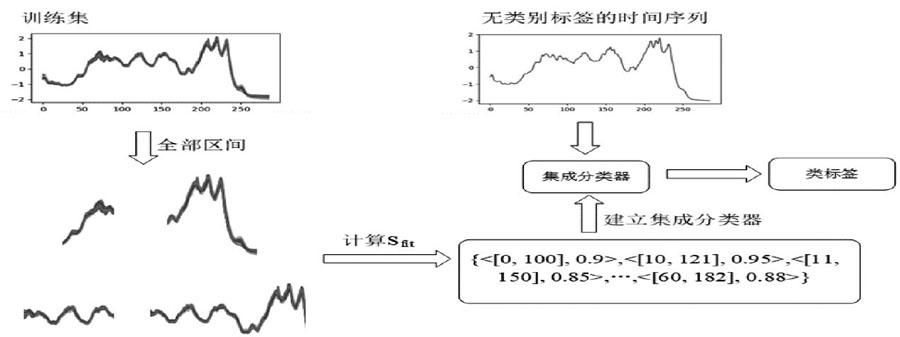
該過程與使用不同長度的滑動窗口獲取全部區間相比,更有利于后續的并行化。對于時間序列長度為m的數據集,此過程會計算全部m(m-1)/2個區間的權值,如果產生與之相同數量的基分類器,則后續的分類過程將會十分耗時。因此EAIW算法僅使用某一時間索引產生的具有最高權值的區間來構建基分類器,該區間以及其權值記錄在訓練結果 中。這樣可以提高基分類器的質量,提升分類準確率;同時又能夠減少基分類器的數量,降低集成分類器對測試集分類時所需的時間。EAIW算法的總體示意圖如圖4 所示。
在對測試集分類之前,與訓練時相同,首先對其進行z-score標準化。第i個基分類器在對測試集進行分類時,不對整個測試集中的時間序列進行類標號預測,而是預測其區間[[i][1][1],? [i][1][2]]所對應的測試集的子集的類標號。基分類器的結合策略為加權投票,對于第i個基分類器,其權值為[i][2]。EAIW算法對測試集進行分類的偽代碼如算法4所示。
4.3 并行化集成分類器
集成分類器的并行化方案為每個GPU線程使用第j個基分類器預測測試集中時間序列的類標號。為此引入矩陣P來記錄GPU線程預測的類標號,P的行數為k,與測試集中時間序列的數量相對應,P的列數為m-1,與基分類器數量相對應。P中元素記錄預測出的類標號。并行集成分類器的核函數的偽代碼如算法5所示。
計算DTW距離時需要構建矩陣,該矩陣所需的空間為,現今所有支持CUDA的GPU的線程本地內存(local memory per thread)僅為512KB,該空間開銷對于單個GPU線程而言過于龐大。例如,當時間序列的長度為512,時間序列中的數據使用單精度浮點數(占用4字節)存儲時,則計算DTW距離需要至少1MB的內存空間,大于GPU線程的本地內存。因此本文使用降低了空間復雜度的DTW距離,使用它可以使本文中所用到的時間序列長度最長的數據集所需的空間小于512KB。
矩陣P計算完成后,對其每行由基分類器集合得到的結果進行加權投票,對應的基分類器的權值為。該過程結束后,可得到測試集中每條時間序列的預測類標號。
5 性能評價
5.1 實驗環境
本文算法實現環境為Intel(R) Core(TM) i7-8700 CPU @ 3.2GHz,24.00G 內存,GP107 型GPU。算法基于Python實現,以PyCharm為主要開發工具,在Windows 10平臺下調試運行。
算法實現中所用到的庫主要包括:NumPy、SciPy以及Numb等。其中Numba用于將Python代碼編譯為CUDA核函數以及設備函數。
5.2 算法分類準確率評價
5.2.1 數據集
本文使用UEA&UCR時間序列分類數據庫中的數據集,該數據庫中共包含85個數據集,這些數據集被近年來的許多時間序列分類文獻所采用。本文將這些數據集分為兩個部分,一部分用于確定集成算法EAIW中結合策略的參數,稱為train;另一部分用于與其他算法進行分類準確率的對比,稱為test。
train與test的劃分原則是,使它們中的數據集的數量盡可能相等,且TSCI的分布近似相同。這樣可以避免引入額外的偏差,影響最終結果。
5.2.2 分類準確率
本節將EAIW與基準算法1NN以及BOP算法進行分類準確率對比,如表1所示。其中1NN-ED與1NN-DTW分別采用的是歐幾里得距離與DTW距離。BOP算法基于時間序列的詞袋表示。分類準確率為分類正確的時間序列數量與測試集中時間序列總數之比。
由表1可知,四者的最優個數分別為15、10、12、7,因此本文提出的算法的最優正確率數目比基準算法高25%以上,43個數據集的平均準確率為0.763、0.743、0.760、0.729,本文提出的算法依然最高,這說明了本文算法的有效性。
5.3 算法運行時間評價
5.3.1 數據集
影響本文提出算法的運行時間的因素主要包括:訓練集大小、測試集大小以及時間序列長度,本文從這三個方面來評價并行化改進后算法的運行時間。使用UEA&UCR數據庫中的第5個數據集WormsTwoClass,評價時間序列長度對算法運行時間的影響,并將數據集的訓練集與測試集大小擴充為前文中提及的85個數據集相應部分的平均值,訓練集的平均大小為529,測試集的平均大小為1068。時間序列的長度范圍為100至900,記錄每個時間序列長度對應的算法的訓練時間、分類時間以及總運行時間。使用UEA&UCR數據庫中的第13個數據集Ham,評價訓練集大小與測試集大小對運行時間的影響。該數據集的時間序列長度為431,接近85個數據集的平均時間序列長度為422。訓練集與測試集的大小范圍為100至900,記錄每個訓練集與測試集大小對應的算法的訓練時間、分類時間以及總運行時間。在上述兩個評價過程中,如果所用的數據集的訓練集或測試集的大小不能滿足實驗要求,則使用其訓練集中的第一條時間序列與其對應的類標簽將訓練集或測試集擴充至指定大小。
5.3.2 運行時間評價
并行化改進后的EAIW算法的運行時間隨時間序列長度的變化如圖5所示。由圖5可知,隨著時間序列長度的增加,訓練時間、分類時間以及總時間的增長均較為緩慢。訓練時間總體上低于分類時間,這是由于訓練時的區間權值計算使用了時間復雜度較低的歐幾里得距離,而分類時采用了時間復雜度較高的DTW距離所導致的。圖5表明并行化改進后的EAIW算法的運行時間具備對于時間序列長度的可伸縮性。
并行化改進后的EAIW算法的運行時間隨訓練集與測試集大小的變化如圖6所示。由圖6 可知,隨著訓練集與測試集大小的增長,并行化改進后的EAIW算法的訓練時間的增長幅度較小,說明算法對訓練集與測試集大小具有可伸縮性;而分類時間與總運行時間的增長幅度較大。這說明分類耗時對于時間序列長度的增加較不敏感,而對于訓練集與測試集大小的增加較為敏感。其原因在于分類時使用的基分類器是基于實例的,且計算DTW距離的時間復雜度較高,因此每個基分類器的分類耗時會隨訓練集大小而較快地增加,導致總分類時間的增加。同時測試集的增加又進一步增加了分類耗時,這兩個因素導致了分類時間對于訓練集與測試集大小的增加較為敏感。
6 結束語
時間序列是一種日常生活中廣泛存在的數據形式,在時間序列數據上進行數據挖掘可以發現一些新的知識與模式。本文針對傳統分類算法存在的失真問題,提出了基于區間的集成分類算法EAIW,并在時間序列分類文獻中常用的數據集上,對本文提出的算法進行了實驗,與其他算法進行了對比,實驗結果顯示算法準確率優于基準算法。針對多分類器訓練、預測運行時間較長的問題,對本文的分類器中較為耗時的部分進行了基于CUDA并行化改進,算法具備可伸縮性。
基金項目:
1.國家自然科學基金資助項目(項目編號:61872073,61572123);
2.遼寧省高校創新團隊支持計劃資助項目(項目編號:LT2016007)。
參考文獻
[1] Fu T. A review on time series data mining[J]. Engineering Applications of Artificial Intelligence, 2011, 24(1): 164-181.
[2] Ma L.B , A Novel Many-objective Evolutionary Algorithm Based on Transfer Learning with Kriging model, Information Sciences,2019, DOI: 10.1016/j.ins.2019.01.030.
[3] Kate R J. Using dynamic time warping distances as features for improved time series classification[J]. Data Mining & Knowledge Discovery, 2015, 30(2): 283-312.
[4] NVIDIA Developer Zone, CUDA toolkit documentation[EB/OL]. https://docs.nvidia.com/cuda/cuda-c-programming-guide/, 2018.
[5] Ye L, Keogh E. Time series shapelets: a new primitive for data mining[C]//Proceedings of the 15th ACM SIGKDD international conference on Knowledge discovery and data mining. ACM, 2009: 947-956.
[6] Fang Z, Wang P, Wang W. Efficient Learning Interpretable Shapelets for Accurate Time Series Classification[C]//2018 IEEE 34th International Conference on Data Engineering (ICDE). IEEE, 2018: 497-508.
[7] Fulcher B D, Jones N S. Highly comparative feature-based time-series classification[J]. IEEE Transactions on Knowledge & Data Engineering, 2014, 26(12): 3026-3037.
[8] Hatami N, Gavet Y, Debayle J. Bag of recurrence patterns representation for time-series classification[J]. Pattern Analysis & Applications, 2018: 1-11.
[9] Ergezer H, Leblebicio?lu K. Time series classification with feature covariance matrices[J]. Knowledge and Information Systems, 2018, 55(3): 695-718.
[10] Silva D F, Batista G E A P A, Keogh E. Prefix and suffix invariant dynamic time warping[C]. IEEE International Conference on Data Mining, 2017: 1209-1214.
[11] Sch?fer P. The BOSS is concerned with time series classification in the presence of noise[J]. Data Mining and Knowledge Discovery, 2015, 29(6): 1505-1530.
[12] Sch?fer P. SFA: a symbolic fourier approximation and index for similarity search in high dimensional datasets[C]. International Conference on Extending Database Technology, 2012: 516-527.
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
大眾投資指南(2021年35期)2021-02-16 01:06:26
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
少兒科學周刊·少年版(2015年3期)2015-07-07 21:00:00
