基于CFS-SAMME集成算法的入侵檢測應用研究
2019-06-11 09:23:52賈俊星
網絡安全技術與應用 2019年6期
◆賈俊星
?
基于CFS-SAMME集成算法的入侵檢測應用研究
◆賈俊星
(沈陽理工大學信息科學與工程學院 遼寧 110000)
針對當前網絡入侵隱蔽性強、危害大、手段高,傳統的入侵檢測方法已經難以有效防范的問題,本文進行了基于CFS和SAMME多分類集成算法的入侵檢測的應用研究。實驗結果表明:經過相關性特征選擇后的SAMME多分類集成算法不僅提升了檢測準確率,也大幅度提高了入侵檢測效率,為入侵檢測提供了有效的思路和方法。
CFS;最佳優先搜索;SAMME多分類集成算法
0 引言
由于互聯網攻擊行為的增加給國家、社會、個人造成了大量的損失,網絡活動的安全性在計算機網絡中得到了高度重視[1]。因此使用各種安全系統(如IDS)來防御檢測多種多樣的網絡攻擊行為。IDS通常與防火墻一起使用,并作為它們的補充。IDS安全系統已用于觀察和分析嚴重違反或威脅計算機和網絡中的計算機安全策略的事件[2]。通常,IDS的目的是檢測攻擊和安全漏洞并將其通知給管理員。IDS應該能夠使用監視,檢測和響應系統內的未授權活動來識別所有異常模式和流量。但是,對于網絡流量中龐大且不均衡的數據[3],IDS面臨著大流量數據所帶來的挑戰,檢測出惡意攻擊行為的準確性通常很低,檢測時間過長。因此,提升惡意攻擊行為的檢測精度和檢測時間已成為入侵檢測技術中的重中之重。
1 相關性特征選擇
相關性特征選擇[4](correlation -based feature selection,簡稱 CFS) 是一種經典的過濾器模式的特征選擇方法,采用基于相關性的啟發式方法來評估特征的價值。這種啟發式的方法考慮到了數據集中單個特征對預測屬性標簽的有用性以及它們之間的相互關聯程度,CFS通過它們之間的相關性,能夠快速識別冗余特征以及相關性小的特征,在提升檢測準確率的同時達到降低數據維數和約簡數據集的目的。
特征的相關性計算應用了Pearson[5]系數,Pearson系數作為相關性的評價指標已經被廣泛應用。通過計算特征與特征,特征與屬性標簽之間的Pearson系數,選取出特征集之間相關性差且特征與屬性標簽相關性強的特征。一個好的特征集通常情況下只包含與屬性標簽高度相關但彼此不相關的特征。
目前,特征搜索的策略有很多種,本文選取了最佳優先搜索算法[6](best first)用作特征搜索。首先通過CFS計算出特征與特征、特征與屬性標簽之間的相關性矩陣,然后利用啟發式評估函數對將要遍歷點進行估價,最后選擇代價小的進行遍歷,直到遍歷完所有的點。最佳優先搜索是從一組空特征集開始的,并且同時生成所有可能的單個特征子集。通過添加單個特征,使用Merit[7]作為衡量標準,以相同的方式選擇和擴展具有最高評估的特征子集。如果擴展的一個特征集性能沒有任何改進和提升,搜索將轉變到下一個最佳未進行搜索的特征子集,開始新的搜索。最佳優先搜索將探索整個特征集空間,直到找到最大相關性的特征子集,當搜索終止時,返回找到的最佳特征子集。
2 多類指數損失函數逐步添加模型(SAMME)
Adaboost算法的思想起源于PAC[8](Probably Approximately Correct)學習理論,它的基本思想是一種基于boosting算法的迭代算法。多類指數損失函數逐步添加模型[9](SAMME)是一種多分類的Adaboost算法模型,它的原理是通過擴展指數損失函數,以達到多分類集成算法對弱分類器準確率大于1/n的基本使用要求,它是通過改變數據分布來實現基分類器的迭代,從而使分類性能越來越強。它根據每次訓練集之中每個樣本的分類是否正確,以及前一次總體分類的準確率,重新確定每個樣本的權值。將重新確定過權值的新數據集在后一個分類器中繼續進行分類訓練,最后將所有訓練得到的基分類器加權融合起來,生成最終的決策分類器。而權值的調整主要依靠前一次分類器的樣本,若前一次樣本分類正確,則降低分類正確樣本的權值;若前一次分類錯誤的樣本,則提高分類錯誤樣本的權值。由于最終的決策分類器準確率比傳統的單分類器(決策樹、KNN)要高很多,因此在多分類問題上SAMME算法得到了廣泛的應用。
3 實驗
3.1 數據集與預處理
為了更好保證實驗的權威性和說服力,本文使用著名的網絡流量數據集NSL-KDD[10]作為實驗數據集進行實驗分析論證。該數據集包含41種屬性以及對應的1種屬性標簽,NSL-KDD數據集是對KDD CUP99數據集的改良,除去了KDD CUP99數據集里面的大量冗余數據,重新劃分了正常數據和異常數據的比例,使得NSL-KDD數據集中訓練和測試數據數量更加合理,更加適合用于網絡入侵檢測實驗中。
3.2 實驗環境
實驗環境為Windows7操作系統,內存為4GB,Weka3.8,Python,Spyder。
3.3 數據預處理
由于NSL-KDD數據集中包含有字符型的數據特征,在進行特征相關性計算和SAMME集成算法分類時,導致實驗出現錯誤。因此必須對NSL-KDD數據集進行預處理,將數據集里面字符型的數據特征轉換為數值型特征。
3.4 實驗結果
將經過預處理后的41種特征屬性,用Vn(n=1,2,……,41)來表示,如V1=duration,V2=protocol_type,V3=service,…,V41=dst_host_srv_rerror_rate等。在進行相關性特征選擇時,首先在Weka中將41種特征屬性進行離散化,將離散化的數據集采用十折交叉校驗的測試方法進行相關性特征選擇,NSL-KDD數據集在經過相關性特征選擇后,從41個特征屬性中選取出V2,V3,V4,V5,V7,V8,V10,V12,V25,V29,V30,V35,V36,V37,V38,共15個特征作為最佳特征子集,將未經過特征選擇的全部數據集和經過相關性特征選擇的最佳特征子集分別使用Spyder導入進SAMME多分類算法中,并且分別取迭代次數為10,20,30,40,50,60,70,80,90,100的情況進行實驗驗證。實驗結果如表1所示:
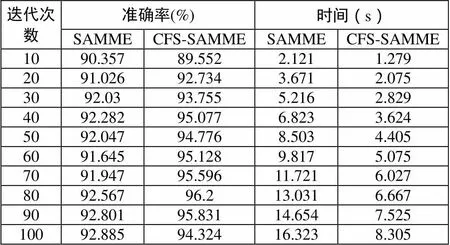
表1 NSL-KDD數據集下的檢測效果
圖1,2分別表示SAMME和CFS-SAMME的檢測準確率和檢測時間的對比。
從上述實驗結果可以得出,經過本文相關性特征選擇方法后,相比于未使用特征選擇的方法,檢測準確率有了明顯的提升。從檢測效率方面來看,顯著降低了檢測模型的復雜度,檢測時間將近減少了二分之一,檢測效率更加高效,除此之外,隨著CFS-SAMME多分類器迭代次數的增加,準確率也隨之增長,但是,當CFS-SAMME迭代次數為80次時,檢測準確率達到峰值96.2%,檢測準確率就開始下降。實驗結果表明,本文方法CFS-SAMME在網絡入侵檢測精度和檢測效率上有一定提高,證明了CFS-SAMME的有效性。
4 結束語
針對目前網絡流量大,數據量多,各種網絡攻擊愈發隱蔽,更難被入侵檢測系統檢測到的問題,本文進行了基于CFS-SAMME多分類集成入侵檢測的應用研究,利用數據集中屬性彼此之間的相關性,選取出對判定結果起重大作用的特征且彼此間相關性小的特征組成最佳特征子集,采用SAMME多分類集成方法進行迭代訓練,生產最終的入侵檢測模型。通過實驗結果可以清晰看出,CFS-SAMME在一定程度上提高了算法的檢測精確度和檢測效率,更加適用于當前復雜網絡入侵檢測系統中。

圖1 檢測準確率對比
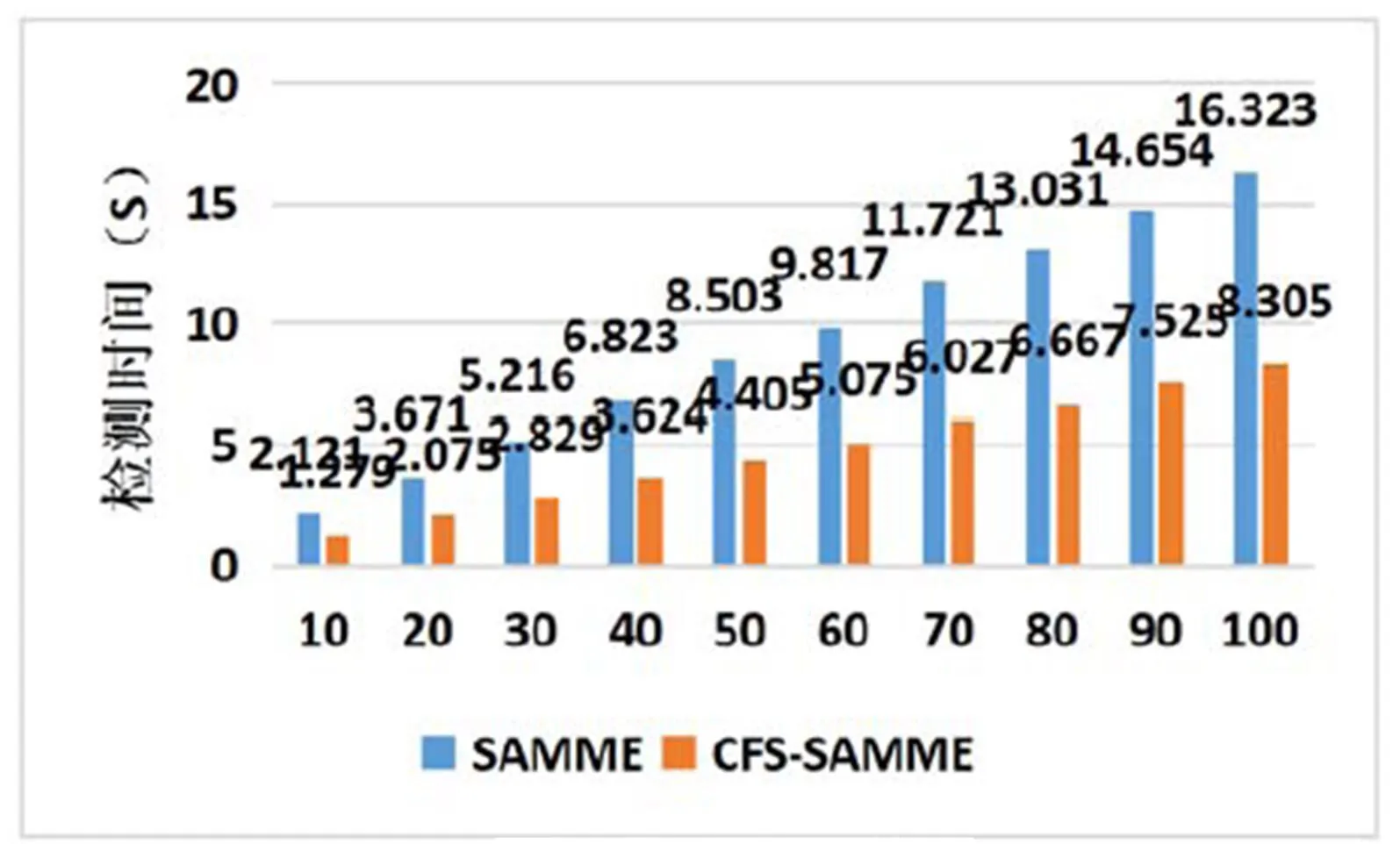
圖2 檢測時間對比
[1]張浩.一種新型分類算法及其在網絡入侵檢測中的應用研究[D].北京郵電大學,2018.
[2]郭春.基于數據挖掘的網絡入侵檢測關鍵技術研究[D].北京郵電大學,2014.
[3]朱小剛,ZHANG Ji-dong.不均衡數據分類下特征有效識別分析[J].計算機仿真,2018,35(04):145-148.
[4]Hall M A .Correlation-based Feature Selection for Discrete and Numeric Class Machine Learning[C]// Proceedingsof the Seventeenth International Conference on Machine Learning (ICML 2000), Stanford University, Stanford, CA,USA,June 29-July 2, 2000. Morgan Kaufmann Publishers Inc.2000.
[5]Pearson K,F.R S.NOTES ON THE HISTORY OF CORRELATION[J].Biometrika,1920,13(1):25-45.
[6]Lu B , Liu Z .PROLOG WITH BEST FIRST SEARCH[C]// 第25屆中國控制與決策會議.
[7]魏浩,丁要軍.屬性相關選擇和AdaBoost算法在入侵檢測中的應用[J].信息技術,2014(07):29-32.
[8]Valiant L G.A theory of the learnable.Communications of the ACM 1984,27(22):1134-1142.
[9]Ji Zhu,Hui Zou.Multi-class AdaBoost.Statistics and ItsInterface Volume 2(2009)349-360.
[10]DARPA Intrusion Detection Evaluation.http://www.11.mit.edu/IST/ideval/index.html.
猜你喜歡
小獼猴智力畫刊(2022年9期)2022-11-04 02:31:42
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:25:56
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
小哥白尼(趣味科學)(2019年6期)2019-10-10 01:01:50
當代陜西(2019年10期)2019-06-03 10:12:04
中學生數理化·七年級數學人教版(2019年4期)2019-05-20 10:06:32
中學生數理化·七年級數學人教版(2018年6期)2018-06-26 08:36:06
初中生世界·七年級(2017年9期)2017-10-13 22:27:46
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
發明與創新(2016年38期)2016-08-22 03:02:52
