安全協議綜合識別方法
2019-04-02 08:07:20王文濤
網絡安全技術與應用 2019年3期
關鍵詞:特征
◆王文濤
?
安全協議綜合識別方法
◆王文濤
(解放軍91033部隊 山東 266003)
安全協議識別技術是信息安全領域的關鍵問題。現有的三類協議識別方法各有優缺點。本文首先分析研究安全協議識別特征項,在此基礎上,綜合利用現有協議識別方法,給出安全協議識別策略,提出安全協議識別算法,識別報文所屬的安全協議類型。實驗結果表明本文方法可以有效識別安全協議。
安全協議;協議識別;端口特征;負載內容特征;流量統計特征
0 引言
當前大量網絡安全關鍵應用都以其所采用網絡協議的詳細描述為基礎,網絡協議流量分析也成為各種安全應用的重要環節。基于網絡報文數據,識別信息系統所采用的協議類型是網絡協議流量分析的關鍵內容,有助于對各種網絡應用實施監控和管理,能夠有效降低系統面臨的安全風險,提升信息系統抵御惡意攻擊的能力。
隨著密碼技術的廣泛應用,安全協議被大量應用在互聯網各種核心、關鍵應用中,與安全協議相關的各種數據在網絡流量中比重日益增加,對安全協議的識別已成為當前網絡安全技術中關鍵技術之一。
現有協議識別方法主要包括基于端口映射的方法、基于負載內容的方法、基于流量統計特征的方法。在協議識別的早期,許多傳統應用大都采用由IANA分配的固定端口,因此可以依據端口號快速地識別出相應的網絡協議。隨著采用動態端口技術和復用端口技術的應用不斷增加,基于端口映射的識別方法在很多協議上識別失效,人們開始研究基于負載內容的識別方法,利用協議負載的內容特征進行識別。該方法能夠實現精確的協議識別,但需要預先建立待識別協議的特征項,對新版本協議的識別存在一定的滯后性;對包含加密內容的安全協議,由于可提取的特征較為稀少,特征提取難度較大。為了不依賴于報文的負載內容識別協議,基于流量統計特征的協議識別方法受到了關注,其基本思想是:相同協議的網絡流具有相似的流量統計特征,可依據網絡報文的流量統計特征完成對協議的識別。相對基于負載內容的協議識別方法,基于流量統計特征的協議識別方法可以識別全加密的協議,性能高,但是準確性和健壯性不如基于負載內容的方法。由上可知,這三類協議識別方法各有優缺點。如何結合各種方法的優點,使其優勢互補是協議識別領域的重要研究方向。
本文在分析研究安全協議特征項的基礎上,綜合利用現有三類協議識別方法,給出安全協議識別策略,提出一種安全協議綜合識別方法,并在此基礎上識別網絡流量所屬的安全協議類型。
1 安全協議識別特征項分析
本節對安全協議識別特征項進行分析研究,下面進行詳細闡述。
(1)端口特征項
與普通網絡協議相似,安全協議也有各自對應的通信端口,通過向這些固定的端口發送和接收數據完成協議連接和數據交換。因此,可借助端口特征識別安全協議。
(2)負載關鍵詞特征項
絕大多數的網絡協議都在報文格式中定義一個或多個用于標識協議報文類型和傳遞相關控制信息的協議字段,該字段稱為協議關鍵詞。協議的關鍵詞可以是協議包頭中的特征字符串,包括協議名稱、版本號等,也可以是協議控制信息的特征字符串,包括命令碼、標識信息等。關鍵詞在協議中頻繁出現,是組成協議特征的重要元素。
大多數安全協議都存在明文部分,用于在會話開始時協商參數,因此通常也存在關鍵詞字段。例如,SSL協議通信雙方使用明文交互版本號和相關參數等,在SSL協議(TLSV1.2版本)的ClientHello報文頭中,第0個偏移位置的字節值為“0x16”,表示協議類型為SSL握手協議,第1-2偏移位置的2個字節值為“0x03,0x03”,表示協議版本采用TLS1.2。
(3)統計特征項
安全協議中包含大量密文信息,其可用明文關鍵詞信息相對普通網絡協議更為稀少,但安全協議相關的流量統計特征不受加密影響,容易提取,其中數據包大小、包到達時間間隔是關鍵特征。Charles Wright等人認為:數據包大小、數據包到達時間間隔以及到達方向是不受加密影響的,并基于上述特征識別加密協議。Este等人利用互信息量比較網絡流特征的時空穩定性,發現TCP連接建立后的第一個數據包大小所含的信息量最大,并在不同的時間和地點采集的數據上進行測試,驗證了數據包大小是最穩定的特征。
(4)總結
為對協議流量進行早期識別,P. Haffner指出只需要流中前64B負載就可以很好地發掘協議識別特征。本文采用端口、流中前64B負載的關鍵詞、流中前N個數據包的大小和包到達間隔時間作為安全協議識別特征。
2 安全協議識別方法
本節給出安全協議識別策略,并在此基礎上提出安全協議識別算法。
2.1 安全協議識別策略
協議在網絡運行中以IP數據包形式進行傳輸。同一個雙向流中的數據包通常屬于同一種協議,將數據包組合成流進行考慮可以降低復雜度。識別策略如下:
(1)基于流識別協議。安全協議識別在流的基礎上進行,對每一個流記錄識別狀態,包括已識別(標記協議類型)、尚未識別(標記正在使用的識別方法)、不可識別三種狀態,直到流結束。對每一個到達的數據包判斷其所在流是否識別,若識別,將該數據包并入該流,更新流狀態;若未識別,則需要進一步利用該數據包進行識別。
(2)基于反向流識別協議。當流(SIP、SPort、DIP、DPort、Transport_protocol)被識別為協議A時,其反向流(DIP、DPort、SIP、SPort、Transport_protocol)同樣識別為協議A。
(3)分階段識別協議。對協議特征庫中的每一個安全協議,給出各自的識別策略,設置其所使用的識別方法和優先級。端口特征是最簡單、復雜度最低的特征。負載關鍵詞特征——流中前64B負載中關鍵詞是最精準的特征,并且由于只需考慮流中前64B負載,復雜度較低。現有的協議識別系統大都是基于負載關鍵詞特征的。統計特征——負載統計特征和數據包統計特征容易獲取,復雜度低,但屬于模糊特征,其識別準確度不如負載關鍵詞特征。本文對識別方法設置優先級,按照端口識別——>DPI——>基于統計特征識別的順序,分階段進行識別。在每個階段,若成功識別,則標記相應的協議類型;若未識別,則采用下一階段進行識別;若所有階段均未識別,則將該流標記為不可識別。
2.2 安全協議識別算法
識別算法如圖1所示。

圖1 安全協議識別算法
Step1:對每一個到達的網絡數據包,查找其所屬流是否存在。若所屬流不存在,產生新的流標識,將流識別狀態標記為“尚未識別”,識別方法設置為“端口識別”;若所屬流存在,執行Step2;
Step2:查找數據包所屬流或者反向流的識別狀態,若為“已識別”和“不可識別”,則不再對數據包進行識別,輸出相應的協議類型;若為“尚未識別”,則執行Step3;
Step3:對尚未識別協議類型的數據包,根據其正在使用的識別方法進行在線特征提取。若正在使用的識別方法為端口識別,則從數據包的傳輸層頭部獲取流的端口特征,并利用端口識別規則與實例特征庫中的協議端口值進行匹配。若存在相同的協議端口值,則輸出相應的協議類型;若不存在相同的協議端口值,則執行Step4,并將所采用的識別方法設置為“負載關鍵詞識別”;
Step4:根據協議關鍵詞特征提取報文中的消息內容,并進行匹配。
①當協議關鍵詞為固定偏移關鍵詞特征時,在數據包的應用層負載中根據關鍵詞的偏移、長度查找相應字段,并與關鍵詞的值進行匹配,若相同,則成功匹配,繼續與協議中下一關鍵詞進行匹配,直到最后一個關鍵詞匹配完畢;若不同,則不屬于該類協議,與下一協議的關鍵詞特征進行匹配;
②當協議關鍵詞為非固定偏移關鍵詞時,則需要在數據包的應用層負載中查找與關鍵詞值相同的字段,若存在,則成功匹配,繼續與協議中下一關鍵詞進行匹配,直到最后一個關鍵詞匹配完畢;若不存在,則不屬于該類協議,與下一協議的關鍵詞特征進行匹配;
③若協議關鍵詞序列全部成功匹配,則成功識別,輸出該報文所屬流的協議類型,并將流識別狀態標記為“已識別”;
④若協議特征庫中所有協議的關鍵詞特征均與該報文所屬流不同,則將流識別方法設置為“統計特征識別”。
Step5:提取數據包所屬流的統計特征,并根據協議特征庫中的統計特征進行識別。在協議特征庫中每個協議的統計特征由類簇中心和距離閾值刻畫。計算提取的特征向量與所有協議類簇中心之間的歐式距離。①若特征向量與所有協議類簇中心之間的歐式距離均大于給定的距離閾值,則將該流識別狀態標記為“不可識別”;②若存在協議類簇中心使得歐式距離小于給定的距離閾值,則選擇距離最近的類簇中心作為對應的協議類型,并將流識別狀態標記為“已識別”。
3 實驗評估
3.1 實驗數據
為驗證本文方法的識別效果,設計實現了安全協議在線監測平臺,并將其部署在實驗室交換機的旁路上。
對SSL、SSH、NS和sof協議進行訓練,并將這四類協議的特征存入安全協議特征庫中。本文的網絡流量除了以上4類協議外,還需要包含安全協議特征庫中未出現的流量,以測試識別方法對新類型協議的發現能力。
實驗中,采用10臺主機與交換機相連,并在主機上運行協議。本文選取SSL協議、SSH協議、NS公鑰協議、sof協議以及Skype協議、普通網絡協議(包括HTTP、FTP等)進行實驗,其中SSL、SSH和Skype協議是網絡中廣泛應用的安全協議;NS公鑰協議和Sof屬于經典基礎安全協議。SSL協議采用OpenSSL與Apache實現、SSH協議采用OpenSSH實現、NS公鑰協議和sof協議的應用程序采用Spi2Java工具生成、Skype應用程序可從其官網下載,FTP服務和HTTP服務利用IIS開啟。隨后,在交換機上通過端口鏡像,將全部網絡流量鏡像到管理服務器上。在管理服務器上運行安全協議監測平臺,對協議進行在線識別。協議流量數據集如表1所示。
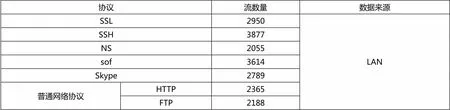
表1 協議流量數據集
3.2 識別性能指標
本文采用兩個性能指標(識別率和誤識別率)衡量協議識別效果。協議A的識別率是指:被正確識別為協議A的流量占協議A整個流量的百分比。協議A的誤識別率是指:被錯誤識別為協議A的流量占協議A整個流量與錯誤識別流量之和的百分比。識別率越高,誤識別率越低,說明相應的識別效果越好。
3.3 實驗結果
本文設計實現了安全協議在線監測平臺,以識別協議類型,識別效果如圖2所示。

圖2 協議識別效果圖
協議識別結果如圖3所示:(1)該平臺在識別出安全協議實例特征庫已有協議的同時,能夠區分出實例特征庫中未出現的協議,具有發現新類型協議的能力;(2)對每類協議,識別率基本在91.7%以上,誤識別率在5.8%以下,可以較好地識別協議。

(a)協議識別率(基本在91.7%以上)
(b)協議誤識別率(基本在5.8%以下)
圖3 協議識別結果
4 結束語
本文提出了一種安全協議綜合方法,給出了安全協議識別策略,在此基礎上提出了安全協議識別算法,識別網絡報文所屬的協議類型。實驗結果表明,本文方法可以較好地解決安全協議識別問題。
[1]Xu K, Zhang M, Ye MJ, Chiu DM, Wu JP. Identify P2P Traffic by Inspecting Data Transfer Behavior[J]. Journal of Computer Communications,2010.
[2]Aceto G,Dainotti A,Donato W,et al.PortLoad: Taking the Best of Two Worlds in Traffic Classification[A]. Proceeding of IEEE INFOCOM Conference on Computer Communicaitons Workshops[C].San Diego,California, USA,2010.
[3]Freire MM, Carvalho DA, Pereira M. Detection of Encrypted Traffic in eDonkey Network Through Application Signatures[A].First International Conference on Advances in P2P Systems[C].Sliema, 2009.
[4]Crotti M,Dusi M,Gringoli F,et al.Traffic Classification through Simple Statistical Fingerprinting[J].ACM SIGCOMM Computer Communication Review. 2007.
[5]Crotti M,Gringoli F,Salgarelli L.Optimizing statistical classifiers of network traffic[A]. Proceedings of the 6th International Wireless Communications and Mobile Computing Conference[C]. ACM,2010:758-763.
[6]Bacquet C,Gumus K,Tizer D,Zincir-Heywood A.N, Heywood M.I.A Comparison of Unsupervised Learning Techniques for Encrypted Traffic Identification[J]. Journal of Information Assurance and Security, 2010.
[7]Wright C, Monrose F,Masson G M.On inferring application protocol behaviors in encrypted network traffic[J].Journal of Machine Learning Research 7 (December 2006).
[8]Este A,Gringoli F,Salgarelli L.On the stability of the information carried by traffic flow features at the packet level[J].ACM SIGCOMM Computer Communication Review,2009.
[9]Tongaokar A, Keralapura R, Nucci A. SANTaClass: A Self Adaptive Network Traffic Classification System[A]. IFIP Networking,2013.
[10]Haffner P,Sen S,Spatscheck O,et al.ACAS: automated construction of application signatures[A]. Proceedings of the ACM SIGCOMM workshop on Mining network data[C]. ACM,2005.
猜你喜歡
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化(高中版.高考數學)(2022年3期)2022-04-26 14:04:16
數學年刊A輯(中文版)(2020年1期)2020-05-19 00:30:36
空間科學學報(2020年2期)2020-04-01 03:50:40
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
中等數學(2019年8期)2019-11-25 01:38:14
當代陜西(2019年10期)2019-06-03 10:12:04
新聞傳播(2018年11期)2018-08-29 08:15:24
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
廣西科技大學學報(2016年1期)2016-06-22 13:10:38
