基于EEMD-Hilbert和FWA-SVM的滾動軸承故障診斷方法
2019-07-11 07:09:12蔡振宇包珊珊
西南交通大學學報 2019年3期
張 敏 ,蔡振宇 ,包珊珊
(1.西南交通大學機械工程學院,四川 成都 610031;2.西南交通大學軌道交通運維技術與裝備四川省重點實驗室,四川 成都 610031)
滾動軸承廣泛存在于機械結構中,作為重要的旋轉結構,是最容易出現故障的部件之一.滾動軸承振動信號具有非線性與非穩定的特性,單從時域或頻域進行故障診斷較困難[1].于德介等[2]首次引入固有模態函數(intrinsic mode function,IMF)分量應用于機械故障診斷,本文簡稱模態函數,將M 距離函數和支持向量機(support vector machine,SVM)進行結合實現故障模式識別,但經驗模態分解(empirical mode decomposition,EMD)[3]分解出具有原始信號特征的IMFS 容易出現模態混疊,掩蓋原始信號的真實特征[4-5].Wu 和Huang 等[6]在EMD 的基礎上改進提出集合經驗模態分解(ensemble empirical mode decomposition,EEMD),引入高斯白噪聲能夠有效地避免模態混疊[7],分解出的IMFS 具有完整信息,但IMF 所含信息有限,還需進一步處理.Hilbert 包絡解調是一種運用廣泛的信息解調技術,但在確定帶通濾波參數時需要豐富的經驗,限制了該技術的發展[8],若直接在模態函數上進行Hilbert 變換則可避免帶通濾波參數的確定.
多分類SVM 通過核參數將特征向量映射到高維空間實現分類,參數的確定影響整個分類效果.何青等[9]用果蠅優化算法優化SVM 參數,但測試集量少,大數據下還有待驗證.煙花算法(firework algorithm,FWA)[10]是Tan 和Zhu 在2010年提出的一種新型進化算法,具有很強的優化求解能力,應用在優化SVM參數時比粒子群算法(particle swarm optimization,PSO)迭代時間快且更準確[11],近年來逐漸受到研究者的關注.
本文提出利用EEMD 將原始數據分解成IMFS,再對IMF 進行Hilbert 變換,避免帶通濾波參數的確定,同時可對模態函數進行信息解調分析;將模態函數及其變換后的解調信息進行統計特征提取并降維處理;最后采用新型煙花算法優化SVM 分類參數,代入數據實現快速、準確的故障診斷.
1 數據特征提取
1.1 集合經驗模態分解
EEMD 是通過給目標信號加入一定幅值的高斯白噪聲,利用白噪聲頻譜均衡分布的特點來均衡噪聲,有效地解決了EMD 出現模態混疊的現象.適用于各種非線性和非穩定的信號處理,步驟如下:
步驟1隨機生成均值 μ為0,標準差 σ為en的高斯白噪聲nm(t),t為時間,設定原始參數,m表示第m次分解,1 ≤m≤M,M表示EMD 分解次數.
步驟2將高斯白噪聲nm(t)加入待處理的信號y(t)中 ,得到信號為ym(t),t為時間,即

步驟3對處理后的信號ym(t)進行EMD 分解,得到S個IMF 分量cs,m(t),
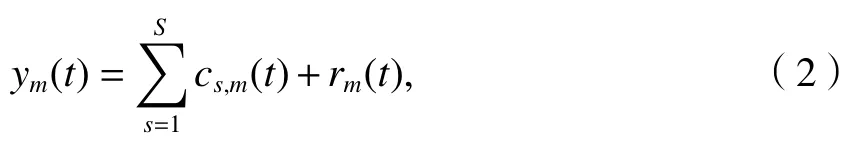
式中:rm(t)為 第m次分解得到的余項;cs,m(t)為進行第m次EMD 分解后的第s個IMF 分量,由頻率從高到低排列.
步驟4若m<M,則返回執行步驟(2),M=m+1,到M次終止;
步驟5計算進行M次EMD 分解后得到每個IMF 分量的均值,根據不相關隨機序列統計均值為0,消除加入高斯白噪聲對真實IMF 分量的影響,即:
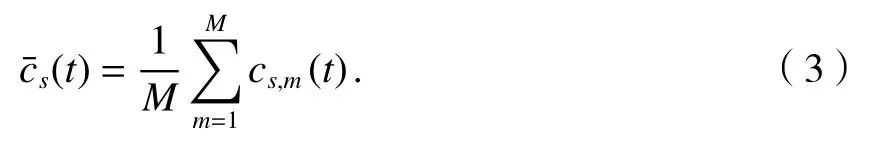
步驟6將(t)作為EEMD 最終得到的第s個IMF 分量.
1.2 Hilbert 包絡解調原理
信號進行EEMD 分解得到排序降次的IMF,本文選取前幾個作為研究對象,后面殘存的以低頻噪聲為主,不予考慮.對選取的(t)進行Hilbert 變換,解調原理如下:
濾波器公式h(t)為

式中:δ(t)為脈沖函數.
解析信號公式q(t)為
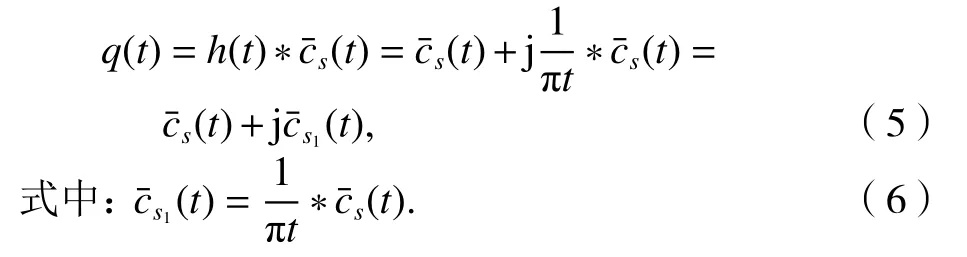
1.3 統計特征提取與降維
將主要的IMF 及其對應的解調信息作為提取特征對象,為有效提取特征值,挑選最合適的統計特征值來對處理的信息進行特征提取,本文選取的統計特征值依次是均值、峰值、極差、標準差、偏度、峰度、變異系數和平方和.綜合上述的所有統計特征量,特征維度較高,本文采用核主元分析(kernel principal component analysis,KPCA)對特征維度進行壓縮提取,實現特征降維,便于后面快速故障診斷.由于篇幅問題,本文不對KPCA 降維具體內容進行論述,詳細參考文獻[12].
2 模式識別
2.1 支持向量機
支持向量機通過核函數來實現線性不可分向線性可分的轉化,研究表明徑向基核函數K(xi,yi)在SVM 中表現出良好的泛化能力[13],將輸入向量從原來的空間映射到高維特征空間P,并在該特征空間P內建立優化超平面.分類線方程為[14-15]
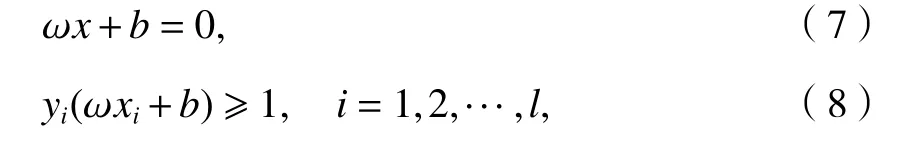
式中:(xi,yi)為 訓練樣本;ω為權值;x為輸入向量值;b為閾值;l為向量的個數.
根據Karush-Kuhn-Tucker,優化各個系數得到最優決策函數為
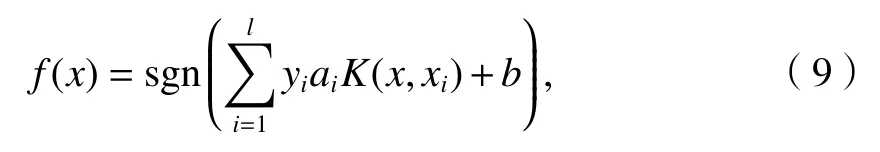
式中:ai為Lagrange 系數.
最后得到適應度函數為

式中:C為懲罰參數;σ為核參數.
由式(10)可知進行SVM 分類模型構建時,性能的關鍵因素在于參數C和 σ的選取.
2.2 FWA-SVM 模型
FWA 是將每個煙花都當作一個解空間中的可行解,通過爆炸產生煙花點作為全局搜索的可行解.通過每個煙花的適應度值來變化爆炸半徑和爆炸數,適應度值越小的點爆炸范圍越小,爆炸數越多,適應度值大的則相反.煙花算法核心包括爆炸算子、變異操作、映射規則、選擇策略4 個部分[16].
假定待求解的優化問題形式為minf(u)∈R,u∈Ω,Ω為可行解.煙花算法對SVM 參數優化步驟如下:
步驟1在解空間內隨機生成N個初始un,有N個煙花;
步驟2計算每個煙花的適應度值與它們的爆炸半徑Bn和爆炸花火個數Qn;
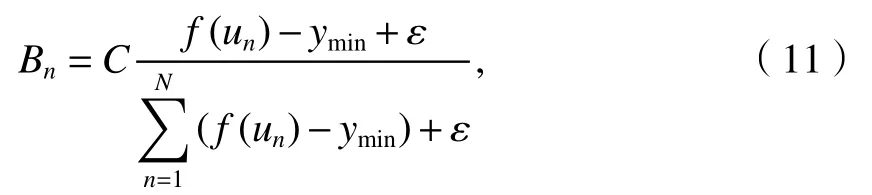
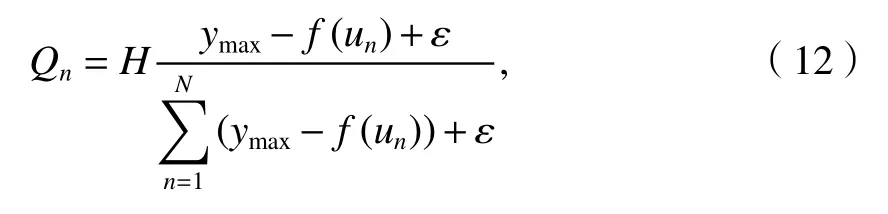
式中:ymin=min{f(un)},為這次迭代中的最優值,也為最小值,n=1,2,...,N;ymax=max{f(un)}為當前迭代中的最劣值,也為最大值;H為爆炸火花數的大小;ε為機器最小量,避免出現零操作.
為了避免適應度值優的或者劣的產生過多或者過少的爆炸火花,文獻[10]對火花個數做出如下的限制:
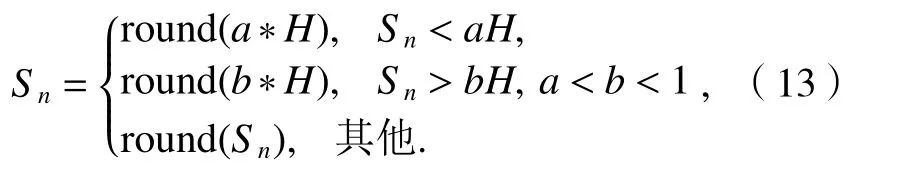
式中:Sn為火花個數;a、b為常數.
步驟3產生爆炸火花,集合DC具有z個維度,z=round(D×rand(0,1)),D為煙花un的維數.在DC中的每個維度k下進行爆炸操作,再經過越界處理將Tnk保存到火花種群中.

式中:h為偏移量;unk為第n個煙花在第k維上的位置;Tnk為unk爆炸操作后的火花位置.
步驟4進行高斯變異操作,每個維度通過式(16)進行高斯變異,再經過越界處理保存到高斯種群當中.

式中:e~N(1,1)表示均值為1,方差為1 的高斯分布.
步驟5選擇操作,在所有得到的種群中挑選最好的一個,另外N-1 個則通過輪盤賭法進行選擇如式(17)、(18).
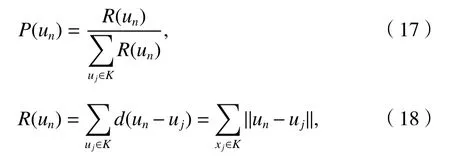
式中:P(un)為R(un)的 概率;R(un)為個體un與其它個體的距離之和;d(un-uj)是 指任意兩個個體un和uj之間的歐式距離.
步驟6判斷是否滿足終止迭代條件,滿足則結束輸出最優SVM 參數,不滿足就繼續迭代.
2.3 基于EEMD-Hilbert 和FWA-SVM 的滾動軸承故障診斷
基于EEMD-Hilbert 特征提取和FWA-SVM 故障診斷具體步驟如下:
步驟1原始信號樣本提取.獲得設備運行所采集到的數據樣本,對樣本進行分組.
步驟2EEMD 分解處理.將樣本數據進行EEMD 分解得到若干個IMF 函數.
步驟3Hilbert 變換處理.對選取的IMF 進行Hilbert 變換,獲得瞬時頻率.
步驟4統計特征提取.對IMF 分量和解調信息分別計算其對應的統計特征值.
步驟5KPCA 特征降維.提取出有用的信息特征實現特征降維.
步驟6FWA 尋SVM 最佳參數.將訓練樣本帶入FWA-SVM 進行訓練,得到最佳的SVM 分類參數.
步驟7模式識別.將訓練好的FWA-SVM 模型進行測試集故障分類,輸出結果.
基于EEMD-Hilbert 特征提取和FWA-SVM 故障診斷流程如圖1所示.
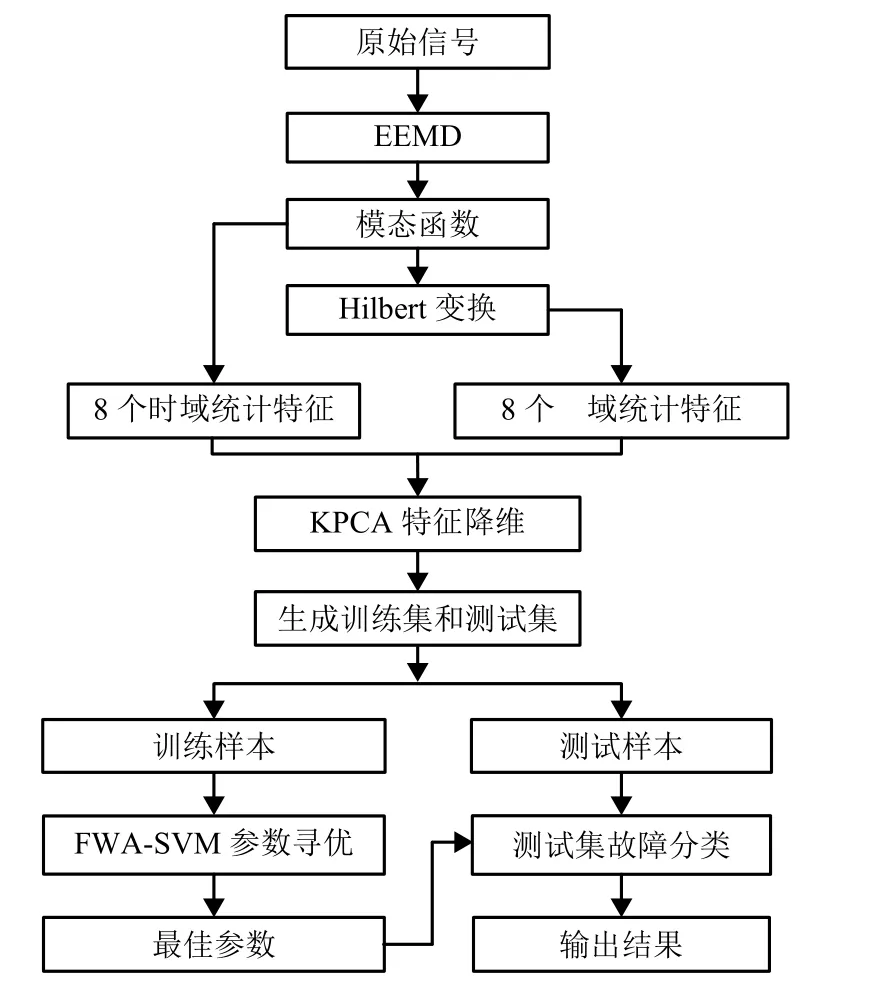
圖1 故障診斷流程Fig.1 Flowchart for troubleshooting
3 案例分析
為驗證算法模型的可行性和有效性,本文采用美國Case Western Reserve University 電氣工程實驗室的滾動軸承實驗平臺數據[17],實驗中測試的軸承是由SFK 公司生產的6205-2RS 深溝球軸承.
3.1 數據特征樣本
選取滾動軸承在轉速為1797 r/min,采樣頻率為12 kHz 情況下的正常工作狀態,內圈故障、滾動體故障和外圈故障3 種故障狀態,其中外圈故障選擇發生在6 點鐘方向上.同時考慮3 種故障狀態下的3 種損傷尺寸,分別為0.178、0.356、0.533 mm,具體數據如表1.

表1 軸承故障樣本Tab.1 Bearing failure samples
將信號進行EEMD 分解,得到正常、內圈故障、滾動體故障和外圈故障,故障點直徑為0.178 mm的4 個IMF 分量與其對應的原始信號如圖2所示.
3.2 各種方法結果對比
3.2.1 不同信號處理方法的比較研究
方法a 將信號進行EEMD 和Hilbert 變換,通過統計特征量提取,再進行KPCA 降維,將特征數據代入PSO 優化SVM 參數模型內進行分類,記為EEMD_H模型.方法b 與方法a 類似,但不進行Hilbert 變換,記為EEMD 模型.方法c 對原始信號進行EMD 分解[18],后面和方法a 一樣,記為EMD_H 模型.PSO 初始參數為20 種群數,400 的最大迭代數.結果如表2(數據結果為5 次平均值)所示,圖3是同一信號分別進行EEMD 和EMD 分解之后選擇首個IMF 進行圖像化的波形圖.
進行EEMD 分解的迭代時間比進行EMD 分解時間更短,且正確率要低4%左右.圖3說明EEMD可以較好避免EMD 的模態混疊現象.不加Hilbert變換處理的數據比加Hilbert 變換數據要差5%,說明加Hilbert 變換特征更全面,達到更好的數據特征提取.以上證明了EEMD_H 方法能夠更精確地提取原始信號的特征信號,達到高效、準確的特征提取,證明了該特征提取方法的有效性與可行性.
3.2.2 算法參數尋優收斂性對比研究
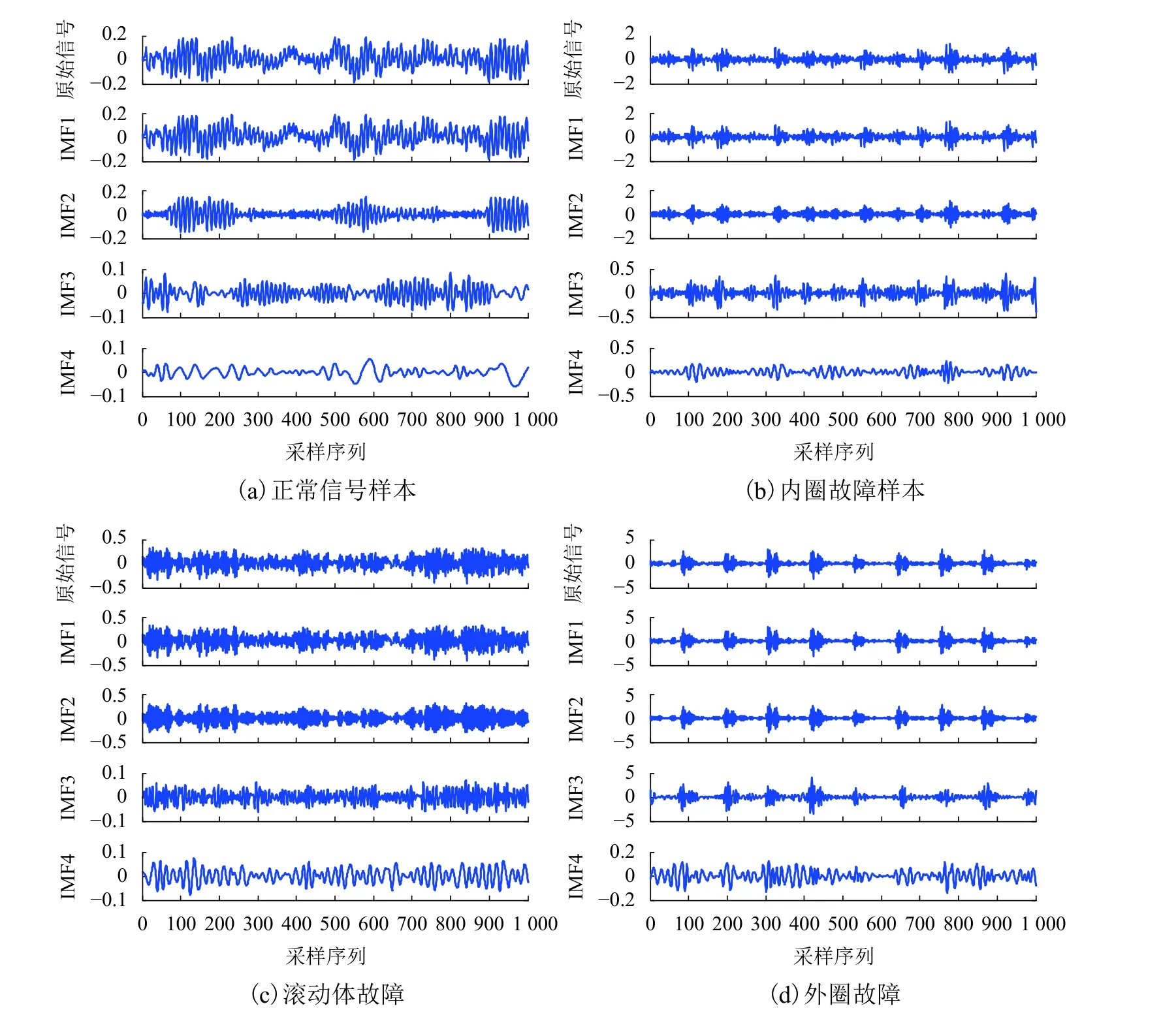
圖2 原始信號和 IMF1~IMF4 分量波形圖Fig.2 Original signal and IMF1- IMF4 component waveforms
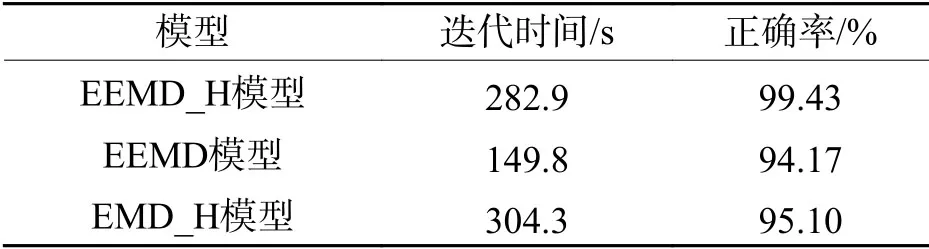
表2 3 種分類結果Tab.2 Classification results for the three methods
利用目前成熟的粒子群算法和遺傳算法(genetic algorithm,GA)優化SVM 參數構造的模型與煙花算法優化參數進行對比,所選的粒子群算法和遺傳初始參數種群數為20,最大迭代數為200;煙花算法初始參數煙花種群數量為20,最大迭代數為200.結果如表3和圖4所示,其中適應度值是原始算法中適應度實值的絕對值.
由表3與圖4可知,FWA 優化SVM 參數比PSO更早達到最大值,且FWA 比PSO、GA 得到的訓練集正確率更高,說明煙花算法比PSO、GA 在搜索域內能快速、準確得到最優的核函數參數.GA 算法源于搜索域較廣,容易陷入局部最優,間接說明FWA的迭代收斂能力更強.另外FWA 與PSO 出現此類差別原因需從算法構造思路不同處進行分析:(1)煙花算法通過分布式信息共享,根據分布在不同區域煙花的適應度值決定爆炸強度大小和輻射范圍,但PSO 是單項流動,搜索迭代過程是跟隨當代最優解;(2)煙花算法中的高斯變異在變異中選出的不同維,而維度上的位移是相同的,保證了某些維度之間一些聯系,而PSO 中各維變異是不相同的;(3)煙花算法中的高斯變異每代都要進行,而粒子群中每隔一定的迭代次數才運行1 次.
3.2.3 不同模型的故障診斷效果對比研究
利用遺傳算法GA 和粒子群算法PSO 分別優化SVM 參數構造的模型與煙花算法FWA 優化SVM 參數進行對比,分別記為GA 模型、PSO 模型和FWA 模型.各算法初始種群數都為20,最大迭代數為400,其他都選各自最合適的參數.將上述處理好的訓練集和測試集代入構造好的模型,進行結果分析.結果如表4(數據結果為5 次平均值)和圖5所示.
從表4和圖5可以看出,在時間上FWA 優化SVM 參數的平均時間只要14 s,相對較好迭代時間效果GA 縮短了100 s 多,而PSO 迭代時間較長,效果較差;FWA 優化的模型也在正確率上體現出優勢,比GA 高0.4%,比PSO 高0.2%.以上說明FWA能夠實現快速、準確地對SVM 參數優化,因此驗證了煙花算法能夠很好地優化SVM 參數,構建的模式識別模型能準確地進行故障診斷.
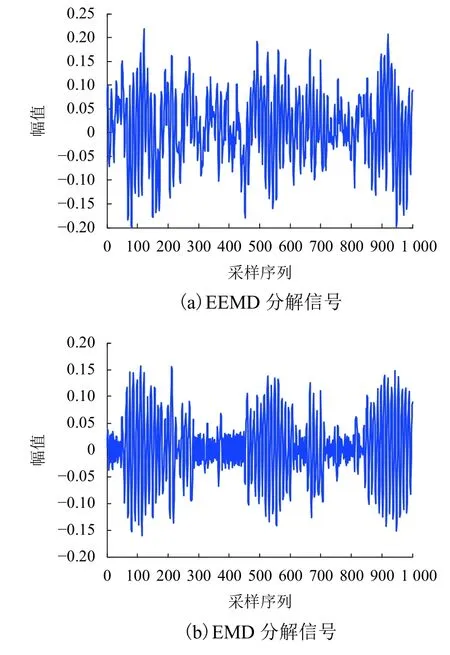
圖3 兩種方法首個IMFFig.3 Two methods for the first IMF chart

表3 FWA、PSO、GA 對SVM 參數尋優Tab.3 FWA,PSO,and GA for SVM parameter optimisation
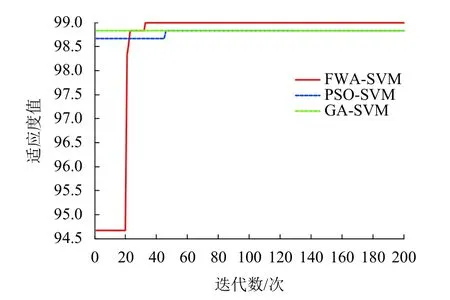
圖4 3 種算法SVM 參數迭代對比Fig.4 Comparison of SVM parameters for the three algorithms
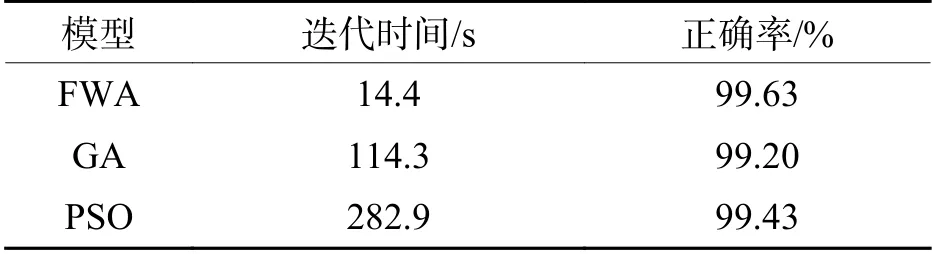
表4 3 種分類結果Tab.4 Classification results for the three algorithms
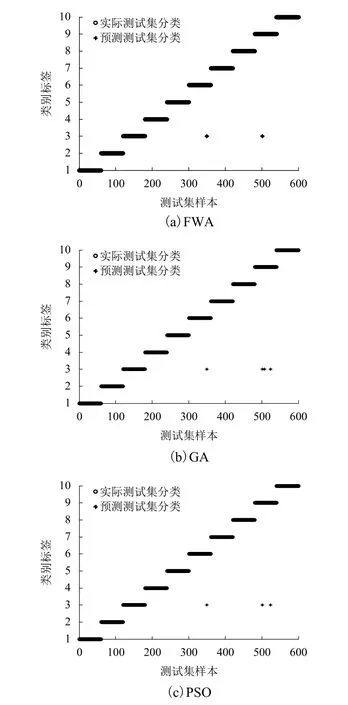
圖5 3 種分類結果對比Fig.5 Comparison of the three classification results
4 結束語
提出一種采用集合經驗模態分解、Hilbert 變換的特征提取方法,并利用煙花算法優化支持向量機分類參數的滾動軸承故障診斷方法.將振動信號進行EEMD 分解,避免了EMD 分解的模態混疊現象,準確提取信號特征;通過對IMF 分量進行Hilbert 變換獲得頻域統計特征,綜合了Hilbert 處理數據的優點,避免帶通濾波參數的選取,實現原始信號特征更準確提取;最后利用煙花算法優化SVM 參數,比傳統的遺傳算法、粒子群算法識別率更高,迭代時間更少,實現了快速、準確的故障診斷.案例分析的結果證明,運用該算法模型在故障診斷方面是一條可行的途徑.
猜你喜歡
電子制作(2019年15期)2019-08-27 01:12:00
中國生物醫學工程學報(2017年6期)2017-02-10 05:11:45
湖北經濟學院學報·人文社科版(2015年8期)2015-12-29 05:53:07
重慶工商大學學報(自然科學版)(2015年10期)2015-12-28 07:43:58
上海電機學院學報(2015年4期)2015-02-28 14:30:00
噪聲與振動控制(2015年4期)2015-01-01 07:08:21
計算物理(2014年2期)2014-03-11 17:01:39
振動、測試與診斷(2014年5期)2014-03-01 01:14:21
機械與電子(2014年1期)2014-02-28 02:07:31
河南科技(2014年3期)2014-02-27 14:05:48
