基于Spark并行SVM參數(shù)尋優(yōu)算法的研究
2019-07-23 01:24:14何經(jīng)緯劉黎志付星堡
武漢工程大學學報 2019年3期
何經(jīng)緯 ,劉黎志*,彭 貝 ,付星堡
1.智能機器人湖北省重點實驗室(武漢工程大學),湖北 武漢 430205;2.武漢工程大學計算機科學與工程學院,湖北 武漢 430205
隨著互聯(lián)網(wǎng)的發(fā)展,越來越來的智能設(shè)備被接入到網(wǎng)絡(luò)中來,數(shù)以萬計的設(shè)備每天都在產(chǎn)生大量的數(shù)據(jù),如何從海量的數(shù)據(jù)中獲取有價值的信息成為當前研究的熱點。支持向量機[1-5](support vector machine,SVM)算法在參數(shù)設(shè)置合理的情況下,處理小樣本、高維度數(shù)據(jù)集時表現(xiàn)出很好的性能和準確率,而不合理的參數(shù)設(shè)置將會導致糟糕的性能和極低的準確率,所以參數(shù)的選取是SVM算法中至關(guān)重要的一環(huán)。傳統(tǒng)的SVM參數(shù)尋優(yōu)算法在處理大規(guī)模數(shù)據(jù)集時往往會遇到計算機性能的瓶頸,計算機的處理器資源、內(nèi)存資源全部被占用,在耗費相當長的時間后才能得到處理結(jié)果。
集群環(huán)境下的并行計算方式為大數(shù)據(jù)的處理提供了新的思路,目前主流的大數(shù)據(jù)處理技術(shù)基本都用到了集群環(huán)境[6-13]。集群環(huán)境并行計算是提高大規(guī)模數(shù)據(jù)集SVM參數(shù)尋優(yōu)速度的一種有效途徑,多計算機并行的SVM參數(shù)尋優(yōu)算法可以有效解決計算機單機計算能力不足、宕機等問題。目前主流的集群計算平臺有Hadoop和Spark,基于內(nèi)存計算的Spark目前應(yīng)用非常廣泛,如雅虎、Uber等公司都在使用Spark平臺處理自己的業(yè)務(wù),所以使用Spark實現(xiàn)并行化的SVM參數(shù)尋優(yōu)算法是可行的方案。
劉澤燊等[14]使用Spark實現(xiàn)了并行的SVM算法,李坤等[15]使用Spark集群建立了SVM參數(shù)并行尋優(yōu)模型,但是他們都忽略了集群Task分配、負載均衡等方面對參數(shù)尋優(yōu)效率的影響。為了更加合理地利用集群資源,同時使集群中的Executor達到負載均衡,本文對SVM算法最優(yōu)參數(shù)網(wǎng)格搜索的過程以及Spark并行計算引擎的特點進行了分析,調(diào)整優(yōu)化網(wǎng)格搜索算法的結(jié)構(gòu),使用Spark平臺實現(xiàn)具體的并行算法,并通過調(diào)節(jié)Task的并行度對Spark的Task分配進行優(yōu)化,使集群中各個Executor達到負載均衡,從而大幅度地減少尋優(yōu)時間。
1 概述
1.1 SVM算法
SVM算法是一種基于結(jié)構(gòu)風險最小化,建立在統(tǒng)計學理論上的有監(jiān)督機器學習算法,具有很好的泛化能力,在分類與回歸分析中有著廣泛的應(yīng)用,如人臉識別、文本分類、手寫字體識別等方面。
SVM算法的目的是求解最優(yōu)超平面,本質(zhì)上是一個凸二次規(guī)劃問題,假設(shè)訓練樣本集為,設(shè)超平面系數(shù)為w=(w0,w1,…,wn),截距為b,求解最優(yōu)超平面原問題描述如下:
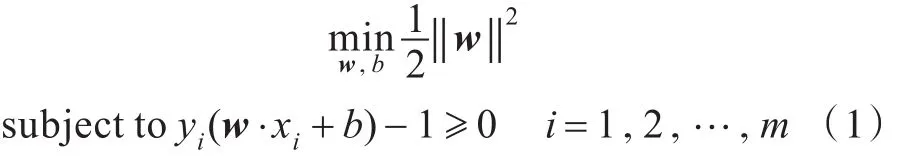
式(1)表示在滿足條件yi(w?xi+b)-1≥0的約束下,超平面系數(shù)向量w的模最小,從而使得超平面距離支持向量的物理間距最大。原問題不容易求解,可以通過原問題的對偶問題求解,引入拉格朗日算子并且對參數(shù)求偏導,進而求出與原問題對應(yīng)的對偶問題,具體對偶問題如下所示:
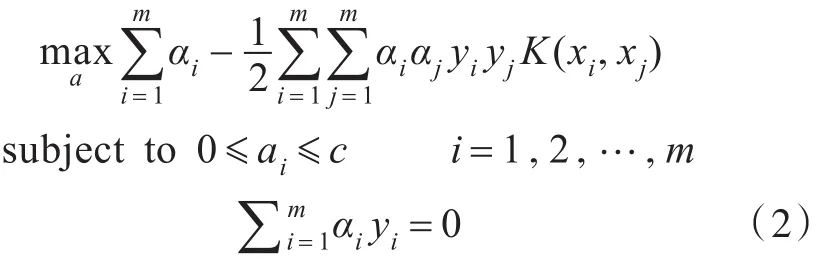
式(2)中m為支持向量的個數(shù),αi為支持向量對應(yīng)的拉格朗日算子,c為懲罰參數(shù),表示對分類錯誤樣本點的懲罰代價。
由式(2)可以看出,非邊界樣本點對應(yīng)的參數(shù)αi都是0,因此只有支持向量樣本點對問題的求解有用,懲罰參數(shù)c可以剔除樣本集中的一些噪聲點。
對于樣本集線性可分的情況,最優(yōu)超平面可以很容易求解出來;若樣本集線性不可分,此時需要引進核函數(shù),將低維空間線性不可分問題映射成高維空間線性可分的問題。SVM核函數(shù)主要有四種,分別為線性核函數(shù)(linear Kernel)、多項式核函數(shù)(polynomial kernel)、徑向基核函數(shù)(RBF kernel)、Sigmoid核函數(shù)(sigmoid kernel)。徑向基核函數(shù)也稱高斯核函數(shù),是比較常用的一種核函數(shù),公式為:H(x,x′)=exp(1-g‖x-x′‖2)。其中本文參數(shù)尋優(yōu)涉及的2個參數(shù)c、g,c代表式(2)中的懲罰參數(shù),g代表徑向基核函數(shù)中的參數(shù)g。
1.2 Spark
Apache spark是一種基于內(nèi)存計算的通用計算引擎,常用來處理大規(guī)模數(shù)據(jù)集。與Hadoop相同的是,Spark可以執(zhí)行Map、Reduce等操作,但Spark還包含了很多Hadoop不具備的算子,在數(shù)據(jù)處理方面要比Hadoop靈活很多。Spark的各種操作主要集中在內(nèi)存,但Hadoop在數(shù)據(jù)處理過程中需要頻繁讀寫HDFS,造成大量的磁盤I/O和通信開銷,所以在計算速度上,Spark要比Hadoop快很多。同時Spark與Hadoop完全兼容,Spark可以使用Hadoop集群上的HDFS做為分布式文件存儲系統(tǒng)。
Spark的核心部分是彈性分布式數(shù)據(jù)集(resilient distributed datasets,RDD),RDD是一個基于內(nèi)存具有容錯性的分區(qū)只讀記錄集合,通過RDD分區(qū)(partition)來決定集群中Worker的任務(wù)分配。RDD包含轉(zhuǎn)換(transformation)和動作(action)兩種算子,轉(zhuǎn)換,如map()、flatmap()、filter()等,它是將一種格式的RDD轉(zhuǎn)換為另外一種格式的RDD;而動作,如collect()、count()、take()等,它的功能則是得到具體的結(jié)果。其中轉(zhuǎn)換操作不會被立即執(zhí)行,只有遇到動作時,動作之前的轉(zhuǎn)換操作和動作才會被執(zhí)行。
Spark的運行模式有Local、Standalone和Yarn等模式,本文中采用的是Standalone模式,在Standalone模式下,Driver程序可以在Master節(jié)點運行也可以在本地的Client端運行,本文使用Eclipse向集群提交Application,所以Driver程序運行在Client端。
1.3 支持向量機軟件包
支持向量機軟件包(library for support vector machines,LIBSVM)是臺灣大學林智仁教授等開發(fā)的一個用于SVM快速建模程序包,它提供了大量的API給開發(fā)者進行調(diào)用,各個方法的參數(shù)設(shè)置非常靈活,目前很多SVM算法相關(guān)的研究都是基于LIBSVM的二次開發(fā)。
在SVM分類模型建立過程中,懲罰參數(shù)c和核函數(shù)參數(shù)g的選取直接影響模型分類的準確率。由于不能確定使模型分類準確率最高的參數(shù),為了獲得最優(yōu)的(c,g)參數(shù),通常使用LIBSVM自帶的網(wǎng)格搜索(grid search)算法進行參數(shù)尋優(yōu),網(wǎng)格搜索即通過窮舉將所有的參數(shù)組合進行交叉驗證(cross-validation),找出分類準確率最高的參數(shù)組合,是一個非常耗時的過程。
2 參數(shù)尋優(yōu)算法并行與優(yōu)化
2.1 算法并行化的思路
網(wǎng)格搜索過程中,因為每組(c,g)參數(shù)組合的交叉驗證過程相互獨立,所以可以通過Spark并行計算引擎將搜索過程并行化。利用RDD的MapReduce原理,將所有的參數(shù)組合存入RDD中,RDD觸發(fā)動作后被分解為很多邏輯相同的Task,這些Task會被分配到相同或者不同的Executor上并行執(zhí)行。算法將交叉驗證的過程放在RDD的Map階段,使交叉驗證在各個Task上并行執(zhí)行,等待所有Executor中的Task完成交叉驗證后,利用Reduce動作匯總所有結(jié)果并計算出最高準確率和參數(shù)組合。算法中使用LIBSVM包提供的交叉驗證方法對參數(shù)進行交叉驗證,由于原生LIBSVM交叉驗證算法的輸入輸出不能夠滿足實驗需求,所以實際算法對svm_train.java的訓練集讀取方式以及交叉驗證結(jié)果的輸出形式進行了改寫,使其能適應(yīng)并行網(wǎng)格搜索的輸入和輸出。交叉驗證的基本流程為:
1)將原始訓練集均勻劃分成k份的數(shù)據(jù)集;
2)選取其中1份數(shù)據(jù)集(未被作為測試集的數(shù)據(jù)集)作為測試集,其他的k-1份作為訓練集;
3)用訓練集訓練出模型,再用測試集去測試模型的準確率;
4)重復上述第二步和第三步,直到原始訓練集中所有的數(shù)據(jù)集都被作為測試集進行測試為止;
5)求出所有測試所得準確率的均值作為最終準確率。
上述步驟即為k折交叉驗證(k-fold cross-validation),本文所提到的交叉驗證都為k折交叉驗證,k折交叉驗證的過程中對訓練集中所有的數(shù)據(jù)都進行了測試,可以有效地避免過擬合和欠擬合問題。
2.2 廣播變量的使用
并行網(wǎng)格搜索前,將Driver端讀取的訓練集以廣播變量的形式廣播給各個Executor,每個Executor保存一份訓練集副本;如果Driver端讀取的訓練集以List形式保存共享,Executor的每個Task都會保存一份訓練集副本。
假設(shè)在1個Application中分配m個Executor,每個Executor中有n個Task在執(zhí)行,當訓練集使用廣播變量的形式進行廣播時,整個Application中總共保存m份訓練集副本;但當訓練集使用List形式在Driver端保存共享時,整個Application中總共保存m·n份訓練集副本,所以采用List形式保存共享訓練集會比廣播變量形式多產(chǎn)生m·n-m=(n-1)·m份訓練集副本。當訓練集較大、Task的數(shù)量較多時,重復保存的(n-1)·m份訓練集副本會占用大量的內(nèi)存,甚至會導致內(nèi)存溢出。
2.3 Task并行度與Executor負載均衡
在Spark集群中,根據(jù)Action的不同Application被劃分為不同的Job,Job中的每處寬依賴被劃分一個Stage,每個Stage中包含多個Task,Task是運行在Executor處理器內(nèi)核中,執(zhí)行Job的最小邏輯單元。并行網(wǎng)格搜索計算量最大,最耗時的交叉驗證階段是由Executor中的Task來完成的,為了讓Application中分配的所有Executor能夠發(fā)揮最大效能,本文通過在Map階段控制Task的并行度,讓每個Executor分配到的Task數(shù)目一致或者接近一致,盡可能的使Executor之間達到負載均衡,從而加快搜索的速度。Executor的Task分配情況如圖1的Map階段所示,圖1描述的為理想情況,所有Executor分配的Task數(shù)目一致,此時的尋優(yōu)速度較快。
為將Task并行度變?yōu)樽灾骺煽貐?shù),本文把Spark集群配置文件中的spark.default.parallelism參數(shù)提取出來并重寫覆蓋,將其定義為一個變量(Parallelism),算法中的通過控制Parallelism來控制并行Task的數(shù)量。并行可調(diào)的網(wǎng)格搜索算法主要流程如圖1所示,實現(xiàn)步驟如下:
1)輸入Application的Task并行度,c、g參數(shù)數(shù)目,交叉驗證折數(shù)。
2)根據(jù)c、g的數(shù)量和步長自動生成參數(shù)組合,并將其存入RDD中。
3)讀取訓練樣本,并將其轉(zhuǎn)換為廣播變量。
4)根據(jù)輸入的Task并行度以及存儲參數(shù)組合的RDD為每個Executor分配Task。
5)對存有c、g參數(shù)組合的RDD執(zhí)行mapToPair()轉(zhuǎn)換,并在轉(zhuǎn)換過程中對廣播變量中的訓練樣本進行交叉驗證,將參數(shù)組合和準確率以鍵值對的形式返回。
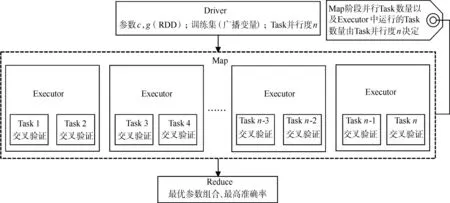
圖1 并行網(wǎng)格搜索過程Fig.1 Searching process of parallel grid
6)通過Reduce()動作計算出最優(yōu)參數(shù)組合以及準確率,Driver計算出尋優(yōu)總時間。
并行可調(diào)網(wǎng)格搜索算法的核心算法:
Input:TrainDatasetPath,Parallelism,CNum,GNum,K-Fold
Output:C,G,Accuracy,TotalTime
1.Application初始化,根據(jù)Parallelism設(shè)置Task并行度;
2.JavaSparkContext jsc=new JavaSparkContext(spark.sparkContext());
3.List<String> cgList=new ArrayList<String>();
4.for(int i=0;i<CNum;i++){for(int j=GNum;j> 0;j--){//生成c,g參數(shù)組合
5.String sparam=String.valueOf(初始值 +i*步長)+"-"+String.valueOf(初始值+
j*步長);cgList.add(sparam);}}
6.JavaRDD<String> lines=jsc.parallelize(cg-List);//RDD形式的c、g參數(shù)
7.調(diào)用ReadTrainFromHDFS算法
8.調(diào)用mapToPair算法
9.調(diào)用reduce算法
10.Driver計算出尋優(yōu)總時間TotalTime;
并行網(wǎng)格搜索前需要將HDFS中的訓練集讀取出來,并轉(zhuǎn)換為廣播變量,ReadTrainFromHDFS算法如下:
Input:fs-FileSystem對象,pt-訓練集HDFS路徑,jsc-JavaSparkContext對象
Output:broadcastssvRecords
1.Vector<String> svRecords= new Vector<String>();
2.if(fs!=null){BufferedReader br=new BufferedReader(new InputStreamReader(fs.open(pt)));
3.try{String line;while((line=br.readLine())!=null&&line.length()>1){
4.svRecords.addElement(line);}} finally {br.close();}}//將訓練集讀取為 Vector<String>格式
5. Broadcast<List<String>> broadcastssvRecords=jsc//將訓練集轉(zhuǎn)換為廣播變量
.broadcast(Arrays.asList(svRecords.toArray(new String[svRecords.size()])));
6.return broadcastssvRecords;
Map階段的并行Task的數(shù)量即并行交叉驗證的數(shù)量由Parallelism決定,mapToPair算法如下:
Input:s-String類型格式為“c-g”的參數(shù)組合,K-Fold
Output:Tuple2(s,acc)
1.String[]svr=(String[])broadcastssvRecords.value().toArray();//使用廣播變量
2.Double c=Double.valueOf(s.split("-")[0]);3.Double g=Double.valueOf(s.split("-")[1]);
4.MSSvmTrainer svmTrainer=new MSSvm-Trainer(svr,c,g,K-Fold);
5.String acc=svmTrainer.do_cross_validation();//交叉驗證
6.return new Tuple2(s,acc);//返回<參數(shù)組合,準確率>的鍵值對
Reduce階段主要處理Map階段產(chǎn)生的鍵值對,通過比較準確率大小,得出最優(yōu)參數(shù)組合,reduce算法如下:
Input:x,y
Output:返回x,y鍵值對中準確率高的鍵值對
1.if(Double.parseDouble(x._2().replace("%",""))>Double.parseDouble(y._2().replace("%",""))){
2.return x;}else{return y;}
3 實驗部分
3.1 實驗環(huán)境與數(shù)據(jù)
Spark集群的主要硬件環(huán)境為一臺戴爾R720服務(wù)器,服務(wù)器配置為兩顆E5-2620V2 6核12線程處理器,主頻2.1 GHz,最大睿頻2.6 GHz,32 GB內(nèi)存,8 TB硬盤,服務(wù)器被虛擬化為4個節(jié)點,一個Master節(jié)點4個Worker節(jié)點(Master節(jié)點也是Worker節(jié)點),每個節(jié)點有3個內(nèi)核,8 GB內(nèi)存,2 TB硬盤;集群使用的主要軟件有Spark2.1.1、Hadoop2.7.3、JDK1.8等,操作系統(tǒng)為 Ubuntu-16.04.1-Server-amd64。
實驗采用的是LIBSVM官網(wǎng)提供的a8a二分類數(shù)據(jù)集,該數(shù)據(jù)集大小為1.6 MB,包含22 696個樣本,每個樣本有123維特征。
3.2 實驗結(jié)果及性能分析
實驗選擇64組(c,g)參數(shù)組合作為測試對象,交叉驗證折數(shù)k為4,參數(shù)c、g各8組。參數(shù)c的初始值為0.5,遞增步長為0.25,搜索范圍為0.5~2.25;參數(shù)g的初始值為0.05,遞增步長為0.012 5,搜索范圍為0.05~0.137 5。實驗過程中為Application分配4個Executor,每個Executor 3個內(nèi)核,2 GB內(nèi)存。
在不設(shè)置并行Task數(shù)量與通常采用的最大并行Task數(shù)量的情況進行實驗,實驗結(jié)果如表1所示。

表1 兩種Task并行度實驗結(jié)果Tab.1 Experiment results of two parllelisms of tasks
從表1可以看出,不設(shè)置并行度的情況下只有2個Task并行執(zhí)行,設(shè)置最大并行度后,64個Task并行執(zhí)行,尋優(yōu)總時間極大地減少。從Spark Web UI上的Executors上查詢出,不設(shè)置并行度時集群中只啟動了2個Executor來執(zhí)行Task,顯然Application沒有使用本次分配的全部集群資源,有一部分資源處于閑置狀態(tài);而設(shè)置最大并行度后,集群使用了分配的全部資源,啟動了4個Executor來執(zhí)行Task。
為了比較集群并行Task的數(shù)量對尋優(yōu)效率和速度的影響,在實驗中設(shè)置核心算法中的Parallelism參數(shù)分別為 4、8、12、16、20、24進行參數(shù)尋優(yōu)的測試,實驗數(shù)據(jù)如表2所示。
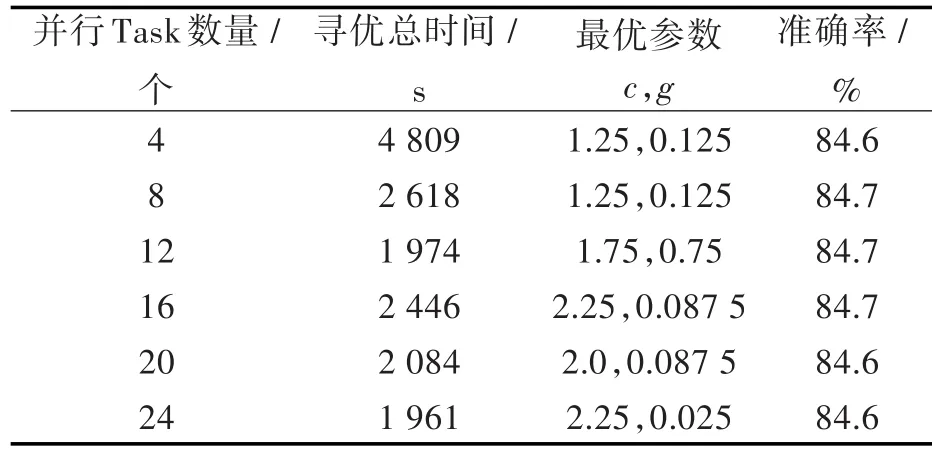
表2 不同Task并行度實驗結(jié)果Tab.2 Experimental results of different parallelisms of tasks
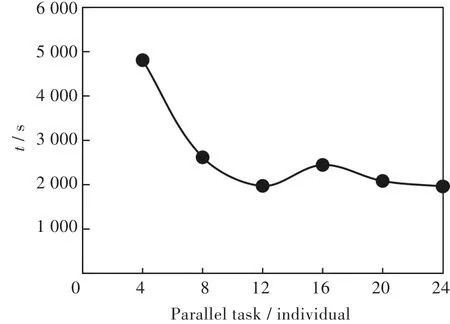
圖2 不同并行度尋優(yōu)總時間趨勢圖Fig.2 Trend diagram of total optimization time for different parallelisms
圖3 三種并行度尋優(yōu)總時間對比圖Fig.3 Comparison diagram of total optimization time for three parallelisms
從表2和圖2可以看出,Task的并行度并非設(shè)置越大越好,當并行的Task數(shù)量小于12時,訓練總時間隨著并行的Task數(shù)量的增加而降低;但當并行的Task數(shù)量超過12時,總訓練時間開始上升,在并行的Task數(shù)量為24時,總訓練時間接近Task并行數(shù)量為12時。在設(shè)置合理的并行Task數(shù)量后,參數(shù)尋優(yōu)的準確率基本不變(上下波動不超過0.1%),時間性能提升了(4 890-1 961)/1 961≈149%。從圖3可以看出,在并行的Task數(shù)量為24的時候,尋優(yōu)的時間性能相對在不設(shè)置并行度、并行度最大的情況下都有一定的提升,相對在不設(shè)并行度的情況下提升了(6 731-1 961)/1 961≈243%,相對在最大并行度的情況下提升了(2 544-1 961)/1 961≈30%。
為了進一步測試并行Task數(shù)量為12整數(shù)倍對尋優(yōu)總時間的影響,設(shè)置Parallelism參數(shù)為36再次進行測試,結(jié)果如表3所示,并行Task數(shù)量為12或12的整數(shù)倍的時候,總尋優(yōu)時間比較接近。
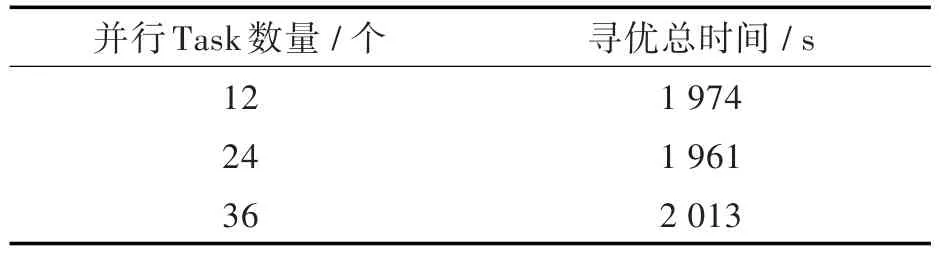
表3 并行度為12整數(shù)倍的實驗結(jié)果Tab.3 Experimental results of parallelisms in integer multiples of 12
從表1和表3以及圖2相關(guān)數(shù)據(jù)可以看出,Task并行度的設(shè)置對尋優(yōu)總時間有很大的影響,進一步分析Task并行度對Executor負載均衡的影響,在程序中設(shè)置標簽來統(tǒng)計每個Executor完成的Task數(shù)量,將相關(guān)數(shù)據(jù)在Logs輸出,統(tǒng)計數(shù)據(jù)如表4所示。
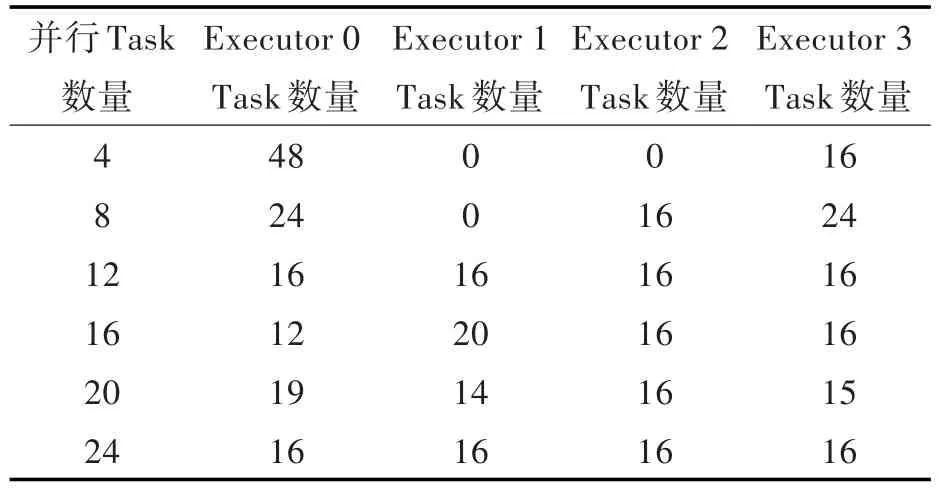
表4 不同并行度各Executor分配Task數(shù)量Tab.4 Numbers of tasks assigned to each executor under different parallelisms 個

圖4 不同并行度各Executor分配Task數(shù)量對比圖Fig.4 Comparison diagram of tasks assigned to each executor with different parallelisms
通過表4和圖2以及圖4可以看出,當Task數(shù)量是12或者12的整數(shù)倍的時候,各個Executor分配的Task數(shù)量相同,達到負載均衡,此時的尋優(yōu)總時間也是最短的;當Task數(shù)量不是12或者12的整數(shù)倍的時候,各個Executor分配的Task數(shù)量不一致,分配Task數(shù)量較多的Executor的交叉驗證的總時間會相對較長,分配Task數(shù)量較少的Executor在完成交叉驗證Task后會等待分配Task較多的Executor,直到所有Executor完成交叉驗證Task,網(wǎng)格搜索結(jié)束,所以網(wǎng)格搜索的總時間是由交叉驗證總用時最長的那個Executor決定的。默認情況下,Executor的一個內(nèi)核在同一時間只處理一個Task,所以設(shè)置并行Task的數(shù)量為Application的Executor內(nèi)核總數(shù)或總數(shù)的整數(shù)倍可以使各個Executor分配到的Task數(shù)目相等,達到負載均衡,從而使并行網(wǎng)格搜索的速度達到最快。
4 結(jié) 語
SVM大數(shù)據(jù)集參數(shù)尋優(yōu)的計算量相當大,用傳統(tǒng)的單機參數(shù)尋優(yōu)算法來處理大數(shù)據(jù)集顯然不現(xiàn)實。本文提出了一種基于Spark通用計算引擎的并行可調(diào)SVM參數(shù)尋優(yōu)算法,通過分析算法在Task不同并行度下的尋優(yōu)時間,發(fā)現(xiàn)并非Task并行度設(shè)置的越大尋優(yōu)速度越快,需要根據(jù)Application分配的集群資源,調(diào)整Task的并行度(設(shè)Application的Executor內(nèi)核數(shù)量為m,Executor數(shù)量為n,則Task最優(yōu)并行度為m·n或m·n的整數(shù)倍),使各個Executor達到負載均衡,從而顯著提高尋優(yōu)速度。從集群的角度來看,在Application中每個Task耗時相差不大的情況下,Task分配的越均勻,Application的總耗時越少,當Task完全均勻分配時,即負載均衡的時候,Application總耗時最少。
參數(shù)尋優(yōu)過程中集群內(nèi)存資源的消耗優(yōu)化是今后研究的重點之一,通過動態(tài)評估內(nèi)存消耗,給Executor設(shè)置合理的內(nèi)存,在不降低尋優(yōu)速度的前提下,消耗盡可能少的內(nèi)存資源完成SVM參數(shù)尋優(yōu)算法。
