使用LDA構建預警情報的本體映射依據研究
2019-06-12 11:51:16劉冬瑞潘越郭繼光
中小企業管理與科技 2019年12期
劉冬瑞,潘越,郭繼光
(中國電子科技集團公司 電子科學研究院,北京100041)
1 引言
軍事預警情報在戰爭中扮演著重要的角色。傳統戰爭過程中,首先圍繞情報的爭奪拉開戰爭序幕[1]。隨著信息技術的飛速發展以及網絡的高度普及,軍事預警信息承載形式也發生了變革[2]。收集到的預警情報數據具有多元、復雜、無序和異構等挑戰,為軍事預警情報準確定位及服務帶來巨大挑戰,是情報工作者必須解決的問題。使用本體技術能夠更加規范、完整地將情報內容描述出來,增強情報的透明度和共享性。
由于本體可以描述數據語義,所以在網絡或傳統數據庫中的任何數據都可以用本體來表示,使不同用戶可以進行高效的數據交互,有效解決了預警情報信息共享和復用效率低的問題。本體映射是解決異構本體之間互操作的有效方法[3,4],是本體研究領域中的基礎性研究。
本文針對互聯網絡中的預警情報信息,使用本體技術描述預警情報的特征,為決定作戰決策提供輔助。并且結合LDA主題建模技術,建立本體之間的映射依據,提供自動化本體映射的有利依據,為研究本體構建策略提供參考。
2 預警情報需求
20世紀90年代以來,以信息化為核心的軍事預警變革蓬勃發展,信息化武器裝備大量出現和廣泛運用,信息作戰正成為一種全新的作戰樣式,信息化戰爭的核心之一就是情報戰。隨著現代技術在情報領域的運用,軍事預警情報呈現出情報范圍廣泛、數據量大、保密性強、成為戰爭前沿等特性,增加了軍事預警情報搜集和使用的難度,針對這些特性研究者進行了相關研究,包括實現了基于Web 軍事預警情報挖掘模型[5]、提出一種基于云計算架構的四層軍事預警情報融合系統實現模型[6]、建立了基于本體的情報元數據模型等。
3 構建本體映射關系探索
使用本體技術能夠有效解決情報信息共享和復用效率低的問題,但由于本體本身具有分散性,不同用戶可以構建不同本體,而導致在同一個領域產生了大量冗余的本體,出現本體異構問題。異構的本體之間不能進行互操作,用戶之間也不能進行相互理解。本體映射能夠很好地解決本體異構的問題,為本體之間的互操作提供支撐。
3.1 軍事領域中本體的應用價值
目前本體理論在軍事情報領域當中已經有了相關的研究,如信息檢索、知識管理、信息服務等方面。基于本體的元數據思想引入軍事情報描述中,建立了用于描述軍事情報資源的元數據模型,能夠更加清楚地反映軍事情報資源所涵蓋的信息,提出了基于本體的情報需求滿足度計算方法,解決了海量軍事情報排序問題,提出基于軍事訓練本體的向量空間模型構建方法,使用文檔相似度作為參考標準,解決了語義相關問題。
以上研究將本體技術應用于軍事情報領域,在一定程度上提升了情報共享和信息檢索的效率。但本體自身帶有分散的特性,很多具有相似屬性的數據可能來自多個不同本體。由于本體的創建和建模方法不同,即使對同一領域內數據的建模,不同專家開發的本體也很可能存在差異,導致本體異構問題,限制了本體之間的互操作。本體映射可以有效解決本體異構的問題,從根本上解放本體互操作的限制,從而進一步提升本體應用價值。
3.2 本體映射方法
本體異構問題已經成為語義網所面臨的重要問題之一,而本體映射能夠較好地解決本體異構問題。國內外對本體映射較為統一的認識是:“假設O1 和O2 兩個本體,用一種方式來映射本體O1 中的每一個概念,使其能在本體O2 中找到相應的類或概念,反之亦然”。
近年來,本體映射技術已經成為一個研究的熱點,許多國內外研究者開發出了不同的本體映射方法。例如:基于Schema 的本體映射方法、基于上層本體的映射方法、基于語義相似度的本體映射方法、基于機器學習的本體映射方法、組合映射方法等。
本文首先使用LDA 主題模型提取本體文本的主題,將文本主題詞作為本體的文本概念,通過比較不同文本概念的相似度,為確認本體之間的映射關系提供依據。
3.3 LDA 簡介
最早在2003年,David M.Blei 等人提出LDA 主題模型。該模型的目標是識別文檔中的主題詞集,根據詞集對文檔進行分類。目前LDA 已經廣泛應用于文檔分類、人臉識別、信息演化分析等方面。本文結合LDA 和本體技術,構建語境情報領域內容本體映射關系,為數據共享提供支撐。
3.4 使用LDA 提取本體的文本特征
本文對本體映射依據進行研究,主要分為3 個步驟:
①根據專家經驗為本體添加描述性綜述文檔作為本體文本特征;
②抽取文本特征的主題信息,作為本體映射依據;
③構建本體映射依據的映射關系。
在構建本體過程中,依靠專家經驗,為每一個本體添加描述,作為本體的文本特征。在不解讀本體概念關系前,提供本體摘要性描述,該過程依賴于專家的經驗。
4 基于文本特征構建本體映射依據
本文目標給本體映射提供依據,為實現自動構建本體映射關系提供支撐。所謂本體映射,是根據兩個本體O1、O2之中不同概念的相似度進行比較,認為概念相似度較大的本體屬于同一本體庫。給出本體O1和O2的映射過程:
①map:O1→O2;
②如果Sim(C1,C2)>ε,則map(C1)=C2,其中ε 是設定的閾值,C1∈O1,C2∈O2。
概念C1和C2的相似度sim<(C1,C2)如果高于閾值ε 時,則建立O1和O2之間的映射關系,將異構本體不同概念建立映射關系的過程轉化為概念語義相似度計算。如果本體庫中存在大量本體,構建本體映射關系以前,首先要確定相似的本體集合。
為了提高映射的整體效率,對于待映射的本體概念,首先直接比對本體的文本主題詞集,如果相似度大于閾值ε,繼續建立映射關系,否則沒有映射關系,閾值ε 根據專家經驗給出,公式(1)表示如下:
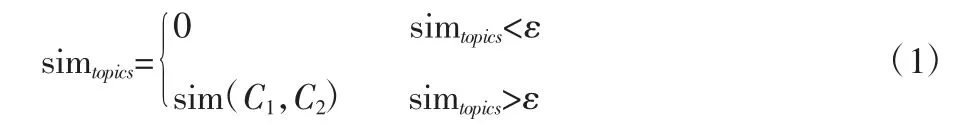
使用Jaccard 相似度模型計算不同本體中不同主題詞集Ct1與Ct2的相似度,如公式(2)所示:

針對多本體之間構建映射關系問題,設計了適用于本體文本映射的算法,如算法1 所示。算法思想:在所有本體Os中,本體Oi之間的文本特征Ct進行相似度比較,若相似度大于閾值ε,則對本體間的文本概念建立映射關系,繼續建立其
余概念映射關系。
算法1:

通過以上方法,能夠確認本體之間的映射依據。在映射依據的基礎之上,對本體之間繼續構建映射關系,提升多本體之間建立映射關系的效率。
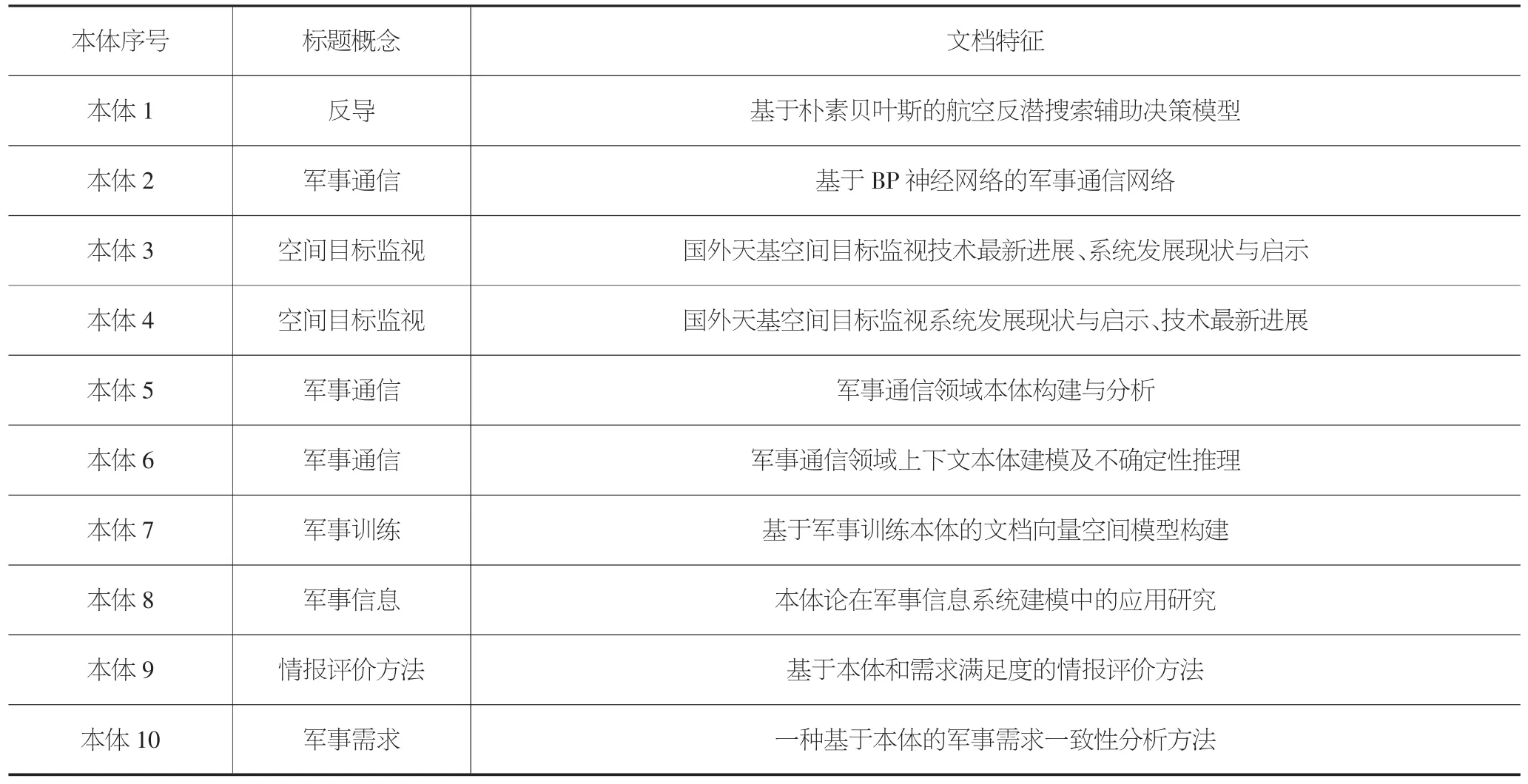
表1 試驗數據
5 試驗
5.1 實驗數據
本文選擇10 個有關預警情報特征的本體進行試驗。根據專家經驗為每個本體添加綜述性文檔特征,試驗數據描述如表1 所示,其中每個文檔特征用一篇綜述性文章進行表示。依照本體的構建過程,本體3 與本體4 非常類似。
5.2 試驗結果及分析
使用Mallet 主題建模工具提取每個本體文本特征的主題,設置主題個數為20。例如提取本體7 文檔特征的主題如下:model space vector training military ontology based construct revelance semantic representation text index problem solve VSM show results experimental reduction。
依照主題之間的相似度作為本體映射的依據,選擇了本體1、3、5、7、9 的數據進行顯示,如圖1 所示,其中橫軸表示10個本體,縱軸表示本體間文本概念相似度。明顯發現其中本體3 和本體4 的文本主題相似度達到50%,而其余本體之間的文本主題相似度均低于25%。說明本體3 和本體4 具有映射依據,很有可能是異構的本體,應該對其進行本體映射處理。

圖1 本體映射依據
進一步分析發現,影響構建映射依據有效性的原因可能有以下幾個方面:①根據專家經驗為本體添加文本概念,能夠在解析本提前對其進行描述,為后期本體映射提供依據。但該文本概念還沒有固定的形式,依賴于專家的決策,直接影響到本體的映射依據。②LDA 提取到的主題,能夠對文本概念進行較為準確的描述。但字符數較多的文本概念無法用20 個主題進行準確表現,因此LDA 提取的主題個數應該隨著文本概念長度的變化而變化,可以進一步提升映射依據的準確性。
6 結語
本文在軍事預警情報領域當中,使用本體相關技術,提升軍事情報的共享和復用性。首先根據專家經驗為每一個本體添加文本概念,接著使用LDA 技術提取文本概念的主題,最后通過比較主題之間的相似度,為本體映射提供依據。試驗選取了10 個預警情報領域的本體,經驗證發現本文所提方法能夠在多個本體映射之間,提供本體映射依據,為本體之間自動構建映射關系提供支撐。
猜你喜歡
現代裝飾(2022年1期)2022-04-19 13:47:32
甘肅教育(2020年8期)2020-06-11 06:10:02
現代裝飾(2020年2期)2020-03-03 13:37:44
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
中學生數理化·高一版(2018年9期)2018-10-09 06:46:48
中學生數理化·高一版(2017年9期)2017-12-19 12:15:14
湘江法律評論(2016年0期)2016-06-15 20:29:32
小學教學參考(2015年20期)2016-01-15 08:44:38
人間(2015年20期)2016-01-04 12:47:10
