基于KMSMOTE和隨機森林的爬升段油耗分類
2019-04-15 07:46:18陳靜杰崔金成
計算機應(yīng)用與軟件 2019年4期
關(guān)鍵詞:分類
陳靜杰 崔金成
(中國民航大學電子信息與自動化學院 天津 300300)
0 引 言
飛機在爬升的過程中,影響飛行燃油消耗的特征眾多,為了分析不同飛行特征對油耗的影響,需要根據(jù)影響爬升段油耗的主要飛行特征對飛行油耗數(shù)據(jù)進行分類[1]。由于收集的數(shù)據(jù)具有隨機性,致使油耗區(qū)間樣本分布不平衡。因此,本文以爬升段油耗為研究對象,并在數(shù)據(jù)層面處理不平衡性,以改善爬升段油耗分類結(jié)果。
針對數(shù)據(jù)不平衡的分類問題,國內(nèi)外許多學者在算法層面和數(shù)據(jù)層面進行了大量的研究。其中,基于算法層面的有代價敏感學習、集成算法等。文獻[2]采用改進的隨機森林算法,對構(gòu)成森林的每棵樹進行篩選,以方便分析高維空間中數(shù)據(jù)分布的不平衡問題。文獻[3]提出了權(quán)重采樣算法,即boosting中權(quán)重更新機制保持不變,弱學習器在采樣后的權(quán)重分布下學習,以提高分類器性能。文獻[4]提出了一種動態(tài)調(diào)整閾值的ε-KSVM分類器,在利用KSVM對待測樣本進行分類前,采用遺傳算法尋找最優(yōu)閾值ε。而基于數(shù)據(jù)層面主要有過采樣、欠采樣和混合采樣技術(shù)。文獻[5]采用改進的SMOTE算法構(gòu)造少數(shù)類樣本,充分利用異類近鄰的分布信息,對構(gòu)造的偽樣本的質(zhì)量和數(shù)量進行控制,用來提高分類準確率。文獻[6]針對數(shù)據(jù)樣本分布不平衡,提出一種基于概率分布的過采樣技術(shù)構(gòu)造偽樣本,然后使用隨機森林進行分類。文獻[7]采用SMOTE算法對少數(shù)類樣本進行過采樣,和欠采樣對多數(shù)類樣本進行去重,構(gòu)造更清晰的分類界面。
飛機飛行過程是一個復(fù)雜的非線性過程,極易受飛行環(huán)境影響,致使收集的樣本數(shù)據(jù)分布不平衡。根據(jù)少數(shù)類樣本在爬升段油耗上的分布,本文利用k-medoids對少數(shù)類樣本聚類,并使用SMOTE對聚類的簇構(gòu)造偽樣本。不僅能保證在很大程度上不破壞原始數(shù)據(jù)分布,還能有效提升數(shù)據(jù)集的質(zhì)量。另外,文中采用隨機森林作為爬升段油耗分類器,森林在建樹的過程中,訓練樣本采用隨機有放回的采樣,在一定程度上消除了數(shù)據(jù)不平衡對分類器的影響。
1 基于KMSMOTE的隨機森林
1.1 KMSMOTE基本原理
傳統(tǒng)的SMOTE算法從少數(shù)類樣本中隨機構(gòu)造偽樣本,對所有少數(shù)類樣本一視同仁,導致原始數(shù)據(jù)分布的改變。另一方面,如果構(gòu)造的偽樣本位于少數(shù)類與多數(shù)類的區(qū)間邊界,甚至向多數(shù)類靠攏,加大了誤分類的概率[8-9]。針對以上兩點,本文提出一種基于k-medoids聚類的改進SMOTE算法。KMSMOTE的基本思想是將少數(shù)類樣本進行聚類,記錄每一個聚類簇的中心值(簇心),之后SMOTE利用簇心對少數(shù)類進行插值構(gòu)造偽樣本。KMSMOTE算法具體計算過程如下:
(1) 確定需要聚類的個數(shù)k。
(2) 在少數(shù)類樣本集合中選取k個點作為各個聚簇的中心點。
(3) 計算其余所有點到k個中心點的距離,并把每個點到k個中心點最短的距離作為自己所屬的聚簇。
(4) 在每個聚簇中按照順序依次選取點,計算該點到當前聚簇中所有點距離之和,最終距離之和最小的點,則視為新的簇中心點。
(5) 重復(fù)步驟2、步驟3,直到各個聚簇的中心點不再改變。設(shè)最終各個類的簇心分別為{c1,c2,…,ck}。
(6) 選擇k-medoids聚類得到的簇心及其近鄰構(gòu)造偽樣本,對每一個簇心等概率的構(gòu)造偽樣本。使用改進的公式構(gòu)造樣本,公式如下:
xnew=ci+rand(0,1)×(xj-ci)i=1,2,…,k
(1)
式中:xnew為新構(gòu)造的樣本點;ci為簇心;xj是以ci為簇心的聚類簇里的樣本;rand(0,1)表示0到1之間的隨機數(shù)。
1.2 分類算法設(shè)計
針對爬升油耗數(shù)據(jù)分布不平衡問題,文中主要從數(shù)據(jù)層面入手,使用改進的SMOTE算法對少數(shù)類樣本進行插值處理,使其達到與多數(shù)類相同的樣本數(shù)。平衡樣本數(shù)據(jù)后,利用隨機森林的優(yōu)勢構(gòu)建爬升段油耗分類器[10-11]。隨機森林從訓練集中隨機有放回的選取樣本,訓練得到ntree棵CART決策樹,作為基分類器。將生成的多棵決策樹組成隨機森林,對于分類任務(wù),得到ntree個基分類器投出最多票數(shù)的類別為最終類別。基于KMSMOTE和隨機森林的分類算法,具體步驟如下:
(1) 從QAR數(shù)據(jù)中提取爬升段油耗及飛行特征,并對油耗數(shù)據(jù)進行離散化,得到不同飛行特征對應(yīng)的油耗類別。
(2) 利用KMSMOTE對少數(shù)類樣本進行插值構(gòu)造偽樣本,使其與多數(shù)類擁有相同的數(shù)據(jù)規(guī)模。
(3) 隨機森林分類。將原始數(shù)據(jù)訓練集進行平衡化處理之后,使用隨機森林對平衡后數(shù)據(jù)進行訓練和預(yù)測。其中,由于飛行特征多為連續(xù)特征,所以采用CART決策樹構(gòu)成隨機森林。
(4) 分類模型KMSMOTE-RF的訓練與驗證。
1.3 分類模型評價指標
采用準確率,精確率和召回率三個性能指標,評價分類器性能。這些評價指標的計算都需要用到如表1所示的三分類的混淆矩陣[12-13]。混淆矩陣的主對角元素(v11,v22,v33)為被分到正確類別的樣本數(shù),對角線以外的元素為隨機森林分類相對于樣本真實類別的誤分類數(shù)。其中,V1、V2和V3表示分類的類別。

表1 三分類混淆矩陣
準確率:指對于給定的測試數(shù)據(jù)集,分類器正確分類的樣本數(shù)與總樣本數(shù)的比值,反映了分類器對整個測試集樣本的判定能力,計算公式如下:
(2)
精確率:指被分類器預(yù)測的樣本中預(yù)測結(jié)果正確的比重,公式如下:
(3)
召回率:指被分類器正確預(yù)測的樣本占真實類別樣本的比重,公式如下:
(4)
2 實驗設(shè)計與結(jié)果分析
2.1 數(shù)據(jù)集
飛機的飛行一般包括起飛、爬升、巡航、下降和著陸五個階段。滑跑段和著路段情況復(fù)雜且油耗占比較少,文中只對爬升段油耗進行分析,巡航段和下降段油耗分析方法與爬升段類似。根據(jù)QAR數(shù)據(jù)和相關(guān)文獻[14-15],分析出4個影響爬升段油耗的主要飛行特征:(1) 爬升距離,即爬升段實飛距離,根據(jù)QAR數(shù)據(jù)里的經(jīng)緯度求出每秒大圓距離,累加可得。(2) 爬升時間,指爬升段所用的總時間。(3) 平均爬升率,即每分鐘飛機上升的高度。(4) 初始爬升重量,由飛機起飛前總重量減去滑跑段油耗量。另外,目標變量為爬升油耗,即爬升段平均油耗,根據(jù)飛機爬升期間,左發(fā)動機和右發(fā)動機燃油流量相加,對時間取平均值得出。
本文選取飛行航線為北京飛大連,機型為空客A331,共560個QAR航班數(shù)據(jù)為實驗樣本。同一航線、同一機型多個航班的爬升油耗是一個在區(qū)間內(nèi)隨機取值的連續(xù)性變量,首先需要將油耗數(shù)據(jù)進行離散化處理,本文采用等間距法將其劃分為三個互不相交的小區(qū)間,劃分結(jié)果如圖1所示。每個區(qū)間由一個類別標簽表示,分別為最小油耗區(qū)間V1、平均油耗區(qū)間V2和最大油耗區(qū)間V3。由圖2可以看出不同類別的樣本量極度不平衡,即類別之間的比例失調(diào),致使預(yù)測結(jié)果會偏向較多樣本的類。
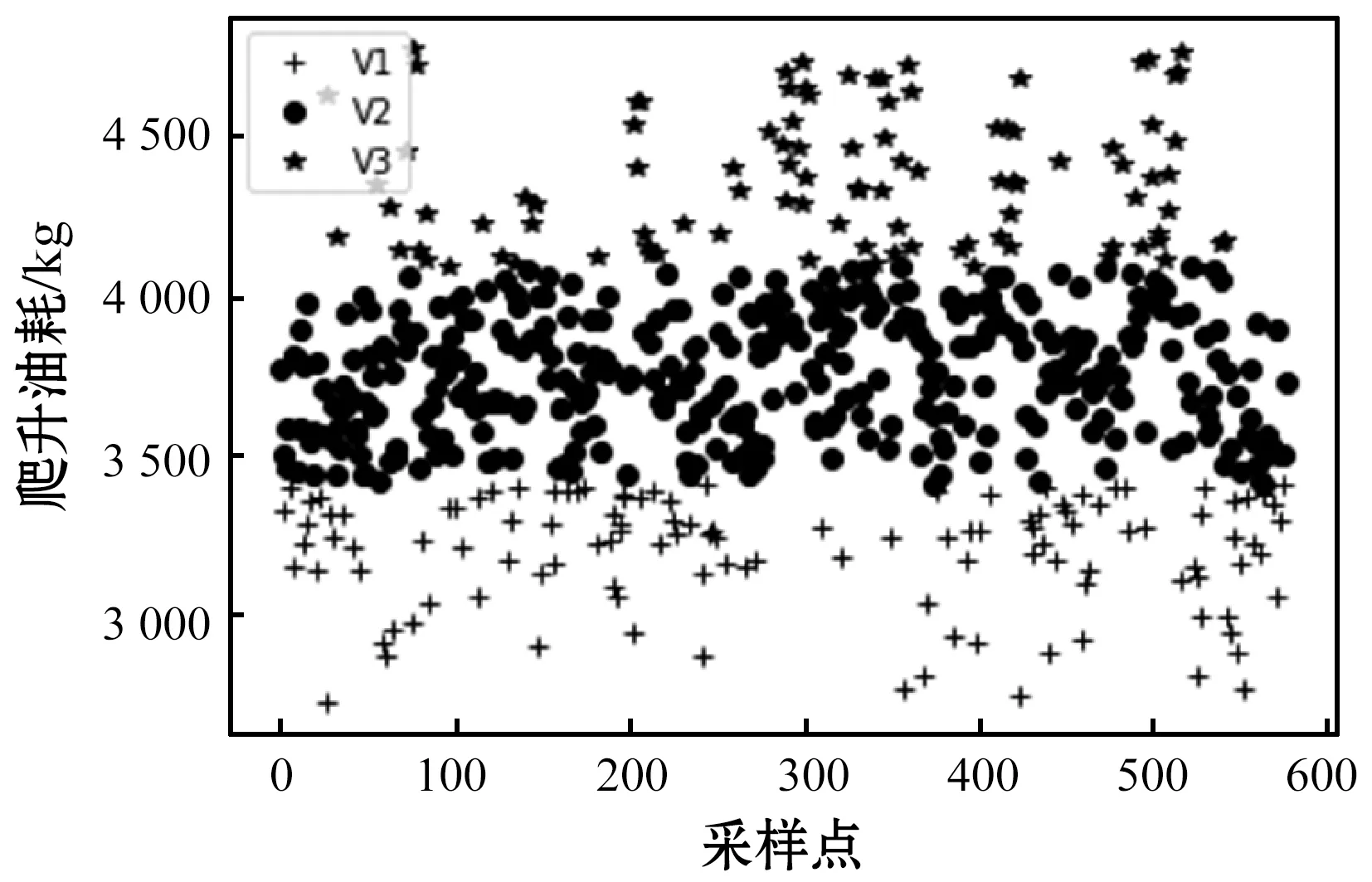
圖1 爬升油耗區(qū)間劃分
由圖1可得,對于V2而言,區(qū)間V2和V3都屬于少數(shù)類,約是多數(shù)類的三分之一。爬升段油耗分布比較離散,不同區(qū)間的差值也比較大。尤其最大值與最小值油耗相差近1 500 kg燃油,這為調(diào)節(jié)航空燃油提供了充足的優(yōu)化空間。
2.2 實驗參數(shù)設(shè)置
隨機選取總樣本量的80%作為訓練集,剩下20%樣本作為驗證模型的測試集。在對爬升段油耗分類過程中,聚類個數(shù)k值和構(gòu)成森林樹的個數(shù)ntree會對分類算法產(chǎn)生一定的影響。故使用準確率指標,測試了ntree和k值對本文所提方法分類性能的影響。在測試森林規(guī)模時,特征指標不變,取k值為一固定值,僅改變森林規(guī)模在10到500棵樹之間,每增加10棵樹運行10次算法,求其準確率均值,結(jié)果如圖2所示。
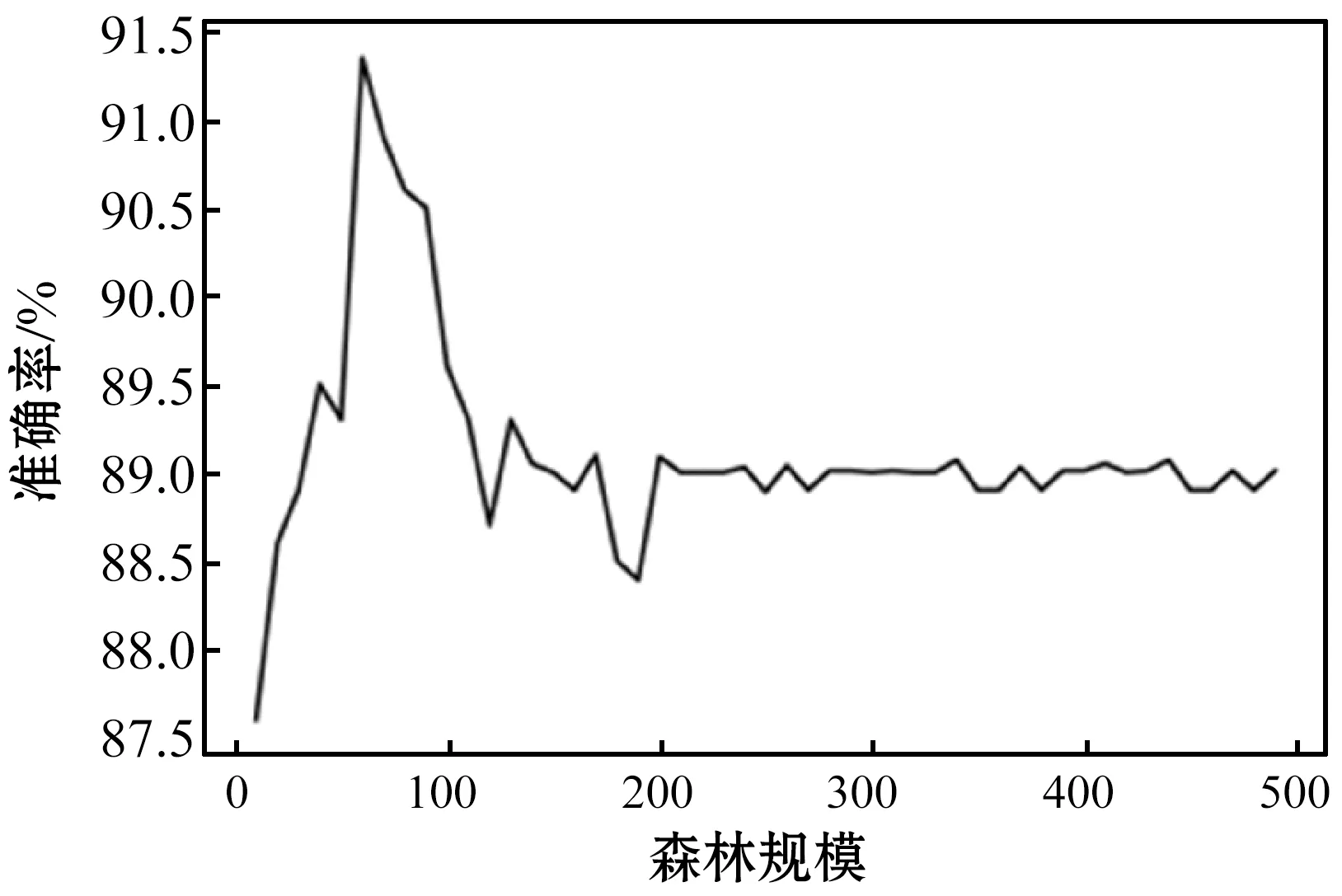
圖2 不同森林規(guī)模的分類準確率
根據(jù)圖2可以看出,隨機森林規(guī)模在70棵樹的時候,分類準確率最高,達到91.3%。隨著森林規(guī)模的增加,預(yù)測準確率呈衰減狀態(tài),最后趨于平穩(wěn)。這是因為隨著森林規(guī)模的增加,后面的樹可解釋性變差。
測試聚類個數(shù)k值時,保持森林規(guī)模ntree等于200,聚類個數(shù)分別從3到10,每個k值運行10次,以準確率均值作為評價指標,結(jié)果如圖3所示。
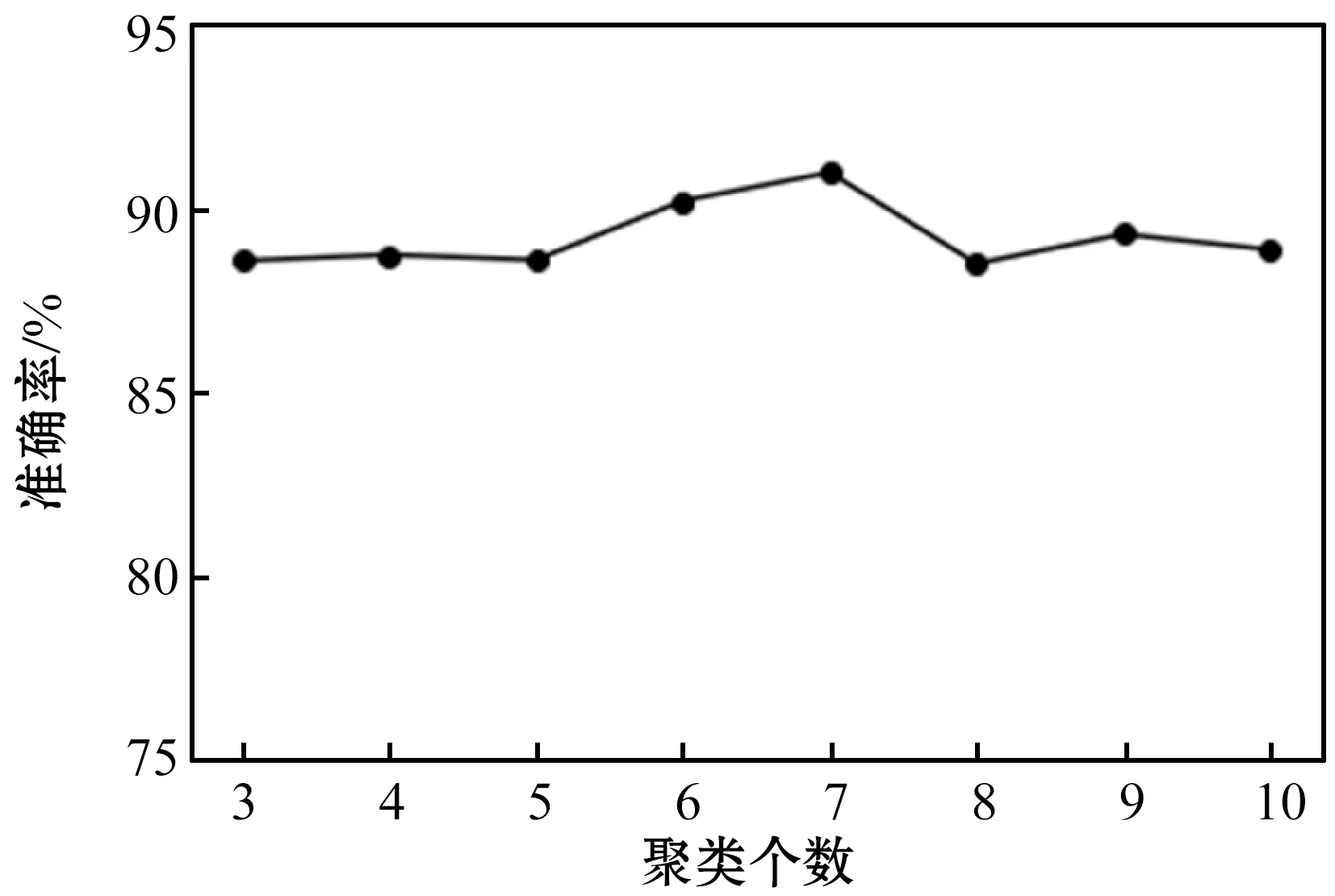
圖3 不同k值的分類準確率
由圖3可得,當聚類個數(shù)k值等于7時,最大分類平均準確率為90.3%。所以,本文在使用KMSMOTE-RF方法做實驗時,均基于k-medoids聚類個數(shù)設(shè)置為7,隨機森林規(guī)模ntree設(shè)置為200。
2.3 實驗結(jié)果及分析
采用對比試驗,使用隨機森林、傳統(tǒng)SMOTE-RF和文中所提方法分別進行了實驗。為保證結(jié)果的精確度,每個實驗獨立運行10次,最后取性能指標的平均值。平均分類性能如表2所示。
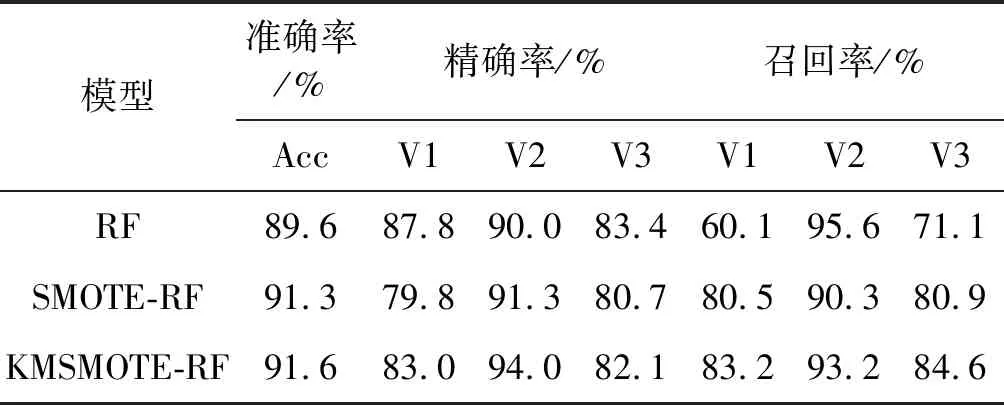
表2 分類模型性能評價指標
由表2可以得出以下結(jié)論:
(1) 單獨使用隨機森林進行分類時,從少數(shù)類召回率明顯低于多數(shù)類的召回率,在分類過程中仍然存在樣本不平衡問題。
(2) 加入SMOTE算法對原始數(shù)據(jù)進行處理后,分類準確率有所提高。類別V1的精確率由88.6%減小到79.8%,而召回率由60.1%增大到80.5%,說明分類器對少數(shù)類樣本的識別能力提高了。
(3) 使用改進的KMSMOTE與隨機森林相結(jié)合,不僅在分類準確率上有所提高,且還降低了多數(shù)類與少數(shù)類的精確率與召回率之間的差值,使分類結(jié)果不在偏向多數(shù)類。
3 結(jié) 語
在航空業(yè)節(jié)能減排的趨勢下,文中從爬升段油耗的數(shù)據(jù)不平衡著手,基于KMSMOTE的隨機森林分類器處理油耗數(shù)據(jù)的不平衡問題。一方面,該算法對從數(shù)據(jù)層面分析數(shù)據(jù)的不平衡性,并對傳統(tǒng)的過采樣技術(shù)SMOTE進行改進,以此提高分類器的性能。另一方面,由于隨機森林的集成思想的優(yōu)勢,構(gòu)成森林的每一棵決策樹訓練和分類過程都是獨立的,可以通過并行處理降低程序的運行時間,本文的不足之處在于油耗區(qū)間劃分過硬,對油耗數(shù)據(jù)區(qū)間劃分未與飛行特征聯(lián)系起來,這是下一步需要研究的方向。
猜你喜歡
西北民族大學學報(自然科學版)(2021年4期)2021-12-29 02:54:24
數(shù)學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
小聰仔(科普版)(2020年12期)2021-01-18 09:16:52
東方少年·布老虎畫刊(2020年4期)2020-06-08 15:48:10
學生天地(2019年32期)2019-08-25 08:55:22
中學生數(shù)理化·七年級數(shù)學人教版(2019年4期)2019-05-20 10:06:32
中學生數(shù)理化·七年級數(shù)學人教版(2018年6期)2018-06-26 08:36:06
小天使·一年級語數(shù)英綜合(2017年11期)2017-12-05 18:49:56
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
