基于多任務深度卷積神經網絡的人臉/面癱表情識別方法
2019-04-15 05:17:32彭先霖張海曦胡琦瑤
西北大學學報(自然科學版) 2019年2期
彭先霖,張海曦,胡琦瑤
(1.西北工業大學 電子信息學院,陜西 西安 710129;2.西北大學 信息科學與技術學院,陜西 西安 710127)
在心理學和人工智能領域,人臉表情識別(facial expression recognition)是一個持續不斷的研究課題,在過去30年中吸引了眾多研究者的關注,至今仍然是一個富有挑戰性的課題。
人臉表情通常被劃分為憤怒、蔑視、厭惡、恐懼、幸福、悲傷和驚訝這7類,表情識別方法主要有基于傳統人工特征提取和分類器相結合的方法[1-5]和基于深度學習的方法。傳統表情識別方法中人工選擇的特征難以較完整地描述人臉表情特點,因此表情識別效果不佳。深度學習由于在特征提取方面的卓越表現已成為目前表情識別領域的主流方法。Yu[6]構建一個 9 層 CNNs 結構,在最后一層連接層采用softmax分類器將表情分為 7 類,該模型在 SFEW2. 0 數據集上識別率達到 61.29%。Lopes[7]在CNN網絡前加入預處理過程,探索預處理對精度的影響,最終識別率在CK+數據集上達到 97.81%,且訓練時間更短。Wang[8]采用triple損失函數訓練CNN模型,并且運用數據增強手段,將識別率提高2%。該模型對難以區分的類間表情(如生氣和厭惡)表現優良。Zhao[9]融合 MLP 和 DBN,將 DBN 無監督特征學習的優勢和MLP的分類優勢聯系起來以提高性能。He[10]結合深度學習與傳統機器學習,首先運用LBP/VAR提取初次特征,以初次特征作為 DBN的輸入實現分類。Li[11]為了解決DBN忽略圖像局部特征的問題,將CS-LBP與DBN進行融合,提高了識別率。
面癱是一種常見病,臨床表現為面部表情肌群運動功能障礙,如口眼歪斜,嚴重患者甚至無法完成閉眼、皺眉、微笑等動作,因此,可以通過被觀察者在閉眼、微笑、抬眉、皺眉、聳鼻、示齒和鼓腮等動作下的面部表觀特點,判斷其是否存在面癱癥狀以及存在哪種癥狀,從而初步判定其是否有面癱疾病。從面癱患者的面部變化特點可以看出,面癱表情可以看作一類特殊的表情劃分類別。與常規表情類似,面癱表情也體現在嘴巴、鼻子、眉毛等人臉部位的變化,但面癱表情在這些部位的變化特點與常規表情不同。由此可以推出,人臉常規表情識別的方法可以推廣應用于面癱表情識別。
目前計算機技術已初步用于對面癱表情進行自動分析。Neely等人提出了一種基于灰度對比法的面癱識別算法[12]。Moran等人對該方法做了推廣,使其具有了更廣泛的應用[13]。Murty等采用測量和比較患者靜態和固定動作狀態下的特征點間距離的方法來對面神經功能進行量化,得到Nottingham分級法[14]。王紹宇等人提出了基于特征光流(Eigen flow)特征的面癱客觀評估算法[15],利用主動形狀模型提取出感興趣的人臉區域和面部特征,然后結合醫學圖像分析方法,使用光流對面癱時具有的特殊面部表情進行評價。閆亞美等提出了一種基于對稱軸的面癱分級算法[16],在圖像邊緣提取的基礎上,根據面癱患者面部不對稱的特點進行面癱識別。Guo等人提出了一種基于卷積神經網絡的面癱客觀評估算法[17],并在給定的面癱數據庫UPFP數據集上得到更高的預測精度。
現有深度神經網絡方法大多專注于表情識別單個任務,然而,現實世界中人臉表情與不同個體的面部形態、頭部姿勢、外部光照等多種因素交織在一起。為了減弱面部形態對表情識別的影響,本文構建深度多任務學習框架,將知識從人臉識別相關任務中遷移過來,克服面部形態對表情識別的影響。考慮到卷積神經網絡(convolution neural network,CNN)已廣泛用于圖像處理與分析領域[18-19],特別是VGG face[20],Googlenet[21],Resnet 34[22]的優秀表現,本文選擇這些深度模型來驗證本文所提方法的有效性,并將其推廣到面癱表情識別。
1 基于分層多任務學習的人臉表情識別
本文提出的多任務深度學習方法的結構如圖1所示。與傳統的深度CNN方法相比,進行了以下改進:①采用雙層樹分類器代替深層網絡中的平面softmax分類器,在提出的網絡中共同使用人臉表情標簽和人臉標簽;②利用多任務深度學習方法學習不同任務的特定深度特征。
1.1 分層結構的構建
文中構建了一個兩層結構來體現人臉識別和人臉表情識別任務之間的關系。對于人臉表情識別,其目的是忽略人臉成分并識別表情成分,而對于人臉識別,人臉表情成分應該被忽略,重點識別人臉。本文的多層次結構將不同人臉與不同人臉表情視為一個新的類別,通過利用人臉標簽和人臉表情標簽,學習更具辨別力的深層特征。
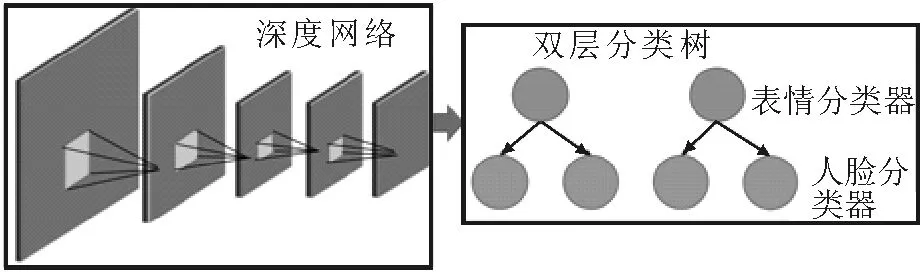
圖1 分層多任務學習框圖Fig.1 The hierarchical multitasking learning block diagram
多任務深度學習模型采用的層次結構如圖2所示,其中,使用一個人臉表情識別分類器和多個人臉識別分類器。高層學習任務側重于人臉表情的識別,而每個低層學習任務側重于人臉識別(具有相同表情的人臉)。此外,分層結構可用于確定每個學習任務中的粗節點(人臉表情)的數量和低層節點(人臉)的分布,其中具有相同人臉表情的人臉應被分配到相同的學習任務中。
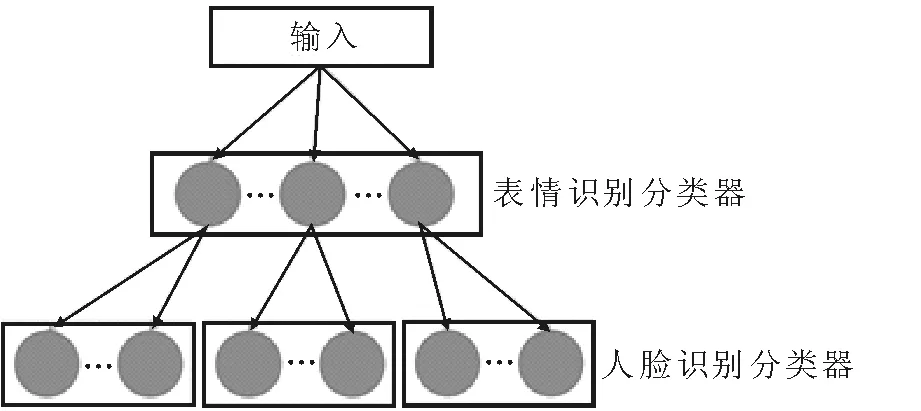
圖2 兩層結構框圖Fig.2 The two-layer structure block diagram
1.2 基于分層結構的多任務深度學習
如上所述,使用兩層樹分類器來代替傳統深層網絡中的平面softmax分類器,在提出的網絡中,可利用人臉表情標簽和人臉標簽來幫助深度網絡學習更具辨別力的深度特征。更重要的是,由于人臉表情的變化會影響人臉識別的準確率,因此,應該針對不同的分類任務使用特定的深度特征。
對于輸入圖像I,屬于第l個人臉表情的對象圖像I的預測概率可以用式(1)計算,
(1)
其中,We表示人臉表情識別分類器權重參數;xe表示人臉表情識別學習的特定深部特征;M是粗粒度屬(人臉表情)的總數。人臉表情識別的預測概率可用于選擇特定的人臉識別分類器。對于對應于第l個表情的第l個低層分類器,輸入圖像I屬于第j個類別的預測概率可以表示為
(2)
其中,Wf表示特定的人臉識別分類器權重參數;xf表示用于人臉識別的特定深度特征;Hl是對象圖像被分類的特定學習任務。
由于最終預測概率可計算為P(I∈el)P(I∈fj),因此深層網絡的損失函數可以表示為
£(W,x)=
(3)
本文提出目標函數旨在最大化人臉表情識別和人臉識別的正確預測概率,因此,在每次迭代期間可以聯合優化多級分類器中的權重參數。
損失函數用于在訓練過程中優化分層樹分類器中的所有權重參數,可通過誤差反向傳播的方法進行學習。具體而言,可分別在式(4)和式(5)中計算多級分類器X和Y中的權重參數的對應梯度
(4)
(5)
可以看到,與傳統的反向傳播不同,在每次迭代過程中只優先考慮相關的學習任務。這是因為,損失函數僅考慮分層樹分類器中的相關權重參數,以及其他學習任務的預測概率,防止在訓練過程中遠離全局最優。
2 實 驗
本文提出的分層多任務學習方法在流行的人臉表情數據集(CK+)[23]上進行了對比實驗,并進一步在面癱表情數據庫上進行了本文方法的有效性驗證。
2.1 CK+數據集實驗結果及分析
CK+數據集:擴展CohnKanade*(CK+)數據集是用于評估人臉表情識別方法的最常用數據集之一。 CK+包含來自123名受試者的593個視頻序列,其中只有327個被標記。CK+數據集未為每幅圖像提供精確的標簽,只有圖像序列有標簽,序列中包含了從平靜到表情表現峰值的圖像。因此通過對應表情序列取表情峰值附近的3幀。之后,9個子集用于訓練,另一個子集用于驗證。文中118個具有精確標簽的受試者被分配到7個粗類別(人臉表情)中。值得注意的是,由于每個類別的CK+數據集中沒有足夠的圖像,因此,本文以VGG-face人臉模型參數為基礎進行訓練。
所有方法在CK+數據集上的識別準確率如表1所示,可以很容易地發現,本文所提出的方法在準確率方面取得了很好的表現。與基于低級特征的方法(如HOG3D[24]或3D Sift[25])相比,基于深度學習的方法在學習可靠性和特征提取上均具有更好的表現。此外,與基于深度學習的已有方法(3DCNN[26],DTGAN[27],PHRNN-MSCNN[28],Inception V3[21],Resnet 34[22],VGG-face[20])相比,本文提出的方法仍然可以在依賴于人的實驗中獲得最佳性能,更重要的是,可以在不依賴于人的實驗上得到更多的改善。
表1 CK+數據集上不同表情識別方法的準確率
Tab.1 Accuracy of different expression recognition methods on CK+data sets

方法 準確率/%HOG3D 60.89 3D Sift 64.39 3DCNN 85.9 3DCNN-DAP 92.4 DTGAN(weighted sum) 96.94 DTGAN(joint) 97.25 PHRNN-MSCNN 97.78 VGG face fintune(person-dependent) 96.42 Our method(person-dependent) 97.53 VGG face fintune(person-independent) 92.70 Our method(person-independent)95.64Inception V3(person-dependent)100.0Our method(person-dependent)100.0Inception V3(person-independent)93.35Our method(person-independent)96.02Resnet 34(person-dependent)100.0Our method(person-dependent)100.0Resnet 34(person-independent)94.21Our method(person-independent) 96.62
同樣容易理解的是,依賴于人臉的準確率高于不依賴于人臉的準確率,因為人臉信息可以在深層網絡中學習,并且可能影響表情識別。與傳統深度CNN方法相比,本文提出的方法可以實現更高的準確率。
提出方法的混淆矩陣如表2所示,從表2可以看到,本文提出的方法可以在某些人臉表情(如憤怒,蔑視,厭惡,恐懼和幸福)上獲得令人滿意的表現,而對于其他一些人臉表情(如悲傷和驚喜),由于表情彼此相似,難以區分,識別準確率仍相對較低。
表2 本文方法在CK +數據庫上的混淆矩陣(依賴于人的結果)
Tab.2 The confusion matrix of this method on CK+database (depending on human results)
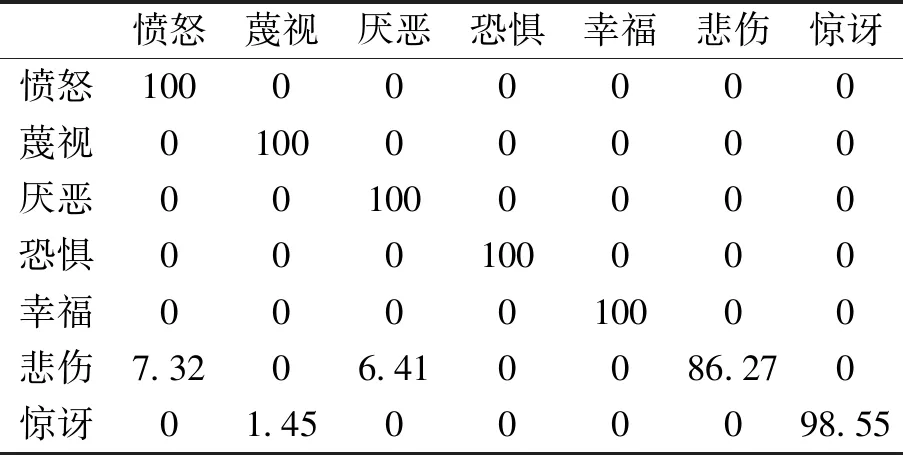
憤怒蔑視厭惡恐懼幸福悲傷驚訝憤怒100000000蔑視010000000厭惡001000000恐懼000100000幸福000010000悲傷7.3206.410086.270驚訝01.45000098.55
2.2 面癱表情數據集實驗結果及分析
考慮到面癱表情和基本人臉表情間的相關性,本文提出的分層多任務深度學習方法進一步在面癱表情識別問題上進行了驗證。
目前,國內外沒有統一的面癱評估標準和公用數據庫,在本實驗中,利用一個尚未公開的面癱表情數據庫進行實驗。如圖3所示,該數據庫記錄了49名面癱患者的7種面癱表情動作(閉眼、微笑、抬眉、皺眉、聳鼻、示齒和鼓腮)。

圖3 同一個人的7種面癱表情Fig.3 Seven facial expressions of the same person
由于所得的面癱數據有限,每一個人對應每一個表情動作只有一張圖片,因此在本實驗中只能進行face-independent的實驗。在實驗中,本文選擇了268個面癱表情樣本作為訓練樣本,40個樣本作為測試樣本。
實驗結果如表3和圖 4所示。可以發現,本文提出的模型在面癱表情動作的識別上依舊可以得到一定的提升。相比傳統的手工特征方法, 基于深度學習的算法能夠得到更加穩定的特征。而且本文提出的算法通過利用人臉信息和表情信息,可以使深度網絡學習得到可分性更強的特征。但是由于數據量極少,因此有限的數據可能難以將網絡參數進行有效的優化。同時可以發現,微笑和皺眉很難被正確區分,這是因為這兩種表情很容易與其他表情混淆。
表3 面癱表情數據庫上不同方法的準確率
Tab.3 Accuracy of different methods on the facial expression database

方法準確率 VGG-fintune62.50 VGG+multi-task learning67.50Inception V370.00Inception V3+multi-task learning72.50Resnet 3475.00 Resnet 34+multi-task learning 80.00
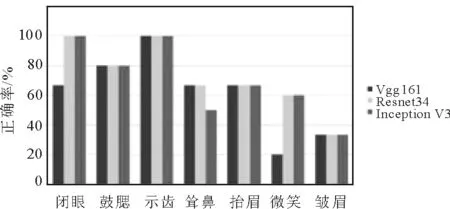
圖4 面癱數據集3種方法正確率比較Fig.4 Comparison of the correctness rates of three methods for facial data sets
3 結 語
本文提出了一種基于分層多任務學習的人臉表情識別方法。該方法采用雙層樹分類器代替傳統深層CNN中的平面softmax分類器,構成在表情識別同時考慮人臉識別的多任務學習框架,與用于人臉表情識別的傳統單層分類器相比,有效提高了表情識別率。本文進一步將提出的方法推廣應用于面癱表情識別中,也取得較好的識別效果。
猜你喜歡
作文中學版(2022年1期)2022-04-14 08:00:34
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
學生天地(2020年31期)2020-06-01 02:32:06
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
計算機工程(2015年8期)2015-07-03 12:19:07
