空氣質量監測大數據區間的統計問題
2019-05-23 02:55:30劉黎志何經緯
武漢工程大學學報 2019年2期
關鍵詞:定義
劉黎志,何經緯
智能機器人湖北省重點實驗室(武漢工程大學),湖北 武漢 430205
城市空氣質量監測站的監測過程需要記錄大量實時數據,以及根據實時數據計算出的小時均值數據、日均值數據和評價數據[1-3]。湖北省環境中心站所管轄的102個自動化站每天產生的海量數據,如果使用關系型數據庫存儲,數據檢索的實時性和效率將無法保證。基于Hadoop的大數據解決方案的研究為有效存儲和快速檢索空氣質量監測數據提供了新途徑,其中HBase是建立在Hadoop之上,具有高可靠性、高性能、列存儲、可伸縮、實時讀寫等特點的數據庫系統,HBase通過指定行鍵(row key)的范圍來查詢數據,為海量的數據提供高效率的數據維護及檢索功能[4-11]。
在對空氣質量監測數據進行查詢時,通常需要對某個監測值或評價值進行區間統計,如統計宜昌市全年NO2的實時濃度值在0.00~41.00 μg/m3,43.05~82.00 μg/m3,84.05~123.00 μg/m3,125.05~164.00 μg/m3,166.05~205.00 μg/m3區間的分布情況;統計宜昌市的伍家崗站2016年6月輕度污染以上的天數,即 AQI指數分別在 101~150,151~200,201~ 300,>300的天數。HBase提供的 Scan方法,每執行一次next操作,只會從服務端讀取一行數據,因此掃描多個Region會在客戶端和服務端之間形成大量的遠程過程調用(remote procedure call,RPC)通訊,從而影響查詢效率。HBase0.92版本中提出的終端(Endpoint)協處理器可以在服務端完成計數、求和、求最大值等統計工作,并將結果返回到客戶端,減少了客戶端到服務端的RPC調用,從而極大地提高了統計查詢的效率[12-14]。本文將對如何使用終端(Endpoint)協處理器對空氣質量監測大數據進行區間統計進行討論。
1 空氣質量監測大數據存儲模式設計
基于HBase的空氣質量監測大數據的存儲模式設計如圖1所示。
空氣質量存儲模式的具體描述見文獻[15],實際的應用證明該模式可以有效地對空氣質量監測數據進行存儲及滿足地區、站點之間的數據同比、數據環比、趨勢分析等查詢所需的要求。
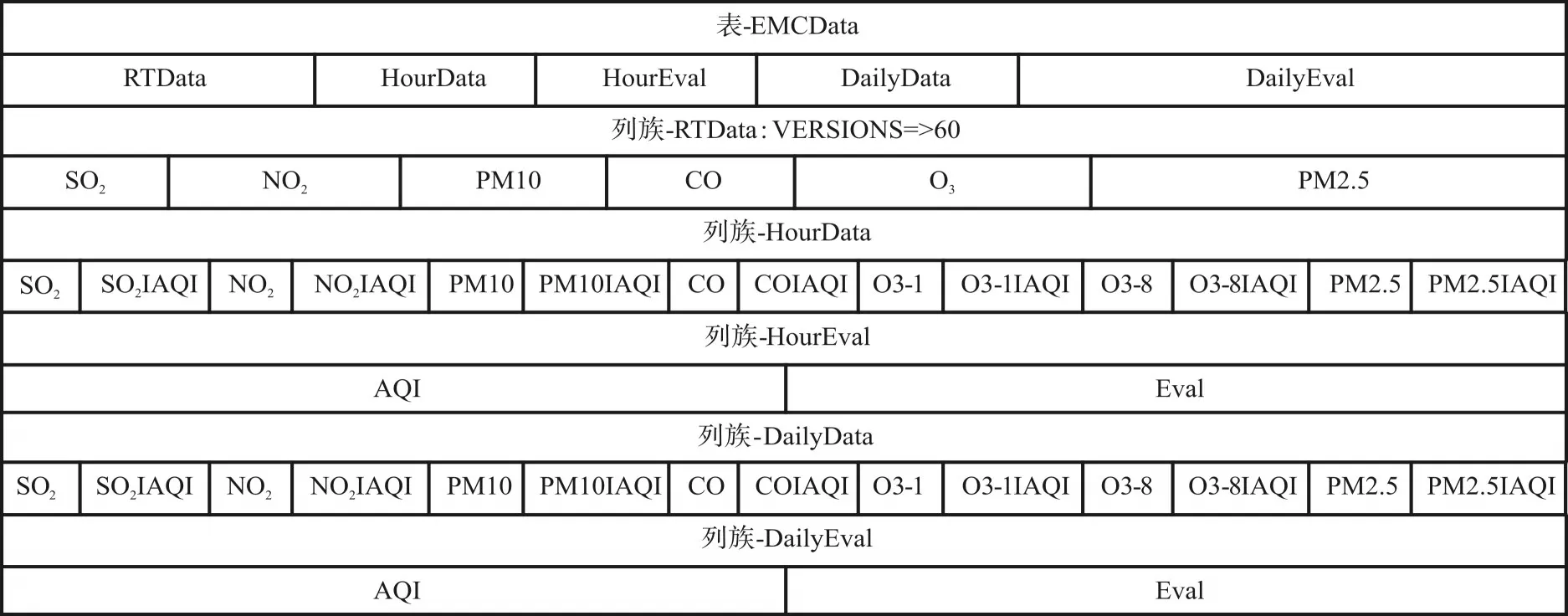
圖1 空氣質量監測數據存儲模式Fig.1 Store schema of air quality monitoring data
2 區間統計協處理器
協處理器分為觀察者(Observer)模式及終端(Endpoint)模式兩種。終端協處理器可以將數據檢索統計過程放在服務端完成,減少客戶端到服務端的遠程過程調用產生的通訊開銷,從而提高統計效率,使用終端協處理器對數據進行區間統計的過程如圖2所示。
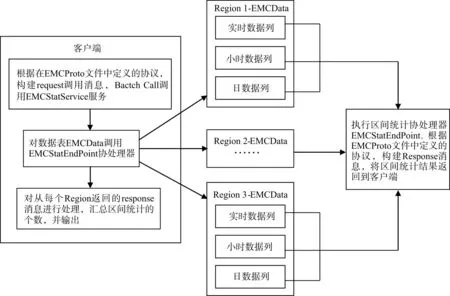
圖2 協處理器調用過程Fig.2 Process procedure of co-processor
數據區間統計的步驟為:1)定義EMCStat.proto文件,按照protobuf協議定義區間統計協處理器的 request,response消息格式及 RPC服務;2)定義協處理器類EMCStatEndPoint,實現EMCStat.proto文件中定義的RPC服務EMCStatService,服務中的getEMCStat方法實現區間統計的業務邏輯;3)為EMCData表加載 EMCStatEndpoint協處理器;4)客戶端調用EMCStatEndpoint協處理器,對分布在不同Region上的數據進行區間統計,并輸出結果。
2.1 Protobuf協議
終端協處理器使用protobuf協議來定義客戶端與服務端進行通信的消息格式,實現空氣質量區間統計終端協處理器的protobuf協議的定義為:
message EMCStatRequest
{ //定義客戶端請求協議格式
required string areacode=1;//地區碼
optional string ssid=2 ;//站點編碼
required string stattime=3;//統計開始時間
required string endtime=4;//統計結束時間
required string cf=5;//列簇名
required string qual=6;//列限定符
message LHLimit//區間嵌套消息
{
required float ll=1;//區間下限
required float hl=2;//區間上限
}
repeated LHLimit lh=7;
//區間消息可重復,表示可以定義多個區間
}
message EMCStatResponse
{ //定義服務端返回協議格式
required string areacode=1;//地區碼
optional string ssid=2 ;//站點編碼
required string cf=3;//列簇名
required string qual=4 ;//列限定符
message LHCount/區間統計結果嵌套消息
{
required float ll=1 ;//區間下限
required float hl=2;//區間上限
required int64 count=3 ;//區間計數
}
repeated LHCount lhc=5;
}//可以輸出多個區間統計結果
service EMCStatService
{//協議服務名
//rpc調用方法名
rpc getEMCStat(EMCStatRequest)
returns(EMCStatResponse);
}
客戶端在調用服務端的終端協處理器時,會根據EMCStatRequest協議的格式,向協處理器傳遞參數,包括:區間統計的地區碼、站點編碼、統計時間段,需要統計的列簇名及列限定符名,統計區間集合列表。協議服務EMCStatService表示其RPC方法 getEMCStat以EMCStatRequest消息為輸入,在獲取其定義的所需參數后,執行區間統計程序,服務端協處理器按照EMCStatResponse協議格式將區間統計的結果返回給客戶端。所有協議被定義在EMCStat.proto文件中,使用protoc工具,執行protoc--java_out=./src EMCStat.proto命令,可以在項目中生成EMCStatProtos.java文件,該Java文件是區間統計協處理器數據交換協議的代碼實現,文件中定義了EMCStatService抽象類以及抽象方法getEMCStat。
2.2 區間統計協處理器實現
定義EMCStatEndPoint類為區間統計協處理器的實現邏輯類,該類繼承于EMCStatService抽象類,并實現了Coprocessor和CoprocessorService接口,EMCStatEndPoint類中的getEMCStat方法用于實現區間統計過程,主要過程如下:
算 法 getEMCStat(RpcController rpcCt,EMCStatRequest emcsRequest,RpcCallback <EMCStatResponse> done){
輸入:emcsRequest;
輸出:done;
1:Scan sc=new Scan();sc.setMaxVersions();
2:讀取emcsRequest消息的各個字段,包括地區碼、站點編碼、統計時間段、列簇名、列限定符賦值到對應的變量;
3:根據emcsRequest消息提供的統計區間對區間類集合列表進行初始化,將每個區間的計數設置為0;
4:if(站點編碼為空){將地區下的所有站點編碼添加到lstSSIDS集合,表示統計所有站點};
5:else{將站點編碼添加到lstSSIDS集合}
6:EMCStatResponse response=null;InternalScanner itScanner=null;
7:for(String assid:lstSSIDS){
8:sc.setStartRow(startKey);//區間統計 startKey為地區碼_站點編碼_統計開始時間
9:sc.setStopRow(endKey);//區間統計endKey為地區碼_站點編碼_統計結束時間
//判斷是否需要對該region進行統計
10:if(startKey > env.getRegion().getEndKey()||end-Key < env.getRegion().getStartKey()){break;}
11:sc.addColumn(Bytes.toBytes(列簇名),Bytes.to-Bytes(列限定符));
12:itScanner=env.getRegion().getScanner(sc);
13:List<Cell> cellResults=new ArrayList<Cell>();boolean isHasMore=false;
14:do{
15:isHasMore=itScanner.next(cellResults);
16: for(Cell cell:cellResults){根據cell的值,確定其所在的區間后,將其集合列表中對應的記數加1;}
17:cellResults.clear();}}
區間統計協處理器在對每個Region進行統計時,可以根據Region的StartKey和EndKey來判斷該Region是否參與統計,當進行區間統計的Start-Key大于Region的EndKey或區間統計的EndKey小于Region的StartKey時,可直接跳過該Region。在如圖3所示的5個區間統計中,Region-A參與區間統計 2、3、4,不參與區間統計 1、5。在區間統計過程中跳過不需要進行統計的Region,可以加快掃描速度,提高統計效率。
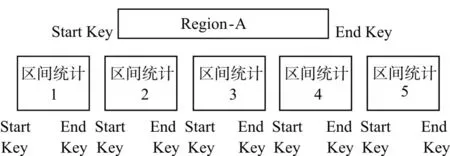
圖3 Region統計邏輯Fig.3 Statistic logic of region
算法中的區間類的定義和EMCStatResponse中的消息LHCount的格式一致。EMCStatEndPoint類編譯成功后,將其所在的jar包導出,并上傳到Hadoop集群的HDFS分布式文件系統中,使用alter‘EMCData’,‘coprocessor’=>‘hdfs:///jar包的路徑/jar包|EMCStatEndPoint協處理器的完整類名|表示優先級的整數值|參數’命令將協處理器加載到EMCData表。
2.3 客戶端調用
客戶端區間統計業務邏輯按EMCStatRequest的消息格式定義協處理器統計過程所需要的參數后,以Batch Call方式調用EMCData表的區間統計協處理器,由于Batch Call只負責對每個Region進行區間統計,所以還需要對每個Region的區間統計結果進行匯總后輸出,過程如下:
算法:main(String[]args){
輸入:args[0]:地區碼,args[1]ssid :站點編碼,若為“-”,表示查詢所有子站點;args[2]startTime-endTime 以-分隔;args[3]列簇名:限定符;args[4]lh-hh:lh-hh表示統計區間
輸出:每個region的統計結果;
1:根據args數組,將用戶輸入的參數地區碼、站點編碼、統計時間段、列簇名、列限定符賦值讀取到對應的變量;
2:將統計區間讀取到LHLimit類型的集合列表中;構造EMCStatRequest消息;
3:long beginTime=System.currentTimeMillis();Configuration config=HBaseConfiguration.create();
4:HTable htb=new HTable(config,“EMCData”);
5:Map<byte[],String> resultMaps=htb.coprocessorService(EMCStatService.class,null,null,
6:new Batch.Call<EMCStatService,String>(){//調用協處理器
7:public String call(EMCStatService emcStat){
8:ServerRpcController srController=new ServerRpcController();
9:BlockingRpcCallback<EMCStatResponse> bRpcCb=
10:new BlockingRpcCallback<EMCStatResponse>();
11:emcStat.getEMCStat(controller,request,bRpcCb);
12:EMCStatProtos.EMCStatResponse emcsResponse=bRpcCb.get();//得到Response返回消息
13:if(emcsResponse ! =null){List<LHCount> lstlh-Count=emcsResponse.getLhcList();
14:for(LHCount lhc:lstlhCount){輸出每個 region的統計結果;將每個region的區間統計結果進行累加;}}
15:return“”;}});
通過記錄區間統計的開始和結束時間,得到協處理器區間統計所需的時間,可以快速地與直接使用Scan操作進行區間統計所需的時間進行比較。
3 實驗部分
實驗環境的安裝和配置和文獻[16]中描述的一致。模擬的數據寫入程序按每個監測項目,每小時40~60個實時值寫入EMCData表,實時數據寫入完成后,自動計算并寫入小時均值及評價,全天的小時均值計算完成后,自動計算并寫入全天的日均值及評價。
在數據的寫入過程中,當Region的數量分別為 3、5、7、9、11時,對存儲 NO2實時濃度數據的列RTData 按 0.00~41.00 μg/m3,43.05~82.00 μg/m3,84.05~123.00 μg/m3,125.05~164.00 μg/m3,166.05~205.00 μg/m3進行區間統計,參數為:地區碼 4201,站點編碼為空,表示統計該地區下的所有站點(9個子站+城區),統計時間段覆蓋所有Region。為減少客戶端Scan統計過程RPC調用,可以為Scan操作設置一個掃描緩存值,表示一次RPC調用可以從服務端讀取的行數,從而減少客戶端RPC請求次數,但掃描緩存值不能設置太高,否則會過多消耗客戶端內存,嚴重時還會導致內存溢出,且延長next操作的時間,反而降低了查詢效率。掃描緩存值的設置需要在減少RPC請求及客戶端內存消耗之間取得平衡,實驗中將掃描緩存值設置為256。客戶端Scan的統計過程的具體實現算法類似于區間統計協處理器,這里不再具體描述。各區間值統計的結果,使用協處理器進行區間統計及客戶端Scan進行統計所需的時間如表1所示,時間對比如圖4所示。
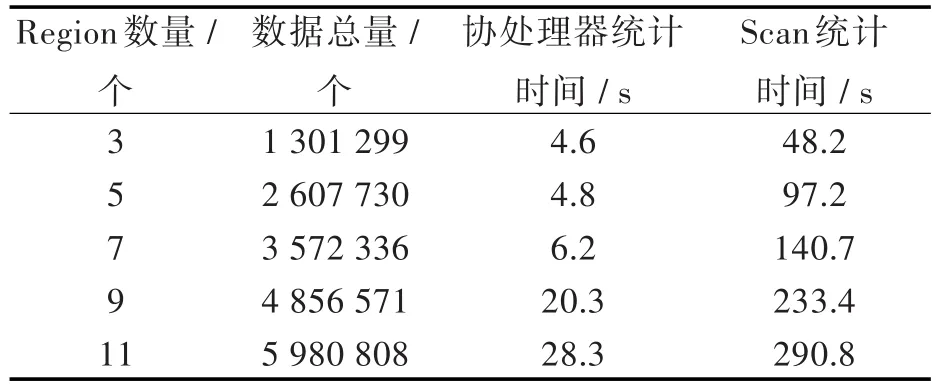
表1 實驗結果Tab.1 Experimental results
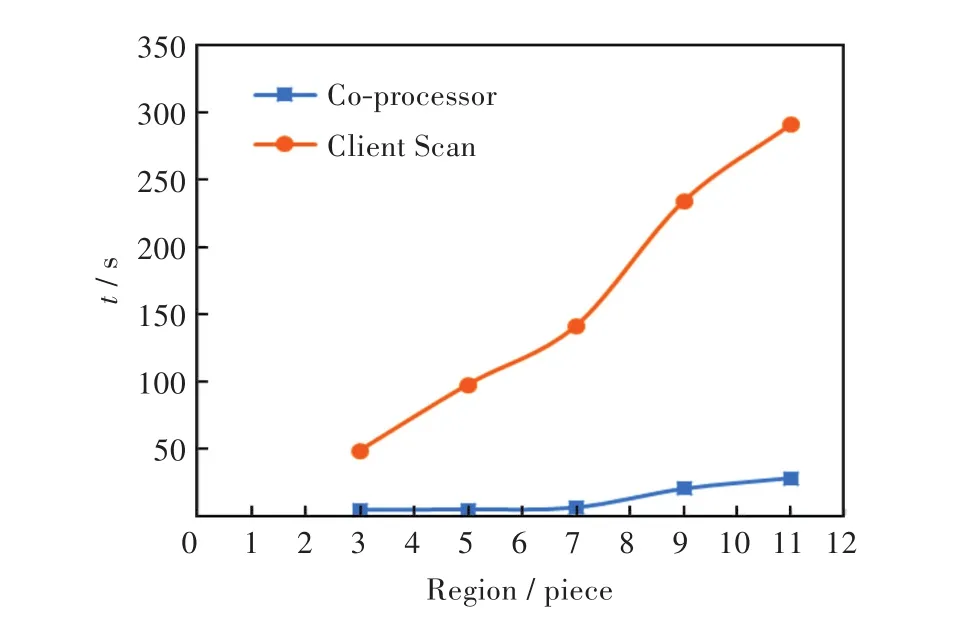
圖4 協處理器和客戶端Scan區間統計時間對比Fig.4 Time comparison of interval statistics by co-processor and client Scan
從實驗結果分析,隨著區間統計需要掃描Region數量的增長,客戶端Scan統計所需的時間呈直線增長,而使用協處理器所需的時間則增長平緩,且當Region數量較少時,時間幾乎沒有增長。使用協處理器進行區間統計較使用客戶端Scan至少快一個數量級(10倍)。
4 結 語
在服務器端使用Endpoint協處理器對城市空氣質量監測數據進行常規的統計工作,會顯著的減少統計所需的時間。理論上,若HBase的數據表在Hadoop集群的每個數據節點上的Region數量相同,且每個Region的大小相同,由于可以進行并行計算,此時Endpoint協處理器的工作效率達到最佳,這也是實驗中,當Region的數量較少時,區間統計的時間幾乎沒有增長的原因。但隨著數據的增長,Region的不斷分裂導致其數量的增加,Region在每個數據節點上的數量不再相同,數據在各個Region上的分布也不再均衡,實驗中在進行區間統計時,客戶端和ZooKeeper服務進行RPC通訊時會出現延遲阻塞的現象,從而導致Region數量從7增加到9時,區間統計所需時間發生突變(增加近3倍)。如何有效解決這一問題,將是今后的研究方向。
猜你喜歡
幼兒教育·父母孩子版(2022年4期)2022-05-08 21:35:35
中學生數理化(高中版.高考數學)(2021年3期)2021-06-09 06:09:14
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:38
中學生數理化(高中版.高二數學)(2021年2期)2021-03-19 08:54:04
海峽姐妹(2020年9期)2021-01-04 01:35:44
華人時刊(2020年13期)2020-09-25 08:21:32
VOGUE服飾與美容(2020年9期)2020-09-02 14:47:26
山東青年(2016年1期)2016-02-28 14:25:25
汽車維護與修理(2015年6期)2015-02-28 12:16:55
當代修辭學(2014年3期)2014-01-21 02:30:44
