基于候選區域的深度學習目標檢測算法綜述
2019-06-21 07:47:56詹煒長江大學計算機科學學院湖北荊州434023
長江大學學報(自科版) 2019年5期
詹煒 (長江大學計算機科學學院,湖北 荊州 434023)
Inomjon Ramatov (長江大學計算機科學學院,國際學院,湖北 荊州 434023)
崔萬新,喻晶精 (長江大學計算機科學學院,湖北 荊州 434023)
1 目標檢測的提出
從計算機誕生之時,人們就希望它可以幫助甚至代替人類完成一些重復性工作。利用巨大的存儲空間和極快的運算速度優勢,計算機可以輕易地完成一些對于人類非常困難的問題。如統計一本書中不同單詞出現的次數,存儲一個圖書館中所有的藏書,計算復雜的數學公式,都可以通過計算機輕松解決。然而,一些人類可以輕松解決的問題,目前卻難以通過計算機實現。如自然語言理解、圖像識別、語音識別等,而這些就是人工智能(artificial intelligence,AI)[1]需要解決的問題。
2006年以來,隨著深度學習的出現,機器學習領域取得突破性進展。深度學習是機器學習的一個分支,其動機在于建立、模擬人腦進行分析學習的神經網絡,它模仿人腦的機制來解釋數據,如圖像、聲音和文本。2006年加拿大多倫多大學教授、機器學習領域的泰斗Geoffrey Hinton和他的學生Ruslan Salakhutdinov在《Science》上發表了一篇文章,掀起了深度學習在學術界和工業界的研究和應用浪潮[2]。之后一直到2016年由Google開發的AlphaGo擊敗圍棋世界冠軍李世石,人工智能的深度學習展現出了極大的潛力。
雖然人工智能目前已經可以擊敗圍棋世界冠軍,但讓人工智能實現汽車自動駕駛仍然十分困難。要實現汽車自動駕駛,計算機需要判斷哪里是路,哪里是障礙,這些對人類非常直觀的東西對計算機卻是相當困難,這是因為人類有最重要的感知系統——視覺。人類大腦中幾乎一半的神經元與視覺有關,視覺系統主要解決的是物體識別、物體形狀和方位確認、物體運動判斷這3個問題。人類能通過視覺從復雜結構的圖片中找到關注重點,在幽暗的環境中認出熟人。但由于主觀及客觀條件的影響,導致許多信息無法被人類視覺系統準確獲取,于是便產生了計算機視覺(computer vision,CV)[3]。隨著信息時代的到來,大量圖像和視頻數據的產生,計算機視覺已成為人工智能最重要和發展最快的研究領域之一。
計算機視覺是一個跨領域的交叉學科,通過計算機模擬人的視覺系統,實現人的視覺功能,以適應、理解外界環境和控制自身的運動。計算機視覺能夠增強、改善人們的生活,代替人類完成更多的任務:一方面,它為人類自身視覺提供強有力的輔助和增強,極大地改善人與世界交互的方式,如通過圖片搜索引擎找到與之相關信息;另一方面,機器可以準確、客觀而穩定地看見,突破人類視覺的局限,代替人類完成更多的任務,如24h不間斷、不疲倦地進行場景監控。
人工智能基礎架構如圖1所示,計算機視覺賦予機器“看”和“認知”的功能,是人工智能的一類基礎應用技術,它與語言識別[4]、語音識別[5]一起構成人工智能的感知智能,讓機器完成對外部世界的探測,進而做出判斷,采取行動,讓更復雜層面的智慧決策、自主行動成為可能。基于深度學習算法模型和CPU、GPU等關鍵硬件的支撐,計算機視覺技術應用得以實現,并最終集成于多類產品和應用場景之中,目前計算機視覺正應用于車輛交通檢測[6]、智慧工業[7]、農業自動化[8]等多個領域。
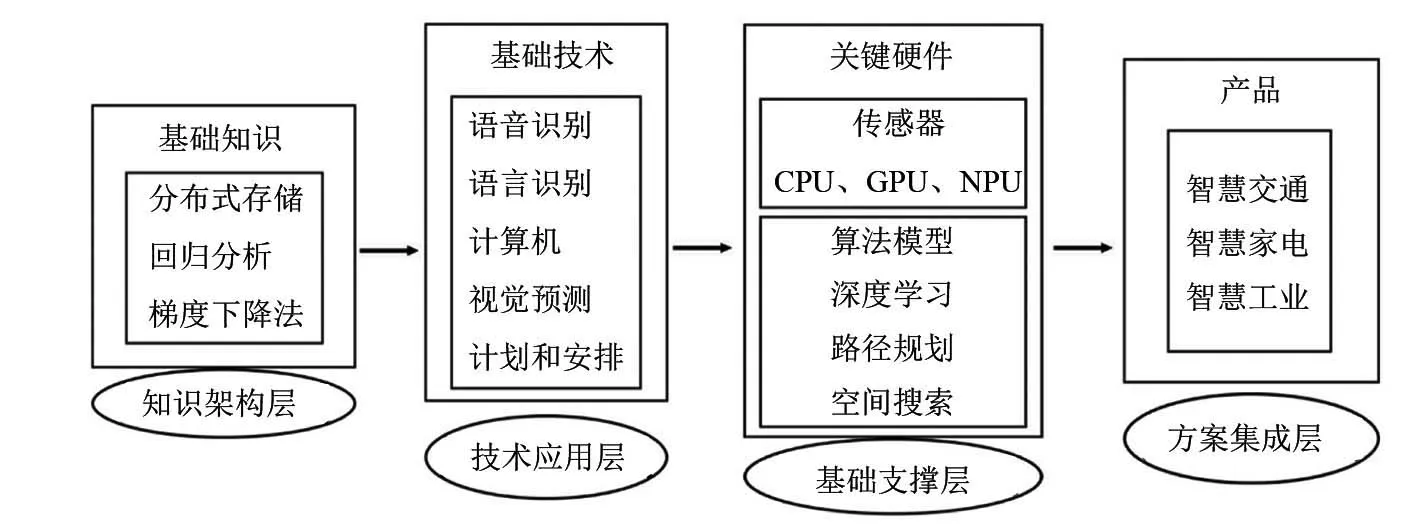
圖1 人工智能基礎架構
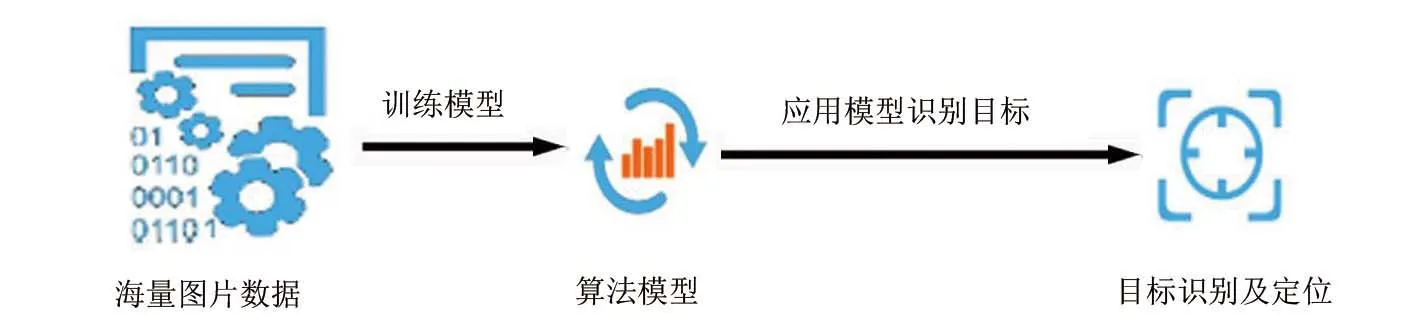
圖2 目標檢測流程
作為圖像理解和計算機視覺的基石,目標檢測(object detection)是計算機視覺中真正核心的任務,也一直都是一個活躍的研究領域。目標檢測流程如圖2所示,目標檢測不是簡單的將圖像分類,是將目標定位和目標分類結合起來,通過海量而優質的圖片數據訓練算法模型,從而實現機器判斷出輸入圖像中具有所需特征的物體,并且確定目標物體的位置與范圍。其準確性和實時性是整個系統的重要指標。然而,這其中有很多難點,如視角、不同照明條件、可變型、遮擋、圖片背景混亂、類內差異,算法需要處理這些難點,這是具有挑戰性的難題。
傳統的目標檢測算法[9]多是通過在輸入圖像中滑動一個固定大小的窗口,將窗口中的子圖像作為候選區,使用尺度不變特征變換(Scale-Invariant Feature Transform,SIFT)[10~12]、方向梯度直方圖(Histogram of Oriented Gradient,HOG)[13~15]、Haar[16]提取特征,再使用訓練完成的分類器進行分類,如部位形變模型(Deformable Part Model,DPM)[17~20]、支持向量機(Support Vector Machine,SVM)模型[21]等。但是,由于傳統目標檢測主要存在的2個缺陷(基于滑動窗口的區域選擇策略的針對性不強,導致時間復雜度提高,窗口冗余;設計的特征難以應用于多目標檢測),使得其目標檢測的準確性達不到實際需求。為促進計算機視覺的發展,從2009年開始,ImageNet團隊組織了ImageNet大規模視覺識別大賽,其中具有7層的AlexNet卷積網絡[22]在2012年度的大賽中以絕對的優勢取得冠軍,其效果遠超傳統算法,將大眾的視野聚集到了卷積神經網絡(Convolutional Neuron Networks,CNN)。
從2012年到2015年,通過對深度學習算法的不斷研究,ImageNet圖像分類的錯誤率以4%的速度遞減,這說明深度學習算法完全打破了傳統算法在圖像分類上的瓶頸,讓圖像分類問題得到了更好的解決。到2015年時,深度學習算法的錯誤率為4.94%,已經成功超越了人工標注的錯誤率(5.1%),實現了計算機視覺研究領域的一個突破。
2 目標檢測算法——卷積神經網絡的基本結構

圖3 LeNet-5模型
一個簡單的卷積神經網絡是由各種層按照順序排列組成,主要由輸入層、卷積層、池化層、全連接層、輸出層組成。通過將這些層疊加起來,就可以組成一個完整的神經網絡。由加拿大多倫多大學LeCun教授提出的LeNet-5網絡[23]如圖3所示,該模型由8層網絡結構構成,除輸出層外,其余每層都有訓練參數。
卷積層是構建卷積神經網絡的核心層,它產生網絡中大部分的計算量。卷積層越多,特征的表達能力就越強。卷積核是卷積層的重要組成,其作用是對輸入圖像的深層信息進行提取。輸入圖像大小為32×32(像素),卷積核大小為5×5(像素),采用滑動窗口的方法對圖像進行卷積,得到的特征圖大小為28×28(像素)。特征圖之間是相互聯系的,上層特征圖會影響下一層特征圖。
(1)
常用的激活函數為sigmoid函數和tanh函數:
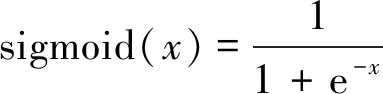
(2)
(3)
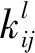
通常,在連續的卷積層之間會周期性地插入一個池化層。池化層的作用是逐漸降低數據體的空間尺寸,減少網絡中參數的數量,使得計算資源耗費變少,也能有效地控制過擬合。一般池化層可以通過以下方式計算:
(4)

圖4 卷積和池化過程
式中:d(x)為池化操作,一般是進行最大池化操作,它是將輸入的圖像劃分為若干個局部區域,對每個局部區域輸出最大值。池化層會不重疊地選擇局部區域,再次計算出圖像重要的特征值。經過圖像的二次特征提取,池化層降低了空間尺寸,提高了抗畸變的能力。卷積和池化操作如圖4所示。卷積過程為:利用卷積核fx卷積圖像,再加上偏移量bx,最后得到特征圖。池化過程為:最常用的降采樣操作是取最大值,這里使用的是尺寸為2×2大小(像素)的濾波器,每個取最大值操作是從4個數字中選取(即2×2的方塊區域中)。
全連接層在整個卷積神經網絡中起到“分類器”的作用,全連接層位于提取特征之后,全連接層將上一層的所有神經元和當前層的每個神經元相互連接,將局部特征結合成全局特征。
全連接層的一般形式為:
xl=f(wlxl-1+bl)
(5)
式中:wl表示全連接層的權重;bl表示全連接層的偏移量;函數f(x)表示非線性激活函數,即sigmoid函數或tanh函數。
3 基于候選區域的卷積神經網絡的發展
3.1 R-CNN
由Girshick等提出的R-CNN是將卷積神經網絡用于目標檢測的開端[24]。圖5是R-CNN進行目標檢測步驟。首先是利用Selective search方法[25]從輸入圖片中預測目標可能出現的位置,生成若干個候選區域;然后將每個候選區域轉換為固定大小并使用卷積神經網絡對其提取特征;最后使用SVM分類器對特征進行分類,并通過邊界回歸得到精確的目標區域。
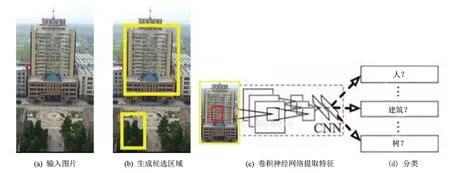
圖5 R-CNN目標檢測流程圖
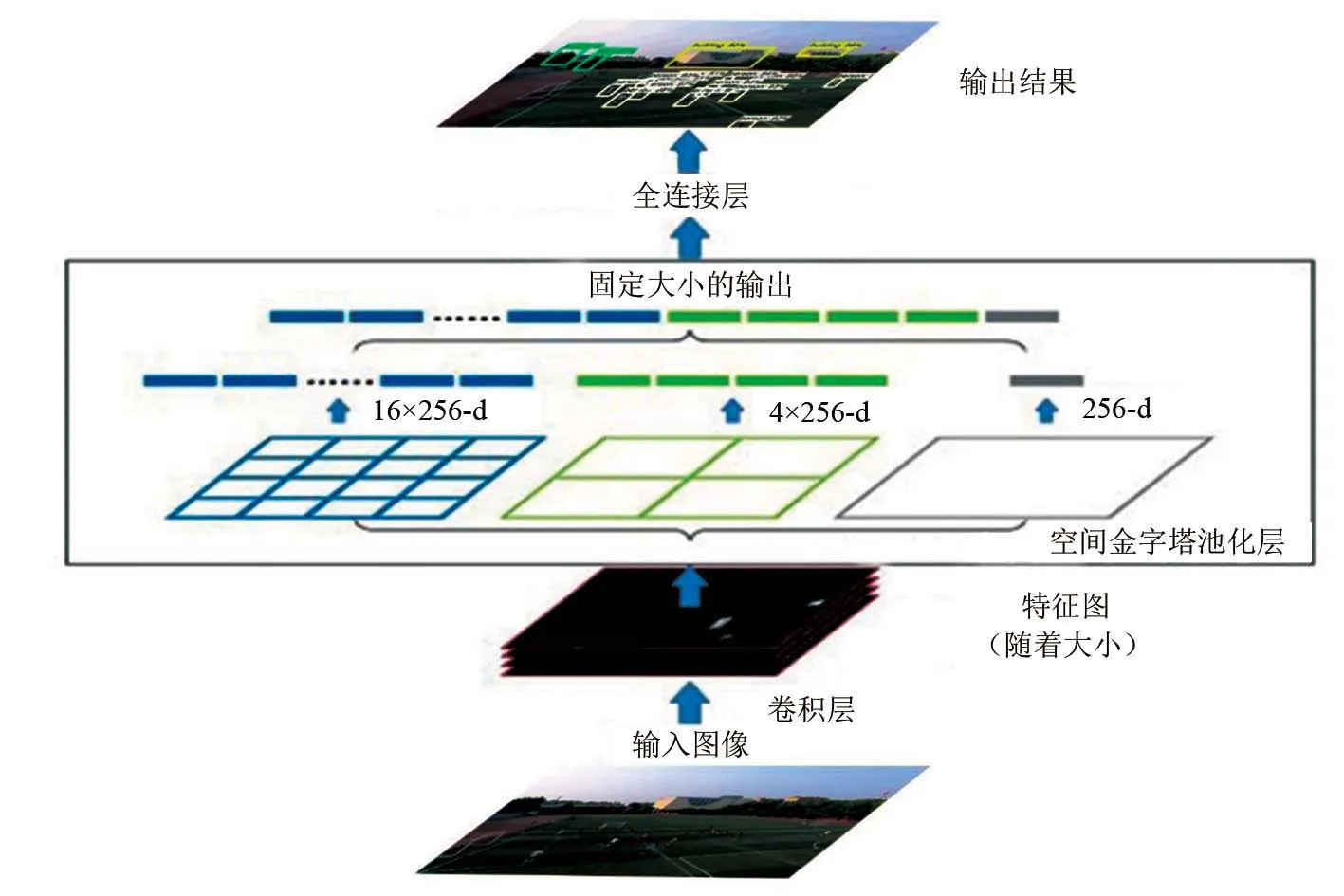
圖6 空間金字塔池化層工作過程
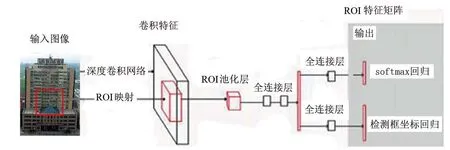
圖7 Fast R-CNN目標檢測流程
雖然R-CNN較傳統的CNN在目標檢測方面準確性更高,但實時性達不到實際需求,其原因是:①訓練分為多個階段,微調卷積神經網絡,對SVM分類器進行訓練,對邊界回歸器進行訓練,訓練空間和時間代價很高;②多個候選區域對應的圖像需要預先提取,占用較大的磁盤空間,R-CNN對每個候選區域都放入卷積神經網絡進行特征提取,計算量巨大。
3.2 SPP-net
卷積神經網絡需要輸入固定大小的圖像尺寸(如224×224)才能進行特征提取和特征分類。為了卷積神經網絡能夠處理任意尺寸和比例的圖像,何愷明等[26]提出了空間金字塔池化層(Spatial Pyramid Pooling,SPP)。空間金字塔池化層工作過程如圖6所示。通過將空間金字塔池化層替換掉全連接層之前的最后一個池化層,有效解決了R-CNN需要對每一個候選區域獨立計算的問題,該網絡結構稱為SPP-net。
空間金字塔池化層工作過程為:輸入圖像在卷積層中進行特征提取,得到一個隨意大小的特征圖,接著在空間金字塔池化層中把特征圖分成不同大小的空間塊,如4×4、2×2、1×1,在每個空間塊中進行一次最大池化。池化后的特征拼接得到一個k×w維的固定維度向量(k為最后一層卷積層的卷積核數量,w代表空間塊的數目), 這個固定維度的向量就是全連接層的輸入。雖然SPP-net在檢測速度上大大提高,但是SPP-net仍然存在著同R-CNN一樣的問題:訓練分為多個階段,步驟繁瑣。
3.3 Fast R-CNN
由Girshick提出的Fast R-CNN[27]修正了R-CNN和SPP-net的缺點,同時提高其速度和準確性。圖7是Fast R-CNN目標檢測流程。
Fast R-CNN目標檢測的過程為:整個網絡首先會使用多個卷積層和池化層來處理輸入圖像,產生特征圖。對每一個候選區域,用ROI池化層從特征圖中提取出固定長度的特征向量。然后特征向量將被送入一系列全連接層中,這將分支成2個同級輸出層:一個使用softmax輸出N個類別的概率估計,另一個輸出N個類別的檢測框坐標,修正邊界位置。
ROI是卷積特征圖中的一個矩形窗口,ROI池化層是對任何有效的ROI卷積特征圖通過最大池化轉換成固定空間范圍(H×W)的小特征圖,其中H和W是層的超參數,獨立于任何一個ROI。如一個尺寸大小為h×w的ROI窗口分割成H×W個網格,那么子窗口大小需要劃分為(h/H)×(w/W),然后對每個子窗口進行最大池化,得到相應的輸出。ROI池化層其實只是SPP-net中使用的空間金字塔池化層的特殊情況,只有一個金字塔層。
Fast R-CNN網絡主要有以下優點:①訓練使用多任務損失函數的單階段訓練,實現端到端的訓練過程;②訓練可以更新所有網絡層參數;③不需要額外的磁盤空間來緩存特征。其主要缺點在于,使用selective search算法提取候選區域,使得目標檢測時間大多消耗在提取候選區域上,實時性無法滿足實際需求。
3.4 Faster R-CNN
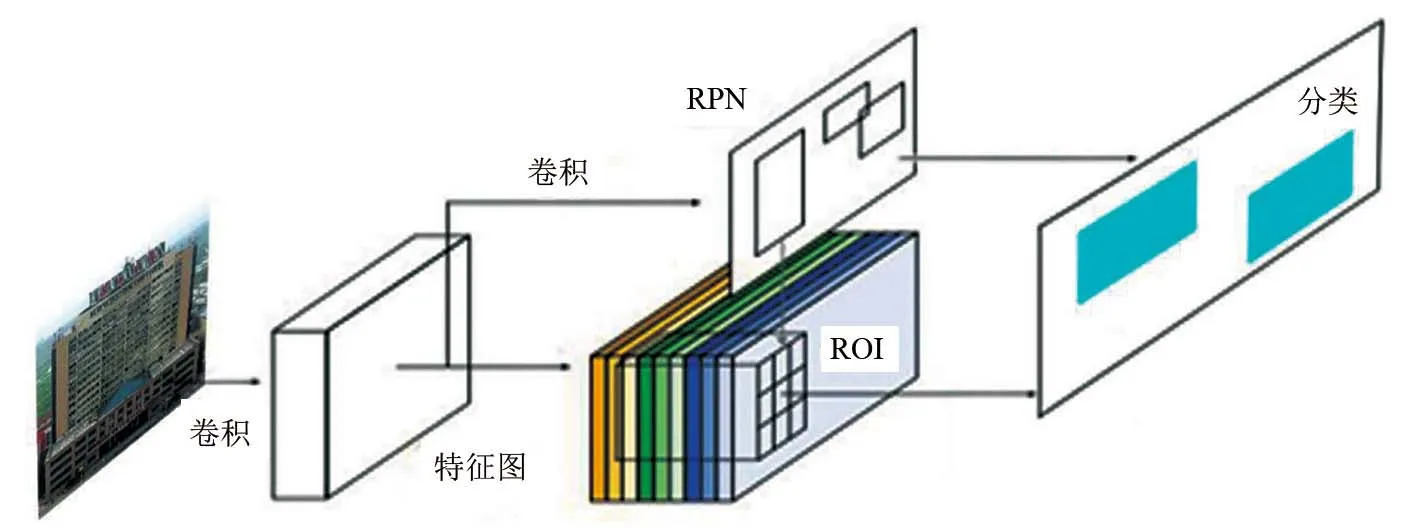
圖8 RPN網絡結構程
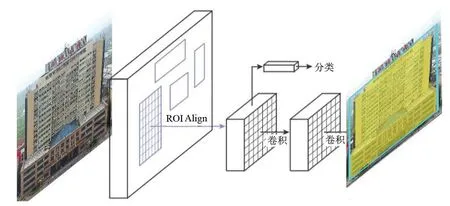
圖9 Mask R-CNN實例分割框架
R-CNN和Fast R-CNN都是使用selective search算法提取候選區域,但候選區域生成速度慢,特征層次較低,生成的候選區域質量不高。因此,任少卿等提出了Faster R-CNN[28],主要由區域建議網絡(Region proposal -network,RPN)候選框提取模塊和Fast R-CNN檢測模塊2個模塊組成。
RPN網絡結構如圖8所示。對于任意大小的圖像輸入到RPN中,都可以生成高質量的區域建議框。RPN網絡中使用一個3×3的卷積核,采用滑動窗口機制,在最后一個共享卷積層參數的特征圖上滑動,以滑動窗口的中心對應位置映射回輸入圖像,預設3種尺度和3種長寬比,這樣在特征圖的每一個位置都對應著9個錨框。如果特征圖的大小是H×W,則一共有H×W×9個錨框,采用滑動窗口能夠關聯特征圖的全部特征空間,使得RPN提取的候選區域更加準確。之后再連接2個同級的1×1卷積層,其中一個使用softmax分類輸出錨框目標和背景的分數,另一個用于輸出錨框對應于真實目標邊界框的回歸偏移量。通過這2個輸出對錨框進行初步篩選和初步偏移,最終得到候選區域。
3.5 Mask R-CNN
為了實現實例分割,何愷明等[29]提出了Mask R-CNN。該模型在Faster R-CNN的基礎上增加了第3個模塊——目標掩碼模塊。Mask R-CNN實例分割框架如圖9所示。
ROI池化層在進行歸一化過程中,會導致ROI和提取的特征之間產生錯位,因此Mask R-CNN模型使用ROI Align層替代了ROI池化層。ROI Align層采用了雙線性內插法,根據ROI中的4個采樣點計算輸入特征的精確值并匯總結果,對提取的特征和輸入之間進行了校準。
Mask R-CNN定義了一個多任務損失函數L:
L=Lcls+Lbox+Lmask
(6)
式中:Lcls是分類誤差;Lbox是真實目標邊界框回歸誤差;Lmask是分割誤差。對于每一個ROI,掩碼分支都有一個Km2維的矩陣輸出,即K個類別在分辨率為m×m上的二進制掩碼。對于每一個像素,都是采用sigmoid函數求得平均二值交叉熵損失函數,即Lmask。對于僅與第K類相關聯的ROI,Lmask僅在第K個上定義掩碼,避免了不同類別掩碼之間的影響,有效增強了實例分割的效果。
4 算法性能對比
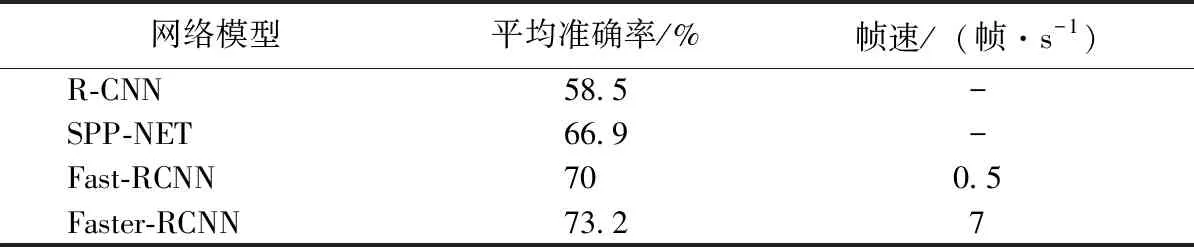
表1 基于候選區域的深度卷積網絡在目標檢測方面的性能對比
基于候選區域的深度卷積網絡在目標檢測方面的性能對比如表1所示,Faster-RCNN在準確性和實時性上遠遠超越其余模型,而Mask R-CNN在性能上與Faster R-CNN差別不大,因為Mask R-CNN主要用于掩碼輸出,故表1中未標注Mask R-CNN。
5 結語
傳統的目標檢測任務使用滑動窗口的框架,把一張圖分解成幾百萬個不同位置不同尺度的子窗口,針對每一個窗口使用分類器判斷是否包含目標物體,這有極大的局限性。近年來,基于候選區域的深度學習目標檢測算法飛速發展,從最初的R-CNN到現在的Mask R-CNN,其準確性和實時性比傳統的目標檢測有極大的突破,同時還在實例分割方面達到了目前最高的水準,但是距離廣泛地實際應用還有一段差距。除此之外,還產生了基于回歸的深度學習目標檢測YOLO[30]、SSD[31]系列算法。R-CNN系列算法和YOLO、SSD系列算法為研究深度學習目標檢測提供了2種基本框架。以下是基于深度卷積神經網絡的目標檢測的研究熱點:
1)多層網絡特征融合[32]。傳統的卷積神經網絡就是把輸入圖像一層一層地進行映射和過濾,其中最后一層的特征就是最后的結果。在此過程中,不同的卷積神經網絡層提取的特征是不相同的,淺層網絡提取的大多是層次信息,最深層的網絡得到的則是更加抽象的語義信息,所以傳統的卷積神經網絡只是利用最深層網絡提取出的特征信息來構建分類器,過濾掉淺層網絡的特征信息,因此需要更有效地解決多層網絡特征融合來增強模型算法對圖像的表現能力。
2)合理利用有效感受野。感受野是指卷積神經網絡中神經元對應輸入圖像的區域,即特征輸出受感受野區域內的像素點的影響。當對輸入圖像中的每個像素進行預測時,每個輸出像素具有大的感受野是至關重要的,這會使重要的信息在預測時不被遺漏。有效感受野即是感受野在預測時作用較大的區域,它具有高斯分布,且僅占整個理論的感受野很小的一部分。有效感受野對卷積神經網絡的深度工作非常重要,如果有效感受野在目標中占有的面積很大,則目標檢測中該神經元的效果好。
3)利用上下文關聯信息。目標檢測在實際應用中目標不可能是一個獨立存在的個體,它或多或少會與周圍其他的對象或者環境有一定關系,這就是上下文關聯信息。機器需要通過捕捉不同的對象之間的相互作用信息,依此來對新目標進行檢測。上下文關聯信息能提高識別的準確度和精確度。但是想要將其廣泛應用于實踐之中仍有很多問題需要解決,因此有效利用上下文關聯信息還是如今研究的熱點。
總而言之,基于深度卷積網絡的目標檢測依舊是一個充滿了挑戰性的課題,其研究意義和應用價值十分重要。隨著更多更全面的數據集和各種開源深度學習框架的出現,該課題將會更加快速地發展。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
中國科技博覽(2016年2期)2016-04-25 20:32:39
小學生導刊(2016年34期)2016-04-11 00:49:44
電測與儀表(2015年5期)2015-04-09 11:30:52
