基于AP-SVM組合模型的股票價格預測
2019-07-23 01:24:16胡迪,黃巍*
武漢工程大學學報 2019年3期
胡 迪 ,黃 巍*
1.武漢工程大學計算機科學與工程學院,湖北 武漢 430205;
2.智能機器人湖北省重點實驗室(武漢工程大學),湖北 武漢 430205
股票漲跌趨勢預測是利用歷史的股票數據信息對未來的股票走勢方向做出預測。股票價格受政治,經濟和人為操作等許多因素影響,股票的漲跌是這些因素的綜合表現。對于投資者來說要考慮這些因素,需要花費大量的人力和物力來收集這些信息,在股票數據信息爆炸式增長的時代,這種做法是不可取的。因此在股票數據上直接進行預測分析,既能避免繁雜的數據獲取過程,又能避免大量的冗余信息的干擾。目前,股票預測的方法有很多種,大致可以分為三類:人為經驗法,統計學方法和人工智能方法。隨著人工智能技術在計算機視覺和自然語言處理領域的表現越來越出色,在時序預測方面相比于人為經驗法和統計學方法有更大的優勢。
股票漲跌預測是金融領域經久不衰的研究課題,由于人為經驗法和統計學方法等傳統方法在股票漲跌預測中的效果并不理想,國內外研究者開始探索新的股票預測方法,為了能夠準確預測股票漲跌的變化趨勢,學者們進行了大量的分析和驗證,探索出了越來越多的預測方法和模型。
彭麗芳等[1]提出一種基于時間序列的SVM股票預測方法,建立股票收盤價回歸預測模型,克服了傳統時間序列預測模型僅局限于線性系統的情況,提高了預測準確率。金桃等[2]提出采用基于支持向量機(support vector machine,SVM)的多變量股市時間序列預測算法來提高預測準確率,實驗證明相較于單變量的SVM回歸預測有更好的泛化能力。程昌品等[3]提出二進制正交小波變換和自回歸平均移動-支持向量機(autoregressive integrate moving average supportvectormachine,ARIMA-SVM)方法,使用小波分解[4]算法對數據進行分解,分離出非平穩時間序列中的低頻和高頻信息,然后對高頻信息構建自回歸平均移動模型(autoregressive integrate moving average,ARIMA)預測,對低頻信息用SVM模型進行擬合,最后將各模型的預測結果進行疊加。實驗表明,小波分解ARIMA-SVM的組合模型較單一的預測模型效果更高。黃同愿等[5]通過選擇最優的徑向基核函數,再利用網格尋參[6],遺傳算法[7]和粒子群算法[8]對最佳核函數參數進行對比尋優,構建的SVM模型能夠準確的預測股票反轉點。張貴生等[9]提出近鄰互信息特征選擇的支持向量機-廣義自回歸條件異方差模型(svm support machine-generalized autoregressive conditional heteroskedasticity,SVM-GARCH),通過近鄰互信息的方式融合了與目標指數數據關系密切的周邊證券市場的相關變化信息,仿真結果表明在時序數據除噪,趨勢判別以及預測的精確度等方面均優于傳統的自回歸平均移動-廣義自回歸條件異方差模型(autoregressive integrate moving average-generalized autoregressive conditional heteroskedasti,ARIMA-GARCH)。李輝等[10]提出一種兩層特征選取及預測的方法,即特征子集區分度衡量準則-二進制粒子群-支持向量機(discernibility of feature subsets-binary particle swarm optimization-supportvectormachine,DFS-BPSO-SVM),第一層特征選取高效剔除部分非預測相關特征,縮減了特征規模,第二層選擇出最優特征組合,提升了預測準確率。張偉等[11]提出將SVM和遺傳和支持向量機組合算法(genetic algorithm-support vector machine,GA-SVM),預測未來股票市場的走勢,實驗證明GA-SVM優于其他方法。胡蓉[12]提出多輸出的SVM回歸模型,預測股票的最高價和最低價,與單輸出相比有更好的整體預測精度和抗噪性能。
曾岫等[13]針對K線圖是一個分形圖,把其分維數作為聚類參數對股票進行聚類實證研究,研究結果表明,同一類的股票有著極強的相似走勢。柯冰等[14]利用9項財務指標,對19家上市公司進行聚類分析,能把上市公司分為4個不同的類,與公司的實際情況相符。由此可見,聚類能將相同走勢的股票歸類在一起。吳薇等[15]利用反向傳播神經網絡(back propagation,BP)網絡[16]有較好的分類能力,對滬市綜合指數漲跌進行預測,實驗結果表明BP網絡對中國股票市場的預測是可行的和有效的。
過去的研究一般考慮對單支或少數股票進行實證分析,忽略了股票與股票之間相關性,這種相關性的股票之間往往會有相同的變化趨勢。本文提出了基于SVM的聚類股票預測算法近鄰傳播聚類和支持向量機組合算法(affinity propagationsupport vector machine,AP-SVM),首先用近鄰傳播算法(affinity propagation,AP)對股票進行聚類,然后將簇內股票按時間索引構建成矩陣簇,最后利用SVM,BP,AP-SVM和近鄰傳播和反向傳播組合算法(affinity propagation-back propagation,AP-BP)對太平洋證券進行漲跌預測,對比分析4種算法在不同時間間隔上的預測表現,同時進一步討論簇內股票數目對于預測結果的影響。
1 AP-SVM模型
A股股票常用特征有7個,即日期、最高價、最低價、開盤價、收盤價、成交量和成交額。首先對除時間以外的其余6個特征做相關性分析,計算各個特征之間的相關系數,選擇相關性較弱的特征作為模型的輸入,由于這些特征之間的差異性較大,需要先對其進行最大最小歸一化處理,然后對收盤價做二范數歸一化[17]處理,將處理好的數據進行聚類分析,最后利用不同算法進行訓練,預測聚簇股票的漲跌。
1.1 特征選擇
由于股票數據中的特征存在相關性,會造成數據冗余,對預測結果產生影響,需要對股票特征之間進行相關性分析,挑選出能夠有效代表完整股票數據的特征子集。使用相關系數來描述各個特征之間的相關性,相關系數的取值在[-1,1]之間,-1表示完全負相關,1表示完全正相關,0表示不相關。相關系數n的定義如下:

其中μi和μj分別是特征vi和特征vj的均值,E和D分別表示計算期望和方差。
中信證券(股票代碼為600030)各特征之間的相關系數如圖1所示。由圖1可知,開盤價、收盤價、最高價和最低價之間的相關系數接近1,表示這些特征之間相關性很強,成交量和成交額之間也是相關性很強,而開盤價、收盤價、最高價、最低價與成交量、成交額之間相關性較小。因此只需要2個輸入特征就夠了,由于漲跌預測需要用到收盤價的差值來計算,根據圖1的第二行,收盤價與成交量的相關系數最小,所以選取成交量當做是股票的第二個輸入特征。

圖1 中信證券特征之間的相關系數Fig.1 Correlation coefficient diagram between CITIC securities features
由于股票的收盤價和成交量在數量級上相差較大,對2個特征進行最大最小歸一化處理(規范化到[0,1]區間),以減少訓練過程中計算的復雜度和預測準確率。歸一化的公式如下:

其中,xmax和xmin分別為樣本中特征的最大值和最小值,x′i為歸一化后的數據。
1.2 聚類相似度度量
相同走勢的股票之間往往有較高的相似性,可以利用股票價格間的相似性提高股票價格預測的準確性。
聚類操作可以挑選出與待預測股票價格走勢相近的股票。首先對每支股票的收盤價進行二范數歸一化,假設某支股票包含N天的收盤價格,則這支股票的收盤價格可記為x=(x1,x2,…,xN),其二范數歸一化定義如下:

式(3)中,xi表示這支股票第i天的收盤價表示這支股票第i天的歸一化收盤價。二范數歸一化如圖2所示。

圖2 收盤價的二范數歸一化Fig.2 Normalization of two norms of closing price
在圖2中,x,y表示2支不同股票在同一個交易日的原始收盤價,x*,y*表示x,y歸一化后股票的收盤價。從圖2中可以看出,二范數歸一化后,所有股票的收盤價格向量落到一個球面上,因而可以使用2支股票收盤價向量x和y的夾角余弦刻畫它們的相似程度。
由向量內積定義可知,2支股票價格向量x和y的夾角余弦定義如下:對于二范數歸一化后的股票價格向量x*和

y*,有||x*||2=||y*||2=1,帶入到式(4)中,可得:
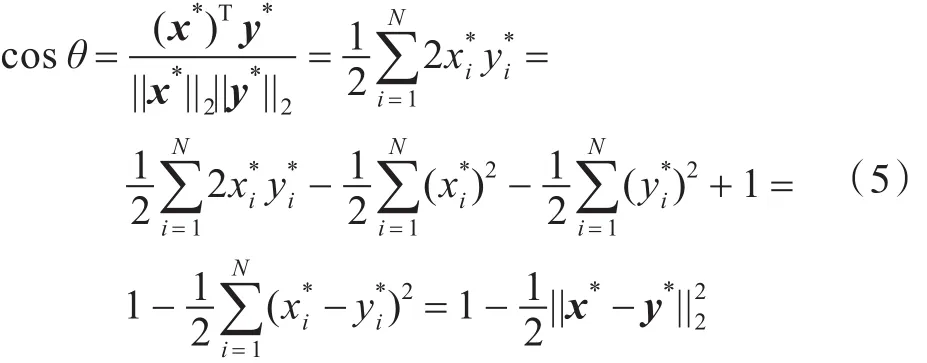
去掉式(5)中的平移因子1和比例因子1/2,對于二范數歸一化后的價格向量,可以使用負歐幾里德距離-||x*-y*||2作為價格向量的相似性度量函數。
1.3SVM
目前,有許多股票預測的研究方法,如遺傳算法、決策樹、馬爾科夫鏈[18]等,這些方法在股票這種非線性、高噪聲、波動性較強的數據中,不能很好的預測股票的漲跌,而SVM能利用核函數,通過非線性映射將股票數據映射到一個更高維的空間,利用線性函數對股票的漲跌進行分類。
對于股票數據集 (xi,yi),i=1,2,…,m,其中m是樣本個數,xi∈Rn,yi∈{-1,1},n表示樣本的特征數。
對于單支股票而言,yi表示股票的漲跌,-1表示股票下跌,1表示股票上漲。為了驗證AP-SVM算法對于單支股票的預測有影響,簇的標簽與單支股票的標簽一致。

對于線性可分的點,SVM可以通過選擇最佳超平面來分類數據。

如果存在滿足方程式(7)的超平面,通過求解以下的優化問題,就能夠找到最佳的線性分離超平面。
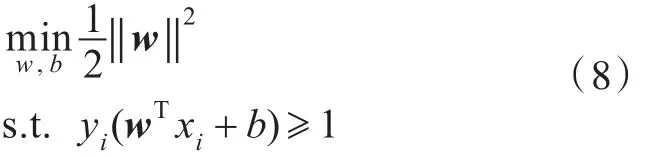
引入拉格朗日乘子αi,用條件極值求解最優分界面,構造拉格朗日函數。

利用對偶求解可得:

直接求解式(10)很難,不能做到100%線性可分,可以通過引入松弛變量ε,允許有股票預測處于分類錯誤的一側。

εi是松弛變量,常數C是懲罰系數。如果股票數據點分類錯誤,劃分到其他類,C越大表示越不想放棄這個點,邊界就會縮小,錯分點會更少,但是過擬合情況會更加嚴重。

分類決策函數

1.4 AP-SVM算法模型
利用AP算法將具有相同變化規律的股票歸為一個簇,簇內股票大多處于相同行業,這些股票之間相關性很強,股票與股票的數據之間產生影響,將簇內股票數據結合在一起構建新的矩陣簇,相比于單支股票擁有更多的信息量,以便于更好地預測股票價格漲跌趨勢,矩陣簇擁有行業信息的同時,數據維度也極大的增加了,而SVM能夠有效處理股票這種高維非線性數據,從而提出AP-SVM算法,分類流程如下:
輸入:A股股票數據
輸出:股票漲跌分類
1)選取中信證券股票,利用式(1)對股票特征做相關性分析,選取相關性較小的2個特征作為模型的輸入特征。并用式(2)對輸入特征做最大最小歸一化處理。
2)獲取A股10年內停牌較少的股票數據,根據式(3)對其收盤價做二范數規范化,將處理好的數據構建成一個新的矩陣,根據式(4)和(5)利用AP算法對其進行聚類分析。
3)根據式(6)對簇和簇內股票進行樣本標簽制作。
4)將特征輸入到SVM中,利用網格搜索尋找最優的C和gamma,通過式(7)~式(13),求解出 w*和b*,可以計算出分類決策函數。
如果分類結果與真實結果一致,則表示分類正確,統計分類正確樣本占樣本總數的比例,就能得到股票的預測準確率。
2 結果與討論
從聚寬網站上獲取A股2008-09-10至2018-09-10這10年間所有股票的日數據信息,包括時間、開盤價、最高價、最低價、收盤價、成交量、成交額。剔除數據嚴重缺省、退市、股票數據長時間不變的股票,最后所剩的1 561支股票作為本次實驗的研究對象。
2.1 聚類結果分析
將這些股票的收盤價通過時間索引,構建成一個1 561×2 433的矩陣,通過二范式的預處理對收盤價進行處理,將股票數據規范化到一個單位的圓內,避免了不同股票價格間差異過大,而對預測結果產生的影響,然后利用AP算法對新矩陣內的股票數據進行聚類分析,將有相同變化趨勢的股票劃分到同一個簇中。
使用AP算法聚類的部分股票結果如下:
聚簇1:華銀電力,上海電力,華電能源,東方能源
聚簇2:海通證券,中信證券,東北證券,西南證券
聚簇3;新鋼股份,鞍鋼股份,馬鋼股份,山東鋼鐵
聚簇4:北京銀行,浦發銀行,交通銀行,中信銀行
從聚類分類結果來看,大部分簇是按照行業來劃分的,簇內股票根據行業的發展而有相對應的波動,這與通常的認識一致。
選取證券行業內股票,統計其漲跌天數和行業內股票漲跌差值,圖3中的橫坐標表示漲跌差值,即一天內簇內股票上漲的股票數與下跌股票數的差值,若上漲股票數為5,下跌股票數為4,則漲跌差值記為1,縱坐標表示10 a內這些股票漲跌差值所出現的天數,結果如圖3所示。
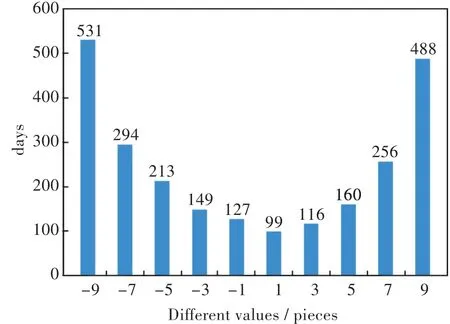
圖3 證券行業內股票漲跌天數差Fig.3 Days of stock prices in up and down movement in security industry
由圖3可以看出,證券行業股票成一個V字型,即2端的數值最大,向中間位置逐漸減少,中間位置的數值最小。圖3中的[-1,127]表示證券行業有127 d下跌的股票數比上漲的股票數多1支,[1,99]表示有99 d上漲的股票數比下跌的股票數多1支。證券行業內的股票全漲的天數為488 d,占總交易天數的20%,全跌的天數為531,占總交易天數的21.8%,同漲同跌的天數為1 019 d,占總交易天數的41.8%,超過總交易天數的40%,有1支股票表現和其他股票漲跌不一致的天數為550 d,占總交易天數的22.6%,有2支股票表現和其他股票漲跌不一致的天數為373 d,占總交易天數的15.3%。證券行業內的股票有79.7%的天數有著大致相同的漲跌,可以認為在大的方向上,相同行業內的大部分股票漲跌是相同的。
2.2 AP-SVM預測結果討論
根據AP算法聚類得到證券行業股票,實驗數據為在2008-09-10至2018-09-10期間證券行業的9支股票,每一支有2 433天的交易數據,將其前90%當做訓練集,用于訓練模型的參數,后10%為測試數據,選擇股票前k個交易日的收盤價和成交量作為模型的自變量,模型的因變量是第(k+1)個交易日的漲跌,將證券行業內所有股票的特征當作是簇的特征,構建成一個擁有18個特征的矩陣簇。
以往的研究中證實了不同核函數對預測結果有不同的影響,最常用的高斯核函數在大多數情況下都有不錯的表現效果,因此本文將在以往的研究基礎上,引入高斯核函數,利用網格搜索算法對高斯核函數的參數g和懲罰因子C進行參數尋優。根據SVM基本原理,構建SVM模型對矩陣簇和簇內股票進行實驗預測。
本文選擇了 SVM,BP[19],AP-SVM 和 AP-BP算法進行了對比實驗,在5 d,10 d,15 d,20 d 4種時間間隔的數據進行預測,刪除其中停牌日期的數據,對太平洋證券的預測結果如表1所示。

表1 不同時間間隔下四種模型的預測準確率對比表Tab.1 Comparison of prediction accuracy of four models at different time intervals
對比AP-SVM和SVM的預測結果,當時間步長為5 d、10 d和15 d時,AP-SVM的預測準確率要好于SVM,說明聚簇的股票相互作用,會對簇內單支股票的預測準確率有提升作用,當步長慢慢增加,AP-SVM相比單支股票擁有更多行業相關數據,預測準確慢慢變大,但是隨著步長繼續變大,AP-SVM的輸入維度變得很大,樣本數據很少,導致準確率慢慢變小。
對比AP-BP和BP的預測結果,當時間步長為10 d、15 d、20 d時,AP-BP的預測效果要好于BP神經網絡,說明通過AP聚類和BP神經網絡結合,也會提升股票的預測效果。
對比AP-SVM和AP-BP的預測結果,當時間步長為5 d、10 d和15 d時,AP-SVM的預測效果是最好的;當時間步長為20 d時,AP-BP的預測效果要好于AP-SVM。綜上所述,當時間間隔取較短時,通過AP聚類和其他算法結合的預測效果會優于單獨算法進行預測。
根據AP聚類在一起的股票,大部分是屬于同一個行業的,而這些行業之間的股票有著相似的波動,股票數據之間相互作用提供了單支股票所缺乏的行業信息,從而提升了預測準確率。為了進一步確定簇內多少股票對于預測有作用,利用收盤價計算每兩支股票之間相似度,假設2支股票的收盤價矢量表示為X={x1,x2,…,xN}和Y={y1,y2,…,yN},則X和Y的相似性度量如下:

利用式(14)計算以收盤價聚類的證券簇內股票之間的相似度,兩支股票越相似,它們之間的余弦值越接近1,如圖4所示。

圖4 證券行業內股票的相似度關系圖Fig.4 Similarity relation schema of stocks in security industry
由圖4可知,與太平洋證券走勢相似的股票依次是長江證券、東北證券、國金證券、西南證券、吉林敖東、中信證券、國元證券和海通證券。根據與太平洋證券相關性的強弱,依次選取1~9支股票構建AP-SVM算法對太平洋證券進行漲跌預測,選用時間步長為10進行預測的實驗結果如圖5所示。

圖5 不同股票數目的預測準確率對比圖Fig.5 Comparison diagram of prediction accuracy for different stock numbers
由圖5可知,當選用2支與太平洋證券走勢相近的股票時,就能達到用整個簇進行預測的結果,因此可以用簇內的3支股票來預測太平洋證券在不同時間間隔上的表現,預測結果如表2所示。

表2 不同時間間隔下兩個不同股票數模型的預測準確率對比表Tab.2 Comparison of prediction accuracy of two stock number models at different time intervals
由表2可知,當時間間隔取10 d和15 d時,選擇簇內3支股票和簇內所有股票的預測結果是一樣的,說明只要選擇用3支走勢相近的股票代替整個簇進行漲跌趨勢預測,能夠減少計算量,縮短計算時間。
3 結 語
本文提出了AP-SVM模型對A股2008~2018年間的股票進行漲跌預測,通過AP算法對A股股票進行聚類,發現聚類在一起的股票是按行業劃分的,簇內的股票基本上遵循著同漲同跌的變化規律。通過相關性分析,篩選出相關性小的2個特征,將簇內股票按時間索引構建矩陣簇,對比SVM、BP、AP-SVM和AP-BP在不同時間間隔上對太平洋證券進行預測,結果表明隨著時間間隔增大,AP-SVM的預測效果要優于其他3種算法,當時間間隔取最大時,由于AP-SVM的維度變得很大,導致最后的預測結果反而變差。進一步分析簇內股票數目對預測結果的影響,發現在時間間隔取10 d和15 d時,走勢最相似的3支股票的預測效果跟整個簇的預測準確率是相同的,可以代替用整個簇預測。
驗證了AP算法和其他算法結合,相比單獨使用SVM和BP算法,對于股票的準確率預測有提升效果。本文只用同一個簇內有很強相關性的股票進行實驗,而不同簇之間也有相關性,挖掘出不同行業漲跌的先后規律,結合深度學習算法是今后的研究方向。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
數學小靈通·3-4年級(2024年2期)2024-05-15 02:02:28
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
世界科學技術-中醫藥現代化(2020年2期)2020-07-25 02:05:36
數學物理學報(2020年2期)2020-06-02 11:29:24
瘋狂英語·新策略(2019年10期)2019-12-13 08:43:28
當代陜西(2019年10期)2019-06-03 10:12:04
數學小靈通·3-4年級(2017年9期)2017-10-13 08:10:54
光學精密工程(2016年6期)2016-11-07 09:07:19
核科學與工程(2015年4期)2015-09-26 11:59:03
