
水庫型飲用水水源地水質綜合評價RDPSO-RF模型及應用
2019-03-28 06:48:46
人民珠江 2019年3期
(云南省水文水資源局紅河分局,云南紅河661100)
水庫型城市集中式飲用水水源地作為中國集中式飲用水水源地重要類型之一,不但承擔著城市居民生活供水任務,而且在城市防洪、工農業供水等方面發揮著重要作用。近年來,隨著經濟社會發展和人類活動加劇,一些水庫型城市集中式飲用水水源地水質受到不同程度污染,傳統單因子水質評價法(亦稱一票否決法)以最劣指標類別作為最終評價結果,不能客觀、科學反映水源地水質綜合狀況。因此,開展水庫型水源地水質綜合評價,對于保障城市居民飲用水源安全,科學實施水源地防污治污以及落實最嚴格水資源管理制度均具有重要意義。目前,水源地水質綜合評價方法主要有卡爾森指數法[1]、模糊綜合評價法[2]、支持向量機法[3]、投影尋蹤法[4]、物元可拓法[5]等,均在水源地水質綜合評價中取得較好的評價效果。隨機森林(random forest,RF)是由Leo Breiman提出的一種集成機器學習方法,主要利用Bootsrap重抽樣方法從原始樣本中抽取多個樣本,對每個Bootsrap樣本進行決策樹建模,然后組合多棵決策樹通過投票方式獲得最終評價結果[6],可以看成由很多弱分類器(決策樹)集成的強分類器,能有效避免“過擬合”和“欠擬合”現象的發生,已在各領域及水質綜合評價[7-8]中得到應用。然而,在實際應用中,合理選取RF模型決策樹數量ntree和分裂屬性個數mtry2個參數對于提高RF模型預測或分類性能至關重要。目前普遍采用試湊法[9-10]或網絡搜索法[6,11]確定決策樹數量、分裂屬性個數,但取值效果往往不理想。近年來,隨著群體仿生智能算法研究的不斷深入,其已被嘗試用于RF模型決策樹數量、分裂屬性個數的優化,如周博翔等人[12]利用蜜蜂交配算法優化隨機森林參數,構建HBMO-RF模型用于人體姿態識別;王杰等人[13]提出基于粒子群優化(PSO)算法的加權隨機森林分類模型,并通過實驗數據驗證了該模型的分類效果;趙東等人[14]采用果蠅優化算法(FOA)對RF關鍵參數進行優化,構建FOA-RF模型對蟲害數據進行預測。但基于群體仿生智能算法優化決策樹數量、分裂屬性個數的RF模型用于水質綜合評價的文獻并不多見。
為進一步拓展群體仿生智能算法優化RF 2個關鍵參數的應用范疇,本文提出一種基于隨機漂移粒子群(random drift particle swarm optimization,RDPSO)算法優化的RF評價方法,利用RDPSO算法優化RF決策樹數量和分裂屬性個數2個關鍵參數,構建RDPSO-RF水源地水質綜合評價模型,并構建基于RDPSO算法優化的回歸支持向量機(SVR)模型作對比分析,以云南省紅河州17個水庫型飲用水水源地水質綜合評價為例進行實例研究。通過選取水源地水質綜合評價因子,依據GB 3838—2002《地表水環境質量標準》在各評價因子等級閾值間隨機內插和隨機選取樣本對RDPSO-RF、RDPSO-SVR模型進行訓練和測試;利用測試好的RDPSO-RF、RDPSO-SVR對實例水質綜合類別進行評價,旨在驗證RDPSO -RF模型用于水庫型水源地水質綜合評價的可行性和有效性。
1 RDPSO-RF評價模型
1.1 隨機漂移粒子群算法
隨機漂移粒子群(RDPSO)算法是孫俊等人受PSO算法的軌跡分析和金屬導體中自由電子定向漂移運動、隨機無規則熱運動啟發而提出來的一種具有較強全局搜索的群體智能算法。RDPSO算法中自由電子的定向漂移運動類似于粒子的局部搜索,隨機無規則熱運動類似于粒子的全局搜索[15]。參考文獻[15-17],RDPSO算法數學描述如下。
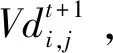
(1)
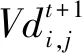
(2)
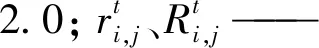
式(2)可表示如下:
(3)
(4)
(5)
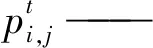
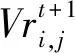
(6)
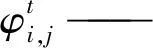
(7)
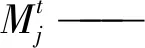
(8)
式中N——群體規模。將式(6)改寫為:
(9)
綜上,RDPSO算法中粒子速度和位置更新公式表示為:
(10)
(11)
1.2 隨機森林算法
隨機森林(RF)算法是由Leo Breiman[18]提出的基于決策樹分類器的融合算法,該算法通過隨機的方法建立一個由許多決策樹組成的森林,每棵決策樹之間沒有關聯;每棵決策樹均采用bootstrap方法進行采樣,隨機產生k個訓練集,利用每個訓練集生成對應的決策樹;然后再從所有M個決策屬性中隨機抽取m個屬性進行評價;在訓練過程中,一般m的取值維持不變;訓練結束后,當測試樣本輸入時,每棵決策樹均對測試樣本進行評價,并將所有決策樹中出現最多的投票結果作為最終評價結果,具體算法步驟見文獻[13-19]。假設對于一個測試樣本x,第l棵決策樹的輸出為ftree,l(x)=i,i=1,2,…,c,即為其對應的輸出值,l=1,2,…,L,L為RF中的決策樹棵數,則RF的輸出可表示為:
fRF(x)=argmax{I(ftree,l(x)=i)},i=1,2,…,c
(12)
式中I(·)——滿足括號中表達式的樣本個數。
研究表明,決策樹數量ntree和分裂屬性個數mtry的合理選取是提高RF評價精度的關鍵,ntree設置過小易使RF訓練不充分而導致模型“欠擬合”,設置太大又易使RF過度訓練而導致“過擬合”;同樣,mtry設置太小易使RF過度訓練而導致“過擬合”,設置太大會使得RF訓練不充分而導致模型“欠擬合”。“過擬合”“欠擬合”均會降低RF模型的分類性能[20]。本文基于Matlab軟件環境和randomforest工具箱,利用RDPSO算法尋優RF關鍵參數決策樹數量(ntree)和分裂屬性個數(mtry)。
1.3 RDPSO-RF評價實現步驟
Step1基于水源地水質評價因子和GB 3838—2002《地表水環境質量標準》分級閾值構造RF模型訓練及測試樣本,進行歸一化處理,并合理劃分訓練樣本和測試樣本。設定決策樹數量ntree和分裂屬性個數mtry搜尋范圍。
Step2確定適應度函數。本文選用訓練樣本均方誤差作為適應度函數,描述如下:
(13)
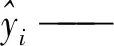
Step3設置RDPSO算法群體大小N,最大迭代次數T,最大、最小熱敏系數α,常數c1和c2。設置當前迭代次數t=0,初始化粒子位置和速度。
Step4計算漂移系數β,依據式(8)更新群體平均最優位置。
Step5基于式(13)計算目標適應度值,更新全局最優位置G和粒子局部最優位置P。
Step6根據式(10)、(11)更新粒子的速度和位置。
Step7判斷算法迭代終止條件是否滿足,若滿足則轉至Step8,否則令t=t+1,并執行Step4—7。
Step8輸出最優適應度值和最優粒子個體空間位置,即待優化問題的最優適應度值及最優解。
Step9利用RDPSO算法優化獲得的決策樹數量ntree和分裂屬性個數mtry代入RDPSO-RF模型對測試樣本進行評價。
Step10利用測試好的RDPSO-RF模型對紅河州17個水庫型水源地水質進行綜合評價。
2 實例應用
2.1 基本概況
紅河州位于云南省東南部,北連昆明,東接文山,西鄰玉溪,南與越南接壤,北回歸線橫貫東西。紅河州是云南省第四大經濟體,經濟總量和部分社會經濟指標居中國30個少數民族自治州之首。全州國土面積32 931 km2,轄4市9縣,多年平均水資源量214.03億m3。紅河州4市9縣共有城市集中式飲用水水源地25個,其中,水庫型城市集中式飲用水水源地17個,河流型8個,龍潭型地下水4個。本文以云南省水文水資源局紅河分局2017年監測的17個水庫型城市集中式飲用水水源地水質綜合評價為例進行實例研究,選取對水體影響較大的NH3-N、TN、CODMn、BOD5、TP、氟化物和糞大腸菌群的年均值作為水質綜合評價影響因子,利用RDPSO-RF及RDPSO-SVR模型分別對其進行綜合評價。水質監測數據及分級標準見表1、2。
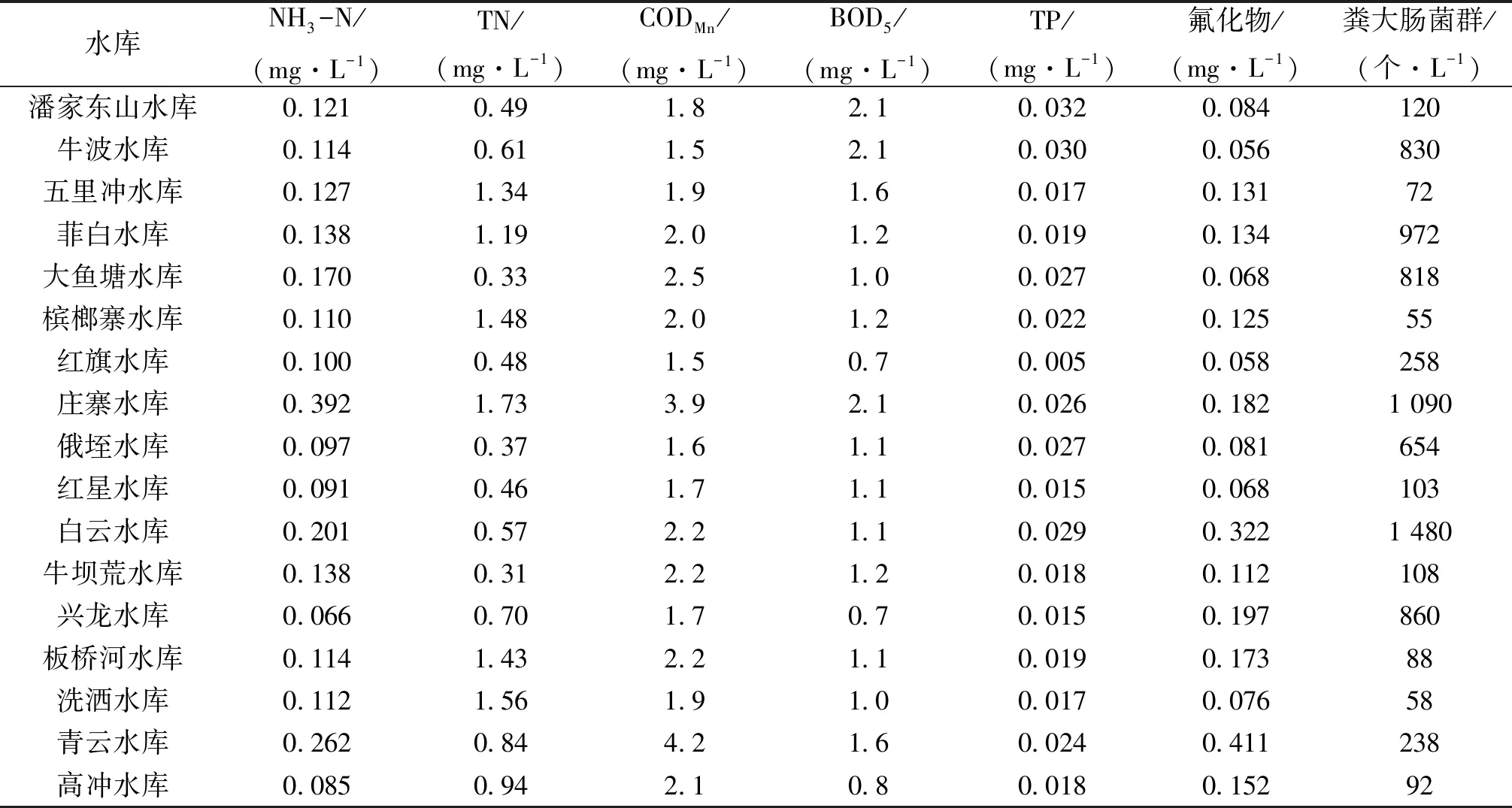
表1 2017年紅河州各水源地7項水質評價因子監測值

表2 7項水質評價因子分級標準值及限值
注:由于GB 3838—2002《地表水環境質量標準》中氟化物Ⅰ~Ⅲ類和Ⅳ~Ⅴ類分級閾值相同,不甚合理,筆者對其分級閾值進行劃分
2.2 模型構建與參數設置
a) 構建樣本。采用隨機內插的方法在7個評價因子分級標準閾值間生成40組樣本(7個評價因子最小值均設置為0),共隨機內插得到200組樣本,隨機選取150組作為訓練樣本,50組作為測試樣本,將1~5作為Ⅰ、Ⅱ、Ⅲ、Ⅳ、Ⅴ類水質類別的模擬輸出,并對各評價因子進行[0,1]歸一化處理。
b) 參數設置。RDPSO算法最大迭代次數T=100,最大、最小熱敏系數α分別設置為0.9、0.3(參考文獻[15-17],并經反復調試確定,當最大、最小熱敏系數α分別設置為0.9、0.3時RDPSO算法尋優效果最佳),常數c1、c2均設置為2。RF、SVR待優化參數搜索空間設置為:RF決策樹數量ntree∈[2,400],分裂屬性個數mtry∈[2,10];SVR懲罰因子C∈[0.1,1000],核函數參數g∈[0.1,1000],不敏感系數ε∈[0.0001,1],交叉驗證參數V=5。
c) 模型構建及評價。基于上述分析和MatlabR2011b軟件環境,分別構建7輸入1輸出的水源地水質綜合評價模型。選取平均相對誤差絕對值MRE和最大相對誤差絕對值MaxRE作為評價指標。
2.3 模型檢驗
利用上述構造樣本對RDPSO-RF、RDPSO-SVR模型進行訓練及測試,測試結果見表3。并給出RDPSO-RF、RDPSO-SVR模型的進化過程和測試樣本相對誤差,見圖1、2。
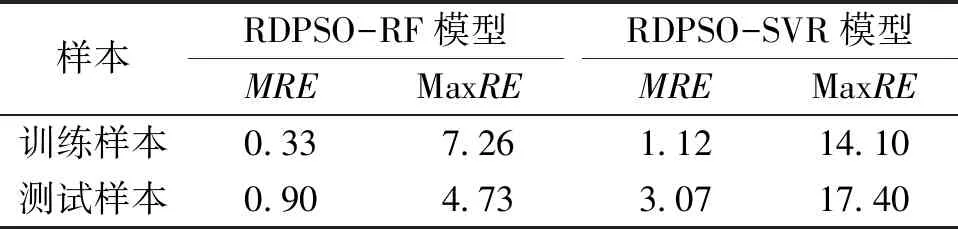
表3 2種模型樣本評價結果 %
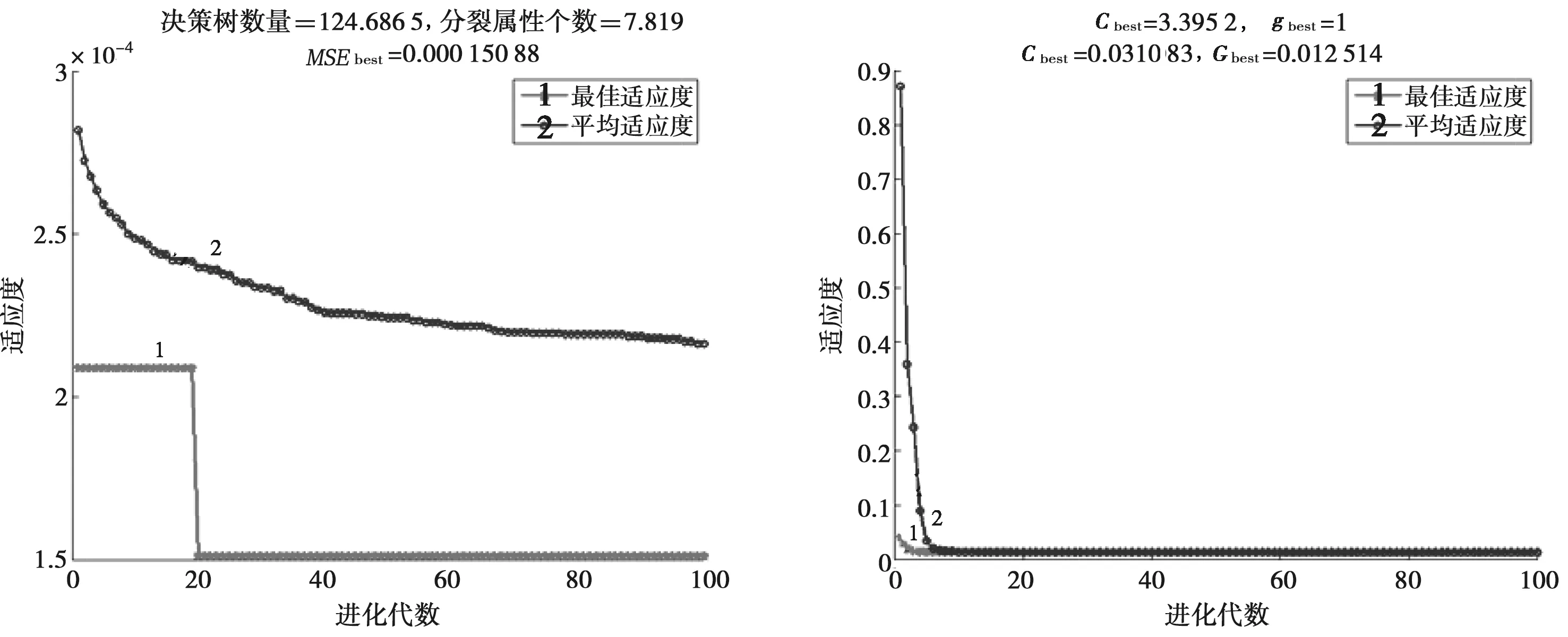
a)RDPSO-RF進化過程 b)RDPSO-SVR進化過程圖1 RDPSO-RF、RDPSO-SVR模型進化過程
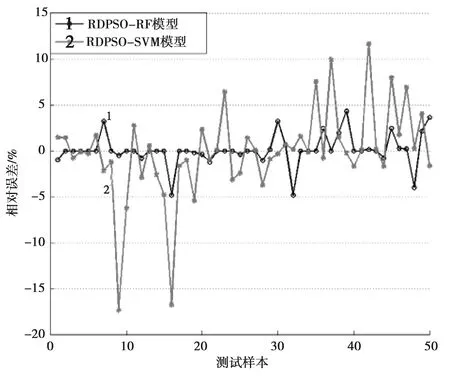
圖2 RDPSO-RF、RDPSO-SVR模型監測樣本相對誤差效果
從表3及圖1、2可以看出,RDPSO-RF模型訓練樣本的MRE、MaxRE分別為0.33%、7.26%,優于對比模型RDPSO-SVR的1.12%、14.10%;測試樣本的MRE、MaxRE分別為0.90%、4.83%,優于對比模型RDPSO-SVR的3.07%、17.40%;最優適應度值0.000 15,同樣優于對比模型RDPSO-SVR的0.012 51。可見,無論是訓練樣本還是測試樣本,RDPSO-RF模型評價精度均優于RDPSO-SVR模型,具有較好的評價精度和泛化能力。
2.4 水源地水質綜合評價
利用上述測試好的RDPSO-RF、RDPSO-SVR模型對表1中紅河州17個水庫型集中式飲用水水源地水質進行綜合評價,并與單因子評價法評價結果進行比較,見表4。利用表2中各評價因子等級閾值輸出值劃分水質綜合評價等級。經模擬,RDPSO-RF模型劃分依據為:Ⅰ類<1.39、Ⅱ類∈[1.39,2.17)、Ⅲ類∈[2.17,3.10)、Ⅳ類∈[3.10,4.03)、Ⅴ類∈[4.03,5.00)和劣Ⅴ類≥5.00。RDPSO-SVR模型劃分依據為:Ⅰ類<1.54、Ⅱ類∈[1.54,2.52)、Ⅲ類∈[2.52,3.18)、Ⅳ類∈[3.18,4.19)、Ⅴ類∈[4.19,4.59)和劣Ⅴ類≥4.59。
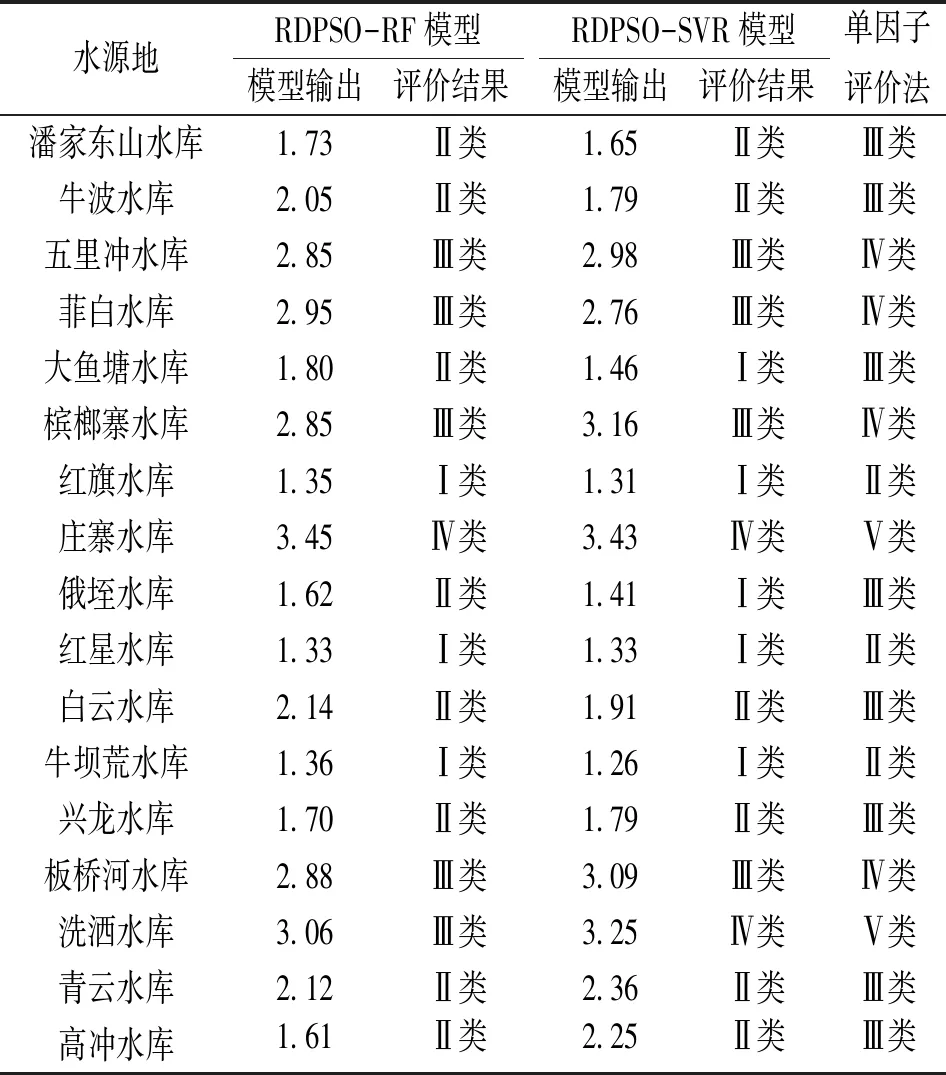
表4 紅河州水庫型集中式飲用水水源地水質綜合評價結果及比較
a) RDPSO-RF模型的評價結果比單因子評價法評價結果低1個等級(除洗灑水庫低2個等級外)。其中,莊寨水庫評價為Ⅳ類,從表1來看,莊寨水庫總氮Ⅴ類、總磷Ⅲ類、糞大腸菌群和氨氮Ⅱ類,莊寨水庫存在一定程度的污染,水質綜合評價為Ⅳ類,符合客觀實際;五里沖水庫(總氮Ⅳ類、總磷Ⅱ類、其余Ⅰ類)、菲白水庫(總氮Ⅳ類、總磷和糞大腸菌群Ⅱ類、其余Ⅰ類)、檳榔寨水庫(總氮Ⅳ類、總磷Ⅱ類、其余Ⅰ類)、板橋河水庫(總氮Ⅳ類、高錳鹽指標和總磷Ⅱ類、其余Ⅰ類)、洗灑水庫(總氮Ⅴ類、總磷Ⅱ類、其余Ⅰ類)5個水源地總氮存一定的超標現象,但其余指標均不劣于Ⅱ類,總體評價為Ⅲ類符合水庫水質現狀;其余11個水庫各評價因子水質不劣于Ⅲ類或Ⅱ類,水質綜合評價牌Ⅱ~Ⅰ類之間較為客觀。
b) RDPSO-RF模型與RDPSO-SVR模型評價結果基本相同,但大魚塘水庫、俄垤水庫和洗灑水庫評價結果存在差異。對于大魚塘水庫,總磷Ⅲ類,氨氮、總氮、高錳酸鹽指數和糞大腸菌群Ⅱ類,水質綜合評價為Ⅰ類顯然不符合客觀實際,評價為Ⅱ類與水質現狀較為接近;對于俄垤水庫,總磷Ⅲ類,總氮和糞大腸菌群Ⅱ類,水質綜合評價為Ⅱ類符合水質現狀;對于洗灑水庫,總氮Ⅴ類,總磷Ⅱ類,其余Ⅰ類,其影響水質綜合評價的因素較少,水質綜合模輸出3.06,雖然水質綜合評價為Ⅲ類,但較接近Ⅳ類臨界值3.10,評價結果符合現狀水質。表明RDPSO-RF模型較RDPSO-SVR模型具有更高的評價精度。
c) RDPSO-RF模型不但可以科學、客觀評價各集中式飲用水水源地水質綜合類別,而且可從模型輸出值大小客觀反映17個水庫型水源地水質相對優劣程度。
3 結論
a) 依據隨機漂移粒子群(RDPSO)算法良好的全局搜索能力和隨機森林(RF)強分類集成器二者的優點,提出RDPSO-RF水源地水質綜合評價模型,并給出RDPSO-RF模型的構建方法和實現步驟,進一步拓展了群體仿生智能算法優化RF模型關鍵參數的應用范疇。
b) 基于GB 3838—2002《地表水環境質量標準》指標分級閾值構造樣本對RDPSO-RF、RDPSO-SVR模型進行訓練和測試,并利用測試好的RDPSO-RF、RDPSO-SVR對實例水質綜合類別進行評價,樣本構造方法和模型檢驗方法具有一定的參考意義。
c) 通過RDPSO-RF、RDPSO-SVR模型對測試樣本檢驗和對實例17個水源地水質進行綜合評價,結果表明,RDPSO-RF模型評價精度遠優于RDPSO-SVR模型,具有較好的評價精度和泛化能力。將RDPSO-RF模型用于集中式飲用水水源地水質綜合評價是可行和有效的,可為相關評價研究提供參考。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
環境(2023年5期)2023-06-30 01:20:01
石油瀝青(2021年4期)2021-10-14 08:50:44
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
當代水產(2019年1期)2019-05-16 02:42:04
光學精密工程(2016年6期)2016-11-07 09:07:19
中國教育技術裝備(2015年19期)2015-03-01 02:43:07
河南科技(2014年23期)2014-02-27 14:19:07
河南科技(2014年18期)2014-02-27 14:14:54
