多特征融合的中文實體關系抽取研究
2019-07-29 00:41:36孫康康
無線互聯科技 2019年9期
孫康康
摘? ?要:詞性等特征在句子中扮演著重要的角色,往往能揭示命名實體之間的關系,而當前的實體關系抽取任務大多僅基于詞向量進行,忽視了詞性等對實體關系抽取任務有益的特征。因此,文章采用了一種多特征融合的方式進行中文實體關系抽取模型的訓練,在以詞向量作為輸入單元的前提下融合了句子中詞語的詞性、距離實體對的位置、實體標注相關特征,并以雙向長短期記憶網絡結合注意力機制的模型進行了中文實體關系抽取的實驗,實驗結果表明,基于多特征融合的訓練方式提升了中文實體關系抽取的效果。
關鍵詞:實體關系抽取;多特征;雙向長短期記憶網絡;注意力機制
實體關系抽取(Entity Relation Extraction,ERE)的主要任務是識別并抽取實體對間存在的語義關系,本文進行的實體關系抽取工作是為了從文本數據中提取實體間的語義關系作為知識表示的一部分。當前國內外主流的實體關系抽取大多采用機器學習的方法,根據其對標注語料庫規模的不同需求,分為有監督學習、弱監督學習和無監督學習等方法[1]。弱監督方法中常以遠程監督的方式進行實體關系抽取,是在基于現有知識庫中存在領域知識的前提下進行的,而現有知識庫并不能完全涵蓋某些領域的實體關系。此外,基于無監督的實體關系抽取技術目前識別效率較低,難以投入實際應用。
為此,本文采用了基于有監督學習方法的BiLSTM-Attention模型,并以人物關系抽取為例進行實體關系抽取的實驗,其中,針對模型注意力不足的問題,提出了一種多特征融合的改進措施。此外,在實驗之初,本文定義了5種人物之間的關系,分別為祖孫、父母、兄弟姐妹、好友和上下級。
1? ? 數據預處理
本文采用了中國科學院軟件研究所的劉煥勇[2]及Guan[3]在Github上發布的人物關系語料庫,將訓練語料的處理主要分為兩部分。
(1)采用分詞工具,通過哈爾濱工業大學語言技術平臺(Language Technology Platform,LTP)對訓練語料進行分詞處理,為了保證分詞的準確性,將語料庫中的實體添加到分詞工具的字典中,并采用word2vec對分詞后的語料數據進行分布式詞向量的訓練,訓練模型采用Skip-Gram,詞向量的維度為100維。
(2)采用神經語言程序學(Neuro-Linguistic Programming,NLP)工具(哈工大LTP)對訓練語料進行詞性標注,獲得語料庫中各語句的詞性標注序列;計算語料庫中各詞與實體對的相對位置,生成各語句的位置標簽序列;將語料庫中的實體進行標注,獲得各語句的實體標簽序列。分別對以上序列進行Word embedding操作,由于以上序列的相關特征較少,因此,采用隨機初始化的方式,序列維度均為10,其中,相對位置標注序列可以分為距離實體1和實體2的相對位置,在此分別對其進行向量隨機初始化。
2? ? 多特征融合
使用詞性標注工具對句子中的詞語進行詞性分析,獲得該句子對應的詞性標注序列;對句子中各詞距離實體對的相對位置進行標注,以及對實體的標注,獲得該句子的位置標注序列和實體標注序列。將以上標注序列分別采用隨機初始化向量的操作得到各序列的向量化表示,然后與句子中各詞的向量表示進行拼接,通過融合句子的詞性特征、位置特征及命名實體特征,增強句子中對關系抽取的有益成分,具體做法如下。
以分詞后的語句“母親 章含之 是 對洪晃 影響 最大 的 一個人 。”為例,該語句中命名實體為“章含之”和“洪晃”,其中語句中各詞對應的詞性標注序列POS為:
語句中各詞距離實體1和實體2的相對位置標注序列RP1和RP2分別為:
語句中各詞對應的實體標注序列NER為:
語句各詞對應的分布式向量Wi表示如下:
最終經融合后語句中各詞的向量表示為:
3? ? 實驗結果及分析
本文采用了BiLSTM-Attention模型對人物關系進行抽取。首先,進行參數調優實驗,分別選擇對模型性能有影響的batch_size、優化器、隱藏層節點數及學習速率進行實驗。經過參數調優,最終確定的模型參數為batch_size:32,優化器Adam,隱藏層節點數200,學習速率0.001。
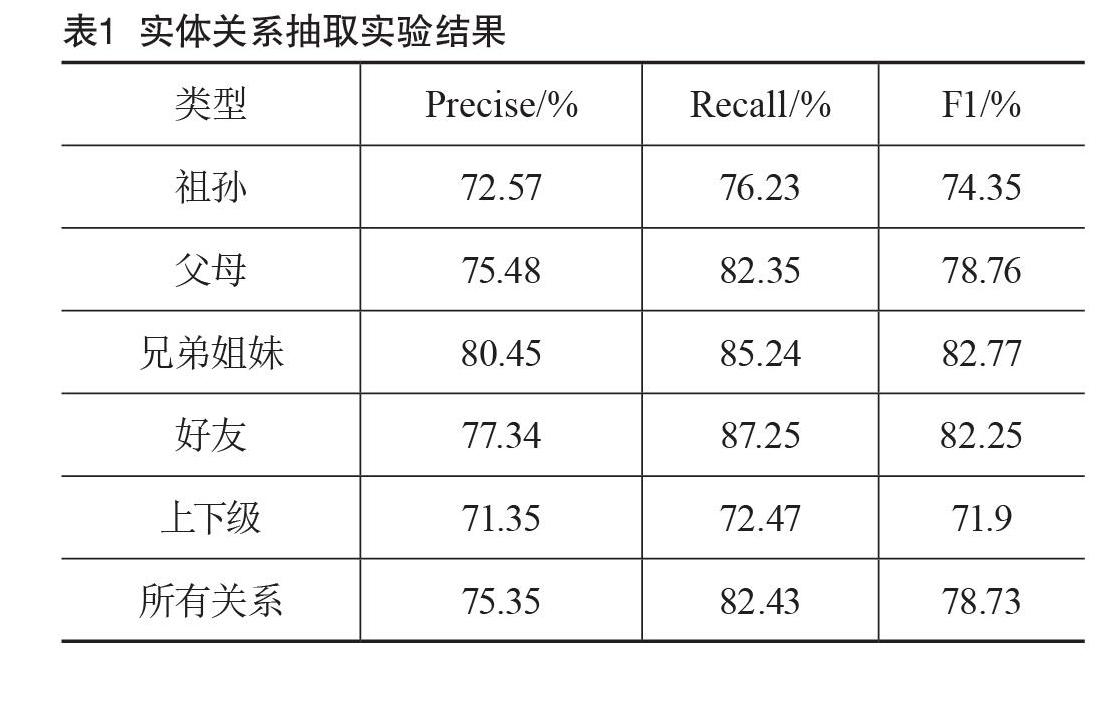
通過對參數的選擇實驗,模型最終在測試集上取得了78.5%的F1值,實驗結果如表1所示。
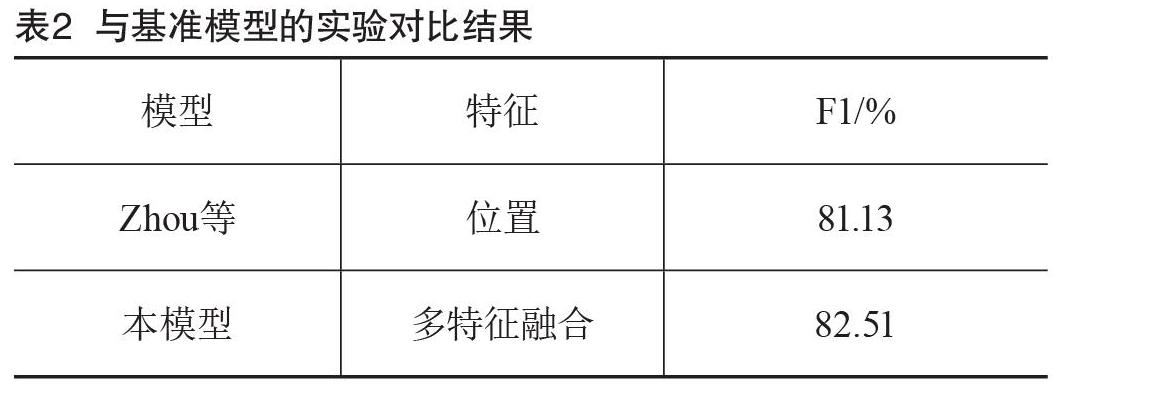
為了驗證多特征融合的有效性,本文選擇與2016年Zhou等[4]提出的基準模型進行對比,對比結果如表2所示。該文同樣采用了雙向長短期記憶網絡(Long Short-Term Memory,LSTM)結合注意力機制的模型進行實體關系抽取,但并未采用任何詞性及實體標注的信息,在采用與該論文相同數據集的情況下,本模型的F1值比其高出1.38%。
4? ? 結語
本文選擇了BiLSTM-Attention模型對人物關系進行抽取,針對BiLSTM-Attention模型中注意力層不足的問題,提出了多特征融合的改進措施,并針對改進措施進行了模型對比分析,驗證了多特征融合的有效性。
[參考文獻]
[1]胡亞楠,舒佳根,錢龍華,等.基于機器翻譯的跨語言關系抽取[J].中文信息學報,2013(5):191-197.
[2]LIU H Y.Person relation knowledge graph[EB/OL].(2018-12-15)[2019-05-13].https//github.com/liuhuanyong/person relation knowledge graph.
[3]GUAN W.Small-Chinese-Corpus[EB/OL].(2017-09-13)[2019-05-13].https//github.com/crownpku/Small-Chinese-Corpus/tree/master/relation_multiple_chi.
[4]ZHOU P,SHI W,TIAN J,et al.Attention-based bidirectional long short-term memory networks for relation classification[C].Shanghai:Meeting of the Association for Computational Linguistics,2016.
Abstract:Features such as part of speech play an important role in sentences, and often reveal the relationship between named entities. The current task of extracting entity relationships is mostly based on word vectors, ignoring the characteristics of part-of-speech and other useful tasks for extracting entities. Therefore, this paper adopts a multi-feature fusion method to train Chinese entity relationship extraction model. Under the premise of word vector as input unit, the word part of the sentence, the position of the distance entity pair and the entity labeling related feature are combined. The experiment of Chinese entity relationship extraction is carried out by using the bi-long short-term memory network combined with the attention mechanism model. The experimental results show that the training method based on multi-feature fusion improves the effect of Chinese entity relationship extraction.
Key words:entity relationship extraction; multi-feature; bi-long short-term memory network; attention mechanism
