學習分析視角下的個性化預測研究
2019-05-08 03:23:10張琪王紅梅莊魯賴松
中國遠程教育 2019年4期
張琪 王紅梅 莊魯 賴松
【關鍵詞】? 學習分析;學習預測;數據挖掘;人格特質;個性化建模;智能學習系統;預測效能;數據驅動教學
【中圖分類號】? G434?????? 【文獻標識碼】? A?????? 【文章編號】 1009-458x(2019)4-0038-08
一、引言
教育智能時代,教學范式的變化正順應個性化教育的需求,以學習者為中心教學模式的深度應用驅動新技術的普及與常態化。技術在學習場景中的無縫切換,對學習時空的全方位覆蓋,對學習方式的個性化支持,無不突顯出技術以常態化形式“無縫內嵌”學習過程之核心特征。以學習分析為核心的“數據驅動教學”成為破解“千校一面”“千人一面”教育格局的主要力量。在學習分析多樣化研究領域中,基于“嵌入式”日志數據的學習預測(預警)是重要的研究趨向。通過對日志數據的挖掘與建模,可以分析學習者個體與群體的行為信息,幫助教師盡早洞察學習者的學習進度與質量,并對學習者真實水平進行評測(丁夢美, 等, 2017)。
在學習結果預測方面,目前大多數研究將學習者視為整體進行評估,缺少個性化的分類形式與預測指標,統一的數據建模很難針對不同學習者獲得較好的預測效能。此外,也鮮有較為全面的數據挖掘算法的比較研究。本研究以學習分析支撐的數據驅動教學為落腳點,以實驗校一學期的互聯網+教學實踐為研究對象,基于人格特質分類對不同特征群體進行建模,利用數據挖掘技術進行預測與評估,以判斷學習者的潛在學習危險。這不僅是預防輟學、以評促學的需要,更是契合“互聯網+教育”需求,實現智能教育與個性化學習支持的必然趨勢(李爽, 等, 2018)。
二、文獻綜述
教育大數據為基于學習分析的預測研究提供了多方面的可能性。Morris等(2005)發現學習者在Blackboard上觀看內容頁的數量與其最終成績顯著相關,討論信息總數、發送郵件數量與作業情況對未能通過課程的判定準確率達到74%;Romero等(2013)通過聚類算法預測學生是否成功通過課程,最佳準確率為90.3%;Yu等(2014)建立了包含在線時間、同伴交互數量、教師交互量、總登錄頻率、下載次數與學習時間間隔規律等在內的預測因子。Rafaeli等(1997)對混合學習環境中學習者平臺行為數據進行了分析,研究表明學習者的閱讀量與在線提問數量導致了學習成績的差異;Wong(2013)構建了混合學習環境下預測學習績效的在線學習行為指標,包括登錄次數、章節平均學習時間、在線測試完成次數及時間、查看和下載資源數量以及論壇參與頻率;Zacharis(2015)對混合學習環境的研究表明,閱讀量、發布消息數量、內容創作數量、測驗成績與文件瀏覽數量對學生成績預測準確率為52%,分類預測準確率為81.3%;A Pardo等(2017)結合學習動機策略問卷與在線學習活動共同預測學習投入,研究表明可以更全面地理解成功的學習狀態。趙慧瓊等(2017)利用多元回歸分析法分析影響學生學習績效的預警因素,在此基礎上構建了干預模型;胡祖輝等(2017)比較了基于關聯規則、決策樹與邏輯回歸3種算法對學習結果的預測精度,認為關聯規則挖掘算法的總體性能最好。
由此可見,學術界圍繞各類LMS平臺、MOOC課程、混合學習環境中的預測因子與教育數據挖掘技術展開了較為深入的研究,結果顯示預測指標的多樣性以及預測精度的差異性。在過去十年中,有大量理論和研究集中在學習者個性特征如何影響其行為與信息加工。學術界普遍接受的觀點認為,學習者優先處理與人格特征相和諧的情感刺激,同類學習者在學習過程中會表現出相似行為傾向(Mischel, 1999)。但從研究方法上看,多數研究還是將學習者視作一個整體進行預測,并未針對他們的個性特征進行分類建模,差異性研究的缺失使得預測模型精度不足(肖巍, 等, 2018),很難滿足構建個性化干預系統的需求;從算法上看,學習結果預測(數值預測與分類預警)仍缺少較為全面的數據挖掘方法在預測精度以及魯棒性方面的比較研究。
三、研究問題
本研究擬構建適合不同特征群體的預測模型,利用多樣化的數據挖掘算法對預測精度進行比較。對于學習者個性特征的劃分,目前的理論探討集中在西方對學習風格與認知風格的相關研究上,鑒于地域差異以及學習者(尤其是中學生)學習風格存在差異(張琪, 等, 2018),加之將傳統環境下的研究結論直接應用于在線學習環境是否妥當等問題,制約了基于學習風格與認知風格模型設計自適應教學系統的合理性(葛子剛, 等, 2018)。眾所周知,在混合(在線)學習環境中學習的本質是社會性學習,涉及無形資源(多媒體信息與數字化資源)的信息交換。因此,人格特質已廣泛應用于在線學習環境的評估研究。
人格與在線學習行為的緊密聯系源于網絡信息的特征。在線學習涉及大量基于任務的學習、信息選擇策略以及優秀觀念的產生(Burt, 2004),在此類人工情境下學習者的信息加工符合中介范式和調節范式(陳莉, 2005)。其中,中介范式認為人格特質對情緒加工的顯著作用是間接的,即人格影響心境狀態,而心境狀態又影響情緒加工;調節范式認為心境狀態對情緒加工的作用受人格特質影響或受其調節。此外,人格特質具有較好的穩定性。其穩定性與獨特性在很大程度上歸功于其核心成分——特質(Trait)。特質使個體對不同種類的刺激以某種相對一貫、穩定且相同的方式進行反應,是個體的“神經特性”(Matthews, et al., 2003)以及“支配個人行為的能力”(Allport, 1937)。
鑒于人格特質在識別個體差異、跨文化普適性以及與在線學習行為的關聯性等方面具備優勢,故本研究利用“大五人格”識別學習者特征。基于“大五人格”的“開放性”和“外傾性”維度的高低水平劃分不同人格類型(張琪, 等, 2018),建立相應預測模型,解析不同人格類型相應的顯著預測因子。具體來說,本研究的研究問題包括3個:
問題1:學習平臺采集的學習行為指標與不同人格特質群體學習結果之間是否呈顯著相關?
問題2:對于具有不同人格特質的學習群體,哪些學習行為指標對于預測學習結果是重要的,是否存在共性的行為指標?
問題3:從統計學角度看,什么樣的數據挖掘算法在數值型與分類預測中具備最佳精度與魯棒性?
四、研究過程
(一)研究場景
本研究基于高中實驗校“互聯網+”混合學習場景。在智慧學習平臺支撐下,教學中心、學習中心、管理中心、資源中心全局數據無縫銜接。學習者有明確的學習目標、任務和時間安排,基于“四維驅動”教學模式開展學習。“四維驅動”教學模式是指“以導學任務單驅動學生的自主學習,以層級式問題驅動學生的合作探究,以學習數據分析驅動教師的按需教學,以課堂即時評測和成果分享驅動知識內化”。“四維驅動”教學模式強調4個方面的特征:一是以層級式任務為導向,以銜接課前與課后的活動貫穿始終;二是基于移動學習終端,以教育云平臺作為支撐環境;三是平臺模塊功能與教學模式深度融合,技術以常態化形式“無縫內嵌”于學習過程之中;四是派生出操作性和指導性極強的全學科常態化教學設計流程。
學生在一學期的課程學習中充分利用PAD終端進行學習,課程持續進行16周,后2周為期末考試。研究選取全體高一年級662名學生為樣本,基于語文與英語兩門課程的學習行為數據展開分析。將兩門課程期末成績與平時成績加權分(期末成績占70%,課堂表現占30%)的平均分作為最終成績,以相對客觀地量化學習結果。
(二)采集行為指標
采集的行為指標來自LMS平臺的頁面系統、交互系統、課件點播系統、測試系統和筆記系統。其中,頁面系統包括課程頁面瀏覽總次數與總時間;交互系統包括文本型提問數量、文本型回答數量、媒體型提問數量、媒體型回答數量與教師推薦發言數量;課件點播系統以交互電子教材(視頻)形式呈現,根據內嵌客觀問題權重自動判分,包括課件點播次數、課件點播時長與交互課件得分;測試系統包括及時測評剩余時長(班級學生最長作答時間減去各學生作答時間)、及時測評分數與課后測驗平均分數;筆記系統包括學習筆記數量(序號之和)與學習筆記長度(字符串長度之和)。
(三)人格特質識別
本研究采用NEO-FFI大五人格簡化問卷測量人格特質水平(Costa & McCrae, 1992)。已有研究表明,該問卷具有與完整版相同的信度和效度(Kurtz & Sherker, 2003),其中“開放性”和“外傾性”維度各為12個題項,采用5級計分。“開放性”Cronbach α為0.736,均值為40.32,標準差為5.91;“外傾性”Cronbach α為0.831,均值為41.19,標準差為4.76。將各維度數值標準化,分別映射到區域[0,3]與[-3,0],即每一維度劃分為高低兩類,最終得出4種人格類型P={P1, P2, P3, P4}。P1、P2、P3、P4分別代表“高開放、高外傾”“低開放、高外傾”“低開放、低外傾”“高開放、低外傾”4類人格群體。樣本數量分布分別為31.11%(P1)、21.45%(P2)、25.23%(P3)和22.21%(P4),人數分布大致均勻。
五、研究結果
(一)不同人格特質群體行為指標與學習結果的相關性
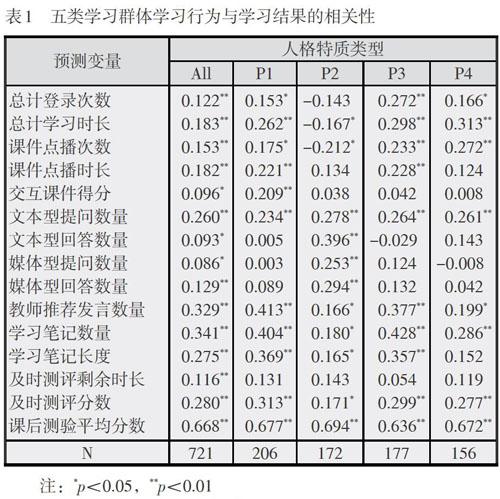
表1給出了不同數據集學習行為與學習結果相關分析的數據。基于全集樣本的相關分析結果表明,15個行為指標與學習結果均呈顯著正相關。其中,課后測驗平均分數與學習結果呈現高相關(r=0.668),教師推薦發言數量(r=0.329)、學習筆記數量(r=0.341)與學習結果呈現中相關,其余指標均為低相關。
對于“高開放、高外傾”學習者,11個行為指標與學習結果呈顯著正相關。其中,課后測驗平均分數與學習結果呈現高相關(r=0.677),教師推薦發言數量(r=0.413)、學習筆記數量(r=0.404)、學習筆記長度(r=0.369)、及時測評分數(r=0.313)與學習結果呈現中相關,其余指標均為低相關。
對于“低開放、高外傾”學習者,9個行為指標與學習結果呈顯著正相關。其中,課后測驗平均分數與學習結果呈現高相關(r=0.694),文本型回答數量(r=0.396)與學習結果呈現中相關,其余指標均為低相關。值得一提的是,總計學習時長(r=-0.167)和課件點播次數(r=-0.212)與學習結果均為低負相關。
對于“低開放、低外傾”學習者,10個行為指標與學習結果呈顯著正相關。其中,課后測驗平均分數與學習結果呈現高相關(r=0.636),教師推薦發言數量(r=0.377)、學習筆記數量(r=0.428)、學習筆記長度(r=0.357)與學習結果呈現中相關,其余指標均為低相關。
對于“高開放、低外傾”學習者,8個行為指標與學習結果呈顯著正相關。其中,課后測驗平均分數(r=0.672)與學習結果呈現高相關,總計學習時長(r=0.313)與學習結果呈現中相關,其余指標均為低相關。
(二)不同人格特質群體的學習建模
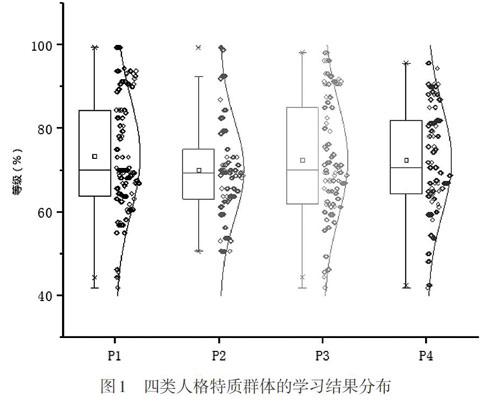
以15個行為指標為自變量,學習結果為因變量,利用逐步回歸進行數據建模。將所有具有低顯著水平的預測因子從模型中刪除。圖1給出了不同人格特質群體學習結果分布的箱線圖。箱線圖的優勢是不受異常值的影響,是相對穩定的數據離散分布可視化形式。從圖1可以看出各群體均服從正態分布,“低開放、高外傾”群體的學習結果平均水平與波動程度低于其他群體。
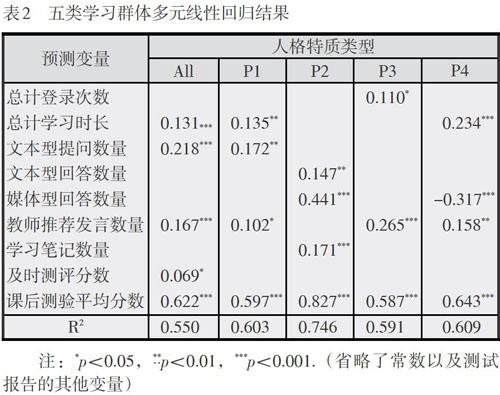
容忍度與方差膨脹系數的結果排除了各回歸方程的多元共線性問題。表2給出了5類學習群體對應的回歸方程預測變量。其中,全集數據樣本中總計學習時長、文本型提問數量、教師推薦發言數量、及時測評分數、課后測驗平均分數5個變量依次進入回歸方程(F=174.141, P=0.000),對學習結果解釋力為55%;“高開放、高外傾”學習群體,總計學習時長、文本型提問數量、教師推薦發言數量、課后測驗平均分數4個變量依次進入回歸方程(F=50.340, P=0.000),對學習結果解釋力為60.3%;“低開放、高外傾”學習群體,文本型回答數量、媒體型回答數量、學習筆記數量、課后測驗平均分數4個變量依次進入回歸方程(F=174.141, P=0.000),對學習結果解釋力為74.6%;“低開放、低外傾”學習群體,總計登錄次數、教師推薦發言數量、課后測驗平均分數3個變量依次進入回歸方程(F=46.451, P=0.000),對學習結果解釋力為59.1%;“高開放、低外傾”學習群體,總計學習時長、媒體型回答數量、教師推薦發言數量、課后測驗平均分數4個變量依次進入回歸方程(F=43.916, P=0.000),對學習結果解釋力為60.9%。
為了進一步考察各回歸方程中課后測驗平均分數(最高權重)與學習結果的關系,以散點圖形式給出了兩者可視化關系,見圖2。散點圖是識別變量之間潛在相關趨勢的有效方法(Field, 2005)。圖2再次表明,課后測驗平均分數與不同人格特質學習者的學習結果之間呈正相關,且為線性趨勢。
(三)不同數據挖掘方法的預測效能比較
基于Python 3.7環境,利用28種回歸算法比較預測精度,包括ElasticNet回歸、Linear回歸、MLP回歸、SMO回歸、RandomTree回歸、RandomForest回歸、SVM回歸等。利用皮爾遜相關系數(PCC)、一致性相關系數(CCC)、平均絕對誤差(MAE)與均方根誤差(RMSE)以及5倍交叉驗證,判別具有最佳精度和魯棒性的數據挖掘方法。其中,皮爾遜相關系數是預測分值與實際分值的皮爾遜相關;一致性相關系數考察連續變量之間的一致性與重現性;平均絕對誤差是絕對誤差的平均值,能反映預測值誤差的實際情況;均方根誤差用來衡量預測值與實際值之間的誤差大小。圖3給出了不同算法的分析結果。

如圖3所示,對于皮爾遜相關系數,RandomForest回歸最高(0.859),其次是KStar回歸(0.841);對于一致性相關系數,RandomForest回歸最高(0.850),其次是KStar回歸(0.837);對于平均絕對誤差,KStar回歸最低(4.176),其次是JR回歸(6.490)和RandomForest回歸(6.635);對于均方根誤差,RandomForest回歸最低(10.906),其次是KStar回歸(11.663)。由此可以看出RandomForest回歸為最佳的預測算法。
利用分類算法對課程風險進行識別預測,學習結果低于60分的學習者被視為“具有風險”,60分至80分被視為“表現良好”,高于80分被視為“學業優秀”。本研究比較了24種分類算法的預測精度,包括JR、RandomTree、RandomForest、SVM以及SMO等。利用準確率(Precision)、正確率(Accuracy)、召回率(Recall)、F值(F-Measure)以及5倍交叉驗證,判別具有最佳精度和魯棒性的數據挖掘方法。其中,正確率指分類正確的樣本數與樣本總數的比率;準確率即查準率,指檢索相關文檔數與檢索出文檔總數的比率;召回率即查全率,指檢索相關文檔數與所有相關文檔數的比率;F-Measure為查準率與查全率加權調和平均值。圖4給出了不同算法的分析結果。

如圖4所示,在準確率方面,RandomForest最高(0.905),其次是KStar(0.891)和MODLEM (0.875),NaiveBayes最低(0.563);在正確率方面,RandomForest最高(0.913),其次為MODLEM (0.887)與KStar(0.873),ConjunctiveRule(0.498)最低;在召回率方面,KStar最高(0.870),其次是RandomForest(0.859)和PART(0.830),SMO(0.591)最低;在F-Measure方面,RandomForest最高(0.879),其次為KStar(0.871)與MODLEM(0.830),SMO(0.529)最低。可以看出,RandomForest在預測學習者失敗風險方面效果最好。
六、分析與討論
(一)研究結論
猜你喜歡
體育科技文獻通報(2022年3期)2022-05-23 13:46:54
天津外國語大學學報(2021年3期)2021-08-13 08:32:18
遼金歷史與考古(2021年0期)2021-07-29 01:06:54
大眾投資指南(2021年35期)2021-02-16 01:06:26
科技傳播(2019年22期)2020-01-14 03:06:54
民用飛機設計與研究(2019年4期)2019-05-21 07:21:24
汽車工程學報(2017年2期)2017-07-05 08:13:02
電力與能源(2017年6期)2017-05-14 06:19:37
中國中醫藥信息雜志(2016年7期)2016-12-01 06:07:55
信息通信技術(2015年6期)2015-12-26 01:16:46
