基于SparkR的水文傳感器數據的異常檢測方法
2019-08-01 01:57:38劉子豪李凌葉楓
計算機應用 2019年2期
劉子豪 李凌 葉楓
摘 要:為了高效地從海量的水文傳感器數據中檢測出異常值,提出一種基于SparkR的水文時間序列異常檢測方法。首先,對數據進行清洗后,采用滑動窗口配合自回歸積分滑動平均模型(ARIMA)在SparkR平臺上進行預測;然后,對預測的結果計算置信區間,將在區間范圍以外的判定為異常值;最后,基于檢測結果,利用K均值算法對原數據進行聚類,同時計算其狀態轉移概率,對檢測出的異常值進行質量評估。以在滁河獲取的水文傳感器數據為實驗數據,分別在運行時間和異常值檢測效果這兩個方面進行了實驗。結果顯示:利用SparkR對百萬級數據進行計算時,利用雙節點計算的時間要長于單節點;但是對千萬級數據進行計算時,雙節點比單節點計算時間上更少,最多減少了16.21%,且評估過后的靈敏度由之前的5.24%提高到了92.98%。實驗結果表明,在SparkR下,根據水文數據的特點并結合預測檢驗和聚類校驗的方法對千萬級水文時間序列進行檢測時,能有效提高傳統方法的計算效率,并且在靈敏度方面相比傳統方法也有顯著提升。
關鍵詞:SparkR;自回歸積分滑動平均模型;異常檢測;水文時間序列;K均值
中圖分類號: TP391
文獻標志碼:A
Abstract: To efficiently detect outliers in massive hydrologic sensor data, an anomaly detection method for hydrological time series based on SparkR was proposed. Firstly, a sliding window and Autoregressive Integrated Moving Average (ARIMA) model were used to forecast the cleaned data on SparkR platform. Then, the confidence interval was calculated for the prediction results, and the results outside the interval range were judged as anomaly data. Finally, based on the detection results, K-Means algorithm was used to cluster the original data, the state transition probability was calculated, and the anomaly data were evaluated in quality. Taking the data of hydrologic sensor obtained from the Chu River as experimental data, experiments on the detection time and outlier detection performance were carried out respectively. The results show that the millions of data calculation by two slaves costs more time than that by one slave, but when calculating the tens of milllions of data, the time costed by two slaves is less than that by one slave, and the maximum reduction is 16.21%. The sensitivity of the evaluation is increased from 5.24% to 92.98%. It shows that under big data platform, the proposed algorithm which is based on the characteristics of hydrological data and combines forecast test and cluster test can effectively improve the computational efficiency of hydrologic time series detection for tens of millions data and has a significant improvement in sensitivity.
Key words: SparkR; AutoRegressive Integrated Moving Average (ARIMA) model; anomaly detection; hydrologic time series; K-Means
0 引言
水文數據是按其物理量分為各種類型的水文時間序列。目前許多專家認為,水文時間序列一般由確定分量和隨機分量組成。確定分量具有一定的物理概念,隨機分量則由不規則的震蕩和隨機影響產生[1]。水文時間序列主要表現出隨機性、模糊性、非線性、非平穩性和多時間尺度變化等復雜特性[2]。隨著物聯網、傳感器技術的迅猛發展,水利信息化部門越來越多地采用傳感器技術來獲取水文數據,這里面往往也包含許多異常值。對于水文時間序列來說,與一般規律相差較大的數值, 便可以將其判定為異常數據[3]。異常值往往包含著重要的信息,通過精確找到隱藏在數據背后的隱藏值,對之后的分析決策意義重大。目前,對于水文時間序列,傳統的方法只適用于小數據集,不適用于現在的大數據環境,且精度僅在特異度方面達到了99%[4]的水準,靈敏度仍有提升空間。以滑動窗口算法為例,雖然理論上它可以作用于任意長度的數據集,但是對于海量數據,它的計算復雜度較高且靈敏度低。
本文提出了一種基于SparkR的海量水文時間序列異常檢測方法,將預測檢驗和聚類檢測進行結合。首先,對得到數據進行清洗、降維、去重、篩選和排序;之后,采用滑動窗口配合自回歸積分滑動平均模型(AutoRegressive Integrated Moving Average, ARIMA)進行預測,并對預測的結果計算置信區間,在區間范圍以外的,將其判定為異常值。針對海量水文數據的特點,在檢測完成后利用K均值(K-Means)對原數據進行聚類,同時計算其狀態轉移概率,對檢測出的異常值進行質量評估,提高靈敏度。該方法可以在海量水文時間序列中有效提高滑動窗口法的計算效率,同時還給出了可靠的置信度來提升整體的靈敏度,能快速準確地在海量水文時間序列中檢測出異常值。相比傳統的滑動窗口檢測算法,本文利用大數據處理平臺SparkR提高了算法的計算效率;同時還提出了一種結合預測檢驗和聚類校驗的異常檢測方法,通過對傳統的滑動窗口算法進行校驗,保留了滑動窗口算法特異度高的優勢,并解決了該算法靈敏度過低的問題。
1 相關工作
1.1 異常檢測
異常值[5]是在數據集中偏離大部分數據的數據,這些數據疑似并非為隨機誤差所致,而是產生于完全不同的機制。對于異常檢測,一些有代表性的方法包括:牛麗肖等[6]提出的一種基于小波變換和ARIMA的短期電價混合預測模型, 該模型確實可以檢測到突變點的情況,但對非線性的部分或者時間序列過長的數據則存在著不足。任勛益等[7]提出了一種基于向量機和主元分析的異常檢測,先用主元分析法降低維度,再用支持向量機(Support Vector Machine, SVM)建模并檢驗異常數據;但當數據中存在較多種類異常值時,該方法的檢測精確度不高且計算復雜度高。孫建樹等[3]提出了基于ARIMA-SVM的水文時間序列異常值檢測,該方法使用ARIMA預測線性部分,使用SVM預測非線性部分,將兩部分的值相加得到最終預測的結果并將不在置信區間的值判定為異常值。這類算法在處理小規模數據集時效果較好,但是無法處理多元和大規模的數據,而且閾值的確定也較為困難。
基于距離檢測的方法是設定某種距離函數對數據點進行距離計算,當一個點與其余點距離過大時,將其視為異常點。Vy等[8]提出了針對時間序列可變長度的異常檢測算法:先對時間序列分段;然后對每種模式的異常因子進行計算,計算出異常因子之間的距離;最后根據該異常因子距離判斷是否為異常。該方法的優點是便于用戶使用,時間復雜度相對較小,不足在于對局部異常點不敏感。
Breunig等[9]提出了局部異常因子(Local Outlier Factor,LOF)的概念來計算數據集密度。LOF越大,意味著對象離群程度越高,是異常值可能性就越高;但是不同密度的子集混合會造成檢測錯誤,雖然后續又有人提出了相關改進方案,但是總體時間復雜度較高。
1.2 SparkR
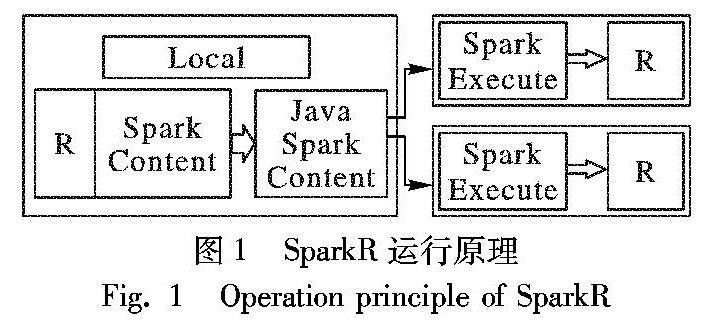
SparkR[14]是一個提供輕量級前端用于在R中使用Apache Spark的R包,它提供了分布式數據框架接口,可以支持選擇、過濾、聚集等操作。到Spark2.3.0,SparkR可以用來操作數據框,而且可以通過MLlib使用分布式的機器學習。彈性分布式數據集(Resilient Distributed Dataset, RDD)是Spark的基礎數據模型[15],是容錯、并行、只讀的數據結構,它允許用戶存儲數據在磁盤和內存中,并且控制數據分區;同時,它也是一個分布式的內存抽象,代表一個只讀部分記錄的集合,并且只能被存儲在穩定的物理存儲或者其他現有的RDD中;它只能通過對數據集執行某些確定性的操作來創建;而且它只支持粗粒度轉換,也就是說在許多記錄上執行單個操作。DataFrame是Spark推出的應用程序編程接口(Application Programming Interface, API),主要應用于大數據處理方面,基于DataFrame,所有主要的數據源會被連接并自動轉換為并行處理形式。DataFrame是Spark SQL、Streaming和MLlib的基礎。SparkR支持常見的閉包功能,用戶定義函數中引用的變量會自動發送到群集中的其他計算機。SparkR的運行原理如圖1所示。
2 關鍵實現
2.1 算法描述
本文基于SparkR的水文時間序列異常檢測算法結合了預測檢驗和聚類檢測兩個過程。首先,采用預測檢驗的思想對時間序列{x1,x2,…,xn}建立ARIMA模型,采用滑動窗口的方式得到預測出的置信區間,并與原數據進行對比,識別出異常值;在檢測出異常值之后,采用K-Means算法對原始的數據進行聚類,聚類出結果之后計算出其狀態轉移矩陣,用狀態轉移矩陣對之前得到的異常值進行異常評估,最后確定異常值。
2.2 基于滑動窗口的異常值檢測
定義水文時間序列X中待檢測點Xi的滑動鄰居窗口Li,為了降低算法復雜性,采用該點的前L個點作為預測模型輸入參數進行計算。本算法選擇預測節點的左鄰居窗口作為算法輸入,單邊定義如下:
基于滑動窗口的異常檢測,核心是建立ARIMA模型[16],通過滑動窗口的輸入來預測觀測點的值,得到一系列預測值。首先要對時間序列進行單位根檢驗,如果是非平穩序列,就要通過差分來轉化為平穩序列。以AIC(Akaike Information Criterion)為準,需要確定自回歸階數p和移動平均階數q,找出具有最小ACI值的p、q組合。ARIMA模型是針對非平穩時間序列建模,適用于水文時間序列。本文取置信區間為95%。將ARIMA模型計算出的置信區間與原始序列進行比較,不在置信區間內的即判定為異常值。
2.3 基于K-Means模型的異常值校驗
2.3.1 狀態轉移概率矩陣
通過滑動窗口配合ARIMA識別出異常值之后,還要計算出異常點的置信度,用來判定該點是否確實為異常點,以減少誤判,降低人工工作量。
K-Means算法屬于聚類算法中的一種,其原理是:給定K(K代表要將數據分成的類別數)的值,然后根據數據間的相似度將數據分成K個類,也稱為K個簇(cluster)。度量數據相似度的方法一般是用數據點間的距離來衡量,比如歐氏距離、漢明距離、曼哈頓距離等。一般來說,可使用歐氏距離來度量數據間的相似性。比如,對于二維平面上的兩個點A(x1,y2)和B(x2,y2),兩者間的歐氏距離為:(x1-x2)2+(y1-y2)2。
而對于每一個簇,用簇中所有點的中心來描述,該中心也稱為質心(centroid)。通過對簇中的所有數據點取均值(mean)的方法來計算質心。具體來說,K-Means將整個時間序列{x1,x2,…}作為輸入,序列T={T1,T2,…}作為輸出,將時間序列上的點轉換為各個聚類點,{T1,T2,…}表示這一時間點上屬于哪一個中心,對時間序列進行了狀態分類。之后用前面獲得的異常值和其前一時刻值當作輸入,提供給K-means模型后,計算每個樣本與聚類中心的距離,即計算樣本與狀態向量的相似度,然后把聚類中心分配給每一個樣本。
K-Means模型訓練結束后,可以得到狀態序列T,通過計算可以得到一個狀態轉移矩陣,為了便于之后的計算,將矩陣轉換為數據框。該數據框有三列,第一列代表狀態i,第二列代表狀態j,第三列表示狀態i轉移到j的概率。假設某時間序列{xi,xi+1}通過 K-Means模型轉換得到對應的狀態序列為prob,Xi+1出現在Xi之后,換言之相當于發生了一次從狀態Ti到Tj的轉移,轉移概率為:
pij=狀態Ti轉移到狀態Tj的次數狀態Ti轉移到所有其他狀態的次數
2.3.2 異常值校驗
本文采用發生轉移的概率與由前一時刻的狀態轉移到下一個最有可能的狀態的概率相比,作為評價標準。假設Xi為待檢驗異常點,前一時刻的值為Xi-1,轉換后得到的狀態為Ti和Ti-1,Ti-1最有可能轉移到的狀態記為Tm,由此定義一個異常值概率:
pi=1-狀態Ti-1轉移到狀態Ti的概率狀態Ti-1轉移到Tm的概率由上式可知,狀態Ti-1轉移到Tm的概率為定值,狀態Ti-1轉移到狀態Ti的概率越小,pi越大,則Xi為異常值的概率越大。
由于現實中水文數據的異常判定往往以變化量大于2cm作為異常值的判定,利用K-Means作聚類可能會出現異常值和其前一時刻的值處于同一狀態下而導致漏判的情況,故在判定異常值后需要將異常值概率為0但是相差大于2cm的值也判定為異常值。
2.3.3 SparkR
本次實驗基于Spark RDD/DataFrame 形成數據模型,并將所有的數據通過相應的數據源輸入并轉換成RDD/DataFrame 模式。應用gapply函數可以實現在SparkR上運行R程序。
3 實驗與討論
3.1 實驗環境和配置
本次仿真使用雙節點:一臺PC為8核,8GB內存;另一臺PC為16核,8GB內存。相關軟件版本如下:Java 1.8,Spark 2.3,Hadoop 2.7,R 3.4.4和SparkR 2.3。實驗數據來自江蘇省各個水文站從2016年到2017年的數據,共18910864條數據。
3.2 實驗結果與分析
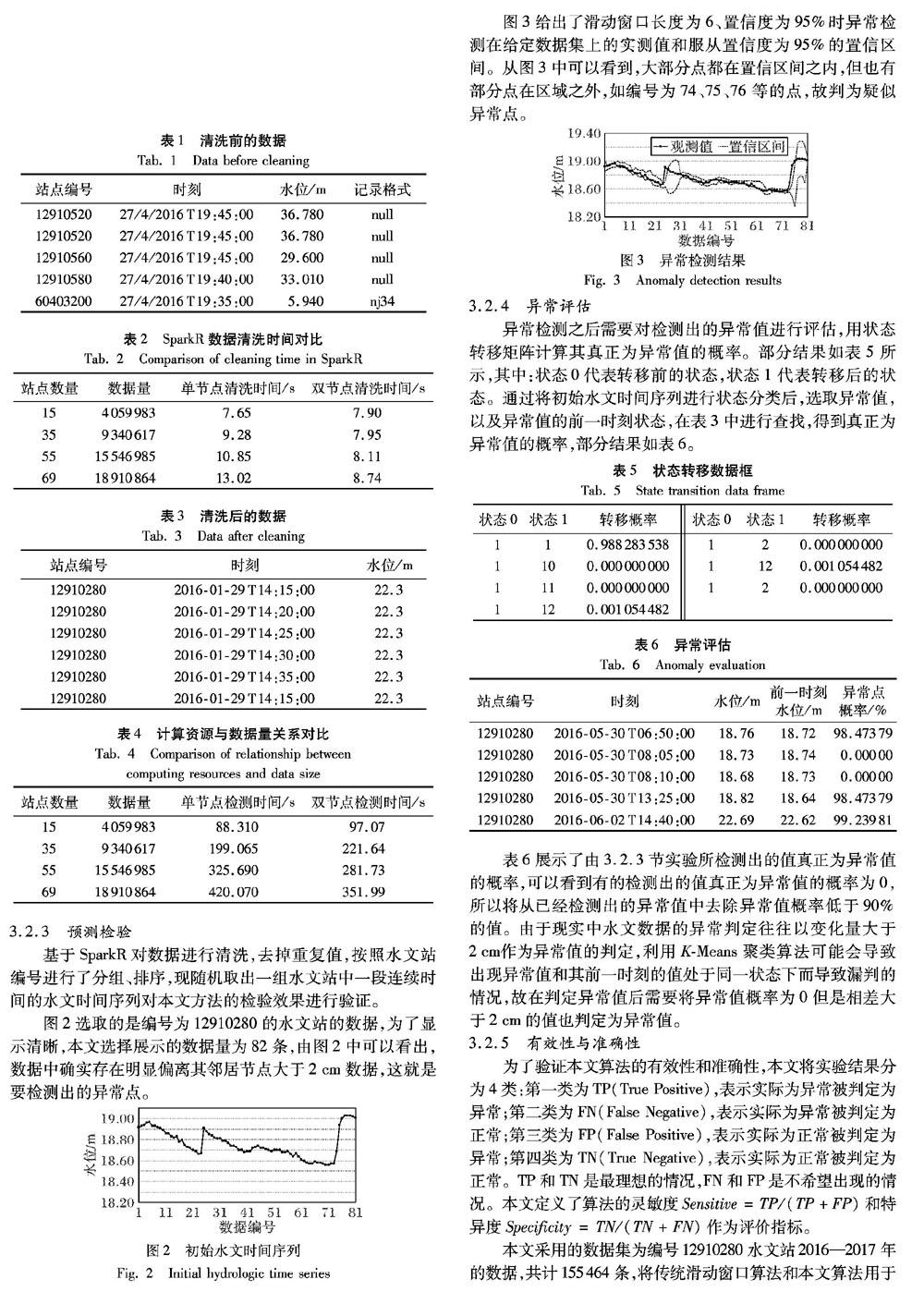
3.2.1 數據清洗
在進行異常檢測之前,需要對取得的數據進行數據清洗,清洗前部分數據如表1所示。從表1可以看到,原始數據存在諸多問題,如重復、排序混亂、時刻格式不符合數據挖掘要求、存在無關數列等。針對以上問題,本文基于SparkR對初始的18910864條水文數據進行了清洗,并比較了計算資源和數據量的關系,結果如表2所示。
如表2所示,當選取15個站點時,雙節點的運行速度慢于單個節點,但隨著數據量的增加,用雙節點計算的結果變化浮動較小,而只用單節點時間有著明顯上升。SparkR在數據清洗后的部分數據如表3所示。可以看到,數據按照水文站編號進行了分組并按時間順序排列,同時刪除了跟結果無關的記錄格式列,降低了計算量。經清洗后,數據只剩下水文站編號、時間以及水位值,符合數據挖掘要求。
3.2.2 檢測時間
本節實驗主要針對基于滑動窗口進行時間序列預測時計算復雜度高、運行計算時間過長的問題,采用SparkR進行計算,比較不同的計算資源下利用SparkR執行該算法的時間,結果如表4所示。可以看到,在選擇的15個和35個水文站點數據下,雙節點運行速度并不理想,但當數據量上升到千萬級別時,雙節點的優勢就可以體現出來,時間增長速度以及計算時間都占據優勢。可見,在更大的數據集下,雙節點下運行速度更快,最快情況下檢測時間減少了16.21%。
3.2.5 有效性與準確性
為了驗證本文算法的有效性和準確性,本文將實驗結果分為4類:第一類為TP(True Positive),表示實際為異常被判定為異常;第二類為FN(False Negative),表示實際為異常被判定為正常;第三類為FP(False Positive),表示實際為正常被判定為異常;第四類為TN(True Negative),表示實際為正常被判定為正常。TP和TN是最理想的情況,FN和FP是不希望出現的情況。本文定義了算法的靈敏度Sensitive=TP/(TP+FP)和特異度Specificity=TN/(TN+FN)作為評價指標。
本文采用的數據集為編號12910280水文站2016—2017年的數據,共計155464條,將傳統滑動窗口算法和本文算法用于同一水文時間序列進行了對比,結果如表7所示。由表7可以看到,改進后的模型保留了滑動窗口檢測的優勢,在FN和TP方面保持不變,保留了傳統方法在特異度方面的優勢,但在FP方面,因為先前給予滑動窗口預測的方法在判斷異常值方面界限比較模糊,對于日均水文數據,由于數值間相差較大,所以靈敏度即正確率比較高,但是對于每隔5min接收一次的水文傳感器數據來說,水位變化較小,誤檢率就會變高,因此在檢測完之后添加了異常值評估,這樣可以顯著減少錯判,提升正確率。
經計算,在特異度方面二者相差無幾,改進前為99.95%,改進后為99.97%,但靈敏度由改進前的5.24%提高到了92.15%,得到了顯著的提高。這表明本文算法在傳統算法的基礎上引入SparkR后解決了傳統滑動窗口算法計算復雜度高的問題,同時通過增加聚類校驗能夠有效地檢測出水文時間序列中的異常值,且正確率也比較高。
4 結語
在大數據背景下,傳統的檢測算法已經不能夠適應當今的需求。本文利用滑動窗口的特點,同時針對傳統滑動窗口檢驗的缺陷,如時間復雜度高、誤檢率高等缺點,提出了一種基于SparkR的水文時間序列異常檢測方法。該方法使用SparkR進行計算,減少了計算時間;而且結合了預測檢驗和聚類檢測兩個過程,利用ARIMA模型對時間序列的水文數據進行建模來預測可能的異常點,再利用K-means聚類后計算狀態轉移矩陣,根據水文數據的特點對異常點進行判定。結果表明:基于SparkR對百萬級數據進行計算時,利用雙節點計算的時間要長于單節點;但是對千萬級數據進行計算時,雙節點比單節點計算時間少,時間最多能減少1621%;且評估過后的靈敏度由之前的5.24%提高到了9298%。這表明本文算方法在對千萬級水文數據進行檢測時,利用SparkR通過增加節點的方式可以有效提高滑動窗口法的計算效率,而且在靈敏度方面相比傳統滑動窗口檢測方法也有顯著提升。但是,本文算法在檢測正確率上仍有進一步完善的空間,后續工作將聚焦于更加精確地辨識出哪些為異常值、哪些為由自然因素引起的正常波動。
參考文獻:
[1] 吳德.水文時間序列相似模式挖掘的研究與應用[D].南京:河海大學,2007.(WU D. Research and application of hydrological time series similarity pattern[D]. Nanjing: Hohai University, 2007.)
[2] 桑燕芳,王中根,劉昌明.水文時間序列分析方法研究進展[J].地理科學進展,2013,32(1):20-30. (SANG Y F, WANG Z G, LIU C M. Research progress on the time series analysis methods in hydrology[J]. Progress in Geography, 2013, 32(1): 20-30.)
[3] 孫建樹,婁淵勝,陳裕俊.基于ARIMA-SVR的水文時間序列異常值檢測[J].計算機與數字工程,2018,46(2):225-230. (SUN J S, LOU Y S, CHEN Y J. Outlier detection of hydrological time series based on ARIMA-SVR model[J]. Computer & Digital Engineering, 2018, 46(2):225-230.)
[4] 余宇峰,朱躍龍,萬定生,等.基于滑動窗口預測的水文時間序列異常檢測[J].計算機應用,2014,34(8):2217-2220,2226. (YU Y F, ZHU Y L, WAN D S, et al. Time series outlier detection based on sliding window prediction[J]. Journal of Computer Applications,2014,34(8):2217-2220,2226.)
[5] HAWKINS D M. Identification of Outliers[M]. Berlin: Springer, 1980:27-41
[6] 牛麗肖,王正方,臧傳治,等.一種基于小波變換和ARIMA的短期電價混合預測模型[J].計算機應用研究,2014,31(3):688-691. (NIU L X, WANG Z F, ZANG C Z, et al. Hybrid model based on wavelet and ARIMA for short-term electricity price forecasting[J]. Application Research of Computers,2014,31(3):688-691.)
[7] 任勛益,王汝傳,孔強.基于主元分析和支持向量機的異常檢測[J].計算機應用研究,2009,26(7):2719-2721. (REN X Y, WANG R C, KONG Q. Principal component analysis and support vector machine based anomaly detection[J]. Application Research of Computers,2009,26(7):2719-2721.)
[8] VY N D K, ANH D T. Detecting variable length anomaly patterns in time series data[C]// Proceedings of the 2016 International Conference on Data Mining and Big Data, LNCS 9714. Berlin:Springer, 2016: 279-287.
[9] BREUNIG M M, KRIEGEL H-P, NG R T, et al. LOF: Identifying density-based local outliers[C]// Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data. New York: ACM, 2000:93-104.
[10] 潘淵洋,李光輝,徐勇軍.基于DBSCAN的環境傳感器網絡異常數據檢測方法[J].計算機應用與軟件,2012,29(11):69-72. (PAN Y Y, LI G H, XU Y J. Abnormal data detection method for environment wireless sensor networks based on DBSCAN[J]. Computer Applications and Software, 2012, 29(11): 69-72.)
[11] twitter/AnomalyDEtection [EB/OL]. [2015-09-01]. https://github.com/twitter/AnomalyDetection.
[12] 楊志勇,朱躍龍,萬定生.基于知識粒度的時間序列異常檢測研究[J].計算機技術與發展,2016,26(7):51-54. (YANG Z Y, ZHU Y L, WAN D S. Research on time series anomaly detection based on knowledge granularity[J]. Computer Technology and Development, 2016, 26(7):51-54.)
[13] 劉雪梅,王亞茹.基于異常因子的時間序列異常模式檢測[J].計算機技術與發展,2018,28(3):93-96. (LIU X M, WANG Y R. Anomaly pattern detection in time series based on outlier factor[J]. Computer Technology and Development, 2018, 28(3):93-96.)
[14] Spark R (R frontend for Spark) [EB/OL]. [2016-06-11]. https://github.com/amplab-extras/SparkR.pkg.
[15] 譚旭杰,鄧長壽,董小剛,等.SparkDE:一種基于RDD云計算模型的并行差分進化算法[J].計算機科學,2016,43(9):116-119,139. (TAN X J, DENG C S, DONG X G, et al. SparkDE: a parallel version of differential evolution based on resilient distributed datasets model in cloud computing[J]. Computer Science, 2016, 43(9):116-119,139.)
[16] CONTRERAS J, ESPINOLA R, NOGALES F J, et al. ARIMA models to predict next-day electricity prices[J]. IEEE Transactions on Power Systems,2003,18(3):1014-1020.
