一種面向醫(yī)學(xué)文本數(shù)據(jù)的結(jié)構(gòu)化信息抽取方法
2019-07-09 11:57:44聶鐵錚申德榮
小型微型計算機系統(tǒng) 2019年7期
楊 兵,聶鐵錚,申德榮,寇 月,于 戈
(東北大學(xué) 計算機科學(xué)與工程學(xué)院,沈陽 110819)
1 引 言
隨著國內(nèi)信息技術(shù)蓬勃發(fā)展,數(shù)字化建設(shè)步伐加快,各大醫(yī)療機構(gòu)在很好地服務(wù)人們的同時也積累了大量的醫(yī)學(xué)信息數(shù)據(jù).然而,目前大部分的醫(yī)療文本都是以自然語言描述的非結(jié)構(gòu)化數(shù)據(jù),如醫(yī)學(xué)影像報告、病理報告等.由于自然語言與機器語言之間存在巨大鴻溝,導(dǎo)致用計算機直接處理和分析非結(jié)構(gòu)化文本的效率較低,也影響了分析結(jié)果的質(zhì)量[1].因此,如何利用現(xiàn)有的技術(shù)方法從非結(jié)構(gòu)化的醫(yī)學(xué)文本數(shù)據(jù)中提取潛藏的、有價值的信息逐漸成為信息抽取[2,3]領(lǐng)域關(guān)注和研究的重點.
醫(yī)學(xué)影像報告是醫(yī)生根據(jù)X線片、CT、MR等影像學(xué)資料編寫的一種電子文本記錄,是一種典型的非結(jié)構(gòu)化數(shù)據(jù),其目的是反映疾病在某一階段的病理變化和功能改變,是重要的臨床診斷參考依據(jù).然而,目前的醫(yī)學(xué)影像報告主要是通過醫(yī)務(wù)工作者在電子信息系統(tǒng)中手動編寫的方法來產(chǎn)生.一方面,這種報告文本往往沒有固定的書寫格式,并且要求表述確切、內(nèi)容全面,常常使用大量的醫(yī)學(xué)術(shù)語進行描述;另一方面,為了方便臨床醫(yī)生的快速診斷,要求文字簡明扼要、重點突出,因而常常使用短句描述,這就需要豐富的醫(yī)學(xué)領(lǐng)域知識和一定的語言學(xué)功底.
針對以上問題,本文在分析醫(yī)學(xué)影像報告數(shù)據(jù)特征的基礎(chǔ)上,提出了一種高效的針對醫(yī)學(xué)文本數(shù)據(jù)的結(jié)構(gòu)化信息抽取方法.該方法首先構(gòu)建VSM模型[4]對訓(xùn)練文本進行聚類,再從聚類后的文本集合中識別并提取醫(yī)學(xué)描述語言常用的關(guān)鍵詞,以生成醫(yī)學(xué)領(lǐng)域的專業(yè)術(shù)語庫,并將該醫(yī)學(xué)術(shù)語庫用于提高中文分詞處理的效果,然后對文本中的描述短句進行語義依存分析并構(gòu)建依存句法樹,以實現(xiàn)對醫(yī)學(xué)描述中的關(guān)鍵指標(biāo)及其指標(biāo)值的抽取,最終得到
2 相關(guān)工作
早期的結(jié)構(gòu)化信息抽取主要面向英文文本,因為英文語法形式更為規(guī)范,并且已經(jīng)構(gòu)建了強大的語義知識庫(WordNet[5]等),而國內(nèi)針對中文文本的結(jié)構(gòu)化抽取技術(shù)還相對不夠成熟,這主要因為國內(nèi)該領(lǐng)域的研究起步較晚,且中文語法復(fù)雜,常常需要進行中文分詞[6,7]、實體識別[8]等處理,這使得針對中文的結(jié)構(gòu)化數(shù)據(jù)抽取更為困難,并且現(xiàn)有的知識庫(HowNet[9]等)并不支持特定領(lǐng)域內(nèi)的詞匯和語法.尤其是面向醫(yī)學(xué)文本數(shù)據(jù),由于書寫自由、領(lǐng)域突出等特點,采用的方法大多依賴于通用的中文分詞系統(tǒng),如北京理工大學(xué)張華平博士團隊的NLPIR[10]、復(fù)旦大學(xué)自然語言處理團隊的FNLP[11]以及從開源項目Lucene發(fā)展而來的IKAnalyzer[12],此外還需要中文醫(yī)學(xué)知識庫的支持(如CMeSH[13]).
目前,對非結(jié)構(gòu)化的醫(yī)學(xué)文本進行信息抽取大多采用基于規(guī)則的方式,但由于醫(yī)療文本中不同組織器官所具有的屬性不同,且描述不同病種所使用的指標(biāo)詞也不同,所以若想制定出一種適用所有醫(yī)學(xué)報告形式的結(jié)構(gòu)化規(guī)則十分困難[1].因此,研究人員從自然語言處理和機器學(xué)習(xí)兩個方向做了很多嘗試.
Socher R[14]等人提出了一種基于依賴關(guān)系樹的DT-RNN模型,該模型與之前使用分區(qū)樹的RNN模型不同,DT-RNN能更好地抽象出詞序和句法的細節(jié)描述,并使用遞歸神經(jīng)網(wǎng)絡(luò)將句子映射到一個抽象空間,然后計算句子在依賴樹中的向量表達,最終通過這種方法得到的句子向量所包含的語義信息.
Li[15]等人提出一種基于詞語位置增益和知識庫(HowSet)語義的計算模型——LaSE,考慮文本數(shù)據(jù)中的位置特征和語義特征,而位置特征具有可計算性和可操作性,語義特征具有可理解性和現(xiàn)實性,通過這種特征結(jié)合的方式來進行實體關(guān)系抽取.
Jonnalagadda S[16]等人使用語義劃分來進行醫(yī)學(xué)領(lǐng)域的概念抽取,該方法使用判別式分類器(CRF)來提取醫(yī)療事故、臨床描述以及試驗中的醫(yī)學(xué)概念.通過語義劃分的方式來構(gòu)建索引,然后從未標(biāo)注的語料數(shù)據(jù)中構(gòu)建向量空間模型,進行分類任務(wù),并從給定的句子分類結(jié)果中抽取出詞匯模式.
Denecke K[17]等人使用統(tǒng)一醫(yī)學(xué)語言系統(tǒng)(UMLS)來進行語義結(jié)構(gòu)化和信息提取,并提出了一種從自然語言文本數(shù)據(jù)中自動生成知識表示的方法——SeReMeD,然后結(jié)合現(xiàn)有的語言工程方法和語義轉(zhuǎn)換規(guī)則,將語義信息映射為語義表示,并通過這種方式將醫(yī)學(xué)文獻的內(nèi)容轉(zhuǎn)換為結(jié)構(gòu)化的語義信息.
上述方法都主要從模型和方法角度來進行研究,而忽略了數(shù)據(jù)本身的特征,即沒有充分考慮醫(yī)學(xué)文本數(shù)據(jù)(如醫(yī)學(xué)影像報告)所獨有的詞匯特征和語法特征.本文在總結(jié)各種模型和方法的同時,深入分析了實驗數(shù)據(jù)本身的特殊性以及與其他文本數(shù)據(jù)的差異性,針對醫(yī)學(xué)領(lǐng)域的專業(yè)詞匯和醫(yī)學(xué)報告的語法習(xí)慣分別構(gòu)建醫(yī)學(xué)術(shù)語庫和依存關(guān)系庫,并進行多次迭代計算,以實現(xiàn)高魯棒性和可擴展性.
3 問題描述
醫(yī)學(xué)文本是醫(yī)務(wù)工作者在電子信息系統(tǒng)中采用自然語言編寫的一種記錄報告.以醫(yī)學(xué)影像報告為例,醫(yī)生通過觀察醫(yī)學(xué)影像設(shè)備(如胃鏡、支氣管鏡、CT、彩超等)的圖像顯示,給出病灶在某一階段的病理變化和功能改變的描述,數(shù)據(jù)樣例如表1所示.
表1 醫(yī)學(xué)影像報告數(shù)據(jù)樣例
Table 1 Data sample of medical imaging reports

檢查項目主要病癥人工描述支氣管鏡肺惡性腫瘤氣管環(huán)清晰,粘膜正常,隆突銳利,血管紋理清晰,左上葉管口可見新生物,管腔完全阻塞,取病理,左肺二級隆突粘膜充血,肥厚,左下葉管口粘膜充血,肥厚,左下葉B6管口局部粘膜充血,左肺余支氣管開口正常,未見新生物,右肺各支氣管開口正常,未見新生物.
因此,醫(yī)學(xué)影像報告是醫(yī)生編寫的一種病情描述,由表1可知,其用詞上大量使用醫(yī)學(xué)術(shù)語,如“氣管環(huán)”、“隆突”、“管腔”等;語法上主要采用短句結(jié)構(gòu),并為了語言精簡而大量省略動詞,同時常常伴有文言句式的表達形式,如“取病理”、“可見……”、“未見……”等.為了減少人工閱讀量,需要從這些文本數(shù)據(jù)中抽取結(jié)構(gòu)化信息,但前提是必須準(zhǔn)確識別這種自然語言描述中的關(guān)鍵指標(biāo)及其相對應(yīng)的指標(biāo)值.下面給出本文所涉及到的幾個定義.
定義1.病灶.機體上發(fā)生病變的部分,包括人體中任何組織器官的病變.
定義2.關(guān)鍵指標(biāo).對人體指定部位檢查所涉及到的組織名和器官名等名詞.
定義3.指標(biāo)值.一種與關(guān)鍵指標(biāo)名相對應(yīng)的描述信息.
以表1中的數(shù)據(jù)為例,在人工描述中包含“氣管環(huán)”、“粘膜”、“血管紋理”等人體肺部的組織器官名,即為關(guān)鍵指標(biāo)名,而對于這些指標(biāo)名的描述即為對應(yīng)的指標(biāo)值.因此,可以大致得到表1中人工描述信息進行抽取后的結(jié)果,如表2所示.
表2 結(jié)構(gòu)化抽取結(jié)果示例
Table 2 Example of structured extraction
4 醫(yī)學(xué)文本結(jié)構(gòu)化抽取方法
4.1 處理框架
本文提出的方法主要是對醫(yī)學(xué)報告文本中的結(jié)構(gòu)化信息進行抽取,如圖1所示,系統(tǒng)分為兩個處理模塊:
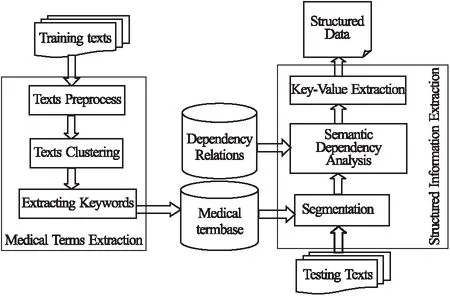
圖1 醫(yī)學(xué)文本數(shù)據(jù)結(jié)構(gòu)化抽取過程Fig.1 Processing of structured extraction for medical text data
1)在醫(yī)學(xué)術(shù)語提取模塊,對預(yù)處理后的訓(xùn)練文本進行聚類,然后在每個文本類簇中進行關(guān)鍵詞抽取,以獲取具有豐富領(lǐng)域知識的醫(yī)學(xué)術(shù)語庫.
2)在結(jié)構(gòu)化信息抽取模塊,利用生成的醫(yī)學(xué)術(shù)語庫提高測試文本的分詞質(zhì)量,再利用現(xiàn)有的依存關(guān)系庫進行語義依存分析,構(gòu)建依存句法樹的結(jié)構(gòu),然后依據(jù)語法規(guī)則抽取關(guān)鍵指標(biāo)及其對應(yīng)的指標(biāo)值,最終得到結(jié)構(gòu)化的輸出結(jié)果.
4.2 醫(yī)學(xué)術(shù)語提取
該模塊包含文本預(yù)處理、文本聚類和關(guān)鍵詞抽取三個操作,主要處理的是訓(xùn)練文本,目的是為了獲取具有領(lǐng)域知識的醫(yī)學(xué)術(shù)語庫.在預(yù)處理階段,主要是分詞和數(shù)據(jù)清洗,包括去除停用詞和過濾句子結(jié)束符等.關(guān)于文本聚類和關(guān)鍵詞提取兩個階段,本文將分別在4.2.1節(jié)和4.2.2節(jié)中詳細介紹.
4.2.1 文本聚類
如第3小節(jié)所描述的數(shù)據(jù)特征,醫(yī)學(xué)文本往往句式復(fù)雜并且常常采用大量短句結(jié)構(gòu),從而造成語義晦澀,不便于機器理解,類別分散,聚類數(shù)據(jù)量大等困難,所以常用的聚類算法[18]并不能很好地處理這類數(shù)據(jù).因此,本文采用了基于向量空間模型(VSM)的文本聚類方法,以向量的形式來量化分析醫(yī)學(xué)文本的類別特征.
在向量空間模型中,每一個文本被看成一個詞匯集合,然后被表示成詞條權(quán)重的向量:
di={wi1,wi2,…,win}
(1)
其中,di表示一個文本,n表示詞條空間的維數(shù),每一個詞條的權(quán)重win代表了該詞條在文本中的重要性.
本文使用TF-IDF方法來計算詞條的權(quán)重,并使用向量的余弦系數(shù)來衡量文本之間的相似度[4],最終將文本數(shù)據(jù)劃分到不同的類簇中.
4.2.2 關(guān)鍵詞提取
為了獲得醫(yī)學(xué)領(lǐng)域的常用術(shù)語,需要提取每一個文本類簇中重要的描述詞,即醫(yī)學(xué)文本中的關(guān)鍵詞.為此,本文使用一種改進的TextRank[19,20]算法,在有向圖結(jié)構(gòu)中使用依存關(guān)系作為節(jié)點詞之間關(guān)聯(lián)的主要規(guī)則,并且采用短句拆分的方式來降低圖結(jié)構(gòu)的復(fù)雜程度.如算法1所示,這種方法可以在不需經(jīng)過預(yù)先訓(xùn)練的情況下進行關(guān)鍵詞提取.
考慮到依存關(guān)系只出現(xiàn)在相鄰兩個詞之間且文本以短句為主,所以算法1中的窗口大小k設(shè)置為2,權(quán)重收斂條件為連續(xù)兩次計算的結(jié)果相差不超過0.0001,權(quán)重更新的最大迭代次數(shù)count為10,候選關(guān)鍵詞數(shù)t為3.
然而,由于構(gòu)建有向圖之前還需要利用現(xiàn)有工具對描述短句進行分詞和詞性標(biāo)注,鑒于目前的各種NLP系統(tǒng)在醫(yī)學(xué)領(lǐng)域的文本數(shù)據(jù)上處理效果一般,所以在利用算法1提取出關(guān)鍵詞后還需要進一步的人工校正,以提高醫(yī)學(xué)術(shù)語庫的可用性.
4.3 結(jié)構(gòu)化信息抽取
該模塊包含中文分詞、語義依存分析和關(guān)鍵指標(biāo)抽取三個操作,目的是從醫(yī)學(xué)文本中抽取出結(jié)構(gòu)化的鍵值對數(shù)據(jù).在中文分詞階段,本文采用基于HMM訓(xùn)練模型的Jieba分詞系統(tǒng),并利用在4.2節(jié)中生成的醫(yī)學(xué)術(shù)語庫來識別醫(yī)學(xué)文本描述中的命名實體,包括人體組織名、器官名和一些常用的醫(yī)學(xué)表述詞,以此來提高醫(yī)學(xué)領(lǐng)域文本數(shù)據(jù)的分詞質(zhì)量,而語義依存分析和關(guān)鍵指標(biāo)抽取兩個階段將分別在4.3.1節(jié)和4.3.2節(jié)中詳細介紹.
算法1.基于TextRank的關(guān)鍵詞提取算法
輸入:文本類簇集合CLUSTERS,每個類簇包含若干個文本dj,迭代次數(shù)count,窗口大小k,候選詞數(shù)t;
輸出:關(guān)鍵詞集合KeyWords.
1. 初始化WordSet=φ,迭代次數(shù)count=0;
2. FORCiINCLUSTERS
3. FORdjINCi
4.WordList=posSegment(dj);
5. FORwkINWordList
6. Filter(wk);/*對wk進行語法過濾*/
7. Graph←wk;/*將詞wk添加到有向圖中*/
8. IF dependency(wk,wl,k)
9. Graph←edge;/*添加有向邊*/
10.WS←Init();/*初始化權(quán)重*/
11. WHILEcount 12. IFWS達到收斂 break; 13. Update(WS);/*更新權(quán)重WS*/ 14. count++; 15. WHILE 節(jié)點Vi≠NULL 16. Sort(WS) /*節(jié)點權(quán)重降序排列*/ 17. WHILEi 18.WordSet←Vi;/*將節(jié)點詞添加到KeyWords*/ 19.count←0;/*更新迭代次數(shù)為0*/ 20. RETURNKeyWords. 4.3.1 語義依存分析 由于醫(yī)學(xué)文本都是采用自然語言描述的,需要通過語義分析來進行解析,因此本文利用依存語法來分析詞條之間的這種語義依存[21-23]關(guān)系.依存語法是一種描述句子中各個詞條之間的依存結(jié)構(gòu)的語法,這種語法不僅表示形式簡單,而且保留了短語結(jié)構(gòu)信息.語言學(xué)家Robinson[24]總結(jié)了依存語法的理論基礎(chǔ),歸納出以下4個公理: 公理1.一個句子中只有一個成分可以作為核心成分; 公理2.一個句子中的某一成分直接依存于句子中的其他成分; 公理3.句子中的任何成分不能依存于兩個或者兩個以上的成分; 公理4.句子中具有依存關(guān)系的成分之間不能有交叉關(guān)系. 根據(jù)依存語法的4個約束公理,本文在現(xiàn)有語法規(guī)則的基礎(chǔ)上歸納總結(jié)了中文自然語言中常用的14種語義依存關(guān)系,如表3所示.同時為了方便檢索和理解,本文對每一種依存關(guān)系都做了相應(yīng)的標(biāo)注和英文描述,通過這些常見的語義依存關(guān)系來構(gòu)建一個依存關(guān)系庫,并將其應(yīng)用于后續(xù)的語義依存分析處理. 在語義依存分析階段,本文使用CRFs模型獲取短句中任意兩詞之間最可能的依存關(guān)系,并采用最小生成樹算法來構(gòu)建依存句法樹.以表1中的數(shù)據(jù)樣例為例,人工描述中寫到“左上葉管口可見新生物”,進行中文分詞后可得到詞條序列{“左上葉/nz”、“管口/n”、“可見/v”、“新生物/n”},再分析語義依存關(guān)系可得到圖2所示的依存句法樹.由圖2可知,依存關(guān)系樹的根節(jié)點就是每個短句具有核心關(guān)系的詞,即整個句子的核心,每個節(jié)點包含了原始詞、詞性以及該節(jié)點與其父節(jié)點之間的依存關(guān)系(根節(jié)點除外).由于醫(yī)學(xué)報告文本往往以短句的形式來描述,因此生成的依存句法樹通常結(jié)構(gòu)相對簡單,并且樹的高度較低,這樣便于從這種樹形結(jié)構(gòu)中抽取 表3 語義依存關(guān)系歸納 序號依存關(guān)系標(biāo)注描述1主謂關(guān)系SBVSubject-verb2動賓關(guān)系VOBVerb-object3定中關(guān)系A(chǔ)TTAttribute4狀中關(guān)系A(chǔ)DVAdverbial5動補關(guān)系CMPComplete6并列關(guān)系COOCoordinate7介賓關(guān)系POBPreposition-object8間賓關(guān)系IOBIndirect-object9前置賓語FOBFronting-object10左附加關(guān)系LADLeft-adjunct11右附加關(guān)系RADRight-adjunct12獨立結(jié)構(gòu)ISIndependent-structure13核心關(guān)系HEDHead14兼語DBLDouble 4.3.2 關(guān)鍵指標(biāo)抽取 從4.3.1節(jié)中可知,對于每個描述短句,都可以構(gòu)建與之對應(yīng)的依存句法樹,并且具有核心關(guān)系的詞作為根節(jié)點,從而可得到每個詞的詞性及其與父節(jié)點的依存關(guān)系.本節(jié)將結(jié)合句法樹中的語義依存關(guān)系和詞性特征來提取醫(yī)學(xué)文本描述中的關(guān)鍵指標(biāo)及其指標(biāo)值,以實現(xiàn)結(jié)構(gòu)化信息抽取. 圖2 依存句法樹示例Fig.2 Example of dependency tree 在中文自然語言中,一個短句的成分通常包括:主語、謂語、賓語、定語、狀語和補語,其中具有核心關(guān)系的詞一般作為謂語成分,而醫(yī)學(xué)文本描述中又常常以動詞、名詞、形容詞作謂語;同時,在對醫(yī)學(xué)報告文本的描述語言進行歸納總結(jié)后,發(fā)現(xiàn)短句中常出現(xiàn)的語義依存關(guān)系(除核心關(guān)系外)主要有5種:主謂關(guān)系(SBV)、動賓關(guān)系(VOB)、定中關(guān)系(ATT)、動補關(guān)系(CMP)和并列關(guān)系(COO),表4列舉了醫(yī)學(xué)描述語言中的動詞、名詞和形態(tài)詞分別作為核心詞時主要出現(xiàn)的依存關(guān)系. 本文依據(jù)句法樹中根節(jié)點上的核心詞詞性及其與各孩子節(jié)點間的依存關(guān)系,分別采用不同的抽取策略.如算法2所示,當(dāng)根節(jié)點上的詞性為動詞時,直接遍歷子節(jié)點并判斷其與父節(jié)點之間的依存關(guān)系即可確定關(guān)鍵指標(biāo)名及其相對應(yīng)的指標(biāo)值;當(dāng)根節(jié)點上的詞性為名詞或形容詞時,在遍歷各子節(jié)點之后,還需要對具有并列關(guān)系的子節(jié)點上的詞進行合并,作為最終的指標(biāo)名,而將具有定中關(guān)系的詞作為相應(yīng)的指標(biāo)值. 表4 不同詞性的核心詞主要出現(xiàn)的依存關(guān)系 SBVVOBCMPATTCOO動詞√√√名詞√√形容詞√√ 算法2.關(guān)鍵指標(biāo)抽取算法 輸入:由各關(guān)鍵詞節(jié)點生成的依存句法樹,樹的每個節(jié)點包含原始詞word、詞性postag和依存關(guān)系relation; 輸出:結(jié)構(gòu)化鍵值對 1. 初始化RESULT=φ; 2. IF 根節(jié)點root≠NULL 3. FORword,postag,relationINroot 4. IFpostag==′v′|′vn′|′vd′ /*根節(jié)點為動詞*/ 5. WHILE 子節(jié)點child≠NULL 6. IFchild[relation]==′主謂關(guān)系/SBV′ 7. 指標(biāo)名key←child[word]; 8. ELSE IFchild[relation]==′動賓關(guān)系/VOB′|′動補關(guān)系/CMP′ 9. 指標(biāo)值value←child[word]; 10.RESULT←(key,value);/*將鍵值對添加到結(jié)果集*/ 11. IFpostag==′n′|′ns′|′nz′|′a′|′ad′|′an′ /*根節(jié)點為名詞或形容詞*/ 12. 指標(biāo)名key←root[word]; 13. WHILE 子節(jié)點child≠NULL 14. IFchild[relation]==′并列關(guān)系/COO′ 15.k←combine(root[word],child[word]);/*合并具有并列關(guān)系的詞*/ 16. 更新指標(biāo)名key←k; 17. ELSE IFchild[relation]==′定中關(guān)系/ATT′ 18. 指標(biāo)值value←child[word]; 19.RESULT←(key,value); 20. RETURNRESULT. 本文使用真實的醫(yī)學(xué)影像報告作為實驗數(shù)據(jù),其中共包含3000多條文本記錄,每條記錄由檢查項目、主要病癥和人工描述三個文本類型的屬性組成.針對這些實驗數(shù)據(jù),本文首先進行了初步的統(tǒng)計分析,如表5所示,實驗的文本數(shù)據(jù)集在各類別上分布不均.因此,本文重點篩選了樣本數(shù)量占比較大的支氣管鏡、彩超、胃鏡的影像報告數(shù)據(jù)進行實驗.此外,本文還將數(shù)據(jù)分為訓(xùn)練文本集和測試文本集,兩部分數(shù)據(jù)集的規(guī)模按照6:4的比例進行隨機劃分. 針對選取的這3類樣本數(shù)據(jù)集,本文從句型的角度分析了醫(yī)學(xué)報告文本的句子特征.表6統(tǒng)計了支氣管鏡、彩超和胃鏡的報告文本中的句子長度情況,從中可以看出醫(yī)學(xué)上的文本數(shù)據(jù)主要以短句為主,句子的長度絕大部分都不超過10個詞,且主要集中在5個詞以內(nèi),平均占比達到了84.73%,而在胃鏡的檢查報告中,使用短句最多,5個詞以內(nèi)的短句達到了91.67%,這說明醫(yī)學(xué)領(lǐng)域的文本描述受書寫習(xí)慣的影響較大,往往為了表述上的簡潔明確而弱化了中文自然語言的語法規(guī)則,從而增加了語義分析的難度. 表5 樣本數(shù)據(jù)統(tǒng)計信息 序號檢查項目樣本數(shù)量占比1支氣管鏡41.28%2彩超32.36%3胃鏡19.71%4CT1.51%5DR1.41%6MR1.41%7腸鏡1.01%8超聲胃鏡0.70%9鼻咽鏡0.61% 表6 三類樣本數(shù)據(jù)集的句子長度統(tǒng)計 0<詞數(shù)≤55<詞數(shù)≤10詞數(shù)>10彩超80.33%19.64%0.03%胃鏡91.67%8.32%0.01%支氣管鏡82.20%17.76%0.04%平均值84.73%15.24%0.03% 本文的實驗數(shù)據(jù)首先要經(jīng)過中文分詞處理.目前開源的分詞工具較多,但采用的算法模型不同,效果不一,因此本文對于使用比較廣泛的3種分詞工具,即NLPIR、IKAnalyzer和Jieba分別在現(xiàn)有數(shù)據(jù)集上進行了分詞實驗.由圖3的對比結(jié)果可知,對于醫(yī)學(xué)領(lǐng)域的中文文本數(shù)據(jù),三種分詞工具進行直接分詞的效果并不理想.相比之下,Jieba分詞能夠達到90%左右的準(zhǔn)確率,較之NLPIR和IKAnalyzer有一定的優(yōu)勢,因此本文選擇Jieba作為本文實驗的主要分詞工具. 通過關(guān)鍵詞提取,本文得到了醫(yī)學(xué)描述中常用的術(shù)語,圖4給出了訓(xùn)練文本和醫(yī)學(xué)術(shù)語庫中的一些高頻詞的分布情況.由圖4可知,動詞、名詞和形容詞作為醫(yī)學(xué)描述語言中的常用詞匯,在訓(xùn)練文本和術(shù)語庫中的占都比較大,其中名詞使用頻率最高,在訓(xùn)練文本中使用頻率達31.13%,而在術(shù)語庫中出現(xiàn)的頻率達43.62%,這主要因為醫(yī)學(xué)報告通常是對人體組織名和器官名的描述,所以名詞出現(xiàn)最多.相比于訓(xùn)練文本數(shù)據(jù),醫(yī)學(xué)術(shù)語庫中動詞、名詞和形容詞相較于其它詞性的詞分布更加集中,這說明關(guān)鍵詞提取操作有效識別并提取了醫(yī)學(xué)描述語言中的一些常用詞匯. 圖4 訓(xùn)練文本和術(shù)語庫中高頻詞對比Fig.4 High frequency words in training texts and termbase 為了提高中文分詞質(zhì)量,本文使用生成的醫(yī)學(xué)術(shù)語庫作為用戶詞典,用于輔助分詞,表7給出了直接分詞和使用術(shù)語庫進行輔助分詞的結(jié)果對比.在實驗中,本文將測試數(shù)據(jù)集分為三個子集,分別從彩超、胃鏡、支氣管鏡三個主要的樣本數(shù)據(jù)來比較分詞的準(zhǔn)確率.由表7可知,使用提取出的醫(yī)學(xué)術(shù)語庫可以明顯提高中文分詞的質(zhì)量,平均準(zhǔn)確率達到了97.78%,相比直接進行分詞,提高了7.23%,并且在胃鏡檢查的文本類簇中的分詞效果最好,準(zhǔn)確率達到98.24%,而在支氣管鏡的文本類簇中的分詞效果提升最明顯,準(zhǔn)確率提高了9.30%,由此可見,使用關(guān)鍵詞提取得到的術(shù)語庫進行輔助分詞確實有效地提高了醫(yī)學(xué)文本數(shù)據(jù)的分詞質(zhì)量. 表7 直接分詞和使用術(shù)語庫的分詞準(zhǔn)確率對比 彩超胃鏡支氣管鏡平均值直接分詞92.06%91.23%88.37%90.55%術(shù)語庫分詞97.42%98.24%97.67%97.78%差值+5.36%+7.01%+9.30%+7.23% 在結(jié)構(gòu)化信息抽取階段,本文采用了哈爾濱工業(yè)大學(xué)NLP實驗室開發(fā)的LTP工具包來進行語義依存分析,并且與基于結(jié)構(gòu)化模板匹配[25]的方法進行了實驗對比.根據(jù)樣本數(shù)據(jù)的三個主要類別,本文設(shè)計了三組對比實驗,分別針對彩超檢查報告、胃鏡檢查報告和支氣管鏡檢查報告進行文本數(shù)據(jù)的結(jié)構(gòu)化處理,并分析計算結(jié)果的準(zhǔn)確率、召回率和F1值,實驗結(jié)果如表8、表9和表10所示. 由表8、表9和表10可知,在三組不同樣本集的實驗中,采用語義依存分析的方法準(zhǔn)確率都能達到80%以上,相比之下,基于結(jié)構(gòu)化模板匹配的方法由于通過人工構(gòu)建模板庫在三個樣本集中實驗效果更佳,在彩超和支氣管鏡的樣本數(shù)據(jù)上準(zhǔn)確率和召回率都要高于語義依存分析的結(jié)果.然而在胃鏡檢查報告的樣本數(shù)據(jù)中采用語義依存分析的結(jié)果準(zhǔn)確率達到了83.76%的準(zhǔn)確率,與通過模板匹配的結(jié)果相差不大,并且在召回率上甚至達到了88.09%,高出了0.94%,這說明語義依存分析的方法能夠有效識別并抽取醫(yī)學(xué)文本描述中的結(jié)構(gòu)化信息,并且與通過人工模板庫進行匹配的結(jié)果相近,甚至在一些特定數(shù)據(jù)集下采用語義依存分析的方法能獲得更高的指標(biāo)覆蓋率,即能夠識別出更多的關(guān)鍵指標(biāo),從而抽取出更多的 表8 彩超報告結(jié)構(gòu)化信息抽取結(jié)果對比 準(zhǔn)確率召回率F1基于模板匹配81.62%85.21%83.37%語義依存分析80.53%83.11%81.80%差值 -1.09%-2.10%-1.57% 表9 胃鏡報告結(jié)構(gòu)化信息抽取結(jié)果對比 準(zhǔn)確率召回率F1基于模板匹配84.02%87.15%85.56%語義依存分析83.76%88.09%85.87%差值 -0.26%+0.94%+0.31% 表10 支氣管鏡報告結(jié)構(gòu)化信息抽取結(jié)果對比 準(zhǔn)確率召回率F1基于模板匹配82.51%86.21%84.32%語義依存分析80.93%84.50%82.68%差值 -1.58%-1.71%-1.64% 最后,本文對抽取的結(jié)構(gòu)化鍵值對做了進一步分析,圖5給出了語義依存分析和基于模板匹配兩種方法處理后的結(jié)果數(shù)據(jù)中五種高頻依存關(guān)系的對比情況.由圖5可知,采用結(jié)構(gòu)化模板進行匹配的方法主要處理的是具有主謂關(guān)系、定中關(guān)系和并列關(guān)系的詞,而對于具有動賓關(guān)系和動補關(guān)系的詞處理效果較差.相比之下,采用語義依存分析的方法對于這五種依存關(guān)系都能取得較好的效果,占比都在10%以上,并且對于具有并列關(guān)系的詞能達到21.57%的處理效率,由此說明采用語義依存分析的方法能識別并處理更多的依存關(guān)系,相比模板匹配具有更高的語法覆蓋率,因而該方法適用性更強,并有利于向其它文本數(shù)據(jù)擴展. 圖5 語義依存分析和模板匹配的依存語法覆蓋率對比Fig.5 Grammar coverage of semantic dependency analysis and template matching 本文所提出的一種針對醫(yī)學(xué)領(lǐng)域文本數(shù)據(jù)的結(jié)構(gòu)化信息抽取方法,重點分析了樣本集的數(shù)據(jù)特征,并采用文本聚類和關(guān)鍵詞抽取的方法獲得了醫(yī)學(xué)術(shù)語庫,顯著提高了醫(yī)學(xué)文本的分詞質(zhì)量;在結(jié)構(gòu)化信息抽取階段,本文通過分析詞與詞之間的語義依存關(guān)系和構(gòu)建依存句法樹,準(zhǔn)確識別并抽取出了醫(yī)學(xué)描述中的關(guān)鍵指標(biāo)及其對應(yīng)的指標(biāo)值,同時取得了很好的語法覆蓋率,有利于本方法的擴展應(yīng)用.然而在抽取的準(zhǔn)確率上,本文的方法還有待改進和提升,未來將考慮結(jié)合深度學(xué)習(xí)相關(guān)的算法模型,更加充分地提取和利用數(shù)據(jù)本身的特征,以更好地實現(xiàn)結(jié)構(gòu)化信息抽取.
Table 3 Summary of semantic dependency relations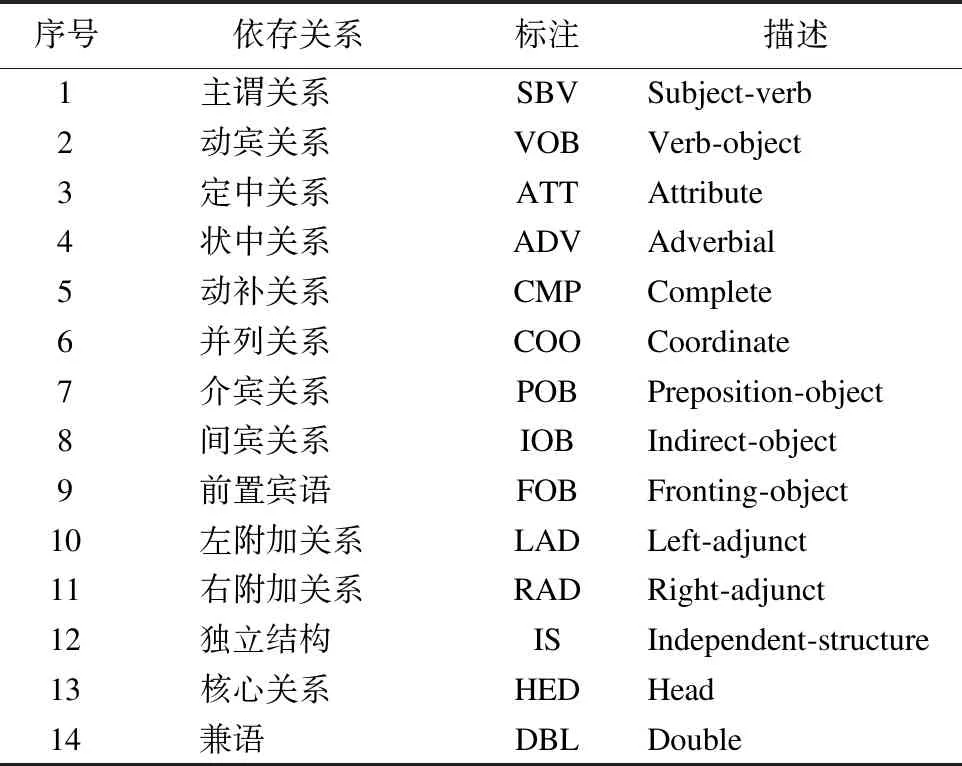
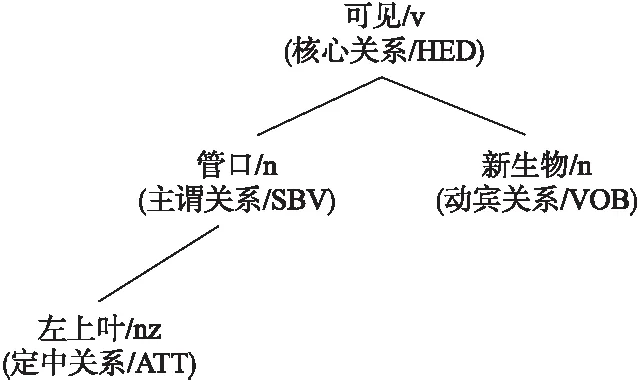
Table 4 Dependency relations on different key words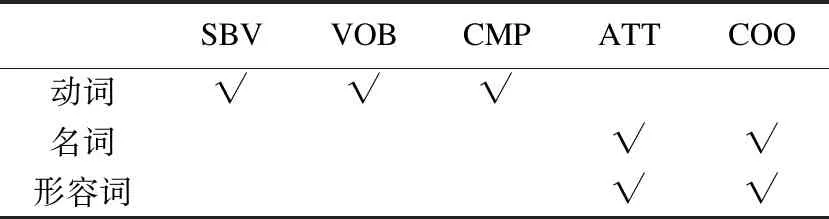
5 實驗與結(jié)果分析
5.1 實驗數(shù)據(jù)集
Table 5 Statistics of sample data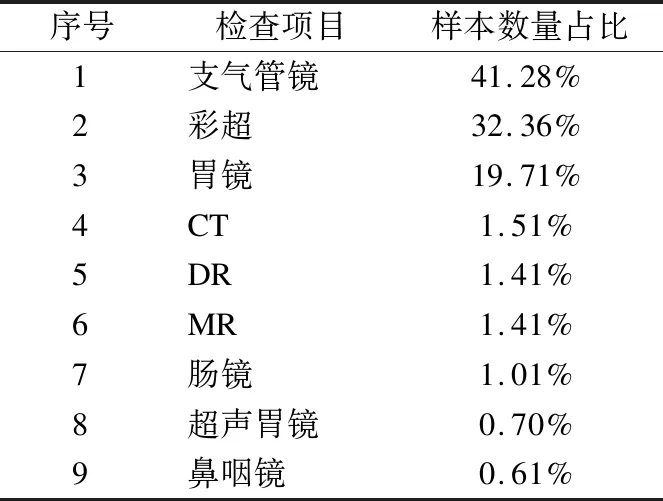
Table 6 Statistics of sentences in three samples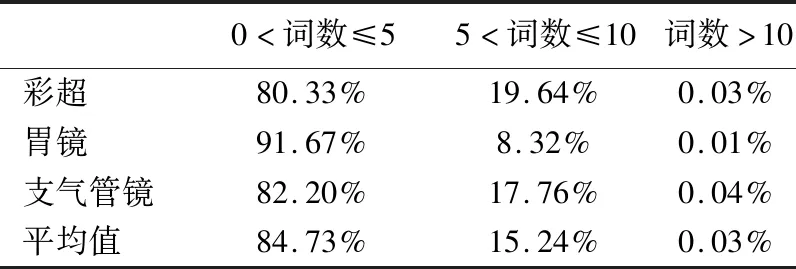
5.2 對比實驗與分析
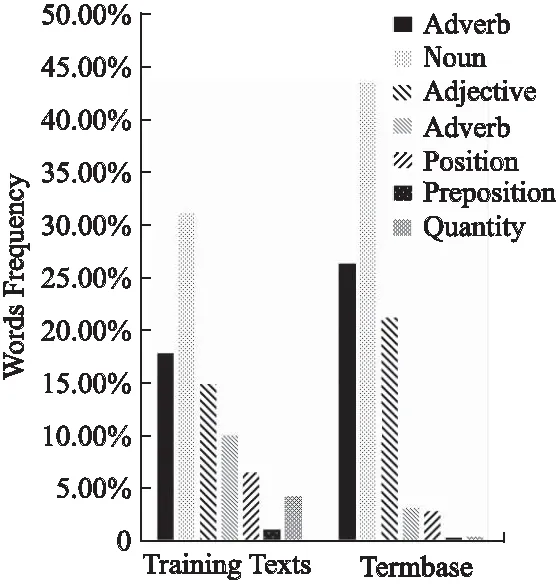
Table 7 Comparison of segmentation accuracy with directly segmenting and using termbase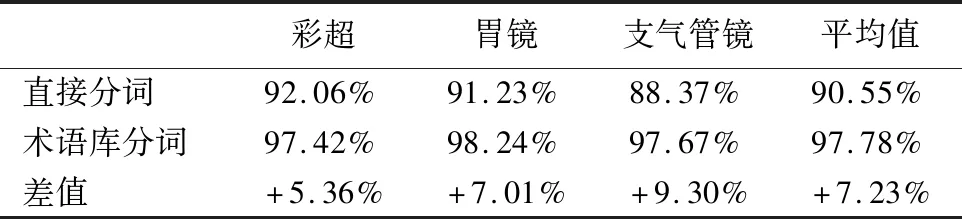
Table 8 Comparison of the results on color doppler reports for structured extraction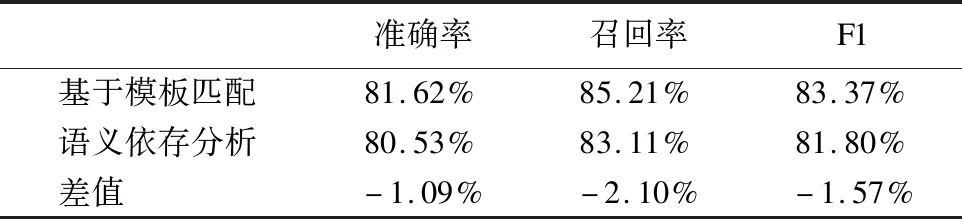
Table 9 Comparison of the results on gastroscope reports for structured extraction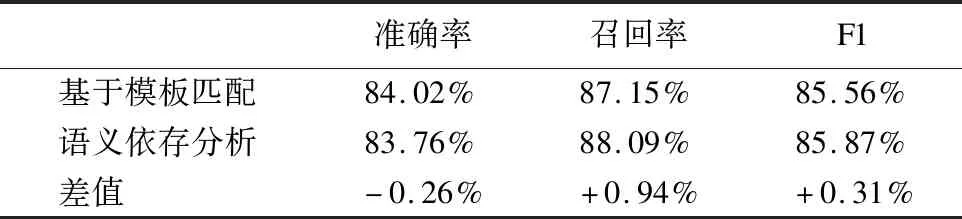
Table 10 Comparison of the results on bronchoscopy reports for structured extraction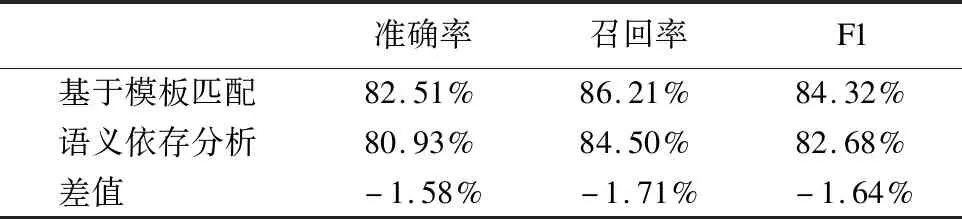
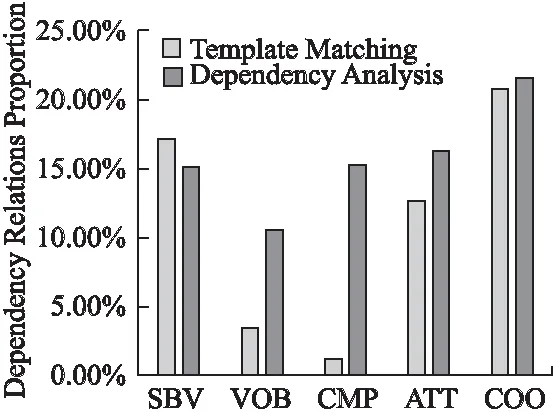
6 總 結(jié)
猜你喜歡
甘肅教育(2020年8期)2020-06-11 06:10:02開放教育研究(2020年2期)2020-03-31 01:54:14制造技術(shù)與機床(2019年10期)2019-10-26 02:48:08電子制作(2018年18期)2018-11-14 01:48:06現(xiàn)代語文(2016年21期)2016-05-25 13:13:44小學(xué)教學(xué)參考(2015年20期)2016-01-15 08:44:38人間(2015年20期)2016-01-04 12:47:10大連民族大學(xué)學(xué)報(2015年2期)2015-02-27 08:28:11語文知識(2014年1期)2014-02-28 21:59:13當(dāng)代修辭學(xué)(2011年6期)2011-01-29 02:49:50
