大數據視角下的區(qū)域稅收發(fā)展不平衡探析
2019-03-27 05:54:38孫存一譚榮華
商業(yè)研究 2019年3期
孫存一,譚榮華
(1.北京物資學院 物流學院,北京 101149;2.中國人民大學 財政金融學院,北京 100872)
內容提要:我國區(qū)域經濟發(fā)展差距一定程度上體現在稅收缺口的不平衡。本文選取中國31省份30多萬規(guī)模以上工業(yè)數據,以適合大數據分析的機器學習作為核心算法,從稅收流失的視角分析地區(qū)之間的稅收差異。結果表明,在同等稅收政策的前提下,省份之間的流失金額、流失率、流失戶、流失戶比差異明顯。因此,稅務機關應以“互聯(lián)網+”以及大數據為契機,科學識別區(qū)域稅收流失差異,促進區(qū)域稅收征管平衡,保證經濟稅收的良性發(fā)展。
一、引言
稅收缺口等同于稅收流失,是稅收理論值與實際值之間的差異。測度各地稅收流失的大小,在一定程度上可以考察各地稅收征收情況與國家統(tǒng)一標準之間的差距,從而衡量區(qū)域稅收發(fā)展的差異。稅收流失是國家、集體和個人之間利益分割問題,是行為主體對國家法律的遵從程度,基于區(qū)域研究稅收流失并最大限度地降低區(qū)域稅收差異,可以保證國家稅收執(zhí)法的剛性以及公平公正問題,有效地促進區(qū)域經濟發(fā)展平衡,減緩區(qū)域經濟差異擴大的趨勢,保證經濟社會的持續(xù)、穩(wěn)定、健康發(fā)展。運用大數據科學測度稅收流失額度,對于考察區(qū)域經濟發(fā)展不平衡具有重要意義。
我國稅收流失的測算方法日益豐富,分析視角逐漸從宏觀、中觀到微觀,分析結果越來越精細。但是,由于稅收流失測算方法理論較多,并未獲得統(tǒng)一的意見,爭議頗多,諸如:測算視角是否具有主觀性,樣本數據是否具有代表性,模型能否充分擬合復雜的現實條件等。互聯(lián)網+、大數據、機器學習、人工智能作為新的科學技術力量,帶來面向大數據的機器學習法。其優(yōu)勢體現在不需要對數據做主觀假定,支持規(guī)模超大、關系錯綜復雜的數據信息。對于本文的研究,該方法有利于充分利用樣本信息,構建出代表性強、擬合度高的稅收經濟關系模型;此外,模型以數據為導向,解析數據之間的相關性,自學習、自適應、自完善,適合涉稅行為多樣、財務核算復雜的大型企業(yè)。
二、樣本數據
由數據到信息、由信息到知識、由知識到智慧是大數據分析的根本目標。機器學習法以數據為導向構建模型,自助檢驗模型的可靠性,然后進行外推預測,從這一點來講,機器學習法不是針對經濟理論而構建,有什么樣的數據就有什么樣的結論,所以我們必須要有足夠的數據支撐,從大數據的角度來講,涉稅數據無處不在,主要區(qū)分為兩種類型:一是主要描述企業(yè)的經營條件、業(yè)務范圍、財務狀況等的基本面數據;二是描述企業(yè)的交易行為、涉稅行為等的行為數據。從現實的角度講,還要考慮數據的可獲得性以及數據的質量等問題。鑒于此,本文選擇中國301961戶工業(yè)規(guī)模以上企業(yè)的數據作為樣本數據,包括登記信息、申報信息、征收信息、財務信息等基本面數據,數據的基本結構如表1所示。
表1得知,樣本數據體量足夠龐大,主要記載了納稅人的基本信息、財務狀況、涉稅記錄等。抽取數值變量中的“營業(yè)收入、營業(yè)成本、銷售費用”3個核心指標;分類變量中的“地域、行業(yè)、經濟性質”3個重要維度,查看它們的分布狀況,如圖1所示。
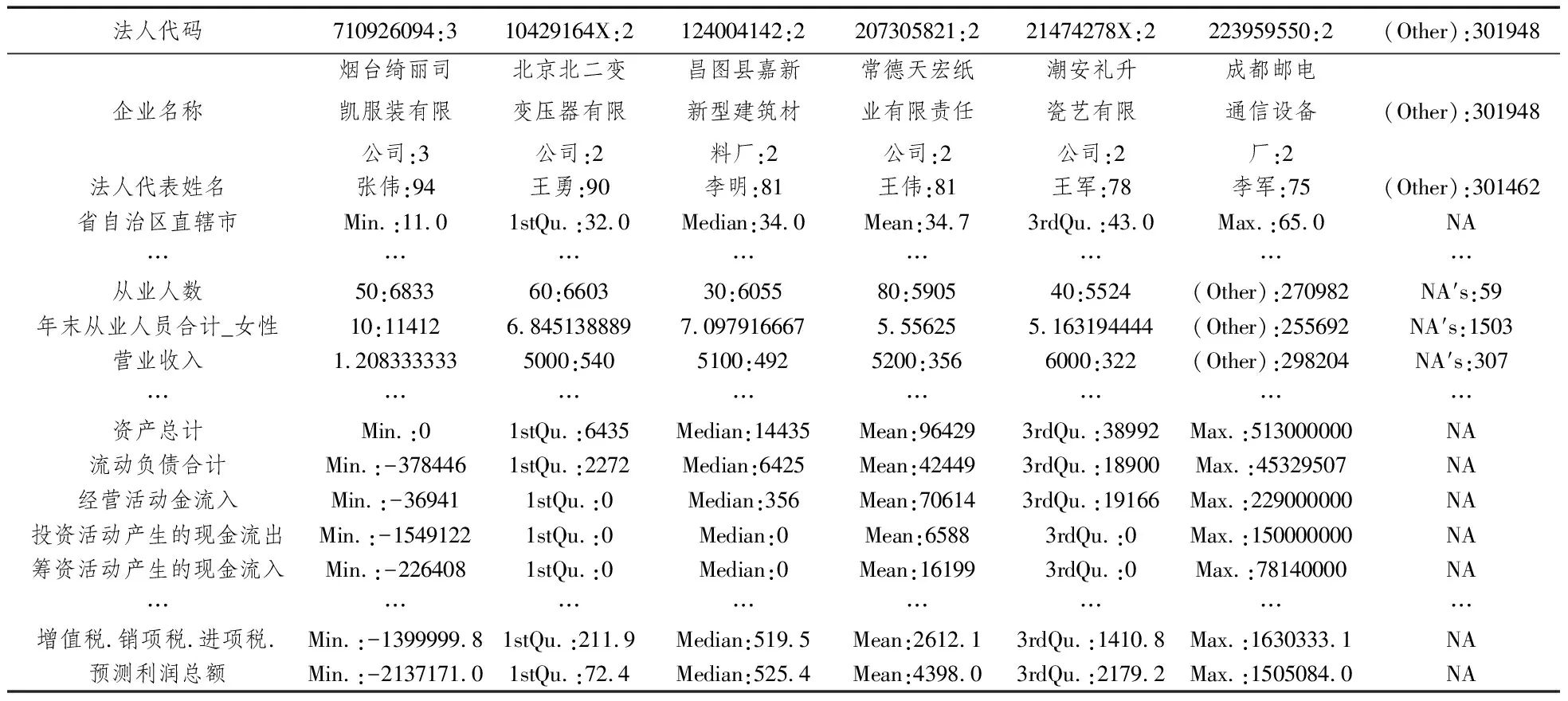
表1 樣本數據的基本結構表
注:表1中實際變量119個,限于篇幅不再一一列舉。其中的經營活動、投資活動、籌資活動分別指的是經營活動、投資活動、籌資活動產生的現金流量,原始數據中變量使用了簡稱。
數據來源:規(guī)模以上工業(yè)企業(yè)年報(國家統(tǒng)計局)。
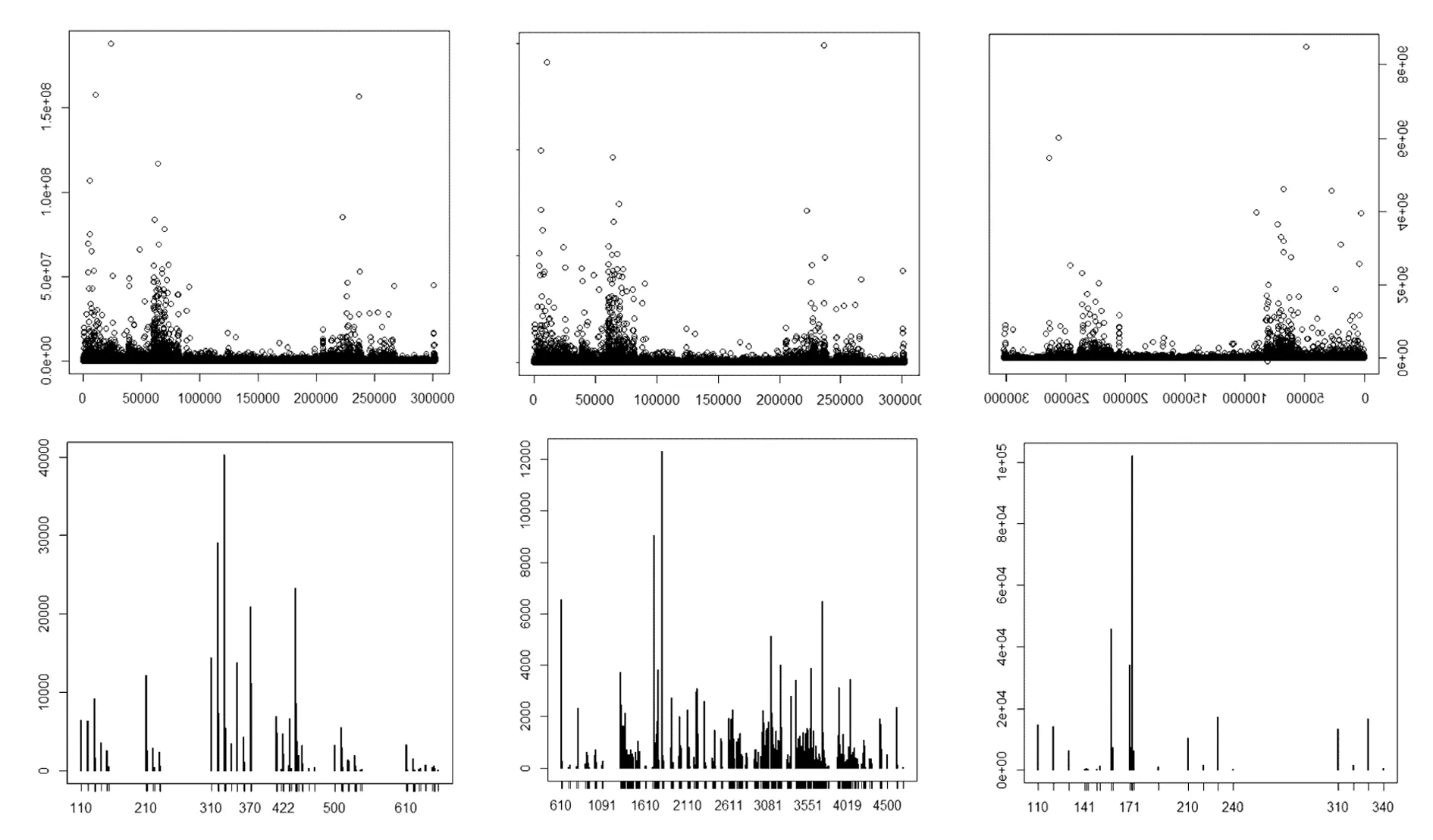
圖1 核心指標的分布圖
圖1得知,數值變量的分布極不規(guī)則,根本不符合傳統(tǒng)的正態(tài)分布;而分類變量的分布也不平衡,無法滿足信息平衡的要求。單從以上兩點看,傳統(tǒng)的模型是無法使用的。大數據分析不能給數據做分布假定,以致背離客觀事實,我們必須要從數據的隨機特征出發(fā),以歸納的思維得出結論。機器學習算法,通過解析數據之間的普遍聯(lián)系,然后區(qū)分出觀測值之間的差異,可以挖掘出復雜數據的規(guī)律,屬于當前所認可的適合大數據分析的算法。基于以上數據,本文在測算中參與變量119個,經過上千余次的反復測試和修正,最終實現了對中國30萬規(guī)模以上工業(yè)企業(yè)的稅收流失指向明確、有一定可靠性的測算結果,在此基礎上分析我國31個省份的稅收流失率、稅收流失戶比等指標,推斷出不同地域下中國的稅收發(fā)展平衡問題。
三、研究設計
(一)理論基礎
無論是國內、國外,基本上把“納稅人已繳稅額與實際應納稅額之間的差額”,定義為“稅收缺口”,又稱之為稅收流失。稅收流失率、稅收流失戶比是衡量稅收流失的兩個重要指標,稅收流失率計算公式是:(預測應納稅額-實際繳納稅額)/預測應納稅額*100%或流失金額/(流失金額+實際繳納稅額)*100%,稅收流失戶比計算公式是:存在流失金額的戶數/總戶數*100%。由以上公式得知,稅收流失是基于稅種的流失,考慮到企業(yè)所得稅的財務關系明確,容易構建起理想的稅收經濟關系模型,本文選擇測算的稅種是企業(yè)所得稅。
(二)測算方案
測算方案是以獲得數據為出發(fā)點,以測算目標為導向,構建方法體系和遵循技術路徑的選擇,如圖2所示。
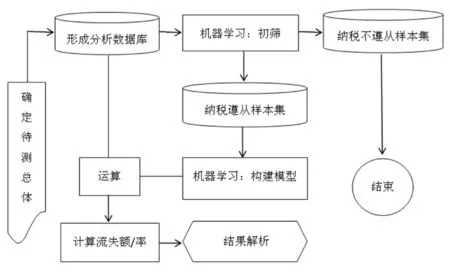
圖2 測算方案
從圖2看以看出,稅收流失測算的主要內容有4點:(1)確定待測總體;(2)選擇方法和模型;(4)控制測算過程;(4)結果解析。基于聯(lián)合建模的思路,機器學習算法出現在初篩、構建模型2個環(huán)節(jié)。形象的理解,首先,機器學習法通過初篩,篩選出表現較好的納稅人群體,即納稅遵從樣本集。然后,基于納稅遵從的樣本集,構建出“理想的”稅收經濟關系模型。在上述基礎上,推斷表現不好的納稅人群體,即納稅不遵從的樣本集,預測納稅不遵從樣本集可能存在的稅收流失。
(三)變量設置
因變量:會計利潤。計算企業(yè)所得稅有直接法、間接法,在此我們在預測中采用的是“間接法”,即:應納稅所得額=會計利潤+納稅調整增加額-納稅調整減少額;會計利潤=收入-成本-期間費用(營業(yè)費用、管理費用、財務費用)。注意兩點:一是為避免收入、成本和期間費用的重復預測,本文將會計利潤作為附加變量進行預測,不再單獨預測收入、成本以及期間費用,同時對會計利潤進行預測更能體現出企業(yè)的共性,因為納稅調整增加(減少)額是針對個別企業(yè)、個別業(yè)務而執(zhí)行的稅收政策,企業(yè)虛假申報的機會較小。二是考慮到企業(yè)所得稅預測的復雜性,本次預測僅預測會計利潤,企業(yè)所得稅流失額=(預測會計利潤+納稅調整增加額-納稅調整減少額)*適用稅率-(實際繳納所得稅額)*適用稅率,如果報表勾稽關系正確的話,實際繳納所得稅額=申報會計利潤+納稅調整增加額-納稅調整減少額,所以最終企業(yè)所得稅的流失額=(預測會計利潤-申報會計利潤)*適用稅率。
自變量:機器學習支持全樣本、全變量參與,尋找的是數據之間的非線性關系。自變量為全變量,主要包括表1中的稅務登記信息、申報信息、征收信息、財務信息等。考慮到數據缺少“實際繳納企業(yè)所得稅稅額”,在計算稅收流失額(率)的時候用“應交所得稅”替代,如此也避免了由于減免稅優(yōu)惠、境外所得等企業(yè)個性差異對最終結果的影響。
(四)數據分組
一般來講,同一時間、同一地區(qū)、同一行業(yè)、同一經濟類型的企業(yè)會具有相似的經營條件、業(yè)務范圍、財務狀況、稅收政策等,其所體現出的經濟行為才具有同質性。所以對于大數據分析,數據分組非常重要。為保證理論稅收在全國統(tǒng)一標準線上,避免按區(qū)域對數據分組。從哪一個維度入手,還需要結合數據的狀況,考慮到經濟性質相同的企業(yè),財務狀況上具有同質性,本文選擇以“登記注冊類型”(或經濟性質)作為數據分組標準,簡要統(tǒng)計如表2所示。
由表2得知,我們將從23個數據子集中構建23子模型,并基于子模型進行企業(yè)所得稅的稅收流失預測。
(五)模型構建
機器學習法包括決策樹、支持向量機、神經網絡等諸多算法,不同的算法適用不同的應用場景,實驗結果表明,隨機森林(randomForest,以決策樹CART、bagging作為核心算法,兩種算法諸多文獻有介紹,不再贅述。)在預測稅收流失方面表現性能最好。隨機森林是由多棵CART構成的,對于每棵樹使用的訓練集是從總的訓練集中采用bagging原理采樣出來的,這意味著,總的訓練集中的有些樣本可能多次出現在一棵樹的訓練集中,也可能從未出現在一棵樹的訓練集中。在訓練每棵樹的節(jié)點時,使用的特征是從所有特征中按照一定比例隨機地無放回抽取的。隨機森林預測企業(yè)所得稅主要區(qū)分為兩個過程,即訓練過程和預測過程。
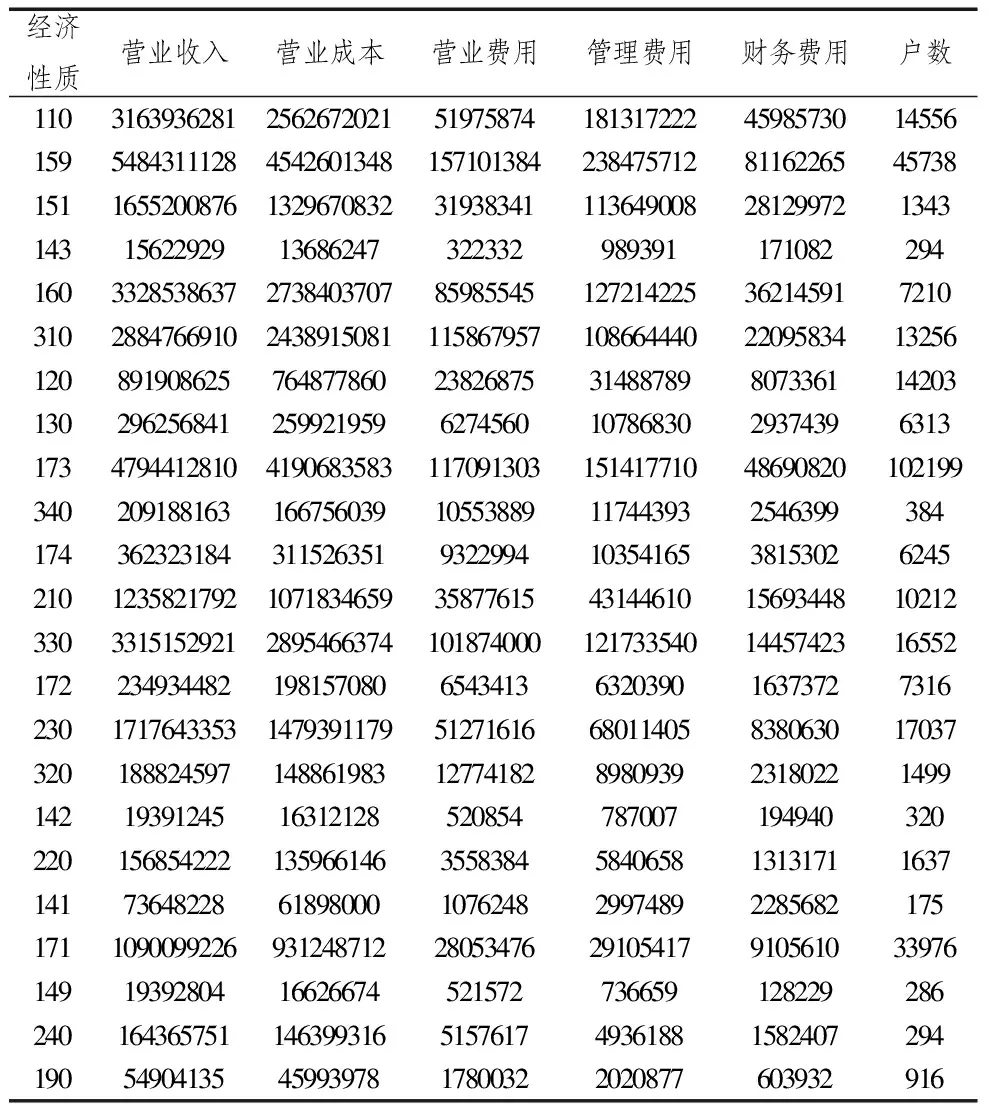
表2 企業(yè)按經濟性質分組之后的數據分布簡表 單位:千元
注:經濟性質中的內容為原始數據的代碼,該代碼與中國綜合征管軟件的登記注冊類型代碼一直,代碼表示的注冊登記類型名稱不再贅述。
1.訓練過程如下:
第一步,給定訓練集S,測試集T,特征維數F。確定參數:使用到的CART的數量t,每棵樹的深度d,每個節(jié)點使用到的特征數量f,終止條件:節(jié)點上最少樣本數s,節(jié)點上最少的信息增益m,對于第1:t棵樹,iin 1:t。
第二步,從S中有放回地抽取大小和S一樣的訓練集S(i),作為根節(jié)點的樣本,從根節(jié)點開始訓練。
第三步,If當前節(jié)點上達到終止條件,則設置當前節(jié)點為葉子節(jié)點,在企業(yè)所得稅的回歸預測中,輸出為當前節(jié)點樣本集各個樣本值的平均值。然后繼續(xù)訓練其他節(jié)點。If當前節(jié)點沒有達到終止條件,則從F維特征中無放回地隨機選取f維特征。利用這f維特征,尋找分類效果最好的一維特征k及其閾值th,當前節(jié)點上樣本第k維特征小于th的樣本被劃分到左節(jié)點,其余的被劃分到右節(jié)點。繼續(xù)訓練其他節(jié)點。
第四步,重復第二步、第三步,直到所有節(jié)點都訓練過了或者被標記為葉子節(jié)點。
第五步,重復第二步、第三步,第四步,直到所有CART都被訓練過。
2.預測過程如下:
第一步,從當前樹的根節(jié)點開始,根據當前節(jié)點的閾值th,判斷是進入左節(jié)點(
第二步,重復執(zhí)行第一步,直到所有t棵樹都輸出了預測值。企業(yè)所得稅預測問題,則輸出為所有樹的輸出的平均值。
從以上介紹得知,機器學習法利用計算機強大的運算能力,總會找到一個擬合數據特征的函數C,C作為企業(yè)所得稅稅收經濟關系的理想模型,即納稅人理論上應繳納企業(yè)所得稅的計稅基礎。但C能否描述客觀事實?還應該看C的外推性如何,即C對訓練集數據之外的數據是否具有擬合能力,如果訓練集的擬合度高,而預測集的擬合度低,那自然就產生了“過擬合”問題,這樣的模型是失效的。從這一點來講,隨機森林可以一定程度上避免產生過擬合問題,證明如下:我們將上述的CART分類模型的集合記為:{h1(X),h2(X),…,hk(X)},那平均正確分類數超過平均錯誤分類數的程度(余量函數)為:mg(X,Y)=avkI[hk(X)=Y]-maxavkI[hk(X)=j],所以mg(X,Y)越大,預測越可靠。外推誤差可寫成:PE*=PX,Y[mg(X,Y)<0],當CART分類模型足夠多,hk(X)=h(X,Θk),如此隨機森林隨著決策樹的增加,而避免產生過度擬合的問題。
由以上算法構建原理可知,隨機森林注重的是數據本身的隨機特征,除目標變量的約束外,其他的自變量不受業(yè)務假設的影響,支持全變量、全樣本掃描,所以適合用來做復雜數據以及大數據分析。當然,隨機森林對計算機的依賴性較強,需要大量的運算解析過程,應該考慮到時間復雜度的問題,隨著互聯(lián)網、云計算等技術日益成熟,隨機森林模型的時間開銷已經不是主要考慮的問題,所以將其應用于稅收大數據分析的條件已經具備。
(六)模型檢驗
機器學習不需要先驗的假設分布,所以之前“假定分布=>用明確的數學模型來擬合=>假設檢驗=>P值”的經典過程,不能滿足機器學習模型檢驗的要求。本文使用比較通用的交叉驗證方法,以五折交叉檢驗為例,其原理是將所抽取的樣本數據集分割成5個子樣本,1個單獨的子樣本被保留作為驗證模型的數據,其他4個樣本用來訓練。交叉驗證重復5次,每個子樣本驗證一次,最終得到估測。這個方法的優(yōu)勢在于,同時重復運用隨機產生的子樣本進行訓練和驗證,每次的結果驗證1次。如此,可以用來檢驗模型的外推性,即對未知企業(yè)的預測能力。本文按照企業(yè)的經濟性質進行了劃分,建立了23個子模型,所以必須要對每一個子模型都要進行檢驗,外推性(即測試集)的檢驗結果如表3所示。
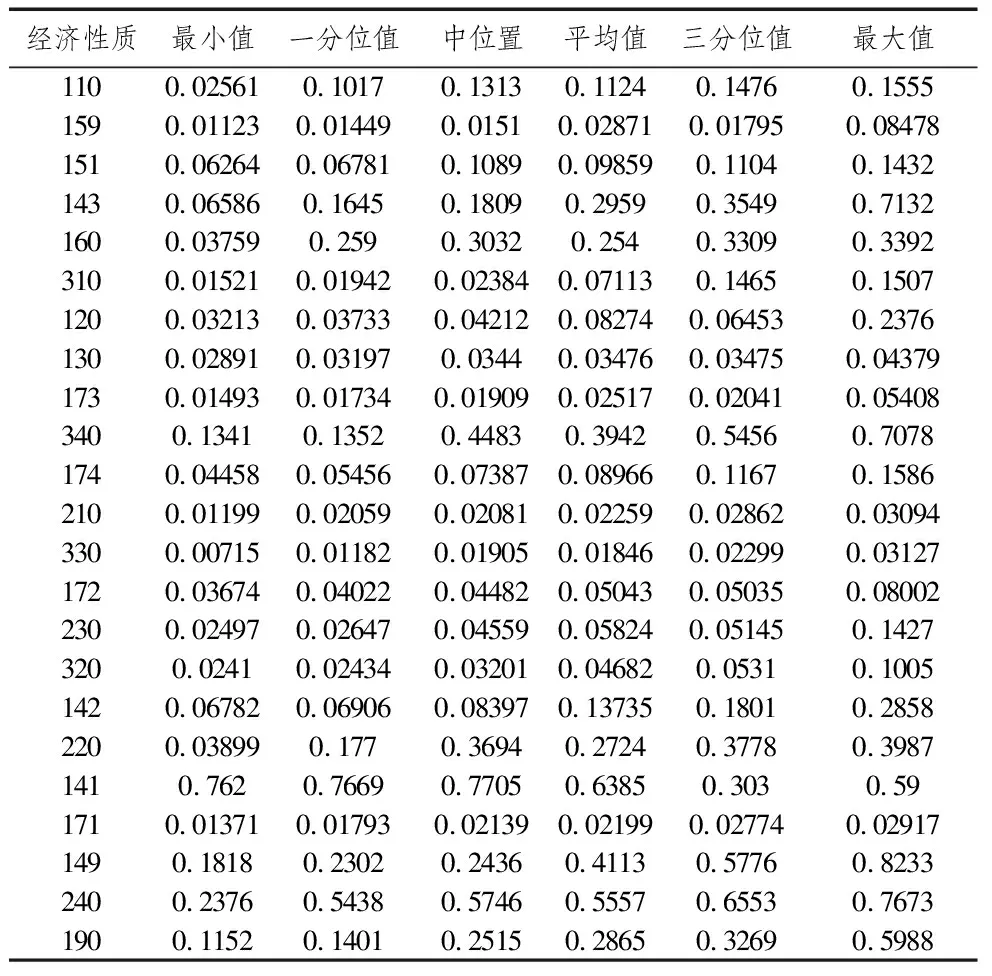
表3 五折交叉檢驗誤差結果表
注:表3中標準化均方誤差(NMSE)是反映模型預測或分類結果精度的指標,可以根據NMSE的值來對一個模型的計算結果進行判斷。基本原理是如果NMSE=1,則相當于用因變量的均值做測算,模型對結果基本沒有影響(抽象能力差);如果NMSE>1,則說明模型的計算還不如用均值計算的結果好,因此這個模型很糟糕;如果NMSE<1,則說明模型對計算結果有好的影響,而且NMSE越小,則模型計算的效果越好。其中訓練集是用來檢驗訓練模型對數據的擬合能力,測試集是用來檢驗模型的泛化能力。
圖3 五折交叉檢驗誤差結果圖
由表3得知,23個數據子集所形成的模型的均方誤差在區(qū)間[0.00715, 0.8233]內。一般來講,如果什么模型都不用,只是用均值來做預測,均方誤差應該等于1,因此,如果計算出來的均方誤差大于1,則說明這個模型很糟糕,判斷一個模型是否適合,均方誤差應該越小越好,從測試集看誤差率遠小于1,且小的多,這是非常理想的效果,所以23個子模型的外推性很好,通過模型所預測的企業(yè)所得稅是可靠的。為進一步形象展示誤差分布,如圖3所示。
四、測算結果及解析
(一)總體情況
機器學習法算法模型構建完成之后,要進行應納企業(yè)所得稅稅額的預測,本次預測的總體結果:301961戶工業(yè)規(guī)模以上企業(yè),預測應納企業(yè)所得稅稅額365619795千元、實際已繳企業(yè)所得稅稅額318917139千元、總流失金額46702656千元、總流失率12%,存在低申報繳納稅款的戶數為139343戶,總流失戶比46%。以上結果按流失金額大小劃分為四個區(qū)間,主要分布情況如表4所示。
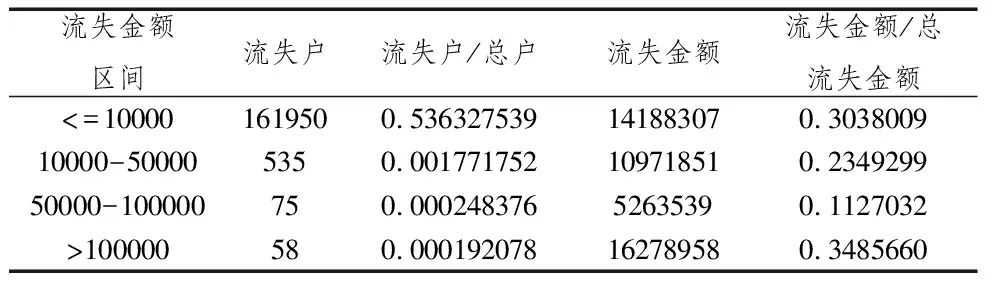
表4 流失分布總體情況表(單位:千元)
由測算總體結果及表3流失分布情況可知,中國工業(yè)規(guī)模以上企業(yè)總流失金額達460億以上,40%以上的企業(yè)存在稅收流失,金額之大、比率之高,說明我國企業(yè)的納稅遵從意識普遍較低。進一步分析發(fā)現,30%的流失戶集中在1億以下金額區(qū)間,70%的流失金額集中在少數的大的企業(yè)上,由此可見,只要大型企業(yè)在國民經濟中的主導、甚至是壟斷地位不變,企業(yè)所得稅的稅收流失率水平必然決定性地受其左右,而流失戶主要由組織分散的小型、微型企業(yè)所決定,諸多小微企業(yè)缺少有效監(jiān)管習慣性地存在不同程度的稅收流失情況。從征方的角度看,許多稅務機關基于短期的征管成本考慮,采取了“抓大放小”的措施,雖然能夠保障稅收收入的平穩(wěn)增長,但也存在一定的弊端,即造成了中小微企業(yè)普遍納稅遵從意識較低的事實。
(二)詳細情況
本文主要分析基于區(qū)域的稅收經濟發(fā)展平衡狀況,即稅收流失情況,所以必須要按照區(qū)域(省份)作為維度進行稅收流失情況統(tǒng)計,如表5所示。
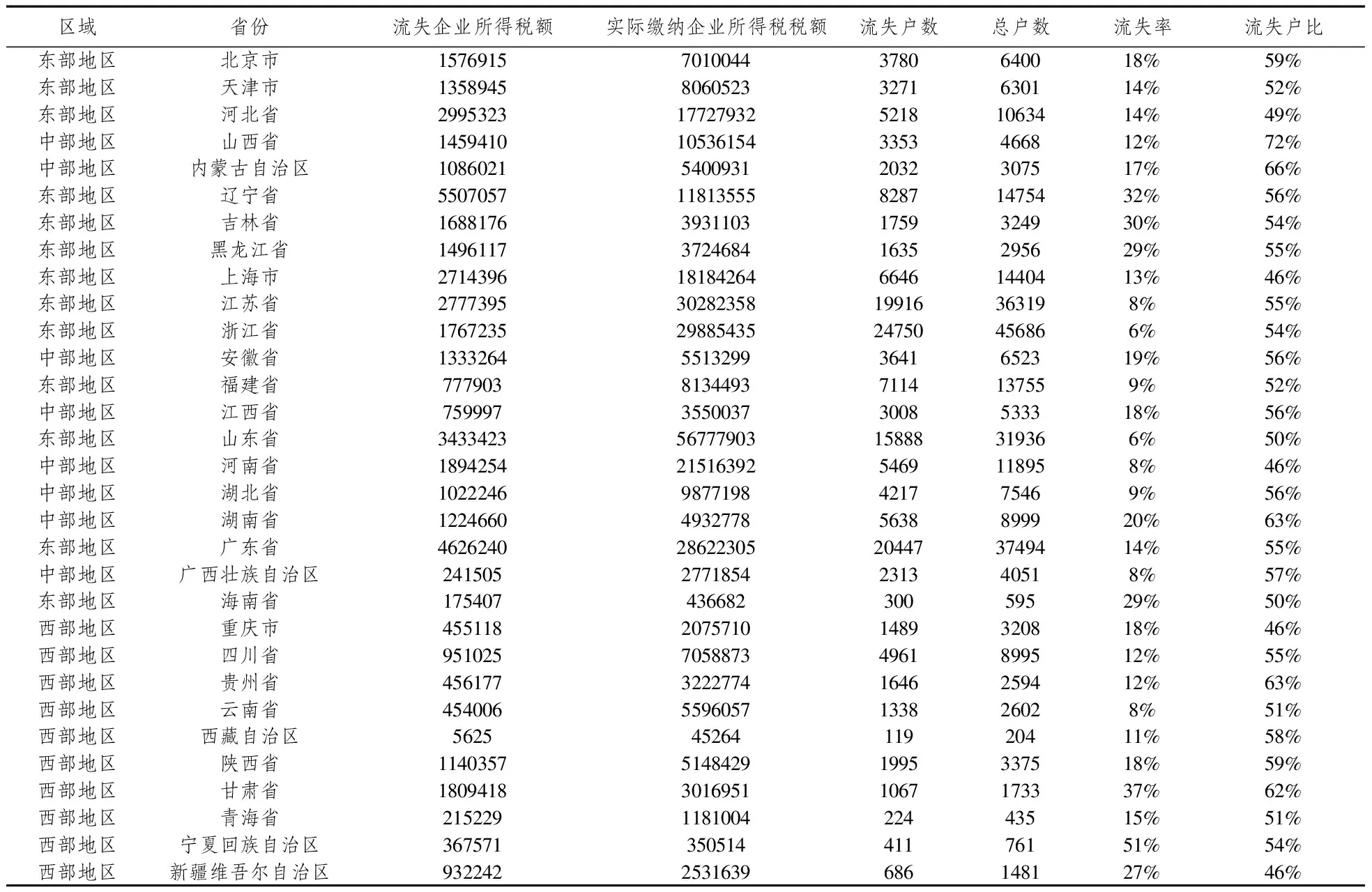
表5 按省份流失分布詳細情況表(單位:千元)
由表5可知,中國31省稅收流失率、流失戶比差異明顯,從中、東、西部的大的維度看,表現出不同的趨勢。這與地方稅源狀況、組織收入能力有關,東部發(fā)達地區(qū)相對中西部地區(qū)(包括東北三省)征管能力較強,稅收流失率較低,與此同時東部地區(qū)的稅源比中西部地區(qū)充沛,所以東部地區(qū)往往是“抓大放小”,更多的精力關注在稅收額度較大的企業(yè)上,也會造成稅收流失戶比反常的事實。西部地區(qū),征管能力弱,稅收流失率整體偏高,特別是地域廣闊的區(qū)域,需要征管的企業(yè)面較廣,但受組織能力的限制,兼顧不周,最終導致稅收流失戶比落后于東部地區(qū)。由此可見,以稅收流失率、稅收流失戶比兩個角度看,中國的稅收區(qū)域發(fā)展依然存在諸多不平衡,呈現出中東西部以及經濟發(fā)達程度、地域范圍、征管能力等多因素的條件差異。
五、結論與啟示
由實證分析結果得知,我國稅收流失額度之大、比例之高,稅收區(qū)域發(fā)展存在諸多不平衡。稅收發(fā)展不平衡顯然不利于經濟社會的可持續(xù)健康發(fā)展,醞釀出社會不穩(wěn)定因素,不利于發(fā)揮社會經濟的規(guī)模效應。稅收發(fā)展不平衡不是短時間內能夠徹底解決的,在當前和今后相當一段時間內稅收發(fā)展不平衡的因素依然存在。我國需要在適應市場經濟的過程中逐步推進區(qū)域稅收發(fā)展平衡,通過計劃和市場兩種資源配置方式,制定扶持西部貧困地區(qū)發(fā)展的長期計劃,改變東部地區(qū)經濟稅收發(fā)展征管考核機制等。當然,區(qū)域經濟發(fā)展中,國家先后出臺了諸多政策方針,貫徹落實力度還不夠,這由諸多客觀因素造成的。從稅務機關的角度看,“互聯(lián)網+稅務”思維為我們推進稅收現代化提供了無限想象空間和創(chuàng)新余地。在此本文政策含義如下:
一是緊跟“互聯(lián)網+”大形勢,發(fā)揮互聯(lián)網在生產要素配置中的優(yōu)化和集成作用,融稅收業(yè)務線上、線下業(yè)務于一體,推進透明度更強、參與度更高、協(xié)作性更好的多元化平臺,在便利納稅人、提高稅務機關征收效率同時,實現稅收管理由粗放式向精準化轉型。利用互聯(lián)網能超越時間、空間和形態(tài)限制,依托信息化手段,由辦稅服務廳實地辦稅轉為足不出戶的網上辦稅、自助辦稅和移動辦稅,把實體辦稅服務的主要業(yè)務大量移植到線上,推動線上線下融合發(fā)展,使辦稅方式發(fā)生根本性變革,解決中西部區(qū)域稅收征繳線下征管的約束。
二是重視科學技術創(chuàng)新,形成以大數據、云計算、機器學習等作為支撐生產力的核心,打造功能實際、界面友好、操作簡潔、價格低廉的互聯(lián)網平臺,幫助企業(yè)更好的經營,納稅人可以隨時掌握國家產業(yè)動態(tài)、稅收政策變化、行業(yè)競爭狀況、交易資源配置等等,以期在耗用最少社會資源條件下迅速提高企業(yè)的市場競爭力。開發(fā)統(tǒng)一的數據情報平臺、數據共享交換等稅收風險控制軟件,充分挖掘應用第三方信息和涉稅記錄信息,用大數據預測思維方式來思考問題,解決問題,實現大數據預測、大數據記錄預測、大數據統(tǒng)計預測、大數據模型預測,大數據分析預測、大數據模式預測、大數據深層次信息預測,改變西部地區(qū)風險管理的落后狀況,提高納稅遵從的效率以及精準度。
三是人才的儲備、人才的培養(yǎng)、人才的使用極其關鍵。大數據分析需要審時度勢提出任務目標的能力、圍繞目標任務組織數據的能力、基于良好的素養(yǎng)構建模型的能力以及對輸出結果的解析能力等跨界能力,應加大西部地區(qū)人才的培養(yǎng)力度,開展與發(fā)達地區(qū)的智庫合作、院校合作、商業(yè)機構合作、研究結構合作等多層次、多樣化的人才培養(yǎng)鍛煉機制。大數據是技術發(fā)展所帶來的不可逆的大趨勢,應該鼓勵那些站位前沿、勇于擁抱變革的人,深入我國西部大膽試驗、大膽實踐,通過大數據思維、大數據技術思考問題、解決問題。
從長遠來看,區(qū)域稅收發(fā)展的平衡,關系到國家稅收征納關系是否和諧,和諧的稅收征納關系是社會處于依法征納、文明規(guī)范、協(xié)調融洽以及良性互動的一種狀態(tài),是確保稅務機關有效履行職能、避免雙方沖突、實現稅收執(zhí)法公平公正的需要,甚至關系經濟社會的穩(wěn)定發(fā)展,事關經濟社會發(fā)展全局。需要指出的是,解決區(qū)域稅收發(fā)展不平衡問題不能單靠稅務一家,這是一項社會性的綜合工程。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
當代水產(2022年8期)2022-09-20 06:44:30
當代水產(2022年6期)2022-06-29 01:11:44
當代水產(2022年5期)2022-06-05 07:55:06
當代水產(2022年3期)2022-04-26 14:27:04
當代水產(2022年2期)2022-04-26 14:25:10
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
云南畫報(2020年9期)2020-10-27 02:03:26
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
