中小尺度流域洪水模型模擬比較研究
2019-07-30 10:04:10宋曉猛張建云王國慶
中國農村水利水電 2019年7期
關鍵詞:模型
王 婕,宋曉猛,張建云,王國慶,劉 晶
(1.中國礦業大學 資源與地球科學學院,江蘇 徐州 221116;2.南京水利科學研究院 水文水資源與水利工程科學國家重點實驗室,南京 210029;3.水利部應對氣候變化研究中心,南京 210029)
0 引 言
在氣候變化日益復雜的今天,洪澇災害發生的頻率和強度也在不斷增大[1,2]。作為一項有效的防洪非工程措施,洪水預報在防汛工作中發揮著巨大的作用,因此,洪水預報技術的不斷提高顯得愈發重要。在現代洪水預報調度中,關鍵部分就是流域水文模型的應用,各類水文模型在水循環模擬中考慮的側重點不同,造成了模擬結果間的差異[3-7]。國內學者比較了不同模型間結果的差異,如劉佩瑤等[8]應用新安江模型和改進后的神經網絡模型在閩江進行水文預報,發現基于LM算法的網絡模型模擬效果明顯優于新安江模型;張漢辰等[9]對比了CASC2D與新安江模型的應用結果,發現在前毛莊流域效果相近,在前板橋流域新安江模型效果略優;王思媛等[10]比較了HBV模型和新安江模型在黃河源區的應用,發現GA算法率定下的新安江模型模擬效果優于HBV模型。此外,宋曉猛[11]、闞光遠[12]等則將新安江模型和人工神經網絡模型進行耦合應用,模型模擬效果均獲得改善。目前研究大多集中在同類模型的比較,對不同類型模型的比較相對欠缺。
本文利用新安江模型(集總式模型)、TOPMODEL模型(半分布式水文模型)、人工神經網絡模型(數據驅動模型)3種不同類型模型的基本原理及結構,以沿渡河流域為例,進行次洪過程模擬和對比研究,分析比較各模型模擬結果的優劣及地區適用性,為洪水預報方案的完善與選擇提供前期的模型數據支持。
1 資料與方法
1.1 流域概況
沿渡河流域位于長江上游支流(110°05′E~110°30′E,31°10′N~31°30′N),流域面積601 km2。流域內多山地,植被茂密,屬典型的季風氣候,年均氣溫在11.5 ℃左右,年均降水量為1 650 mm左右,汛期為每年5-9月。流域內分布有5個雨量站,沿渡河流域水系及測站分布圖如圖1所示。
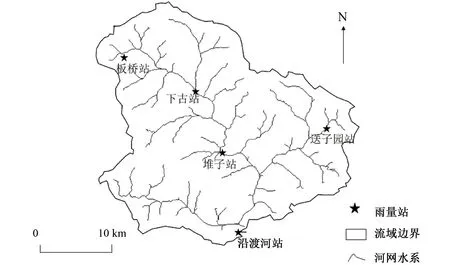
圖1 沿渡河流域水系及測站分布Fig.1 Drainage networks and observational station distribution
本文利用沿渡河流域1981-1987年30場歷史洪水資料進行次洪模擬,其中降雨徑流及其他水文氣象數據均來源于流域測站觀測資料。挑選18場代表性洪水作為率定場次,其余12場作為驗證場次。
1.2 新安江模型
新安江模型是一個集中性概念式的流域水文模型,以蓄滿產流為基礎,主要由四個模塊構成,分別是產流計算、蒸發計算、水源劃分和匯流計算,模型計算流程如圖2所示[13]。
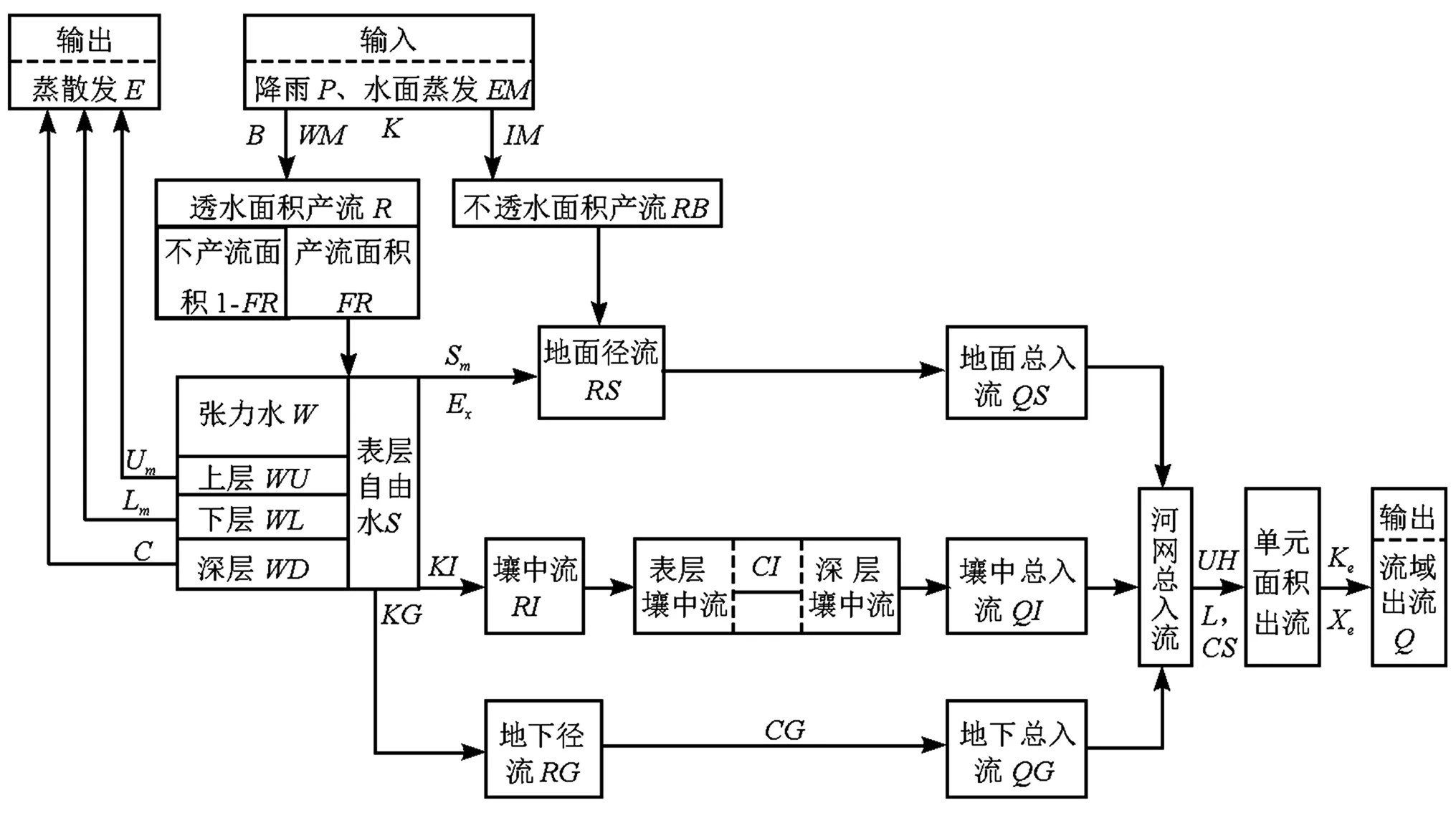
圖2 新安江模型(三水源)計算流程圖Fig.2 Framework of the Xin'anjiang Model (three runoff components)
本文應用的模型參數共有16個,其中產流計算參數10個:蒸發折算系數(K),蓄水容量曲線的方次(B),流域平均蓄水容量(WM),上層蓄水容量(WUM),下層蓄水容量(WLM),深層蒸散發系數(C),自由水蓄水容量(SM),自由水蓄水容量曲線的方次(EX),自由水蓄水庫補充地下水的出流系數(KG),自由水蓄水庫補充壤中流的出流系數(KI);匯流計算參數6個:地下水庫消退系數(CG),壤中流消退系數(CI),地表消退系數(CS),單元河段的馬斯京根模型參數K值(Ke)和X值(Xe),滯后演算參數(L)。
1.3 TOPMODEL
TOPMODEL是基于變動產流概念半分布式流域水文模型,考慮了流域地形地貌、土壤、地下水等影響因子,其計算包括地形指數計算、產流計算、匯流計算,模型計算流程圖如圖3所示[14]。
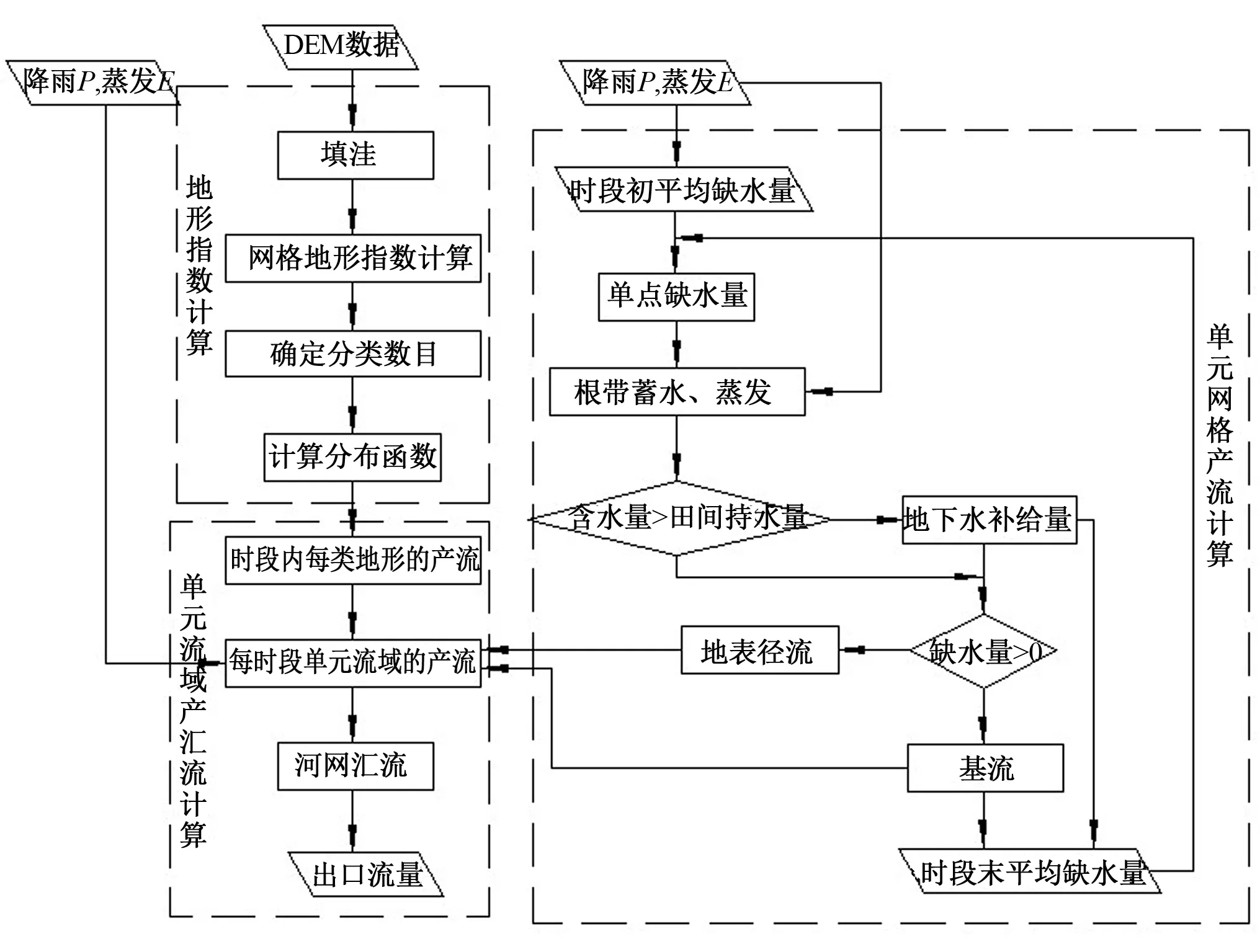
圖3 TOPMODEL計算流程圖Fig.3 Framework of the TOPMODEL model
TOPMODEL共有參數5個:土壤下滲率以指數形式降低的速率參數(m),剛達到飽和狀態時的土壤有效傳導率的自然對數ln(T0),根帶最大蓄水能力(SRmax),初始缺水量(SRinit),地表匯流的有效速度(Chvel)。
1.4 BP模型
BP模型是具有多層網絡,且可以逆序傳遞修正降低誤差的一種前饋神經網絡[15]。本文構建的BP模型結構為8-17-1(輸入層-隱含層-輸出層),其結構圖如圖4所示。圖中P代表降水,Q代表流量,N代表與模擬仿真函數相關的隱含層節點。
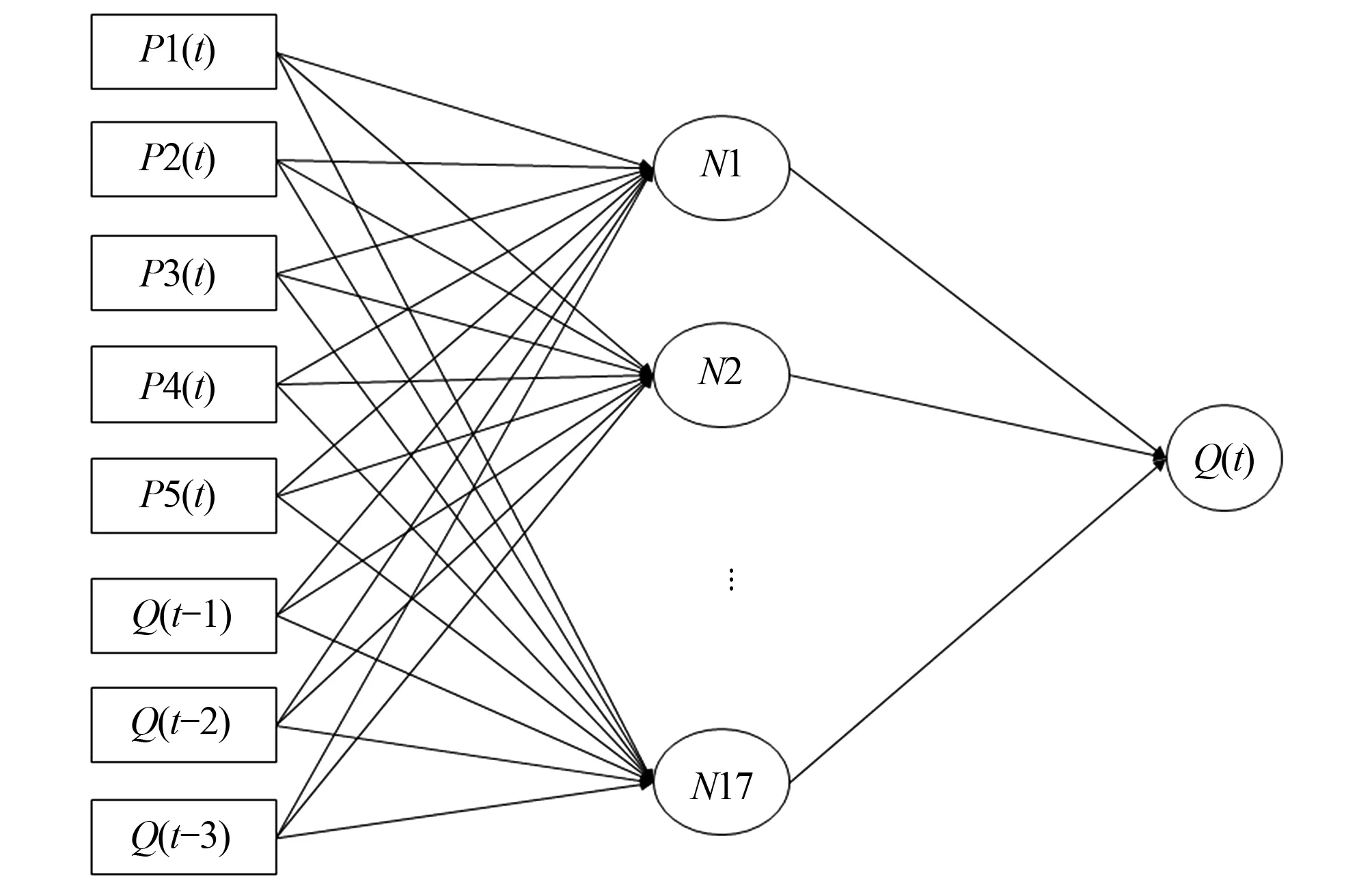
圖4 BP模型結構圖Fig.4 BP model flowchart
1.5 評價目標函數
選擇納什效率系數、相對誤差及峰現時刻誤差為目標函數進行模型參數率定,目標函數計算公式如下:
(1)
(2)
ΔT=T實測-T模擬
(3)
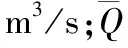
采用Rosenbrock優化算法進行模型參數率定[16];當NSE系數越接近1,徑流深相對誤差和峰現時刻誤差越接近0,說明模擬精度越高。
2 結果與討論
2.1 流域水文特性
圖5給出了沿渡河流域1981-1987年場次洪水降雨量、徑流深及徑流系數的變化。由圖5可以看出,有3場洪水的降水量和徑流深超過了200 mm,受降水因素影響,大量級洪水主要集中出現在1982年和1983年,1981年及1984-1987年間發生的洪水量級相對較小。一般而言,徑流系數均小于1,然而有接近半數的場次徑流系數的計算結果大于1,這并非違背水文過程的客觀規律,而是受前期退水影響和洪水場次劃分等方面的因素導致的,這一點在本文中并不影響洪水模擬的結果。
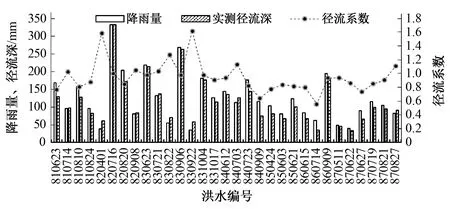
圖5 場次洪水降水量、徑流深及徑流系數圖Figu.5 Variation of rainfall, runoff and runoff coefficient at annual and flood-event scales
比較年尺度和場次尺度的徑流系數,年尺度和場次尺度的徑流系數均值分別為0.79和0.92,可見沿渡河流域屬于濕潤地區,徑流較為豐富。年尺度普遍低于洪水尺度的徑流系數,一方面是因為對于年平均徑流系數考慮了流域全年在豐平枯水季節的整體規律,而對于洪水徑流系數則著重考慮了汛期的變化規律;另一方面如前所述洪水過程的劃分受前期退水的影響,使得徑流系數偏大。
2.2 各模型應用與評價
對新安江模型、TOPMODEL、BP模型分別進行參數率定。對于新安江模型,先對日模型進行參數率定以滿足水量平衡的要求,再率定次洪模型,其中K、WM、B、C、EX、WUM、WLM在次洪模型中通用,其余參數中SM、KI、KG、CS、CG較為敏感,則參考目標函數評價結果在經驗取值范圍內進行率定。對于TOPMODEL,需要利用ArcGIS計算地形指數再率定,其中土壤下滲率參數m和傳導率參數ln(T0)較為敏感,新安江模型和TOPMODEL最終率定結果如表2所示。對于BP模型,選取tansig和logsig為激勵函數,采用Levenberg-Marquardt法訓練網絡,選取訓練步數為1 000,誤差取10-8,由8-17-1的模型結構可知,共有權值153個,閾值18個,采用自動優選方法進行率定,得出輸入層與隱含層、隱含層與輸出層之間的連接權值矩陣和隱含層、輸出層的閾值矩陣作為模型參數。

表1 新安江次洪模型參數率定結果Tab.1 The calibrated parameters of hourly-based event Xin’anjiang model
根據3種模型的參數率定結果進行洪水模擬,圖6給出了以830623號、830906號洪水代表的模擬場次及驗證場次的實測洪水過程線與不同模型模擬結果洪水過程線對比圖,并統計各模型模擬場次及驗證場次的平均徑流深、洪峰流量相對誤差,峰現時刻誤差和NSE效率系數,結果如表3所示。整體來看3種模型均取得了良好的模擬效果,平均徑流深誤差均底于12%,峰現時刻誤差維持在許可誤差3 h的范圍內,NSE效率系數均大于0.7。就驗證期來看,新安江模型模擬結果為三者最優,其徑流深平均誤差為8.14%,峰現時刻平均誤差1.67 h,NSE系數大于0.82,因此模擬精度較高。相對而言,BP模型模擬結果精度較低,各項指標評價值均為3種模型中最低的。

表2 TOPMODEL參數率定結果Tab.2 The calibrated parameters of the TOPMODEL
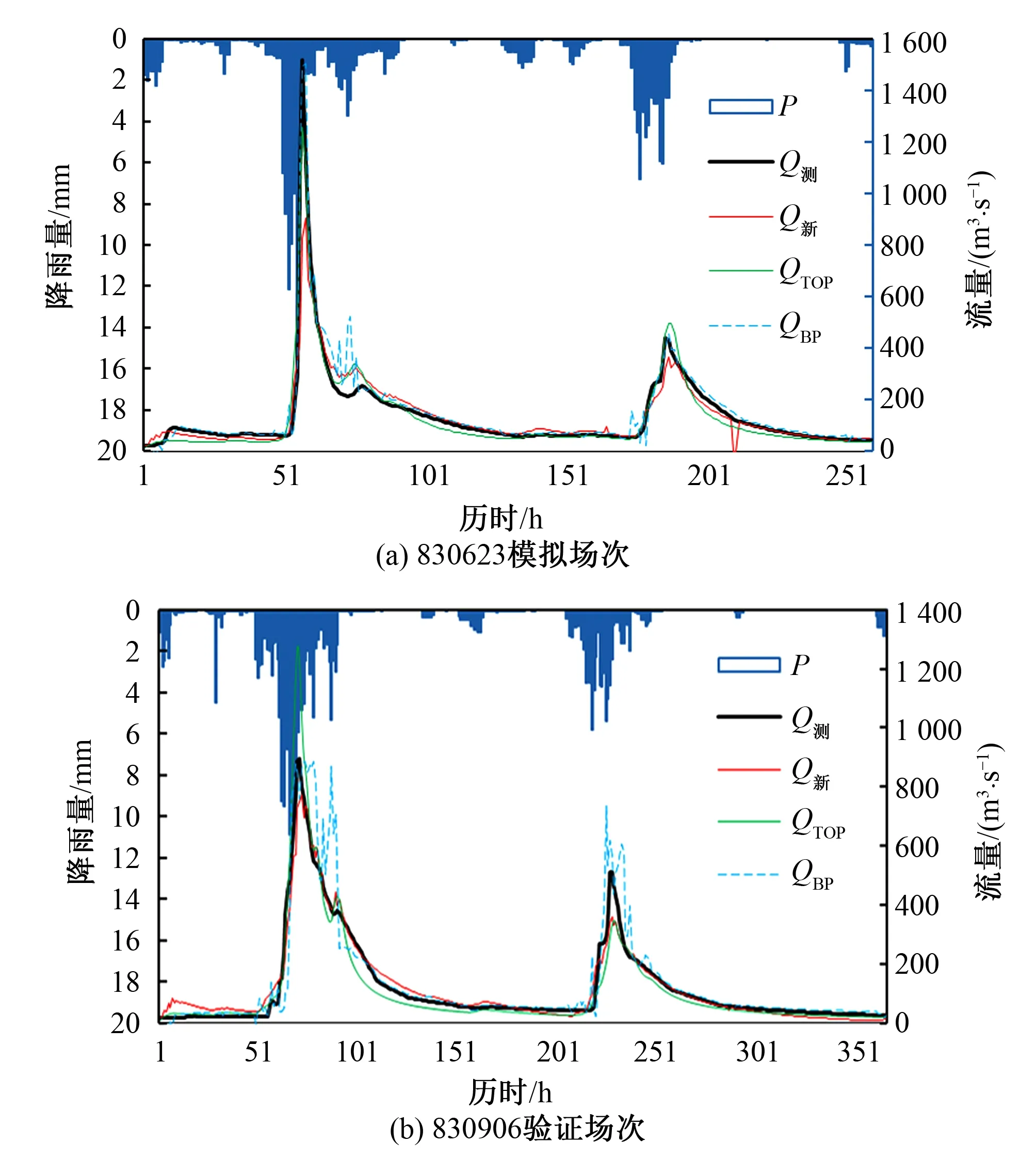
圖6 模擬及驗證場次洪水實測與模擬過程Fig.6 Recorded and simulated hydrographs of simulation and validation flood
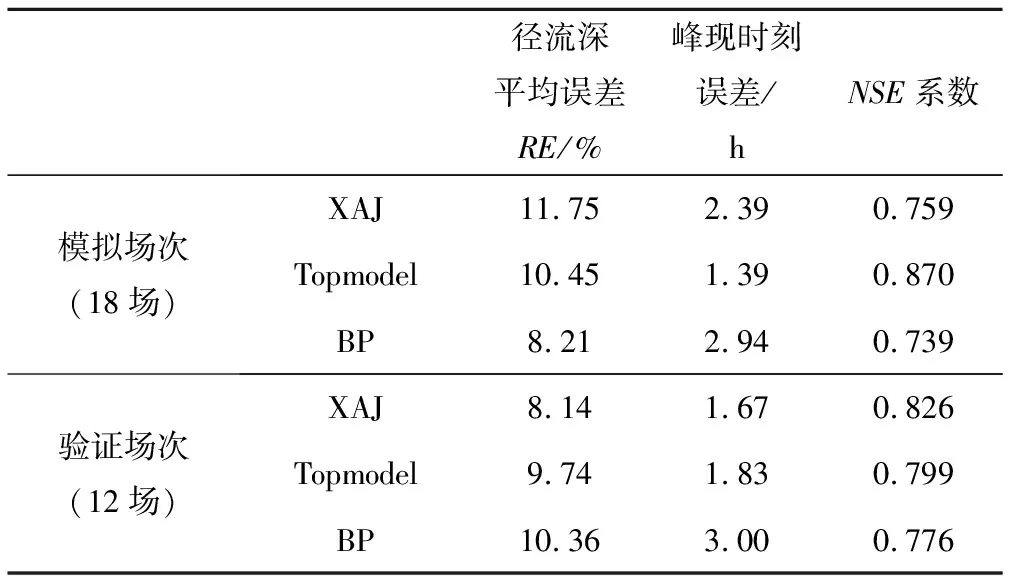
徑流深平均誤差RE/%峰現時刻誤差/hNSE系數模擬場次(18場)XAJ11.752.390.759Topmodel10.451.390.870BP8.212.940.739驗證場次(12場)XAJ8.14 1.67 0.826 Topmodel9.74 1.83 0.799 BP10.36 3.00 0.776
為觀察分析各場次洪水的模擬情況,繪制12場驗證洪水場次的徑流深相對誤差分布圖及NSE效率系數分布圖,如圖7所示。就徑流深相對誤差而言,新安江模型的相對誤差均在許可誤差20%以內,而TOPMODEL和BP模型分別有2場(840703、840909)和1場(831017)相對誤差超過20%,其對應的誤差值分別為20.34%、-24.65%、-23.63%。因此,從徑流深模擬的角度看,新安江模型效果最好,其次是BP模型,最后是Topmodel;就納什效率系數而言,3種模型驗證場次的納什效率系數均值分別為0.826、0.799、0.776,驗證洪水各場次的NSE系數均大于0.6,可見3種模型均達到了精度要求。 并且,NSE系數結果依舊為新安江模擬結果最好,均值達到了0.8以上。
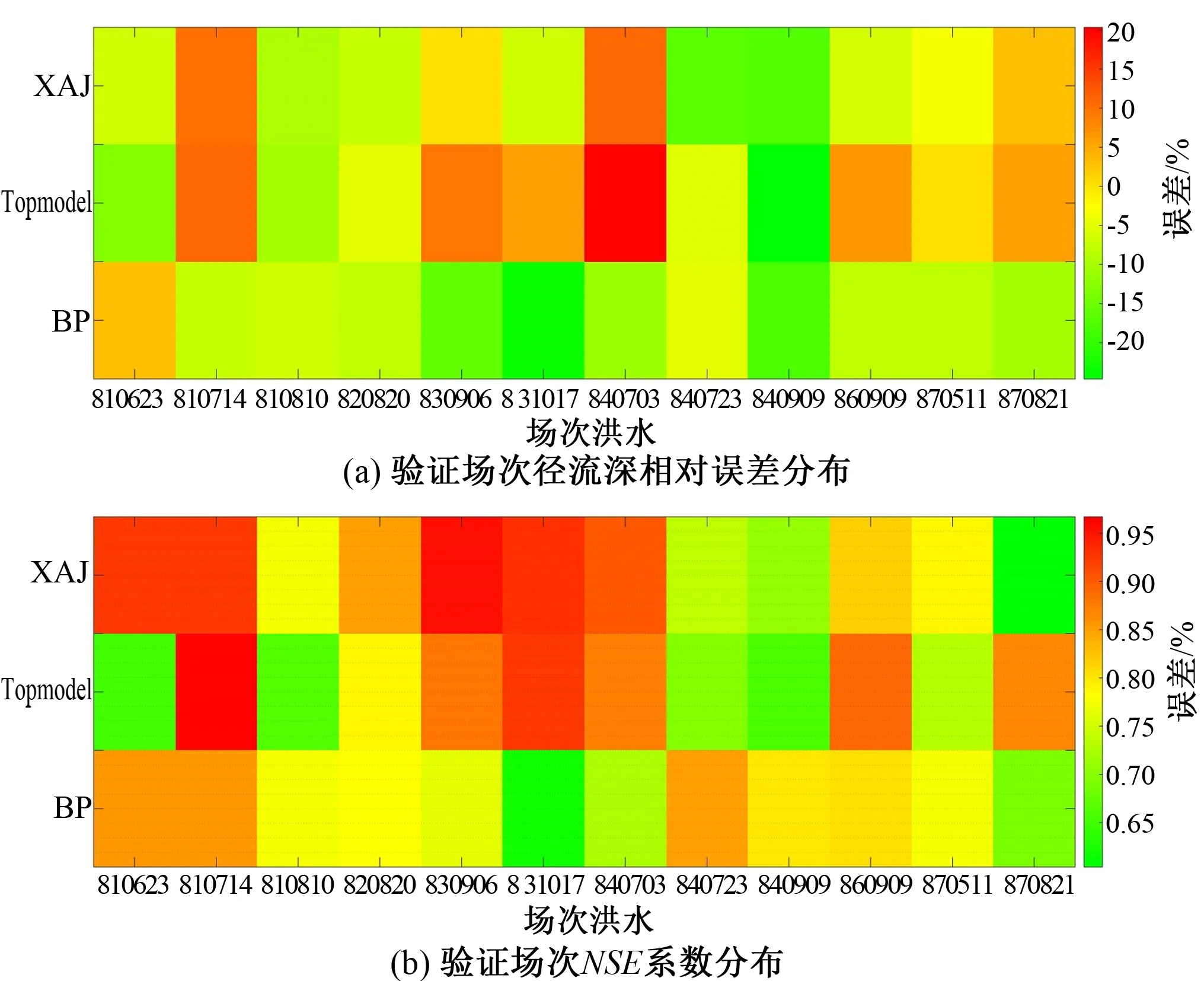
圖7 三種水文模型對洪水模擬效果的比較Figure 7 Comparison of relative errors
3種模型實測與模擬流量的散點圖如圖7所示,可以看出:①新安江模型、TOPMODEL和BP模型在實測與模擬流量之間存在良好的線性關系,其R2值均大于0.8。②BP模型和新安江模型實測與模擬流量點群的相關性分別達到了0.98和0.96,最為接近1∶1線,說明新安江模型和BP模型的模擬結果最接近于真實值,流量模擬效果最好。③TOPMODEL點群較為偏離1∶1線,相關系數為1.11,說明相較而言TOPMODEL在流量過程方面模擬結果相對較差一些,且可以看出其徑流模擬值相對實測值普遍偏高。
新安江模型是概念式水文模型,采用蓄滿產流計算,適用于濕潤地區水文模擬,而本研究區是位于長江上游的濕潤地區,新安江模型在此具有良好的適用性,取得了最佳的模擬精度。Topmodel模擬結果相對劣于新安江模型的原因是,參數m的確定與洪量洪峰有較大的關系,30場洪水中,洪水量級差異明顯,在率定過程中為保證整體精度率定得出的m,可能使得少數場次洪水的模擬精度不高。BP模型本質上是個黑箱模型,是基于數據驅動的仿真模擬模型,并沒有明確的物理成因規律,故其僅在各時刻徑流的數值模擬方面結果較好,因此在水量、峰現時刻和NSE系數方面的評價精度遠不如洪峰的模擬精度。

圖8 3種模型實測與模擬流量比較Fig.8 Comparison of the measured and simulated runoff of three models
3 結 語
(1)沿渡河流域是位于濕潤地區的典型中小尺度流域,在次洪模擬的過程中,不同模型在不同評價指標中表現出不同的性能。驗證期內新安江模型模擬的平均納什效率系數最大,徑流深相對誤差最小,峰現時刻誤差最小,取得了較高的精度。而Topmodel和BP模型模擬結果中,均有少數場次的誤差超出許可誤差要求,前者的水量和流量模擬在三種模型中相對較差;后者的劣勢則表現在水量和峰現時刻結果方面。此外,BP模型實測與模擬流量點群與1∶1線最為接近,說明BP模型在流量過程的數值模擬方面效果最好。綜合來看,新安江模型在研究區的適用性是最好的,Topmodel和BP模型次之。
(2)不同水文模型對自然現象概化方式不同,導致對于不同評價指標不同洪水場次,各模型的模擬結果之間存在差異,本文應用3種不同類型的模型對沿渡河流域洪水進行模擬,包括新安江模型(概念型集總式水文模型)、TOPMODEL(半分布式水文模型)、人工神經網絡模型(數據驅動下的黑箱模型)。這3個模型在各自的模型類別中都具有一定的代表性,將其應用于流域洪水模擬,并進行結果比較,分析各模型的流域適用性,從而為同類地區洪水預報方案的確立提供理論基礎和參考依據。
猜你喜歡
童話王國·奇妙邏輯推理(2024年5期)2024-06-19 16:03:38
網絡安全與數據管理(2022年1期)2022-08-29 03:15:20
導航定位學報(2022年4期)2022-08-15 08:27:00
中學生數理化·中考版(2022年8期)2022-06-14 06:55:24
新世紀智能(數學備考)(2021年9期)2021-11-24 01:14:36
成都醫學院學報(2021年2期)2021-07-19 08:35:14
新世紀智能(數學備考)(2020年9期)2021-01-04 00:25:14
中學生數理化·七年級數學人教版(2020年10期)2020-11-26 08:24:50
數學物理學報(2020年2期)2020-06-02 11:29:24
光學精密工程(2016年6期)2016-11-07 09:07:19
