基于Sentinel-2A影像的縣域冬小麥種植面積遙感監(jiān)測
2019-06-01 02:23:42馮美臣楊武德張美俊
山西農(nóng)業(yè)科學(xué) 2019年5期
王 蓉,馮美臣,楊武德,張美俊
(1.山西農(nóng)業(yè)大學(xué)資源環(huán)境學(xué)院,山西 太谷 030801;2.山西農(nóng)業(yè)大學(xué)農(nóng)學(xué)院,山西 太谷 030801)
遙感是獲取作物播種信息的關(guān)鍵技術(shù),在農(nóng)情監(jiān)測領(lǐng)域具有對(duì)地表信息獲取的覆蓋面廣、信息量大、周期短、受地面條件限制少、調(diào)查成本相對(duì)較低等明顯優(yōu)勢[1]。在農(nóng)作物遙感估產(chǎn)中,農(nóng)作物種植面積的遙感估算是農(nóng)作物產(chǎn)量預(yù)測的基礎(chǔ)和主要內(nèi)容;準(zhǔn)確而及時(shí)的農(nóng)作物類型及其空間分布更新信息是優(yōu)化種植結(jié)構(gòu)的基本依據(jù),為制定合理、有效的糧食宏觀調(diào)控措施、保證國家糧食安全提供科學(xué)支撐[2]。
農(nóng)作物遙感識(shí)別分類與面積提取的研究主要考慮遙感數(shù)據(jù)源、特征變量和分類算法[3]3 個(gè)方面。到目前為止,適合開展大范圍高空間分辨率農(nóng)作物種植區(qū)域識(shí)別與提取的遙感數(shù)據(jù)源主要有GF-1,Sentinel-2 和Landsat-8。田海峰等[4]使用多景GF-1全色多光譜(Pan Multiple Spectral,PMS)影像,對(duì)河南省滑縣冬小麥種植分布信息進(jìn)行了提取研究,并取得良好效果。BELGIU 等[5]采用Sentinel-2 多光譜傳感器(Multi Spectral Sensor,MSI)數(shù)據(jù),對(duì)時(shí)間加權(quán)動(dòng)態(tài)時(shí)間規(guī)整(Time-Weighted Dynamic Time Warping,TWDTW)算法在農(nóng)作物分類的應(yīng)用效果進(jìn)行研究。ZHANG 等[6]提出利用 Landsat-8 OLI 時(shí)間序列和物候參數(shù)的融合數(shù)據(jù),在多云雨地區(qū)提取水稻種植面積。與MODIS 數(shù)據(jù)相比,GF-1,Sentinel-2 和Landsat-8 等影像數(shù)據(jù)具有高空間分辨率和高時(shí)間分辨率的雙重優(yōu)勢,并在一定程度上減少了混合像元對(duì)作物分類結(jié)果的干擾,提高了農(nóng)作物分類制圖精度與效率。
遙感光譜數(shù)據(jù)及其衍生的各種指數(shù)信息、紋理特征、時(shí)間序列閾值和變化信息常被國內(nèi)外學(xué)者用作研究農(nóng)作物遙感分類的特征變量。其中,光譜及其衍生指數(shù)的信息相對(duì)容易獲得也是最常用的[3]。SONOBE 等[7]在研究Sentinel-2A 多光譜傳感器數(shù)據(jù)計(jì)算植被指數(shù)的潛力中發(fā)現(xiàn),植被指數(shù)在確定特定作物類型方面貢獻(xiàn)最大。史飛飛等[8]采用多源數(shù)據(jù)集進(jìn)行了農(nóng)作物分類信息提取研究,發(fā)現(xiàn)在NDVI 時(shí)間序列數(shù)據(jù)中融入高光譜數(shù)據(jù)可以提高分類精度。紋理信息作為區(qū)分特征,對(duì)高分辨率(米級(jí)或亞米級(jí)以下)影像數(shù)據(jù)的分類效果較好[9]。CHUANG等[10]將主成分、灰度共生矩陣紋理信息作為分類器的輸入變量,解譯出臺(tái)灣中部地區(qū)茶葉種植區(qū)域。
另外,選擇不同的算法對(duì)農(nóng)作物面積的提取也有著較大的影響。隨機(jī)森林(Random Forest,RF)方法由于2 個(gè)隨機(jī)性(隨機(jī)且有放回地抽樣訓(xùn)練集、隨機(jī)地從樣本特征維度中選取特征子集)的引入,在分類中不易陷入過擬合,具有分類精度高、泛化能力強(qiáng)、數(shù)據(jù)挖掘能力優(yōu)異、抗噪聲能力良好等優(yōu)點(diǎn),對(duì)處理樣本數(shù)據(jù)分布不平衡等方面表現(xiàn)優(yōu)良,成為當(dāng)前機(jī)器學(xué)習(xí)領(lǐng)域的研究熱點(diǎn)[2]。GAO 等[11]研究探討了新型高光譜快照馬賽克相機(jī)在雜草和玉米分類方面的潛力,發(fā)現(xiàn)RF 模型表現(xiàn)總體上優(yōu)于K-最近鄰(K-Nearest Neighbor,K-NN)模型。
以上研究都不同程度提高了作物識(shí)別精度,但綜合數(shù)字高程模型、遙感影像數(shù)據(jù)及其衍生的植被指數(shù)信息、紋理特征,利用單時(shí)相遙感影像進(jìn)行雨養(yǎng)區(qū)冬小麥與灌溉區(qū)冬小麥空間分布信息提取方面的研究少有報(bào)道。
筆者在前人研究的基礎(chǔ)上,利用冬小麥生長關(guān)鍵期的Sentinel-2A 遙感影像數(shù)據(jù),選擇紅邊歸一化植被指數(shù)、主成分分量與幾何紋理特征作為特征變量,研究基于隨機(jī)森林算法的冬小麥種植面積提取方法,并結(jié)合DEM 數(shù)據(jù)實(shí)現(xiàn)雨養(yǎng)區(qū)和灌溉區(qū)冬小麥的分類,以期為不同灌溉類型冬小麥長勢遙感監(jiān)測以及產(chǎn)量估測提供科學(xué)依據(jù)。
1 材料和方法
1.1 研究區(qū)概況
研究區(qū)位于山西省運(yùn)城市北部的聞喜縣,總面積 1 167.1 km2,地理坐標(biāo)為 110°59′33″~111°37′29″E,35°9′38″~35°34′11″N。聞喜縣地處運(yùn)城盆地與臨汾盆地的交界處,地形多樣,河谷、塬地、丘陵、山地共存。氣候?qū)倥瘻貛Т箨懶约撅L(fēng)氣候,晝夜溫差大,四季分明。農(nóng)作物以冬小麥種植為主,屬南部冬麥區(qū)。
1.2 數(shù)據(jù)來源
1.2.1 Sentinel-2A 影像數(shù)據(jù) Sentinel-2A 的多光譜成像儀含有13 個(gè)通道,主要應(yīng)用于地表覆蓋變化監(jiān)測、資源調(diào)查、近海域污染檢測、災(zāi)害監(jiān)測等,波段信息如表1所示。結(jié)合運(yùn)城地區(qū)冬小麥與其他作物主要生育期,為有效提取冬小麥種植面積[12],選擇使用2018年3月27日獲取的上層大氣反射的L1C 級(jí)別的Sentinel-2A 數(shù)據(jù)。
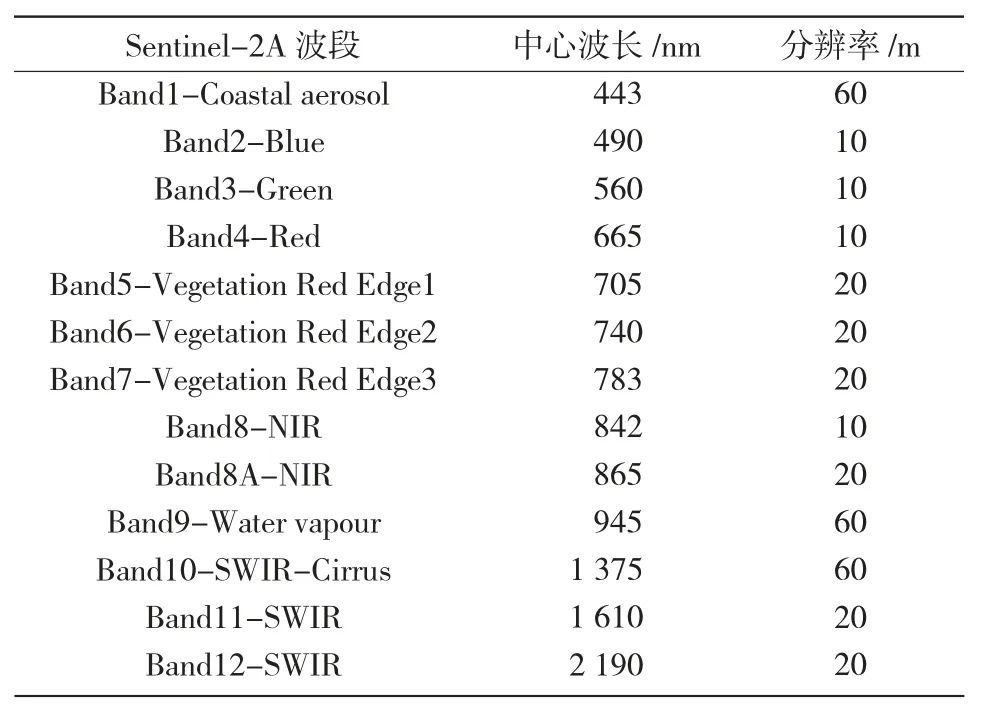
表1 Sentinel-2A 波段信息
1.2.2 地面調(diào)查 為獲取山西省運(yùn)城市聞喜縣冬小麥的分布情況,2018年3月進(jìn)行了實(shí)地調(diào)查。野外調(diào)查時(shí)采用手持GPS 獲取冬小麥的經(jīng)緯度信息,調(diào)查路線覆蓋聞喜縣絕大部分鄉(xiāng)鎮(zhèn)(石門鄉(xiāng)除外)。在野外調(diào)查GPS 數(shù)據(jù)基礎(chǔ)上,結(jié)合目視解譯方法,確定訓(xùn)練樣本數(shù)據(jù)集和驗(yàn)證樣本數(shù)據(jù)集。
1.3 研究方法
1.3.1 數(shù)據(jù)預(yù)處理 數(shù)據(jù)下載自歐洲航空局的數(shù)據(jù)共享網(wǎng)站(http://scihub.copernicus.du/s2/#/home)。原始數(shù)據(jù)已進(jìn)行過幾何校正處理,由于處理前各波段分辨率不同,因此,使用三次卷積內(nèi)插法對(duì)各波段(不包括 Band1,Band8,Band9,Band10)進(jìn)行重采樣,經(jīng)處理后的各波段分辨率為20 m。
1.3.2 隨機(jī)森林分類算法 其通過對(duì)數(shù)據(jù)及特征變量進(jìn)行隨機(jī)重采樣,構(gòu)建多個(gè)CART 決策樹(不剪枝),最終采用多決策樹投票的方式確定數(shù)據(jù)的類別歸屬。它能夠處理具有高維特征的輸入樣本,又對(duì)過度擬合不敏感[13],在生成的過程中就可以對(duì)誤差建立一個(gè)無偏估計(jì)。因而,對(duì)于遙感影像農(nóng)作物面積提取具有很好的抗噪性能,在農(nóng)田制圖研究方面取得了有效的分類結(jié)果[14-15]。
1.3.3 特征變量的選擇
1.3.3.1 主成分分析 主成分分析(Principal component analysis,PCA)又稱 K-L 變換,利用波段間的相互關(guān)系,在盡可能不丟失信息的條件下,用幾個(gè)綜合性波段代表多波段的原圖像,使處理的數(shù)據(jù)量減少。
1.3.3.2 植被指數(shù) 本研究選擇窄帶綠度植被指數(shù)(Narrowband greenness)中的紅邊歸一化植被指數(shù)(Red Edge Normalized Difference Vegetation Index,RENDVI)[16]。其計(jì)算公式如下。
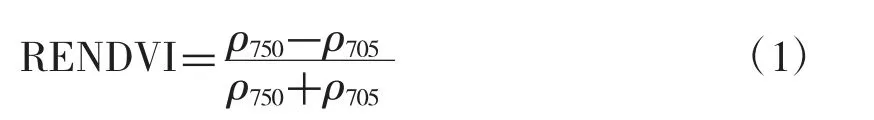
式中,ρ705和 ρ750分別對(duì)應(yīng)表2中的 Band5 和Band6 的反射率,RENDVI 值的范圍是 -1~1,一般綠色植被區(qū)的范圍是0.2~0.9。
1.3.3.3 紋理特征 紋理是指圖像色調(diào)作為等級(jí)函數(shù)在空間上的變化[17]。由HARALICK 提出的灰度共生矩陣(GLCM)方法是公認(rèn)的紋理特征提取的有效方法,具有較強(qiáng)的適應(yīng)能力和魯棒性[18]。該方法首先計(jì)算圖像的GLCM,然后由GLCM 導(dǎo)出描述紋理的二階統(tǒng)計(jì)特征[19]。在合適的空間分辨率遙感影像中,農(nóng)作物區(qū)別于其他地物具有更為鮮明的空間紋理特征[20]。因此,加入紋理特征,有利于冬小麥分布區(qū)域的準(zhǔn)確提取。
1.3.4 基于DEM 的地形分析 數(shù)字地面模型(Digiatl Terrain Model,DTM)中地形屬性為高程時(shí)稱為數(shù)字高程模型(Digital Elveatoin Model,DEM)。數(shù)字高程模型是指描述地球表面形態(tài)多種信息空間分布的有序數(shù)值陣列。根據(jù)文獻(xiàn)[21],本研究采用三次卷積方法對(duì)研究區(qū)DEM 數(shù)據(jù)進(jìn)行重新采樣,以減少精度損失。
1.3.5 精度評(píng)價(jià)方法 基于地面樣點(diǎn)數(shù)據(jù)驗(yàn)證是精度驗(yàn)證的主要手段之一,也是說明分類結(jié)果準(zhǔn)確程度的指標(biāo)之一。本研究以Kappa 系數(shù)、總體精度、制圖精度、用戶精度等4 項(xiàng)指標(biāo)表述基于地面樣點(diǎn)數(shù)據(jù)精度驗(yàn)證結(jié)果[22]。此外,由于區(qū)域冬小麥提取面積在產(chǎn)量估產(chǎn)中具有重要作用,因此,同樣需要評(píng)價(jià)冬小麥面積提取值與實(shí)際冬小麥面積值之間的比值。
2 結(jié)果與分析
2.1 特征變量的選擇
2.1.1 波段數(shù)據(jù)的統(tǒng)計(jì)特征分析 從表2可以看出,B8A 波段標(biāo)準(zhǔn)差(1 247.058 207)為所有波段中最大,其次是B11 波段、B7 波段,標(biāo)準(zhǔn)差分別為1 235.138 932 和1 155.616 279。標(biāo)準(zhǔn)差最大,說明該波段內(nèi)地物的亮度取值距均值的離散程度最大,即地物間的差異可能表現(xiàn)最明顯,信息量最豐富。因此,B8A 波段包含的信息量最豐富,同時(shí)也進(jìn)一步表明原始影像的B8A 波段在植被類型分類中具有顯著作用。
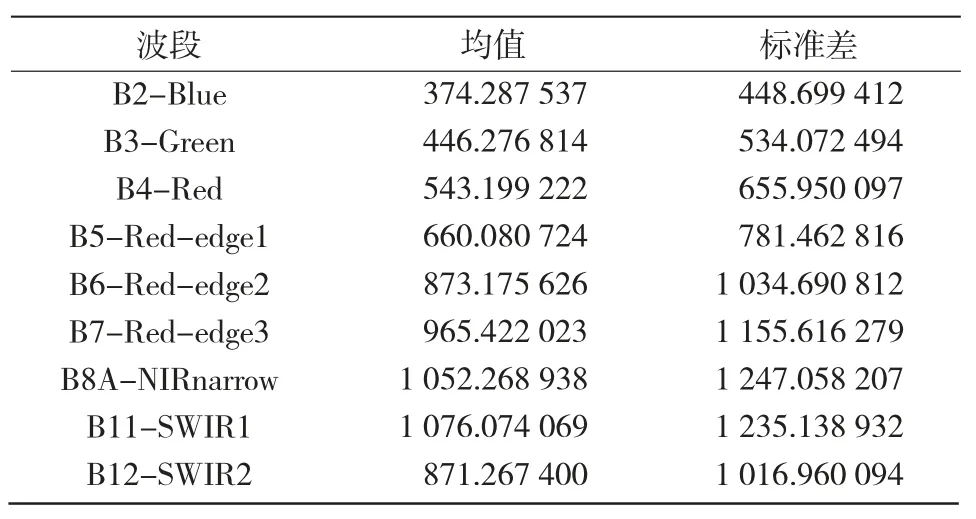
表2 原始影像波段基本信息量
2.1.2 主成分分析 從表3可以看出,第1 主成分分量(PC1)的信息占9 個(gè)波段總信息量的97.3%,第2 主成分占總信息量的2.23%,第3 主成分占總信息量的0.38%,前3 個(gè)主成分共占據(jù)了99.91%的信息量,其他成分對(duì)于影像信息只是噪音,所以,前3 個(gè)成分可以代表原始影像的數(shù)據(jù)信息。在構(gòu)成第1 主成分的向量中,B8A 最高(為 0.44),占各波段特征向量和的15.3%。這說明第1 主成分中,B8A波段的貢獻(xiàn)最大,其次是B11(14.6%) 和B7(14.2%),說明在原始影像的9 個(gè)波段中,B8A 波段包含的地物信息量最豐富。
2.1.3 波段間相關(guān)性分析 從表4可以看出,B8A與B7 波段間相關(guān)系數(shù)最高(r=0.999 4),其次是與B6 波段(r=0.997 4) 和 B5 波段(r=0.959 5),與B11 波段的相關(guān)系數(shù)為0.958 2。說明B8A 波段與這些波段數(shù)據(jù)彼此重疊較多。
2.1.4 特征變量選擇結(jié)果 選用B8A 波段作為專門提取紋理特征的波段,經(jīng)多次試驗(yàn)對(duì)比分析,選用3 多3 大小的移動(dòng)窗口,利用灰度共生矩陣計(jì)算該波段的8 種紋理特征:均值、方差、同質(zhì)性、對(duì)比度、差異性、熵(Entropy)、二階矩、相關(guān)性。
綜上所述,本研究提取3 類特征波段:紅邊歸一化植被指數(shù)(RENDVI)、主成分變換前3 個(gè)分量以及原始影像B8A 波段的紋理特征,共計(jì)12 個(gè)變量。各變量具體信息列于表5。
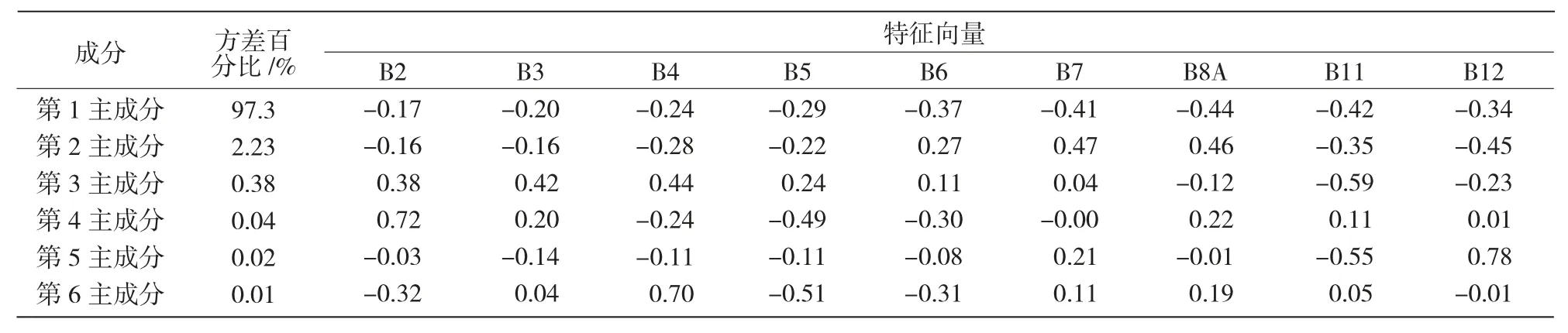
表3 研究區(qū)Sentinel-2A 各波段主成分分析結(jié)果
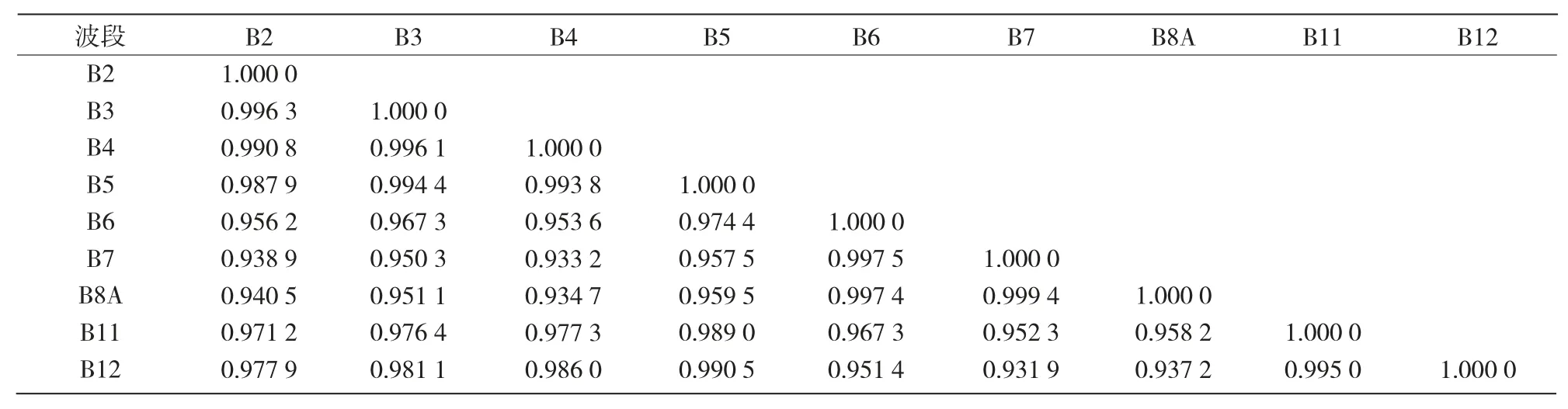
表4 研究區(qū)Sentinel-2A 各波段數(shù)據(jù)相關(guān)分析結(jié)果

表5 用于分類的特征變量信息
2.2 基于特征波段與隨機(jī)森林的冬小麥種植面積提取結(jié)果
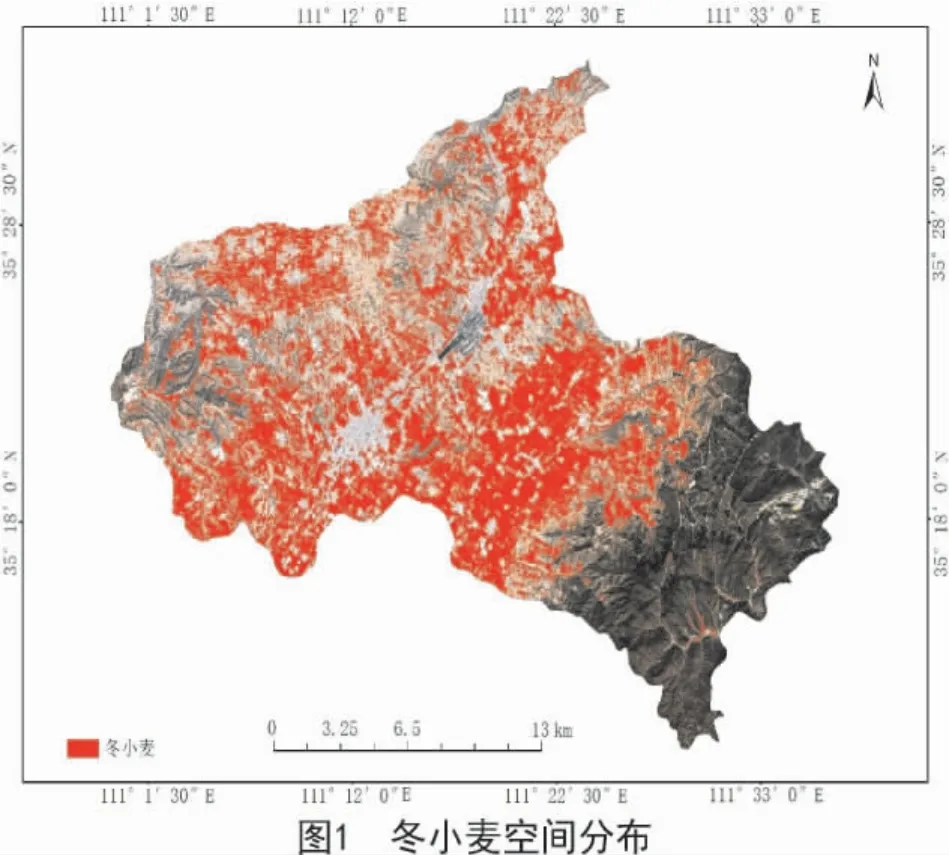
將 2018年3月27日的 Sentinel-2A 影像輸入到隨機(jī)森林分類器[23]中,將前 3 個(gè)主成分(PC1,PC2,PC3)、紅邊歸一化植被指數(shù)(RENDVI)和 B8A 波段紋理特征組合進(jìn)行分類提取,獲得聞喜縣冬小麥種植面積空間分布(圖1)。由圖1可知,冬小麥主要分布在中部地區(qū),北部有少量種植分布,原因?yàn)槁勏部h地處運(yùn)城盆地與臨汾盆地的交界夾槽處,三面環(huán)山,地勢西北、東南高,中間低,冬小麥適宜生長在地形平坦地區(qū),林地等非冬小麥植被主要分布在東南山地;另外,由于丘陵塬地遍布縣境,冬小麥在西北部分布較為零散,這與實(shí)地調(diào)查情況相符。
2.2.1 特征波段對(duì)分類精度的影響 由表6可知,未加入特征波段,采用原始影像波段作為隨機(jī)森林分類器的輸入數(shù)據(jù),分類結(jié)果的總體精度為94.72%,Kappa 系數(shù)為0.92;采用3 項(xiàng)特征波段后,分類結(jié)果的總體精度增加了3.39 百分點(diǎn),Kappa 系數(shù)增加了0.05,這與分類結(jié)果(圖1)表現(xiàn)一致,說明綜合主成分分析、紅邊歸一化植被指數(shù)以及紋理特征后能提高遙感影像分類總體精度,同時(shí)冬小麥的分類用戶精度由87.91%提升到92.22%,說明引入特征波段有助于提高冬小麥種植面積提取的可信度。
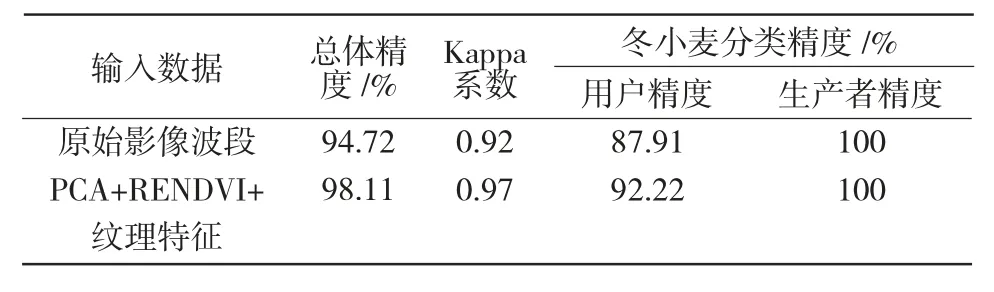
表6 隨機(jī)森林算法條件下原始影像波段與特征波段分類精度對(duì)比
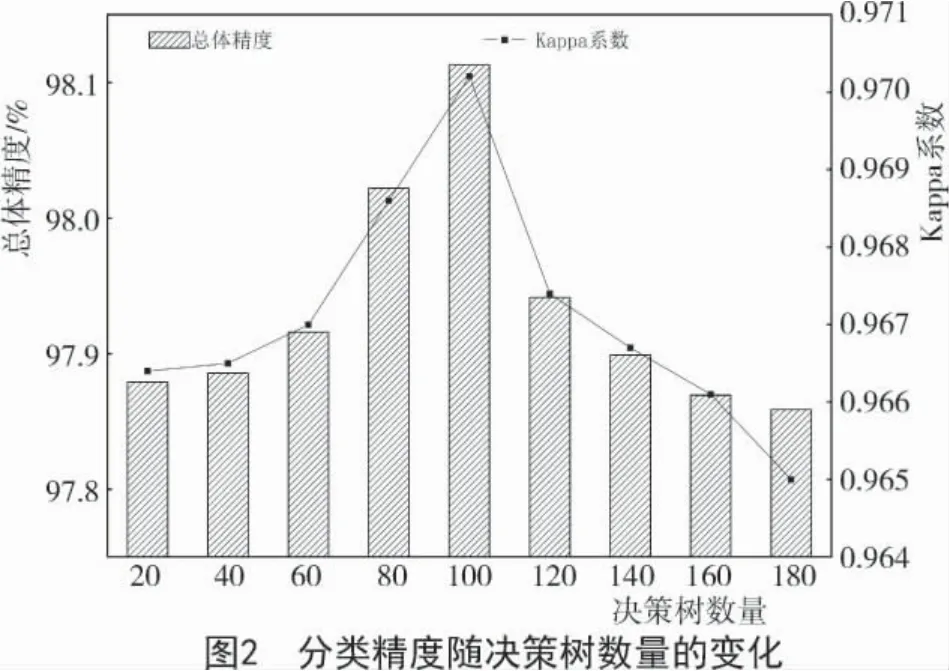
2.2.2 決策樹和特征變量的數(shù)量對(duì)精度的影響考慮到在隨機(jī)森林分類過程中,決策樹和特征變量的數(shù)量可能影響最終分類的精度,需研究決策樹和特征變量的數(shù)量對(duì)分類精度的影響。特征變量的數(shù)量對(duì)分類精度的影響甚微可忽略不計(jì),即分類精度對(duì)特征變量數(shù)量的設(shè)置并不敏感[24]。因此,本研究僅分析決策樹的數(shù)量對(duì)分類精度的影響。由圖2可知,當(dāng)保持特征變量數(shù)量不變時(shí),將決策樹的數(shù)量分別設(shè)定為20,40,60,80,100,120,140,160,180進(jìn)行試驗(yàn),得到的分類精度隨決策樹數(shù)量變化而改變。由圖2可知,在20~100 的范圍內(nèi),當(dāng)決策樹數(shù)量增加,分類精度隨之增加,并且在決策樹數(shù)量為100 時(shí)分類精度達(dá)到最大值;當(dāng)決策樹數(shù)量超過100 時(shí),分類精度隨決策樹數(shù)量的增加而出現(xiàn)降低趨勢,且隨著決策樹數(shù)量增加,模型訓(xùn)練時(shí)間也在增加。
2.3 不同分類方法分類結(jié)果對(duì)比
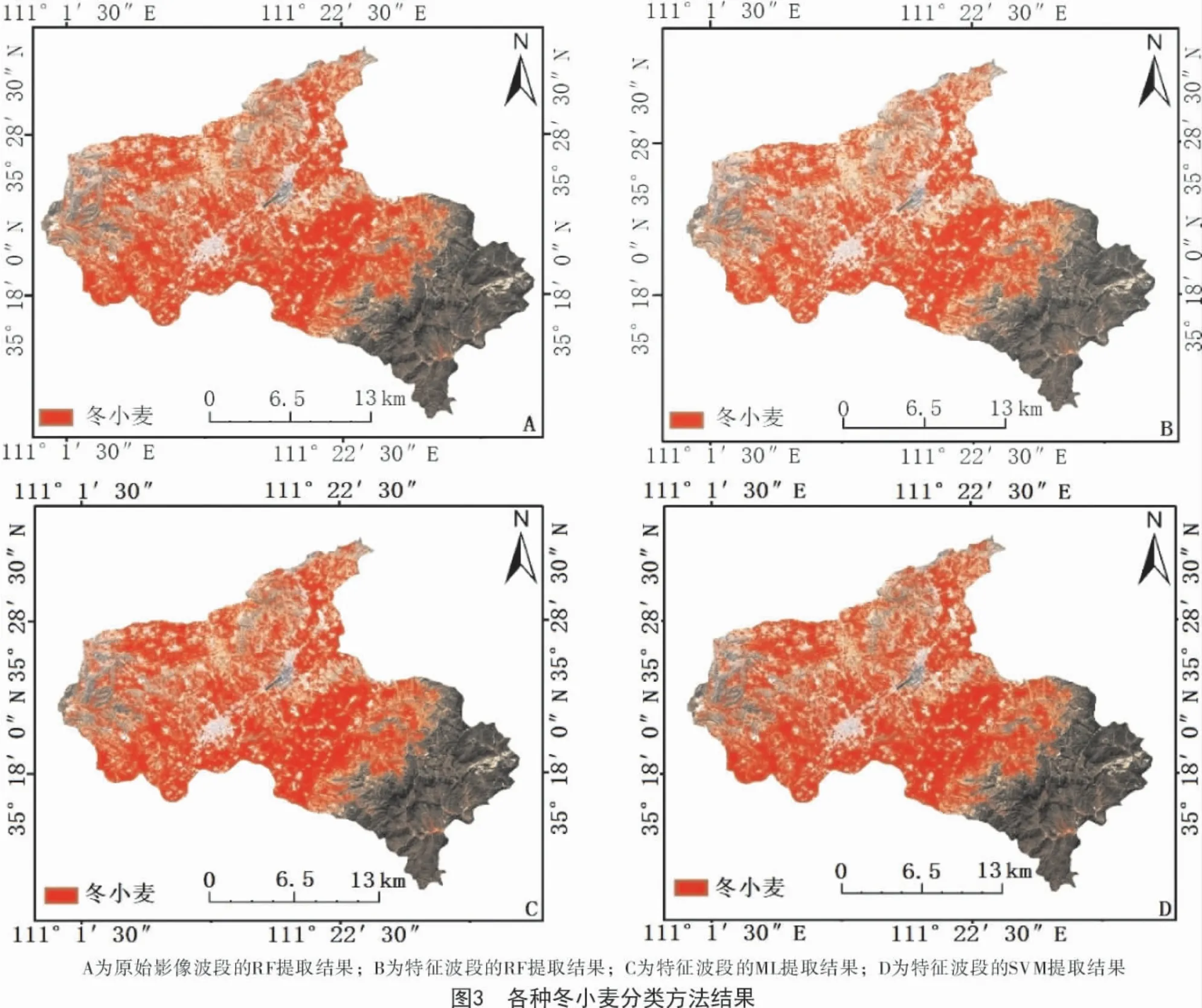
為進(jìn)一步驗(yàn)證本研究所采用的隨機(jī)森林分類方法的有效性,利用實(shí)地調(diào)查點(diǎn)信息將隨機(jī)森林算法分類結(jié)果與支持向量機(jī)算法、最大似然算法進(jìn)行對(duì)比分析(圖3)。
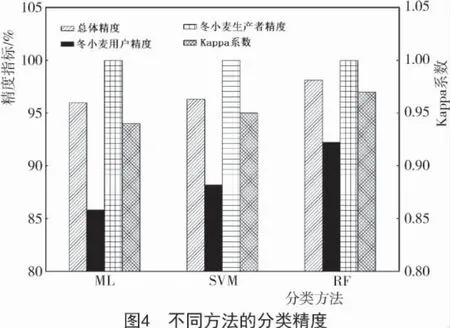
從圖3可以看出,隨機(jī)森林算法(RF)、最大似然算法(ML)和支持向量機(jī)算法(SVM)分類結(jié)果在空間分布上大致趨于一致,但隨機(jī)森林算法分出的冬小麥地塊較為完整,且能分出絕大部分冬小麥種植區(qū)域,其分類總體精度和Kappa 系數(shù)均最高,分別為98.11%和0.97(圖4),其次是支持向量機(jī)算法(總體精度和Kappa 系數(shù)分別為96.3%和0.95),最大似然算法最差。這是由于最大似然算法分類器基于統(tǒng)計(jì)算法,計(jì)算給定像元屬于某一訓(xùn)練樣本的似然度,根據(jù)似然度將像元?dú)w并到似然度最大的一類當(dāng)中,而在3月下旬聞喜縣冬小麥與蔬菜的光譜特征容易混淆,增大了利用似然度劃分地物像元的難度。支持向量機(jī)分類是一種建立在統(tǒng)計(jì)學(xué)習(xí)理論基礎(chǔ)上的機(jī)器學(xué)習(xí)方法,可以自動(dòng)尋找那些對(duì)分類有較大區(qū)分能力的支持向量,由此構(gòu)造出分類器,可以將類與類之間的間隔最大化,因而較最大似然法有更高的分類準(zhǔn)確率,但是蔬菜與冬小麥的混淆光譜仍對(duì)其有一定的影響。而隨機(jī)森林算法通過對(duì)數(shù)據(jù)及特征變量進(jìn)行隨機(jī)重采樣,采用多決策樹投票的方式確定數(shù)據(jù)的類別歸屬,在生成過程中就可以對(duì)誤差進(jìn)行一個(gè)無偏估計(jì),因此,其可信度最高,為92.22%。黃健熙等[25]使用MODIS 數(shù)據(jù)對(duì)黑龍江省主要農(nóng)作物的種植面積提取進(jìn)行研究,發(fā)現(xiàn)SVM算法分類精度優(yōu)于RF,ML 算法的分類精度,這可能是由于MODIS 數(shù)據(jù)空間分辨率低,混合像元效應(yīng)明顯,導(dǎo)致每棵決策樹的分類能力降低,而森林的分類效果(錯(cuò)誤率)與每棵樹的分類能力有關(guān);本研究中Sentinel-2A 數(shù)據(jù)空間分辨率明顯優(yōu)于MODIS 數(shù)據(jù),故RF 算法分類效果最佳。
2.4 雨養(yǎng)區(qū)與灌溉區(qū)冬小麥分類結(jié)果
由于不同灌溉條件下冬小麥有著不同的生育進(jìn)程,因此,在冬小麥長勢監(jiān)測和估產(chǎn)的研究中應(yīng)該進(jìn)行雨養(yǎng)區(qū)冬小麥與灌溉區(qū)冬小麥分類,以提高監(jiān)測精度。在晉南地區(qū)冬小麥種植區(qū)域中,灌溉區(qū)冬小麥一般分布在海拔600 m 以下,坡度小于15°的平川區(qū)域,此區(qū)域有利于土壤水分涵養(yǎng);反之,則為雨養(yǎng)區(qū)冬小麥分布區(qū)[26]。
從圖5和表7可以看出,灌溉區(qū)冬小麥主要分布在禮元鎮(zhèn)、東鎮(zhèn)鎮(zhèn)、侯村鄉(xiāng)、桐城鎮(zhèn)、郭家莊鎮(zhèn)、裴社鄉(xiāng)、河底鎮(zhèn)以及神柏鄉(xiāng)東南部等各鄉(xiāng)鎮(zhèn)沿涑水河流域的平川區(qū)域,面積為12 773.33 hm2,占總面積的34.92%;而雨養(yǎng)區(qū)冬小麥主要分布在聞喜縣西北部和東南部各鄉(xiāng)鎮(zhèn)丘陵垣臺(tái)區(qū)域,在西北部分布較為零散,在后宮鄉(xiāng)西部分布較為集中,面積為23 806.66 hm2,占聞喜縣冬小麥總面積的65.08%。同山西省統(tǒng)計(jì)年鑒數(shù)據(jù)(38 800 hm2)進(jìn)行對(duì)比分析,聞喜縣冬小麥總提取面積的精度可以達(dá)到94.28%,雨養(yǎng)區(qū)為93.48%,灌溉區(qū)為95.8%。本研究得出的雨養(yǎng)區(qū)和灌溉區(qū)冬小麥提取精度明顯優(yōu)于文獻(xiàn)[26]的研究結(jié)果(86.16%和86.15%),說明Sentinel-2A數(shù)據(jù)可以明顯降低混合像元效應(yīng),更適合區(qū)域冬小麥種植面積提取研究。
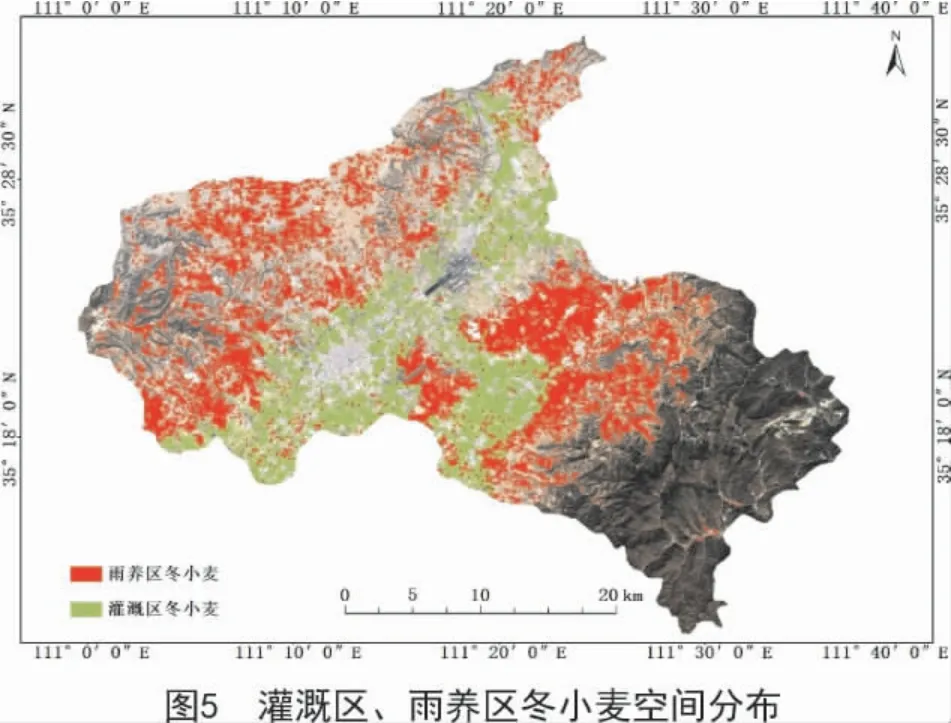
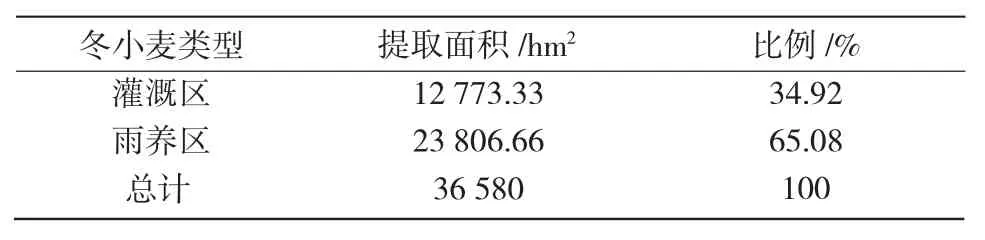
表7 聞喜縣雨養(yǎng)區(qū)、灌溉區(qū)冬小麥分類統(tǒng)計(jì)結(jié)果
3 結(jié)論
本研究以2018年冬小麥拔節(jié)期內(nèi)的Sentinel-2A 數(shù)據(jù)為數(shù)據(jù)源,以山西省運(yùn)城市聞喜縣為研究區(qū),通過利用遙感影像主成分變換、波段特征提取技術(shù),將主成分信息、波段空間紋理特征、紅邊歸一化植被指數(shù)以及大量調(diào)查樣本點(diǎn)輸入到隨機(jī)森林分類器中進(jìn)行決策樹構(gòu)建,并基于數(shù)字高程模型提取的坡度、高程信息,提取了2018年聞喜縣冬小麥的灌溉區(qū)與雨養(yǎng)區(qū)的空間分布信息。結(jié)果表明,Sentinel-2A 遙感數(shù)據(jù)適合作為縣域尺度冬小麥監(jiān)測的數(shù)據(jù)源。Sentinel-2A 數(shù)據(jù)重訪周期為10 d,在農(nóng)作物物候時(shí)期內(nèi)更容易獲得質(zhì)量較好地遙感影像,并且該數(shù)據(jù)影像空間分辨率較高,獲取成本低,能夠滿足大面積冬小麥監(jiān)測的要求。采用隨機(jī)森林分類器對(duì)聞喜縣地物進(jìn)行識(shí)別與分類,其分類總體精度達(dá)到98.11%,Kappa 系數(shù)達(dá)到0.97,優(yōu)于同等條件下采用支持向量機(jī)法與最大似然算法。主成分分析、紋理特征和RENDVI 的引入可以提高單時(shí)相遙感影像對(duì)縣域冬小麥分類識(shí)別能力。2018年聞喜縣冬小麥遙感監(jiān)測面積為36 580 hm2,提取精度達(dá)到94.28%。其中,雨養(yǎng)區(qū)冬小麥遙感監(jiān)測面積為23 806.66 hm2,提取精度達(dá)到93.48%,占當(dāng)年總面積的65.08%;灌溉區(qū)冬小麥遙感監(jiān)測面積為12 773.33 hm2,提取精度為95.8%,占當(dāng)年總面積的34.92%。
猜你喜歡
數(shù)學(xué)小靈通·3-4年級(jí)(2024年2期)2024-05-15 02:02:28
數(shù)學(xué)小靈通(1-2年級(jí))(2021年4期)2021-06-09 06:25:56
大眾健康(2021年6期)2021-06-08 19:30:06
世界科學(xué)技術(shù)-中醫(yī)藥現(xiàn)代化(2020年2期)2020-07-25 02:05:36
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當(dāng)代陜西(2019年10期)2019-06-03 10:12:04
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2019年4期)2019-05-20 10:06:32
中學(xué)生數(shù)理化·七年級(jí)數(shù)學(xué)人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(jí)(2017年9期)2017-10-13 22:27:46
數(shù)學(xué)小靈通·3-4年級(jí)(2017年9期)2017-10-13 08:10:54
