基于神經網絡的口碑商家推薦
2019-06-01 05:54:30楊楚珺胡哲
現代計算機 2019年12期
關鍵詞:用戶
楊楚珺,胡哲
(西南大學計算機信息與科學學院,重慶 400715)
介紹推薦系統在口碑平臺的應用。在提取用戶特性和時間特性以及商家特性的基礎上,使用BP 神經網絡給用戶推薦商家,同時對比BP 神經網絡中單隱層和雙隱層的效果區別。對有線上記錄的用戶使用協同過濾進行推薦,對于無線上記錄的新用戶由于沒有淘寶購物記錄,無法判斷其愛好,所以從商家特性進行分析并推薦給新用戶。
BP 神經網絡;推薦系統;協同過濾
0 引言
隨著智能手機的普及,基于位置的服務也進入了日常生活,人們會在使用滴滴打車、高德地圖、美團外賣等App 上面共享自己的位置。因此,大量的用戶數據積累下來,打開了機器學習/數據挖掘的大門。在這次本賽中,需要研究線上和線下的相關性偏好用于推薦就近商店。阿里巴巴提供了淘寶和天貓的線上購物數據,螞蟻金服提供了支付寶的口碑中的線下數據。同時享受了這兩項服務的用戶擁有同樣的用戶ID。淘寶和天貓的線上數據擁有大量的用戶數據,但口碑才上線五個月,所以用戶數據較少。
淘寶和天貓的線上數據能夠加強口碑的線下推薦準確度。Zheng 等人和Bao 等人[2]使用用戶歷史地理位置來幫助構建社交網絡。Liao[3]和Zheng 等人[4]使用GPS 數據模擬人類行為模式,并預測人類活動,推薦本地服務。
本數據集中,口碑線下商家有五個月的歷史記錄,涉及到冷啟動問題。冷啟動是推薦系統最常見且最大的挑戰。已經有很多研究員在這個問題上做了大量研究。Zhou 等人[5]通過使用基于用戶的協同過濾的決策樹預測新用戶偏好,Liu 等人[6]使用現有用戶的線性組合來近似新用戶的行為。還可以利用其他來源中的用戶信息來處理冷啟動的問題。Lin 等人[7]通過社交網絡的用戶信息解決了App 推薦的冷啟動問題。并且應用潛在因素模型來處理冷啟動問題。用戶特征被投影到降維空間中,這個降維空間可以找到用戶相似度最有效的表示[8]。適用于冷啟動解的潛在因素模型包括主成分分析[9],限制波爾茨曼機制[10]和奇異矢量分解[11]。
由于口碑只有從上線開始的五個月的記錄,大量的新用戶和新商家的加入造成了冷啟動問題。這里,將用戶群分成三類:有淘寶購物記錄的新用戶、無淘寶購物記錄的新用戶、有口碑記錄的老用戶。線下購買行為能夠從以前的記錄中得到,也可以由線上購物記錄推測而來。數據集的典型特征和分析,以及相關算法如下。
1 數據分析
本文主要的目標在解決兩個推薦問題,一個是冷啟動問題,一個是實體店的人流量控制問題。
首先,由于口碑只有五個月的銷售記錄,并且是剛上線的五個月的銷售記錄,每個月都會出現很多新用戶和新商家。要給這些用戶推薦好的商家就成了一個棘手的難題,不過,這里還給出了這五個月來口碑中一部分用戶的淘寶購物記錄。我們可以通過淘寶記錄上的用戶偏好來給口碑用戶進行推薦。
然后,是每個商家的人流量問題,雖然店主都希望人越多越好,但從用戶角度看,人多就會造成等待時間過長這個問題,每個商家每天能接待的客戶都是有限的。由于沒有十二月份的評測數據集,并且口碑上線時間短,每個地點用戶基數不大,人流量問題不予考慮。
本文使用的四個數據集,分為:淘寶數據集、口碑訓練數據集、商家數據集和測試數據集。
第一個是淘寶線上購物記錄集。淘寶集共有44528127 條數據,用戶ID 最大為2063701,包含用戶963823 名、店鋪一萬家。淘寶集是用戶某一天在淘寶上瀏覽或者購買的記錄。
第二個是口碑訓練集,口碑集共有1081724 條數據,用戶ID 最大為2063695,包含用戶230496 名、店鋪5910 家(不包含連鎖店數量),商家ID 號為1 到9999。口碑集是用戶某一天在口碑上的購買記錄。
第三個是商家信息集,商家集共有5910 條數據,商家ID 最大為9999。商家集是口碑七月份到十二月份上線的所有商家。
第四個是測試集,有數據473533 條,是十二月會消費的用戶會去哪些地方的數據集,競賽要求是要按照這個集合進行商家推薦。
2 推薦系統
因為口碑的商家中存在新商家,用戶也存在新用戶,所以此處將用戶集分為:無淘寶購物記錄的新用戶、有淘寶購物記錄的新用戶和老用戶。針對不同的集合采用不同的方法。
無淘寶購物記錄的新用戶有90602 名,有淘寶購物記錄的新用戶有330609 名,老用戶有52322 名,對于不同的用戶組采用不同的方法。
2.1 老用戶
由于沒有十二月份的口碑記錄,無法判斷最后結果好壞,所以先針對老用戶,將口碑集中前五個月的特征提取出來,得到訓練集,并從訓練集中取95%作為訓練數據,5%作為測試數據。由于在大多數地點,商家數量較少,如圖1 所示,大部分地區的商家數量為0-10,基于項目的協同過濾方法不適用于這里。
采用BP 神經網絡,雙隱含層,每層十個神經元。對于每一個用戶-商家-地點組,統計用戶特性,時間特性和商家特性,用戶特性包括是否去過那家店,去的總次數,去的可能性,在線購買總量。時間特性包括最近一次購買時間,是否最后一次購物商家,第一次購買時間。商家特性有,與這家店最相似的兩家商家id,去過沒,購買可能性,地點商家總量。特征表如表1 所示。特征集包含數據30 多萬條。
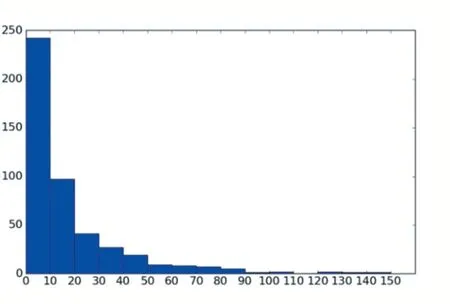
圖1 商家數量
BP 算法具體內容如下:
(1)輸入模式是由輸入層經過隱含層向輸出層逐層傳播的“模式順傳播”過程。
(2)網絡的期望輸出與實際輸出之差,即誤差信號,是由輸出層經隱含層向輸入層逐層修正連接權值的“誤差逆傳播”過程。
(3)由“模式順傳播”過程和“誤差逆傳播”過程反復交替進行的網絡“記憶訓練”過程。
(4)網絡趨向收斂,即網絡的全局誤差趨向極小值的“學習收斂”過程
BP 神經網絡的主要能力有非線性映射能力、泛化能力和容錯能力。
(1)非線性映射能力:無需事先了解輸入輸出模式之間的映射關系,只要能夠為BP 神經網絡提供足夠多的輸入輸出樣本模式供其進行學習訓練,BP 神經網絡就能夠學習并存儲大量的輸入輸出模式映射關系,就能夠完成由n 維輸入空間到m 維輸出空間的非線性映射。

表1 特征表
(2)泛化能力:BP 神經網絡學習訓練完成后會將所提取的樣本模式對中的非線性映射關系存儲在網絡連接權向量中,因此,在其后的正常工作階段,當向BP神經網絡輸入訓練時未曾見過的數據時,BP 神經網絡也能夠完成由輸入模式到輸出模式的正確映射。BP神經網絡的泛化能力是衡量BP 神經網絡性能優劣的一個重要因素。
(3)容錯能力:BP 神經網絡的另外一個重要能力,也是人工神經網絡的重要特點之一,是容錯能力,即允許輸入模式及樣本中存在較大的誤差,甚至允許出現錯誤。這時,因為連接權向量的調整過程是從大量的樣本模式對中提取的統計特性的過程,而反映正確規律的只是來自于全體樣本模式,所以個別樣本中存在的誤差不能影響對連接權向量的正確調整。
采用BP 神經網絡的方法以特征集為輸入,輸出為這個用戶下一次會光顧的商家id,迭代100 次,使用MATLAB 自帶的神經網絡工具箱。
迭代一百次以后,訓練集最穩定表現如圖2 所示。
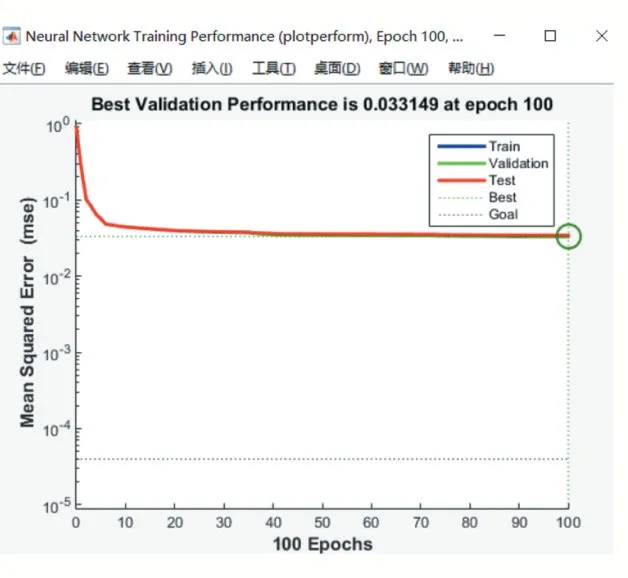
圖2 訓練效果
迭代100 次的BP 網絡預測誤差如圖3 所示,綠色圓圈為預測輸出,藍色星號為期望輸出。從圖中可以看出存在離群點,這可能是用戶嘗試了新的店。圖4是BP 網絡的預測誤差,雖然有很多誤差較大的輸出,但是可以看到有很多點是在0 周圍。
誤差在一定范圍內是允許的,計算預測準確率有0.7130。同樣的訓練集,只用一層隱含層。使用同樣的訓練集、測試集,單隱含層的計算預測準確率有0.2364。
為防止過擬合的情況,這里我們計算了十次雙隱含層和單隱含層的訓練情況,如圖5 所示,僅有兩次情況,單隱含層與雙隱含層準確度類似,80%的情況下雙隱含層的結果好于單隱含層。
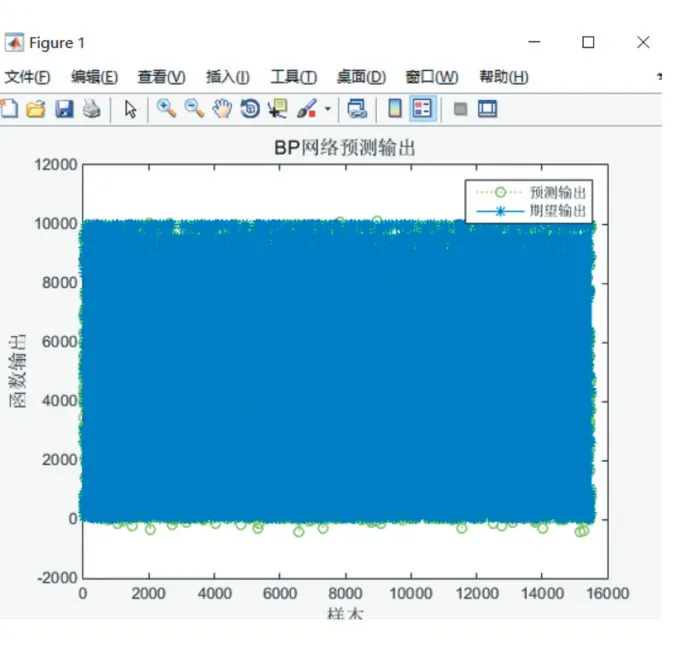
圖3 BP神經網絡預測輸出

圖4 BP網絡預測誤差
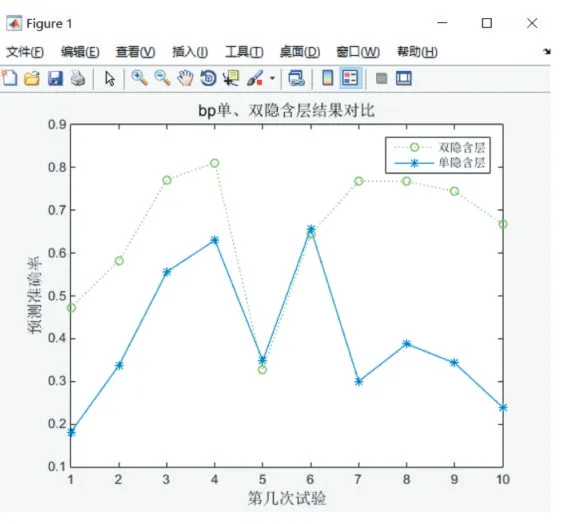
圖5 BP單、雙隱含層結果對比
2.2 無淘寶記錄的新用戶
對于沒有淘寶線上購物記錄和口碑線下購物記錄,亦即沒有任何用戶偏好特性的用戶群來說,無法從用戶角度給用戶推薦商家,只能從商家角度出發,給用戶推薦商家。這里,我們提取了商家的相關特性:商家連鎖店數量、商家銷售記錄、商家預算、商家第一次銷售記錄時間、商家最后一次銷售記錄時間和商家營業時間。
主要特征為商家ID,商家連鎖店數量,商家銷售記錄,商家營業時間,商家第一次銷售記錄時間,可以默認為商家上線時間,商家最近一次銷售記錄時間。然后計算商家與商家之間的Pearson 相關系數。為了統計商家特性,本文還根據地點的銷售數量、商店數量、連鎖店數量這三類分出了最熱門區域,次熱門區域以及冷門區域。
區域主要特征為最熱門區域,次熱門區域,冷門區域。根據這個圖我們給用戶推薦在熱門區域有連鎖店的商家。但是由于沒有官方的對比數據無從得知最后結果如何,因此這里只說明采用的方法,沒有最后的結果比對。
2.3 有淘寶購物記錄的新用戶
對于有淘寶記錄的新用戶,這里可以借用這個用戶線上購物偏好特性給這位用戶進行線下推薦。由于淘寶的記錄是每個用戶在每家店的購物記錄,而不是評分記錄,所以此處統計淘寶集中每個用戶在每家店的購物次數,以用戶標號為行,商家標號為列,形成用戶評分矩陣,計算每個用戶的平均評分,沒有購物記錄的不列入平均評分計算中。然后計算每個用戶的Pearson 相關系數,找出前N 個最相似的用戶,找出這前N 個用戶中有口碑購物記錄的用戶,統計這些用戶最經常去的商家,然后選出top10 推薦給新用戶。
3 結語
本文首先采用協同過濾對數據集進行分類,此方法對于商家推薦卓有成效。另外選用了兩種方法進行比較,在BP 神經網絡算法中,根據針對老用戶集進行推薦的比較結果來看,雙隱含層要優于單隱含層。
后續改進,研究采用代價函數是否為交叉熵的優缺點進行推薦,同時調節BP 神經網絡中神經元的個數,比較對最后結果造成的影響。
猜你喜歡
車主之友(2022年4期)2022-08-27 00:58:26
知音·下半月(2022年5期)2022-05-23 23:17:04
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年5期)2016-11-28 09:55:15
非公有制企業黨建(2016年1期)2016-07-19 13:02:51
商用汽車(2016年6期)2016-06-29 09:18:54
商用汽車(2016年4期)2016-05-09 01:23:12
衛星與網絡(2016年12期)2016-02-05 09:23:23
創業家(2015年10期)2015-02-27 07:55:08
創業家(2015年10期)2015-02-27 07:54:39
