命名數據網絡包處理流程性能改進
2019-05-08 03:01:26于廣路
科學與技術 2019年19期
于廣路

摘要:互聯網用戶對數據的內容感興趣,而并不關心它的位置在什么地方。但是,當前的客戶端/服務器架構仍然需要一個請求被定向到特定的服務器來獲取響應。命名數據網絡(NDN)是可以滿足這種以內容為需求的全新的網絡模式,這種網絡的轉發決策是基于內容的名稱而不是IP地址,并很好的解決了當前TCP/IP網絡設計上的缺陷。本文將會從微觀架構探索NDN網絡包處理流程中執行流水線的執行情況,并分析因為訪存帶來的流水線暫停的性能瓶頸問題,最終提出了兩種指令預取的策略來提高CPU緩存命中率和系統吞吐量。
關鍵詞:命名數據網絡;NDN;指令流水;數據預取
一、命名數據網絡的意義。
命名數據網絡(Named Data Network,NDN)[1]是將內容的名字作為網絡轉發的核心信息,與當前的IP網絡對比,NDN不再使用特定的IP地址,而是具有層次結構的內容的名字進行數據的發送和獲取,NDN路由也不再按照IP地址進行數據包的轉發,而是根據名字進行路由轉發,這種全新的網絡并不限制對于特定的名字是由哪個主機來提供數據,也不需要知道內容的提供者是誰,只需要將需要獲取的內容以名字為核心封裝為興趣包發送到網絡中,然后等待數據的返回。通過這種與IP主機網絡完全不同的網絡架構相比,可以獲取如下優點:(i)路由節點緩存數據可以減少網絡負載和延遲;(ii)數據包經過簽名更加安全;(iii)不再固定地址,具有更好的移動性;(iv)減少了以內容的應用層的通信復雜度。
命名數據網絡作為下一代的網絡架構來設計,是要總結最近幾十年網絡模式實踐中出現的一些問題并加以解決。其中該網絡最大的特點就是路由節點不再單純的只做存儲轉發,而且加入了數據包緩存的能力,這樣對于相同的請求,可以從距離請求方最近一個緩存了數據的路由節點返回請求的數據包,網絡請求可以立即結束,網絡鏈路短,提高了內容資源的重用性,避免了網絡中傳輸大量相同的數據,因而可以提高整個網絡的吞吐量和資源的利用率。
盡管NDN這種全新的網絡架構提供了非常好的好處,但是部署實施確是遇到了最大的挑戰,如何克服IP網絡向NDN網絡的過渡和轉換是不得不面對的問題。雖然網絡功能虛擬化(NFV)給命名數據網絡的部署實施提供了一種機會[2],可以避免現有NDN網絡部署需要對大規模基礎設施的升級,但是這種機會的前提是需要設計出一個高性能的,穩健的命名數據網絡軟件路由,可以運行在現有的商用硬件平臺上,并提供高效的路由轉發性能,使得NDN的實現不再只停留在實驗的階段。
二、命名數據網絡的數據結構和包處理流程。
命名數據網絡主要有興趣包(Interest package)和數據包(Data package)兩種數據報文類型,其中,名字在興趣包和數據包是都存在的,相同名字的興趣包請求相同名字的數據包,一個是發起數據請求的時候由消費方發送興趣包,另一個是由網絡中擁有相同名字數據的節點進行相應的數據包。
NDN網絡的轉發機制相對比IP網絡單純的路由轉發機制是要復雜一些的,因為考慮到了數據的緩存。首先內容的消費者會根絕需要獲取的內容名字來構造興趣包,然后會將該興趣包在網絡內進行廣播,當路由節點接收到該興趣包的時候,路由節點需要首先查詢興趣轉發表(Pending Interest Table,PIT),然后查詢內容緩存(Content Store,CS),當沒有緩存數據的時候,會通過查詢路由轉發表(Forwarding Information Base,FIB)來確定轉發端口。在NDN網絡中的FIB是與IP網絡中的FIB相類似的,他們都包含了名字(IP地址)和轉發端口的映射關系,并根據路由協議來對FIB進行生成和更新,該數據結構是路由轉發的關鍵數據結構,并且轉發端口并不限制單出口,可以像多個出口進行路由的轉發。當有數據包到達的時候,會按照一定的策略將數據緩存在內容緩存(CS)中,這樣當有大量請求相同名字的興趣包到達的時候可以第一時間將CS中緩存的數據發送給請求側,快速的完成網絡的請求,而不需要像IP網絡那樣,每一個請求都只限定在端對端的通信范圍內,無法復用相同的相應數據。
三、分析數據包處理流程的性能瓶頸。
指令預取是為了隱藏CPU指令周期中因為需要訪問內存數據導致流水線中斷的關鍵技術。因此需要分析在網絡數據包處理流程中因為哪些訪存操作導致了CPU流水線中斷的情況。
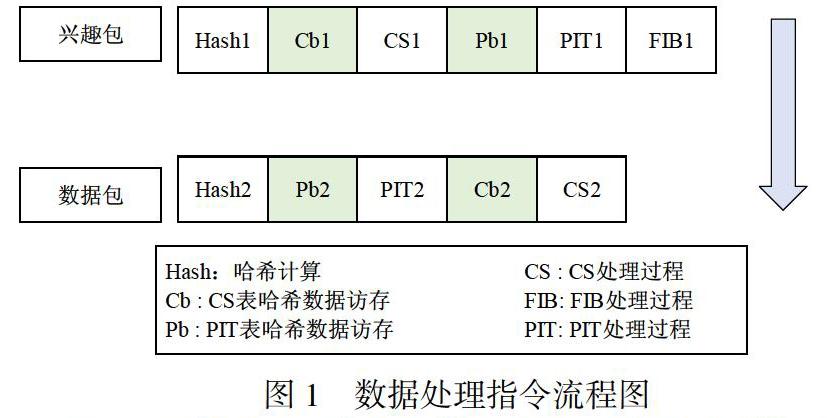
在NDN網絡中,存儲在內存上的數據有PIT、CS存儲名字的哈希表,FIB中用于最長前綴匹配而設計的布隆過濾器和哈希表,對內存的訪問主要就是哈希表自身和哈希表中的元素。因此知道轉發線程何時訪問這些數據結構地址就變得非常重要。圖1顯示了NDN網絡中興趣包和數據包的典型流程。在圖中所示的是興趣包和數據包前后到達的時候,CPU處理的指令流程。接下來使用序號1表示興趣包,序號2表示數據包。同時因為處理興趣包和數據包的指令流程是最長的,因此選擇這2個包來進行分析。從圖中可以看出,當興趣包到達的時候,需要訪問PIT、CS數據結構的哈希表,FIB的哈希表也需要訪問,但是需要在布隆過濾器計算之后才得出需要訪問的哈希表的位置。接著根據數據包的名字搜索CS來判斷是否已經緩存了該名字的數據,當CS不會存的時候需要搜索PIT是否已經存在該名字的記錄,然后會PIT進行修改。如果通過FIB進行名字前綴最長匹配,找到輸出端口然后進行轉發。同時,需要注意的是,當PIT不存在指定名字的記錄的時候,還需要將插入一條記錄到PIT中。
從圖1中,很容易觀察到2處因為CPU需要等待訪存從而導致流水線暫停的情況。首先,Cb1和Pb2都是不能預取的,因為這兩個訪存操作依賴前一步名字的哈希計算過程,這樣的情況下,地址計算和訪存之間沒有CPU的時間間隔,因此只能等待哈希計算完成后不得不停止當前流水線的執行等待Cb1和Pb2兩個訪存操作完成后才能進行后續的處理過程。第二個就是在訪問CS或者PIT之后,才能決定后續需要訪問的哈希表,因此這種后續操作需要依賴之前操作結果的過程會導致CPU流水線的停頓。
四、通過指令預取策略來消除訪存導致的流水線阻塞。
本節設計了兩種預取策略,即預哈希計算和預測哈希表(HT)查找,假設如下:因為系統提供了四個內存通道,內存中的多個數據段被并行地獲取,即最多四個數據是可以同時獲取的。處理PIT、CS和FIB的邏輯流程所消耗的CPU周期比哈希表查找過程更多,這意味著完全可以在計算哈希值的過程中進行數據的預取,這樣就達到了通過預取的方式來隱藏CPU流水停頓帶來的性能開銷的目的。
下面根據圖5-8來描述這兩種策略。圖5-8中的序列是從圖5-7得來的,但是是基于應用預取策略的前提下得出的。首先,預哈希計算指的是將哈希計算的過程提前,因為哈希表查找的整個流程中,查找的Key都是名字對應的哈希值,而不是名字的自身,所有沒有必要等到需要查詢哈希表的時候再進行哈希值的計算,所以只有對哈希進行預計算,才可以對進行后面的數據并行預取。
因為在對興趣包的名字哈希計算完成之后,需要進行數據的預取,因此在此時,對第二個包,也就是數據的哈希值進行計算,這樣就可以避免了CPU因等待訪存而引起的停頓。這種策略意味著在在多個數據包的情況下應該重新考慮計算的順序。也就是說,選取的兩個連續的數據包,在最壞的情況下,大量的數據包會導致同時處理多個數據包的狀態,而這些數據包可能會存儲在內存上。因此采用了一種預計算的方法來對哈希計算進行改進,在計算完第一個數據包的哈希值之后,緊接著計算后續數據包的哈希值。同時,從內存中獲取CS、PIT的哈希表項,如圖中的Cb1、Pb1所示步驟。哈希計算的過程隱藏了因為虛偽訪存獲取哈希表項所導致的阻塞。
其次,計算了第一個包的哈希值后,該興趣包的所有哈希表(即CS、PIT和FIB)的哈希表項都可以從同時從內存中獲取了。因此,所有哈希項,包括那些由于最長前綴匹配結果而無法訪問的哈希項,都是基于推測性地預獲取的,也就是說獲取到的數據在后續的處理流程中可能根本用不到。這種策略被稱為推測性的哈希查找。在獲取后續數據包的哈希項之后,推測性的哈希查找將應用于該數據包的哈希項,需要注意的是,它適用于所有哈希表和哈希項。
對數據預取策略的實現結果顯示平均包處理的CPU周期可以降低20%以上,這將大大的提高了數據包轉發的速率。
五、總結。
為了解決通用平臺網絡包處理的性能瓶頸問題,本文從微觀架構層面分析NDN網絡處理流程中指令流水的執行情況,然后提出了兩種數據預取的策略來降低訪存對系統吞吐量的影響。在高性能軟件的設計流程中,需要尤為注意內存訪問的操作,因此訪存的次數很大程度上影響了CPU流水線的執行,導致性能降低,所以該數據預取策略同樣可以為其他對性能要求極高的軟件設計的提供參考。
參考文獻
[1] Zhang L,Estrin D,Burke J,et al. Named Data Networking(NDN)Project NDN-0001[J]. Acm ?Sigcomm Computer Communication Review,2010,44(3):66-73.
[2]Van Adrichem N L M,Kuipers F A. Ndnflow:Software-Defined Named Data Networking[C]// Network Softwarization(Netsoft),2015 1st IEEE Conference,London:IEEE,2015:1-5.
