一種基于圖文融合的跨模態社交媒體情感分析方法
2019-06-07 15:08:13申自強
軟件導刊 2019年1期
申自強


摘 要:情感分析是目前人工智能與社交媒體研究的熱門領域,具有重要的理論意義和實用價值。為了解決由于社交媒體具有隨意性、情感主觀性等特點造成文本與圖像之間的情感互斥問題,提出一種基于圖文融合的跨模態社交媒體情感分析方法。該方法不僅可以學習到文本與圖像之間的情感互補特性,而且通過引入模態貢獻計算,可避免情感表達不一致問題。在Veer和Weibo數據集上的實驗結果顯示,相比于現有融合方法,采用該方法的情感分類準確率平均提高了約4%。基于圖文融合的跨模態社交媒體情感分析方法能夠很好地處理模態間的情感互斥問題,具有較強的情感識別能力。
關鍵詞:社交媒體;情感分析;圖文融合;貢獻計算;跨模態
DOI:10. 11907/rjdk. 181783
中圖分類號:TP301文獻標識碼:A文章編號:1672-7800(2019)001-0009-05
Abstract: Sentiment analysis is a hot field in artificial intelligence and social media research, which has a very important theoretical and practical value. In order to solve the problem of emotional mutual exclusion between texts and images caused by the randomness and emotional subjectivity of social media, a cross-modal social media sentiment analysis method based on the fusion of image and text is proposed. This method can not only learn the emotional complementarity between texts and images, but also avoid the problem of the inconsistency of emotional expression by introducing the modal contribution calculation. Experimental results on Veer and Weibo datasets show that this method is about 4% more accurate than the existing fusion methods. The cross-modal social media sentiment analysis method based on the fusion of image and text can deal with the problem of modal mutual emotional exclusion well, and has strong recognition ability.
Key Words: social media; sentiment analysis; fusion of image and text; contribution calculation; cross-modal
0 引言
隨著互聯網的發展與普及,公眾參與社會活動的機會也逐漸增加。如今人們不僅從網上獲取信息,而且積極參與信息傳播和輿論表達,如QQ、微信、微博、百度貼吧、知乎等社交媒體已成為人們日常生活中不可或缺的一部分,也是互聯網信息傳播的重要途徑。每天,數以億計的人們在這些社交媒體平臺上發布自己的心情、狀態、觀點及評價等數據信息[1]。對這些媒體數據進行有效的情感分析可以幫助企業機構掌握用戶對于某產品的評價,了解公眾的情感與意見傾向,為產品改進與商業決策提供科學依據[2]。此外,對于政府機關,分析公眾在某個事件或重大熱點問題上持有的態度有利于政府領導體察民情,從而及時、有效地進行輿論引導,積極主動地預防各種突發事件和危機[3]。因此,對于社交媒體情感分析的研究具有重要意義。
目前,對于社交媒體情感分析的研究大多集中在對文本數據的情感分析上,主要方法可分為兩類:基于詞典的方法與基于機器學習的方法。基于詞典的方法以情感詞典作為判斷情感傾向的主要依據,同時兼顧語法結構,設計對應的判別規則。陳國蘭[4]基于開源情感詞典與微博文本的語義規則特點提出微博文本的情感計算方法,對于微博情感分析具有較強的適應性;李晨等[5]采用一種將情感詞典與語義規則相結合的情感關鍵句抽取方法,對段落內的句子進行情感分析。基于詞典的方法雖然操作簡單,但其效果很大程度上取決于人工設計與先驗知識,適用范圍較窄。基于機器學習方法的思路是首先采集一個規模龐大的訓練集,由人工對文本樣本進行情感標簽標注,然后從文本中提取特征,輸入到模型中進行訓練學習,最后利用訓練好的模型預測新文本的情感傾向;趙剛等[6]通過研究情感分析領域若干機器學習模型設計了餐飲領域網上評論情感分析模型,用于判斷客戶情感傾向;Giatsoglou等[7]提出一種快速、靈活、通用的情感檢測方法,其中文本文檔由向量表示,并采用機器學習方法進行模型訓練。此外,隨著社交媒體的多元化發展,人們在社交媒體上已不滿足于僅采用文字形式發布自己的狀態,而更傾向于采用文本與圖像相結合的方式表達情感。在情感分析中,圖像中往往蘊含著用戶情感信息,與文本情感可起到互補作用。例如張耀文等[8]首先提取文本特征和圖像的顏色及紋理特征,然后將兩模態特征映射到同一特征空間里進行情感類別預測;蔡國永等[9]則利用卷積神經網絡分別對文本和圖像特征進行情感極性預測,然后再將兩者結果進行決策融合;羅杰波等[10]提出一種跨模態一致性回歸(Cross-modality Consistent Regression,CCR)模型用于圖文融合情感分析,其主要思想是對相關但不同的模態特征進行一致性約束。這些方法主要集中于將兩種模態信息進行融合,或對兩種模態之間的相關性進行學習融合,但均未考慮實際應用中由于社交媒體的隨意性、情感主觀性等因素造成的文本和圖像之間的情感互斥問題。針對該問題,本文提出一種基于圖文融合的跨模態社交媒體情感分析方法,該方法不僅可以學習到不同模態之間共同的情感特征,還能對模態間的情感互斥問題進行分析處理。具體而言,在模型訓練中,可通過計算每個模態對整體的貢獻判別最終情感傾向,從而避免情感表達不一致的問題。
1 社交媒體情感分析方法
近年來,隨著社交媒體的廣泛應用,針對社交媒體的情感分析已成為研究熱點。其中,文本與圖像數據是社交媒體情感分析研究中兩種重要的模態數據。圖文融合社交媒體情感分析的一般過程可分為:文本與圖像情感特征提取、融合特征學習以及情感分類3個過程。
1.1 情感特征提取
文本的情感特征提取方法主要有兩種模型:傳統模型與深度學習模型。傳統模型一般是基于簡單的統計學技術,而深度模型則是基于神經網絡技術。常用的傳統模型主要包括TF-IDF(Term Frequency-Inverse Document Frequency)、詞性標注(Part-of-Speech Tagging)與N-gram模型。此外,一些研究還表明,通過對傳統文本特征提取方法進行改進,可以獲得更好的結果。如Martineau等[11]使用正反兩個訓練語料庫中TF-IDF分數的差異衡量單詞,將評論分為正和負,其實驗結果顯示,采用Delta TF-IDF特征顯然比采用TF-IDF或單詞頻數特征效果更好;神經概率語言模型是由Bengio等[12]基于神經網絡思想創建而成的,學者們對其作了大量研究,目的是通過學習一種分布式詞向量表示,以對抗由于訓練數據增大而產生的維數災難問題;Mikolov等[13]于2013提出兩個新模型CBOW和Skip-gram,用于學習大規模語料庫的詞向量特征表示。
關于圖像情感特征的提取,一直以來都是圖片情感分析領域的研究熱點。圖像特征一般分為:低級特征、中級特征與高級特征。低級特征主要指顏色、形狀、線條、紋理、亮度等特征,中級特征一般指圖像中存在的對象、目標等特征,而高級特征則是指行為、場景與情感等語義特征。顯然,圖像情感特征屬于高級語義特征。為了提取圖像情感特征,需要提取圖像相關特征后建立模型,以學習圖像本身與情感之間的情感鴻溝映射關系。例如,Mayank Amencherla等[14]通過心理學理論中色彩與情感之間的相關性對圖像中的色彩進行檢測分析,用于圖像情感預測;Stuti Jindal等[15]則是利用遷移學習與卷積神經網絡方法建立圖像情感預測框架。
1.2 融合方法
在情感計算領域已有許多關于圖文融合情感分析的研究成果,其中大多集中于將兩種模態信息進行融合,此外還有一些研究集中于對兩種模態之間的相關性進行學習融合。其常用融合策略可分為3種:特征層融合、決策層融合以及一致性回歸融合。例如,林鴻飛等[16]利用Logistic回歸分別對文本與相關圖像進行情感預測,最后將兩個預測概率進行加權平均,得出最終結果。無論是特征層融合還是決策層融合方法,都忽視了文本與圖像兩模態特征之間的相互關系,而一致性回歸融合則充分考慮了模態之間的相關性。
一致性回歸融合模型的主要思想是認為不同模態在描述同一事物時所表達的情感應該是一致的[10]。在圖文融合社交媒體情感分析中,首先采用不同的特征提取方法分別對文本與圖像進行特征提取,然后將兩模態串在一起作為初始融合特征,接著把文本和圖像特征以及初始融合特征輸入一致性回歸模型中進行訓練學習,采用KL散度度量不同特征預測標簽分布之間的相關性,最后將學習到的模型參數用于情感判斷。KL散度的計算公式其實是熵的變形計算,在原有概率分布p上,加入近似概率分布q,計算它們每個取值對應的對數差,具體公式如下:
其中,[Dkl(p||q)]的值越大,表明兩概率分布的差異性越大,反之表示差異性越小,差異相同時值為0。雖然一致性回歸融合模型可以很好地學習到不同模態間的一致性情感,但沒有考慮實際應用中由于社交媒體的隨意性、情感主觀性等特點造成的模態間情感互斥問題。
2 跨模態社交媒體情感分析方法
本文提出一種跨模態社交媒體情感分析方法(Cross-modal Social Media Sentiment Analysis Method,CSMSA),其完整框架如圖1所示,該框架分別由以下4個階段組成:數據輸入、特征提取、特征融合以及情感分類。首先利用CBOW和CNN提取文本與圖像特征,接著通過計算各模態對整體的貢獻選擇合適的融合策略,然后利用跨模態回歸模型訓練學習模態之間的情感相關權重,最后通過訓練好的分類器進行情感分類。
2.1 文本與圖像特征提取
輸入樣本是指從微博、Veer社交媒體平臺抓取到的文本和圖像數據,每個樣本被定義為[S(ti,vi)],[ti]、[vi]分別表示第[i]個樣本的文本和圖像。通過CBOW與CNN分別學習提取到文本及圖像的情感特征[Xt(xt1,xt2,?,xtm)]和[Xv(xv1,][xv2,?,xvn)],式中[m]、[n]分別代表文本與圖像特征的維度。
2.2 模態特征融合
對于文本和圖像的特征融合,本文通過計算每個模態對整體的貢獻選擇合適的模態融合策略。首先,采用[pθ(Xi)]表示輸入特征[Xi]在參數[θ]下的預測函數,使用Sigmoid函數計算概率分布,公式如下:
2.3 跨模態回歸模型訓練
經過綜合考慮融合特征預測概率與真實標簽之間的損失,以及圖文兩個特征分別與融合特征預測概率之間的損失構建損失函數,其公式為:
3 實驗及結果分析
為了評估與驗證所提方法的有效性,本文分別在Veer和Weibo兩個媒體數據庫上對幾種方法進行對比實驗。接下來將從實驗數據庫、實驗設置、結果分析以及可視化4個方面介紹具體實驗過程。
3.1 實驗數據庫
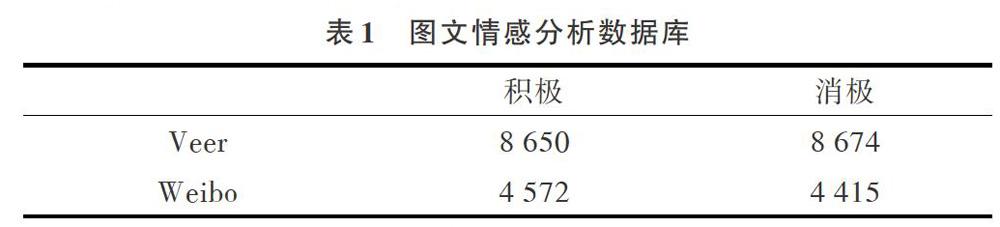
雖然從社交媒體平臺上可以輕松獲取到大量文本與圖像數據,但公開的可用于實驗研究,且帶有真實情感標簽的圖文數據樣本非常稀少。本文利用文獻[17]中的相關技術和思路建立了兩個圖文組合的情感分析數據庫:Veer和Weibo,如表1所示。
其中,Veer平臺可在線提供正版照片、插畫、矢量圖等優質圖像資料。首先通過平臺搜索功能,利用帶有積極與消極情感的關鍵詞進行搜索,并下載對應圖像,以及圖片描述與標題數據,即可獲得帶有弱標簽的文本與圖片數據集;然后請3名專業研究生通過情感標簽投票方式對這些弱標簽數據進行情感投票;最終保留情感票數統一的數據樣本。Veer數據庫總共包括8 650個積極樣本與8 674個消極樣本。對于Weibo數據庫的建立,首先利用爬蟲技術在Weibo平臺上采集大量文本與圖像數據;然后通過張華平博士及其團隊研發的NLPIR漢語分詞系統中的情感分析功能對文本情感進行打分,即為這些數據加上弱標簽;接下來選取并整合其中評分排名靠前的數據,建立弱標簽數據集;最后請3名專業研究生對這些弱標簽數據進行情感標簽投票。Weibo數據庫總共包括4 572個積極樣本與4 415個消極樣本。
3.2 實驗設置
實驗分別采用CBOW和CNN對文本與圖像進行特征提取。在文本特征提取中,設置詞向量維度為300,句子長度為140,學習率為0.025;在圖像特征提取中,圖片初始化大小為227*227,卷積核個數為32個,大小是11*11,Pooling層大小為2*2。此外,模型中超參數[γ]、[λ]的取值分別為1和3。
3.3 實驗結果分析
(1)基于文本和圖像的單模態與多模態情感分類結果比較。表2展示了單模態的文本和圖像以及多模態圖文融合情感分類的結果比較。其中,對于單模態,分別使用CNN和Logistics Regression對其進行模型訓練與分類[18-19]。由表2可以看出,文本模態的情感分析結果普遍高于圖像模態的情感分析結果,這是由社交媒體的特點決定的,雖然圖像也蘊含發布者的情感,但其主觀性和隨意性較強,因此僅從單一圖像模態預測發布者情感傾向的結果并不理想。圖文融合情感分類的結果高于單模態文本和圖像的情感分類結果,說明本文所提方法可以有效結合文本和圖像兩個模態特性,在情感上進行互補,從而提高了情感分類效果。
3.4 可視化
圖2、圖3分別展示了本文提出模型在Veer和Weibo數據庫的分類結果中,排名靠前的部分消極與積極數據預測結果可視化圖,其中使用淺色矩形標記消極樣本,深色矩形標記積極樣本。從圖中可以清晰看出樣本的情感分類結果,消極圖像多與“哭”、“一個人”有關,且色調偏灰暗,積極圖像則相反。其中,有些文本與圖像的分類結果相反,這是由于模態間的內容差異以及社交媒體具有主觀性、隨意性等因素導致的,但根據各模態的貢獻度選擇合適的融合策略,可以在一定程度上提高識別準確率。
4 結語
本文對社交媒體情感分析現狀進行了研究,針對由于社交媒體具有隨意性、情感主觀性等特點造成文本與圖像之間的情感互斥問題,提出一種基于圖文融合的跨模態社交媒體情感分析方法。其核心思想是在訓練跨模態回歸模型時,通過計算每個模態對整體的貢獻選擇合適的融合策略,從而避免情感表達不一致問題。為了驗證所提方法的有效性,分別在Veer和Weibo兩個社交媒體數據集上進行對比實驗,結果表明,本文方法的情感分類準確率優于現有融合方法。此外,由于社交媒體數據過于隨意且不規范,單一模態的情感分析可能無法從中挖掘出足夠的信息。通過綜合考慮文本、圖像及音視頻等多種模態信息進行分析,則可能有效地彌補單模態的缺陷。社交用戶的情感傾向也與個人性格、生活習慣、社交關系及周圍環境等因素有關,在進行情感分析的同時,融入個性化分析也是一個重要研究方向。
參考文獻:
[1] SEVERYN A,MOSCHITTI A. Twitter sentiment analysis with deep convolutional neural networks[C]. 38th Annual International ACM SIGIR Conference on Research and Development on Information Retrieval, 2015: 959-962.
[2] 肖紅,許少華. 基于句法分析和情感詞典的網絡輿情傾向性分析研究[J]. 小型微型計算機系統,2014,35(4): 811-813.
[3] YANG Y. Research and realization of internet public opinion analysis based on improved TF-IDF algorithm [C]. Vienna: International Symposium on Distributed Computing and Applications to Business, Engineering and Science,2017.
[4] 陳國蘭. 基于情感詞典與語義規則的微博情感分析[J]. 情報探索,2016(2):1-6.
[5] 李晨,朱世偉,魏墨濟,等. 基于詞典與規則的新聞文本情感傾向性分析[J]. 山東科學,2017,30(1):115-121.
[6] 趙剛,徐贊. 基于機器學習的商品評論情感分析模型研究[J]. 信息安全研究,2017,3(2):166-170.
[7] GIATSOGLOU M,VOZALIS M G,DIAMANTARAS K,et al. Sentiment analysis leveraging emotions and word embeddings [J]. Expert Systems with Applications,2017,69:214-224.
[8] ZHANG Y, LIN S, JIA X. Sentiment analysis on Microblogging by integrating text and image features[C]. Pacific-Asia Conference on Knowledge Discovery and Data Mining,2015: 52-63.
[9] 蔡國永,夏彬彬. 基于卷積神經網絡的圖文融合媒體情感預測[J]. 計算機應用,2016,36(2): 428-431.
[10] YOU Q,LUO J,JIN H,et al. Cross-modality consistent regression for joint visual-textual sentiment analysis of social multimedia[C]. San Francisco: ACM International Conference on Web Search and Data Mining, 2016.
[11] MARTINEAU J,FININ T. Delta TFIDF: an improved feature space for sentiment analysis[C]. California: International Conference on Weblogs and Social Media, 2009.
[12] BENGIO Y, DUCHARME R, VINCENT P, et al. A neural probabilistic language model[J]. Journal of Machine Learning Research, 2003, 3: 1137-1155.
[13] MIKOLOV T,CHEN K,CORRADO G,et al. Efficient estimation of word representations in vector space[J]. Computer Science,2013(1):1-12.
[14] AMENCHERLA M,VARSHNEY L R. Color-based visual sentiment for social communication[C]. Taiwan: Information Theory,2017.
[15] JINDAL S, SINGH S. Image sentiment analysis using deep convolutional neural networks with domain specific fine tuning[C]. International Conference on Information Processing,2015:447-451.
[16] YU Y, LIN H, MENG J, et al. Visual and textual sentiment analysis of a Microblog using deep convolutional neural networks[J]. Algorithms, 2016, 9(2): 41.
[17] CORCHS S, FERSINI E, GASPARINI F. Ensemble learning on visual and textual data for social image emotion classification[J]. International Journal of Machine Learning & Cybernetics,2017(4):1-14.
[18] XIAO K, ZHANG Z, WU J. Chinese text sentiment analysis based on improved convolutional neural networks [C]. IEEE International Conference on Software Engineering and Service Science,2017: 922-926.
[19] TRUONG Q T, LAUW H W. Visual sentiment analysis for review images with item-qriented and user-oriented CNN[C]. Mountain View: ACM on Multimedia Conference,2017:1274-1282.
[20] CHEN F, JI R, SU J, et al. Predicting Microblog sentiments via weakly supervised multi-modal deep learning[J]. IEEE Transactions on Multimedia, 2017, 99: 1.
[21] PORIA S, CAMBRIA E, HOWARD N, et al. Fusing audio, visual and textual clues for sentiment analysis from multimodal content[J]. Neurocomputing, 2016, 174: 50-59.
