對地觀測用戶需求智能融合處理技術
2019-06-25 09:54:04陳勇
無線電工程 2019年7期
陳 勇
(中國電子科技集團公司第五十四研究所,河北 石家莊 050081)
0 引言
隨著衛星遙感技術的快速發展,各行各業對遙感影像數據的需求也越來越多,雖然應用目的不同,各用戶的遙感數據需求存在多樣性,但不同用戶之間也會存在相似或相同需求,特別是在發生熱點事件和自然災害事件時,各個參與單位會同時申請熱點地區和受災區域的遙感影像數據,這些數據往往會有相同或者相似的需求,如何融合來自不同用戶的需求,實現最大效率地利用衛星觀測資源、地面接收資源、地面數據傳輸資源、降低衛星對地觀測系統的任務負荷,需要開展需求融合歸并技術研究,將相同或者相似的用戶需求進行歸并處理。為了解決上述問題,基于自然語言處理的信息抽取技術提出了一種需求融合方法。
信息抽取是指從原始文本中抽取用戶感興趣的事件、實體和關系[1],并以結構化形式存儲的技術[2]。近年來,信息抽取已經在經濟、醫藥和軍事等許多領域得到了成功應用。沈元一等[3]提出互聯網藥品信息抽取和監測的整體解決方案,對聯網商品信息進行全面、準確、實時、自動的抽取,有效地保障了互聯網藥品交易的質量和服務;孫師堯等[4]提出了適合軍事標圖系統應用的信息抽取策略,可大幅縮短軍事標圖耗費的時間,實現軍事標圖系統自動化;梁帥等[5]設計并實現了一種病理文本數據的結構化處理系統,支持病理報告中標本及其指標值的自動提取,對同類病癥的治療和分析提供有力的數據支持。在海事領域,信息抽取技術也取得較好的應用。吳建華[6]利用信息抽取技術建立了基于AIS的船舶交通流自動統計軟件,實現了船舶交通流的自動統計功能;原歡[7]采用基于規則的信息抽取技術,提出了基于GATE的貨物動態郵件信息抽取方法。
第一個實現規則的機器學習方法的是Cristal信息抽取系統[8]。這個系統先從訓練樣本中生成規則集合,抽取方法是每一個實例提取出一個原始規則。然后循環從規則集合中選擇2個相似度最高的規則進行合并,最后得到最小規則集。Crystal系統目前只能夠支持單槽的信息抽取,其缺陷是無法確定目標字段的界限。WHISK[9]抽取系統通過將規則的約束條件不斷增加來得到最終的結果。此系統首先確定能夠能覆蓋所有樣例的規則,然后通過訓練樣本對規則增加特征和限制進行拓展,滿足一定的錯誤率要求后停止訓練,得到最終的集合。AutoSlog是基于模板詞典的規則構造器,能夠自動構造指定領域的詞典,這樣的模板也叫做概念節點。一個概念節點包含概念位元、語言規則以及觸發條件[10]。其中位元包含了一系列用于觸發的詞組,觸發條件對生成的語言規則在語法上進行一些約束。RAPIER[11]是基于邏輯的一種信息抽取系統,從訓練語料上歸納出所需要的抽取規則。RAPIER采用的是自底向上的學習算法,從具體某一個樣本的規則歸納為覆蓋全集的范式。RAPIER系統在執行規則生成的過程中運用了語義和句法的信息。SRV[12]是一種基于關聯的信息抽取系統,采用自頂向下的歸納式算法進行信息抽取。該系統應用分類算法完成抽取任務,具有相同大小的文本數據被選取為候選項,這些候選項在信息抽取領域。傳統正則學習方法大多著眼于在相對小的字符表上進行正則表達式的學習[13]。常見情況是在詞性標注[14]、形態分析[15]和詞典匹配[16]等文本處理過程之后產生的標注詞上進行正則表達式的學習,字符表的大小就由以上分析步驟產生的標注結果所決定。另外,幾乎所有之前的工作都將問題限制在一個特定的正則類型中[17],禁用或限制了某些正則符號和操作的使用。
本文將自然語言處理中的關鍵信息抽取方法應用于對地觀測用戶需求的智能融合處理,通過對需求文本的語義分析獲取觀測需求關鍵參數的方法,研究將觀測需求進行融合的方法。
1 基于自然語言處理的需求融合方法
基于自然語言處理的需求融合基本原理如圖1所示,包括關鍵信息抽取、需求轉義和融合歸并處理環節,涉及信息抽取知識庫、需求轉義知識庫和融合知識庫。

圖1 基于自然語言處理的需求融合
2 關鍵信息抽取
2.1 關鍵信息抽取分類
用戶需求關鍵信息抽取步驟解決從用戶文本中抽取遙感影像關鍵信息元素的問題,抽取的信息包括時間范圍、地域范圍、任務和影像參數(空間分辨率、傳感器類型和波段)。實際上,關鍵信息抽取實現的是用戶需求的淺層語義分析,主要利用抽取規則實現關鍵信息的識別和抽取[1]。
關鍵信息抽取技術可分為3類:基于自然語言處理(NLP)的方法[18]、基于規則的方法和基于統計學習的方法[19]。基于NLP的方法是早期的信息抽取方法,一般效率較低,現已較少使用。基于規則的信息抽取方法依賴于信息抽取規則,信息抽取規則代表構成目標信息的上下文約束環境,指明此規則的觸發詞、激活條件、上下文約束條件和目標信息的位置特征。其中,觸發詞用于指示目標信息上下文中必須含有的關鍵詞,激活條件指定必須滿足的語言模式,約束條件指定信息的合法性,信息的位置指定信息在句子或者段落中出現的位置特征。基于統計的信息抽取需要有大量的訓練數據,以獲取概率分布模型,但往往很難獲取足夠的訓練數據。
用戶的觀測需求描述通常遵循某種習慣模式,且具有一定規律性,這種模式和規律性使得采用基于規則的方法進行關鍵信息抽取成為可能,因此,在本文采用基于規則的方法進行關鍵信息抽取,主要是針對不同關鍵信息文本片段內部組成的特征規律建立抽取規則,實現關鍵信息的識別和抽取。
2.2 正則表達式
在計算機科學中,正則表達式是指一個用來描述或者匹配一系列符合某個句法規則的字符串的單個字符串。一個正則表達式通常被稱為一個模式(pattern),用來描述或者匹配一系列符合某個句法規則的字符串[20]。例如:Handel,H?ndel,Haendel這3個字符串,都可以由“H(a|?|ae)ndel”這個模式來描述。大部分正則表達式的結構形式如下[21]:
(1) 時間:時間關鍵信息文本片段內部會出現“年、月、日、時、分、秒”等單位,通過對遙感影像用戶需求的分析,常見的表現方式是:年份數字+“年”+月份數字+“月”。
(2) 地理名稱:代表國家地區的地理名稱以及地物名稱,例如用戶需求“肯尼迪航天中心5 m全色影像”中的“肯尼迪航天中心”,“海南島10 m多光譜影像”中的“海南島”。另外,用戶需求描述中還會出現一些地理名稱和目標名稱的縮寫形式,例如,“日北海道3 m全色影像”中的“日”,它的常見表現形式是:國家地區名稱或者目標名稱。
(3) 經緯度:經緯度關鍵信息文本片段內部格式主要有2種,一種是如“東經120°,北緯23°”,另一種如“120E23N”。
(4) 任務類型:任務類型通常是一些業務術語,例如,“水下地形探測”“農作物估產”“水污染監測”“水資源調查”“冬小麥估產”等。其常見表現形式是:“2016年7月中上旬華北冬小麥估產”中的“冬小麥估產”,出現業務術語詞匯的上下文中通常沒有任務類型這樣的引導詞。
(5) 影像參數:遙感影像需求中的影像參數包括分辨率、傳感器類型和幅寬,通過對遙感影像用戶需求的分析,上述參數常見的表現方式如下:
① 分辨率
方式1:“分辨率:”+ 數字+“~”+數字+“m”,例如,“分辨率:1~10 m”;
方式2:“分辨率:”+ 數字+“~”+數字+“米”,例如,“分辨率:1~10米”;
方式3:“分辨率:”+ 數字+ “m”,例如,“分辨率:10 m”;
方式4:“分辨率:”+ 數字+ “米”,例如,“分辨率:10米”。
② 傳感器類型
方式1:“傳感器類型:”+ 傳感器類型名稱,例如,“傳感器類型:多光譜”;
方式2:傳感器類型名稱,例如,“海南島10 m多光譜影像”中的“多光譜”。
③ 波段
方式1:“波段包含” + 波段名稱 + “(”+ 數字“~”+ 數字+“)nm”,例如,“波段包含近紅外(700~1 000 nm)”;
方式2:“波段包含”+ 波段名稱 + “和”+波段名稱,例如,“波段包含近紅外和短波紅外”;
方式3:“波段:”+ 波段名稱+“、”+ 波段名稱,例如,“波段:近紅外、短波紅外”;
方式4:“波段含有” + 數字 + “~”+ 數字 + “nm”,例如,波段含有2 000~3 500 nm。
④ 幅寬
方式1:“幅寬不低于”+ 數字 +“km”,例如,幅寬不低于200 km;
方式2:“幅寬不低于”+ 數字 +“公里”,例如,幅寬不小于200公里;
方式3:“幅寬”+“十里級/百里級/千里級”+“的影像”,例如,“幅寬百里級的影像”;
方式4:“十里級/百里級/千里級”的幅寬,例如,“百里級的幅寬”;
方式5:例如,“幅寬200公里以上”。
為了使抽取規則可被計算機理解和執行,需要對信息抽取規則前提條件中的特征謂詞邏輯(特征詞信息和命名實體信息)進行格式化表達,為此采用正則表達式技術實現規則前提條件的格式化表達[4-6]。
以時間關鍵信息為例,相關的抽取規則示例如下:
① 時間信息實體抽取規則1
正則表達式:(\d){4}(-)(\d){2}(-)(\d){2}
示例:抽取形如“2013-10-29”的時間信息實體。
② 時間信息實體抽取規則2
正則表達式:(\d){4}(.)(\d){2}(.)(\d){2}(-)(\d){1,2}(:)(\d){1,2}
示例:抽取形如“2013.10.29-20:50”的時間信息實體。
③ 時間信息實體抽取規則3
正則表達式:(\d){4}(-)(\d){2}(-)(\d){2}(\d){1,2}(:)(\d){1,2}(:)(\d){1,2}
示例:抽取形如“2013-10-29 20:50:12”的時間信息實體。
④ 時間信息實體抽取規則4
正則表達式:(\d){4}(年)(\d){2}(月)(\d){2}(日)(\d){1,2}(時)(\d){1,2}(分)(\d){1,2}(秒)
示例:抽取形如“2013年10月29 日20時50分12秒”的時間信息實體。
⑤ 時間信息實體抽取規則5
正則表達式:
(\d){1,2}(時)(\d){1,2}(分)(\d){1,2}(秒)
示例:抽取形如“20時50分12秒”的時間實體。
從上述分析可以看出,用戶對于觀測需求中各種關鍵信息描述方式是多種多樣的,所對應的抽取規則業務是多種多樣的,為了有效組織和管理關鍵信息的抽取規則,采用知識本體的方法,形成了信息抽取知識庫。
通過對用戶需求文本的分析,識別出各種關鍵信息的觸發詞、上下文約束條件、區位特征、句子特征和句內特征,基于這些知識構建由特征詞匯構成的用戶需求解析規則,給定一個用戶觀測需求文本,利用特征詞匯形成的模式結構,結合前述4種要素的抽取模式,對需求文本進行解析,確定分別包含時間、地域、任務和傳感器參數的文本子串,以及各個文本子串中包含的具體的時間信息、地域信息、任務信息和影像參數信息。
例如,用戶需求“2016年4月下旬安徽省小麥紋枯病監測,采用高光譜影像,空間分辨率優于5 m”,可利用下面的模式進行解析:
【時間】+“對”【地域】+“進行”+【任務】+“采用”+【影響類型】+【空間分辨率】
解析出的時間信息、地域信息、任務信息和影像參數信息如表1所示。
表1 關鍵信息抽取示例
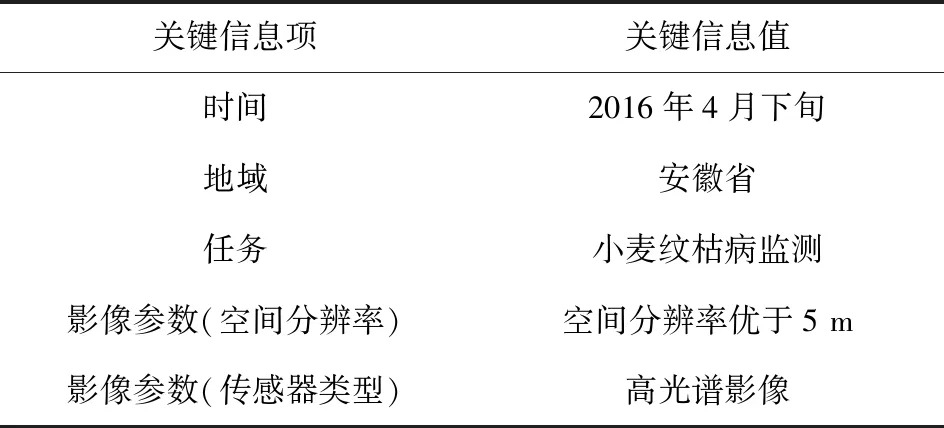
關鍵信息項關鍵信息值時間2016年4月下旬地域安徽省任務小麥紋枯病監測影像參數(空間分辨率)空間分辨率優于5 m影像參數(傳感器類型)高光譜影像
3 需求轉義
需求轉義是在用戶需求關鍵信息抽取的基礎上對抽取結果進行規范,使其滿足標準化和精確化的要求,實際上需求轉義實現的是用戶需求的深層語義分析。
① 時間信息的轉義:將識別出來的各種格式的時間轉變為標準格式。
② 地域信息的轉義:將識別出來的地域范圍轉變為由一系列經緯度值定義的多邊形。
③ 任務信息的轉義:將任務描述轉變為具體的影像參數,任務名稱的轉義基于需求轉義知識庫,知識庫中包含著任務與影像參數之間的映射關系,反映的是完成某種任務用戶所需的影像參數,適用于各軍種的需求轉義知識庫,示例如表2所示。
表2 需求轉義知識庫示例
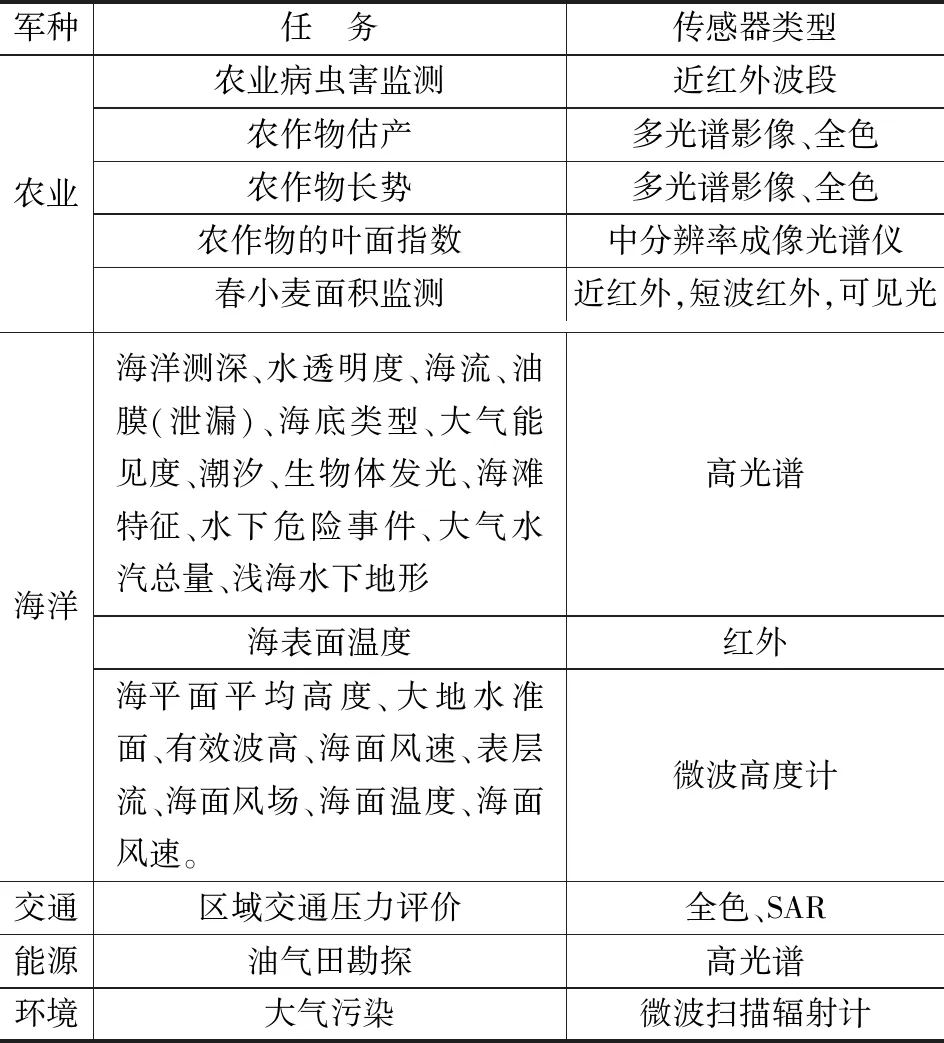
軍種任 務傳感器類型農業農業病蟲害監測近紅外波段農作物估產多光譜影像、全色農作物長勢多光譜影像、全色農作物的葉面指數中分辨率成像光譜儀春小麥面積監測近紅外,短波紅外,可見光海洋海洋測深、水透明度、海流、油膜(泄漏)、海底類型、大氣能見度、潮汐、生物體發光、海灘特征、水下危險事件、大氣水汽總量、淺海水下地形高光譜海表面溫度紅外海平面平均高度、大地水準面、有效波高、海面風速、表層流、海面風場、海面溫度、海面風速。微波高度計交通區域交通壓力評價全色、SAR能源油氣田勘探高光譜環境大氣污染微波掃描輻射計
4 融合歸并
需求融合歸并是在統一、標準化的時間、地域、影像參數格式的基礎上進行的,根據時間、地域、傳感器類型、光譜分辨率、空間分辨率和幅寬等方面對用戶需求之間的相似度進行分析計算,根據計算結果進行需求融合歸并。需求的融合歸并問題實際是用戶需求的聚類過程,經過聚類運算將一批用戶需求聚為若干個簇,簇內的用戶需求在時間、地域、傳感器類型、光譜分辨率、空間分辨率和幅寬等方面相同或者相似。
為了計算需求之間的相似度,需求確定時間、地域、傳感器類型、光譜分辨率、空間分辨率和幅寬等方面相似度的量化標準。
為了計算需求之間的相似度,需要對需求在時間(T)、地域(A)、傳感器類型(S)、光譜分辨率(V)、空間分辨率(P)、幅寬(W)等指標上的相似度進行量化處理,實現在統一量綱下的相似度評估,相似度的計算公式為:
Similarity=T×λ1+A×λ2+S×λ3+V×
λ4+P×λ5+W×λ6,
式中,λ1,λ2,λ3,λ4,λ5,λ6是權重系數,λ1+λ2+λ3+λ4+λ5+λ6=1。
5 仿真與分析
構建了遙感數據用戶需求融合處理原型系統,原型系統的組成如圖2所示。
關鍵信息抽取模塊負責抽取用戶需求文本中的時間、地理范圍、任務和傳感器參數等關鍵信息,需求轉義模塊負責將抽取出的關鍵信息轉變為標準化和精確化的指標要求,融合歸并模塊負責將相同或者相似的用戶需求合并,知識庫管理模塊負責維護管理信息抽取知識庫、需求轉義知識庫和需求融合知識庫。

圖2 原型系統組成
利用農業生產、國土資源和防災減災領域各100份用戶需求共計300份需求進行了需求融合試驗,試驗結果表明,融合歸并的正確率大于90.2%。部分用戶需求關鍵信息抽取、需求轉義及最終融合歸并結果示例如表3所示。
表3 用戶需求關鍵信息抽取需求轉義及最終融合歸并結果示例

序號需求樣例淺層解析結果深層解析結果融合后需求12008年天津春小麥面積監測時間:2008年,地點:天津,對象事件:春小麥面積監測時間:2008-1-1 0:00:00—2008-12-31 23:59:59,地點:中國天津市,west:116.657 888,east:118.026 289,north:40.194 066,south:38.548 975,對象事件:春小麥面積監測,分辨率:10~20 m,觀測時間:6月1日—6月30日,光譜段:近紅外,短波紅外,可見光22008年北京春小麥面積監測時間:2008年,地點:北京,對象事件:春小麥面積監測時間:2008-1-1 0:00:00—2008-12-31 23:59:59,地點:中國北京市,west:115.404 177,east:117.464 825,north:41.057 009,south:39.417 053,對象事件:春小麥面積監測,分辨率:10~20 m,觀測時間:6月1日—6月30日,光譜段:近紅外,短波紅外,可見光32008年河北春小麥面積監測時間:2008年,地點:河北,對象事件:春小麥面積監測時間:2008-1-1 0:00:00—2008-12-31 23:59:59,地點:中國河北省,west:113.439 867,east:119.802 968,north:42.562 44,south:36.038 584,對象事件:春小麥面積監測,分辨率:10~20 m,觀測時間:6月1日—6月30日,光譜段:近紅外,短波紅外,可見光時間:2008-1-1 0:00:00—2008-12-31 23:59:59,地點:中國河北省,west:113.439 867,east:119.802 968,north:42.562 44,south:36.038 584,對象事件:春小麥面積監測,分辨率:10~20 m,觀測時間:6月1日—6月30日,光譜段:近紅外,短波紅外,可見光
6 結束語
本文提出了一種利用自然語言處理技術實現對地觀測需求融合歸并的方法,利用文本信息抽取方法抽取觀測需求文本中的關鍵參數,利用淺層和深層語義分析實現用戶需求的轉義,再利用聚類算法分別從時間、地域、傳感器類型、光譜分辨率、空間分辨率和幅寬等方面對用戶需求之間的相似度進行分析計算,將相同或者相似的用戶需求聚在一起,實驗結果表明,該方法能夠有效對自然語言形式的用戶需求進行融合歸并處理,正確率大于90.2%。
在未來工作中,將嘗試利用深度學習與自然語言處理相結合的方法進一步提高關鍵參數提取的準確率,進一步提升對地觀測用戶需求融合處理的效果。
猜你喜歡
小獼猴智力畫刊(2022年3期)2022-03-29 01:09:42
今日農業(2021年19期)2022-01-12 06:16:36
中老年保健(2021年11期)2021-08-22 03:15:44
中學生數理化(高中版.高考理化)(2021年6期)2021-07-28 06:21:04
數學小靈通(1-2年級)(2021年4期)2021-06-09 06:26:14
中學生數理化(高中版.高考數學)(2021年1期)2021-03-19 08:28:38
現代出版(2020年3期)2020-06-20 07:10:34
Coco薇(2017年11期)2018-01-03 20:59:57
暨南學報(哲學社會科學版)(2016年9期)2017-01-15 13:52:02
NBA特刊(2014年7期)2014-04-29 00:44:03
