基于不等概率的多級索引模型及其鍵值選擇策略研究
2019-06-07 15:08:13匡雯顧佳燕
軟件導(dǎo)刊 2019年1期
匡雯 顧佳燕


摘 要:大規(guī)模服務(wù)存儲結(jié)構(gòu)模型研究中,多級索引模型被證明是非常高效的存儲結(jié)構(gòu),具有穩(wěn)定、易管理、易維護(hù)、低冗余的優(yōu)勢。目前的研究建立在服務(wù)調(diào)用概率平均分布這一假設(shè)之上,然而現(xiàn)實(shí)服務(wù)調(diào)用是不等概率的,這意味著多級索引模型在服務(wù)調(diào)用的不等概率情況下還不是最優(yōu)。為提高服務(wù)調(diào)用不等概率條件下多級索引模型的檢索效率,通過分析多級索引模型的檢索特性,推導(dǎo)出檢索操作的時間復(fù)雜度函數(shù)。利用函數(shù)極值,設(shè)計(jì)了不等概率條件下鍵值的優(yōu)化選擇方法。實(shí)驗(yàn)結(jié)果顯示,該方法比隨機(jī)選鍵方法提高檢索效率15%左右,證明優(yōu)化選擇方法能有效提高服務(wù)檢索效率。
關(guān)鍵詞:服務(wù)計(jì)算;服務(wù)檢索;服務(wù)存儲;多級索引模型
DOI:10. 11907/rjdk. 181798
中圖分類號:TP301文獻(xiàn)標(biāo)識碼:A文章編號:1672-7800(2019)001-0040-05
Abstract: Many works studied storage structures of services. Among them, a multilevel index model was proved to be very efficient for service storage for large-scale service repositories. It has the advantages of non-redundancy, stability, being easy managed and maintained. Previous works are proposed and evaluated on the assumption that the probability of service invoking is equal. However, it is too strict in reality, which means the efficiency of service retrieval is not optimal. In order to improve the efficiency of service retrieval under the condition of unequal probability of service invoking, the time complexity of the service retrieval is deduced and an optimal key selection method is proposed according to the function. Our experimental results show that the optimal key selection method reduces 15% of retrieval time. Therefore, the effectiveness and efficiency of the proposed optimal key selection method under unequal probability of service invoking are valid.
0 引言
隨著互聯(lián)網(wǎng)技術(shù)的飛速發(fā)展和產(chǎn)業(yè)規(guī)模的不斷擴(kuò)大,Web服務(wù)呈現(xiàn)高速增長趨勢[1],這對軟件產(chǎn)業(yè)提出了更高要求。隨時可用性、松散耦合性、靈活的可擴(kuò)展性和分布式以及更高的可重用性,是現(xiàn)代軟件產(chǎn)業(yè)的突出特點(diǎn)[2],服務(wù)組合是研究熱點(diǎn)。Web服務(wù)組合指提供復(fù)雜新功能的組合服務(wù)過程[3]。工作流技術(shù)[4-6]、自動機(jī)[7]、Petri網(wǎng)[8-9]、人工智能規(guī)劃[10]等理論和方法在服務(wù)組合領(lǐng)域都有應(yīng)用。一些研究成果提出采用自己的服務(wù)存儲結(jié)構(gòu)減少服務(wù)組合時間,如Graph結(jié)構(gòu)[11-13]、倒排索引[14]、Service Net[15-17]等,但仍存在一些缺陷,如復(fù)雜度高、可靠性差、用戶滿意度低等。
Wu等[2]基于等價(jià)類、等價(jià)劃分、商集理論,提出了一種大規(guī)模服務(wù)存儲結(jié)構(gòu)——多級索引模型, Wu,Xu等[2,18-20]提到的鍵值選擇策略與筆者先前[21]改進(jìn)的鍵值選擇策略,都是在服務(wù)等概率調(diào)用情況下的選擇策略,但這種假設(shè)在實(shí)際中很難實(shí)現(xiàn)。由于某些服務(wù)“很火”且經(jīng)常被調(diào)用,其它服務(wù)“很冷”且很少被調(diào)用,導(dǎo)致服務(wù)調(diào)用很可能是不等概率的,所以本文設(shè)計(jì)不等概率模塊,完善不等概率的多級索引模型并提出不等概率模型上的鍵值選擇策略。
1 多級索引模型
1.1 服務(wù)基本定義
定義1 一個服務(wù)s是一個三元組[s=s,?s,?O],其中[s]表示服務(wù)的輸入?yún)?shù)集合,[s]表示服務(wù)的輸出參數(shù)集合,O表示服務(wù)其它元素集合,如服務(wù)聲譽(yù)等。
服務(wù)檢索指根據(jù)用戶需求接受一組參數(shù),并返回由該組參數(shù)調(diào)用的一組服務(wù)。根據(jù)當(dāng)前參數(shù)集合查找到可發(fā)生服務(wù)的集合,通過服務(wù)組合和發(fā)現(xiàn)來調(diào)用,定義如下:
定義2 服務(wù)的檢索運(yùn)算可定義為[Re(A,?S)={s | ][s?A∧s∈S}],其中,A為一個參數(shù)集合,S表示服務(wù)集合,s表示一個服務(wù),[Re(A,?S)]表示從服務(wù)集S中找出服務(wù)的輸入?yún)?shù)均包含在A中的所有服務(wù),即在狀態(tài)A下可以引發(fā)的所有服務(wù)。
定義3 用戶需求可定義為一個二元組[Q=(Qp,Qr)],其中Qp表示用戶可提供的參數(shù)集合,Qr表示用戶需要的參數(shù)集合。
1.2 多級索引及模型
大規(guī)模服務(wù)存儲庫通過服務(wù)的輸入輸出參數(shù)進(jìn)行服務(wù)組合操作。由于大規(guī)模服務(wù)庫可能存在一些包含相同輸入輸出參數(shù)的服務(wù)集合,必然導(dǎo)致服務(wù)組合存在大量冗余。
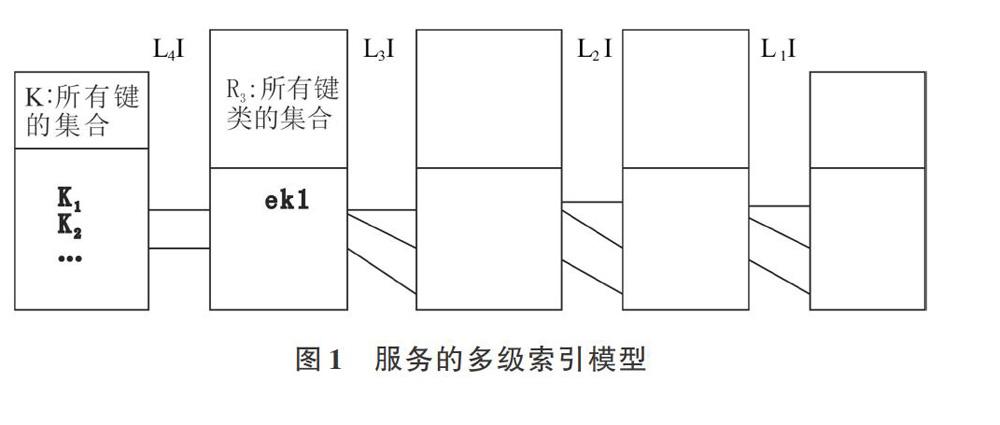
由于等價(jià)類和等價(jià)元素具有完整性、無冗余性、正確性特征,Wu等[2]基于等價(jià)類和等價(jià)元素關(guān)系,將多級索引模型分為4個級別,分別是第1級索引(The First Level Index,L1 I):如果服務(wù)s∈Cs,那么服務(wù)s和相似類Cs之間存在一個索引鏈接;第2級索引(The Second Level Index,L2 I):如果相似類Cs∈Cis,那么相似類Cs和半相似類Cis之間存在一個索引鏈接;第3級索引(The Third Level Index,L3I):如果半相似類Cis∈Ck,那么半相似類Cis和鍵類Ck之間存在一個索引鏈接;第4級索引(The Fourth Level Index,L4 I):對于“Ck∈[?3],”k∈К, 如果fk(Ck)=k,那么在鍵類Ck和鍵k之間存在一條索引鏈接。
Wu等[2]基于4個索引級別提出了3種索引模型:全索引包括L1I-L4I;中級索引包括L2I-L4I;初級索引包括L3I和L4I。在多級索引服務(wù)存儲模型中,基于等價(jià)關(guān)系和等價(jià)類劃分的各類索引函數(shù)關(guān)系,可以有效避免相互之間服務(wù)信息冗余情況,從而解決重復(fù)檢索帶來的模型效率問題。
為了應(yīng)對不同的服務(wù)存儲倉庫情形,多級索引服務(wù)存儲模型提供了彈性部署方案,對于不同的存儲狀況和用戶需求采用不同方案。彈性部署方案包括基于L1I-L4I的完整模型、基于L2I-L4I中級模型和基于L3I-L4I的初級模型。L1I-L4I構(gòu)建了一個服務(wù)的多級索引模型,總體結(jié)構(gòu)如圖1所示。由于每級索引是完整的、無冗余的,所以整個索引模型也是完整的、無冗余的。
2 不等概率模塊設(shè)計(jì)與實(shí)現(xiàn)
2.1 不等概率下的多級索引模型結(jié)構(gòu)
服務(wù)的數(shù)據(jù)結(jié)構(gòu)包括服務(wù)及其輸入輸出、四級索引關(guān)系。下面以一組簡單且易于理解的Web服務(wù)為例說明服務(wù)參數(shù)之間的關(guān)系。表1為一組Web服務(wù)例子,包括4個服務(wù)及輸入輸出參數(shù)。
2.2 服務(wù)參數(shù)的不等概率設(shè)計(jì)
在多級索引模型中,輸出參數(shù)對檢索操作沒有影響,因此本文只討論構(gòu)建服務(wù)的輸入?yún)?shù)不等概率情況。每組服務(wù)都有一組輸入?yún)?shù),服務(wù)輸入?yún)?shù)的不等概率以兩個服務(wù)s1、s2舉例:s1的輸入?yún)?shù)為{a, b},輸出參數(shù)為{g, h},s2的輸入?yún)?shù)為{a, c},輸出參數(shù)為{j, k},那么輸入?yún)?shù)a被使用兩次,而b、c只被使用一次。在大規(guī)模服務(wù)存儲庫中,必然存在有的服務(wù)部分輸入?yún)?shù)相同,有的服務(wù)輸入?yún)?shù)完全不同,這就是服務(wù)輸入?yún)?shù)的不等概率情況,其關(guān)鍵算法如下:
2.3 檢索參數(shù)的不等概率設(shè)計(jì)
由于服務(wù)調(diào)用是通過對檢索參數(shù)進(jìn)行查詢實(shí)現(xiàn)的,因此服務(wù)被調(diào)用的概率不相等,即檢索參數(shù)不等于概率分布。服務(wù)檢索參數(shù)由用戶請求調(diào)用行為產(chǎn)生,每個用戶的調(diào)用行為是隨機(jī)的,同時各用戶調(diào)用行為之間基本獨(dú)立,對所有用戶的調(diào)用行為進(jìn)行統(tǒng)計(jì)可得到各個服務(wù)的檢索概率。滿足要素獨(dú)立、隨機(jī)和相加3個屬性,用戶檢索請求數(shù)據(jù)的分布較接近于正態(tài)分布。表2為jumpshot設(shè)備的主要搜索服務(wù)情況統(tǒng)計(jì),從理論和統(tǒng)計(jì)數(shù)據(jù)可得出檢索參數(shù)的非等概率分布近似收斂于正態(tài)分布的結(jié)論。
將實(shí)驗(yàn)所產(chǎn)生的檢索參數(shù),如樣本容量為3200,均值為500,標(biāo)準(zhǔn)差分別為200的檢索參數(shù)集合,導(dǎo)出到Excel并用spss統(tǒng)計(jì)工具分析,結(jié)果如圖4所示。顯然這3200個檢索參數(shù)基本符合正態(tài)分布趨勢。
3 鍵值選擇策略設(shè)計(jì)與實(shí)現(xiàn)
3.1 鍵定義
初級索引包括L3I和L4I,L3I和L4I是基于鍵構(gòu)造的,鍵是多級索引結(jié)構(gòu)中的一個創(chuàng)新性概念。在多級索引模型的添加操作中引入鍵,不僅能有效移除冗余,而且能提高添加和檢索操作效率。Wu等[2]提出最原始的鍵值選擇策略,簡稱為原始選鍵策略。筆者在文獻(xiàn)[21]中對該策略進(jìn)行改進(jìn),簡稱為隨機(jī)選鍵策略。本文提出服務(wù)調(diào)用不等概率情況下的多級索引模型,并基于此提出一種新型的鍵值選擇策略。
鍵在L3I和L4I上部署,由于初級索引模型、中級索引模型、全索引模型都包含第三和第四級索引,因此本文提出的鍵值策略將在初級索引模型上進(jìn)行部署和實(shí)驗(yàn),實(shí)驗(yàn)結(jié)果和效率分析同樣適用于中級和全索引模型。
圖5顯示了初級索引結(jié)構(gòu)。S是一個服務(wù)存儲庫,當(dāng)s被添加到S中時,鍵值選擇方法會為每個服務(wù)選擇鍵值。鍵值是用作索引條目的參數(shù)。如果si和sj具有相同的鍵,則它們將被分類到相同的鍵值類別中。Ck表示一個鍵值類,它是一組具有相同鍵值的服務(wù),[?3]表示所有鍵值類,К表示所有鍵值類的鍵值集合。
3.3 鍵值選擇算法設(shè)計(jì)
初級索引模型中對服務(wù)的檢索過程根據(jù)用戶提出的檢索參數(shù)集,先對鍵集合進(jìn)行檢索,比較檢索參數(shù)集和鍵集合中的鍵,找到符合的鍵類。每個鍵類對應(yīng)一些服務(wù),對這些服務(wù)進(jìn)行比較,找到請求的服務(wù),并返回用戶需要的參數(shù)集合。結(jié)合理論分析,不等概率情況下提高檢索效率可以盡可能縮短整體調(diào)用時間,即整體調(diào)用次數(shù),而整體調(diào)用次數(shù)取決于每個鍵類的調(diào)用次數(shù)。
由于鍵的調(diào)用概率和調(diào)用次數(shù)事前未知,那么不等概率下,提高檢索操作的效率可從減少服務(wù)比較時間著手,即保持每個鍵對應(yīng)的服務(wù)個數(shù)盡可能少。首先對比鍵集合和輸入?yún)?shù)集,選擇一個鍵集合中沒有的輸入?yún)?shù)作為鍵,如果該服務(wù)的所有輸入?yún)?shù)在鍵集合中都包含了,就遍歷每個輸入?yún)?shù)作為鍵對應(yīng)的服務(wù)個數(shù),選擇一個對應(yīng)服務(wù)個數(shù)最少的作為該服務(wù)的鍵。為方便與其它鍵值選擇方法進(jìn)行對比,將此方法命名為整體最優(yōu)鍵值選擇方法。整體最優(yōu)鍵值選擇算法設(shè)計(jì)如下:
4 實(shí)驗(yàn)結(jié)果與分析
本系統(tǒng)開發(fā)軟件環(huán)境:Microsoft Visual Studio 2012中的控制臺應(yīng)用程序和Windows窗體應(yīng)用程序,開發(fā)語言為Visual C#,采用面向?qū)ο箝_發(fā)技術(shù)。各個組成部分耦合性低,從應(yīng)用層模塊到結(jié)構(gòu)層模塊均可單獨(dú)修改、升級或替換。實(shí)驗(yàn)步驟:首先根據(jù)服務(wù)參數(shù)和檢索參數(shù)不等概率分布算法進(jìn)行編碼,實(shí)現(xiàn)不等概率下的多級索引模型搭建;接著將整體最優(yōu)選鍵方法編碼實(shí)現(xiàn),與等概率下吳等[2]提出的原始選鍵方法及筆者之前提出的優(yōu)化過的選鍵方法——隨機(jī)選鍵方法[21]進(jìn)行檢索效率比較。
4.1 基礎(chǔ)參數(shù)設(shè)置
生成10個數(shù)據(jù)集,每個數(shù)據(jù)集包括20 000個服務(wù),令n=20 000;參數(shù)集合大小是1 000,令m=1 000;每個服務(wù)有10個輸入?yún)?shù),令q=10;每個檢索請求包括32個參數(shù),令r=32;數(shù)據(jù)集包含100個檢索請求。
4.2 實(shí)驗(yàn)結(jié)果對比分析
表3總結(jié)了服務(wù)輸入?yún)?shù)和檢索參數(shù)不等概率情況下,3種方法在初級索引模型上的檢索效率。服務(wù)輸入?yún)?shù)不等概率條件下,整體最優(yōu)選鍵方法與隨機(jī)[21]、原始選鍵方法[2]相比,檢索效率提高20%左右;服務(wù)檢索參數(shù)不等概率條件下,整體最優(yōu)選鍵方法與隨機(jī)[21]、原始選鍵方法[2]相比檢索效率提高15%左右。因此不等概率情況下,整體最優(yōu)選鍵方法是最優(yōu)方法。
5 結(jié)語
本文針對服務(wù)調(diào)用頻率不同的情況,提出了多級索引模型的新的鍵值選擇方法,完善不等概率下的多級索引模型,使其更貼近實(shí)際情況。從理論和實(shí)驗(yàn)上驗(yàn)證了新方法的高效性。通過在初級索引模型上與原始、隨機(jī)選鍵方法比較,發(fā)現(xiàn)不等概率下整體最優(yōu)選鍵方法可縮短檢索操作時間,提高檢索效率,在檢索參數(shù)重復(fù)率較高的情況下效果更佳。
參考文獻(xiàn):
[1] SERRAI W,ABDELLI A,MOKDAD L,et al. Towards an efficient and a more accurate web service selection using MCDM methods[J]. Journal of Computational Science, 2017(22): 253-267.
[2] WU Y, YAN C, DING Z, et al. A multilevel index model to expedite web service discovery and composition in large-scale service repositories[J]. IEEE Transactions on Services Computing, 2016, 9(3): 330-342.
[3] SHENG Q Z, QIAO X, VASILAKOS A V, et al. Web services composition: a decades overview[J]. Information Sciences, 2014(280): 218-238.
[4] CASATI F, ILNICKI S, JIN L J, et al. Adaptive and dynamic service composition in eFlow[J]. Seminal Contributions to Information Systems Engineering,2000(1789): 13-31.
[5] SCHUSTER H, GEORGAKOPOULOS D, CICHOCKI A, et al. Modeling and composing service-based and reference process-based multi-enterprise processes[M]. Berlin: Springer publishing international, 2000.
[6] CASATI F, SAYAL M, SHAN M C. Developing e-services for composing e-services[J]. Lecture Notes in Computer Science, 2001(2068): 171-186.
[7] BERARDI D, CALVANESE D, GIACOMO G D, et al. Automatic service composition based on behavioral descriptions[J]. International Journal of Cooperative Information Systems, 2005, 14(4): 333-376.
[8] BALDAN B, CORRADINI A, EHRIG H, et al. Compositional semantics for open Petri nets based on deterministic processes[J]. Mathematical Structures in Computer Science, 2001, 15(1): 1-35.
[9] HAMADI R, BENATALLAH B. A Petri net-based model for web service composition[C]. Australasian Database Conference, 2003: 191-200.
[10] WU D, PARSIA B, SIRIN E, et al. Automating DAML-S web services composition using SHOP2 [J]. Lecture Notes in Computer Science, 2003(2870):195-210.
[11] WAN Z, WANG P. A novel pattern based dynamic service composition framework[C]. IEEE International Conference on Services Computing, 2016: 235-242.
[12] PUKHKAIEV D,OLEKSENKO O,KOT T,et al. Advanced approach to web service composition[M]. Berlin: Springer International Publishing, 2015.
[13] CHATTOPADHYAY S,BANERJEE A,BANERJEE N. A scalable and approximate mechanism for web service composition[C]. IEEE International Conference on Web Services, 2015: 9-16.
[14] KUANG L,LI Y,WU J,et al. Inverted indexing for composition-oriented service discovery[C]. IEEE International Conference on Web Services,2007: 257-264.
[15] LALEH T,PAQUET J,MOKHOV S A,et al. Efficient constraint verification in service composition design and execution (Short Paper)[M]. Rhodes:On the Move to Meaningful Internet Systems: OTM 2016 Conferences,2016.
[16] JEONG H Y,YI G, PARK J H. A service composition model based on user experience in Ubi-cloud comp[J]. Telecommunication Systems, 2016, 61(4):1-11.
[17] SUNAINA X,KAMATH S S. Enhancing service discovery using cat swarm optimization based web service clustering[J]. Perspectives in Science, 2016, 8(C): 715-717.
[18] WU Y,YAN C, DING Z, et al. A relational taxonomy of services for large scale service repositories[C]. IEEE International Conference on Web Services, 2012: 644-645.
[19] WU Y,YAN C G,LIU L,et al. An adaptive multilevel indexing method for disaster service discovery[J]. IEEE Transactions on Computers, 2015, 64(9): 2447-2459.
[20] XU W, WU Y, LIU L. Performance analysis of multilevel indices for service repositories[C]. International Conference on Semantics, Knowledge and Grids, 2016: 103-108.
[21] KUANG W, WU Y, LIU L. Key selection for multilevel indices of large-scale service repositories[C]. IEEE/ACM International Conference on Big Data Computing, Applications and Technologies, 2017:139-144.
