基于深度CNN和極限學習機相結合的實時文檔分類
2019-04-01 09:10:08董鶯艷
計算機應用與軟件 2019年3期
閆 河 王 鵬 董鶯艷 羅 成 李 煥
1(重慶理工大學計算機科學與工程學院 重慶 401320) 2(重慶理工大學兩江人工智能學院 重慶 401147)
0 引 言
如今,商業文件(見圖1)通常由文檔分析系統(DAS)進行處理,以減少工作人員的工作量。DAS的一項重要任務是對文檔進行分類,即確定文檔所指的業務流程的類型。典型的文檔類是發票、地址變更或索賠等。文檔分類方法可分為基于圖像[1-6]和基于內容的方法[7-8]。DAS選取哪一種方法更合適,通常取決于用戶處理的文檔。像通常的字母一樣,自由格式的文檔通常需要基于內容的分類,而在不同布局中包含相同文本的表單則可以通過基于圖像的方法來區分。

圖1 來自不同類別的Tobacco-3482數據集的樣本圖像
然而,并不總是事先知道文檔屬于什么類別,這就是為什么在基于圖像的方法和基于內容的方法之間很難選擇的原因。一般來說,基于圖像的方法是大多數學者首選的方法,因為它直接工作在數字圖像上。由于文檔圖像類的多樣性,存在高類內方差和低類間方差的類,分別如圖2和圖3所示。因此,很難找到用于文檔圖像分類的人工特征提取方法。

圖2 Tobacco-3482數據集廣告類的文檔, 顯示了較高的類內差異

圖3 不同類別數據集的類間差異
近幾年,隨著深度學習的發展,該技術已經應用到眾多領域。眾多學者將深度學習應用于文檔結構學習中,使用CNN自動學習并提取文檔圖像中的特征,然后對文檔圖像進行分類。然而,同樣在這種方法中,即使使用GPU訓練此過程也非常耗時。通過以上分析,以下簡要概述相關研究發展歷程。
文獻[9]使用布局和結構相似性方法進行文檔匹配,而文獻[10]將基于文本和布局的特征結合起來。2012年,文獻[4]中提出了一種文檔分類的方法,該方法依賴于從文檔圖像的圖像塊中派生出的編碼碼字符。在文檔學習中編碼字典是以一種無監督的學習方式。為此,該方法遞歸地將圖像劃分為塊,并使用圖像塊中字的直方圖來建模圖像塊之間的空間聯系。兩年后,同一位作者還提出了另一種方法,即建立文檔圖像SURF描述符的編碼記錄[11],并用之前所提方法,運用這些特征用于文檔分類。Chen等[5]提出了一種利用低層圖像特征對文檔進行分類的方法。然而,它們的方法僅限于結構化文檔。以上方法大部分都局限于結構化文件。文獻[6]中使用二進制圖像中的像素信息對表單文檔進行分類。該方法利用k均值算法對圖像進行像素密度分類。在文獻[12]中,為了準確地識別出中文、日語、泰語等文檔,本文提出了CE-CLCNN的深度卷積網絡結構。這種結構是基于端到端的學習模型,并通過對文檔的每個字符作為文檔處理。實驗表明,該方法取得了不錯的識別分類效果。文獻[13]中運用卷積神經網絡識別文檔圖像,并運用智能手機的相機提取文檔字符,解決了文檔因權限不能下載等問題,通過在文檔圖片上的對比實驗取得了較好的效果。文獻[14]中提出了一種多視角重構方法,將高維數據映射到低維空間,通過降維處理,并應用于文檔分類識別,通過實驗驗證了此方法有效。文獻[15]提出預訓練網絡結構,并通過訓練學習不同大小的文檔圖像,以增加訓練的數據量,在英文和印度文上的實驗結果表明,此方法具有更好的識別效果。文獻[16]提出了基于區域的深度卷積神經網絡框架,用于文檔學習,在ImageNet數據集中,通過預訓練vgg-16網絡結構中導出權重來訓練文檔分類器,從而實現“域間”轉移學習。文獻[17]運用了輕量級的神經網絡訓練Tobacco-3482數據集,在沒有使用遷移學習的條件下,取得了不錯的效果。在文獻[18]中,比較了RVL-CDIP數據集上的使用AlexNet和Google網絡架構的性能,顯示出比常規方法更高的魯棒性。同時,在文獻[19]分別用AlexNet、VGG-16、Google和ResNet-50模型對RVL-CDIP和Tobacco3482數據集進行了遷移學習測試。盡管上述基于CNN的深度學習方法在魯棒性等方面有了很大的提升,但是大部分網絡的訓練非常耗時。為了使深度神經網絡CNN表現出最佳性能同時滿足實時訓練要求,本文提出使用CNNs[20]和極限學習機(ELM)[21-22]相結合的方法。
在本文中,我們提出使用極限學習機(ELM)的方法完成實時訓練。為了克服人工特征提取和長時間訓練的困難,我們設計了一種將深度CNN的自動特征學習與高效的極限學習機相結合的方法。此方法共有兩階段:第一階段是深度神經網絡的訓練并將其用作特征提取器;第二階段用ELM進行分類。ELM的本質不同于其他神經網絡,具有高效迅速等特點。結果表明,在一幅圖像上平均訓練時間僅需1 ms,因此顯示出對于實時性能的要求。同時,該方法使得神經網絡非常適合在增量學習框架中使用。
1 極限學習機

(1)
式中:wi是連接第i個隱含節點和輸出節點的權值矩陣;βi是第i個節點的輸出權值向量;bi是偏置;函數g為relu、sigmoid等激活函數。
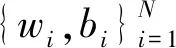
(2)
式中:正則化是為了避免過擬合,其中C是調整系數,通過計算H=[[ψ(x1)]T,[ψ(x2)]T,…,[ψ(xN)]T]T和T=[t1,t2,…,tN]可以得到如下的最優化問題,并稱為嶺回歸:
(3)
上述問題是凸優化問題,并受下列線性條件的約束。
B+CHT(T-HB)=0
(4)
該線性系統可以用數值方法求解,從而得到最優解B*。
(5)
本文方法不需要高分辨率的文檔特征,如光學字符識別。相反,它完全依賴于文檔的結構和布局來對它們進行分類。
本文提出的網絡體系結構是基于AlexNet[21]的CNN網絡。它由五個卷積層和一個極限學習機組成。與原有的AlexNet體系結構一樣,在最后一個最大池層之后,我們得到了256個大小為6×6的特征映射(如圖4所示)。雖然AlexNet使用多個完全連接的層來對生成的特征映射進行分類,但我們建議使用單層ELM。卷積層的權重是在一個大型數據集上預先訓練成一個完整的AlexNet網絡,此網絡有三個全連接層和標準反向傳播機制。在訓練結束后,全連接層被丟棄,卷積層被固定,并作為特征提取器。然后,由CNN提取的特征向量作為ELM訓練和測試的輸入向量。該體系結構中使用的ELM是一種單層前饋神經網絡。當目標數據集有10類時,我們用隱藏層中的2 000個神經元和10個輸出神經元對極限學習機進行測試。隱含層神經元以sigmiod作為激活函數。
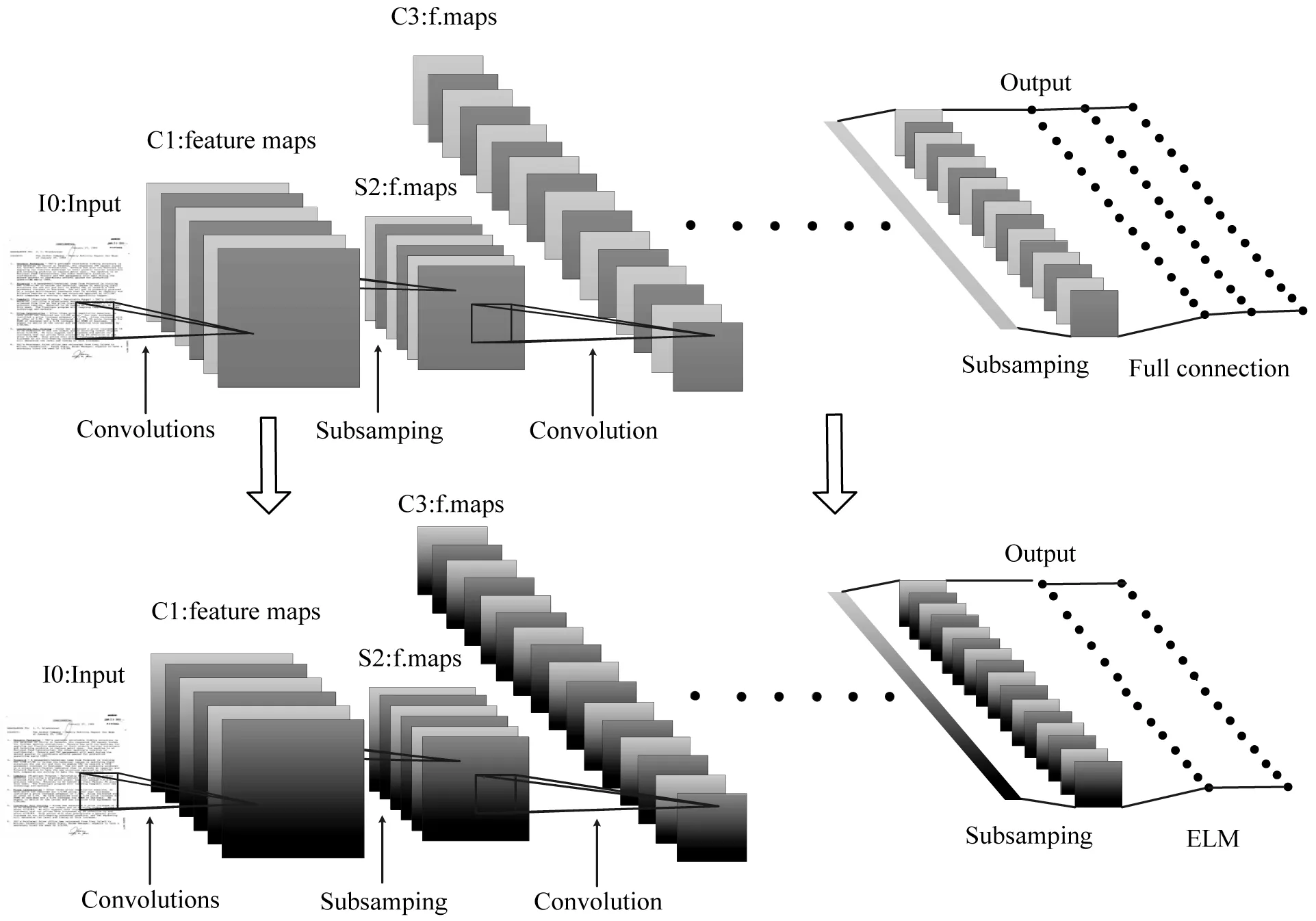
圖4 CNN與ELM結合網絡圖
在一個大型數據集上訓練一個完整的AlexNet,為ELM提供一個有效的特征提取器,然后在目標數據集上對ELM進行訓練。具體來說,在數據集上訓練AlexNet網絡,其中數據中包含16個類。因此,AlexNet最后一個全連接層中的神經元數目從1 000變為16。除了最后一個網絡層之外,所有的網絡層都是使用在ImageNet上預先訓練過的AlexNet網絡模型,并保留此模型的初始化條件。訓練使用隨機梯度下降,批量大小為25,初始學習速率為0.001,動量為0.9,重量衰減為0.000 5。為了防止過擬合,第六層和第七層配置dropout ratio為0.5。經過40次迭代的訓練后,完成了整個訓練過程。本文用Caffe框架[24]來訓練這個模型。
極限學習機被用來訓練和評估包含10個類別的圖像Tobacco-3482數據集[11]。這些圖像通過CNN訓練后并將第五個池化層的激活值傳遞給ELM(全連接層)。
2 實驗和結果
2.1 實 驗
在本文中,使用了兩個數據集。首先,我們使用Ryerson視覺實驗室復雜文檔信息處理(RVL-CDIP)數據集[3]來訓練一個完整的AlexNet。此數據集包含400 000幅圖像,其中分布著16個類,320 000幅用于訓練,40 000幅用于驗證和測試。
其次,我們使用Tobacco-3482數據集[11]對提出的ELM進行訓練,并對其性能進行評價。訓練結果如表1所示。此數據集包含來自10個文檔類的3 482幅圖像。由于兩個數據集之間存在一些重疊,因此我們將包含在大數據集中的兩個數據集排除。AlexNet并不是對32萬幅圖像進行訓練,而是只對319 784幅圖像進行訓練。
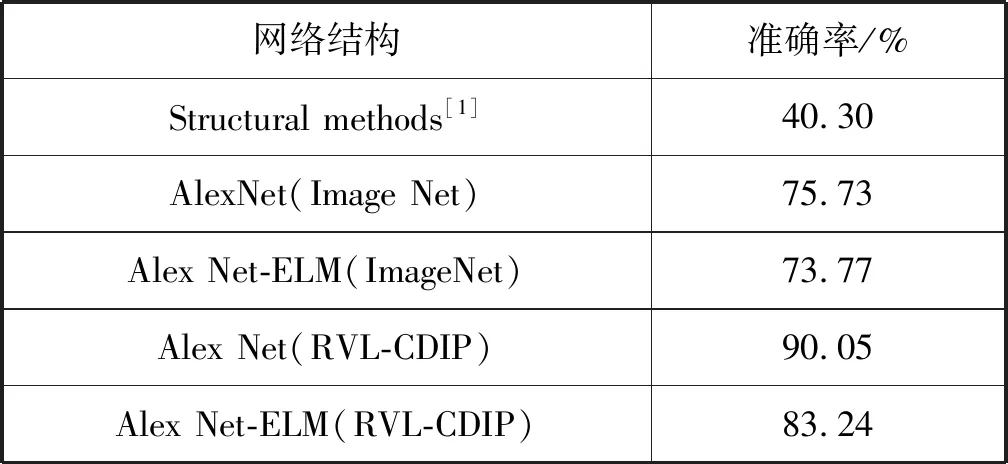
表1 在數據集Tobacco-3482上采用不同預訓練方法 得到的準確率比較
為了與Tobacco-3482數據集上的其他方法進行公正的比較,我們使用了與Kang[2]和Harley[3]類似的評估標準。具體來說,我們只使用Tobacco-3482數據集的子集進行訓練,從每類10幅圖像到每類100幅圖像不等,剩下的圖像用于測試。由于數據集非常小,因此對于每個數據集分為10個不同的數據集來訓練和評估分類器,并得到評估的性能。訓練時間對比如表2所示。

表2 圖像分類所需的時間對比
由于本實驗需要最初的網絡結構AlexNet,因而需要對AlexNet進行訓練,通過運用ImageNet預先訓練好完整的網絡結構,與Afzal等[1]使用Tobacco-3482數據集訓練網絡一樣。前面我們訓練了多個版本的網絡,每個訓練數據的大小劃分為10個不同的區間,即每類圖像分別為10,20,…,100,共訓練了100個網絡。這些實驗的訓練數據集進一步細分為用于實際訓練的數據集(80%)和用于驗證的數據集(20%)。
我們對319 784幅RVL-CDIP語料庫的圖像進行了初始化AlexNet的訓練,并丟棄了網絡中全連接的部分。保留的網絡結構被用作特征提取器來訓練和測試極限學習機。極限學習機在Tobacco-3482數據集上訓練。由于這些網絡初始權值都是隨機初始化,我們為100個分區中的每一類訓練10個ELM,并得到每個分區的平均精度。訓練對比如圖5所示。
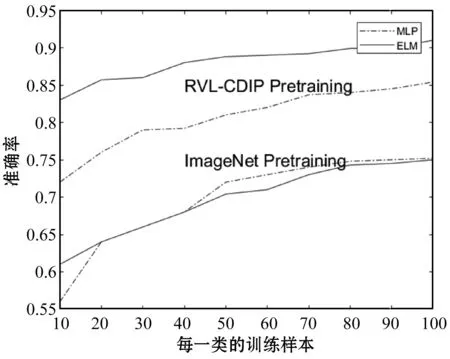
圖5 不同ELM分類器與原始網絡的平均精度對比圖
2.2 結 果
本文提出的分類器性能與圖5中描述的Artis狀態相比較,帶有文檔預訓練的ELM分類器的性能已經優于當前最先進的技術水平。每類100個訓練樣本,測試準確率由75.73%提高到83.24%,相比較減少30%以上的誤差。隨著識別性能的提高,訓練和測試所需的運行時間也減少了。特別是在GPU加速訓練的情況下,本文方法比當前先進水平快500多倍。對于訓練和測試,CNN與ELM相結合的方法每幅圖像識別只需要約1 ms,從而實現了實時性。超過90%運行耗時用于特征提取,使用不同的CNN架構可以進一步加快速度。采用ImageNet預訓練的ELM分類器達到了與目前最先進水平相當的精度,其計算成本僅為計算量的一小部分。
圖6顯示了對每類100幅圖像進行訓練的示例性ELM分類器的混淆矩陣。可以看出,科學這一類文本是迄今為止最難辨認的。這個結果是與Afzal等[1]的實驗結果一致,同時也可以解釋科學類與報告類之間的低類間差異。

圖6 ELM的混淆矩陣
3 結 語
本文主要解決了文檔分類和實時訓練的問題,提出了針對文檔分類的實時訓練方法。本文方法主要分為兩個步驟:首先選用深度神經網絡完成對特征的有效提取;然后運用極限學習機對數據的高效訓練。使用極限學習機后,數據的訓練效率和訓練的時間明顯提升。通過在眾多評定標準和對比實驗下證明了本文方法的有效性和魯棒性。對于文檔分類識別領域是一次重大的突破。
下一步研究方向是如何快速提取圖像特征,因為在本文方法中,超過90%的時間用于從深層神經網絡中提取特征。另一個的研究方向是在一個高性能集群中對googlenet和Resnet-50與ELM結合的分類器進行進一步性能測試。
猜你喜歡
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
兒童故事畫報(2019年5期)2019-05-26 14:26:14
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
Coco薇(2016年2期)2016-03-22 02:42:52
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年7期)2015-08-11 15:03:12
少兒科學周刊·少年版(2015年3期)2015-07-07 21:00:00
