一種結合Bigram語義擴充的事件摘要方法
2019-07-09 11:43:48吳佳偉
小型微型計算機系統 2019年7期
吳佳偉,曹 斌,范 菁,黃 驊
1(浙江工業大學 計算機科學與技術學院,杭州 310023) 2(中國電信股份有限公司浙江分公司,杭州 310014)
1 引 言
近年來,以UGC(User Generated Content)為代表的短文本在各類社交媒體中成井噴式增長,同時,這一類短文本還出現在一些企業的客服系統中,這些客服系統與專業領域緊密結合,分析這些短文本,從中檢測出一些用戶投訴的熱點事件,可以幫助企業有效改進他們的服務.而對熱點事件進行事件摘要可以進一步幫助企業理解事件的主要內容,以便企業可以及時針對用戶投訴的熱點事件做出及時決策與相應的調整.在本文中,我們主要集中于從描述同一事件的短文本集合中提取一組關鍵詞并擴展,從而達到提取出的事件摘要可讀性強,能夠幫助人理解的目的.在這里,我們假定描述同一事件的短文本集合已經事先知道,而在實際中,這一集合可以通過無監督的聚類方法或有監督的分類方法獲得,這取決于實際的應用場景.
然而,傳統的文本摘要方法并不能直接使用在我們的問題中.因為傳統的方法一般應用于長文檔,且大多數方法是基于句子做的[1,2],這種方法對文章中每個句子計算一個得分,最后選擇得分較高的句子作為文本摘要反饋給用戶.雖然這種方法提取出來的句子可讀性較強,但是往往一個句子中不會包含許多的關鍵詞,不能很好的概括整個事件;其次,一些基于關鍵詞提取的事件摘要算法[3,4]雖然可以從事件短文本集合中提取出較多的關鍵詞,但是這些關鍵詞之間由于不存在詞序,且關鍵詞之間相對獨立,因此借由這種方法提取的事件摘要的可讀性并不是很好.
綜上考慮,在本文中,我們提出了一種基于Bigram關鍵詞語義擴充的文本摘要方法.我們的方法首先通過一種基于Single-Pass的IDF計算方法在短文本集合中提取關鍵詞詞組,然后根據事件短文本集合中每個關鍵詞詞對出現的頻率對提取出來的關鍵詞詞組進行了排序,最后我們引入了Bigram語言模型對得到的關鍵詞詞組進行了語義擴充.實驗證明,相較于一些現有方法,我們的方法在中文數據集的表現上具有較高的召回率與較好的用戶可讀性.
2 預備知識
為了能夠幫助讀者更容易理解我們的方法,在本章中,我們介紹了一些預備知識,具體分為如下幾點.
2.1 TF-IDF
當我們需要抽取一篇文檔或者多篇文檔的關鍵詞時,一個直觀的想法就是直接統計所有詞在文檔中出現的次數,即詞頻.但是在實際操作中,通過上述方法得到的關鍵詞往往都是一些類似“的”、“我”這樣的噪聲詞.這些噪聲詞雖然具有很高的詞頻,但是它們并不能成為一篇或者多篇文檔的關鍵詞.因此,TF-IDF[5](Term Frequency-Inverse Document Frequency)的思想就應運而生了.
TF-IDF是一種用于衡量一個關鍵詞在一篇或多篇文檔中的重要性程度的一種指標.這種方法在現今的數據挖掘、文本處理、自然語言處理等領域都得到了較為廣泛的應用.TF-IDF算法的主要思想是:如果一個詞或者短語在一篇文章或者一個句子中出現的次數很高,但是這個詞在其他文章或者句子中出現的次數很少,那么就認為這個詞對于這篇文章或者這個句子來說就是一個關鍵詞.TF-IDF實際上就是 TF*IDF,其中TF(Term Frequency),表示一個詞在文檔中出現的總次數,一般來說,因為不同的文檔包含的詞個數也不同,為了避免不同文檔的長度對這個指標的影響,因此在最終計算中,會對這個指標進行歸一化處理;IDF(Inverse Document Frequency),其主要作用是降低類似于“我”、“的”這種噪聲詞的權重,提高關鍵詞的權重,從而達到突出關鍵詞重要性的作用.IDF的計算公式如公式(1)所示:
(1)
其中,Textnumber代表語料庫中文檔的總條數,wtextTF代表包含詞w的文本數.分母之所以要加1,是為了要避免分母為0的情況.TF-IDF值就是在此基礎上將每個詞的IDF值與其詞頻相乘得到的結果.
2.2 N-Gram語言模型
統計語言模型[6](Statistical Language Model)它是今天所有自然語言處理的基礎,并且廣泛應用于機器翻譯、語音識別、拼寫糾錯等方面.換句話說,統計語言模型中包含了訓練語料庫中所有文本單元可能的排列組合情況對應的出現概率.一個句子的出現概率就是通過幾個條件概率相乘得到的.而如何去計算這些條件概率,就是統計語言模型所做的工作.舉個例子,假設句子S是由詞序列w1,w2,w3…wn組成:
S=w1w2w3…wn
則根據條件概率公式,S出現的概率可以表示為:
(2)
其中,p(wk|w1w2…wk-1)表示第1個詞到第k-1個詞出現的前提下,第k個詞出現的概率.
但是,在實際應用中,當k越變越大時,統計w1w2…wk-1出現的條件下wk出現的概率往往不太符合實際情況.因此,N-Gram模型被提出.
N-Gram模型[7]也被稱為n-1階馬爾科夫模型,它是統計語言模型的一種簡化方式,它建立在如下的假設上:第n個詞的出現概率僅僅與其前面的n-1個詞相關.
因此,根據N-Gram的假設,則公式(1)可以表示成:
(3)
特別地,當N = 2時,即每個詞僅與其前一個詞有關,則更改公式(3)成:
p(S)=p(w1)p(w2|w1)p(w3|w2)…p(wn|wn-1)
(4)
根據條件概率的定義,為了計算p(wn|wn-1),模型需要從大量的訓練語料庫中統計wn-1,wn這一詞對前后相鄰出現的次數以及wn-1這個詞在同一語料庫中單獨出現的次數.即有:
(5)
其中,f(wn-1,wn)代表詞對wn-1,wn在語料庫中前后相鄰出現的次數,f(wn-1)代表詞wn-1在同一語料庫中出現的次數.
另外,對于N-Gram模型,N可以取任意數字.特別地,當N分別取1、2、3時,得到的N-Gram模型分別稱為Unigram、Bigram和Trigram.當然,N越大,可以刻畫語言結構越準確,但是越大的N取值會造成更大的計算量與更稀疏的模型等問題,這將對算法的存儲效率帶來巨大的挑戰[8].在實際應用中,一般取N=2或者N=3就可以達到較好的實際使用效果,且訓練Bigram或者Trigram模型不需要消耗大量的時間.在本文的算法中,N取2,即,本文使用Bigram模型對關鍵詞進行語義擴充.
3 相關工作
面向事件的自動摘要是指從短文本集合中抽取事件相關的信息并進行有效地組織[9].通過事件摘要,人們可以及時了解事件的大致信息.在本文中,每個事件由一定數量的短文本組成,因此對事件進行摘要的任務就轉換成為對文本進行自動摘要的任務.
現有的自動文本摘要大致可以分為兩類:抽取式(extractive)和生成式(abstractive).抽取式方法抽取原文本中的部分信息,但并不對其進行修改.生成式方法則需要系統去理解文章的內容,應用一系列自然語言處理的方法,生成與原文語義相近的摘要.顯然,我們的方法屬于前者,因此接下來我們將在本章簡單介紹在自動文本摘要領域的相關工作.
做自動文本摘要的最簡單易懂方法是基于統計的方法.除了基于詞頻的方法[10]與基于TF-IDF的方法[11]以外,基于詞匯鏈(lexical chains)的自動摘要方法[12,13]也是一種比較簡單可行的方法,該方法不再以單個詞作為分析單元,而是利用WordNet、維基百科等對詞匯的語義進行分析,把原文中與某個主題相關的詞集合起來,構成詞匯鏈.這一類方法雖然簡單易用,但是提取出來的文本摘要的可讀性并不是很好,通常僅憑少數且無序的關鍵詞,人們往往不能很好的了解所發生的事件的真實情況.
還有一種比較常見的方法是基于圖排序的自動摘要方法.Ricard等人[14]指出,在基于圖排序的自動摘要方法中,構成結點的往往是詞、句子等文本單元,結點之間以句子相似性、詞共現關系、語義相似性、句法關系等相連接以構成文本關系圖,接下來再應用圖排序算法來計算每個節點的重要性得分,最后再在此基礎上生成文本摘要.TextRank[15]和LexRank[16]是這類方法的代表方法.在上述兩種方法中,他們把每個句子作為圖的頂點,句子之間的相似度作為邊的權值.耿煥同等人[17]則是利用句子之間共有的一些詞,提出了一種基于詞共現圖的文檔自動摘要算法這類方法.但是在計算的時候需要得知全部的文本單元與每個文本單元之間的關系,這對算法的空間復雜性提出了較大的挑戰.同時,上述方法并沒有考慮關鍵詞之間的順序對文本摘要可讀性的影響.
還有一種方法是基于主題模型的方法來進行自動摘要.這一類方法首先需要確定文檔中有幾個主題,然后選擇對主題描述較好的詞匯,之后按照一些語法規則組成句子、段落、篇章等[18].Hofmann[19]提出的PLSA模型認為:一篇文檔可以由多個主題混合而成,而每個主題都是由一些詞的概率分布組成.而LDA[20]在PLSA的基礎上加入了Dirichlet先驗分布,是PLSA的突破性的延伸.但是,直接使用傳統的LDA或PLSA可能不能很好地用于短文本的主題建模.當然,之后也有許多學者在LDA主題模型上進行改進,例如Labeled-LDA[21],Twitter-LDA[22],MB-LDA[23]等.這些模型均是在社交媒體的大背景下被提出,應用于事件摘要,但是采用這類方法提取出的事件摘要不具備很好的可讀性,在實際操作中往往效果不會很好.
4 基于Bigram關鍵詞擴展的事件摘要技術
在本章中,我們將主要介紹我們的事件摘要方法.其主要流程如圖1所示.可以看到,短文本流數據在經過數據預處理與事件檢測步驟后,每個事件由一定數量的短文本組成.其次,為了生成可讀性較強的事件摘要,每個事件需要經過如下兩個組件:關鍵詞提取與Bigram語義擴展.關鍵詞提取組件通過計算每個事件中每個詞的IDF值來從每個事件中提取出關鍵詞;然而,僅僅只用幾個關鍵詞來做事件摘要是不夠的,因為只通過少數且無序的關鍵詞,人們往往無法明白事件的真正內容.因此通過Bigram語義擴充組件,我們將上述提取出的關鍵詞進行排序和語義擴充,使每個事件摘要的可讀性更強,包含的語義信息更多.接下來我們將詳細介紹我們算法的每個組件.
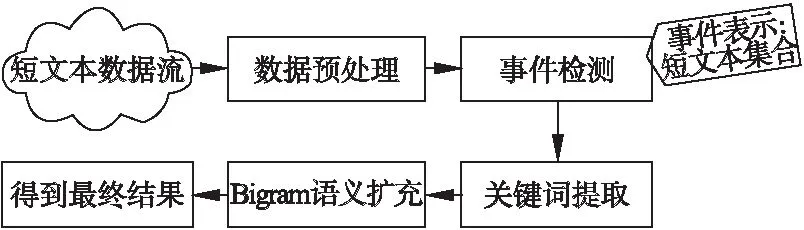
圖1 事件摘要方法整體架構圖Fig.1 Framework of event summarization algorithm
4.1 關鍵詞提取組件
度量一個詞對一個事件是否重要的一個簡單方法是看這個詞在這個事件對應的文本集合中的詞頻高低.從理論上來說,這是一種很直觀的方法,如果在事件檢測中檢測到的事件大多描述同一件事,那么事件核心詞的出現頻率應該很高.然而在實際操作中,這種方法并不適用于短文本的關鍵詞提取.在短文本集合構成的事件中,由于短文本本身短且噪聲多的特點,許多事件的文本經詞頻統計后排在前幾位的往往是一些噪聲詞而非事件的核心關鍵詞.因此,在本組件中,我們使用IDF來對每個事件進行關鍵詞的抽取.
傳統的IDF計算方法是針對每個詞來說的,即針對每一個詞w,統計這個詞在當前文本集合中出現的文本條數Textw.可以注意到的是,Textw并不一定和w的詞頻是完全相等的,因為我們不排除一條文本內可能出現多次詞w的情況.這種方法雖然在計算上比較直觀,但是在集合中文本數量較大的情況下,這種方法是極其耗時的.因此在本文中,我們提出了一種基于Single-Pass的IDF計算算法.其偽代碼如算法1所示.
該算法的主要步驟介紹如下:
1)按順序遍歷輸入的文本分詞列表Lists,針對每條文本分詞s,對其進行詞去重.(line 2-3)例如現有一條文本分詞s為:w1,w2,w1,w3,則去完重復的詞后s為:w1,w2,w3.這么做的原因是,根據公式(1)中IDF值的計算方法,為了計算一個詞的IDF值,我們需要計算在當前語料庫中包含該詞的文檔數.因此在去完重復的詞后,再對剩下的詞進行詞頻統計,得到的結果即為語料庫中包含各個詞的文檔數.
2)完成單條文本去重后,統計剩下的文本分詞結果中每個詞的詞頻.(line 4)
3)接下去針對每個詞,我們得到包含該詞的文本條數以及當前語料庫中總文本條數,再應用公式(1)計算每個詞的IDF值后存入Mapidf.(line 6-10)
4)當所有詞的IDF值都計算完畢后,返回Mapidf.(line 11)
最后,關鍵詞提取組件將從上述列表中提取IDF值最高的top-K個詞作為事件關鍵詞.
算法1.基于Single-Pass的IDF計算算法
輸入:一個事件對應的文本分詞列表Lists
輸出:該事件中對應的每個詞的IDF值列表Mapidf
1. 初始化Map:MapTextTF用于存放詞w在當前文本集合中出現的文本條數Textw.
2. FOR EACHs∈ListsDO
3. s = Distinct(s);
4. 統計s中每個詞的出現次數存入MapTextTF
5. END FOR
6. FOR EACHw∈MapTextTFDO
7.wTextTF=MapTextTF.get(w);
8.wIDF=Cal_idf(wTextTF,Lists.size());
9. Mapidf.put(w,wIDF);
10. END FOR
11. RETURN Mapidf
4.2 基于Bigram的關鍵詞擴展組件
在關鍵詞提取組件獲得一個事件的關鍵詞后,為了讓提取出的關鍵詞具備更強的可讀性,在本小節中,我們提出了一種基于Bigram的關鍵詞擴展方法.算法流程圖如圖2所示.
從流程圖中我們可以得知,本組件的輸入是需要進行事件摘要的文本集合、關鍵詞提取組件提取的關鍵詞詞組和事件特征詞列表.
首先,組件需要加載Bigram模型.這個模型是事先通過大量語料進行訓練的,根據Bigram的定義,這個模型中存儲的是在大量語料庫中每個詞與其他詞前后相鄰出現的次數以及每個詞單獨出現的次數的統計值.之所以采用這種方式進行存儲,目的是當新的語料到來時,我們可以方便的進行增量訓練.若模型文件中存儲的是每個詞對出現的概率,當新的語料到來時,這種方法必須將新語料和舊語料進行合并再次進行模型訓練,這是相當費時的.因此我們采用了直接存儲詞頻的方式.當新的語料到來時,我們只需要將新語料中每個詞對和詞出現的頻率統計出來累加到模型中,這樣既減小了訓練時間,又實現了模型的增量訓練.
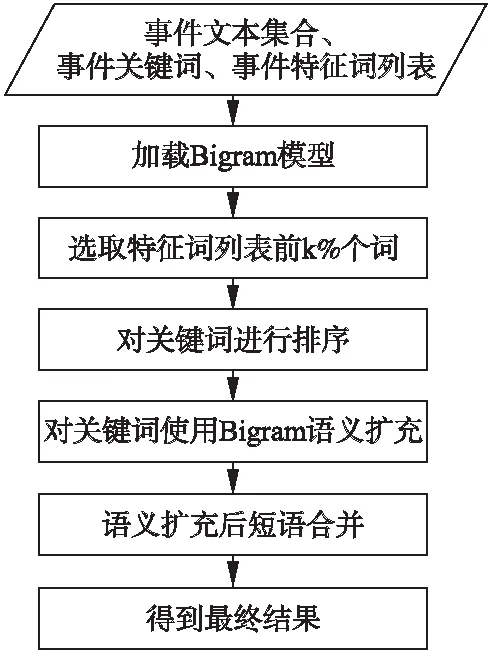
圖2 基于Bigram的關鍵詞擴展組件流程圖Fig.2 Flow chart of Bigram-based keyword expansion component
其次,組件會在事件特征詞列表中選擇排名前k%的詞.由于事件特征詞列表是根據每個詞的TF-IDF值進行排序的,因此排名越是靠后的詞對事件的貢獻程度越不突出.為了避免這些詞對算法的干擾,我們在這里僅選擇事件特征詞列表中選擇排名前k%的詞,其中,k為一個可調整的參數.
由于關鍵詞之間不同的順序會造成完全不同的含義,例如“計算機 學會”和“學會 計算機”.這兩種情況所表達的意思完全不同.前者可能表示的是一個組織,而后者則是表示某人學會使用計算機的某種程序.因此,為了還原關鍵詞之間本來的順序,消除歧義,我們需要對輸入的關鍵詞詞組進行排序.首先,為了確定兩個關鍵詞w1,w2之間的前后關系,我們引入了事件原文本作為排序依據,分別在事件原文本中統計詞對
當所有的關鍵詞詞組依據事件文本排好序后,下一步就是對每個關鍵詞進行Bigram語義擴展.針對每一個關鍵詞,本文需要將其進行前后擴充,直到擴充后的詞個數為m.在本文中,m取3,即把一個關鍵詞擴充為3個詞的組合.根據Bigram的定義,我們需要將關鍵詞與特征詞集合中的每個詞組合計算概率,最后選擇出現概率最高的詞作為該關鍵詞的擴展詞.可以注意到的是,在這一過程中我們設定了一個概率閾值τ,當最后選擇的出現概率最高的詞的概率都不大于該閾值時,我們就放棄該詞的擴展.
最后,當我們把所有詞進行擴展后,假設關鍵詞w1,w2,w3已經被擴展為waw1wb,wbw2wC,w3,可以觀察到,w1,w2擴展后的詞對間wb是相同的.根據Bigram的定義,若將wb繼續向后擴展,得到的詞一定是w2.因此,我們在最后一步中將兩個擴展后的詞合并,即當第一個詞向后擴充的詞與第二個詞向前擴充的詞相同時,通過刪除重復的詞將這兩個擴展結果合并,因此就能得到最后結果waw1wbw2wC,w3.
5 實 驗
5.1 數據集與數據標注
本文實驗中采用的數據集是來自某電信公司業務部門提供的 2017 年 11月的投訴工單,一共包含2256條文本數據,其中囊括了該電信公司真實發生的24個事件,而且投訴工單的平均文本長度大約在140個字符左右.
在數據標注方面,我們請該電信公司的業務人員逐一看過每個事件的文本后,再根據他們平日的業務經驗對每個事件進行歸類、標注.
對于Bigram模型的訓練,本文同樣采用了該電信公司業務部門提供的投訴工單,共300000條文本記錄.另外,電信公司的業務人員還提供了一個適用于電信領域的專業名詞詞庫,通過該詞庫我們可以降低在關鍵詞提取的過程中噪聲的影響.
當然,在數據集選擇上,本文亦可采用英文數據集,在使用時僅需提供相應語料即可.
5.2 評估方法
針對本文提出的算法得到的摘要結果,我們采用了幾個廣泛使用的評價指標來評估我們的算法的有效性.例如準確率、召回率、F值等.準確率和召回率是信息檢索領域中兩個較為重要的指標,準確率反映算法對不同主題的區分能力,準確率越高,每個類中的內容就越集中;召回率主要用來衡量算法結果與人工標注的吻合程度,召回率越高,則算法結果越符合實際情況;F值是綜合準確率和召回率的評價指標,其值介于 0 到 1 之間,反映了算法的綜合性能.本文采用的準確率與召回率的公式如下:

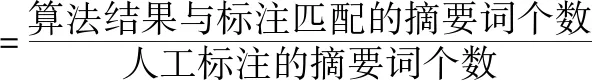
5.3 IDF與專有名詞詞庫的有效性
在本節中,我們將通過實驗證明IDF與專有名詞詞庫在短文本關鍵詞選擇中的有效性.由于在短文本數據集中,TF-IDF是公認的效果較好的方法,因此在本節中,我們選擇TF-IDF作為我們的對比方法.相關實驗結果如表1所示.
表1 采用TF-IDF、IDF與專有名詞詞庫進行關鍵詞提取的效果對比
Table 1 Comparisons of keyword extraction results using TF-IDF 、IDF and jargon dictionary

方法召回率(%)準確率(%)F值(%)TF-IDF43.402834.166737.6172IDF52.847241.666745.9043TF-IDF+專有名詞詞庫68.263953.333358.7762IDF+專有名詞詞庫83.055664.166771.1373
從表1中我們可以看出,使用TF-IDF值做關鍵詞提取與僅使用IDF值做關鍵詞提取的結果大不相同.僅使用IDF做關鍵詞提取的結果在召回率、準確率與F值上均高于使用TF-IDF值做關鍵詞提取的結果.而且,通過在分詞過程中加入專有名詞詞庫過濾后再采用兩種特征值進行關鍵詞提取,其結果也是明顯高于不使用專業名詞詞庫進行關鍵詞提取的結果.這是因為通過專業名詞詞庫對分詞結果進行過濾,可以減少噪音的影響,從而提升了效果.
5.4 算法參數選擇
在上一小節中,我們可以得出,在進行關鍵詞提取中使用IDF值作為特征值以及使用專業名詞詞庫對實驗結果的有效性.在本節中,我們將具體討論在算法中的兩個參數“k”(選擇前k%的關鍵詞進行語義擴展)與“τ”(低于該閾值將不再擴展)對我們算法準確率、召回率以及F值的影響.實驗結果如圖3所示.
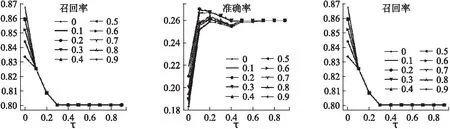
圖3 不同的k值與τ值對算法召回率、準確率與F值的影響Fig.3 Influence of different k values and τ values on algorithm recall,precision and F value
其中,橫坐標表示不同的τ值,不同的折線代表不同的k值,縱坐標表示在不同的τ值和k值影響下的算法召回率、準確率和F值的結果.從圖中可以看出,當k值與τ值在不斷變化的時候,算法的召回率在下降,而準確率和F值在提升,最后趨于平穩.這是因為當τ值不斷變大時,Bigram不再在當前關鍵詞的基礎上再加以擴展,因此結果也就接近于僅使用IDF與專業名詞詞庫提取出的關鍵詞摘要的結果.此外,k值則影響著算法選擇多少候選詞匯對關鍵詞進行擴展,當k值過大時,候選詞匯過多,帶來的噪聲也會較大,但會提升摘要的可讀性(準確率),反之亦然.
5.5 方法對比與實驗分析
為了展示本文方法的有效性,我們將本文的方法與如下的一些現有方法進行對比:
·選擇事件特征詞列表中詞頻最高的top-K個詞.
·選擇事件特征詞列表中TF-IDF值最高的top-K個詞.
·TextRank是一種基于圖排序的文本摘要方法,我們選取由TextRank計算后得到的top-K個詞作為事件摘要.
表2 現有方法與本文方法的對比
Table 2 Comparisons of the state-of-art algorithms
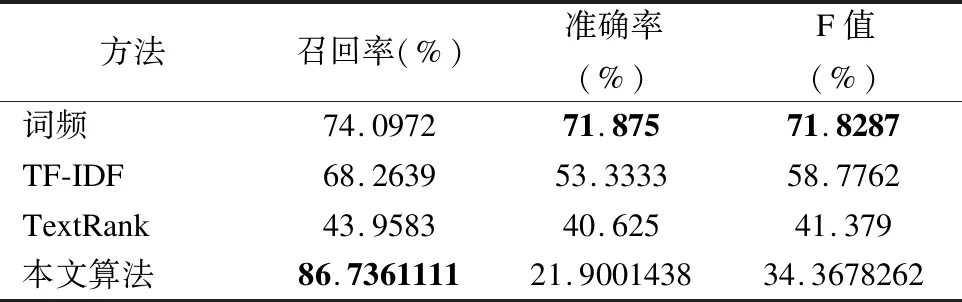
方法召回率(%)準確率(%)F值(%)詞頻74.097271.87571.8287TF-IDF68.263953.333358.7762TextRank43.958340.62541.379本文算法86.736111121.900143834.3678262
針對上述所有方法,我們采用了同一份數據集,進行相同的數據預處理以及人工標注進行實驗.因為上述四種方法中均采用了選取top-K個詞進行文本摘要,在我們的實驗中,考慮到人工標注的詞長度均在4個詞左右,因此我們選擇K=4.實驗結果如表2和表3所示.
表3 現有方法與本文方法的結果對比(關鍵詞間有順序)
Table 3 Examples of the state-of-art algorithms and our algorithm(Orders between keywords are contained)

人工標注本文算法詞頻(top-4)TF-IDF(top-4)TextRank(top-4)手機 無法主被叫 信號不穩定 要求核實手機 無法主被叫 信號 不穩定 提示故障 信號 手機 不穩定信號 手機 無法被主叫 提示故障 手機 信號 提示寬帶 包年到期轉包月收費 不認可寬帶 包年到期 轉包月 收費不認可 金額 費用不認可 收費 包年到期 寬帶費寬帶 認可 到期 金額包年到期 不認可 收費 金額積分商城 積分兌換地址 錯誤省內 積分商城 積分 客戶 兌換 地址 客服地址 積分商城 兌換 積分地址 兌換 積分商城 省內積分 地址 兌換 商城增值業務 計費 訂購愛游戲 費用 退費增值業務 計費 訂購 愛游戲 費用訂購 增值業務 計費 費用增值業務 費用 愛游戲 計費增值業務 訂購 計費
從表中我們可以看出,基于詞頻的方法得到了較高的準確率與F值,而我們的方法得到了較高的召回率.因為在文本分詞結果經過專業名詞詞庫過濾后,分詞結果中僅剩下專業名詞.而在電信公司的投訴工單中發生的相關事件經業務人員標注后,人工標注的摘要中大多為電信領域的專有詞.所以僅通過統計詞頻的方法獲得了較高的準確率.而本文算法則獲得了較低的準確率,這是因為本文算法是基于IDF關鍵詞提取的基礎上將關鍵詞進行擴展,因此得到的事件摘要包含的詞個數較多,因此準確率較低.但是經過了關鍵詞排序與Bigram語義擴充后的事件摘要可讀性更強,用戶可以更清楚的明白事件的主要內容.
6 總 結
在本文中,我們提出了一種基于Bigram關鍵詞語義擴充的事件摘要方法.實驗結果表明,本文算法在召回率與用戶可讀性方面取得了較好的結果.如何提升算法效率和算法的準確率,使之能夠采用更精煉的關鍵詞個數來描述事件,是我們的下一步工作.實際上,本文的事件摘要算法已經應用于一個真實的客服數據分析系統中,其有效性得到了該系統的服務對象的認可.
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
制造技術與機床(2019年10期)2019-10-26 02:48:08
電子制作(2018年18期)2018-11-14 01:48:06
光學精密工程(2016年6期)2016-11-07 09:07:19
Coco薇(2016年2期)2016-03-22 02:42:52
小學教學參考(2015年20期)2016-01-15 08:44:38
Coco薇(2015年1期)2015-08-13 02:47:34
小雪花·成長指南(2015年4期)2015-05-19 14:47:56
