基于GPU的并行圖像離散小波變換
2019-07-20 13:24:35邱霽巖凌翔關非凡李少杰
電子技術與軟件工程 2019年10期
邱霽巖 凌翔 關非凡 李少杰
摘要:針對現有的離散小波變換耗時久的問題,本文利用CUDA并行計算技術,提出了一種基于GPU的離散小波變換算法實驗結果表明在一張2048x2048分辨率的圖像中達到了最大106.34的加速比,而,且保持了良好的效果。
[關鍵詞]小波分析CUDAGPU圖像處理
1離散小波變換簡介
小波變換的原理:小波變換是指將傅里葉變換中的基進行變換,將三角函數基變換為小波基,三角函數基是無限長,小波基是有限長且衰減的。
小波變換公式如下:
其中a是尺度和τ是平移量。尺度a控制小波函數的伸縮,平移量τ控制小波函數的平移。尺度就對應于頻率(反比),平移量τ對應于時間
本文選取離散小波變換。離散小波變換(DiscreteWaveletTransform)是離散化基本的小波的尺度和平移,可以用在數值分析、時頻分析和圖像處理中,效果顯著。尤其是在圖像處理領域,有著突出的表現。
本文選用的小波基是Haar小波,Haar小波為:
對于二維的圖像,Haar小波變換需要先對每一°行做變換,再對每一列做變換。相當于對于每四個像素執行
2CUDA并行計算平臺簡介
CUDA(ComputeUnifiedDeviceArchitecture)是NVIDIA公司推出的基于通用并行計算架構的運算平臺,基于該架構可以運用GPU解決復雜的計算問題。CUDA是一種附加在操作系統和C語言或C++等類程序之間的一層底層庫。
GPU中的典型CUDA架構分為三層:線程、線程束和線程塊。線程是GPU執行的最小單元,可以執行并行任務。線程束是32個線程的集合,可用作單指令多數據操作。線程塊是多個線程的集合。只有同一塊中的線程才能直接通信,例如訪問同一共享內存或快速同步。網格由幾個塊和全局內存,常量內存和紋理內存組成,可以由其中的每個塊和線程訪問。
3并行小波變換算法實現
首先為每一個線程分配一個二維的id用于并行的讀取數據。之后根據id值計算每個線程需要計算的區域。一共分為四個區域HH、HL、LH、LL。之后從紋理內存讀取相鄰的四個數據區域,根據分配到的不同區域進行不同的計算。完成計算之后,根據是線程的id寫入計算結果。
4實驗結果分析
本文通過對比串行的程序分析并行算法的性能。使用加速比S=T/Tp來衡量并行化性能。
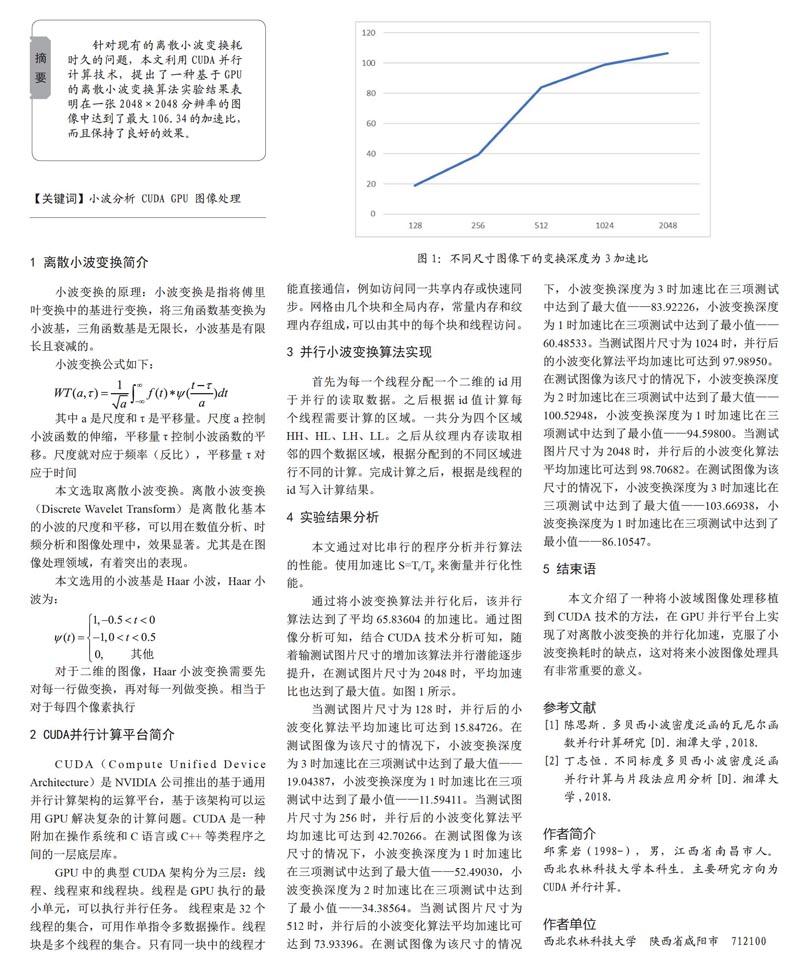
通過將小波變換算法并行化后,該并行算法達到了平均65.83604的加速比。通過圖像分析可知,結合CUDA技術分析可知,隨著輸測試圖片尺寸的增加該算法并行潛能逐步提升,在測試圖片尺寸為2048時,平均加速比也達到了最大值。如圖1所示。
當測試圖片尺寸為128時,并行后的小波變化算法平均加速比可達到15.84726。在測試圖像為該尺寸的情況下,小波變換深度為3時加速比在三項測試中達到了最大值——19.04387,小波變換深度為1時加速比在三項測試中達到了最小值——11.59411。當測試圖片尺寸為256時,并行后的小波變化算法平均加速比可達到42.70266。在測試圖像為該尺寸的情況下,小波變換深度為1時加速比在三項測試中達到了最大值——52.49030,小波變換深度為2時加速比在三項測試中達到了最小值——34.38564。當測試圖片尺寸為512時,并行后的小波變化算法平均加速比可達到73.93396。在測試圖像為該尺寸的情況下,小波變換深度為3時加速比在三項測試中達到了最大值——83.92226,小波變換深度為1時加速比在三項測試中達到了最小值——60.48533。當測試圖片尺寸為1024時,并行后的小波變化算法平均加速比可達到97.98950。在測試圖像為該尺寸的情況下,小波變換深度為2時加速比在三項測試中達到了最大值——100.52948,小波變換深度為1時加速比在三項測試中達到了最小值——94.59800。當測試圖片尺寸為2048時,并行后的小波變化算法平均加速比可達到98.70682。在測試圖像為該尺寸的情況下,小波變換深度為3時加速比在三項測試中達到了最大值——103.66938,小波變換深度為1時加速比在三項測試中達到了最小值——86.10547。
5結束語
本文介紹了一種將小波域圖像處理移植到CUDA技術的方法,在GPU并行平臺,上實現了對離散小波變換的并行化加速,克服了小波變換耗時的缺點,這對將來小波圖像處理具有非常重要的意義。
參考文獻
[1]陳思斯。多貝西小波密度泛函的瓦尼爾函數并行計算研究[D].湘潭大學,2018.
[2]丁志恒。不同標度多貝西小波密度泛函并行計算與片段法應用分析[D].湘潭大學,2018.
猜你喜歡
民用飛機設計與研究(2020年4期)2021-01-21 09:15:02
中學生數理化·七年級數學人教版(2020年11期)2020-12-14 06:59:52
藝術品鑒證.中國藝術金融(2018年8期)2019-01-14 01:14:28
藝術品鑒證.中國藝術金融(2018年10期)2019-01-08 02:44:26
藝術品鑒證.中國藝術金融(2018年6期)2019-01-08 02:43:04
電子制作(2018年18期)2018-11-14 01:48:24
藝術品鑒證.中國藝術金融(2018年12期)2018-08-26 06:03:48
山東工業技術(2016年15期)2016-12-01 05:31:22
新聞傳播(2015年10期)2015-07-18 11:05:40
中國中醫藥現代遠程教育(2014年11期)2014-08-08 13:23:44
