用于異常檢測的負選擇算法的自體半徑分析
2019-06-11 09:33:12◆陶晶
網絡安全技術與應用 2019年6期
關鍵詞:檢測
◆陶 晶
?
用于異常檢測的負選擇算法的自體半徑分析
◆陶 晶
(沈陽理工大學現代教育中心 遼寧 110159)
負選擇算法是用于異常檢測的一種有效方法。可變半徑的負選擇算法中,檢測器的半徑對算法性能影響較大。本文通過實驗分析并驗證了在不同的應用下,自體半徑的最佳取值。
異常檢測;負選擇算法;自體半徑
0 引言
V-detector算法作為否定選擇算法中的一種,因其首次提出用可變半徑的檢測器替代以往固定半徑的否定選擇算法,有效提高了檢測器覆蓋率,并使用了更少數量的檢測器覆蓋了更多的非自體區域。使得后來廣大學者對否定選擇算法的研究中,大多在V-detector之上加以改進,采用zhouji的人造二維數據集進行數據訓練,并以V-detector作為實驗的比對算法。因自體半徑為影響檢測器生成,繼而影響著最終檢測效果。因此對于V-detector訓練集半徑的研究具有重要的意義。本文使用MV-detector算法,在初始自體集半徑的選取上加以改進,以得到V-detector算法的訓練集的最優自體參數,為后續研究提供更優的自體集參數選擇。
在MV-detector算法中,自體數據集的初始半徑采用訓練集中自體點到非自體點的最近距離,因在大多數實際應用中,初始訓練集只有正常數據且zhouji的訓練數據集合全部為自體(正常)數據,因此本章將初始自體半徑加以改進,在實驗階段的自體初始距離采用0.01。
1 MV-detector算法的基本定義
否定選擇算法(NSA)可分為兩個階段:檢測器的生成和非自體檢測。檢測器的生成階段,即訓練數據隨機生成候選檢測器并與自體數據進行距離比較,若覆蓋任何自體區域則舍棄并重新生成候選檢測器,在檢測器集訓練成熟之后可覆蓋非自體空間。
檢測器的實際檢測性能的好壞會受多個參數影響,如自體樣本半徑、檢測器半徑、檢測器生成階段的終止條件。在大多數學者的研究實驗中,自體樣本數據集的大小都根據前人的經驗所設置,因此自體半徑是最容易被忽略的影響參數。公茂果和陳文分別通過建立自體集檢測器和對自體集進行層次聚類,以對NSA進行優化。在本文中,由自體樣本和自體半徑覆蓋的空間被定義為自身區域。如果自體半徑過小,則自體空間覆蓋率過低。通過自體半徑擴展,使得同樣數量的自體樣本覆蓋更多的自體空間,然而一些非自身區域將被錯誤地覆蓋到自體區域中,且兩側自體邊界的不平整導致產生檢測器不能覆蓋的孔洞區域過多。因此,對于NSA選擇合適的自體半徑非常重要。
免疫系統的功能是對身體的正常狀態維持,人體中使用抗體來區分自體和非自體抗原。在NSA中,抗體被定義為用于識別非自體區域的檢測器。因此,生成檢測器的質量決定了檢測性能。以下是一些基本的NSA定義:
(1)從特征空間中提取的所有樣本特征構成抗原集。
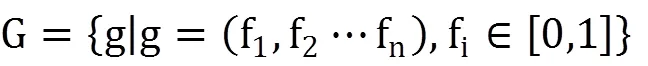
盡管NSA中檢測器被不斷改進,但檢測性能仍受自體半徑、預期覆蓋率、檢測器半徑、檢測器體積等多個參數的影響。陳文等人通過研究證明了大的自體半徑會降低誤檢率;Zhouji預估了檢測器的非自體覆蓋率,并使用非自體覆蓋率作為檢測器終止生成條件;J.Q Zeng 提出ANSA算法可根據檢測結果定期更新改進檢測器半徑。近年來廣大學者在異常檢測算法的參數研究中都取得較好的成績,并使用檢測率與誤檢率作為檢測器效果的衡量標準,然而大多數學者仍忽略了訓練集中自體半徑對檢測結果的影響。
在以往的否定選擇算法中,采用檢測率DR(detection rate)與虛警率FA(false alarm rate)作為檢測器檢測質量的衡量標準:
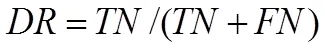
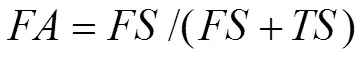
其中,、、、分別指檢測器正確識別的自體數量、正確識別的非自體數量、錯誤識別的自體數量、錯誤識別的非自體數量。
陳文在文獻[3]中提出一種新的評估方法,在原有的檢測率與誤檢率基礎之上,提出自體檢出率p,自體誤檢率p,非自體檢出率p,非自體誤檢率p,預期自體檢出率率p,預期非自體檢出率p,檢出率p,誤檢率p八個指標,并以此共同衡量檢測效果。
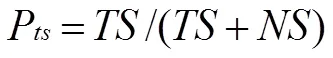
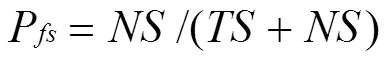
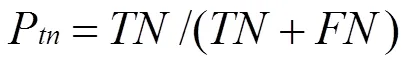
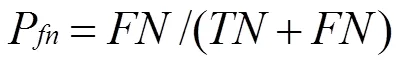

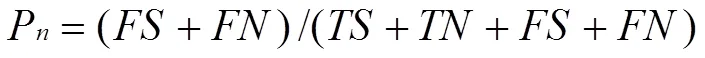
則p,p,p,p與公式(2)(3)對比可得:
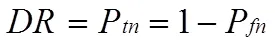
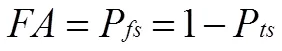
本文在文獻[3]中的算法思想的基礎之上,在實驗階段對訓練集合加以改進,并改變初試自體半徑的選擇,以動態迭代的方式定量的計算最佳自體半徑,以得到V-detector算法的最優數據集。
在文獻[3]中選用樣本大小為2200的數據集,訓練生成檢測器,其中包含2000個自體數據與200個異常數據。因在現實應用中,對網絡異常數據的初次檢測是沒有異常數據進行初始訓練的,因此本章將陳文的MV-detector算法進行訓練集的改進,使用大小為1000的初始自體集,且1000個樣本全部為自體(正常)數據。
在MV-detector算法中,自體數據集的初始半徑采用訓練集中自體點到非自體點的最近距離,因zhouji的訓練數據集合全部為自體數據,因此本文在實驗階段的自體初始距離采用0.01,樣本空間為二維實值空間[0,1]2。
2 MV-detector算法的自體樣本半徑分析
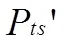
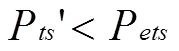
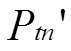
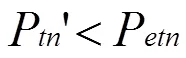
此時應將自體半徑減去r以收縮自體樣本空間,避免對非自體區域的覆蓋,增大檢測率的覆蓋空間。
在MV-detector算法中,得到基礎自體半徑之后,基于局部數據密度調整自體元素s的半徑的方法如下:

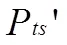

表1 自體半徑迭代
3 結論
本章通過引入文獻[3]的MV-detector的自體檢測率P、非自體檢測率P、總真實檢測率P等參數,通過迭代的方式獲得最佳自體半徑。對于zhouji在經典算法V-detector中所使用二維實值數據集,當自體空間為交叉十字形、環形、三角形三種自體分布空間時,自體半徑=0.2時為最佳自體半徑。
[1]Ji Zhou, Dasgupta D. V-detector: an efficient negative selection algorithm with probably adequate detector coverage. Inform sciences, 2009, 179(10): 1390–1406
[2]李棟,劉樹林,劉穎慧,張宏利.基于自適應超環檢測器的設備異常度檢測方法[J].機械工程學報,2014,50(12):17-24.
[3]Wen Chen ,Tao Li .Parameter analysis of negative selection algorithm[J]. Information Sciences, 2017, 420(12):218-234.
[4]Xin Xiao, Tao Li, Ruirui Zhang. An immune optimiz-ation based real-valued negative selection algorithm[M]. Klu-wer Academic Publishers, 2015
[5]Chen Wen, Tao Li, Xiaojie Liu, et al. A negative sel-ection algorithm based on hierarchical clustering of self set[J]. 2013, 56(8):1-13..
[6]Ji Zhou, Dasgupta D. V-detector:an efficient negativeselection algorithm with probably adequate detector coverage. Inform sciences, 2009, 179(10): 1390–1406
[7]Jinquan Zeng, Xiaojie Liu, Tao Li ,et al. A self-adap-tive negative selection algorithm used for anomaly detection[J]. Progress in Natural Science, 2009, 19(2):261-266.
[8]林偉寧,陳明志,詹云清,劉川葆.一種基于PCA和隨機森林分類的入侵檢測算法研究[J].信息網絡安全,2017(11):50-54.
猜你喜歡
中國設備工程(2022年12期)2022-07-11 04:33:00
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2020年12期)2021-01-18 06:57:46
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:36
中學生數理化·七年級數學人教版(2019年9期)2019-11-25 07:34:34
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:50
中學生數理化·七年級數學人教版(2019年12期)2019-05-21 02:53:48
