基于雙卷積神經(jīng)網(wǎng)絡(luò)的鐵路集裝箱號OCR
2019-07-08 06:46:17陳力暢李宇波
計算機時代 2019年6期
陳力暢 李宇波
摘? 要: 針對尚缺乏識別準(zhǔn)確率高的鐵路集裝箱箱號OCR系統(tǒng)這一現(xiàn)實,設(shè)計了一套識別準(zhǔn)確率能夠達到98%以上的鐵路集裝箱箱號OCR系統(tǒng)。該系統(tǒng)對采集到的圖像進行字符的自動分割,在訓(xùn)練CNN時針對目前數(shù)據(jù)集多樣性不足、樣本較少的情況,采用了數(shù)據(jù)增強的方法擴充數(shù)據(jù)集,并且基于LeNet-5進行了網(wǎng)絡(luò)結(jié)構(gòu)搜索,訓(xùn)練了分別用于數(shù)字和字母識別的卷積神經(jīng)網(wǎng)絡(luò)Digit Net和Letter Net,其在測試集上的識別準(zhǔn)確率分別能夠達到99.7%和99.2%。
關(guān)鍵詞: 鐵路集裝箱箱號; OCR; 數(shù)據(jù)增強; 網(wǎng)絡(luò)結(jié)構(gòu)搜索; 雙卷積神經(jīng)網(wǎng)絡(luò)
中圖分類號:TP391.4? ? ? ? ? 文獻標(biāo)志碼:A? ? ?文章編號:1006-8228(2019)06-01-04
Abstract: In China, there is still a lack of high-accuracy railway container number OCR system. This paper designs a railway container number OCR system with recognition accuracy of over 98%. This system automatically divides the characters in acquired image. When training CNN, to cope with the insufficient diversity of current datasets and the lack of samples, data augmentation is used to enlarge the dataset. This system performs network structure search based on LeNet-5, training the convolutional neural networks Digit Net and Letter Net for digital and letter recognition respectively. The recognition accuracy on the test set reaches 99.7% and 99.2%.
Key words: railway container number; OCR; data augmentation; network structure search; double convolutional neural networks
0 引言
隨著我國“一帶一路”戰(zhàn)略的順利實施,無論是海運集裝箱還是鐵路集裝箱過關(guān)數(shù)目均大幅度上升。這也給近些年來隨著卷積神經(jīng)網(wǎng)路發(fā)展而飛速進步的OCR[1]識別技術(shù)帶來了新的應(yīng)用場景。國內(nèi)已經(jīng)有眾多學(xué)者對OCR技術(shù)做出了改進并且運用于港口與碼頭集裝箱的箱號識別上,如陳永煌[2]等提出了基于模板匹配與特征匹配的港口集裝箱箱號字符識別算法;黃深廣[3]等提出了基于CNN和模板匹配的港口集裝箱箱號智能識別系統(tǒng), 其識別的準(zhǔn)確率能夠達到97%,而且能夠適應(yīng)惡劣天氣。
相對于港口與碼頭集裝箱箱號OCR技術(shù)的廣泛應(yīng)用,鐵路集裝箱箱碼OCR系統(tǒng)的研究則較為缺乏,目前識別率最高的是劉璇[4]提出的基于改進開源的Tessaract-OCR[5]的OCR算法,其識別精度為96.453%,但是這一精度顯然無法最大化滿足邊境檢查人員的實際需要,還是有部分箱號因為識別錯誤需要重新轉(zhuǎn)由人工記錄集裝箱箱號導(dǎo)致清關(guān)的速度沒有辦法最大化。
針對上述問題,本文在OCR識別算法上做出了改進,采用了自主設(shè)計的CNN網(wǎng)絡(luò)并開發(fā)了一套識別準(zhǔn)確率在98%以上的鐵路集裝箱OCR系統(tǒng)。
1 OCR系統(tǒng)總體流程
本文所述的鐵路集裝箱OCR系統(tǒng)的總體流程圖如圖1所示。為了實現(xiàn)這一系統(tǒng),首先需要在鐵軌的兩端固定紅外接收與發(fā)射裝置,由于火車所運輸?shù)膬晒?jié)集裝箱之間會有一小段空隙,一端的紅外接收器將在這段間隙中接收到另一端傳輸過來的紅外信號,此時就達到了拍攝照片的觸發(fā)條件,接收器將向攝像機發(fā)送一個控制信號,示意圖見圖2。而根據(jù)這個觸發(fā)條件,我們可以預(yù)先固定好攝像機的位置和角度,在控制信號到來的時候拍攝圖片,并將拍攝完成的圖片傳回到后端作為OCR識別算法的輸入,最后運用提前訓(xùn)練的CNN模型進行字符識別并輸出結(jié)果。
2 字符提取
2.1 箱號標(biāo)準(zhǔn)
集裝箱箱號編碼采用的是ISO6346(1995)標(biāo)準(zhǔn),由11位編碼組成,其中前4位為大寫的英文字母,后面的7位為數(shù)字。需要明確的是,本文所構(gòu)建的鐵路集裝箱箱號OCR系統(tǒng)只識別集裝箱號,其余數(shù)字或者字母以及標(biāo)志均不在識別的范圍內(nèi)。
2.2 圖像預(yù)處理
⑴ 圖像灰度化:為了加快圖像的處理速度,同時也為了使得圖像上的特征更為明顯,通常需要對圖像進行灰度化處理。本文采用的是加權(quán)平均值法的灰度化方法,采用B,G,R三通道的平均值描述圖像灰度值。
⑵ 中值濾波:在進行灰度化處理之后,為了使得圖像的噪聲減小,通常還需要進行濾波處理。本文在嘗試了高斯濾波,中值濾波以及均值濾波之后發(fā)現(xiàn),對于需要處理的集裝箱圖片來說,中值濾波的效果更好,故采用中值濾波。
⑶ 圖像二值化:本文將經(jīng)過灰度化以及中值濾波之后的圖像進行二值化處理,并通過自適應(yīng)的OTSU法選取閾值T,具體的二值化公式見⑴:
2.3 投影法分割字符
所謂的投影法,就是沿水平方向或者垂直方向統(tǒng)計每一行或每一列中的目標(biāo)像素個數(shù)。針對本文所述的特定場景,就是統(tǒng)計每一行和每一列的白色像素個數(shù)。再根據(jù)每一行和每一列的白色像素個數(shù)進行字符分割。由于本文只針對集裝箱箱號進行識別,所以對于垂直投影來說,只需要分割出第一個波峰,對于水平投影來說則需要依次將所有的波峰切出。雖然已經(jīng)將圖片進行了預(yù)處理,但是不可避免地會存在噪聲的干擾,所以,需要選定一個切割閾值,將閾值以下的部分視為噪聲,將閾值以上的部分進行切割。而根據(jù)在多張圖片上所進行的實驗,本文選取的閾值為10。
3 CNN的訓(xùn)練與優(yōu)化
3.1 數(shù)據(jù)集的構(gòu)建
通過在實地采集的樣本,將圖片上的數(shù)字與字母一一分割取出,本文設(shè)計并構(gòu)建了訓(xùn)練數(shù)據(jù)集和測試數(shù)據(jù)集。訓(xùn)練集一共有36個類包含數(shù)字0-9,大寫字母A-Z,2958張包含單個數(shù)字或者字母的圖片;與數(shù)據(jù)集相對應(yīng)的測試集上有786張圖片,同樣是36個類。
由于鐵路集裝箱在運輸?shù)倪^程中不可避免地會受到風(fēng)化,侵蝕而導(dǎo)致集裝箱碼有不同程度地磨損,如何讓CNN能夠準(zhǔn)確識別這些破損的數(shù)字或者字母也是本文所構(gòu)建OCR要提高識別準(zhǔn)確率所面臨的難點。受到LeCun[2]訓(xùn)練MNIST數(shù)據(jù)集時加入較多的模糊數(shù)字樣本的啟發(fā),本文采用的方法為:在訓(xùn)練集中加入較多的破損數(shù)字和字母的圖片,用來增強神經(jīng)網(wǎng)絡(luò)的泛化能力。
用于LeNet-5訓(xùn)練的MNIST數(shù)據(jù)集的大小為—訓(xùn)練集60,000個樣本,測試集10,000個樣本。前面所提到的自建數(shù)據(jù)集規(guī)模(見表1)顯然遠遠小于這個數(shù)目,為了使得訓(xùn)練的神經(jīng)網(wǎng)絡(luò)具有更高的識別準(zhǔn)確率以及更強的魯棒性,本文對數(shù)據(jù)集進行了數(shù)據(jù)增強。
3.2 數(shù)據(jù)增強
所謂數(shù)據(jù)增強,就是將原始數(shù)據(jù)集通過圖像反轉(zhuǎn),翻轉(zhuǎn),旋轉(zhuǎn),縮放等手段進行數(shù)據(jù)集的擴充。本文所采用的數(shù)據(jù)增強為圖像隨機在[-30?,30?]之間旋轉(zhuǎn),在[0.8,1.2]倍之間放縮。對于增強后可能帶來的像素填充問題,為了防止引入噪聲,本文采取了將空缺像素填0的操作。
3.3 LeNet-5
LeNet-5一共由7層組成,C1為卷積層(Convolution Layer),P1是池化層(Pooling Layer)接下來是另外一組卷積層加上池化層的組合C2和P2,最后是3個全連接層F1,F(xiàn)2,F(xiàn)3(Fully-Connected Layer)。由于切割后的圖片大小為64×48,所以需要將LeNet-5的輸入層改為64×48,輸入層改動后的LeNet-5參數(shù)列表見表2。
3.4 雙卷積神經(jīng)網(wǎng)絡(luò)
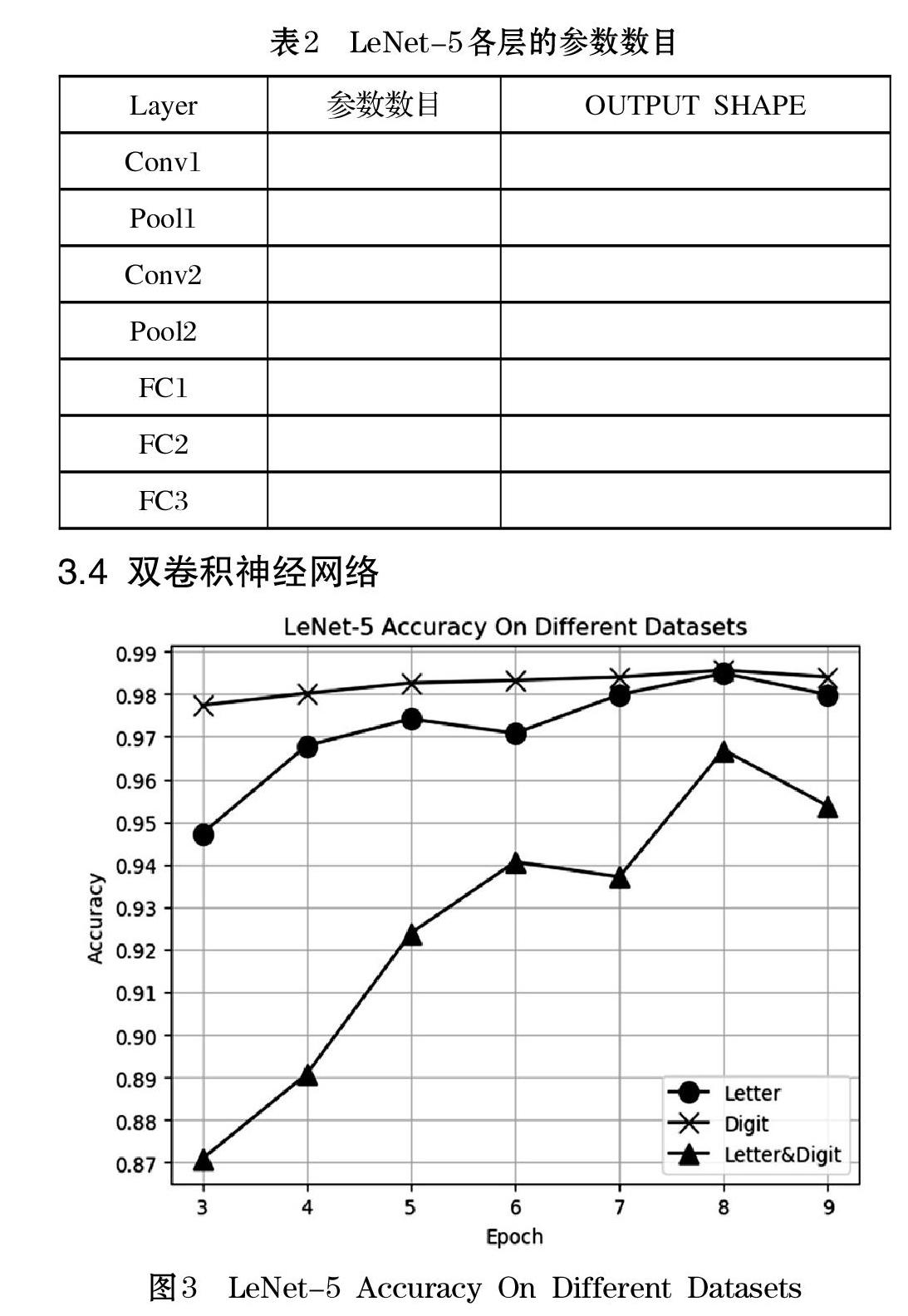
根據(jù)前文所述的集裝箱碼的編碼規(guī)則,前面的4位為字母,后面的7位為數(shù)字,所以本文采取的策略是訓(xùn)練兩個卷積神經(jīng)網(wǎng)絡(luò),Digit Net和Letter Net分別針對數(shù)字識別和字母識別。本文首先運用LeNet-5對分割好的圖片訓(xùn)練,采用提前終止的訓(xùn)練策略——就是在測試集上的準(zhǔn)確率不再上升時停止。分別訓(xùn)練單獨識別數(shù)字0-9的LeNet-5[6],識別字母A-Z的LeNet-5,以及識別數(shù)字+字母一共36個類別的LeNet-5,得到圖3所示結(jié)果。由曲線的對比可得,對于此問題,數(shù)字和字母分開識別的效果遠遠比不分開的效果好。
3.5 基于LeNet-5的網(wǎng)絡(luò)結(jié)構(gòu)搜索
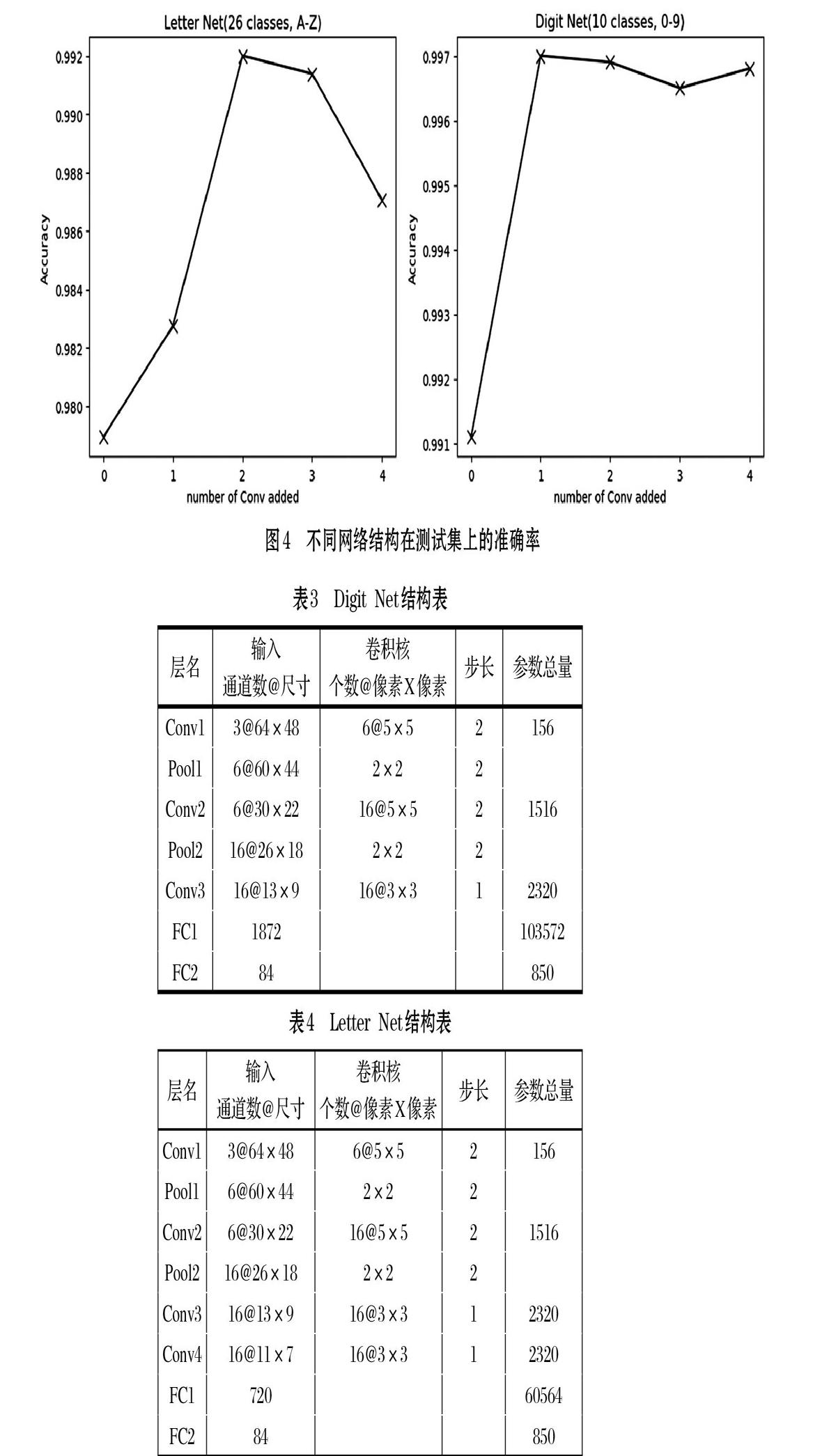
由圖3得,前述的LeNet-5網(wǎng)絡(luò)在數(shù)字測試集上的最高識別準(zhǔn)確率98.5%,在字母訓(xùn)練集上的最高識別準(zhǔn)確率為98.4%,顯然這與在MNIST數(shù)據(jù)集上的最高識別準(zhǔn)確率99.2%還有差距。分析其原因如下。
⑴ 數(shù)據(jù)集的規(guī)模過小(對比見表1)。
⑵ 輸入圖片尺寸不一致可能導(dǎo)致前述網(wǎng)絡(luò)結(jié)構(gòu)不是最優(yōu):由于本文所輸入的圖片尺寸為64×48,但是LeNet-5是用在MNIST數(shù)據(jù)集上進行訓(xùn)練的,MNIST數(shù)據(jù)集的圖片大小均為32×32,原來的卷積層數(shù)目以及卷積核的大小5×5可能不是在本問題上的最佳選擇。
⑶ 網(wǎng)絡(luò)參數(shù)的數(shù)目過多而導(dǎo)致的模型復(fù)雜度上升,進而導(dǎo)致網(wǎng)絡(luò)在小數(shù)據(jù)集上難以收斂。應(yīng)該考慮降低網(wǎng)絡(luò)的復(fù)雜度。
針對上面所述的問題,本文提出了如下的解決方案。
分析表2我們可以得到,F(xiàn)1層所占的參數(shù)數(shù)量為總參數(shù)的94.66%,是最主要的增加神經(jīng)網(wǎng)絡(luò)參數(shù)復(fù)雜度的一層。而這一全連接層的參數(shù)計算如下:先將P2進行展平(Flatten),得到s維向量,再將這s維向量與F1層的神經(jīng)元數(shù)目f進行相乘加上f個神經(jīng)元偏置b。具體見公式⑵:
要減小參數(shù)的數(shù)目,就要減小s和f,對此,本文采取的做法是直接將F1層去掉,從而減小了f。而為了減小s可以采取的是多疊加幾層卷積層,因為多增加卷積層可以使得最后的P2展平后的參數(shù)數(shù)目變小而又能保證網(wǎng)絡(luò)的總體參數(shù)只有少量的增加。
下面以在P2層后面增加一層帶有16個卷積核,且卷積核大小為3×3的卷積層C3為例來說明增加卷積層帶來的參數(shù)減少:C3卷積前,此時網(wǎng)絡(luò)的輸出shape為13×9×16,卷積后的輸出shape為11×7×16,此時如果連接上F1則參數(shù)數(shù)目減少為:(13×9×16-11×7×16)×(120+1)=77440,算上C3卷積層參數(shù)數(shù)目的增加:(3×3×16+1)×16=2320,一共減少參數(shù)的數(shù)目為:77440-2320=75120。
為此本文采取了網(wǎng)絡(luò)結(jié)構(gòu)搜索的辦法搜索最優(yōu)的網(wǎng)絡(luò)結(jié)構(gòu),也就是在P2層后面添加卷積層來實現(xiàn)。
本文基于上述方法,對增加0-4層卷積層的網(wǎng)絡(luò)進行了訓(xùn)練,同樣采取提前終止的訓(xùn)練策略,并分別記錄在測試集上測試精度最高的模型,得到如圖4所示結(jié)果。由準(zhǔn)確率曲線我們選擇識別率最高的Digit Net,99.7%和Letter Net,99.2%,其網(wǎng)絡(luò)結(jié)構(gòu)分別見表3和表4。
最后,將前面所述的OCR算法在含有298張鐵路集裝箱箱碼的圖片的測試集上進行了測試,測試的結(jié)果為能夠正確識別292張圖片上的集裝箱箱碼,由此得到此OCR系統(tǒng)的識別準(zhǔn)確率為98%。
4 結(jié)束語
本文設(shè)計了一套針對鐵路集裝箱碼識別的系統(tǒng),并且詳細說明了此套OCR系統(tǒng)的開發(fā)流程。在數(shù)據(jù)集的構(gòu)建方面,本文采用了數(shù)據(jù)增強技術(shù),將原始的圖片通過旋轉(zhuǎn),放縮進行了擴充,使得樣本的多樣性大幅度提高,從而增強了后續(xù)訓(xùn)練的卷積神經(jīng)網(wǎng)絡(luò)的泛化能力。
本文還詳細說明了兩個網(wǎng)絡(luò)Digit Net和Letter Net的結(jié)構(gòu)搜索方法以及參數(shù)尋優(yōu)過程,最終開發(fā)的針對鐵路集裝箱箱碼的OCR系統(tǒng)識別準(zhǔn)確率能夠達到98%。希望本文網(wǎng)絡(luò)參數(shù)尋優(yōu)的經(jīng)驗?zāi)軌驗槠渌鸒CR系統(tǒng)的開發(fā)者提供參考。
參考文獻(References):
[1] Islam N , Islam Z , Noor N . A Survey on Optical Character
Recognition System[J]. ITB Journal of Information and Communication Technology,2017.
[2] 陳永煌.集裝箱箱號識別技術(shù)的研究與實現(xiàn)[D].華中科技大學(xué),2013.
[3] 黃深廣,翁茂楠,史俞,劉清.基于計算機視覺的集裝箱箱號識別[J].港口裝卸,2018.1:1-4
[4] 劉璇.鐵路集裝箱號碼與車型智能識別系統(tǒng)研究[D].西南交通大學(xué),2018.
[5] Smith R. An Overview of the Tesseract OCR Engine[C]//?International Conference on Document Analysis & Recognition,2007.
[6] Lécun Y, Bottou L, Bengio Y, et al. Gradient-basedlearning applied to document recognition[J].Proceedings of the IEEE,1998.86(11):2278-2324
