一種KD樹集成偏標記學習算法
2019-05-25 11:26:10盧勇全劉振丙顏振翔方旭升
桂林電子科技大學學報 2019年6期
盧勇全, 劉振丙,2, 顏振翔, 方旭升
(1.桂林電子科技大學 電子工程與自動化學院,廣西 桂林 541004;2.桂林電子科技大學 計算機與信息安全學院,廣西 桂林 541004)
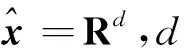
偏標記學習從本質上看是屬于多類分類問題的特例。多類分類問題可以轉換為構建多個二分類問題來解決。然而現有的一對多或一對一方式構建二類基分類器的算法中,很少考慮各個類別樣本數目之間的極度不平衡問題,偏標記學習在處理標簽問題上已經是個難題,加上類不平衡問題,則更加難以解決,且偏標記樣本真實標簽不可知,故該方法不能直接在偏標記學習中使用。做交叉驗證時,有可能將類別少的數據集作為測試使用,從而導致此類別訓練樣本缺失,若運用標簽劃分數據集,則可能存在某類樣本數為0的情況,忽略此極有可能導致算法崩潰。如Lost[4]數據集中存在一類僅有4個樣本的數據,在算法中若不對此情況進行處理,會導致實驗失敗。鑒于此,提出一種KD樹集成偏標記學習算法(ensemble K-dimension tree for partial label learning,簡稱PL-EKT),將樣本候選標簽所攜帶的信息和樣本特征綜合利用,構建多個二分類樣本集,采用集成學習中Stacking的方法處理偏標記學習問題。
1 相關工作
偏標記學習的難度主要是由偏標記數據集的偽標簽造成的[7],為此,學者們提出了一系列算法。最為直觀的方法是對偏標記的偽標簽進行操作,將樣本的偽標簽去掉,也稱為消岐操作,即辨識消岐和平均消岐[8]。辨識消岐是將偏標記的真實標記作為隱變量,采用迭代的方式優化內嵌隱變量的目標函數實現消岐[8]。平均消岐是賦予偏標記對象的各個候選標記相同的權重,通過綜合學習模型在各候選標記上的輸出實現消岐[8]。在辨識消岐中,通過基于極大似然準則的方法優化參數,解決偏標記學習問題。文獻[9]提出一種基于最大間隔偏標記學習算法(PL-SVM),通過模型在Si和非Si上的最大輸出差異進行優化。文獻[10]提出了一種新的基于最大間隔的偏標記學習算法(M3PL),直接優化真實標記與其他標記的差異。在平均消岐中,文獻[11]提出一種代表性的惰性學習算法PL-KNN,類似KNN算法,通過距離度量的方式,根據示例的K個近鄰樣本進行投票預測。文獻[12]提出了基于凸優化的偏標記學習算法CLPL,算法將問題轉化為多個二分類問題,通過在二類訓練集上優化特定的凸損失函數求解偏標記學習問題。
在解決偏標記學習問題上,也有非消岐策略的方法。如文獻[13]提出的編碼解碼策略的輸出糾錯編碼算法PL-ECOC,通過特定編碼和解碼方式實現二分類過程。在編碼階段,通過隨機生成的列編碼來劃分樣本正負集,從而構建二分類器;在解碼階段,讓未見示例在二分類器上輸出特定長度的碼字,將最接近的類別作為測試樣本的預測輸出。PALOC算法[14]、CORD算法[15]通過集成多個分類器,運用模型投票的方法來解決偏標記學習問題。
KD樹(K-dimension tree)是平衡二叉樹,通過利用已有數據對K維空間進行切分[16-17]。KD樹在進行檢索時,以目標點為圓心,以目標點到葉子節點樣本實例的距離為半徑,得到一個超球體,最近鄰的點一定在這個超球體內部。然后返回葉子節點的父節點,檢查另一個子節點包含的超矩形體是否與超球體相交,若相交,就尋找是否有與該子節點更近的近鄰,有的話就更新最近鄰節點;若不相交,直接返回父節點,在另一個子樹繼續搜索最近鄰節點。當回溯到根節點時,保存的最近鄰節點就是最終的最近鄰節點。
集成學習通過聯合幾個模型來提高機器學習效果[18]。與單一模型相比,這種方法可以很好地提升模型的預測性能。其中Stacking是一種通過元分類器或元回歸器來綜合幾個分類模型和回歸模型的集成學習技術。基模型基于整個數據集進行訓練,元模型再將基模型的輸出作為特征進行訓練。
2 KD樹集成偏標記學習
在訓練階段,通過充分利用樣本的候選標簽和樣本特征所隱藏的信息,將樣本分成正負類。其中,1表示正類,0表示負類。劃分正負類數據集后,由于偏標記樣本屬多分類,一般情況下屬于某一類樣本的數量并不多,大部分是其他類別的樣本。在初級模型訓練階段,為了使樣本數量均衡,以小的樣本數量為標準,允許在2倍內波動,當出現某一類樣本極少時,利用KD樹搜索找出特征相似的樣本進行補充,保證正負兩類樣本趨于均衡。完成數據集的劃分后,先訓練出初級分類模型,再利用初級分類模型對樣本進行預測并投票,將初級分類器的預測值加入到原樣本中形成新樣本。運用集成學習的Stacking方法,再次進行分類模型的訓練,最終完成模型的訓練。PL-EKT算法實現過程如下。
輸入:D偏標記樣本集
輸出:根據式(8),返回x*的預測標簽y*
1K:檢索KD的最近K個樣本
2x*:未見示例
3 輸出y*:樣本x*的預測標簽
5 訓練初級分類器Hab←β(D)
6 根據式(6)預測標簽,根據式(7)形成新特征并加入
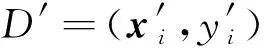
在預測階段,利用初級分類模型對未見樣本進行投票,將投票結果作為新特征加入未見示例中,最后將加入了新特征的未見示例進行最終預測。
按照標簽1、0,根據
(1)
(2)
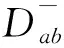
(3)
Dab={T(x1)∪T(x2)…∪T(xk)}
(4)
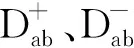
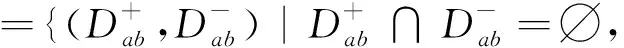
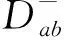
(5)
其中lmax和lmax為設置的樣本數目閾值范圍。
數據集均衡化過程如下:
1)根據式(1)劃分樣本;
2)根據式(2)處理劃分樣本集公共部分,構建KD樹;
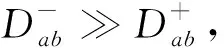
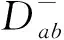
5)樣本為空檢測;
6)若劃分結果不滿足式(5),則返回第2)步。

(6)
實現消岐操作。利用Hab構建樣本新特征,
(7)
(8)
其中γ為平衡因子。
3 實驗
3.1 實驗設置
本次實驗分別在UCI人工數據集和真實數據集2類不同數據集上進行實驗。表2為2組人工UCI偏標記數據集的特性,表3為4組真實偏標記數據集的特性。
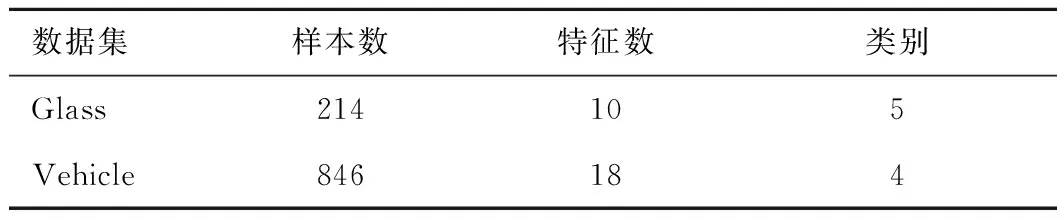
表2 UCI數據集特性
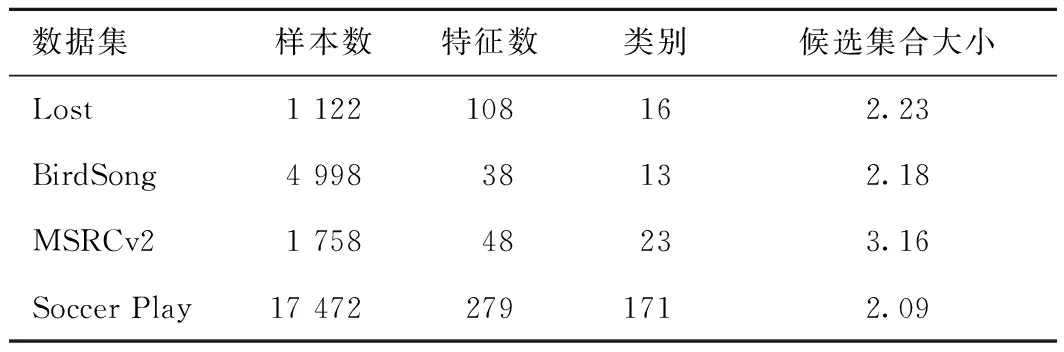
表3 真實數據集特性
3.2 實驗結果
在UCI數據集中,研究提出的算法與各類算法分別在r=1,2,3,步長p從0.1~0.7變化時的分類準確率。采用10倍交叉驗證結果做顯著程度為0.05的成對t檢驗,實驗結果如圖1~3所示。
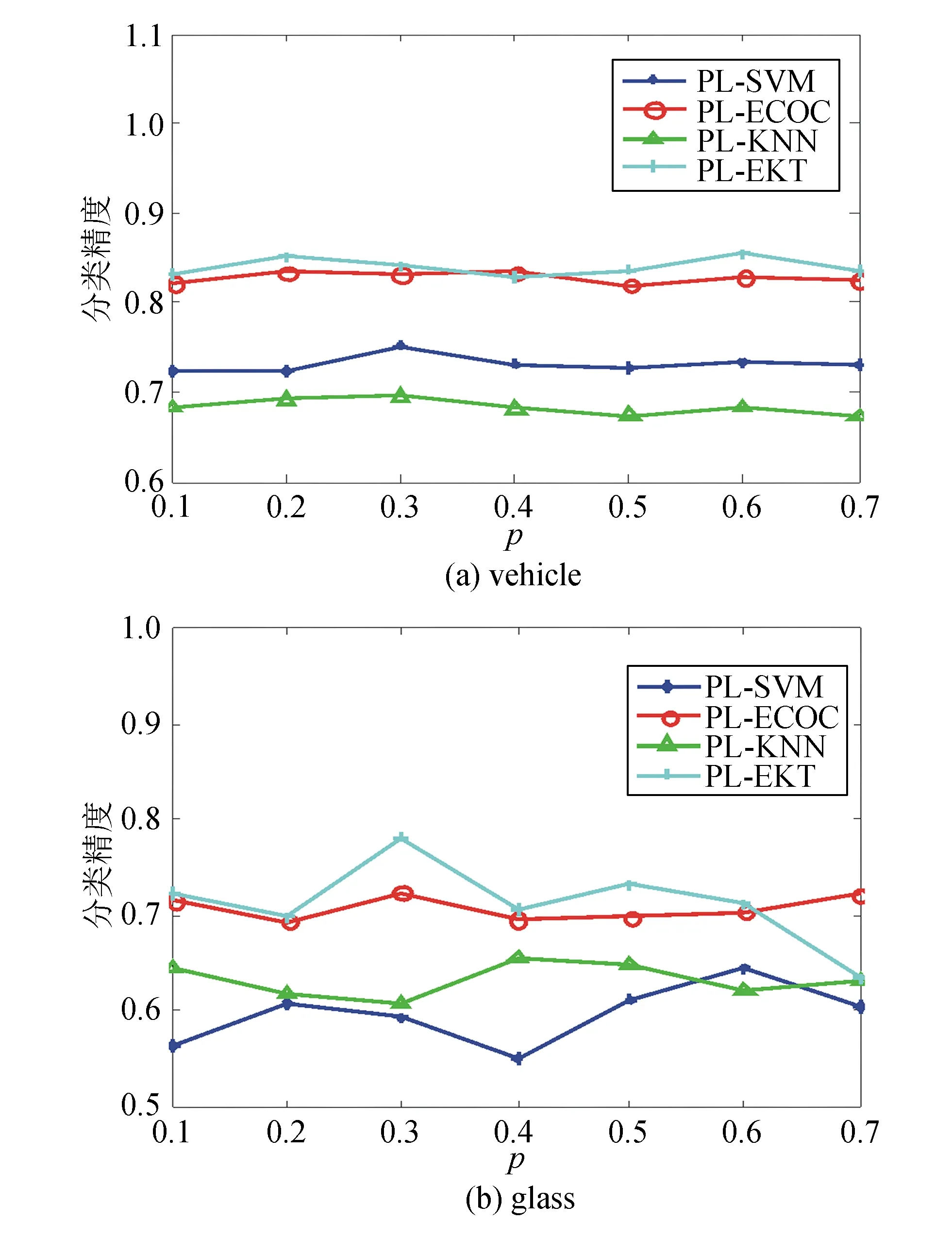
圖1 r=1時p取0.1~0.7的分類精度
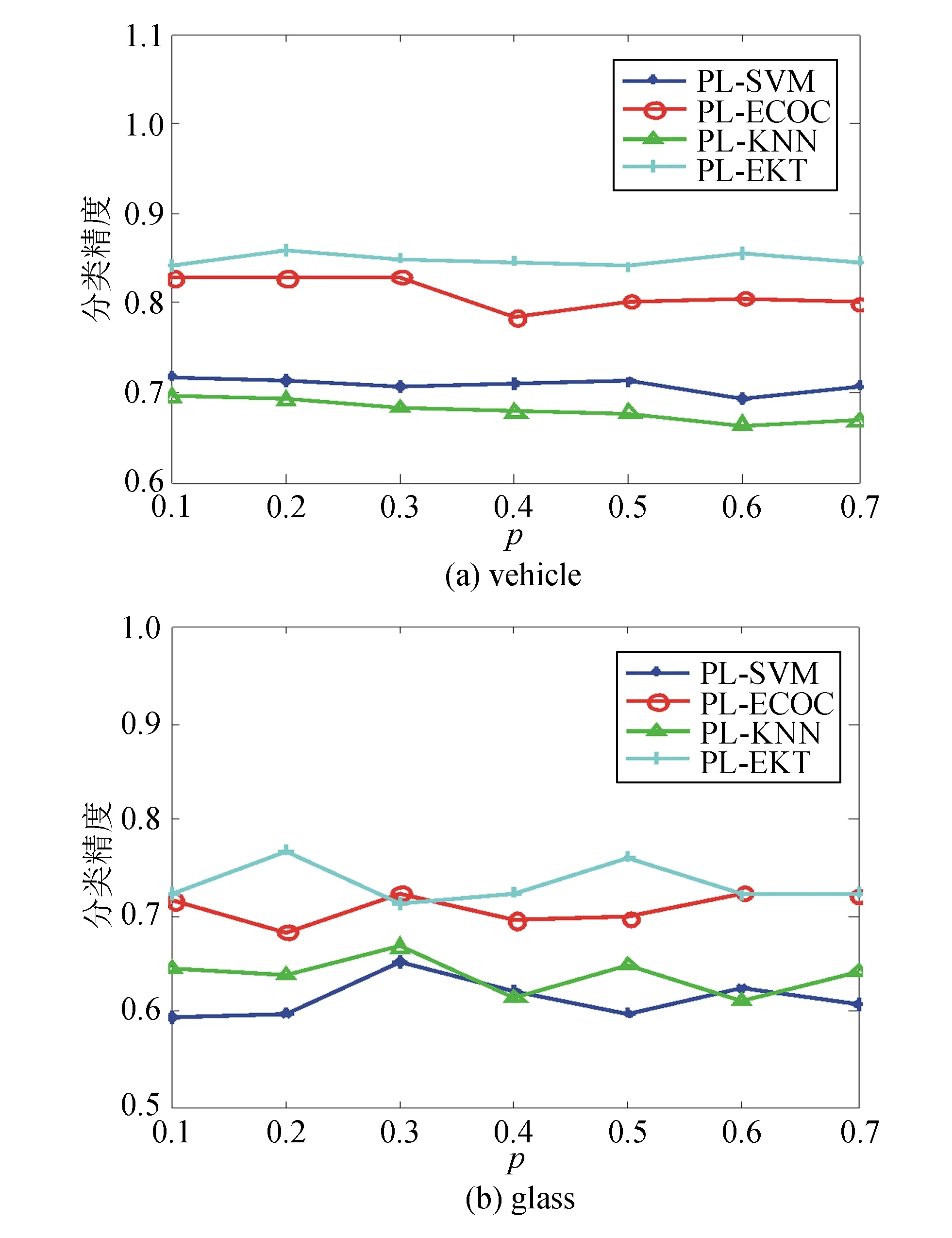
圖2 r=2時p取0.1~0.7的分類精度
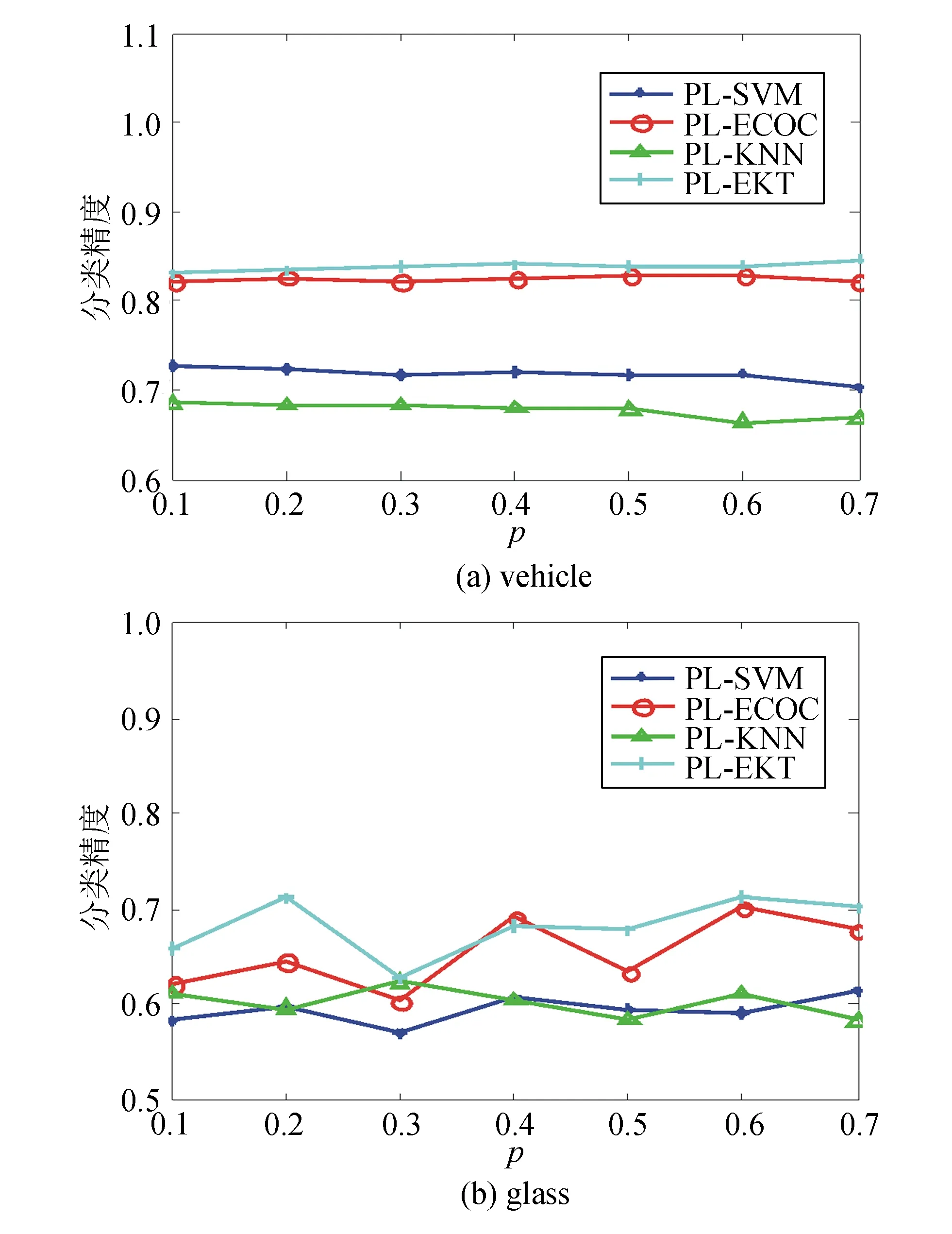
圖3 r=3時p取0.1~0.7的分類精度
通過觀察實驗結果,可得出如下結論:
1)在vehicle數據集上各算法魯棒性均較好,但在glasss數據集上,在不同參數下,各算法分類結果波動較大,魯棒性不足。
2)在vehicle數據集上,除了在個別步長時劣于PL-ECOC算法,PL-EKT算法性能優于其他算法。
在真實數據集上,采用10倍交叉驗證結果做顯著程度為0.05的成對t檢驗。表4給出了各算法在真實數據集上分類精度。
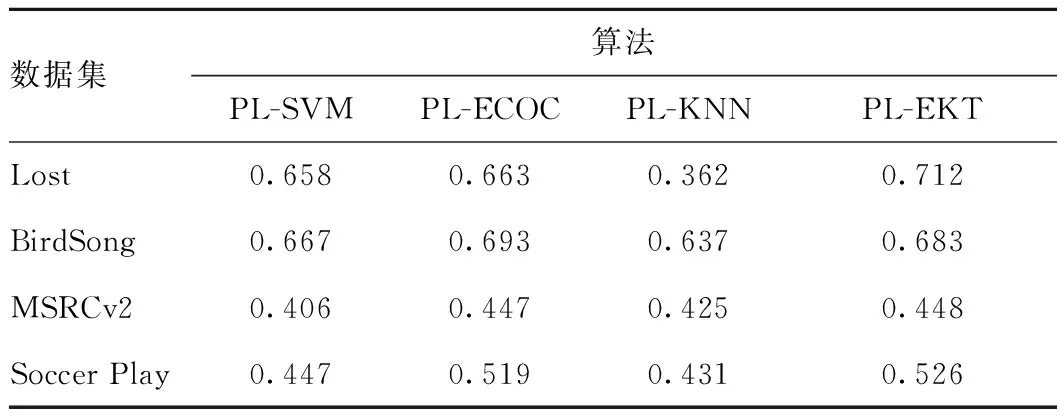
表4 各算法在真實數據集上分類精度
從表4可看出:
1)在Lost數據集上,PL-EKT算法性能比其他3種算法表現好。
2)在MSRCv2數據集上,PL-EKT算法與PL-ECOC算法基本持平,但優于其他算法。
3)在BirdSong和Soccer Play數據集上,PL-EKT算法劣于PL-ECOC算法,優于其他算法。
PL-EKT偏標記學習算法在2組UCI人工數據集和4組真實數據集上都具有較好的表現力。從整體上看,PL-EKT算法在UCI數據集中比其他算法分類精度高,且魯棒性相對較好;在真實數據集上,PL-EKT算法相比于其他算法也擁有較好的效果,僅在Birdsong數據集上劣于PL-ECOC算法。
4 結束語
為了充分利用候選標記來劃分樣本,提出了KD樹集成偏標記學習算法,通過KD樹均衡訓練集,使得偏標記學習算法有較好的泛化性能。實驗結果表明,該算法在真實數據集上有較好的表現。但同時也存在一些不足的地方,在UCI數據集Glass上算法的魯棒性不夠,劃分子數據集仍會存在樣本均衡的問題等,有待進一步改進。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
