基于帶有噪聲輸入的稀疏高斯過程的人體姿態估計
2019-06-22 07:42:20夏嘉欣陳曦林金星李偉鵬吳奇
自動化學報 2019年4期
關鍵詞:模型
夏嘉欣 陳曦 林金星 李偉鵬 吳奇
人體姿態估計是利用圖像特征來估計各個人體部位在圖像中的具體位置的研究過程[1],是一種應用廣泛的結構化預測問題.由于人體姿態估計在視覺跟蹤、計算機動畫[2]以及智能監控、虛擬現實[3]等領域均有廣泛的應用,因此,在過去幾十年中,關于人體姿態估計問題的解決方法層出不窮.
高斯過程(Gaussian process,GP)[2?5]及其變體[6]是一種典型且有效的人體姿態估計方法.作為一種常見的基于貝葉斯概率論進行預測的回歸方法,高斯過程因其對非線性、高維、復雜和小樣本問題的靈活性、有效性[4]及泛化能力強,被廣泛應用于各個領域.然而,人體姿態估計本身通常需要較大的樣本集,所以簡單地將高斯過程的基本模型應用于此類問題會耗費大量的運行時間與運算空間.同時,由于高斯模型本身對于噪聲影響缺乏較高的魯棒性,而人體姿態估計等高維預測問題在實際應用中本身就將受到大量的噪聲干擾,傳統高斯模型的預測準確性也將受到影響.因此,對于大樣本問題預測的計算復雜度和對于噪聲輸入的預測準確性,成為制約高斯過程應用于人體姿態估計問題的重要因素.但是,人體姿態估計作為一種非線性多元輸入輸出的擬合問題,由于其輸入輸出變量的高維性,該問題的預測模型本身就需要解決模型較為復雜、模型參數較多、超參數難以確定等種種問題.而與當前更為主流的預測算法相比,高斯過程具有模型容易實現,參數復雜性低,超參數自適應獲取,無需海量訓練數據,以及輸出具有物理意義等突出優點,這些優點注定了高斯過程在解決非線性高維預測問題方面的巨大優勢與潛力.因此,若能同時改善計算復雜度與噪聲魯棒性這兩項缺陷,那么高斯過程將在解決人體姿勢估計,乃至所有多元輸入輸出問題方面,發揮更加重要的作用,產生更加深遠的影響.
基于上述原因,計算復雜度是高斯過程應用于人類姿態估計的一個重要的考慮因素.稀疏高斯過程、混合專家模型[7?8]、增量式學習[9?10]方法等均是有效降低高斯過程計算復雜度的方法.其中,稀疏高斯過程最為常用.該方法的本質為使用一組誘發輸入(Inducing input)部分替代原輸入進行假設[11]與訓練.應用常規的高斯過程回歸(Gaussian process regression,GPR)需要O(n2)的存儲空間和O(n3)的運行時間,其中n是訓練點的數量.由于人體姿態模型包含了數以千計的高維數據點,因此其計算復雜度超乎想象.然而,如果運用稀疏高斯過程解決問題,則存儲空間將減少到O(nm),而運行時間則將減少到O(nm2),其中m是誘發輸入點的個數.由于m?n,空間和時間成本得以顯著降低.本文將采用稀疏算法中的一種較為優秀的算法:完全獨立訓練條件(Fully independent training conditional,FITC)[12]法,來降低人類姿態估計問題中高斯回歸的計算復雜度.
輸入輸出噪聲是高斯算法的另一個重要考慮因素.對于高斯回歸的噪聲研究始于很早之前,但在大約十年前,噪聲才被擴展到應用于解決大規模和高維輸入輸出[13]的問題.對于測試輸入樣本的噪聲,可通過矩匹配的方法進行解決,而對于訓練輸入樣本的噪聲,先前的方法具有較高的計算復雜度.為了解決這一問題,McHutchon等[14]在2011年提出了一種全新的算法,本文將應用該方法來處理人體姿態估計問題中的輸入噪聲.
早在1975年,人體關節模型就已經被證明包含有豐富的信息,并可用于行為識別.此后的幾十年,眾多研究人員均致力于三維人類姿態的重建[15?16]與信息提取[17?19],幾乎所有的經典模型如高斯過程、支持向量機、人工神經網絡等,都已經被成功且成熟地應用于人體姿態估計問題.因此,在近幾年有關該問題的研究中,更多的人著眼于通過提出更加新穎而復雜預測模型來提高人體姿態估計的預測精度[3,20?21],或通過在現有算法中加入新的優化模型形成混合模型來提升算法性能[1,22],但著眼于從單個已成熟模型本身的數學機理出發,通過改進其數學模型來提高人體姿態估計算法性能的研究則少之又少.模型的數學原理是預測模型的根基,從經典模型的數學原理角度對模型進行優化,不但保證了模型的穩定性與可推廣性,還可以達到比參數優化更好更徹底的優化效果.因此,本文從高斯過程本身的數學原理出發,利用稀疏算法與帶有噪聲輸入的算法這兩種優化方法進行模型改進,并將改進后的模型應用于三維人體姿態估計問題,在降低計算復雜性的同時,也使得算法在輸入噪聲的影響下獲得更好的預測精度.相較于現有算法而言,本文算法具有更強大的數學基礎與泛化能力,可以推廣應用于多種結構化預測問題.
本文結構安排如下:第1節對人體姿態估計問題進行描述;第2節介紹了高斯過程的模型,包括標準高斯過程;第3節介紹帶噪聲輸入的稀疏高斯算法,同時對該算法的合理性和優越性進行簡單驗證.第4節將本文算法與其他預測效果較好的人體姿態估計算法應用于HoG樣本集[17],并對預測結果進行比較與評估.第5節為結論.
1 問題描述
人體姿態估計是人體動作與行為的識別與分析的一個基礎問題[22].由于其在人機交互[23]、人體活動分析和視頻監控等領域都有著廣泛的應用前景[20],因此關于人體姿態估計的方法也層出不窮.在現有的人體姿態估計的算法中,基于模型的方法更被研究者關注.該方法的主要思路是通過建立數學模型來描述人體特征與空間位置,并度量人體部位可能定位區域與真實人體部位外觀的相似程度,從而獲得標準的輸入輸出集,然后設計推理算法來確定相似度較高且符合人體模型約束的各部位定位區域[1].
在實際問題中,實驗個體所處環境往往比較復雜,會很大程度上增加外觀模型的建立難度,因此,選取適當且有效的圖像特征來簡化模型建立過程十分重要.本文考慮選取比較典型的方向梯度直方圖特征(Histogram of oriented gradients,HoG).HoG特征計算的主要過程為:1)計算圖像每個像素的梯度大小和方向,劃分圖像;2)將若干像素組成一個單元(Cell),統計每個單元的梯度直方圖,形成每個單元的特征描述;3)將若干單元組成一個塊(Block),將每個塊內所有單元的特征描述串聯,得到每個塊的HoG特征描述;4)將圖像內的所有塊的HoG特征描述串聯,得到整個圖像的HoG特征.HoG不是考察圖像的單個像素的特征,而是通過計算局部區域中的定向梯度直方圖以形成圖像特征,因此對光線和小幅度的位置偏移并不敏感.
由于HoG特征在人體姿態估計領域具有十分優秀的特征描述能力,近年來使用HOG特征實現人體檢測與估計系統成為研究熱點[24].本文的研究重點在于預測算法的提出與優化,而非特征模型的建立,因此,本文借用Poppe[17]基于Sigal等提出的HumanEva-I[16]數據庫建立的人體姿態HoG特征樣本集進行仿真實驗與分析.
HumanEva-I是一個由視頻序列組成的數據庫,該數據庫中的視頻序列由3個不同視角下的攝相機獲取,包含4名受試者的6種常見的行為.
在本文算法中,定義輸入變量X=(x1, X2,···,xN)T,輸出變量Y=(y1,y2,···,yN)T,輸入輸出均為高維變量,其中,N為樣本個數,X為D維向量,y為E維向量.HoG特征輸入樣本集X的建立過程如下:以單個攝相機獲取的單幀圖片為例,1)將圖片進行背景刪除、二值化、提取興趣區域(Region of interest,ROI)等預處理操作;2)將ROI區域劃分為5行6列的30個網格,每個網格統計出9個HoG特征,并將30個網格的HoG特征串聯,得到單一視角下的270維HoG特征;3)將3個視角下的特征串聯,形成810維HoG特征描述,該特征即為輸入集X下的單個樣本x.輸出變量樣本集Y下的單個樣本y是由20個三維身體關節位置坐標組合成的60維向量,代表在x描述下的人體姿態模型.
2 高斯過程模型
2.1 高斯過程標準模型
高斯過程是一種基于貝葉斯線性回歸產生的一種回歸模型.與其他常用的預測算法相比,高斯過程具有容易實現,超參數自適應獲取等優點.
回歸過程,簡單來說就是根據訓練集Xm與Ym之間的映射關系,預測新的測試點X?最有可能的對應輸出值Y?的過程.高斯回歸是在貝葉斯線性回歸的基礎上,把自變量空間通過核函數映射到高維空間,從而得到更好的預測結果的過程.
在高斯過程回歸中,時間域上所有隨機變量均服從高斯聯合分布,其性質完全由均值函數和協方差函數確定.在實際觀測中,觀測值可能會受到噪聲污染,假設噪聲變量服從,輸出樣本集Y的先驗分布可以表示為
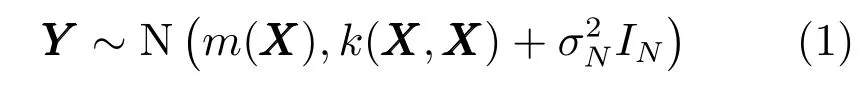
因此,已知的訓練輸出值Ym與未知的測試輸出值Y?的關系可以表示為

其中,Xm表示訓練輸入值,X?表示測試輸入值,m(X)表示X的均值函數,k(X,X')表示X與X'協方差函數,K??,K?m,Km?,Kmm分別是K(X?,X?),K(X?,Xm),K(Xm,X?),K(Xm,Xm)的簡寫形式.
由于變量Ym已知,因此由貝葉斯公式可知,后驗傳遞函數p(Y?|Ym)為
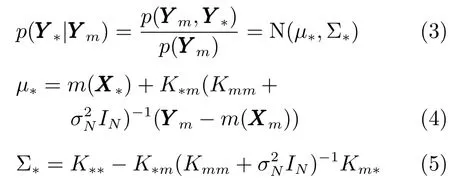
其中,p(Ym,Y?)為先驗傳遞函數,p(Y?|Ym)為高斯函數.
由式(3)~(5)可知,由于時間域上所有隨機變量均服從聯合高斯分布,因此該高斯過程可以被均值函數m(X)和協方差函數k(X,X')共同唯一決定.同時,k(X,X')被稱為從低維空間到高維空間映射的核函數.在高斯過程中,常用的核函數有常數核(Constant function)、線性核(Linear function)、徑向基核(Radial basis function)等,本文采用的協方差函數為平方指數協方差函數(Squared exponential correlation function),即
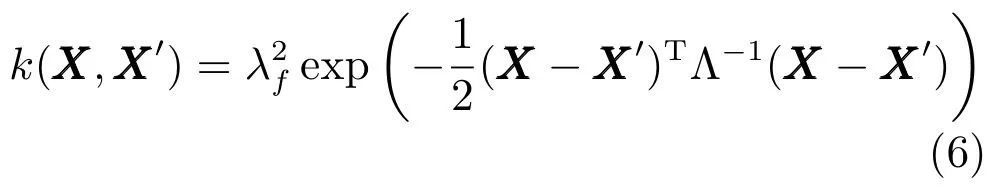
1)建立訓練樣本條件概率的負對數似然函數及其關于θ的偏導數.
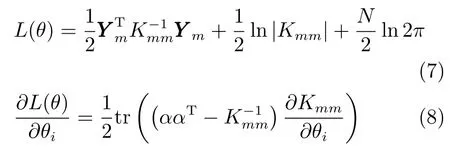
其中,Ym為訓練樣本集,Kmm為訓練樣本協方差函數,N為訓練樣本數,i為超參數集的第i個元素.
2)采用梯度下降法對偏導數進行優化,通過規定的迭代次數,得到超參數的最優解.
2.2 稀疏高斯過程
稀疏高斯過程是通過選取一定數目的誘發輸入點來部分代替原輸入點進行訓練,從而降低運算復雜度的方法.
在本文實驗中,由于輸出變量yi(1≤i≤N)彼此之間相互獨立,符合完全獨立訓練條件(FITC),因此,在各種變量假設均與前文相同的基礎上,同時假設Y變量彼此之間相互獨立,即
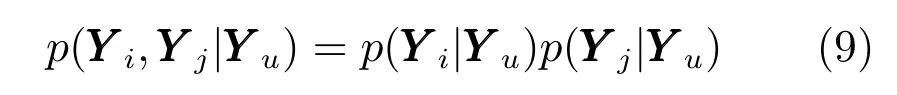
其中,,且與Yu是誘發輸入與輸出.該條件即為完全獨立條件.在該條件下,先驗傳遞函數可表示為
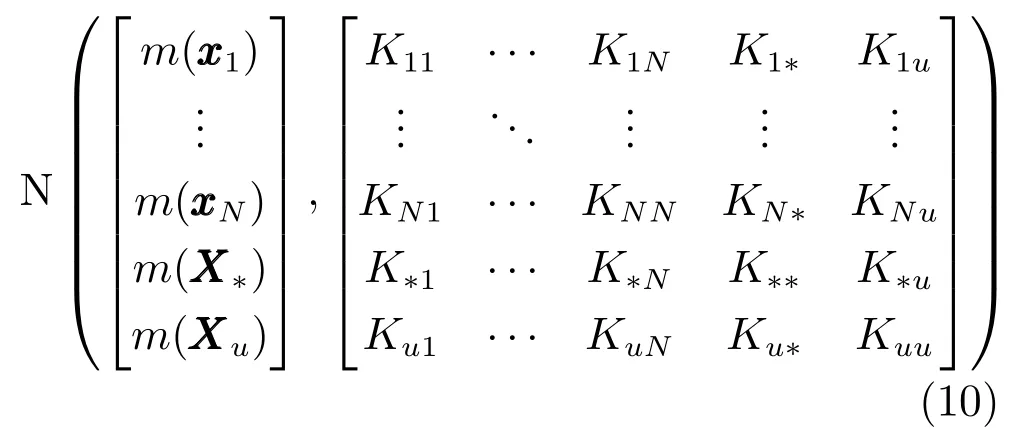
其中,對于每個1≤i≤N而言,,.
在此處,定義Qac為
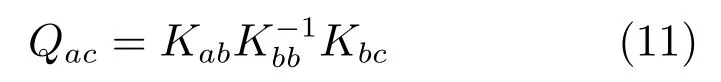
其中,
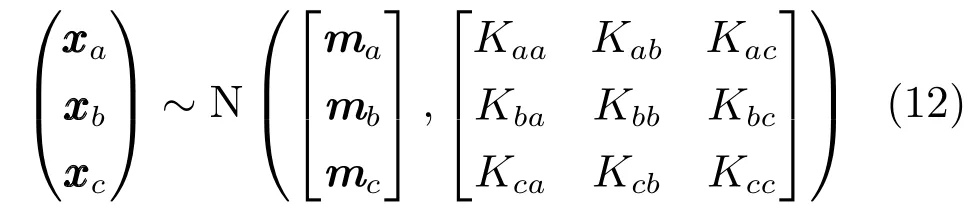

證明.首先,考慮c在給定的xb下的條件分布函數.以xa為例:

由于均值向量與協方差矩陣均已知,因此可以得到xa與Xb的聯合概率分布.同時,通過積分求得邊緣分布.因此,變量Xa在給定的xb下的條件概率的協方差為

同理,變量Xc在給定的xb下的條件概率的協方差為
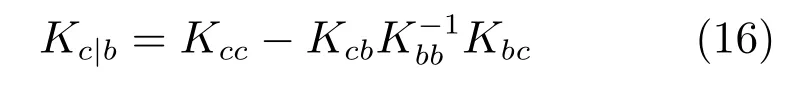
求Xa與xc在Xb條件下的聯合概率分布,可得其協方差矩陣為

因為xa與xc關于給定的Xb條件獨立,所以,即,.
□
通過上述證明過程,可以將式(10)改寫為
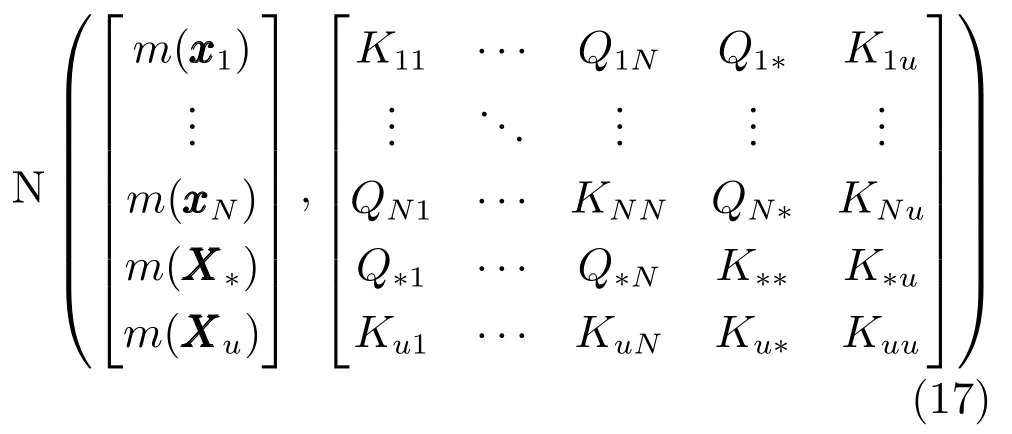
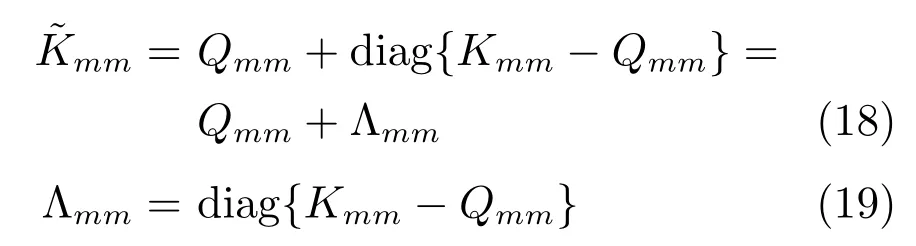
則Yu的后驗傳遞函數可以表示為
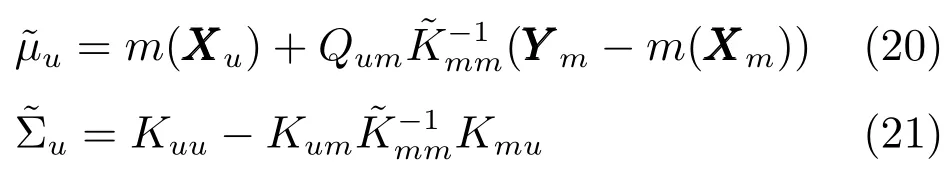
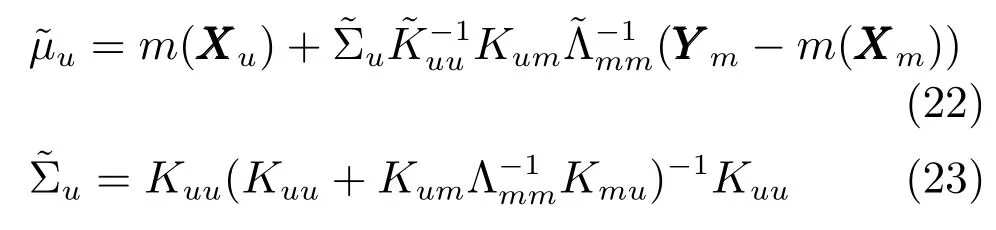
所以,Y?的后驗傳遞函數為
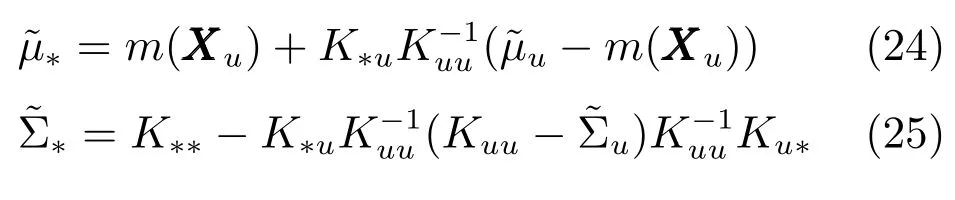
從上述等式可以看出,我們需要計算一個n×n的矩陣Λmm與幾個m×m矩陣的逆矩陣.由于m?n,并且Λmm為對角陣,因此算法的計算復雜度得到了明顯的改善.
如果假設輸入變量X服從零期望值的高斯分布,則其后驗分布函數可以表示為
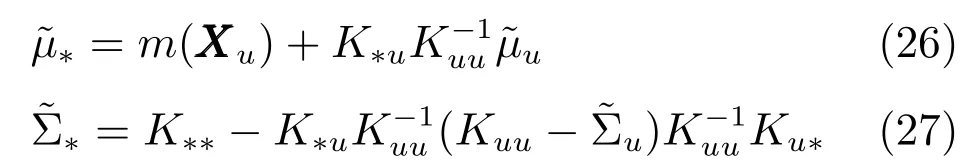
2.3 帶有噪聲輸入的高斯過程
在標準的高斯過程中,常常存在兩個假設:其一是訓練和用于測試的輸入值Xm和X?均為無噪聲的;其二是觀測輸出值Ym受到一個均值為零,協方差為常數的高斯噪聲ε的干擾.但是在實際測量中,Xm和X?卻并非是無噪聲的.也就是說,輸入值X并非某個確定的值,而是一個隨機變量.
2.3.1 測試輸入點為隨機變量
由前文可知,當測試輸入點X?為確定值時,后驗傳遞函數p(Y?|Ym)表達式如式(3)~(5)所示.
但現在假設X?并非確定值,而是一個服從高斯分布的隨機變量,即
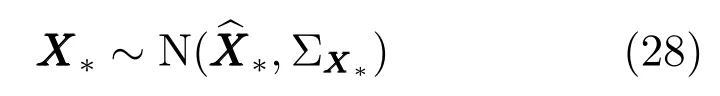
若在此條件下得到Y?的后驗分布,最直觀的方法是運用邊緣概率密度與積分進行計算.但是,在這一過程中,不但需要計算帶有逆矩陣的指數的積分,同時以上計算過程的結果還由一個非線性的隨機變量X?決定,因此計算過程太過復雜,無法直接計算出積分結果.
為了解決積分計算過于復雜的問題,本文采用矩匹配(Moment matching)的方法,規定p(Y?)服從高斯分布,通過求取其均值與方差來確定預測點Y?的值.

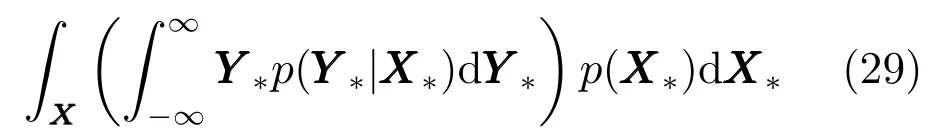
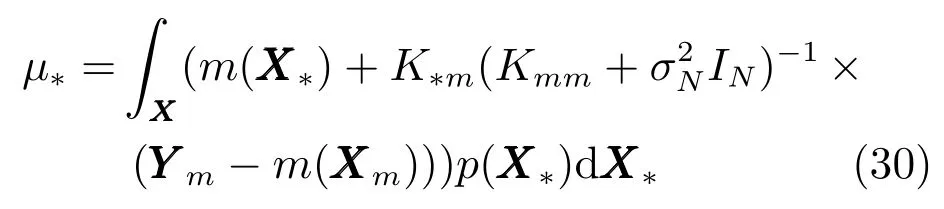
為簡化上式,定義
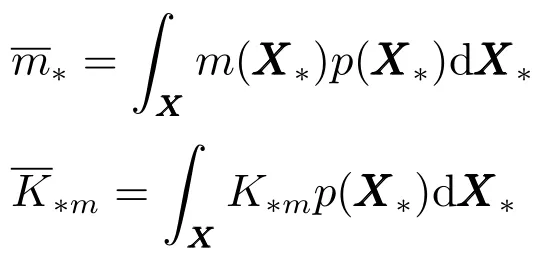
則式(30)可以改寫為
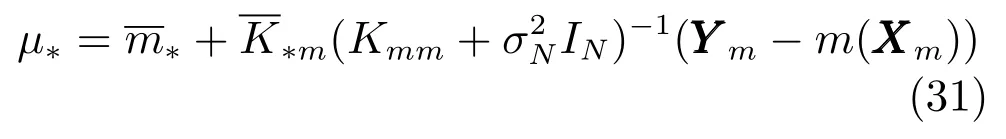
若假設m(X)=0,且協方差函數K為式(6)形式的平方指數協方差函數,則可以表示為
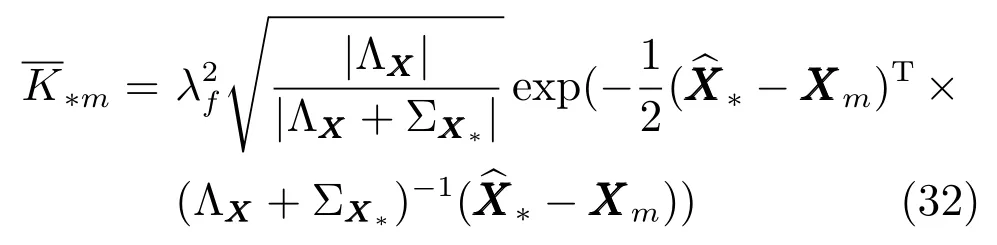
觀察上式可以發現,若X?為確定值,即且,則,此時式 (31)與式(4)相等.
2.3.2 訓練輸入點為隨機變量
同第2.3.1節,假設Xm并非確定值,而是一個服從高斯分布的隨機變量,即
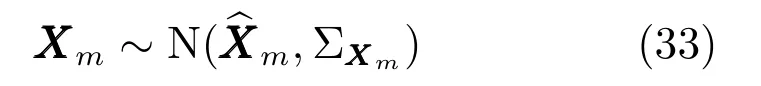
若在此條件下運用邊緣概率密度與積分計算Y?的后驗分布,則會遇到與第2.3.1節相同的問題,計算過程太過復雜,無法直接計算出積分結果.假如將第2.3.1節中的矩匹配方法應用于此處,可以得到
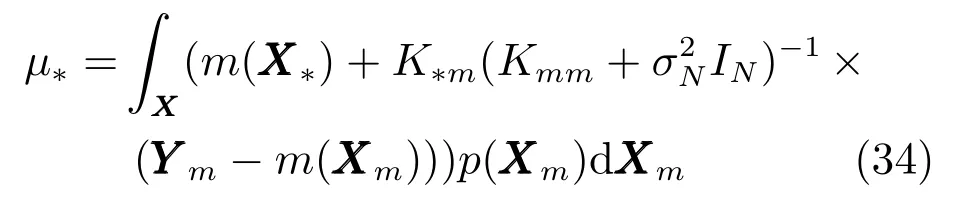
為了解決訓練集的噪聲輸入問題,采用一種全新的方法進行計算,該算法稱為帶有噪聲輸入的高斯過程(Noisy input Gaussian process,NIGP),主要思想是將訓練集的輸入噪聲轉化為輸出噪聲,運用常規的高斯過程回歸解決問題.
首先做如下假設:對于輸入樣本集Xm與輸出樣本集Ym,假設其中的單個樣本x與y分別為真值在噪聲影響下的測量值,由此可得
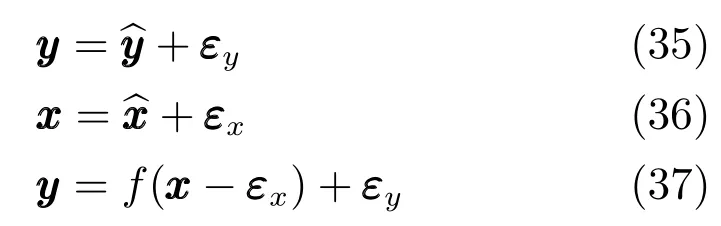
其中,εy~N(0,Σy),εx~N(0,Σx). 不難看出,式(35)與式(1)假設的條件相同,式(36)擴大到整個樣本集即為式(33).
隨后,將f(X?εx) 在x附近進行Taylor展開,并只取到一階導數,即可得到關于噪聲的一階模型:
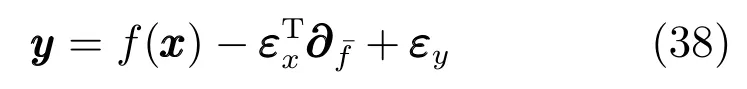
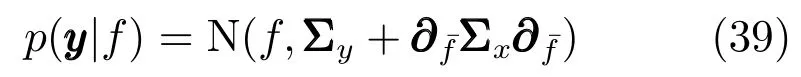
將式(39)與先驗傳遞函數進行聯立,并且擴展到整個樣本集,由此得到后驗函數的均值和協方差為
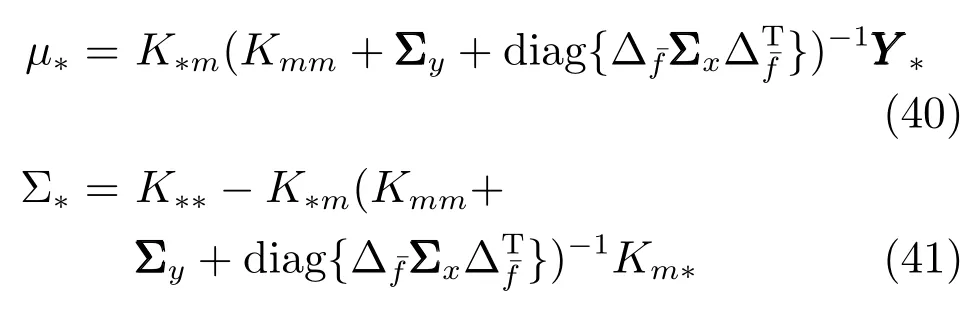
3 帶有噪聲輸入的稀疏高斯過程
本文第2.2節介紹了稀疏高斯過程,第2.3節介紹了帶有噪聲輸入的高斯過程.兩種算法均具有不同的原理與推導過程,本節要在驗證其合理性的基礎上,將兩種算法進行結合,得到更為廣泛的適用范圍及更好的預測結果.
3.1 建議模型
由第2.3節的推導過程可知,在稀疏高斯過程中,Y?的后驗分布的均值與協方差如式(24)和式(25)所示.通過觀察可以發現,式(24)與式(4)的表達形式相同,由此可以推斷式(24)可直接運用式(4)的運算過程.論證如下:
根據矩匹配算法原理,將式(24)代入式(30),得
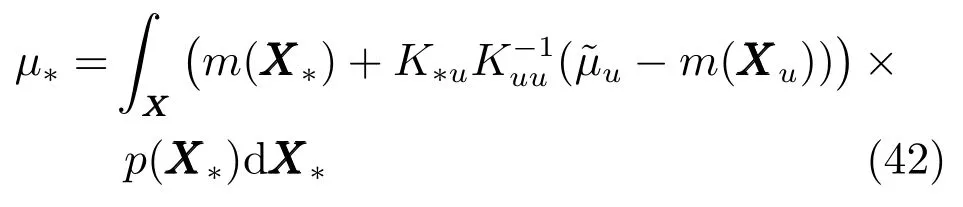

對于訓練樣本集Xm在噪聲影響下的結果應用于稀疏高斯過程,原理與測試樣本在噪聲影響下的原理相同.因此,可由式(40)和式(42),得到帶有噪聲輸入的稀疏高斯過程(Sparse Gaussian process with input noise,SGPIN)的預測輸出值Y?的后驗分布的均值.

其中,
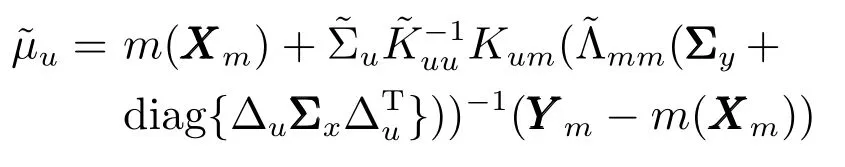
如果假設輸入變量X服從零期望值的高斯分布,則μ?可以改寫為
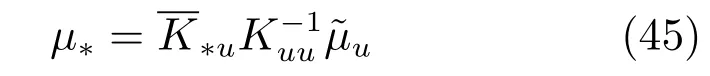
其中,
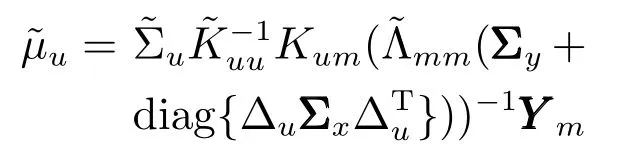
而對于Y?的后驗分布的方差,由于其推導過程過于復雜且占用較大篇幅,同時對預測結果沒有實質性影響,因此只列出推導結果:
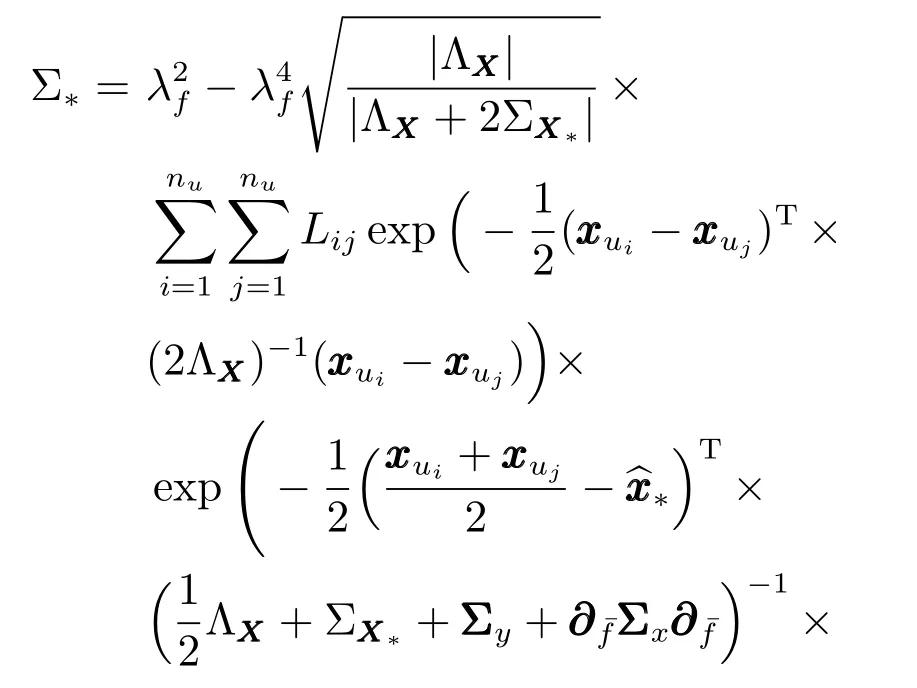
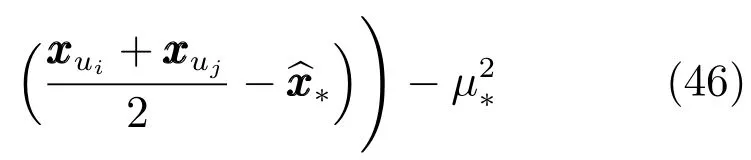
其中,
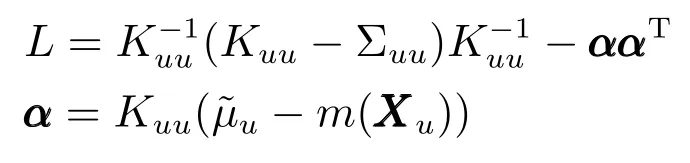
3.2 樣例測試
本文將稀疏高斯過程和有噪聲輸入的高斯模型相融合,提出了一種全新的SGPIN算法.在將該算法應用于人體姿態估計問題之前,為了進一步驗證該種融合的必要性與合理性,采用一些簡單的數據對SGPIN算法、稀疏高斯算法(FITC)、有噪聲輸入的高斯算法(NIGP)和常規高斯算法(GP)進行測試與評估.
如圖1所示,在定義域為[?5,5]、值域為[0,2.5]內隨機生成一條輸入輸出曲線,并將該曲線設定為待預測的理想目標曲線.在曲線上均勻選取若干個點,并人為添加高斯噪聲,組成帶有噪聲輸入的訓練集.隨后分別運用GP,FITC,NIGP和SGPIN四種算法進行預測,得到預測曲線,同時對每種算法的均方誤差(Mean squared error,MSE)和預測時間進行比較與評估,評估結果(10次重復實驗取平均值)如表1所示.
結合圖1與表1中的信息可知,SGPIN算法在預測準確度與運行時間方面均明顯優于其他三種基礎算法,可見稀疏算法與去噪算法的結合確實可以大幅度提高高斯過程算法的性能,達到更好更徹底的優化效果.

圖1 GP,FITC,NIGP和SGPIN算法預測結果Fig.1 Predicting results of GP,FITC,NIGP and SGPIN
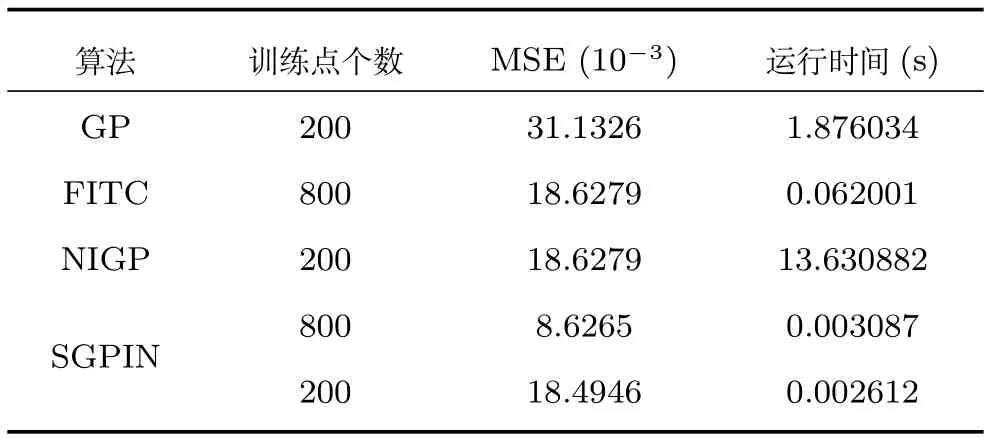
表1 GP,FITC,NIGP和SGPIN算法比較Table 1 Comparison of GP,FITC,NIGP and SGPIN
4 仿真研究與結果分析
本節主要對帶有噪聲輸入的稀疏高斯(SGPIN)算法與雙高斯過程算法(Twin Gaussian processes,TGP)、K–近鄰算法(K-nearest neighbor,KNN)等預測算法進行比較與評估.其中,TGP算法是由Bo等[25]提出的一種基于輸入與輸入兩種聯合概率分布的高斯過程,在解決人體姿態估計問題時,具有比K–近鄰算法、嶺回歸算法以及傳統高斯過程等算法更高的預測準確度.
實驗的數據集來自基于HumanEva-I數據庫[16]的人體姿態HoG特征集[17],包括3位測試對象的行走、慢跑、投擲捕捉,做手勢與拳擊5個動作.更多細節可以參考文獻[17].
4.1 輸入、輸出與誤差度量
1)表2為實驗的數據集,包含不用姿勢和不同研究對象的樣本個數(每個視角下的單幀圖片數).對每個樣本使用由Poppe計算的810維HoG特征描述[17],同時,這個數據也用于評估雙高斯過程和KNN等算法的性能[25].
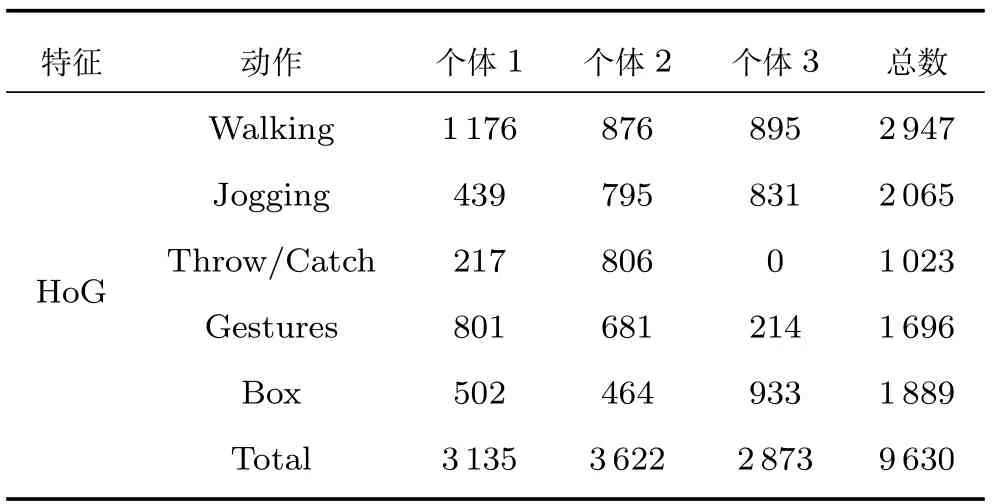
表2 實驗數據集Table 2 Experimental set
2)輸出變量是人體姿態,表示為20個三維身體關節位置組合成的60維向量,并且每個姿勢都需要進行預處理,即將根關節位置設為原點,其他關節的位置表示為與根關節的位置差.這種標準化處理可以減少因研究對象的不同產生的不確定性.
3)借用文獻[16]提出的誤差度量,對于每一個輸出向量,誤差公式可以表示為
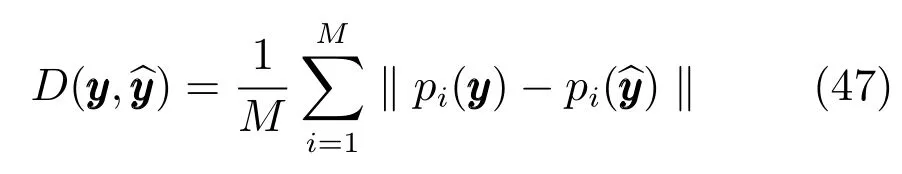
其中,y是60維的估計輸出,是與之對應的真實輸出,M=20是每一個姿態中關節位置的個數,pi的輸出值是第i個關節位置的三維向量.k·k表示歐氏距離.而對于整個輸出序列,平均誤差可以表示為
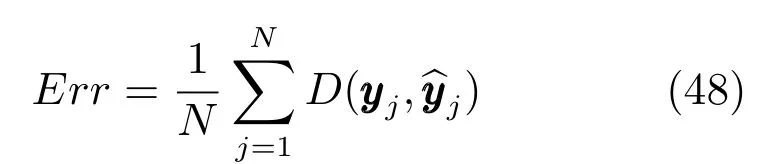
其中,N表示輸出向量的個數.
4.2 初始化與評估
1)對于每一個數據集,將其分成測試、誘發和訓練三部分.在SGPIN算法中,通過迭代的梯度下降法確定超參數值,這種方法會適當增加運行時間,但是卻可以得到更好的精度.對于其他算法,忽略誘發部分數據,參考文獻[25]進行參數值設定.另外,對于每種算法,都會人為地在測試輸入中添加高斯噪聲,同時添加一個極小的噪聲矩陣來增加逆矩陣運算的穩定性.
2)選取高斯過程(GP)、雙高斯過程(TGP)、帶有噪聲輸入的稀疏高斯過程(SGPIN)、帶有KNN算法的雙高斯過程(TGPKNN)、最優雙核復合分類算法(Kernel target alignment,KTA)[26]和希爾伯特施密特的獨立性準則(Hilbert-Schmidt independence criterion,HSIC)[27]下的KNN算法進行預測準確度和運行時間的評估.在準確度方面,比較每一個姿勢的每一個輸出向量的估計誤差和不同姿勢的平均估計誤差.同時,為了保證評估的客觀性,每種算法都進行5次仿真運算,取其平均值作為最終的運算結果.
表3列出了不同姿勢的平均誤差,表4是每一種算法的運行時間.這兩個指標是評價算法綜合能力的重要依據.
在表3和表4中,所有模型均來自于3個研究對象的5個動作.表中列出了樣品數量,最小誤差和最短運行時間用粗體字顯示,“/”表示無數據集進行評估或樣本集過小致使KNN算法無法在與其他樣本相同K值下運行,所有模型的誘發點個數均為nu=20.
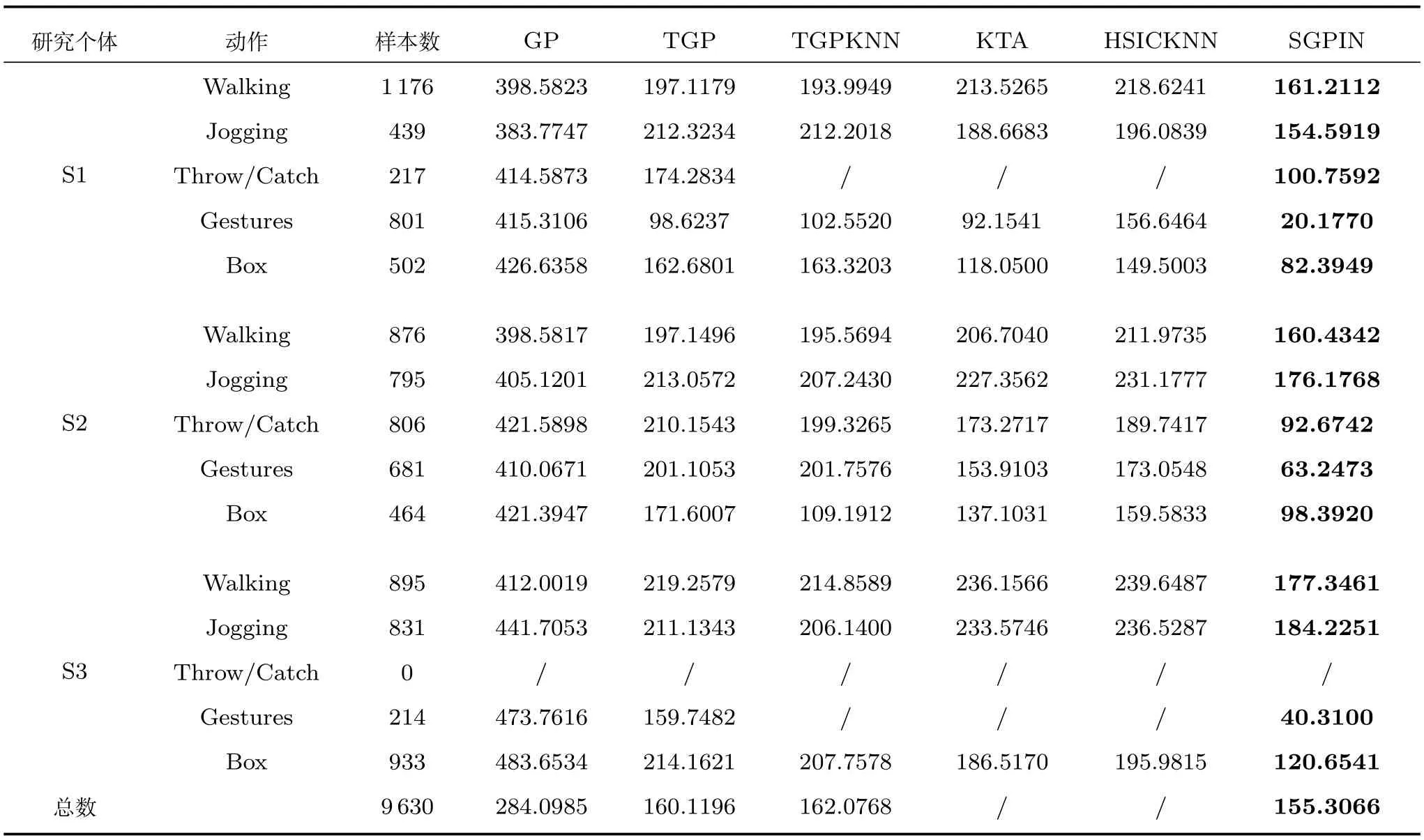
表3 基于HumanEva-I數據集HoG特征的不同算法的平均誤差Table 3 Evaluation of average error of different algorithms based on HoG feature of HumanEva-I
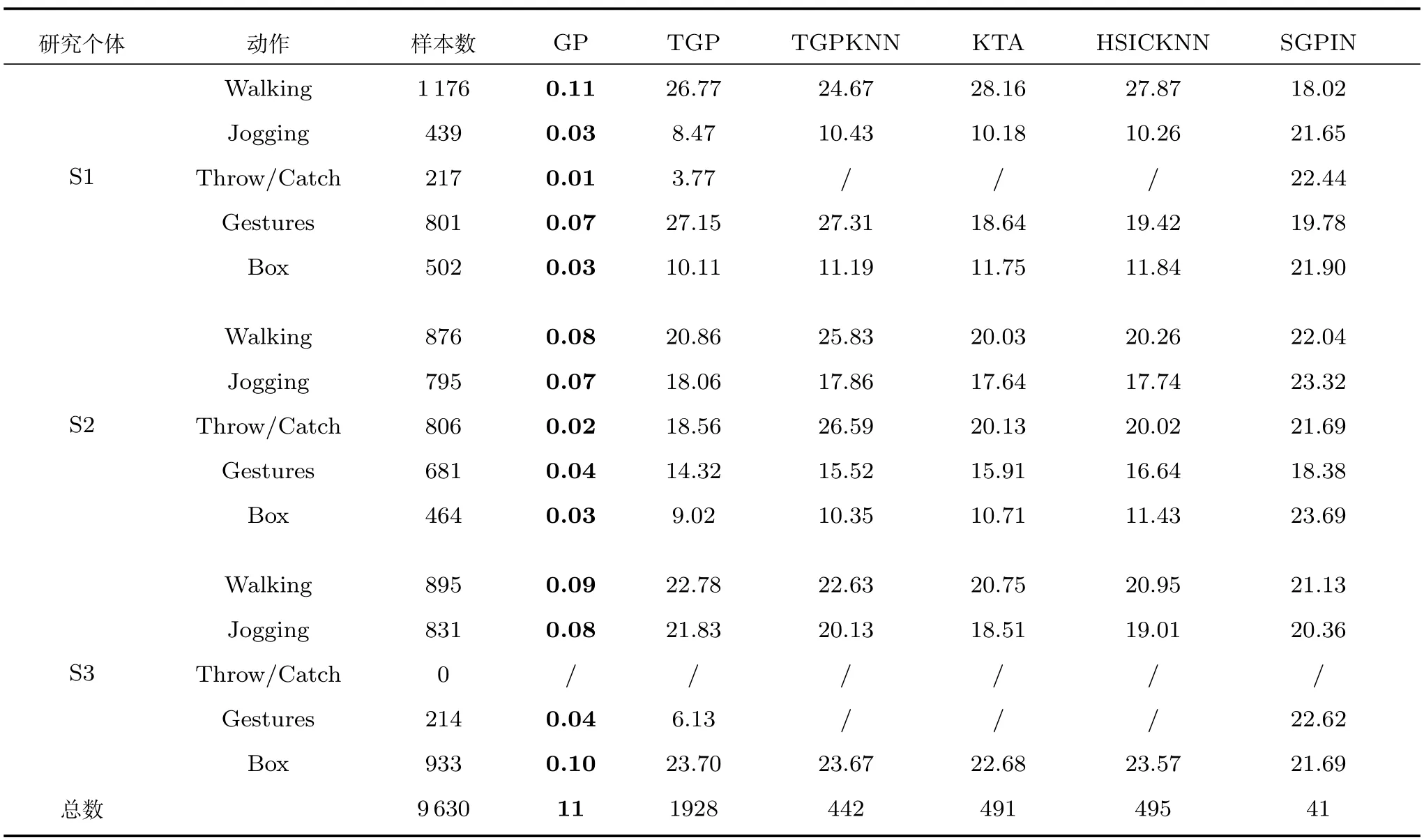
表4 基于HumanEva-I數據集HoG特征的不同算法的運行時間Table 4 Evaluation of runtime of different algorithms based on HoG feature of HumanEva-I
從表3可以看出所有算法的準確性.其中,SGPIN算法最為準確,因為其具有比其他模型更小的平均誤差.TGP和TGPKNN的誤差在所有的運動中都是相似的,因為這兩種方法具有相同的核心算法.KTA和HSICKNN算法與TGP算法的表現比較相似,但KTA算法的預測準確性略優于HSICKNN算法.常規GP模型與其他模型相比具有較大的誤差,因為它更受輸入噪聲的影響與干擾.
同時,從表3可以看出,在預測不同的姿態時,SGPIN算法的優越性不盡相同.在預測Throw/Catch和Gestures等變化比較強烈的姿態時,SGPIN算法的預測準確度格外高,在預測Walking和Jogging這類變化比較平緩的姿態時,則表現了與其他算法相近的預測精度.SGPIN算法的這種表現將在之后的算法穩定性分析中具體討論.
表4的數據反映了所有算法的運行時間.常規GP算法因為其模型的簡單性,比其他算法具有更少的運行時間.另外5種算法在運行時間上沒有較大的差別,屬于同一數量級.觀察表4中的每一列,可以分析出樣本數量對運行時間的影響.具體表現為:樣品數量對TGP,TGPKNN,KTA以及HSICKNN算法具有很大的影響,對GP的影響較小.在大多數情況下,樣本數越小,平均誤差也越小.但是,SGPIN算法幾乎不受樣本大小的影響,因為在SGPIN算法中,承擔了主要運算量的誘發點數量不隨樣本數的變化而變化,其取值均為20.
接下來討論SGPIN算法的穩定性.圖2和圖3列舉了在同一姿態中每一個輸出向量的誤差.由于樣本數量過大,且預測誤差在各樣本子集的分布基本相同,因此只截取每個樣本集的100個樣本進行描述.圖2給出了SGPIN算法與TGP和TGPKNN算法的對比結果,圖3給出了SGPIN算法與GP,KTA和HSICKNN算法的對比結果.
從圖2可以看出,在很多樣本中,TGP和TGPKNN的預測誤差會隨輸出向量的不同產生很大的變化,而SGPIN受到的影響較小.此外,若調細圖2中的曲線,可以發現TGP曲線存在大量毛刺,而TGPKNN和SGPIN的曲線則更為平滑.原因是TGP算法利用了所有輸入點的信息,而TGPKNN和SGPIN算法為了簡化計算過程而忽略了一部分輸入點.
從圖3可以看出,GP幾乎不隨輸出向量的不同而產生變化,原因是GP算法的原理比較簡單,注重的是整個樣本集的總體信息.SGPIN算法因為稀疏過程的存在,輸出向量對測量誤差的影響也較小.而KTA和HSICKNN算法與SGPIN算法相比則極不穩定,預測準確度會隨樣本的不同產生巨大的波動,而預測誤差的離散程度也會隨樣本集的不同而有所不同.

圖2 TGP,TGPKNN與SGPIN算法的誤差比較Fig.2 Error comparison of TGP,TGPKNN and SGPIN
結合圖2和圖3可以發現,在預測Walking和Jogging這類變化比較平緩的姿態時,SGPIN算法的穩定性與TGP和TGPKNN算法基本相同,且都弱于GP算法,具體表現為預測曲線的波動程度相似.在預測Throw/Catch和Gestures等變化比較強烈的姿態時,TGP,TGPKNN,KTA和HSICKNN算法的不穩定性使得算法產生了許多預測誤差較大的樣本,極大影響預測精度,這也是表3中SGPIN算法在預測變化比較強烈的姿態時準確度遠遠超過其他算法的原因.
另外,在預測同一實驗個體的同一種姿態時,預測誤差值的離散程度也反映了算法的穩定性.由于在行走姿態的預測中SGPIN算法與其他算法的預測結果最為相似,因此選取個體3的行走姿態,重復進行5次仿真運算,結果如表5所示.
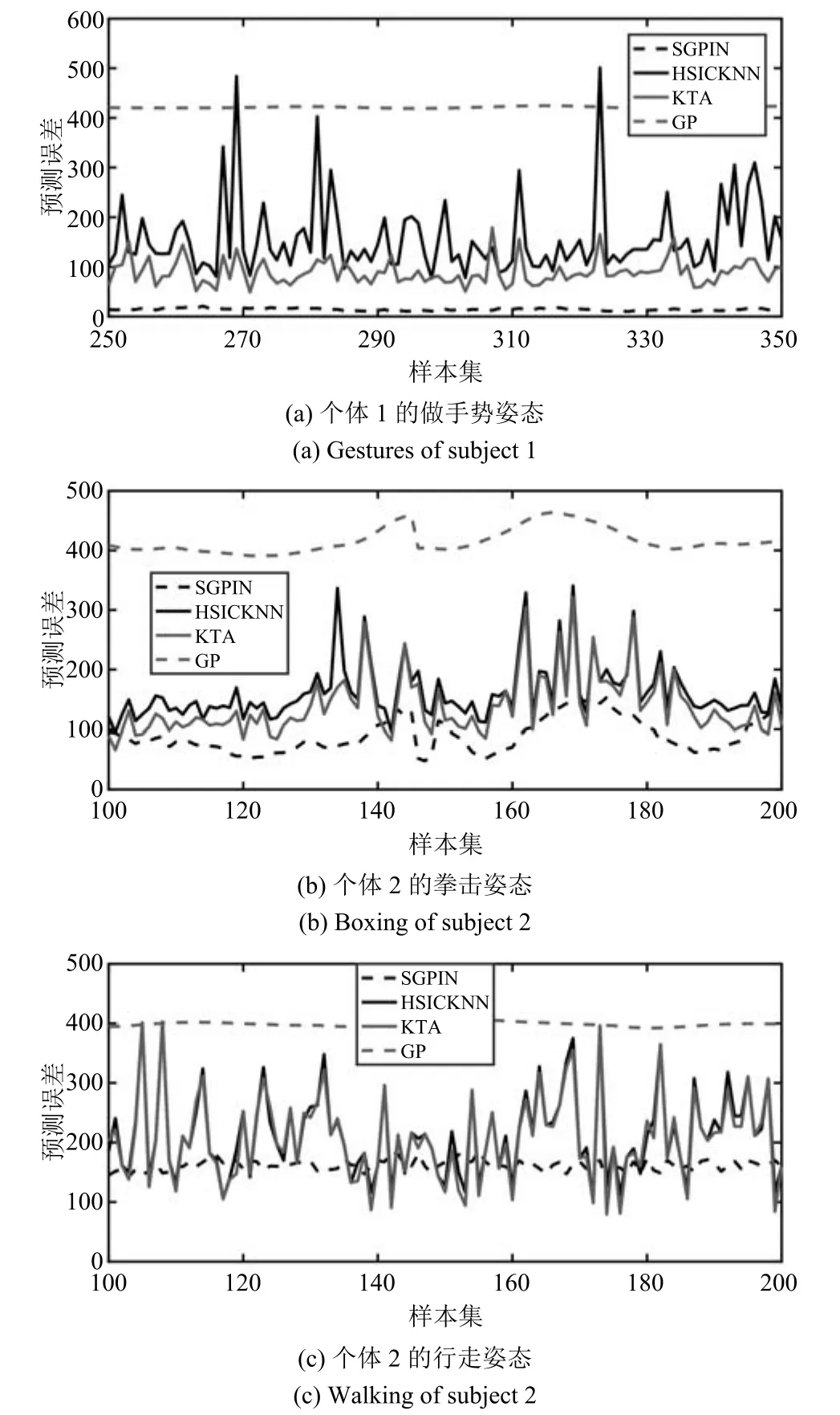
圖3 GP,KTA,HSICKNN與SGPIN算法的誤差比較Fig.3 Error comparison of GP,KTA,HSICKNN and SGPIN
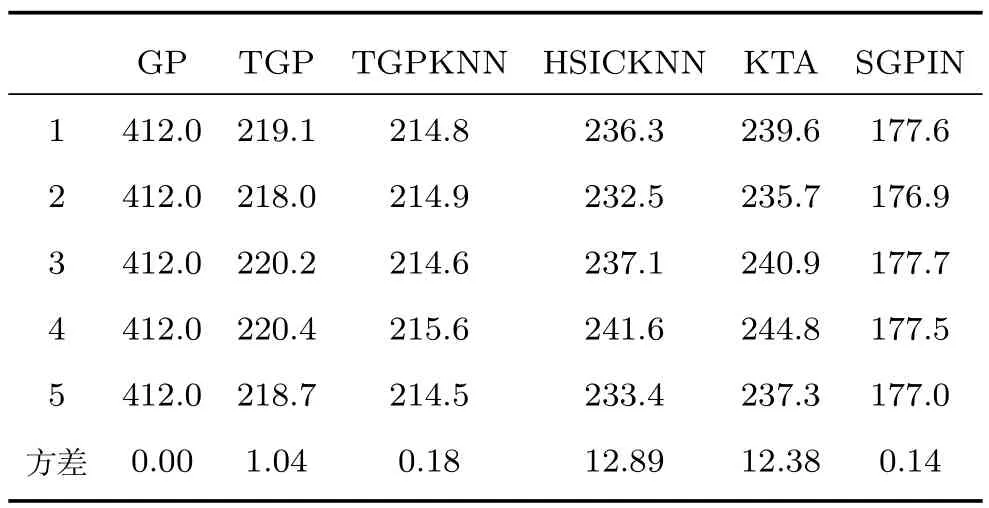
表5 個體3行走姿態的預測誤差Table 5 Predicting errors of subject 3 walking
表5最后一行的方差反映了預測誤差值的離散程度.方差越大,算法的穩定性越低,方差越小,算法的穩定性越高.
結合圖2、圖3和表5可以分析出6種算法的穩定性.HSICKNN和KTA算法極不穩定,TGP和TGPKNN算法穩定性一般,GP算法和SGPIN算法穩定性最好.其中,SGPIN算法無論在預測變化較大的姿態方面,還是在重復運行同一樣本集時,都能達到十分穩定的預測精度,這兩種性質也充分反映了SGPIN算法是一種能夠推廣到實際工程應用領域的人體姿態估計算法.
5 結束語
本文提出了一種從經典高斯過程模型的數學原理角度對模型進行優化來解決人體姿態估計問題的新思路.算法的評估實驗是基于HumanEva-I數據庫的HoG特征集的三維人體姿態估計問題,包括3個研究對象與5個人體姿態.將本文算法與GP算法、TGP算法、TGPKNN算法、HSICKNN算法和KTA算法在預測準確度、運行時間和算法穩定性方面進行比較,本文算法具有較為優秀的評估結果.在算法準確度方面,SGPIN算法與其他算法相比,具有較低的平均誤差和較高的穩定性(較小的誤差方差和較平滑的誤差曲線),TGP和TGPKNN算法在穩定性方面表現一般,KTA算法和HSICKNN算法表現較差.在運行時間方面,SGPIN算法并沒有過于優異,但是與其他算法相比其結果依舊是可以接受的.同時考慮預測準確度、算法穩定性與運行時間三項因素,SGPIN算法是一種應用于人體姿態估計問題的更為有效的算法.
未來的工作首先是對于求解超參數的梯度下降算法的改進,因為運用此種方法得到參數需要較長的運行時間,且并未對輸入信息進行充分利用.此外,需要更好地利用輸入變量之間與輸出變量之間的關系,因為高維輸入輸出變量的各維度之間本身具有復雜的關聯性.同時,將算法的應用領域進行拓展,使其不僅局限于HoG這一特征,甚至不僅局限于人體姿態估計這一問題,而是用于解決更多的結構化預測問題.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
