IDC用戶網站非法信息檢測系統技術實現
2019-07-12 08:28:44張宏丙
電子技術與軟件工程 2019年9期
文/張宏丙
1 引言
隨著互聯網產業高速發展,信息化需求激增,采用服務器托管或是應用直接部署上云的現象已十分普遍。而與此同時,作為信息內容匯聚地的IDC,也成為某些不法分子用于傳播色情、反動、賭博等非法信息的重災區。此外,隨著G20峰會、進博會等重大國際活動的相繼舉辦,非法信息的檢測過濾也顯得尤為重要。一旦發布了非法信息,而一時間各監管部門又難以及時發現,勢必會造成極其惡劣的負面影響。因此,對于那些瀏覽人數眾多,影響面大的網站,尤其需要對其網頁內容進行定期的主動檢測。這樣,對上海電信而言,一方面,可以主動落實包括工信廳網安函【2017】337號文在內的相關工作要求;另一方面,也可以體現上海電信的社會責任感,從而提升自身的社會形象。
由此可見,無論是從管理要求還是社會責任考慮,無論是從提升服務等級還是管理水平考慮,定期對IDC所轄用戶網站內容進行自動檢測都是十分必要的。為此,上海電信近年來一直致力于IDC用戶網站非法信息檢測系統的建設及完善,本文就該系統研發過程中遇到了若干技術問題以及相應的解決方案做一簡單探討。
2 系統概述
IDC用戶網站非法信息檢測系統主要采用爬蟲技術,定期對IDC用戶網站的網頁文本進行掃描和關鍵字匹配,以主動發現那些含有非法信息的網站。所謂爬蟲技術,又稱為網絡爬蟲,其基本思想就是根據網頁上的超級鏈接,逐層遞歸地進行爬取和掃描。同時,該系統對掃描結果進行保存,并生成統計報表以供安全管理員查看。
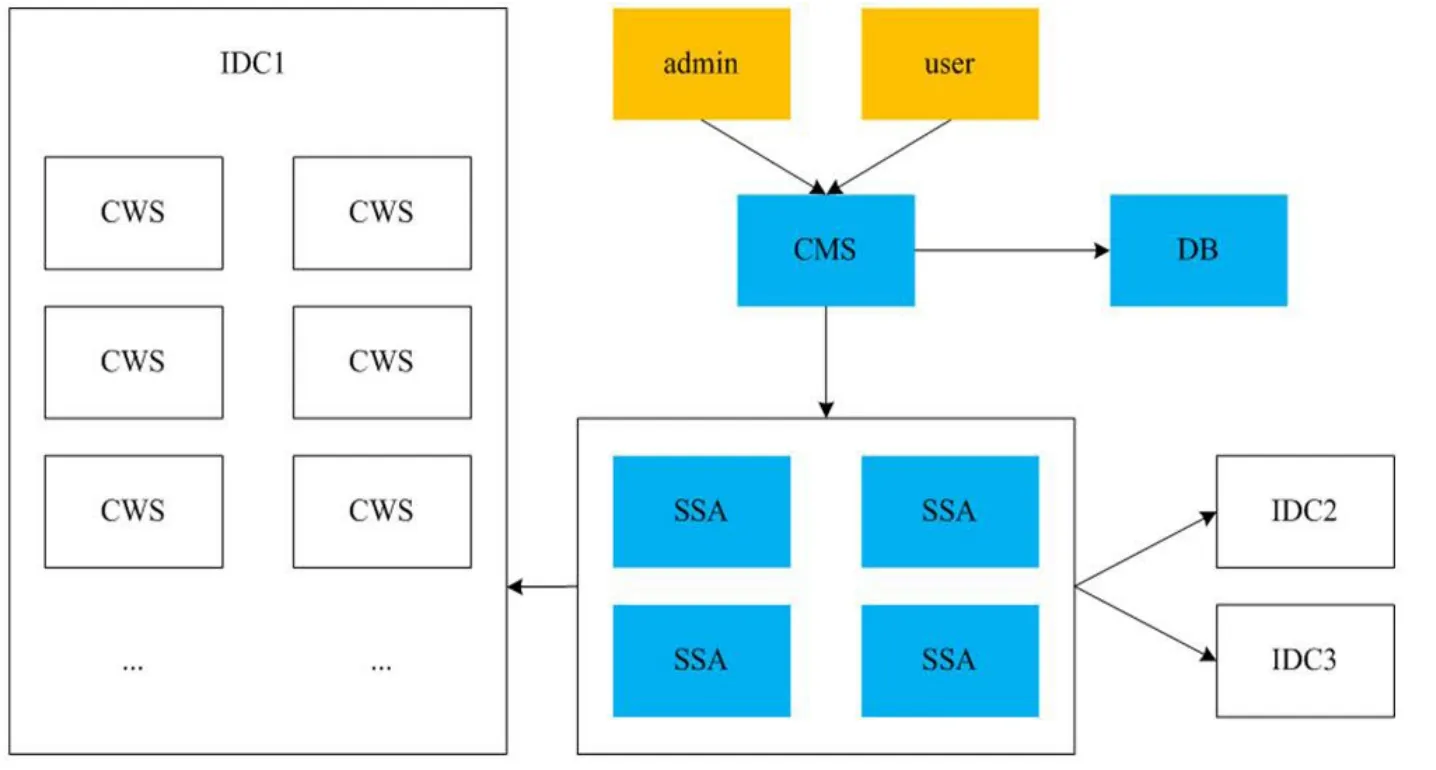
圖1:IDC用戶網站非法信息檢測系統總體架構圖
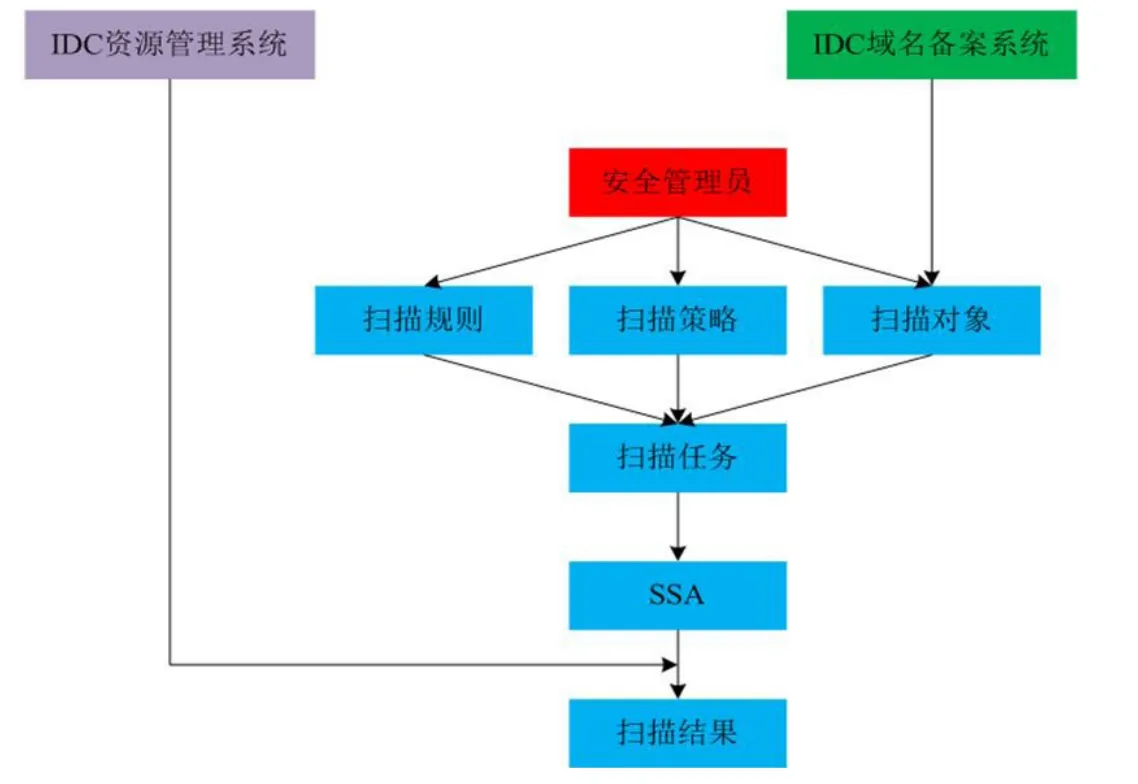
圖2:IDC用戶網站非法信息檢測系統核心要素邏輯結構圖
考慮到集中管理和可擴展性,該系統采用大家所熟知的C/S架構,即中央管理控制器+分布式掃描代理的結構,總體架構如圖1所示。
圖1中藍色背景部分是系統的組件:
(1)中心管理服務器(CMS,Central Management Server)。系統的核心服務器,安全管理員通過web接口訪問,在該服務器上配置掃描規則、掃描策略及掃描對象;生成、調度掃描任務;展現掃描結果。
(2)數據庫(DB)。保存系統的核心數據,包括用戶、服務器和掃描任務的配置,以及掃描結果信息和含有非法信息的網頁快照。
(3)網站掃描代理(SSA,Site Scanning Agent)。根據中心管理服務器(CMS)的安排,執行針對用戶網站的掃描。掃描從指定頁面開始,在一定約束下跟蹤每個引用到的URL。
圖1中白色背景部分是互聯網數據中心及其用戶服務器:
(1)互聯網數據中心(IDC)。托管用戶服務器及用戶網站的機房。
(2) 用 戶 服 務 器(CWS,Client Web Server)。系統進行掃描監控的對象,主要通過IP地址進行標識。
圖1中橙色背景部分是系統的使用者:
(1)系統管理員(admin)。對系統進行維護管理的人員,負責定義用戶、劃分權限等。系統管理員同時負責維護組成系統的各類服務器。
(2)安全管理員(user)。系統一般使用者,主要工作包括監控用戶網站內容,設置關鍵字集和掃描策略,發起手工掃描任務,檢查掃描任務的執行情況,制作報表等。
3 系統核心要素及其之間的邏輯關系
正如之前所介紹的,該系統是采用爬蟲方式對用戶網站的內容進行主動掃描和檢測,因此,掃什么、怎么掃自然就成為系統設計的考慮重點,由此也引申出構成系統的若干核心要素,其中包括:
(1)掃描對象,即受掃描監控的網站。其中一部分來自IDC域名備案系統,另一部分來自非法信息檢測系統本身的錄入。
(2)掃描規則,包括關鍵字數據集及對應的權重值,這也是用來判斷某個網頁是否含有非法信息及其危害程度的依據。
(3)掃描策略,包括掃描頻率、深度約束、每一層頁面抓取上限值等。對掃描層數及每一層頁面抓取上限值的限定,可以使對網站的總體掃描時間變得可控。
(4)掃描任務,由掃描規則和掃描策略作用于掃描對象上而形成的特定任務。掃描任務包含執行該次掃描所需的所有信息,并根據觸發條件自動運行。
(5)掃描結果,以IP地址為橋梁,通過結合來自IDC資源管理系統的相關資源信息,形成擁有詳細信息的掃描結果,其中包括域名、IP地址、關鍵字、權重值、URL、快照、時間戳等。安全管理員可以根據不同查詢條件,獲得其所關心的統計報表。
它們之間的邏輯關系如圖2所示。
4 若干關鍵問題探討
系統總體架構已經搭建,而為了使之有效地運轉起來,有兩個關鍵問題值得我們去思考和關注。
(1)如何準確定位非法信息源頭。通過對問題網站實施內容檢測,我們可以獲得含有非法信息的網頁快照,當然這只是工作的第一步,檢測的最終目的是清除這些非法信息,因此,能否準確地定位網站歸屬就顯得尤為重要。
(2)如何使問題網站掃描變得更加高效。由于我們IDC機房內的網站成千上萬,如果要逐個爬取,其代價可想而知,而且效率也不高,因為大多數網站上的大部分網頁是合法的。如何充分運用有限資源,有針對性地掃描,在某種程度上,就成為決定系統成敗的關鍵。下面我們先就這兩個問題分別加以探討。
4.1 準確定位非法信息源頭
為了說明問題,我們首先來看掃描結果會包含哪些信息。考慮到盡可能方便安全管理員對非法信息的處理,一條完整的掃描結果會包含如下11個字段:域名、IP地址、用戶名、用戶聯系人、聯系方式、所屬機房、包含的關鍵字、權重值、問題URL、問題網頁快照、記錄時間。它們之間的邏輯關系如圖3所示。其中,有三對關系是非靜態的,可能會發生變化,分別是:域名與IP地址之間的關系、IP地址與用戶名之間的關系、IP地址與所屬機房之間的關系。

圖3:一條完整掃描結果所包含字段間的邏輯關系
考慮到上述第一對關系可能隨時被打破,為了避免誤關聯,非法信息檢測系統在掃描之前,會對域名進行實時解析,以獲得該域名當前實際對應的IP地址。
而為了確保后兩對關系的準確性,與IP地址、用戶及所屬機房相關的信息將會定期同步于IDC資源管理系統,因為后者的設計初衷就是為了實現IDC資源的集中管理和統一維護。
4.2 高效掃描問題網站
不同于我們經常使用的搜索引擎,對非法信息檢測系統有效性的評判,更多地在于如何在特定時間內發現更多的含有非法信息的網頁。在系統資源極為有限的前提下,我們采取一系列措施來使得掃描更加高效。
(1)將掃描對象做進一步細分:一類稱作常規監控網站列表;另一類稱作重點監控網站列表。對后者給予重點關注,加強掃描頻次。這樣做主要是基于以下事實考慮:有過前科的網站較之其他網站往往更易再次發布非法信息。對于重點監控網站列表,有兩方面來源:一是由非法信息檢測系統自動發現的問題網站,二是由公安局、安全局、通管局報來的問題網站。這樣,也使得那些被人工處理過的信息得到了有效繼承和再利用。
(2)對于大型網站,掃描一次所花費的時間動輒十幾小時,甚至幾天。因此,對大型網站做全掃描開銷太大。而經過深入分析,對大網站而言,其非法信息往往只集中于某幾個版塊,如bbs、娛樂版等。為掃描對象添加URL入口及URL匹配規則屬性,可以使掃描從指定入口開始,并且限定在匹配規則范圍內,如此能使安全管理員控制大型網站的掃描,快速有效地掃描所關注的內容。
(3)在掃描代理上做文章。一方面,通過多代理多線程設計,使得單個對象的掃描時間進一步縮短。另一方面,由于掃描代理與掃描對象之間的物理位置關系會直接影響到掃描效率,因此,允許安全管理員可以根據實際需要來指定代理對特定對象進行掃描。
為使IDC非法信息檢測系統更加實用、高效,在研發過程中,除了著重考慮和解決前面提到的兩個關鍵問題外,還實現了如下功能:
(1)對由域名備案系統傳來的掃描對象,可以自動配置掃描策略,生成掃描任務,并根據安全期限,來淘汰那些“改邪歸正”的網站,從而保證整個系統自動有序運轉,減少人工干預。
(2)系統支持自定義掃描關鍵字,并可對已定義的關鍵字集實現分組管理。通過為不同掃描對象配置不同關鍵字集,以達到差異化掃描的目的。
(3)關鍵字匹配支持整體匹配和局部匹配,有效提升了匹配效率。利用關鍵字加權求和來對問題網頁進行評分,使安全管理員可以區分問題網頁的危害程度。
(4)使安全管理員能最大限度了解和控制掃描任務的運行情況,增加了系統的靈活性。
5 結束語
IDC用戶網站非法信息檢測系統采用爬蟲技術,定期對受控網站的網頁文本進行掃描和關鍵字匹配,以主動發現那些含有非法信息的網頁。盡管由于技術上的限制,該系統對那些需要密碼才能訪問的網站,還無法實現有效爬取。但是借助它,我們對大多數常規網站已經能實現主動檢測,從而在一定程度上提高了IDC信息安全管理能力。
猜你喜歡
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中學生數理化·七年級數學人教版(2021年6期)2021-11-22 07:50:58
中華手工(2017年2期)2017-06-06 23:00:31
商用汽車(2016年11期)2016-12-19 01:20:16
商用汽車(2016年6期)2016-06-29 09:18:54
海峽科技與產業(2016年3期)2016-05-17 04:32:12
商用汽車(2016年4期)2016-05-09 01:23:12
創業家(2015年5期)2015-02-27 07:53:25
中外會展(2014年4期)2014-11-27 07:46:46
