關于Ceph優化企業云后端存儲方案的研究
2019-05-23 08:47:20解辰輝劉承亮曲左陽
鐵路計算機應用 2019年4期
關鍵詞:優化
解辰輝,劉承亮,曲左陽
(中國鐵道科學研究院集團有限公司 電子計算技術研究所,北京 100081)
OpenStack是目前流行的開源云平臺技術,是企業實現私有云平臺提供IaaS形式服務的重要解決方案[1]。OpenStack所包含的組件相對較多,各個組件間存在依賴關系,如每個組件都會依賴Keystone,Nova還依賴于G lance,Neutron和Cinder;Sw ift,Glance和Cinder需要后端存儲的支持。
原生的OpenStack并不支持統一存儲,云主機服務Nova、鏡像服務Glance、云硬盤服務Cinder的后端存儲各不相同。后果是內耗嚴重,單純從創建虛擬機這一操作來看,通常需要1~3 m in。這樣的設計缺乏合理的橫向擴展性,當系統壓力增大時,必然會出現各種問題。在構建云平臺時,須對存儲進行重新設計。早先業界不少學者或企業在為OpenStack優化Sw ift上做了大量的工作。本文嘗試將云平臺所有數據存儲在Ceph資源池里,包括創建虛擬機,遷移,擴容,縮容等所有操作都可以避免不必要的數據傳輸[2]。提出一套更加適用于企業生產環境的優化方案:通過調整元數據備份策略,網絡傳輸方式以及根據企業環境調整配置策略,提升整體性能。
1 Ceph分布式存儲關鍵技術
Ceph是一種高性能的統一分布式存儲系統,具有高可靠性和可擴展性。Ceph可以通過一套存儲系統同時提供對象存儲、塊存儲和文件存儲系統3種功能,以便在滿足不同應用需求的前提下簡化部署和運維。其中,對象存儲,既可以通過使用Ceph的庫,利用C、C++、Java、Python、PHP代碼訪問,也可以通過Restfu l網關以對象的形式訪問或存儲數據,兼容亞馬遜的S3和OpenStack的Sw ift。塊存儲,作為塊設備,可像硬盤一樣直接掛載。文件系統如同網絡文件系統一樣掛載,兼容POSIX接口。在Ceph系統中分布式意味著真正的去中心化結構以及沒有理論上限的系統規模可擴展性[2]。Ceph的系統層次,如圖1所示。
在Ceph的架構中,對象存儲由LIBRADOS和RADOSGW提供,塊存儲由RBD提供,文件系統由CEPH FS提供,而RADOSGW, RBD, CEPH FS均需要調用LIBRADOS的接口,而最終都是以對象的形式存儲于RADOS里[3]。Ceph集群的節點有3種角色:
(1)M onitor,監控集群的健康狀況,向客戶端發送最新的Crush map(含有當前網絡的拓撲結構)。
(2)OSD,維護節點上的對象,響應客戶端請求,與其他OSD節點同步。
(3)M DS,提供文件的M etadata,提供高層應用接口CephFS[4]。
Ceph是分布式的存儲,它將文件分割后均勻隨機地分散在各個節點上,Ceph采用了CRUSH算法來確定對象的存儲位置,只要有當前集群的拓撲結構,Ceph客戶端就能直接計算出文件的存儲位置,直接跟 OSD節點通信獲取文件而不需要詢問中心節點獲得文件位置,這樣就避免了單點風險。Ceph已經是一套比較成熟的存儲系統了,是OpenStack比較理想的存儲后端,也可以作為Hadoop的存儲后端。
Ceph和Gluster都是靈活存儲系統,在云環境中表現非常出色。在速率上兩者通過各自不同的方式,結果不相伯仲[5]。這里之所以選用Ceph除了因為其更容易與Linux做集成且對于W indow s較為友好,更是看重Ceph 訪問存儲的不同方法有可能使其成為更流行的技術。Ceph已經是主線Linux內核(2.6.34)的一部分,由于其具有高性能,高可靠和高擴展性,Ceph作為一個優秀的開源項目得到更多的關注。
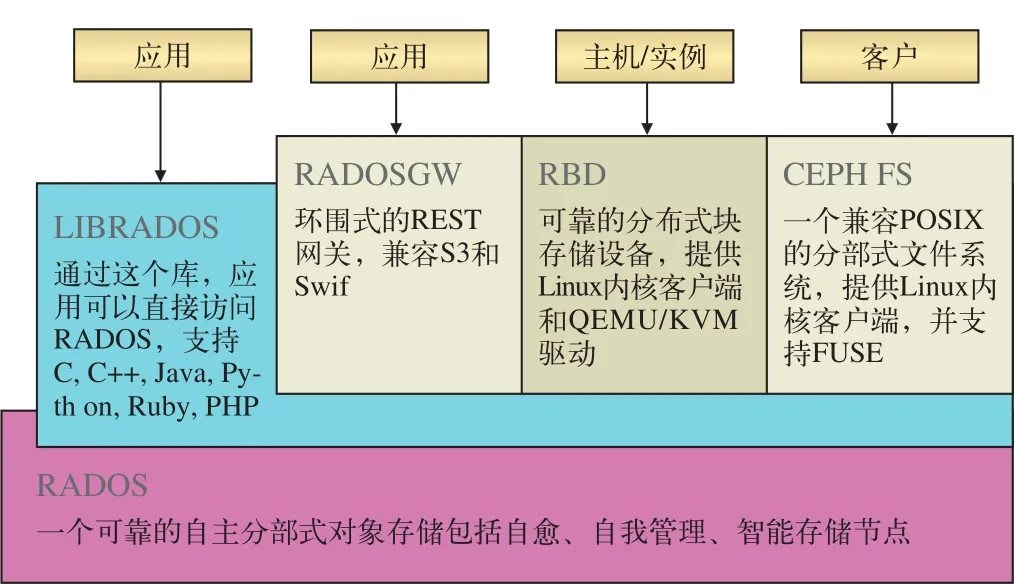
圖1 Ceph的系統層次
2 企業云后端存儲集成Ceph
使用Ceph作為企業云(基于OpenStack)的后端存儲主要有2種思路:(1)由于私有云本身包含Sw ift組件作為對象存儲,Ceph用C++編寫而Sw ift用Py thon編寫,性能上應當是Ceph占優。但是與Ceph不同,Sw ift專注于對象存儲,作為OpenStack組件之一經過大量生產實踐的驗證,與OpenStack結合很好,目前,不少人使用Ceph為OpenStack提供塊存儲,但仍舊使用Sw ift提供對象存儲[6]。(2)將Ceph統一作為Nova/Glance/Cinder的存儲后端[7],如此一來,Nova, Glance, Cinder之間沒有數據傳輸,快速創建虛擬機,只需要管理一個統一存儲[8]。本文采取第2種實現方式進行更深一步的探討。
2.1 實驗環境簡介
整合項目實驗資源(包含設備利舊),搭建實驗集群[9]。總體集群部署分布,如圖2所示。
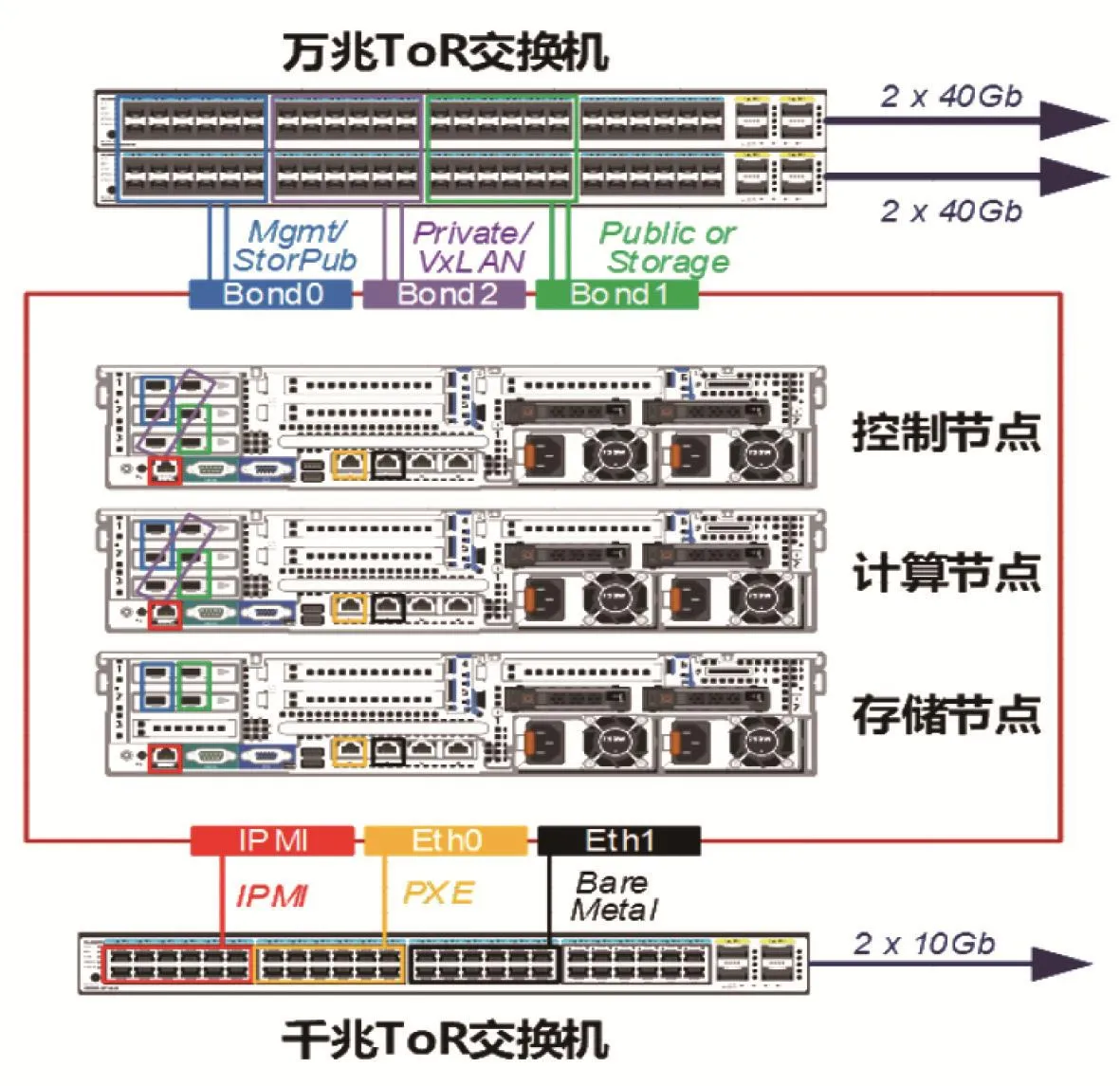
圖2 實驗集群部署功能示意圖
出于未來業務發展需要,集群中部分物理存儲節點選配了3.2 TB NVM E SSD卡。所有存儲節點標配2塊2.5寸600 GB 10K SAS熱插拔硬盤,2塊480 GB SSD(intel S3520系列)熱插拔硬盤,8塊6T 7.2K SATA熱插拔硬盤。
宿主機集群通過部署節點進行PXE網絡部署,操作系統發行版為CentOS Linux release 7.3.1611(Core),部署基于M版OpenStack深度開發的企業云,部署的網絡架構,如圖3所示。
控制節點:存儲pub lic網-雙萬兆,L3 pub lic網-雙萬兆,業務Private網-雙萬兆,部署和物理機監控IPM I-單千兆,管理網-雙萬兆(管理網和存儲Public網合并)。
計算節點:存儲Public網-雙萬兆,業務Private網-雙萬兆,部署和物理機監控IPM I-單千兆,管理網-雙萬兆(管理網和存儲Public網合并)。
存儲節點:存儲Public網-雙萬兆, 存儲Private網-雙萬兆(可用IB),部署和物理機監控IPM I-單千兆,管理網-雙萬兆(管理網和存儲Public網合并)。
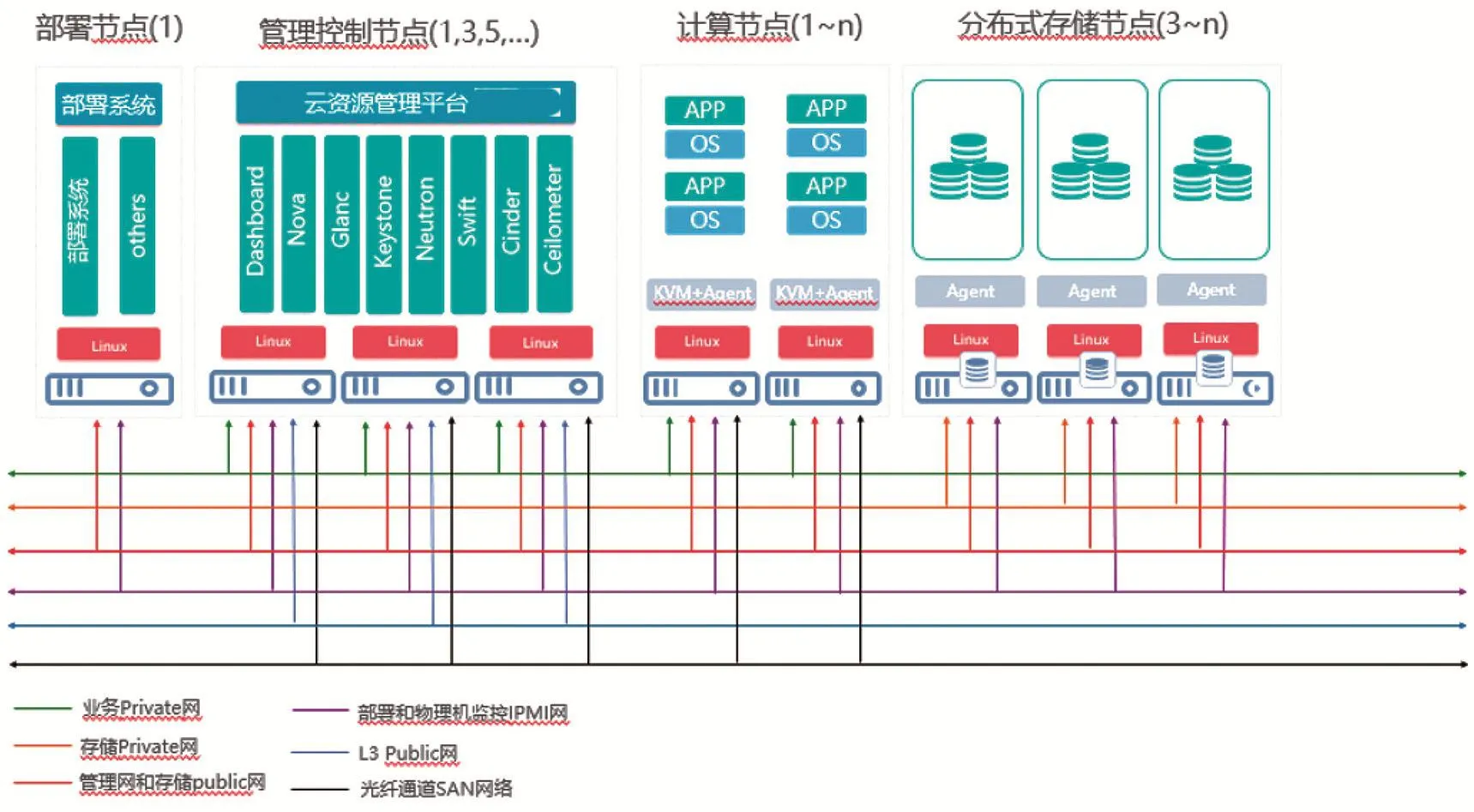
圖3 集群部署網絡架構圖
2.2 社區Ceph支持企業云后端存儲
將Ceph FS作為Nova節點的本地文件系統。作為OpenStack中的共享實例存儲,可以在OpenStack中使用Ceph塊設備鏡像,Ceph塊設備鏡像被當作集群對象。還可以使用OpenStack G lance將鏡像存儲在Ceph塊設備中。這樣OpenStack的Nova G lance和Cinder之間沒有數據傳輸。高可用集群只需管理一個統一存儲[10]。本實驗采用社區版本的Ceph version 10.2.5。
在本文的實驗場景中,Ceph資源池總容量約為479 TB,設置為3副本,可用容量約為159 TB。所有節點上2塊ssd作為日志盤,ssd分為4個區,每個分區大小為 40 G,每個ssd分區對應一個osd。ceph中分為image、volumes、backups 3個池,每個池設置為3副本。由于宿主節點有2種不同的存儲介質,為了發揮硬件資源的最大效力將高速SSD存儲和普通機械SATA存儲劃歸不同的資源池進行測試[11]。按照官方推薦架構做融合,修改OpentStack控制節點中/etc目錄下的配置文件。融合架構,如圖4所示。
在企業云平臺上,實例化1臺Ubuntu14.04 LTS am d_64的云主機,之后分別在2個不同存儲介質的Ceph池中實例化2塊80 G的云硬盤。啟動云主機,分別掛載2塊云硬盤進行fio測試;將ssd掛載到主機后fdisk -l顯示硬盤路徑為/dev/vdb;采用讀寫混合模式fio測試如下:
f io-f ilen am e=/d ev/vdb -direct=1 -iodepth 1 -thread -rw=randrw -rwm ixread=70 -ioengine=psync -bs=16k -size=80G -numjobs=30 -runtime=100 -group_reporting -name=ssd
將ssd卸載,掛載sata硬盤重復上述步驟并進行讀寫混合模式fio測試,測試如下:
fio -filenam e=/dev/vdb -d irect=1 -iodep th 1-thread -rw=randrw -rwm ixread=70 -ioengine=psync-bs=16k -size=80G -num jobs=30 -run tim e=100-group_reporting -name=sata
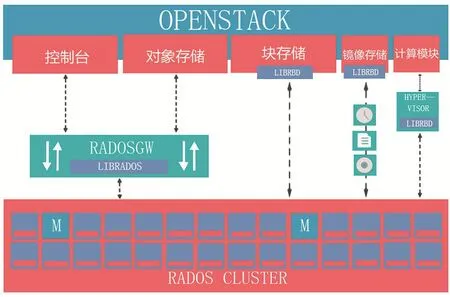
圖4 融合架構
隨后,卸載云硬盤,注銷實例后重新申請,重復上述步驟6次。測試結果如表1、表2所示。
所測試的主要指標包括IO:總的輸入輸出量;bw:磁盤吞吐量;iops:磁盤每秒IO次數;depths:隊列深度,為1;blocksize:塊大小,默認16 K。
從上述測試結果中可以看出,使用社區版Ceph池化資源之后,SSD資源池的讀寫速率只有SATA資源池的2倍左右。
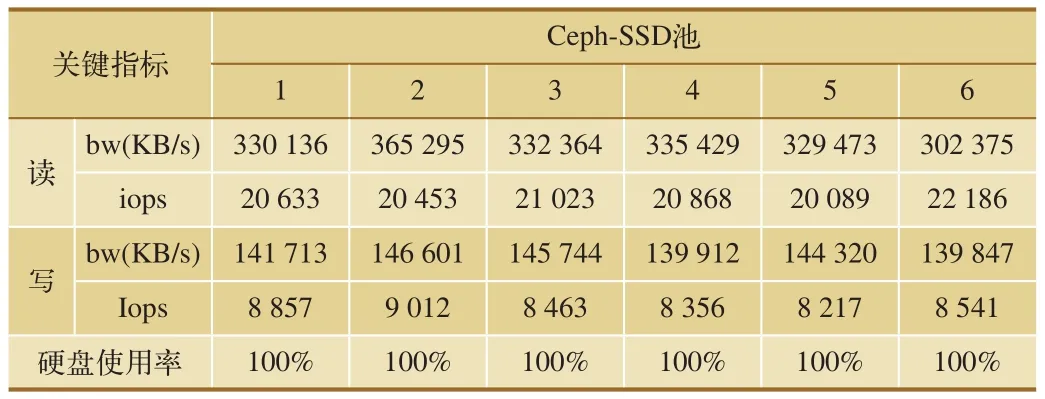
表1 社區版Ceph-FIO-SSD池測試結果
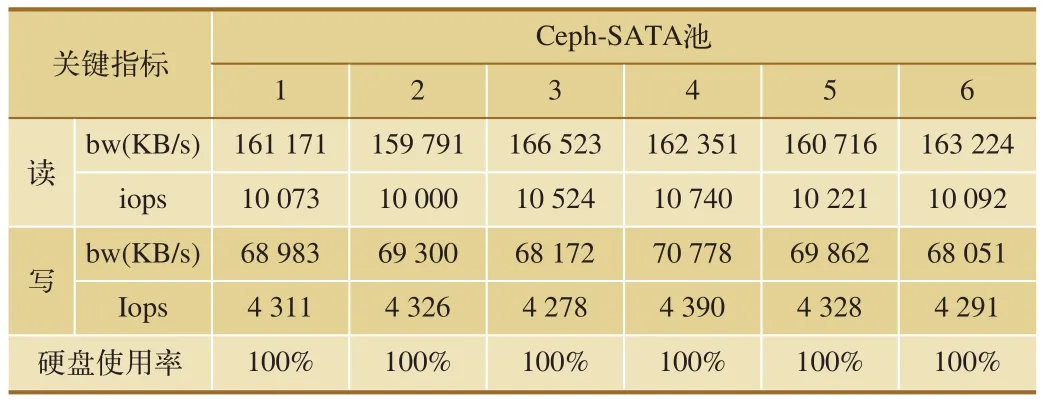
表2 社區版Ceph-FIO-SATA池測試結果

圖5 改進優化的Ceph
2.3 優化Ceph對于企業云后端存儲的支持
如上文所述結果,社區版Ceph存在一定的性能損耗。根據行業統計,社區版Ceph如果沒有好的運維開發團隊,存儲節點數很難超過20個節點以上。在網絡通信,線程調度,內存管理等方面都有很大的提升空間,可以做如下改進:
(1)Ceph在讀寫數據的過程中使用FileStore,在寫數據塊時先寫日志再寫數據,由于雙寫導致性能大打折扣。因此,可將元數據和data分離,只將元數據寫入日志,以此來提升效率。
(2)增加熱點預讀冷池休眠功能,通過將訪問頻次較高的熱數據存儲在高速緩存中,提升讀寫性能。將熱度下降的數據逐步在機械硬盤里落盤,同時控制冷存儲池硬件,減少能耗,增長磁盤壽命。如此一來提高整體的效率。
(3)針對網絡通信進行優化,主要通過聚合TCP鏈路來實現。同時增加對數據接口的支持,包括FC,ISCSI在內的冗余鏈路,保證業務鏈路的安全。并添加壓縮和災備策略,包括1~6的數據副本,糾刪碼等不同的策略。改進架構,如圖5所示。
在具體的使用過程中,可根據集群狀況對一些具體配置進行優化。本文中的配置優化簡述如下:
(1)由于Ceph-OSD進程和Ceph-M SD進程都會消耗大量的CPU資源,因此,通過在節點主機BIOS設置CPU等硬件為最佳性能模式(默認為均衡模式),提高效率,是一個較為簡單卻行之有效的方案。
(2)關閉NUMA,可以在BIOS中關閉NUMA或者修改Ceph節點的配置,在/etc/grub.conf文件添加numa=off來關閉NUMA。
(3)調整PG數量。在本文的實驗環境中共有118個osd;使用3副本;劃分6個poo l,因此,Total PGs=5 900,每個pool的PG計算結果為983,按照以2為底的指數函數取近似,設為1 024。
TotalPGs=(Total_number_of_OSD*100)/max_replication_count
(4)設置預讀,通過數據預讀并且記載隨機訪問內存方式,提高磁盤讀操作。
echo "8192" > /sys/block/sda/queue/read_ahead_kb
總之,高性能硬件帶來效率提升的同時也會增加成本,需要企業根據自身情況和應用場景進行權衡。在架構和配置調優的過程中,不能僅僅關注性能,系統的穩定性同樣重要,上述調優方式較為保守但行之有效。按照2.2節所述測試步驟,進行測試。優化Ceph-FIO-SSD池測試結果,如表3所示。
通過上述測試結果可知,優化后,Ceph的效率較之社區版Ceph效率有較為明顯的提升,為原有效率的130%。
3 結束語
Ceph是面向大型存儲的應用,用以解決企業各種存儲業務上的復雜問題。雖然Ceph的設計初衷定位為PB級的分布式文件系統,但在落地生產環境的過程中尚有很大的提升空間。本文探討了一種可用于實際生產環境的Ceph實施優化方案,較之原生Ceph性能得到了顯著提升,但在生產環境中也需要專業的技術服務團隊作技術支撐。
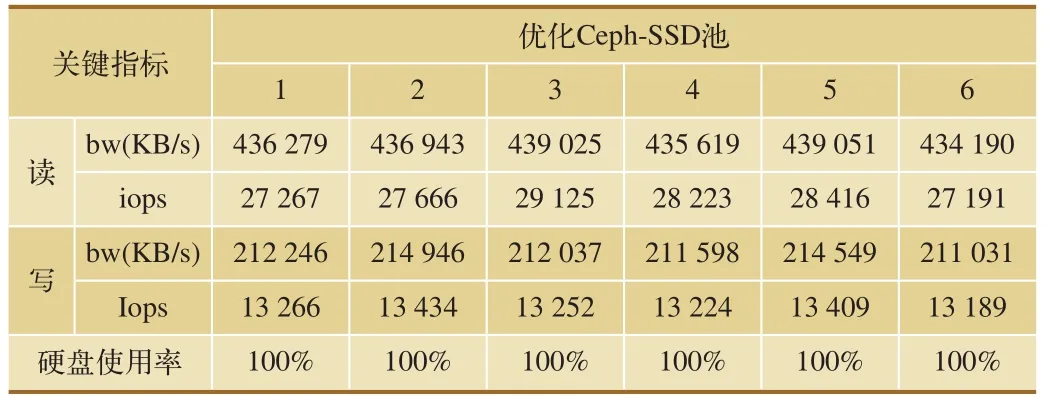
表3 優化Ceph-FIO-SSD池測試結果
猜你喜歡
房地產導刊(2022年5期)2022-06-01 06:20:14
能源工程(2022年1期)2022-03-29 01:06:28
建材發展導向(2021年12期)2021-07-22 08:06:48
建材發展導向(2021年7期)2021-07-16 07:07:52
中學生數理化(高中版.高二數學)(2021年12期)2021-04-26 07:43:48
中學生數理化(高中版.高考數學)(2021年12期)2021-03-08 01:28:50
今日農業(2020年16期)2020-12-14 15:04:59
消費導刊(2018年8期)2018-05-25 13:20:08
家庭影院技術(2018年4期)2018-05-09 07:07:41
電子制作(2017年20期)2017-04-26 06:57:45
