基于CNN特征提取和加權深度遷移的單目圖像深度估計
2019-05-14 07:35:20安國艷梁宇棟
圖學學報 2019年2期
溫 靜,安國艷,梁宇棟
?
基于CNN特征提取和加權深度遷移的單目圖像深度估計
溫 靜,安國艷,梁宇棟
(山西大學計算機與信息技術學院,山西 太原 030006)
單目圖像的深度估計可以從相似圖像及其對應的深度信息中獲得。然而,圖像匹配歧義和估計深度的不均勻性問題制約了這類算法的性能。為此,提出了一種基于卷積神經網絡(CNN)特征提取和加權深度遷移的單目圖像深度估計算法。首先提取CNN特征計算輸入圖像在數據集中的近鄰圖像;然后獲得各候選近鄰圖像和輸入圖像間的像素級稠密空間形變函數;再將形變函數遷移至候選深度圖像集,同時引入基于SIFT的遷移權重SSW,并通過對加權遷移后的候選深度圖進行優化獲得最終的深度信息。實驗結果表明,該方法顯著降低了估計深度圖的平均誤差,改善了深度估計的質量。
單目深度估計;卷積神經網絡特征;加權深度遷移;深度優化
單目圖像深度估計是計算機視覺領域的熱點問題。然而,受到單個攝像頭的制約,想要通過空間立體幾何計算圖像中精確的深度信息是極其困難的。
現有的單目圖像深度估計算法大都是對1幅圖像上的所有像素點賦予一個相對深度關系,有基于線索、基于圖模型和基于采樣的深度估計方法。基于線索的估計方法是利用各種單目深度線索進行深度估計,常用的深度線索包括:運動信息[1]、聚焦[2]、線性透視[3]、紋理、遮擋[4]、陰影[5]等。因為不同的線索只出現在特定的場景,且各線索與深度間的關系不是絕對的,所以存在場景適用性和深度估計失敗的問題。基于圖模型的估計方法[6]考慮到場景在不同深度處成像的陰影、紋理存在差異,以及彼此間的遮擋關系,采用圖模型來描述圖像特征和彼此間的相對位置關系,并通過監督學習進行訓練。該類算法的缺點是需要設計參數化的模型以及引入太多的場景假設。針對此問題,KONRAD等[7]提出基于采樣的估計方法,首先從RGBD (red green blue depth)數據庫中檢索出匹配的圖像,然后通過融合匹配圖像的深度得到測試圖像的深度。文獻[8]提出基于尺度不變特征變換(scale invariant feature transform, SIFT)流的深度遷移方法,在相似場景間通過SIFT流建立像素級稠密空間對應關系,并將相似圖像對應位置上的深度直接遷移到輸入圖像上。文獻[9-11]構建能量方程對遷移后的深度進行插值和平滑,進一步改善了深度估計的質量。但該方法沒有考慮同一對象深度的均勻性,使得同一目標的深度關系不一致。此外,該類算法的核心步驟是從深度數據庫中進行相似圖像的采樣,將直接影響最終深度融合的效果,目前其算法的采樣都是基于傳統的圖像全局特征之間的歐式距離,沒有考慮到輸入圖像中不同目標的差異性和同一目標的一致性。
本文在基于采樣的深度估計方法基礎上通過引入了卷積神經網絡(convolution neural network, CNN)特征獲得更精確有效的相似圖像集,并利用基于SIFT的遷移權重(SIFT similar weight,SSW)改善深度遷移時的圖像深度均勻性問題。為此,本文提出了基于CNN特征提取和加權深度遷移的單目圖像深度估計算法。
1 算法框架
基于CNN特征提取和加權深度遷移的單目圖像深度估計算法框架如圖1所示,主要分為KNN檢索、加權的SIFT流[8]深度遷移、深度圖融合和基于目標函數的深度圖優化4個模塊。對于一幅輸入圖像,①通過KNN檢索出對近鄰圖像和深度圖;②通過SIFT流計算輸入圖像和各近鄰圖像的形變函數,將形變函數分別遷移到對應的候選近鄰深度圖并加權;③融合加權遷移后的候選深度圖作為輸入圖像的初始深度估計;④建立目標函數對加權遷移后的候選深度圖進行優化,便可得到最終的深度估計。
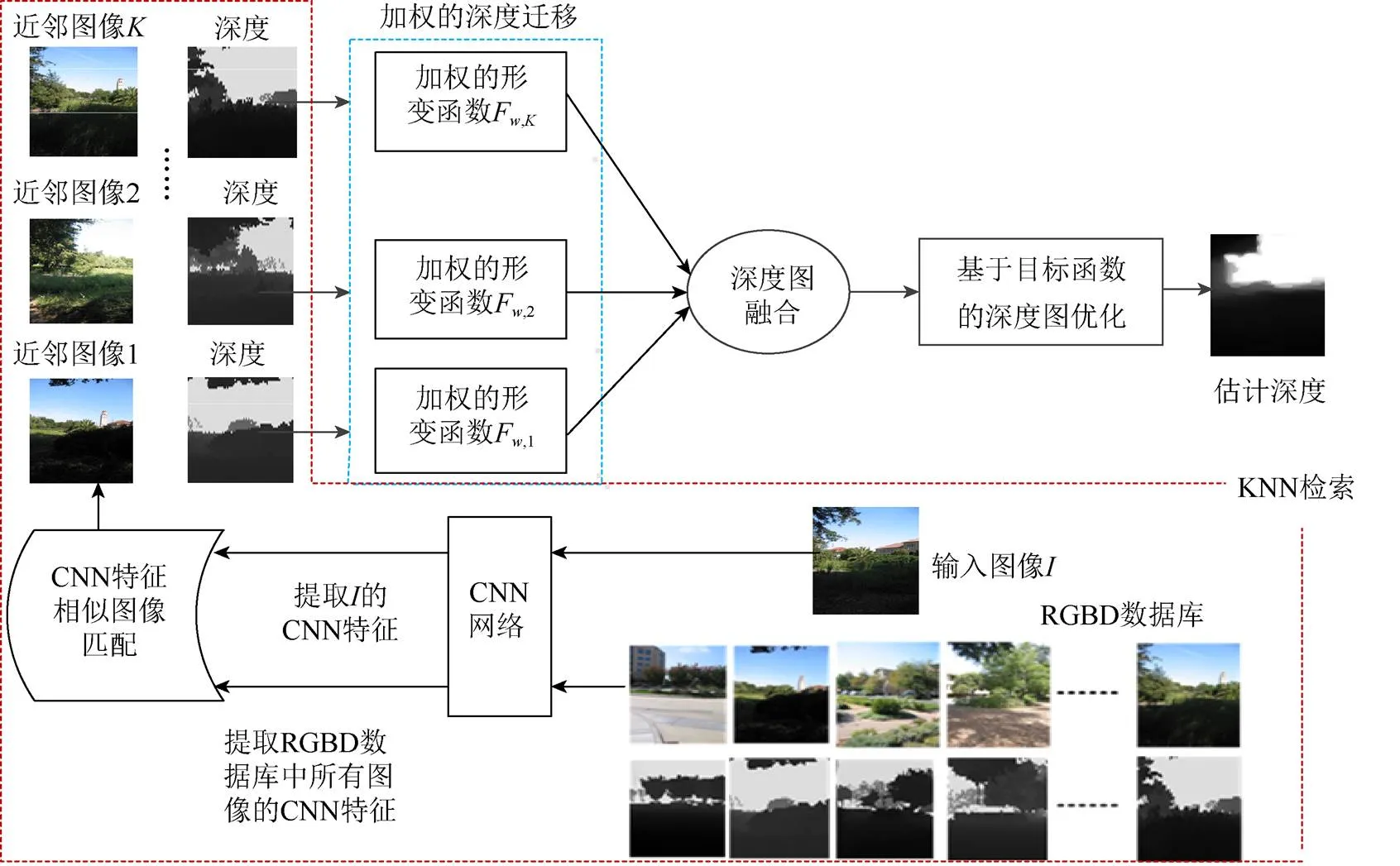
圖1 基于CNN特征提取和加權深度遷移的單目圖像深度估計算法框架
1.1 基于CNN特征的KNN檢索
1.1.1 CNN特征提取
近年來,基于深度模型的CNN[12]在計算機視覺領域取得了重要進展,如物體識別和圖像分類等。從深度網絡模型提取的CNN特征在一定程度上可以彌補電子設備所捕獲的特征和視覺特征所感知到的語義信息之間的差異,如Gist[13]、HOG[14]、LBP[15]和SIFT[16]等特征,其用以表征豐富的語義信息。
本文提取CNN特征所采用的CNN模型如圖2所示,該網絡模型是一個在大量ImageNet數據集上訓練得到的預訓練模型,其包含13個卷積層和3個全連接層。卷積層和前2個全連接層使用RELU(rectified linear units)作為激勵函數。本文使用第2個全連接層的特征圖作為圖像的一種表示,因為該特征具有較好的性能。因此,對于給定圖像,首先將其放縮到224×224大小作為網絡的輸入;其次通過網絡逐層向前傳播;最后,從第2個全連接層提取得到的特征圖()大小為1×1×4096,將其編碼為1×4096大小的一維向量作為CNN的特征表示。
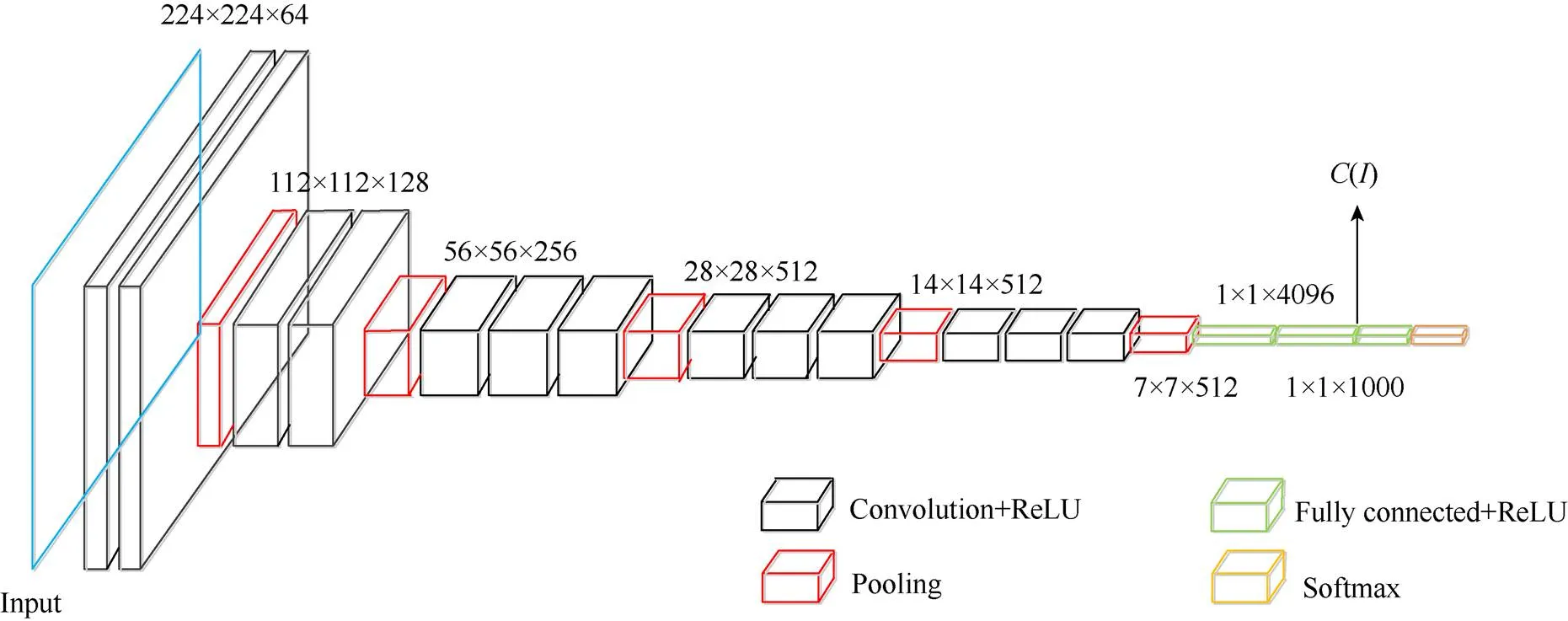
圖2 卷積神經網絡模型
1.1.2 KNN檢索
對于1幅輸入圖像,首先采用1.1.1節中的方法提取其CNN特征,并計算其基于CNN特征余弦匹配在RGBD數據庫中的相似圖像集。假設為輸入圖像,為候選近鄰圖像,(·)為CNN特征,由式(1)計算輸入圖像和RGBD數據庫中每幅圖像的CNN特征的余弦距離;然后,對距離從大到小進行排序;最后,將前個最大CNN余弦距離對應的圖像作為的KNN (K-Nearest Neighbor),其對應的深度作為的候選近鄰深度,即

1.2 加權的SIFT流深度遷移
利用SIFT流[8]建立圖像之間的稠密像素級形變函數,將該形變函數遷移至候選近鄰深度圖像集,可作為輸入圖像估計的深度圖。然而,該方法是對某幅候選近鄰深度圖像的全局遷移,沒有考慮輸入圖像與候選近鄰圖像的空間關系局部差異性,使在同一目標估計出的深度信息缺乏一致性。為此,本文提出基于SSW權重的深度遷移,用于抑制因匹配誤差造成的深度遷移誤差。
1.2.1 基于SIFT流的形變函數
通過計算候選近鄰圖像與輸入圖像之間的SIFT流[8],進而構建候選近鄰圖像到輸入圖像的形變函數F。
設為圖像中(,)處的像素,候選近鄰圖像到輸入圖像間的SIFT流為(),則形變函數F為候選圖像各像素疊加SIFT流的集合,即
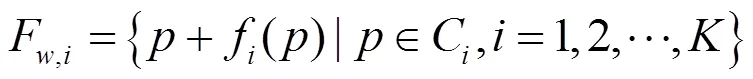
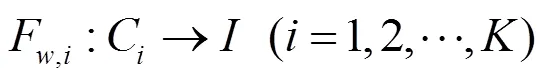
1.2.2 遷移權重SSW
本文提取SIFT描述符計算輸入圖像和候選近鄰圖像的相似程度作為遷移權重,以區分各候選近鄰圖像對輸入圖像深度遷移的貢獻度。可定義該權重為基于SIFT的遷移權重SSW,并依據式(3)計算第幅候選近鄰圖像C到輸入圖像的遷移權重SSW,即
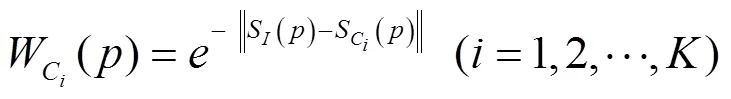
不同于將候選近鄰圖像對應位置上的深度直接遷移到輸入圖像上,而是將深度乘以權重再進行遷移。這樣,各候選近鄰圖像對深度遷移的貢獻不同,對其進行加權后再進行融合,可抑制因匹配誤差造成的深度遷移誤差。
1.2.3 基于SSW的深度遷移
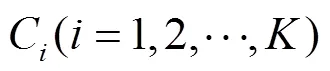

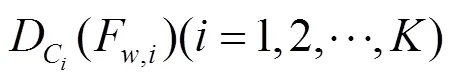
1.3 基于中值濾波的深度圖融合
本文將輸入圖像的候選近鄰深度圖進行加權遷移后的各深度圖進行融合,作為輸入圖像的初始深度估計。基于假設幅圖像與輸入圖像中的相似物體應當出現在同一位置上,例如道路一般出現在圖像的底部,本文采用相同位置上的深度值取中值的方式即中值濾波融合方法,即
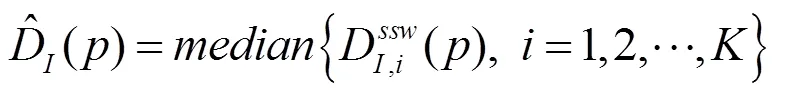
1.4 基于目標函數的深度圖優化
本文將優化后的最終深度圖表示為維的列矢量,其中為輸入圖像中的像素總數。本文構建深度圖優化目標函數包括數據項E、空間平滑項E和先驗項E3部分,即
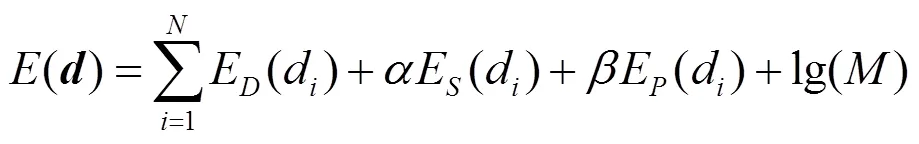
數據項E為優化后的深度圖與遷移后候選近鄰深度圖的關聯程度,其定義為

平滑項E為深度梯度延,方向上的平滑變化函數,即
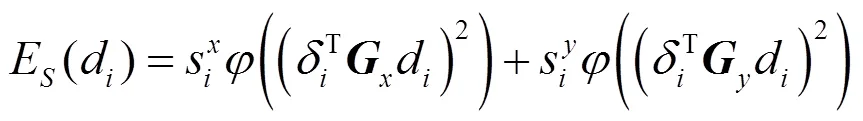
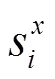
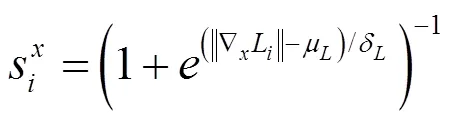

先驗項E是為了防止深度像素匹配的過程中出現輸入圖像的某些像素點,由于在近鄰圖像中匹配的像素點過少,從而無法進行深度賦值的問題,采用式(11)增加一個基本的深度賦值,即
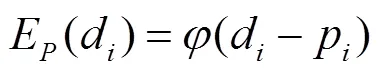
其中,p為所有候選近鄰深度圖的平均值。
式(6)需要一個無約束的、非線性的優化,本文選用迭代重加權最小二乘法(iteratively reweighted least squares,IRLS)[17]對其最小化。IRLS是一種遞歸優化算法,其用一個參數化的線性函數近似代替原始的目標函數,并通過加權最小二乘法求解。由于每次迭代的權值是不確定的,IRLS算法實際上是一種通過迭代獲取權值的方法。通過不斷迭代求解直到收斂,可以得到較精確的估計深度圖。
本文將式(5)的計算結果作為IRLS的迭代初值,對于每次迭代中最小二乘問題,使用預處理共軛梯度法(preconditioned conjugate gradient,PCG)[17]來進行求解。對于1幅輸入圖像,通過KNN候選近鄰圖像的匹配、加權的SIFT流深度遷移、深度圖融合和基于目標函數的深度圖優化4個步驟的逐步求精,可以得到最終的深度估計。
2 實驗結果與分析
為了驗證本文算法的有效性,實驗采用Make3D數據庫[18]和NYU Depth V2數據庫[19]。Make3D數據庫主要采集于室外場景,其包含400對“圖像+深度”訓練數據和134對“圖像+深度”測試數據,圖像和深度的分辨率均為1704×2272,其中深度通過激光測距儀獲得。NYU Depth V2數據庫主要通過Kinect采集于室內場景,將其原始的1 449張圖像分為795對“圖像+深度”訓練數據和654對“圖像+深度”測試數據,圖像和深度的分辨率均為640×480。實驗中IRLS迭代次數設置為10,候選近鄰總數設置為7。
實驗1. 為驗證CNN特征余弦距離匹配進行KNN檢索的有效性,與文獻[10]算法中采用的Gist特征歐式距離匹配選取候選近鄰圖像的方法進行對比。圖3和圖4為場景1和場景2分別基于Gist特征歐式匹配和CNN特征余弦匹配的KNN檢索結果,(a)為原圖,(b)~(h)為對應場景基于KNN的檢索結果。從(b)到(h),與待檢索場景的相似度依次遞減。由圖可看出,通過提取CNN特征進行相似圖像集匹配實驗結果更符合人的語義信息,內容相似的場景被成功檢索出來。
實驗2.為驗證CNN特征提取和加權深度遷移對深度估計的影響,將基于CNN特征提取的深度估計、本文算法與文獻[10]算法進行比較,實驗結果如圖5所示。
從圖5可以看出,CNN圖像匹配可較好地重構出目標場景中的對象,如圖5的第1行中,圖5(d)深度估計比圖5(c)更接近于真實深度;再如第2行中,圖5(c)深度估計錯誤,而圖5(d)準確地重構出目標對象。加權深度遷移更好地刻畫目標圖像中同一對象的均勻性,如圖5的第3行中,圖5(d)背景中馬桶和洗漱臺的邊界不太明顯,而圖5(e)可較明顯區分出邊界信息,體現出了深度均勻性對深度估計的影響。
實驗3. 為驗證本文方法在不同單目圖像上的有效性,與文獻[10]算法進行對比,圖6和圖7分別為Make3D數據庫和NYU Depth V2數據庫的部分實驗結果。從圖中可以看出,通過本文方法估計的深度圖的整體輪廓與真實深度更接近,局部細節信息更準確,更有利于進行圖像的深度估計。
由圖6可知,在室外場景中,相對于文獻[10]算法,本文方法具有更加可信的深度估計結果,可以較好地保持原圖中目標圖像的邊界,例如圖第1和第2行中的樹枝。同時,本文方法可以較好地估計出場景的輪廓結構,例如圖第4行中的場景。此外,本文方法可以重構出場景細微之處的深度信息,例如圖第3行中的右下角部分。

場景1 場景2 (a)(b)(c)(d)(e)(f)(g)(h)

場景1 場景2 (a)(b)(c)(d)(e)(f)(g)(h)

第1行 第2行 第3行 (a) 原圖(b) 真實深度(c) 文獻[10](d) CNN特征(e) 本文算法

第1行 第2行 第3行 第4行 (a) 原圖(b) 真實深度(c) 文獻[10](d) 本文算法

第1行 第2行 第3行 第4行 (a) 原圖(b) 真實深度(c) 文獻[10](d) 本文算法
由圖7可知,在室內場景中,相對于文獻[10]算法,本文方法可以精細地重構場景中的部分結構,例如圖7第1行中的電視和柜子、第2和4行中的餐桌以及第3行中的馬桶和洗漱臺。
實驗4.表1和表2分別給出了本文算法和文獻[10]算法在Make3D數據庫和NYU Depth V2數據庫測試數據上的平均相對誤差RE、平均均方根誤差RMSE和平均對數誤差LE,其分別如式(12)~(14)所定義方法進行計算,即
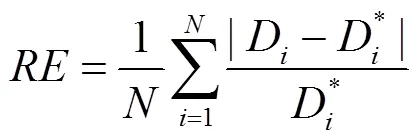
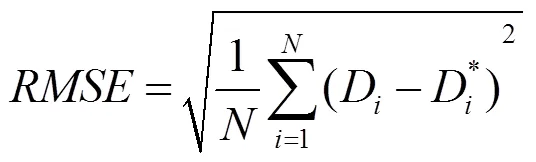
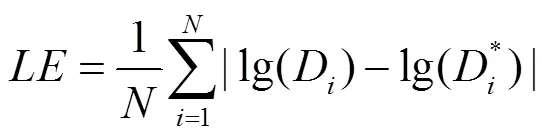
從表1和表2可看出,相比于文獻[10]算法,本文算法利用CNN特征提取明顯降低了估計深度圖的RE、RMSE和LE視覺效果方面也取得了較好的效果,如圖5(d)比(c)深度估計圖更加接近于真實深度,優于文獻[10]算法基于Gist特征進行KNN檢索最終估計的深度效果;其次,本文算法基于CNN特征提取和加權深度遷移在平均誤差方面相比于僅引入CNN特征匹配略有降低,但視覺效果上有明顯提升,如圖5(e)與(d)相比,加權深度遷移能刻畫出場景中同一對象的深度均勻性,較明顯區分出不同對象之間的邊界信息,使估計深度圖更接近于真實深度,又如圖6和圖7,本文算法明顯提升了深度估計效果。

表1 在Make3D數據庫上的比較結果
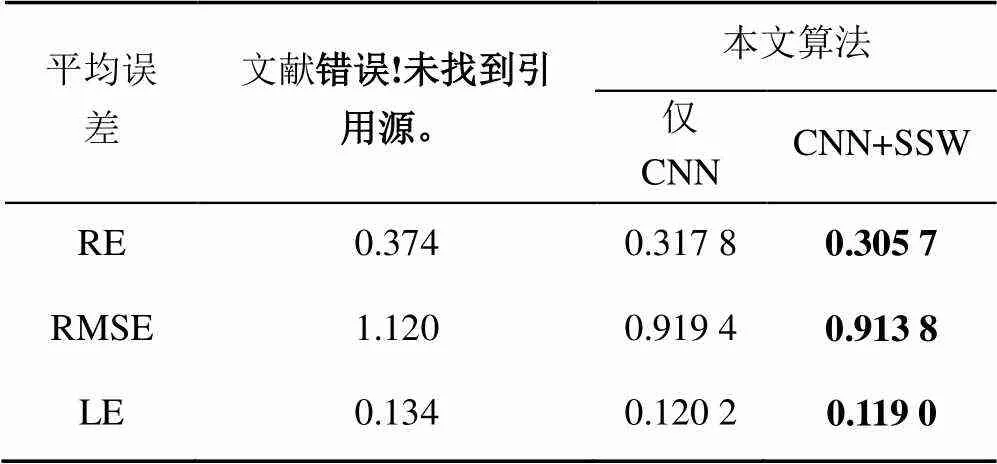
表2 在NYU Depth V2數據庫上的比較結果
3 結束語
本文通過引入CNN特征計算輸入圖像的相似圖像集,將相似圖像對輸入圖像的形變函數遷移至相似候選深度圖像并加權,以獲取最終的深度估計。在實驗結果分析中,無論是在定性的視覺對比,還是定量的性能對比,本文算法都獲得了較優的結果,顯著降低了估計深度的平均誤差,改善了深度估計的質量。
[1] ROBERTS R, SINHA S N, SZELISKI R, et al. Structure from motion for scenes with large duplicate structures [C]//The 24th IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2011. New York: IEEE Press, 2011: 3137-3144.
[2] SUWAJANAKORN S, HERNANDEZ C, SEITZ S M. Depth from focus with your mobile phone [C]//2015 IEEE Conference on Computer Vision and Pattern Recognition. New York: IEEE Press, 2015: 3497-3506.
[3] CHENG C C, LI C T, HUANG P S, et al. A block-based 2D-to-3D conversion system with bilateral filter [C]// 2009 Digest of Technical Papers International Conference on Consumer Electronics. New York: IEEE Press, 2009: 1-2.
[4] CHANG Y L, FANG C Y, DING L F, et al. Depth map generation for 2D-to-3D conversion by short-term motion assisted color segmentation [C]//2007 IEEE International Conference on Multimedia and Expo. New York: IEEE Press, 2007: 1958-1961.
[5] ZHANG R, TSAI P S, CRYER J E, et al. Shape-from-shading: A survey [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 1999, 21(8): 690-706.
[6] SAXENA A, SUNG H. CHUNG A Y N. 3-D depth reconstruction from a single still image [J]. International Journal of Computer Vision, 2008, 76(1): 53-69.
[7] KONRAD J, WANG M, ISHWAR P. 2D-to-3D image conversion by learning depth from examples [C]//2012 IEEE Computer Society Conference on Computer Vision and Pattern Recognition Workshops. New York: IEEE Press, 2012: 16-22.
[8] LIU C, YUEN J, TORRALBA A. SIFT flow: Dense correspondence across scenes and its applications [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2011, 33(5): 978-994.
[9] KARSCH K, LIU C, KANG S B. Depth extraction from video using non-parametric sampling [C]//The 12th European Conference on Computer Vision. Heidelberg: Springer, 2012: 775-788.
[10] KARSCH K, LIU C, KANG S B. Depth transfer: Depth extraction from video using non-parametric sampling [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2014, 36(11): 2144-2158.
[11] 朱堯, 喻秋. 基于非參數采樣的單幅圖像深度估計[J]. 計算機應用研究, 2017, 34(6): 1876-1880.
[12] KRIZHEVSKY A, SUTSKEVER I, HINTON G E. ImageNet classification with deep convolutional neural networks [C]//NIPS’12 Proceedings of the 25th International Conference on Neural Information Processing Systems. New York: IEEE Press, 2012: 1097-1105.
[13] OLIVA A, TORRALBA A. Modeling the shape of the scene: A holistic representation of the spatial envelope [J]. International Journal of Computer Vision, 2001, 42(3): 145-175.
[14] DALAL N, TRIGGS B. Histograms of oriented gradients for human detection [C]//2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPE’05). New York: IEEE Press, 2005: 886-893.
[15] OJALA T, PIETIK?INEN M, M?ENP?? T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, 24(7): 971-987.
[16] LOWE D G. Distinctive image features from scale-invariant keypoints [J]. International Journal of Computer Vision, 2004, 60(2): 91-110.
[17] LIU C. Beyond pixels: Exploring new representations and applications for motion analysis [M]. Cambridge: Massachusetts Institute of Technology, 2009: 153-164.
[18] SAXENA A, SUN M, NG A Y. Make3D: Learning 3D scene structure from a single still image [J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2009, 31(5): 824-840.
[19] SILBERMAN N, HOIEM D, KOHLI P, et al. Indoor segmentation and support inference from rgbd images [C]//The 12th European Conference on Computer Vision. Heidelberg: Springer, 2012: 746-760.
Monocular Image Depth Estimation Based on CNN Features Extraction and Weighted Transfer Learning
WEN Jing, AN Guo-yan, LIANG Yu-dong
(School of Computer and Information Technology, Shanxi University, Taiyuan Shanxi 030006, China)
The depth estimation of monocular image can be obtained from the similar image and its depth information. However, the performance of such an algorithm is limited by image matching ambiguity and uneven depth mapping. This paper proposes a monocular depth estimation algorithm based on convolution neural network (CNN) features extraction and weighted transfer learning. Firstly, CNN features are extracted to collect the neighboring image gallery of the input image. Secondly, pixel-wise dense spatial wrapping functions calculated between the input image and all candidate images are transferred to the candidate depth maps. In addition, the authors have introduced the transferred weight SSW based on SIFT. The final depth image could be obtained by optimizing the integrated weighted transferred candidate depth maps. The experimental results demonstrate that the proposed method can significantly reduce the average error and improve the quality of the depth estimation.
monocular depth estimation;convolution neural network features; weighted depth transfer; depth optimization
TP 391
10.11996/JG.j.2095-302X.2019020248
A
2095-302X(2019)02-0248-08
2018-09-07;
2018-09-12
國家自然科學基金項目(61703252);山西省高等學校科技創新項目(2015108)
溫 靜(1982-),女,山西晉中人,副教授,博士,碩士生導師。主要研究方向為圖像處理、計算機視覺等。E-mail:wjing@sxu.edu.cn
猜你喜歡
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
電子制作(2019年15期)2019-08-27 01:12:00
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
財經(2017年2期)2017-03-10 14:35:35
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
財經(2016年15期)2016-06-03 07:38:02
財經(2016年3期)2016-03-07 07:44:46
財經(2016年6期)2016-02-24 07:41:51
