被遺忘權的制度缺失、發展困境與中國構建路徑
2019-07-11 05:20:54劉學濤張翱鵬
重慶郵電大學學報·社會科學版 2019年3期
劉學濤 張翱鵬

摘 要:數據時代面臨的個人信息受到侵害、個人隱私泄露、算法歧視等一系列重大問題,應將以保護信息主體權利為目的的被遺忘權確立下來。歐美被遺忘權在隱私與自由之間存在的沖突背后所體現的是被遺忘權對于各國需求的重要性,我國現有法律制度中規定的刪除權與歐盟所確立的被遺忘權是不能等同的。現行被遺忘權面臨著調整對象的設定缺陷、權利內容的設定偏差、責任主體的設定不足三方面的發展困境。學者熱議與實踐需求在一定程度上表明我國應當引入被遺忘權,并應從調整對象的優化構建、權利內容的改造構建、責任承擔的明確構建搭建起中國的路徑選擇,以解決網絡信息社會的發展帶給我們的新挑戰。
關鍵詞:被遺忘權;刪除權;情景脈絡完整性;刪除算法
中圖分類號:D923 ? ? ? ?文獻標識碼:A
文章編號:1673-8268(2019)03-0045-12
“被遺忘權”也被稱為“刪除的權利”(the right to erasure),有學者將“被遺忘權”定義為:“數據主體可以在數據控制者沒有合法理由掌握信息的情況下,要求其永久刪除該主體的個人數據的權利。”[1]有史以來,對我們人類而言,遺忘一直是常態,記憶才是例外。然而,由于數字技術與全球網絡的發展,這種平衡已經被改變。在此種情形下,作為一項新興權利的被遺忘權應運而生,成為保障個人信息安全之利器而受到人們的關注[2]。在網絡技術的幫助下,遺忘已經變為例外,而記憶卻成了常態。完善的數字記憶在帶給人們極大便利的同時,也造成了新的困擾。過去,人們犯錯不用擔心未來會受此羈絆,因為尷尬的信息通常只存在于特定的社區并會隨著時間的流逝而被遺忘。但現在,互聯網記住了你的一切,我們的過去正像刺青一樣刻在我們的“數字皮膚”上,遺忘成為奢侈品,一個“永久記憶”的時代已經到來。完善的數字化記憶,可能會令人失去一項重要的能力——堅定地生活在當下的能力[3]。大數據時代,現代信息技術構建的龐大數據庫儲藏著海量信息[4],遺忘作為人類與生俱來的能力,在互聯網以及廉價存儲器的作用下成為過去,傳播和取得不良信息包括傳播和取得未經數據主體同意的隱私資料更為方便,人們私生活的不安寧因素隨之增加[5]。本文以被遺忘權的價值爭議為邏輯起點,結合我國關于刪除權的規定,審視被遺忘權的發展困境,試圖將被遺忘權引入中國并為在引入之后如何具體應對提供構建路徑。
一、歐美被遺忘權的價值基礎:個人尊嚴和自由
自2012年歐盟提出被遺忘權以來,各方爭議不斷。這種分歧在歐盟與美國之間尤為明顯。美國與歐盟在被遺忘權問題上的巨大分歧,背后體現的是兩者對待個人隱私保護的差異。總的來說,歐盟國家更注重個人隱私保護,認為隱私權關系人格尊嚴,是一項“基本權利”,政府應給予高度重視;而美國通常認為隱私是一項“基本價值”,相較于隱私,他們更傾向于保護言論自由。
(一)歐盟的價值基礎:個人尊嚴
歐盟明確將被遺忘權納入“新草案”,并在積極尋求草案的通過。“谷歌西班牙公司案”證實了歐盟的這一立場,雷丁女士更是稱該判決是“歐洲個人數據保護的一次顯著勝利”,歐盟成員國也多持肯定態度。早在歐盟《通用數據保護法則》出臺前,一些成員國就已經在嘗試確立被遺忘權。例如,在法國,2010年10月13日,包括搜索引擎在內的部分互聯網企業在國務秘書的召集下簽署了一項關于被遺忘權方面的宣言。而歐盟民眾對被遺忘權更是熱情高漲。據民調顯示,歐盟有75%的民眾希望享有被遺忘權,以便能按照自己的意愿刪除網絡個人信息。“谷歌西班牙公司案”后,谷歌出臺了在線申請程序,歐盟每天都有上千人申請行使被遺忘權。
歐洲對于個人信息的保護核心源于對個人尊嚴權利的保護。隱私保護的核心是個人的肖像權、姓名權和名譽權,這幾項權利互相聯系,其目的是為了控制個人的公眾形象,使自己在公眾面前免于不當暴露和公開帶來的尷尬。保護隱私是保護尊嚴和榮譽的內容之一,避免隱私泄露導致的尊嚴被傷害和榮譽受損才是有關歐洲法律的目的\[6\]。歐洲的尊嚴文明其實就是隱私文明。歐洲法律學者將隱私作為對一個人肖像、姓名和名聲的控制以及對個人信息的公開披露等相關的權利時,實際上是在說社會大眾對于這些權利的敏感性。Robert Post認為,隱私保護的是一種尊嚴的標準,這種標準表現為禮儀規范,當缺乏這種規范時社會將無法形成共同的意識。歐洲的隱私法從名譽法(the law of insult)發展而來。名譽法涉及的懲罰對象是不尊重的表現,例如表達不尊重的文字手勢等。其所存在的國度,名譽法被認為是關于保護個人榮譽或尊嚴的法律\[7\]。隱私受損而造成的尊嚴或榮譽的損失是由名譽法保護的,名譽法并不要求法律上可認知的侮辱已經傳播到任何第三方。無論是否有任何第三方目睹了該事件,都可以認定為以不尊重或輕蔑的態度對人的尊嚴進行攻擊的行為。
(二)美國的價值基礎:自由
美國的個人信息保護涵蓋于隱私保護中,其來源于對自由的追求,彰顯了個人信息自由的價值。在美國,盡管被遺忘權一直受到憲法第四修正案的反駁,加州仍然通過了《兒童在線隱私保護法案》,該法案規定了兒童的被遺忘權,指出兒童有權擦除其在線記錄。美國的被遺忘權來源于其追求自由的理念,美國隱私權的發展歷程便是追求自由的過程。比如:1965年,在格里斯沃爾德訴康涅狄格州案中,最高法院通過利用第一、第三、第四、第五和第九修正案創造新的隱私權;在Hanlon訴Berger案中,法院認為政府侵犯了公民的隱私自由。
Eric Posner指出,美國法律試圖在第一修正案和隱私權之間維持平衡。例如,在美國的信用報告中,未支付的抵押貸款,即使此類信息為真,十年之后這類信息也會消失[8]。此外,各州對于某些類型的犯罪記錄也會從公共記錄中刪除,即使這些記錄并不存在任何錯誤。Eric Posner因此認為,雖然美國并沒有明確地承認被遺忘權,但這種法律權利其實深藏于美國的歷史傳統中。美國公眾輿論也支持被遺忘權。Pew 研究中心的一項研究顯示,68%的美國互聯網用戶“認為現行法律在保護人們的在線隱私方面不夠好”。此外,一項軟件咨詢調查顯示,500名美國成年人中61%的人都贊成被遺忘權。
雖然歐美被遺忘權的價值基礎不同,但都認為被遺忘權是大數據時代必備的權利。不論從理論基礎還是現實需要,都指明了被遺忘權的重要性。然而,我國并沒有建立被遺忘權,而且類似于被遺忘權的刪除權立法只知其形而未得其神。
二、我國被遺忘權的制度分析:刪除權≠被遺忘權
我國現有的相關法律已經規定了“刪除權”。2005年6月,《中華人民共和國個人信息保護法示范法草案學者建議稿》最早將“刪除”上升為一種權利,規定在個人信息被非法儲存以及當信息處理主體執行職責已無知悉該個人信息的必要時,該個人信息應當被刪除。2011年1月,工信部就個人信息保護頒發了《信息安全技術公共及商用服務信息系統個人信息保護指南》(以下簡稱《指南》),該《指南》第5.5.1條《信息安全技術公共及商用服務信息系統個人信息保護指南》第5.5.1條:個人信息主體有正當理由要求刪除其個人信息時,及時刪除個人信息。刪除個人信息可能會影響執法機構調查取證時,采取適當的存儲和屏蔽措施。對有關個人信息刪除權的規定,是目前我國相關法律、法規、規章中最系統、最全面的,也最接近歐盟被遺忘權的規定。但是,《指南》中規定的刪除權與歐盟所確立的被遺忘權并不相同。陳昶屹法官認為,其一,《指南》是從個人信息保護法的領域這個角度規定的,而歐盟所確立的被遺忘權是從民事權利的角度提出的。由于《指南》是工信部頒發的一種指南性的規定,屬于行政指導的范疇,不具有強制力,所以這其中規定的刪除權嚴格來說很難被認為是一種法定意義上的民事權利或者在行政法上行政相對人個人享有的一項權利。而被遺忘權更多地是一種私權利,如果歸到中國權利體系里面應該屬于民事權利。其二,刪除權從主體上說有這項權利,但并沒有從民事權利或私人主體權利的角度來說。西方有個人信息保護機構,還有對應的投訴機構和管理機構。工信部從信息產業的角度代行了類似的這種權利,但并不是專門保護個人信息、接受個人信息投訴的機構。被遺忘權這一權利最后行使的方式也是信息被抹掉,從這一意義上來說,中國的刪除權和歐盟的被遺忘權的規定很相似。但截止到現在,《指南》中規定的刪除權并沒有成為法定權利和上升到一種被遺忘的權利,這個規定還只是一個指令或者指導。在封存或消除罪犯犯罪記錄的相關規定方面,我國2012年修改的《中華人民共和國刑事訴訟法》專章規定了“未成年人犯罪案件訴訟程序”,其中第275條作出了相關規定《中華人民共和國刑事訴訟法》第275條:犯罪的時候不滿十八周歲,被判處五年以下有期徒刑,應當對相關犯罪記錄予以封存。。最高人民法院《關于審理利用信息網絡侵害人身權益民事糾紛案件適用法律若干問題的規定》第12條也就犯罪記錄能否適用被遺忘權予以刪除作了區分:當犯罪記錄的公開者是網絡用戶或網絡服務提供者等國家機關之外的主體時,能夠行使被遺忘權對該犯罪記錄進行刪除;當犯罪記錄的公開者是國家機關時,該犯罪記錄屬于適用被遺忘權的例外。2012年12月28日通過的《全國人大常委會關于加強網絡信息保護的決定》第8條也做出了規定《全國人大常委會關于加強網絡信息保護的決定》第8條:個人發現網絡運營者違反法律、行政法規的規定或者雙方的約定收集、使用其個人信息的,有權要求網絡運營者刪除其個人信息;發現網絡運營者收集、存儲的其個人信息有錯誤的,有權要求網絡運營者予以更正。網絡運營者應當采取措施予以刪除或者更正。。我國《中華人民共和國侵權責任法》(以下簡稱《侵權責任法》)第36條有關網絡侵權責任的規定,首次明確了針對網絡用戶利用網絡服務實施的侵權行為,被侵權人有權通知網絡服務提供者采取刪除、屏蔽、斷開鏈接等必要措施,即賦予了被侵權人對網絡上針對自身的侵權信息予以刪除的權利。
但是,我們發現,以上關于“刪除權”的規定,無論是對未成年人犯罪記錄的封存,還是基于《侵權責任法》的通知刪除義務,都是基于一個前提:存在違法行為或者侵權行為。然而,被遺忘權并不以存在違法行為為基礎,即便是合法存在于網絡的信息,沒有任何人利用該數據做出對數據主體不利的舉動,數據主體僅僅是由于數據的存在問題就可以通過被遺忘權來主張權利。這也是被遺忘權與我國規定的刪除權最大的不同。從上文可以看出,我國現有法律中規定的刪除權雖然從形式上、內容上和被遺忘權相似、接近,但由于中國的立法環境、立法條件、適用情況和歐洲都有完全不一樣的體系和保護方式,所以很難說上述法律文件中規定的刪除權與歐盟所確立的被遺忘權是一致的,具體分析如下。
一方面,從個人信息治理手段的角度看,歐盟被遺忘權的規定側重于源頭治理,而我國的規定則屬于結果治理。《中華人民共和國網絡安全法》第43條《中華人民共和國網絡安全法》第43條:個人發現網絡運營者違反法律、行政法規的規定或者雙方的約定收集、使用其個人信息的,有權要求網絡運營者刪除其個人信息;發現網絡運營者收集、存儲的其個人信息有錯誤的,有權要求網絡運營者予以更正。網絡運營者應當采取措施予以刪除或者更正。只規定了個人對于個人信息收集和使用違法、違規以及違約狀況下請求刪除的權利,與歐盟《通用數據保護法則》相比缺乏“個人信息過時不必要、撤回同意以及拒絕信息控制者收集三種情況”。這使得我國立法層面喪失了事前的個人信息侵害救濟,只規定事后的懲罰和處理,對個人信息的保護未免過于遲鈍與滯后。
另一方面,《侵權責任法》第36條的規定也并不能起到替代被遺忘權的作用,二者存在巨大差異,具體對比如表1所示。
表1中,從權利主體的角度看,前者要求利用“網絡”,這也符合我國《侵權責任法》第36條“網絡侵權專門條文”的稱謂。而被遺忘權不要求其主體利用網絡,即便是非網絡狀態下收集的個人信息也適用被遺忘權的規定。當然,實踐中也確實大量存在非云端的個人信息收集、儲存和分析等行為,《侵權責任法》要求的網絡前提未免會令調整范圍更狹窄。
從權利客體的角度看,前者的構成要件要求侵權損害事實的發生,而被遺忘權并不強求符合《侵權責任法》規定的侵權行為構成要件,即便沒有損害事實發生,只要符合法律對被遺忘權的規定,個人信息主體即可請求信息控制者刪除其個人信息。信息自決的理念體現了個人對大數據時代產生的個人信息問題進行的回應,具有時代特色。傳統互聯網階段,個人信息量較少,互聯網電商尚不發達,搜索引擎與門戶網站對個人信息的處理需求并不是很大,互聯網社區相對較少,線下的信息儲存和處理行業尚未興起,這一階段適用《侵權責任法》第36條尚可。但大數據時代背景下,算法甚至比使用者更了解其自身,要求侵害結果并進行事后救濟未免效率過低。
因此,我國的相關立法對個人信息的保護缺乏效率,并不能體現被遺忘權信息自決的特點,也無法回應時代對個人信息保護的需求。對被遺忘權進行更精準的分析與改造引進可能會成為更好的選擇。
三、現行被遺忘權的發展困境:規范和實踐的審視
(一)調整對象的設定缺陷:個人信息范圍的狹隘性
針對個人信息,學理界已存在大量討論。齊愛民教授認為,個人信息(information relating to individuals)是一切可以識別本人信息的總和。識別是個人信息的實質要素,得以固定和可以處理是個人信息的形式要素[9]。王利明教授也認為,可識別性是界定個人信息的重要標準,其認為個人信息是指與特定個人相關聯的、反映個體特征的具有可識別性的符號系統,包括個人身份、工作、家庭、財產、健康等各方面的信息[10]。也有學者認為,對于個人信息的界定不應單純考慮與個人的關系,同樣也需要思考個人信息與社會的關系,將個人信息界定得過于寬泛不利于社會公共利益的實現,因此,其認為個人信息是指那些據此能夠直接或者間接推斷出特定自然人身份而又與公共利益沒有直接關系的私有信息[11]。盡管當前個人信息的具體外延仍然是一個爭論不休的問題,但隨著關于個人信息本身討論的不斷深入,可識別性逐漸成為判斷是否屬于個人信息的核心元素。圍繞可識別性界定個人信息也逐漸被廣泛接受[12]。
被遺忘權的權利客體指個人信息,傳統“識別說”定義下的個人信息具有范圍狹隘的缺陷。“識別說”指信息能否成為個人信息,要看該信息能否識別信息主體,能夠識別則為個人信息,不能則相反。歐盟《通用數據保護法則》、我國《網絡安全法》和《個人信息保護法》(草案)均采用“識別說”定義個人信息。然而,技術的發展對“識別說”定義模式的個人信息定義提出了挑戰。一些非個人信息在一定條件下可以轉變為個人信息,個人信息的類型也突破了傳統的規定。實踐操作中,爭議較多的IP地址、cookies、人群位置、地理位置信息以及個人信息衍生產品等是否構成個人信息無法單靠立法的字面規定所解釋,甚至連姓名、電話號碼等是否構成個人信息也頗具爭議[13]70。即便是“匿名化”的信息也可能被重新識別。信息的這種動態化特征使得依靠“識別”來劃分個人信息與非個人信息的靜態立法模式呈現疲態。
“識別說”的個人信息定義方法,會使得被遺忘權的保護產生滯后性。信息的利用很大程度上指的是信息的二次利用和后期挖掘。當收集時,該信息無法識別個體,但海量數據的疊加使得當初無法識別個體的信息轉換成為可識別個體的信息。此時,再認定其為個人信息,利用被遺忘權進行刪除時,該信息已經被非法利用。對被遺忘權的調整對象進行改造便提上了日程。
(二)權利內容的設定偏差:知情同意保護方法的低效
個人信息保護的傳統機制建立在“知情同意”架構之上,要求機構在收集用戶個人信息前告知用戶信息的處理狀況,在網絡服務的語境中通常表現為發布隱私聲明,用戶在閱讀聲明后作出同意的表示,作為對個人信息收集和利用的合法授權[14]。依照前文的分析,作為被遺忘權觸發條件的“知情同意”框架弊端突出。按照“知情同意”框架的保護方式,事前信息采集時設定“知情同意”的架構,使得對于信息的收集不知情和不同意均可行使被遺忘權,這都是重復低效的設定。不論是日常生活的經驗還是實驗數據都證明了這一觀點。
日常生活經驗表明,數據服務需要數據的提供。允許軟件的訪問權限,是使用軟件的前提。如果用戶不同意這一要求,那么軟件將無法使用。在這種情況下,消費者對軟件獲取權限的事實知情,也被迫同意了該訪問請求,這使得如何判斷用戶內心是否真正同意成為難題。如果僅僅按照形式上格式合同的同意,那么人人都可以在接受服務結束后行使被遺忘權。
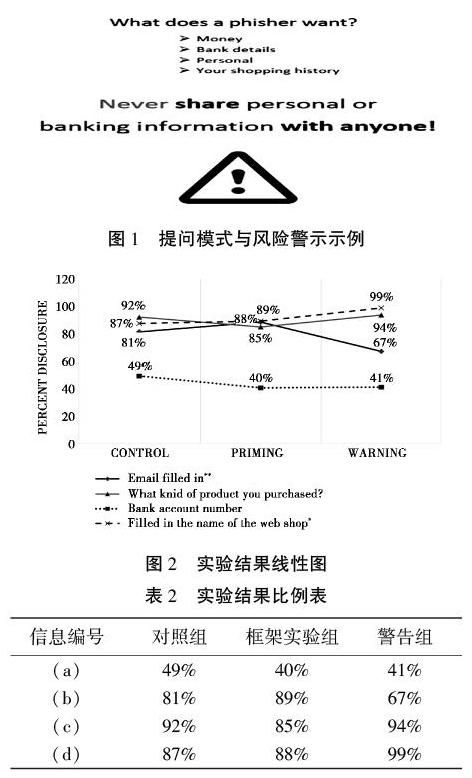
實驗數據也表明了“知情同意”在數據收集階段的功能喪失。2017年,美國學者Junger,Marianne和Lorena Montoya在荷蘭的商場進行了實驗。實驗以商業推廣為名對300多名商場顧客進行了分組詢問,詢問內容包括銀行賬號(a)、郵箱地址(b)、購物記錄信息(c)和瀏覽網店的名稱(d)。分組包括三組:對照組、框架實驗組和警告實驗組。對照組指實驗者直接詢問顧客的如上內容。框架實驗組則設置了一些問題引導顧客注意到披露信息可能導致網絡釣魚,然后才詢問上述內容。警告實驗組則直接采用大的警告標志警示顧客披露信息的風險,然后詢問顧客三項內容,問題和警告如圖1所示[15]80,結果如圖2所示[15]80。
實驗結果是三組中消費者被商家獲取信息的比例(見表2)。
與對照組相比,除“郵箱賬號(b)”之外,各種引導消費者“知情”的方式所能引起消費者謹慎的效果并不明顯。意圖通過令消費者知情,從而使其作出真實意思表示的方式在大多數情況下并沒有明顯效果[15]81。
(三)責任主體的設定不足:收集者、控制者和處理者的混淆
數據責任承擔者的劃分過于機械。《一般數據保護條例》(GDPR)對數據收集者、數據控制者和數據處理者進行了準確劃分,貌似嚴密而不疏漏,實則不然。上述責任者也可能是同一企業在有關個人信息行為的不同階段扮演了不同的角色。比如,某一企業是個人信息的收集者,也可能后續參與個人信息的處理。數據收集、處理和控制的階段轉變也往往在極短時間內完成。科技的進步會使得有關數據的行為超出收集、處理和控制的范疇,從而跳出法律的規制。因此,精確劃分數據責任的承擔者,會導致三者對責任的推諉,也為裁判者留下了如何區分責任承擔者的難題。
就刪除方式而言,“谷歌訴岡薩雷斯被遺忘權案(Google Spain SL, Google Inc. V Agencia Espaola de Protección de Datos (AEPD), Mario Costeja González, C-131/12, 13 May 2014)”在被遺忘權的發展過程中有著如同里程碑一般的重要意義。在該案判決中,最終確立起被遺忘權的概念和內涵,即有關數據主體的“不好的、不相關的、過分的(inadequate, irrelevant or no longer relevant, or excessive)”信息應當從搜索結果中刪除,這使得被遺忘權最終成為信息主體的一項民事權利而得到保護。但是該案僅僅確立了數據主體有權請求搜索引擎刪除鏈接。刪除方法不僅低效,而且留下了搜索引擎掌握個人數據審查權力的詬病。判例中所表現的刪除方法,要經歷個人申請、企業審查和刪除三個階段,費時費力。刪除方式的改進也應當獲得關注。
四、被遺忘權的中國應對:引入及其構建路徑
(一)被遺忘權引入中國的考量
有學者說道:互聯網的全球化意味著完整的數字化記憶以及“記憶成為常態”所帶來的諸多挑戰,不僅存在于倫敦和舊金山,在北京和上海也同樣令人關注,跨越了地理上的界限,完整的數字化記憶正在挑戰著我們所有人。被遺忘權絕不僅僅是歐盟與美國需要討論的話題。實踐中,阿根廷、日本等都在積極應對被遺忘權問題。我國已經進入互聯網時代,2019年2月28日,中國互聯網絡信息中心(CNNIC)發布第43次《中國互聯網絡發展狀況統計報告》,截至2018年12月,我國網民規模達8.29億,普及率達59.6%,較2017年底提升3.8個百分點,全年新增網民5 653萬。在此背景下,數字化永久記憶帶來的遺忘難題將不可避免。此外,歐盟將被遺忘權規則適用于所有在歐盟境內經營的自然人和企業,這意味著任何想要進入歐盟市場的企業都需要應對被遺忘權問題。在“谷歌西班牙公司案”后,谷歌、雅虎、微軟等美國互聯網巨頭都在積極出臺相關在線申請程序,以便應對歐盟對被遺忘權的規定。我國百度、阿里巴巴、騰訊等互聯網巨頭要想實現“走出去”戰略,進入歐盟等確立被遺忘權的國際市場,必須積極應對。
我國現行法律規定中并不存在被遺忘權,但在信息保護方面有相關的法律基礎。有學者認為現有的信息保護法條中,無論是權利主體還是義務主體的界定都顯得較為狹隘,從而降低了法律實施的有效性[16]。從我國現行的實際規定來看,如2015年的任甲玉與北京百度網訊科技有限公司人格權糾紛一案(“中國被遺忘權第一案”)[17],將被遺忘權引入我國規定之中很有必要。有學者就當下我國引入“被遺忘權”的現實要求進行分析認為:就當前我國的法律體系而言,個人信息保護相關法規有所欠缺,“被遺忘權”的引入有望進一步完善我國的法律體系;當前我國個人信息泄露問題較為嚴重,人們的私人生活受到影響,“被遺忘權”的引入有望改善這一現狀;在我國,“刪帖”行為已成為灰色產業鏈,“被遺忘權”的引入一定程度上能抑制此類現象的猖獗[18]。同樣,學者余筱蘭認為,無論是在理論還是實踐層面,信息刪除權在大數據時代的信息保護立法中都有其必要性。這不僅是人權保障的需求,也是市場經營得以正常維系的需要[19]。同時,被遺忘權對公民來說,一方面,可以正確塑造個人形象:每個人或許多少都有著一些不愿意再被人知曉的過去,當過去已然不符合現在的情況,我們有權利讓他人遺忘,網絡空間也應該還原當下的個人情況,這也更有利于他人接收到更新、更準確的個人信息。另一方面,有利于保護個人權利:人們在使用互聯網的時候總會或多或少地泄露一部分自己的信息,而當這些信息數據對信息主體產生負面影響的時候,個人有權將其刪除,維護個人合法利益。因此,無論是從學界的廣泛熱議還是現實的考量,我國都應該引入被遺忘權。
(二)被遺忘權在中國的構建路徑
被遺忘權的引入應當考慮該制度的缺陷,在結合中國實際的基礎上對其調整對象、權利內容以及責任承擔方式進行改良。在被遺忘權的權利主體方面,個人對有關自身的信息行使權利毋庸置疑。在調整對象方面,需要更新信息概念的定義方法,擴大被遺忘權的客體范圍。在權利內容方面,克服知情同意框架帶來的弊端,對權利內容進行風險評估的改良。當然,被遺忘權的責任主體應當得到明確、責任承擔方式也應當進行改造。
1.被遺忘權調整對象的優化構建
正如前文所述,“識別說”模式下的個人信息定義具有狹隘性,應當被改造。
(1)個人信息的重新定義
個人信息應當包括與個人有關聯的信息和數據,凡是與個人有關聯的信息都應當納入個人信息的范疇。當然,個人信息的列舉式立法可以繼續保留,但應當作為參考,而不能賦予其全有或者全無的效力。個人信息不應當局限于事前的預先設置,而應當以結果為導向,摒棄“識別說”的禁錮,確立新的動態定義方式。
(2)個人信息重新定義的原理及意義
遺忘權客體的改造參考了“關聯性”學說的定義方式。個人信息的定義重點應當從“識別”轉向“關聯性”。“關聯性”信息的定義方式來源于美國。美國聯邦貿易委員會(FTC)在回復電子基金會(EFF)的消費者隱私框架報告中指出:該隱私框架可以適用于“與特定消費者、計算機或其他設備合理關聯(link)”的數據[20]。美國《消費者信息隱私保護法》也規定了個人信息“關聯性”的定義方式。
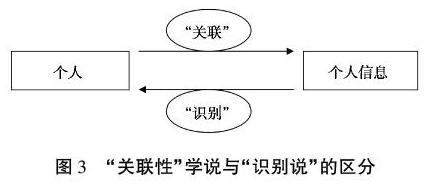
“關聯性”學說的路徑是指先確定某一具體的個人,再以此個人為原點,關聯與該個人有關的信息。能夠關聯到特定個人的信息,并不以特殊性為前提,其作用是豐富給定個體的畫像(profile)[13]72。例如,傳統意義上“性別,男”并不能構成對個人的識別,但如果將“性別,男”與“李某某”相關聯則形成了有關李某某的個人信息。“關聯性”學說與“識別說”的區分如圖3所示。
個人信息的“關聯性”學說可以擴大個人信息的范圍,克服“識別”定義方式的滯后性。“關聯性”定義方式的做法將個人信息保護的重點從關注信息本身轉向關注個人,不要求該信息能夠辨別某一個體。一旦某信息與個人有關,即可認定為個人信息。這使得大數據背景下,某些看似無法識別個人的瑣碎信息也被納入個人信息的保護范疇,避免了信息再次識別對人的侵害。另外,只要有關聯,個人即可行使被遺忘權,哪怕該信息未被利用,也可以提前防范個人信息的侵害,這也使得“識別說”定義方法的滯后弊端得以解決。
2.被遺忘權權利內容的改造構建
被遺忘權權利內容的改造分為以下三檔。
第一檔:個人信息的刪除請求以具體情景的風險評估為準,達到風險標準的敏感信息,數據控制者、利用者和處理者應當著重披露和告知,數據主體可以直接請求將信息刪除。
第二檔:個人信息應當有具體行業規定配套的存儲期限,存儲期限屆滿的個人信息應當自動刪除。例如,規定學前教育行業收集新生兒信息,應當在9個月內刪除。
第三檔:超過信息存儲期限未自動刪除的個人信息,可以由信息主體、信息處理者、控制者和收集者協商付費使用,未達成使用協議的可以由信息主體請求刪除或請求公權力機關責令刪除,或者公權力機關主動責令刪除。當然,還可以在被遺忘權之外的規定中制定配套措施,如對達到風險標準的信息還應當進行備案管理,備案機關可以就“知情同意”的情況進行調查。
(1)情景劃分與風險評估的設立
“情景脈絡完整性”理論的情景劃分為個人信息保護提供了藍本。該理論基于兩個準則的假設[21]:人類行為可以歸于不同的場景中;具體的情景可以為發生于該情景中的行為提供規范。尼森鮑姆認為:“人們的現實生活,它們不僅跨越了二分法,而且在多個不同的領域中來回穿梭。求醫、拜訪朋友、咨詢精神科醫生、與律師交談、去銀行、參加宗教儀式、投票以及購物等,每一個領域都涉及到一個獨特的規范,用來規范其各個方面。”敏感度的分級可以參考尼森鮑姆提出的四個要素:具體的情景脈絡,如報紙的頭版;不同情景中的行為人,如行為者在該情景中的特定身份;信息的屬性,例如信息主體的外觀;信息的傳播方式,例如記者的新聞采訪和傳播。這四則要素為具體情景的劃分提供了基礎。
“情景脈絡完整性”理論對“知情同意”框架的部分替代可以提高被遺忘權的效率。一方面,降低了被遺忘權低效保護的成本。對于敏感度不高的信息而言,收集時的知情與同意并不重要,重要的是該信息的利用方式、利用目的和利用場景。另一方面,“情景脈絡完整性理論”解除了被遺忘權可能阻礙人工智能產業的憂慮。當下人工智能產業的發展需要大量的數據和信息支持,新數據和信息的收集、過往數據和信息的利用是該產業必不可少的環節。2017年,國務院印發了《新一代人工智能發展規劃》,將人工智能發展上升到國家戰略高度,構筑我國人工智能發展的先發優勢,加快把建設創新型國家和世界科技強國提升到國家戰略高度[22]。“情景脈絡完整性”理論剔除了一般個人信息的“知情同意”的框架,將個人信息的保護重點由收集轉向利用,為個人信息的收集降低了難度和成本。
盡管敏感等級評估無法避免,但人工智能產業的發展本身是對信息的合理利用,而非無限利用,解決好信息隱私與信息開發利用之間的矛盾是人工智能產業發展的重大課題。在以往考慮被遺忘權時,其是建立在“知情同意”的前提下,收集信息要求信息主體的同意,在不同意或“假同意”的情形下,信息主體還要承擔被遺忘權的請求。“情景脈絡完整性”理論使得被遺忘權影響產業發展的顧慮得以消除。風險評估的一般標準和具體標準為不同情景下的個人信息風險提供了評估方法。美國學者提出的信息隱私侵害的判斷方法可以為風險評估提供一般標準。對于每個侵犯信息隱私權的案件而言,都可以按順序對以下三個問題進行回答。
第一步:算法分析結果是否超出了信息主體的預期?如果超出預期,則進入第二步;如果沒有超出預期,則視為該分析結果風險可接受。
第二步:該算法分析的結果是否比原信息的敏感度更大?如果更敏感,則進入第三步;如果不敏感,則該分析結果風險可接受。
第三步:該算法分析的結果是否符合具體的情景脈絡?如果符合,則風險評估可接受;如果不符合,風險評估不可接受[23]。
具體情景下的風險評估標準依賴于信息敏感度分級制度的建立。在信息敏感度分級的制度中,敏感度越高對公民的傷害可能越大,反之,則越小[24]17。國內有學者針對公共部門的服務門類,為具體的個人信息評估劃分了敏感等級[24]95,例如,體育、教育和衛生等公用部門的個人信息敏感度劃分,各種商業服務情景下的個人信息也應當進行敏感度評估。
(2)個人信息付費使用機制的建設
盡管弱人工智能的興起并沒有取代人類,但大量失業的焦慮卻并不能令人釋懷,收入分配的差距也令底層大眾焦躁不安。當數據被視為資本時,資本為公司提供利潤,并激勵公司的創新和發展;當數據被視為勞動時,則有助于數據的高質量產出。高質量的數據才是人工智能發展的優秀能源。雖然數據的性質為何仍然在探索中,但為數據付費完全可以作為可選擇的方案。信息的付費使用也有助于篩選真正的信息需求者。經濟學的研究表明,人們“為權利而斗爭”并不是為了真善美,而是為了各自的利益[25]。成本的比較和核算是人的本性,信息的付費使用,要求信息利用者負擔成本,這有助于將粗放經營者排除于市場之外,提高信息服務的質量。
(3)個人信息存儲期限的確立
被遺忘權誕生之時,本身便自帶“遺忘”屬性。舍恩伯格認為遺忘期限為9個月。但對于該期限而言,應當結合民眾意愿和技術需要進行分類規定。增添信息存儲期限的原因如下:一方面,人會遺忘的天性與存儲器永久“記憶”具有必然的矛盾,個體永遠無法保障敏感的信息完全被清理,規定數據存儲期限由數據主體進行選擇是一項事前防范的良好措施,既為數據收集者提供了收集時間,也為數據主體提供了事前防范;另一方面,與個體請求刪除相比,按照到達存儲期限的方式刪除個人數據效率更高,覆蓋面更大。前者是個別鏈接和遺漏信息的刪除,后者則是批量化操作。此外,規定存儲期限還具有“兜底性”的特征。為信息設定存儲期限,既可以為企業提供信息利用的期限,也可以倒逼企業提高效率改良算法,從而提高競爭力。這樣,既為個人信息的保護提供了屏障,也為企業個人信息的利用留下了空間。
3.被遺忘權責任承擔的明確構建
(1)被遺忘權責任主體的明確
被遺忘權的責任主體包括信息控制者、信息利用者、信息處理者以及敏感度等級較高的信息收集者。
首先,岡薩雷斯訴西班牙數據保護局案的判例表明,搜索引擎是被遺忘權的責任承擔者,但并非責任承擔者僅局限于搜索引擎。按照GDPR的規定,被遺忘權的行使對象包括部分收集者以及其余階段的數據責任主體。數據控制者、處理者和數據利用者三者可以互相轉化,也有不同的表現形式。搜索引擎既可以是數據利用者,進行信息的傳達和呈現,也可以是數據收集和控制者,收集和控制信息以分析市場和優化服務。
其次,認為被遺忘權的責任主體僅僅包括搜索引擎的觀點,是對信息流轉的靜態看待,也是對互聯網企業業務的孤立分析。對責任主體名稱進行劃分,并非靜態區別責任主體的種類,某種程度上說,信息控制者、信息利用者和信息處理者的角色可以由同一責任主體在信息加工過程中的不同階段分別扮演。因此,如果過度地將精力投入于明確信息控制者、信息利用者和信息處理者的界限之上,便會有本末倒置的嫌疑。
最后,“情景脈絡完整性”理論并非要完全排除“知情同意”框架。針對高度敏感的個人信息,就“知情同意”的架構進行著重設計,對個人進行科學的提醒,使得其知情并同意個人信息的利用,也具有一定的可實行性。“知情同意”架構的失靈很大程度上來源于信息隱私的模糊、復雜和應用廣泛的特點[26]。如果將隱私協議的數量縮減在高度敏感個人信息的收集范疇中,可以期待更高效的隱私協議設計。前述Junger,Marianne和Lorena Montoya的實驗結果中,郵箱賬號(b)也證明了這一點。
對被遺忘權權利內容的改造,最主要的是運用“情景脈絡完整性”理論對“知情同意”的改造。當然,被遺忘權中刪除為兒童社會信息服務而收集的信息以及刪除不同意收集之外的非法信息也應當得到保留。
(2)刪除責任的承擔原則
明確誰利用誰刪除、誰獲益誰刪除的刪除原則,還要與信息行為發生的時間階段相聯系。這是由信息收集者同時又可能是信息處理者和控制者的特征決定的。在信息刪除糾紛中,不必過于精準劃分信息責任主體的過錯,轉而運用誰受益誰擔責的方式,既可以節約判斷成本,也能夠起到信息保護的作用。這實際上是利用市場的淘汰機制進行信息保護。如果信息收集者違規操作獲得信息但并未被發現,這一信息流通后,信息利用者在不知情的情形下進行了利用,此時不必確認過錯的歸屬,而應當按照誰受益誰負責的直接標準進行責任劃分,由信息利用者承擔責任。信息利用者可以根據違約責任向信息收集者追究損失的補償。在市場環境中,違約而被追究責任的企業往往不能在競爭中勝出,這便會倒逼信息收集者尋找更優秀的信息資源,也會倒逼信息利用者和控制者尋找具有更高信用度的商業伙伴,遵循對信息的合規要求,從而減少損害的發生,節約爭議解決成本。
(3)明確刪除內容的限度
被遺忘權引起爭執的一大緣故在于,互聯網環境中不論是鏈接、數據還是個人信息,要徹底將其刪除存在很大的技術難度并需要一定的成本。除此之外,本地化的數據還可能導致已經刪除的內容再度被上傳網絡并造成一定影響。這一觀點看似很有道理,但并未深窺個人信息保護的內核。對于個人信息的保護,其本質上是先對個人信息形成控制,再以控制手段保護其背后的個人尊嚴等。在美國,信息隱私的主導范式是隱私控制論 ( Privacy-control),即對個人數據使用的控制權[27]。控制不等于刪除,就被遺忘權而言,其刪除是手段而遺忘是目的。對于整個人類而言,遺忘也并非一瞬間可以達成,而需要時間的消磨。
因此,被遺忘權并不是任意刪除,也不是對個人信息、人生痕跡的任意涂改或掩過飾非,而是通過糾正網絡時代的信息泛濫、過度便利和價值背離,保障每個人的人格得以自由發展,而不是生活在過往的陰影之中[28]。刪除手段只是對個人信息形成控制的手段,控制的結果可以是完全控制、部分控制和控制失敗。在整個人類的信息體系中,徹底刪除一條信息固然無法想象,但法律或法規明確在恰當場景中不允許或暫時性刪除某類信息卻確實可以實現。比如,可以規定基因信息不允許出現在日訪客流量500萬以上的網頁中。這便對個人信息的曝光度形成了控制,刪除的目標也便有了更精準的檢索范圍。
(4)刪除算法應用的必要性和可行性
允許信息主體使用刪除算法或允許其委托第三方使用刪除算法有如下理由。
首先,刪除算法的應用具有現實必要性。個人信息隱私在大數據時代面臨兩種威脅:其一,個人無力阻止未經授權的信息傳播;其二,個人被排除在個人信息商業流轉的進程之外。換言之,依靠個人時刻監督和警惕其個人信息被收集和利用的方法成本過高。但算法可以做到為個人提供信息保護的服務,刪除算法只是手段之一。相對于個人與科技巨頭的信息隱私保護斗爭而言,運用刪除算法的助力使得信息隱私保護成為可能,既降低了隱私保護的成本,也有助于培育新時代的信息隱私觀念。
其次,刪除算法的利用具有法學可行性。算法并非一種價值中立的科學活動,它總是蘊含著價值判斷,與特定的立場相關[29]。刪除算法的背后是被遺忘權的價值選擇,是達成被遺忘權目的的工具。刪除算法可以達到符合人類價值觀、個人隱私、隱私與自由等阿西洛馬原則所強調的要求。Lawrence Lessig提出法律與代碼之間的三種關系:法律馴服代碼、代碼代替法律、法律規制代碼。應用刪除算法既是被遺忘權之法律規定對代碼的馴服,也是代碼對法律的規制。賦予個人對信息的刪除權和信息的自動刪除義務,便改變了代碼的分布。刪除算法的應用也改變了法律的運行,在個體無法使用算法之前,刪除的權力掌握在信息控制者和利用者手中,刪除成本高且難度大。刪除算法作為代碼運行的另一種方法,使得刪除的效率得以提高而成本卻有所下降,使被遺忘權真正發揮保障信息的功效。
最后,刪除算法的利用具有技術可行性。當下,互聯網市場已經出現成熟的反個人信息收集的混淆算法,通過在搜索引擎鍵入的關鍵詞里插入無關字符,以達到混淆關鍵詞的目的。混淆算法是事前防備個人信息被不當收集的技術,刪除算法則相反,是事后擦除個人信息的技術。借助技術手段達到權利目的可能更有效。
被遺忘權的提出代表了進一步擴張個人數據權利的傾向,這一傾向是在互聯網尤其是社交網絡急劇發展的背景下出現的[30]。被遺忘權的權利改造要關注被遺忘權本身,它涉及個人信息的其他制度,是牽一發而動全身的工作。其制度改造與技術利用需要同步進行,以合理制度搭載技術之翼可能更易于提高制度的社會效果。
五、結 語
在信息時代,“記憶”已經取代“遺忘”成為網絡空間的規范與常態,網絡空間的“雁過留聲”使人們很難逃離自己的過去[31]。在對待被遺忘權的態度上,歐美因不同的信息隱私和歷史觀念而截然不同。歐盟選擇了被遺忘權,而美國選擇了言論自由。歐美差異選擇的理由啟示我國在引入被遺忘權時,應當結合具體的價值觀念、經濟成本、信息保護需求和法律體系,改造被遺忘權成為必要。通過“關聯性”學說對個人信息進行優化構建,利用“情景脈絡完整性”理論對“知情同意”框架的部分變革可以為被遺忘權的引入打好理論基礎。被遺忘權的刪除責任以及違規責任應當在法條中予以明確。同時,被遺忘權還可以借助算法的技術力量,并在刪除之外擴展其遺忘功效。當然,依照“情景脈絡完整性”理論需要制定各行業不同的信息規范,以滿足動態評估信息收集和利用風險的大小,并制定具體行業存儲期限的長短,這些需要大量的數據支持和行業實踐,并非一日之寒。當個人信息的隱私行將遠去,被遺忘權之探索仍然任重道遠,前路蹉跎,砥礪前行。
參考文獻:
[1] 伍艷.論網絡信息時代的“被遺忘權”——以歐盟個人數據保護改革為視角[J].圖書館理論與實踐,2013(11):4.
[2] 鄭曦.個人信息保護視角下的刑事被遺忘權對應義務研究[J].浙江工商大學學報,2019(1):46.
[3] 維克托·邁爾-舍恩伯格.刪除:大數據取舍之道[M].袁杰,譯.杭州:浙江人民出版社,2013:19.
[4] 劉學濤.大數據時代個人信息的行政法保護分析:內涵、困境與路徑選擇[J].南京郵電大學學報(社會科學版),2018(6):27.
[5] 張新寶.隱私權的法律保護[M].北京:群眾出版社,1998:157.
[6] WHITMAN J Q. The Two Western Cultures of Privacy: Dignity Versus Liberty[J].Yale Law Journal,2004(6):1161.
[7] WHITMAN J Q. Enforcing Civility and Respect:Three Societies Enforcing Civility and Respect[J].Yale Law Journal,2000(6):1297.
[8] DOWNWELL J W.An American Right to be Forgotten[J].Tulsa Law Review,2017(2):331.
[9] 齊愛民.個人信息保護法研究[J].河北法學,2008(4):15.
[10]王利明.論個人信息權的法律保護——以個人信息權與隱私權的界分為中心[J].現代法學,2013(7):64.
[11]劉德良.個人信息的財產權保護[J].法學研究,2007(3):80.
[12]劉學濤.個人數據保護的法治難題與治理路徑探析[J].科技與法律,2019(2):21.
[13]范為.大數據時代個人信息定義再審視[J].信息安全與通信保密,2016(10).
[14]范為.大數據時代個人信息保護的路徑重構[J].環球法律評論,2016(5):94.
[15]MARIANNE J, MONTOYA L, OVERINK F-J. Priming and warnings are not effective to prevent social engineering attacks[J].Computers in Human Behavior, 2017(66).
[16]何治樂,黃道麗.大數據環境下我國被遺忘權之立法構建——歐盟《一般數據保護條例》被遺忘權之借鑒[J].網絡安全技術與應用,2014(5):173.
[17]楊杰.被遺忘權的明晰及本土化探究[J].重慶郵電大學學報(社會科學版),2018(4):73.
[18]郭小安,雷閃閃.“數據被遺忘權”實施困境與我國的應對策略[J].理論探索,2016(6):111-112.
[19]余筱蘭.民法典編纂視角下信息刪除權建構[J].政治與法律,2018(4):27.
[20]Protecting Consumer Privacy In An Era Of Rapid Chan-
ge: A Propesed Frame Work For Business And Policymakers (Preliminary Staff Report) Response Of The Electronic FrontierFoundation[EB/OL].[2018-12-22].https://www.eff.org/files/ftccommentseff.pdf.
[21]NISSENBAUM H. Privacy as Contextual Integrity[J]. Wshington Law Review,2004(6):102.
[22]新一代人工智能發展規劃[EB/OL].(2017-07-20)[2019-01-15].http://www.gov.cn/zhengce/content/2017-07/20/content_52116.htm.
[23]Pan S B. Get to Know Me: Protecting Privacy and Autonomy under Big Datas Penetrating Gaze[J]. Harvard Journal of Law & Technology,2016(30):259.
[24]劉雅琦.基于敏感度分級的個人信息開發利用保障體系研究[M].武漢:武漢大學出版社,2015.
[25]馮玉軍.法律與經濟推理——尋求中國問題的解決[M].北京:經濟科學出版社,2008:32.
[26]BEN-SHAHAR O, CHILTON A. Simplification of Privacy Disclosures: An Experimental Test[J].Journal of Legal Studies,2016(45):45.
[27]高富平.個人信息保護:從個人控制到社會控制[J].法學研究,2018(3):91.
[28]滿洪杰.被遺忘權的解析與構建:作為網絡時代信息價值糾偏機制的研究[J].法制與社會發展,2018(2):217.
[29]丁曉東.算法與歧視——從美國教育平權案看算法倫理與法律解釋[J].中外法學,2017(6):1622.
[30]劉文杰.被遺忘權:傳統元素、新語境與利益衡量[J].法學研究,2018(2):40.
[31]范為.由Google Spain案論“被遺忘權”的法律適用——以歐盟數據保護指令(95/46/EC)為中心[J].網絡法律評論,2013(2):267.
Abstract:China in the data age faces a series of major problems such as personal information infringement, personal privacy disclosure, and algorithmic discrimination. The right to be forgotten should be established with the aim of protecting the rights of information subjects. The right to be forgotten in Europe and the United States is reflected in the conflict between privacy and freedom. The importance of this theory to the needs of countries is that the right to be deleted in Chinas existing legal system cannot be equated with the forgotten right established by the EU. The current right to be forgotten faces the development dilemma of setting defects of adjustment objects, setting deviations of rights content, and insufficient setting of responsible subjects. The heated discussion and practical needs of scholars indicate to a certain extent that China should introduce the right to be forgotten, and that chinas path choice should be set up from the optimization construction of adjustment objects, the reconstruction of rights content, and the construction of responsibility, so as to solve the new challenges brought by the development of network information society.
Keywords:forgotten right; deletion right; contextual integrity; deletion algorithm
(編輯:劉仲秋)
